手把手教你使用YOLOV5训练自己的目标检测模型
大家好,这里是肆十二(dejahu),好几个月没有更新了,这两天看了一下关注量,突然多了1k多个朋友关注,想必都是大作业系列教程来的小伙伴。既然有这么多朋友关注这个大作业系列,并且也差不多到了毕设开题和大作业提交的时间了,那我直接就是一波更新。这期的内容相对于上期的果蔬分类和垃圾识别无论是在内容还是新意上我们都进行了船新的升级,我们这次要使用YOLOV5来训练一个口罩检测模型,比较契合当下的疫情,并且目标检测涉及到的知识点也比较多,这次的内容除了可以作为大家的大作业之外,也可以作为一些小伙伴的毕业设计。废话不多说,我们直接开始今天的内容。
B站讲解视频:手把手教你使用YOLOV5训练自己的目标检测模型_哔哩哔哩_bilibili
CSDN博客:手把手教你使用YOLOV5训练自己的目标检测模型-口罩检测-视频教程_dejahu的博客-CSDN博客
代码地址:YOLOV5-mask-42: 基于YOLOV5的口罩检测系统-提供教学视频 (gitee.com)
处理好的数据集和训练好的模型:YOLOV5口罩检测数据集+代码+模型2000张标注好的数据+教学视频.zip-深度学习文档类资源-CSDN文库
更多相关的数据集:目标检测数据集清单-附赠YOLOV5模型训练和使用教程_dejahu的博客-CSDN博客
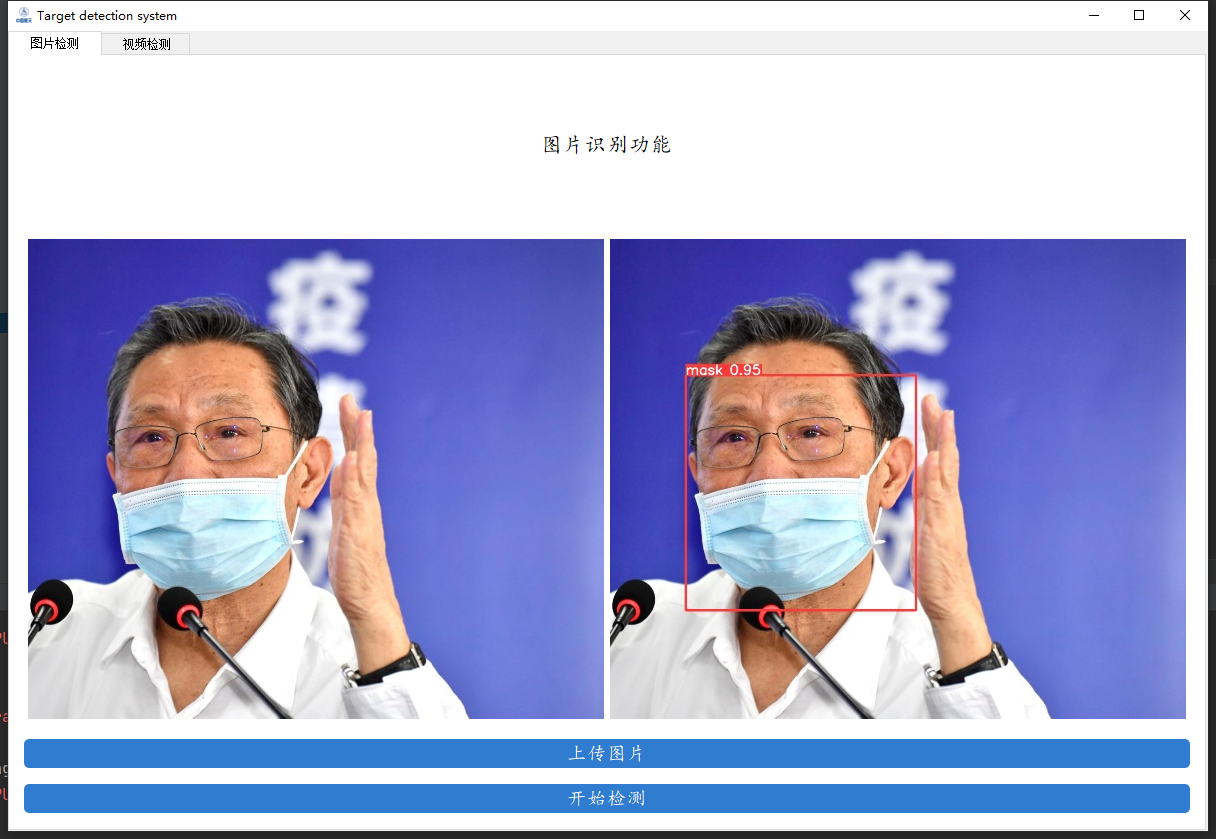
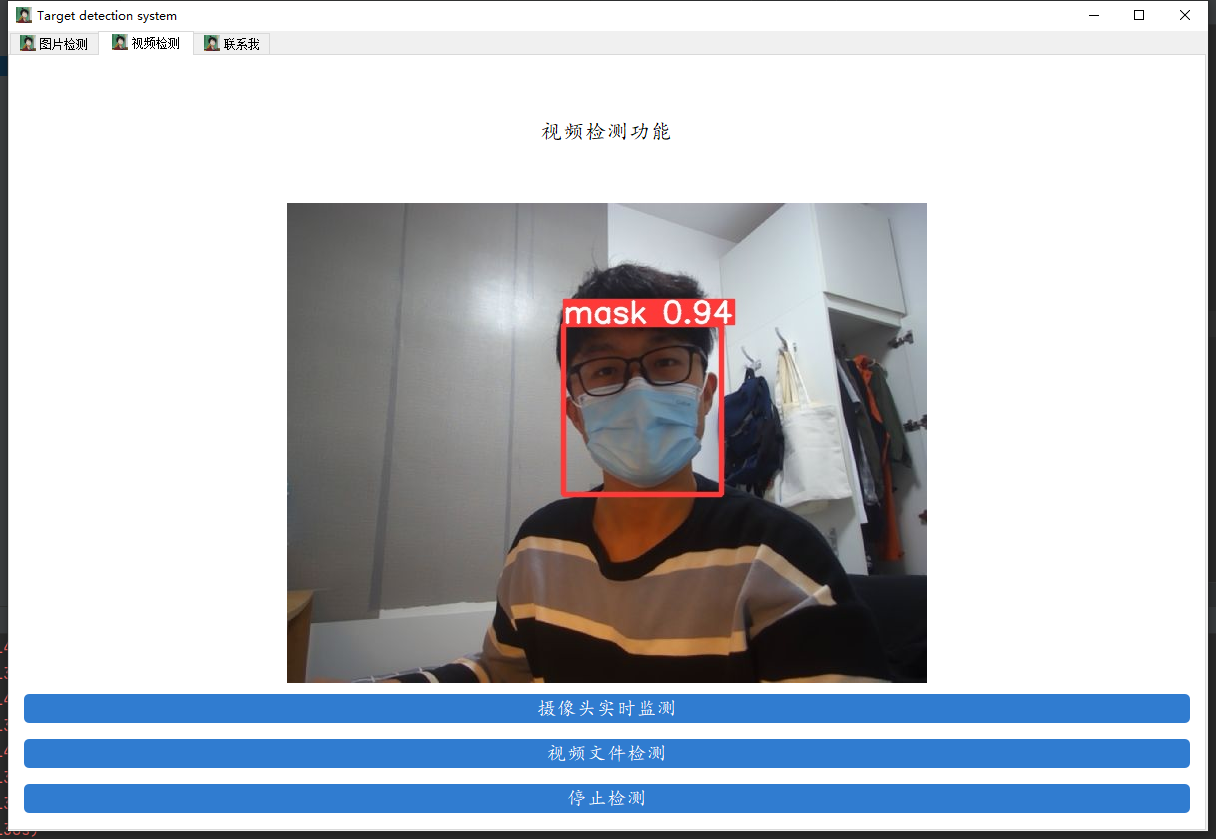
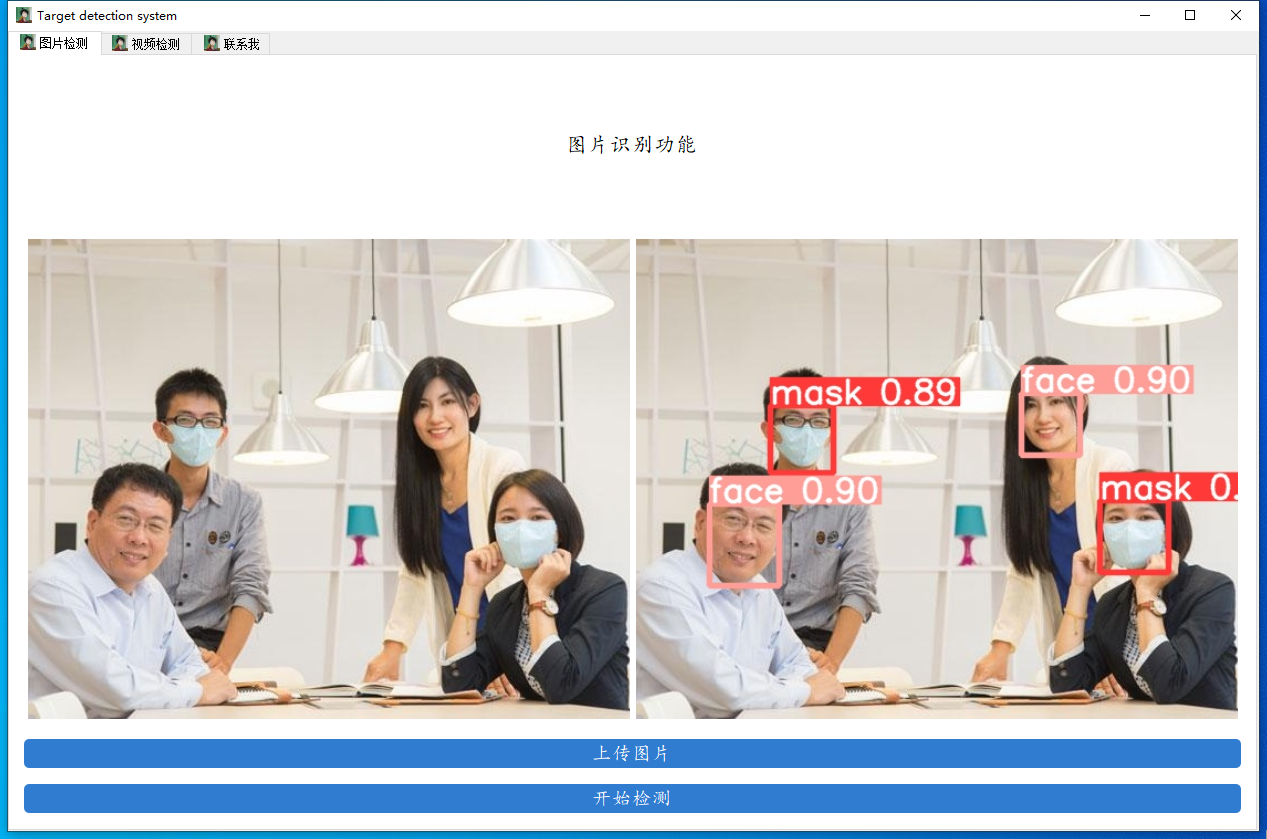
先来看看我们要实现的效果,我们将会通过数据来训练一个口罩检测的模型,并用pyqt5进行封装,实现图片口罩检测、视频口罩检测和摄像头实时口罩检测的功能。
下载代码
代码的下载地址是:[YOLOV5-mask-42: 基于YOLOV5的口罩检测系统-提供教学视频 (gitee.com)](https://github.com/ultralytics/yolov5)
配置环境
不熟悉pycharm的anaconda的小伙伴请先看这篇csdn博客,了解pycharm和anaconda的基本操作
如何在pycharm中配置anaconda的虚拟环境_dejahu的博客-CSDN博客_如何在pycharm中配置anaconda
anaconda安装完成之后请切换到国内的源来提高下载速度 ,命令如下:
conda config --remove-key channelsconda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/main/conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/free/conda config --add channels https://mirrors.bfsu.edu.cn/anaconda/cloud/pytorch/conda config --set show_channel_urls yespip config set global.index-url https://mirrors.ustc.edu.cn/pypi/web/simple首先创建python3.8的虚拟环境,请在命令行中执行下列操作:
conda create -n yolo5 python==3.8.5conda activate yolo5pytorch安装(gpu版本和cpu版本的安装)
实际测试情况是YOLOv5在CPU和GPU的情况下均可使用,不过在CPU的条件下训练那个速度会令人发指,所以有条件的小伙伴一定要安装GPU版本的Pytorch,没有条件的小伙伴最好是租服务器来使用。
GPU版本安装的具体步骤可以参考这篇文章:2021年Windows下安装GPU版本的Tensorflow和Pytorch_dejahu的博客-CSDN博客
需要注意以下几点:
安装之前一定要先更新你的显卡驱动,去官网下载对应型号的驱动安装30系显卡只能使用cuda11的版本一定要创建虚拟环境,这样的话各个深度学习框架之间不发生冲突我这里创建的是python3.8的环境,安装的Pytorch的版本是1.8.0,命令如下:
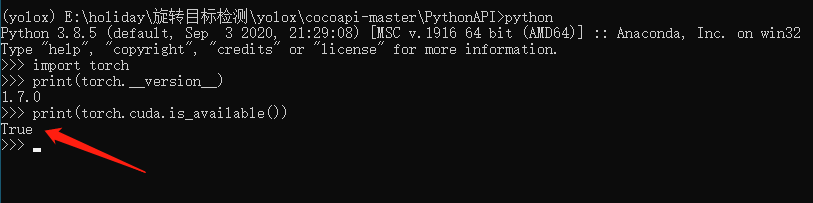
conda install pytorch==1.8.0 torchvision torchaudio cudatoolkit=10.2 # 注意这条命令指定Pytorch的版本和cuda的版本conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cpuonly # CPU的小伙伴直接执行这条命令即可安装完毕之后,我们来测试一下GPU是否
pycocotools的安装
后面我发现了windows下更简单的安装方法,大家可以使用下面这个指令来直接进行安装,不需要下载之后再来安装
pip install pycocotools-windows其他包的安装
另外的话大家还需要安装程序其他所需的包,包括opencv,matplotlib这些包,不过这些包的安装比较简单,直接通过pip指令执行即可,我们cd到yolov5代码的目录下,直接执行下列指令即可完成包的安装。
pip install -r requirements.txtpip install pyqt5pip install labelme测试一下
在yolov5目录下执行下列代码
python detect.py --source data/images/bus.jpg --weights pretrained/yolov5s.pt执行完毕之后将会输出下列信息

在runs目录下可以找到检测之后的结果
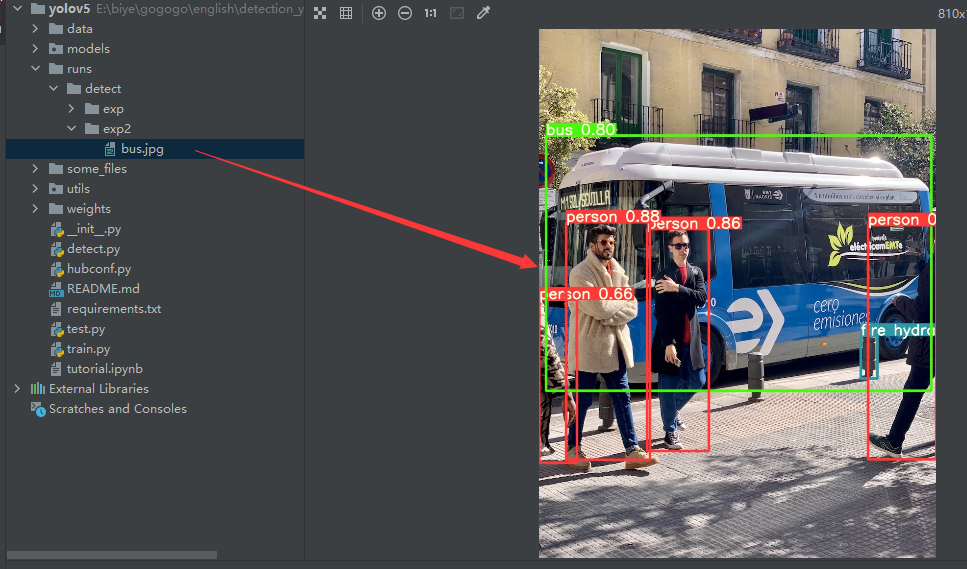
按照官方给出的指令,这里的检测代码功能十分强大,是支持对多种图像和视频流进行检测的,具体的使用方法如下:
python detect.py --source 0 # webcam file.jpg # image file.mp4 # video path/ # directory path/*.jpg # glob 'https://youtu.be/NUsoVlDFqZg' # YouTube video 'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream数据处理
这里改成yolo的标注形式,之后专门出一期数据转换的内容。
数据标注这里推荐的软件是labelimg,通过pip指令即可安装
在你的虚拟环境下执行pip install labelimg -i https://mirror.baidu.com/pypi/simple命令进行安装,然后在命令行中直接执行labelimg软件即可启动数据标注软件。
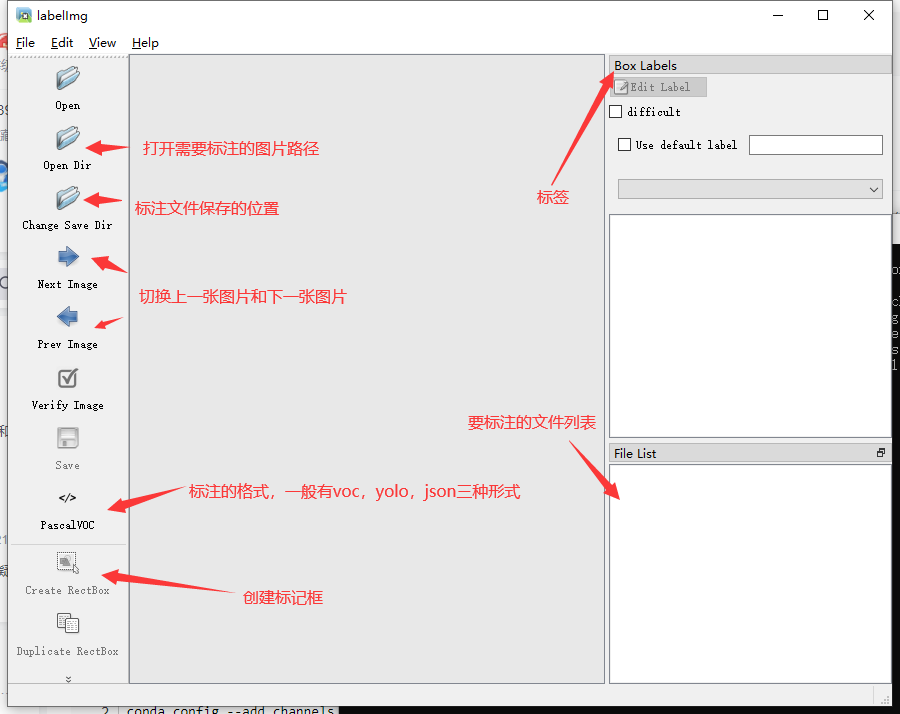
软件启动后的界面如下:
数据标注
虽然是yolo的模型训练,但是这里我们还是选择进行voc格式的标注,一是方便在其他的代码中使用数据集,二是我提供了数据格式转化
标注的过程是:
1.打开图片目录
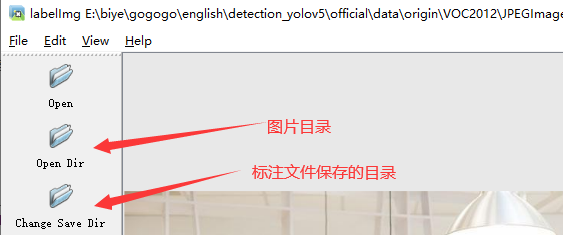
2.设置标注文件保存的目录并设置自动保存

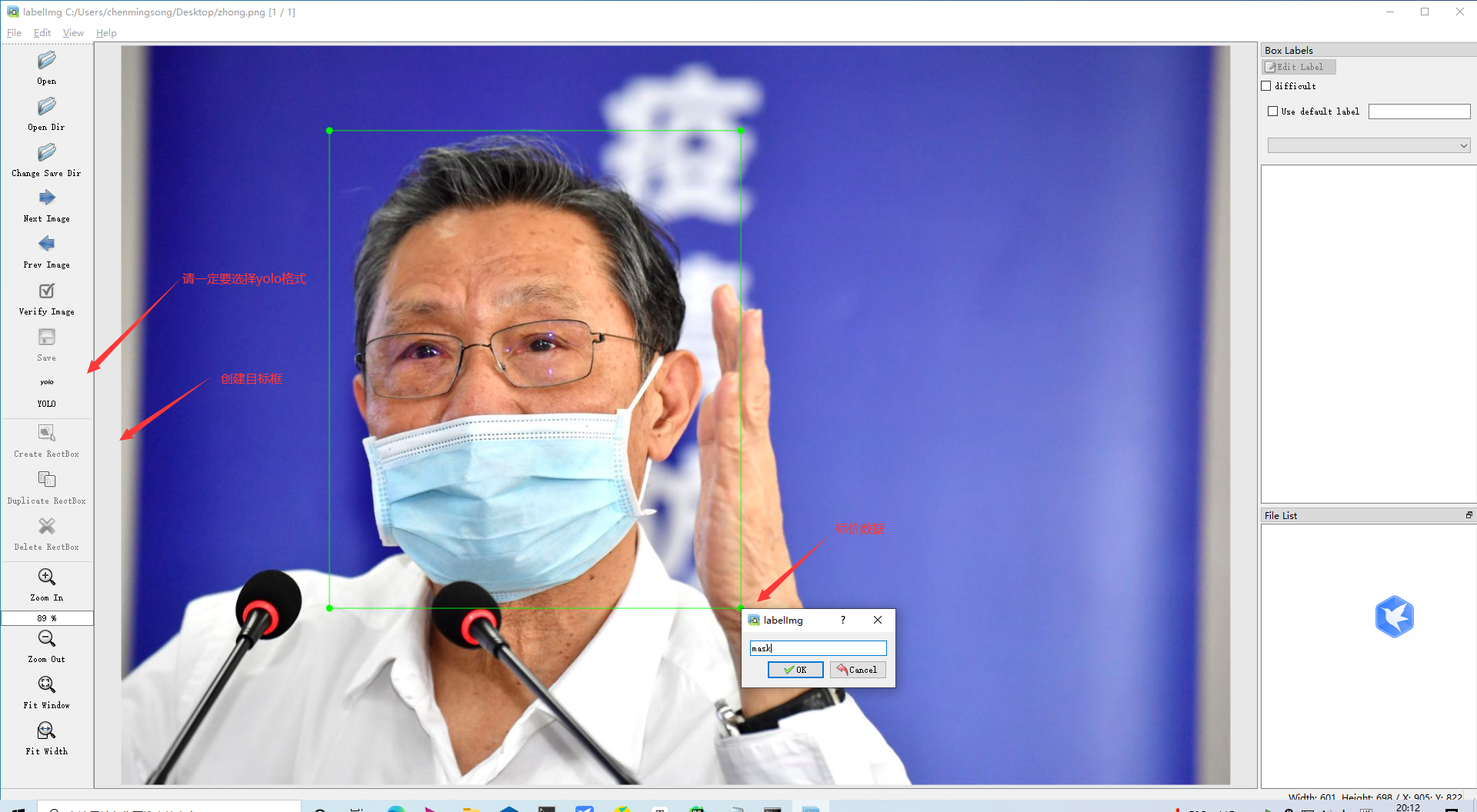
3.开始标注,画框,标记目标的label,crtl+s保存,然后d切换到下一张继续标注,不断重复重复
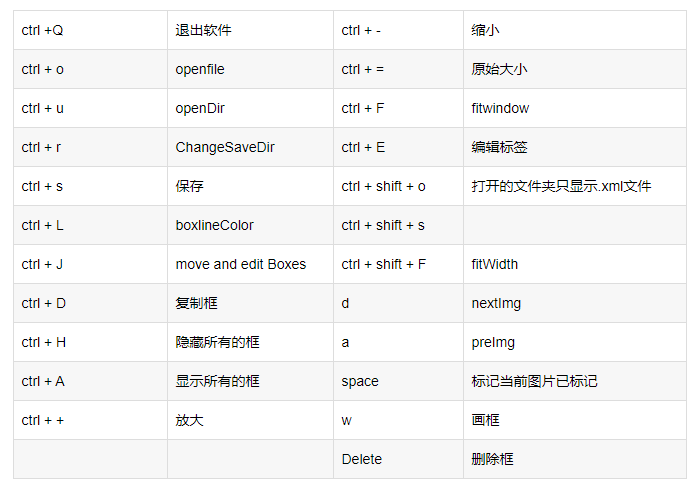
labelimg的快捷键如下,学会快捷键可以帮助你提高数据标注的效率。
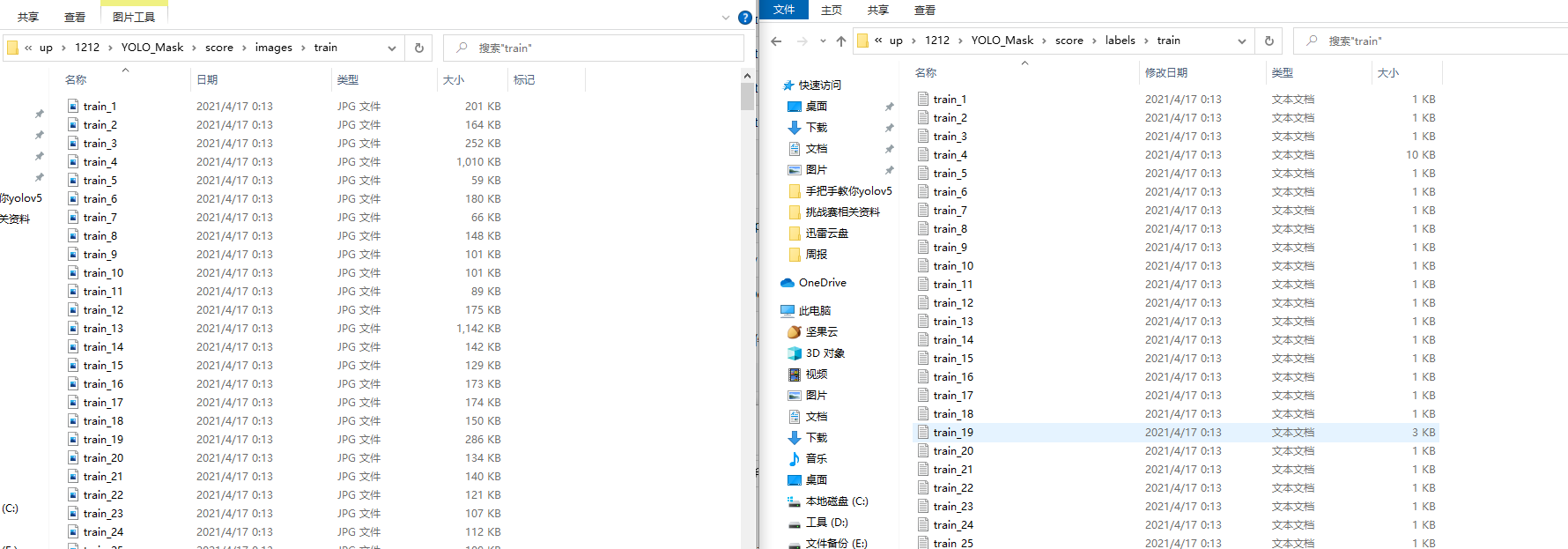
标注完成之后你会得到一系列的txt文件,这里的txt文件就是目标检测的标注文件,其中txt文件和图片文件的名称是一一对应的,如下图所示:
打开具体的标注文件,你将会看到下面的内容,txt文件中每一行表示一个目标,以空格进行区分,分别表示目标的类别id,归一化处理之后的中心点x坐标、y坐标、目标框的w和h。

4.修改数据集配置文件
标记完成的数据请按照下面的格式进行放置,方便程序进行索引。
YOLO_Mask└─ score ├─ images │ ├─ test # 下面放测试集图片 │ ├─ train # 下面放训练集图片 │ └─ val # 下面放验证集图片 └─ labels ├─ test # 下面放测试集标签 ├─ train # 下面放训练集标签 ├─ val # 下面放验证集标签这里的配置文件是为了方便我们后期训练使用,我们需要在data目录下创建一个mask_data.yaml的文件,如下图所示:
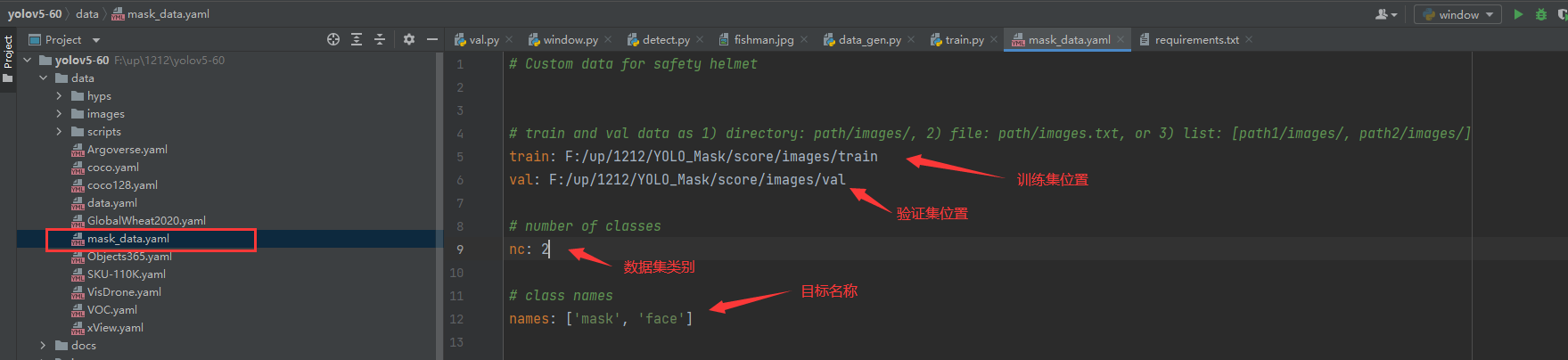
到这里,数据集处理部分基本完结撒花了,下面的内容将会是模型训练!
模型训练
模型的基本训练
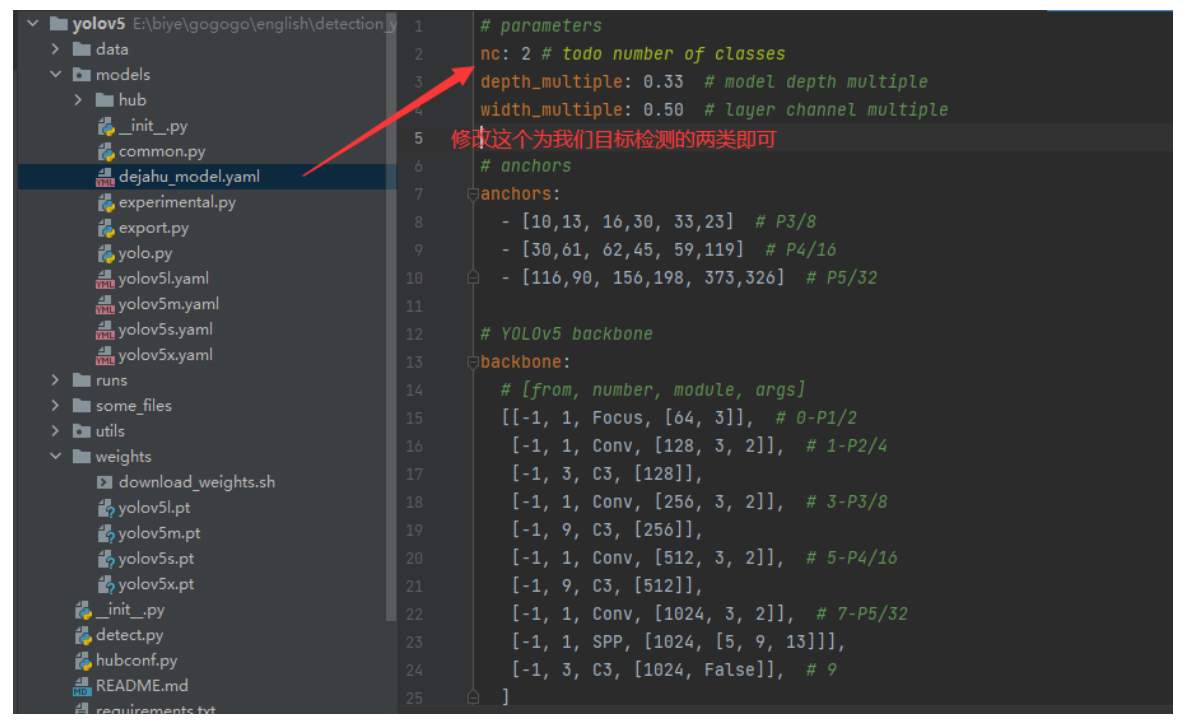
在models下建立一个mask_yolov5s.yaml的模型配置文件,内容如下:
模型训练之前,请确保代码目录下有以下文件
执行下列代码运行程序即可:
python train.py --data mask_data.yaml --cfg mask_yolov5s.yaml --weights pretrained/yolov5s.pt --epoch 100 --batch-size 4 --device cpu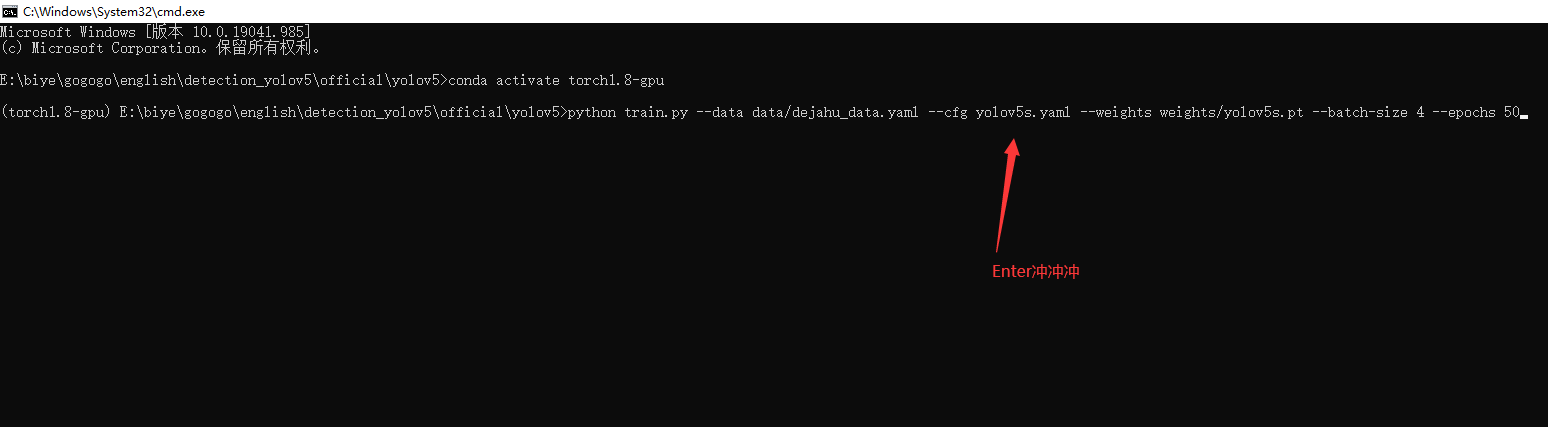
训练代码成功执行之后会在命令行中输出下列信息,接下来就是安心等待模型训练结束即可。

根据数据集的大小和设备的性能,经过漫长的等待之后模型就训练完了,输出如下:

在train/runs/exp3的目录下可以找到训练得到的模型和日志文件
当然还有一些骚操作,比如模型训练到一半可以从中断点继续训练,这些就交给大家下去自行探索喽。
模型评估
出了在博客一开头你就能看到的检测效果之外,还有一些学术上的评价指标用来表示我们模型的性能,其中目标检测最常用的评价指标是mAP,mAP是介于0到1之间的一个数字,这个数字越接近于1,就表示你的模型的性能更好。
一般我们会接触到两个指标,分别是召回率recall和精度precision,两个指标p和r都是简单地从一个角度来判断模型的好坏,均是介于0到1之间的数值,其中接近于1表示模型的性能越好,接近于0表示模型的性能越差,为了综合评价目标检测的性能,一般采用均值平均密度map来进一步评估模型的好坏。我们通过设定不同的置信度的阈值,可以得到在模型在不同的阈值下所计算出的p值和r值,一般情况下,p值和r值是负相关的,绘制出来可以得到如下图所示的曲线,其中曲线的面积我们称AP,目标检测模型中每种目标可计算出一个AP值,对所有的AP值求平均则可以得到模型的mAP值,以本文为例,我们可以计算佩戴安全帽和未佩戴安全帽的两个目标的AP值,我们对两组AP值求平均,可以得到整个模型的mAP值,该值越接近1表示模型的性能越好。
关于更加学术的定义大家可以在知乎或者csdn上自行查阅,以我们本次训练的模型为例,在模型结束之后你会找到三张图像,分别表示我们模型在验证集上的召回率、准确率和均值平均密度。
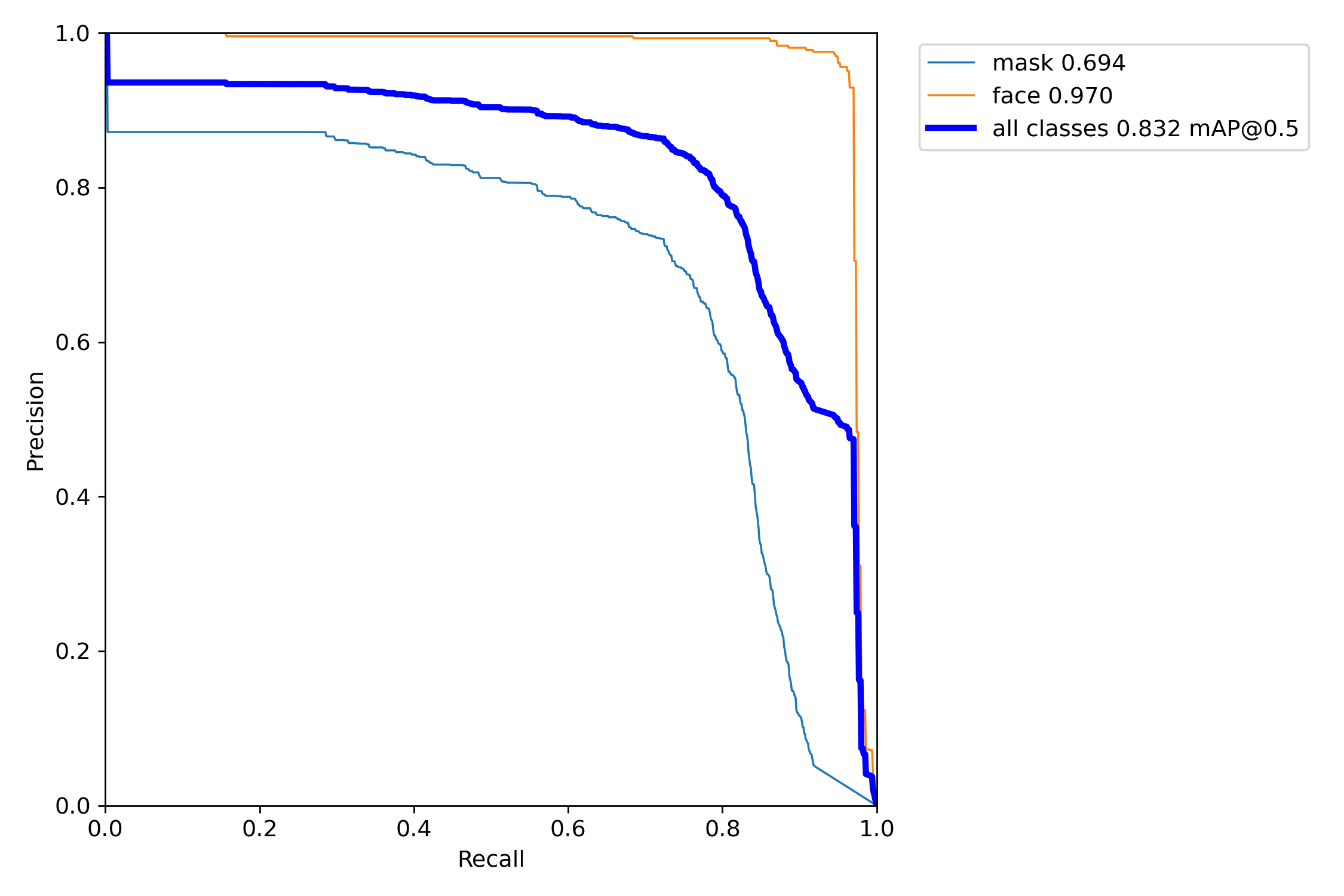
以PR-curve为例,你可以看到我们的模型在验证集上的均值平均密度为0.832。
如果你的目录下没有这样的曲线,可能是因为你的模型训练一半就停止了,没有执行验证的过程,你可以通过下面的命令来生成这些图片。
python val.py --data data/mask_data.yaml --weights runs/train/exp_yolov5s/weights/best.pt --img 640最后,这里是一张详细的评价指标的解释清单,可以说是最原始的定义了。

模型使用
模型的使用全部集成在了detect.py目录下,你按照下面的指令指你要检测的内容即可
# 检测摄像头 python detect.py --weights runs/train/exp_yolov5s/weights/best.pt --source 0 # webcam # 检测图片文件 python detect.py --weights runs/train/exp_yolov5s/weights/best.pt --source file.jpg # image # 检测视频文件 python detect.py --weights runs/train/exp_yolov5s/weights/best.pt --source file.mp4 # video # 检测一个目录下的文件 python detect.py --weights runs/train/exp_yolov5s/weights/best.pt path/ # directory # 检测网络视频 python detect.py --weights runs/train/exp_yolov5s/weights/best.pt 'https://youtu.be/NUsoVlDFqZg' # YouTube video # 检测流媒体 python detect.py --weights runs/train/exp_yolov5s/weights/best.pt 'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream 比如以我们的口罩模型为例,如果我们执行python detect.py --weights runs/train/exp_yolov5s/weights/best.pt --source data/images/fishman.jpg的命令便可以得到这样的一张检测结果。

构建可视化界面
可视化界面的部分在window.py文件中,是通过pyqt5完成的界面设计,在启动界面前,你需要将模型替换成你训练好的模型,替换的位置在window.py的第60行,修改成你的模型地址即可,如果你有GPU的话,可以将device设置为0,表示使用第0行GPU,这样可以加快模型的识别速度嗷。
!!!使用GPU的话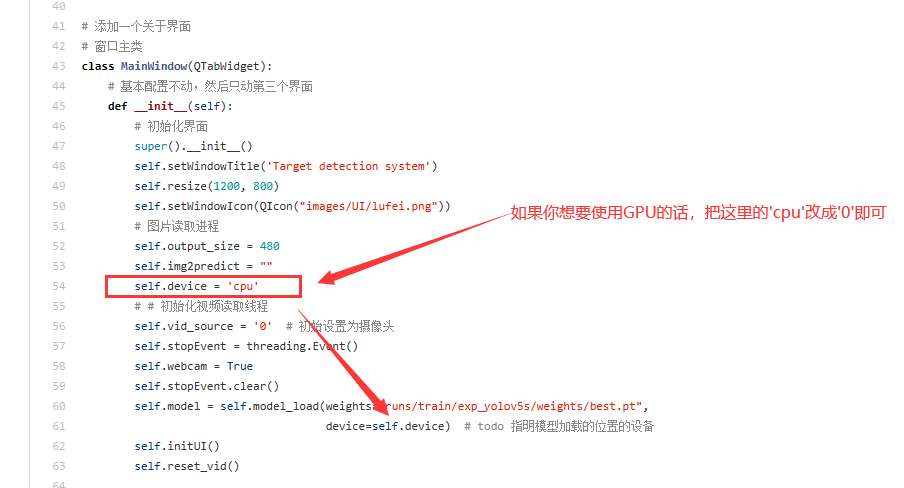
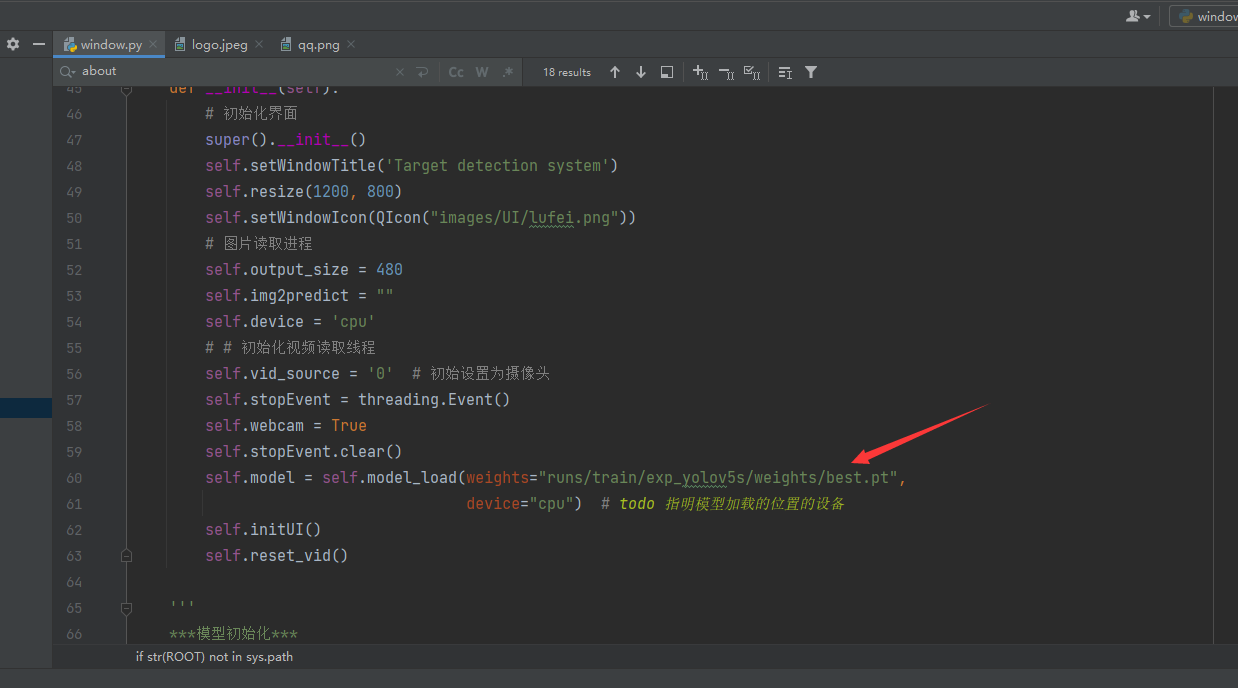
替换之后直接右键run即可启动图形化界面了,快去自己测试一下看看效果吧
找到我
你可以通过这些方式来寻找我。
B站:肆十二-
CSDN:肆十二
知乎:肆十二
微博:肆十二-
现在关注以后就是老朋友喽!