一、Linux系统状态概述
1、Linux系统状态分析工具
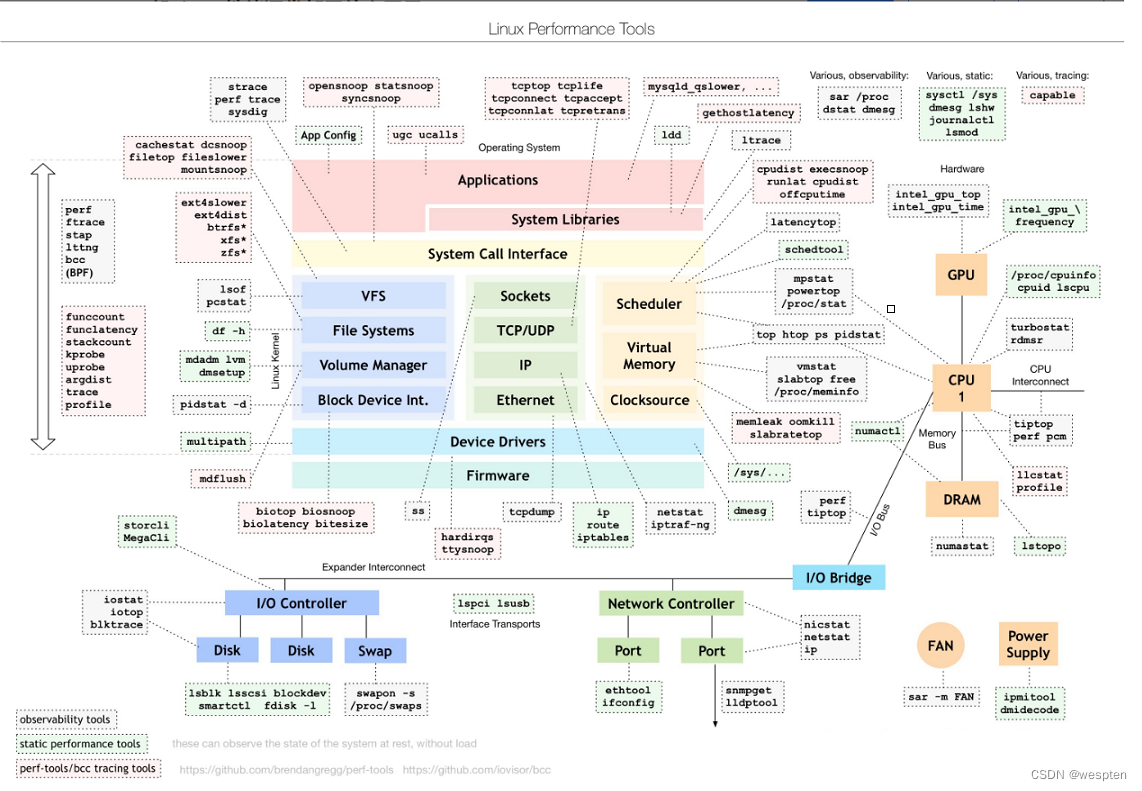
和上面图是同一个链接:
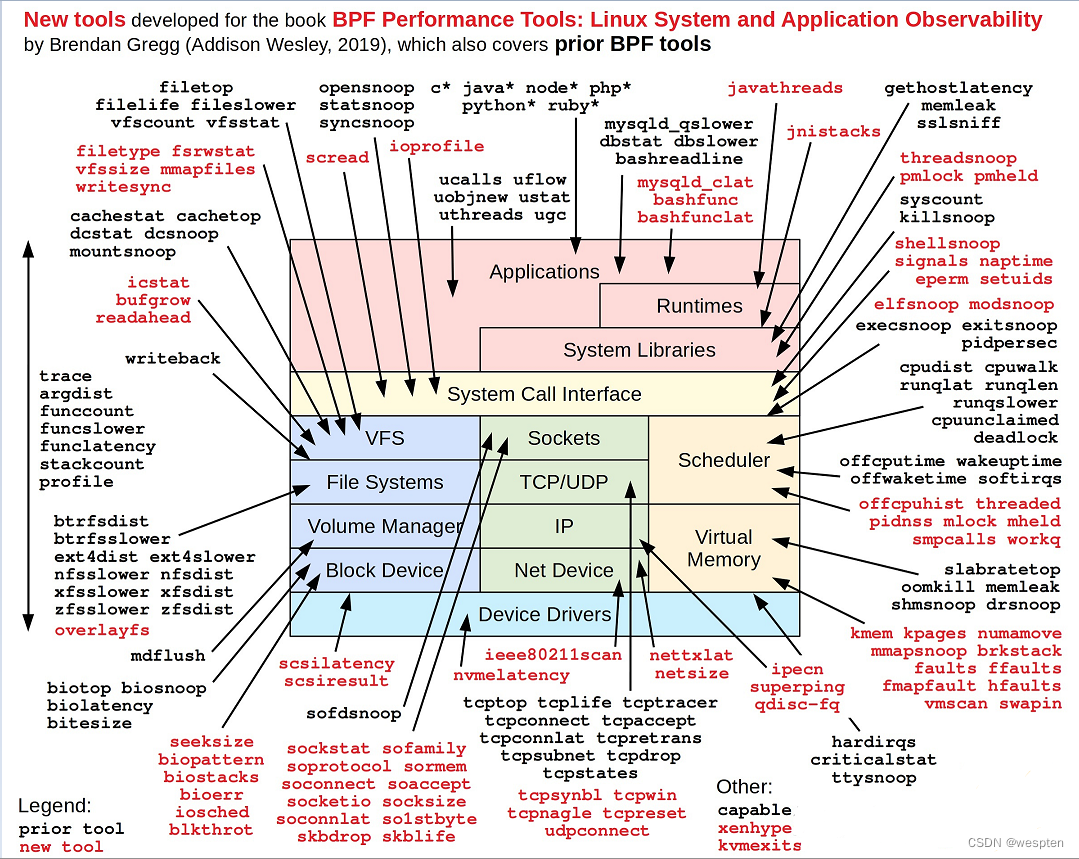

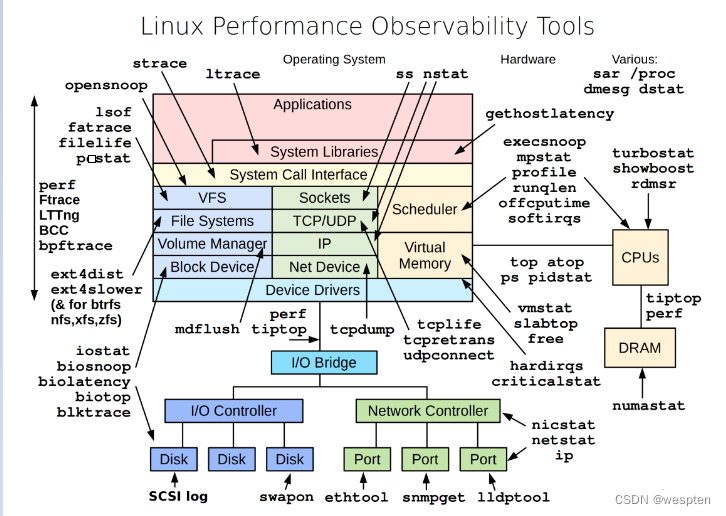
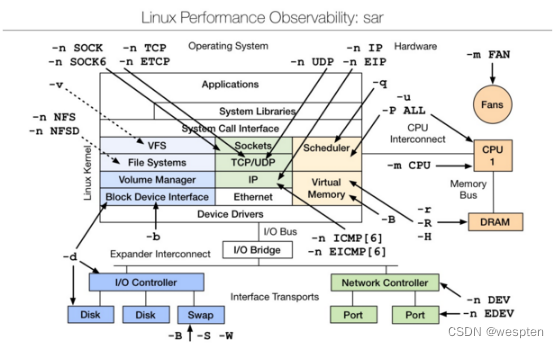
Linux 性能观测工具:
Basic Tool有如下:
uptime、top(htop)、mpstat、isstat、vmstat、free、ping、nicstat、dstat。
高级的命令如下:
sar、netstat、pidstat、strace、tcpdump、blktrace、iotop、slabtop、sysctl、/proc。
Linux 性能测评工具:

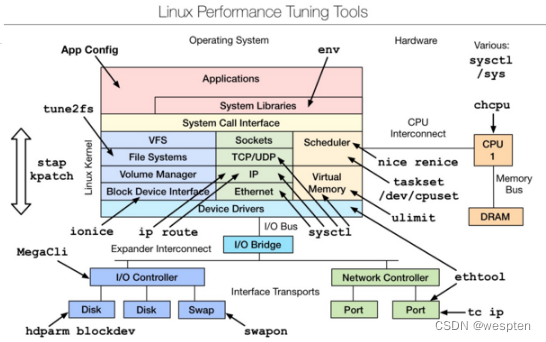
Linux 性能调优工具:
linux性能观测工具:
原文链接如下:
Linux Performance
系统运行状态分析工具大体如下:
静态代码检测工具或平台:cppcheck、PC-lint、Coverity、QAC C/C++、Clang-Tidy、Clang Static Analyzer、SonarQube+sonar-cxx(推荐)、Facebook的inferprofiling工具:gnu prof、Oprofile、google gperftools(推荐)、perf、intel VTune、AMD CodeAnalyst内存泄漏:valgrind、AddressSanitizer(推荐)、mtrace、dmalloc、ccmalloc、memwatch、debug_newCPU使用率:pidstat(推荐)、vmstat、mpstat、top、sar上下文切换:pidstat(推荐)、vmstat网络I/O:dstat、tcpdump(推荐)、sar磁盘I/O:iostat(推荐)、dstat、sar系统调用追踪:strace(推荐)网络吞吐量:iftop、nethogs、sar网络延迟:ping文件系统空间:df内存容量:free、vmstat(推荐)、sar进程内存分布:pmapCPU负载:uptime、top软中断硬中断:/proc/softirqs、/proc/interrupts确定哪些进程正在使用一组给定的文件:lsof很多的监控工具 Ubuntu/CentOS 都不自带,需要手动安装,在开始前我们最好先把所有可能用得上的监控工具都装上。(它们都很小,基本不占空间)
# ubuntu/debiansudo apt-get install \ sysstat iotop fio \ nethogs iftop# centos# 需要安装 epel 源,很多监控工具都在该源中!# 也可使用[阿里云 epel 源](https://developer.aliyun.com/mirror/epel)sudo yum install epel-releasesudo yum install \ sysstat iotop fio \ nethogs iftop2、大一统的监控工具
下面介绍两个非常方便的大一统监控工具,它们将一台服务器的所有监控数据汇总到一个地方,方便监控。
多机监控推荐用 prometheus+grafana,不过这一套比较吃性能,个人服务器没必要上。
NetData: 极简安装、超详细超漂亮的 Web UI。
这里只介绍单机监控。NetData 也支持中心化的多机监控,待进一步研究。netdata 也可以被用作 prometheus 的 exporter.
NetData 我要吹爆!它是 Github 上最受欢迎的系统监控工具,目前已经 44.5k star 了。
CPU 占用率低(0.1 核),界面超级漂亮超级详细,还对各种指标做了很详细的说明,安装也是一行命令搞定。相当适合萌新运维。
默认通过 19999 端口提供 Web UI 界面。
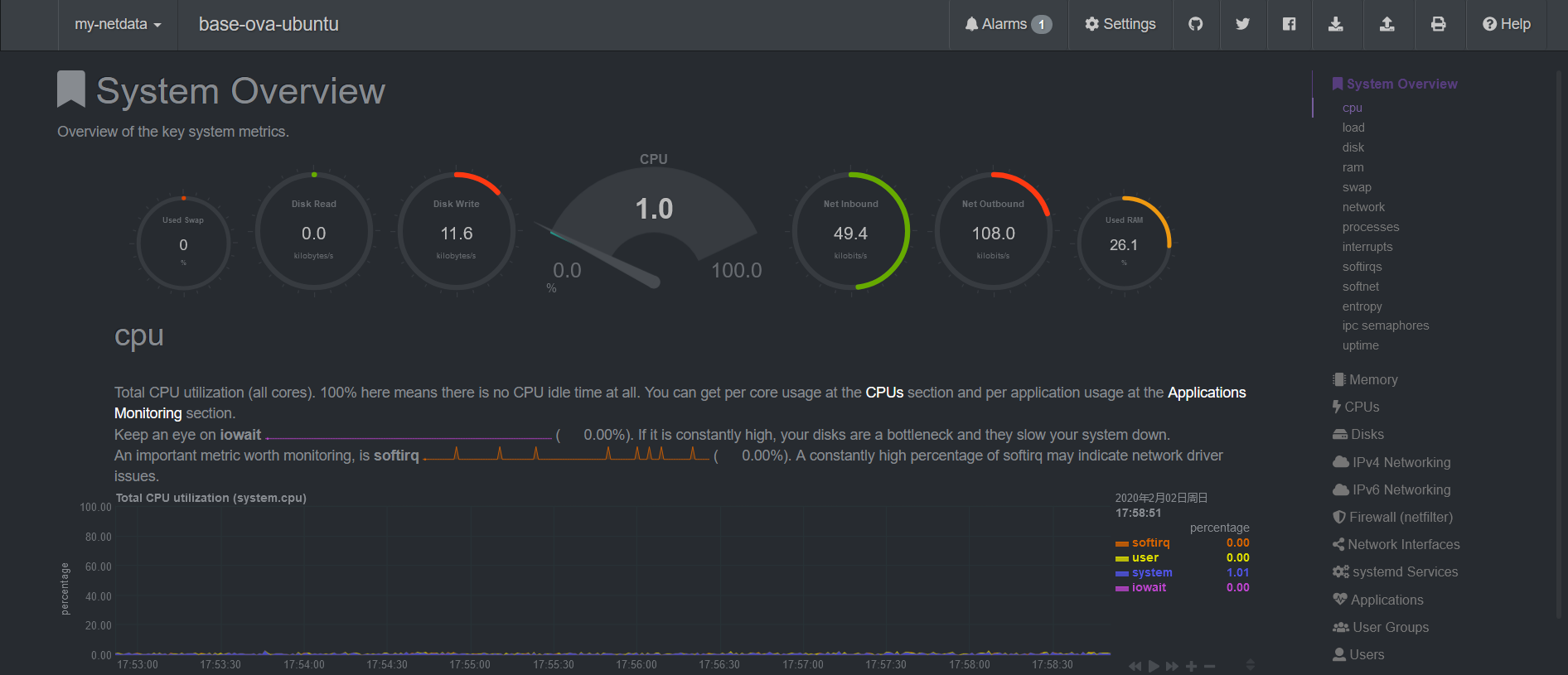
sudo apt-get install netdata# 然后修改 /etc/netdata/netdata.conf,绑定 ip 设为 0.0.0.0sudo systemctl restart netdata现在就可以访问http://<server-ip>:19999查看超级漂亮超级详细的监控界面了!
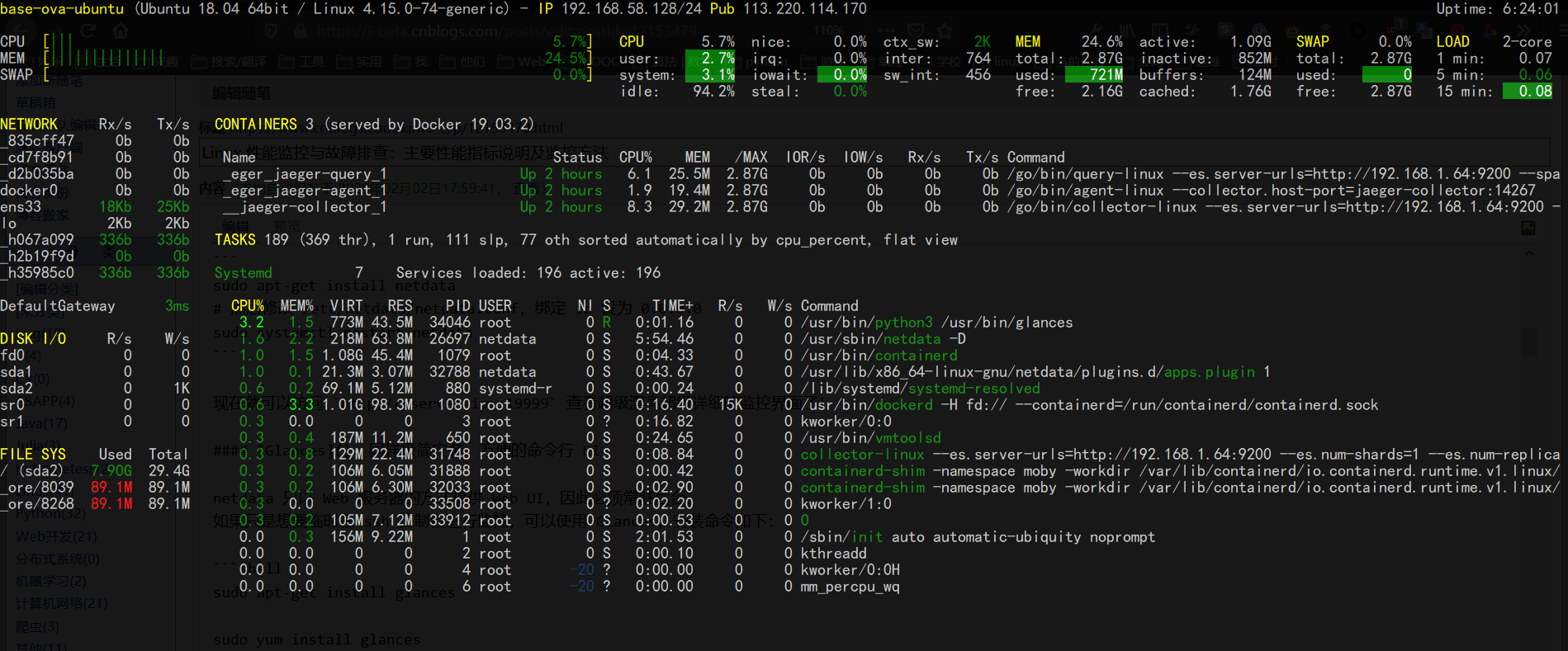
Glances: 同样极简安装、方便的命令行 UI
netdata 只以 Web 服务器的方式提供 Web UI,因此必须常驻后台。
如果只是想要临时在 ssh 控制台进行监控,可以使用 Glances,安装命令如下:
sudo apt-get install glancessudo yum install glances启动命令:glances,可提供 CPU、RAM、NetWork、Disk 和系统状态等非常全面的信息。(只是不够详细)
glances 同样提供中心化的多机监控,还有 Web 界面,但是和 netdata 相比就有些简陋了。
3、Linux主要性能指标说明
一台 Linux 服务器的四类指标如下:
CPU:使用率、平均负载(load average)RAM:used | free | buffer/cache | avaliableDisk:空闲容量大小、IO 状态Network:网速、延迟、丢包率等1)CPU指标
1. CPU 使用率
CPU 使用率即 CPU 运行在非空闲状态的时间占比,它反应了 CPU 的繁忙程度。使用 top 命令我们可以得到如下信息:
%Cpu(s): 0.0 us, 2.3 sy, 0.0 ni, 97.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 stus(user):表示 CPU 在用户态运行的时间百分比,通常用户态 CPU 高表示有应用程序比较繁忙。典型的用户态程序包括:数据库、Web 服务器等。sy(sys):表示 CPU 在内核态运行的时间百分比(不包括中断),通常内核态 CPU 越低越好,否则表示系统存在某些瓶颈。ni(nice):表示用 nice 修正进程优先级的用户态进程执行的 CPU 时间。nice 是一个进程优先级的修正值,如果进程通过它修改了优先级,则会单独统计 CPU 开销。id(idle):表示 CPU 处于空闲态的时间占比,此时,CPU 会执行一个特定的虚拟进程,名为 System Idle Process。wa(iowait):表示 CPU 在等待 I/O 操作完成的时间占比,通常该指标越低越好,否则表示 I/O 可能存在瓶颈,需要用 iostat 等命令做进一步分析。 iowait 只考虑 Synchronous File IO,It does NOT count time spent waiting for IPC objects such as sockets, pipes, ttys, select(), poll(), sleep(), pause() etc.hi(hardirq):表示 CPU 处理硬中断所花费的时间。硬中断是由外设硬件(如键盘控制器、硬件传感器等)发出的,需要有中断控制器参与,特点是快速执行。si(softirq):表示 CPU 处理软中断所花费的时间。软中断是由软件程序(如网络收发、定时调度等)发出的中断信号,特点是延迟执行。st(steal):表示 CPU 被其他虚拟机占用的时间,仅出现在多虚拟机场景。如果该指标过高,可以检查下宿主机或其他虚拟机是否异常。2. 平均负载(Load Average)
top命令的第一行输出如下:
top - 21:11:00 up 8 min, 0 users, load average: 0.52, 0.58, 0.59其中带有三个平均负载的值,它们的意思分别是** 1 分钟(load1)、5 分钟(load5)、15 分钟(load15)内系统的平均负载**。
平均负载(Load Average)是指单位时间内,系统处于 可运行状态(Running / Runnable) 和 不可中断态 的平均进程数,也就是 平均活跃进程数。
我们知道实际上一个 CPU 核只能跑一个进程,操作系统通过分时调度提供了多进程并行的假象。所以当平均负载(平均活跃进程数)不大于 CPU 逻辑核数时,系统可以正常运转。
如果平均负载超过了核数,那就说明有一部分进程正在活跃中,但是它却没有使用到 CPU(同一时间只能有 1 个进程在使用 CPU),这只可能有两个原因:
不论是何种状况,都说明系统的负载过高了,需要考虑降负或者升级硬件。
理想状态下,系统满负荷工作,此时平均负载 = CPU 逻辑核数(4核8线程 CPU 有8个逻辑核)。但是,在实际生产系统中,不建议系统满负荷运行。通用的经验法则是:平均负载 <= 0.7 * CPU 逻辑核数。
当平均负载持续大于 0.7 * CPU 逻辑核数,就需要开始调查原因,防止系统恶化;当平均负载持续大于 1.0 * CPU 逻辑核数,必须寻找解决办法,降低平均负载;当平均负载持续大于 5.0 * CPU 逻辑核数,表明系统已出现严重问题,长时间未响应,或者接近死机。除了关注平均负载值本身,我们也应关注平均负载的变化趋势,这包含两层含义。一是 load1、load5、load15 之间的变化趋势;二是历史的变化趋势。
当 load1、load5、load15 三个值非常接近,表明短期内系统负载比较平稳。此时,应该将其与昨天或上周同时段的历史负载进行比对,观察是否有显著上升。当 load1 远小于 load5 或 load15 时,表明系统最近 1 分钟的负载在降低,而过去 5 分钟或 15 分钟的平均负载却很高。当 load1 远大于 load5 或 load15 时,表明系统负载在急剧升高,如果不是临时性抖动,而是持续升高,特别是当 load5 都已超过0.7 * CPU 逻辑核数 时,应调查原因,降低系统负载。日常运维时,应该重点关注上述三个负载值之间的关系。
3. CPU 使用率与平均负载的关系
CPU 使用率是单位时间内 CPU 繁忙程度的统计。而平均负载不仅包括正在使用 CPU 的进程,还包括等待 CPU 或 I/O 的进程(前面讲过平均负载过高的两种情况)。
因此 CPU 使用率是包含在平均负载内的。这两个参数有两种组合需要注意:
两个参数值都很高:需要降低 CPU 使用率!CPU 使用率很低,可平均负载却超过了CPU逻辑核数:IO 有瓶颈了!需要排查 内存/磁盘/网络 的问题。 最常遇到的场景:内存用尽导致负载飙升。2)RAM内存指标
free # 单位 kbfree -m # 单位 mbfree -g # 单位 gb不考虑 Swap 时,建议以 Avaliable 值为可用内存的参考,因为 buffer/cache 中的内存不一定能完全释放出来!因为:
OS 本身需要占用一定 buffer/cache通过 tmpfs 等方式被使用的 cache 不能被回收使用通过 cgroups 设置的资源预留无法被别的进程回收利用。(容器资源预留)内存泄漏
内存泄漏有多种可能,通过监控能确定的只有内存是否在无上限地上升。很难直接通过监控排查。
3)Disk 磁盘指标
Disk 的性能指标主要有:
bandwidth 带宽,即每秒的 IO 吞吐量 连续读写频繁的应用(传输大量连续的数据)重点关注吞吐量,如读写视频的应用。IOPS,每秒的 IO 次数 随机读写频繁的应用需要关注 IOPS,如大量小文件(图片等)的读写。我们是 Web 服务器/数据库服务器,主要是随机读写,更关注 IOPS。
1. IO 基准测试
要监控磁盘的指标,首先得有个基准值做参考。
方法一:对整块磁盘进行测试
首先安装磁盘测试工具 fio(安装命令见文章开始),然后将如下内容保存为fio-rand-rw.fio(Web 服务器/数据库更关注随机读写):
; https://github.com/axboe/fio/blob/master/examples/fio-rand-RW.fio; fio-rand-RW.job for fiotest[global]name=fio-rand-RWfilename=fio-rand-RWrw=randrwrwmixread=60rwmixwrite=40bs=4Kdirect=0numjobs=4time_based=1runtime=900[file1]size=4Gioengine=libaioiodepth=16现在运行命令fio fio-rand-rw.fio以启动测试,可根据情况调整 .fio 文件中的参数,最后记录测试结果。
方法二:使用 dd 进行磁盘速度测试
使用 dd 测试的好处是系统自带,而且也不会破坏磁盘内容。
# 写入测试,读取 /dev/zero 这个空字符流,写入到 test.dbf 中(就是只测写入)# 块大小为 8k,也就是说偏向随机写dd if=/dev/zero of=test.dbf bs=8k count=50000 oflag=dsync # 每次写完一个 block 都同步,伤硬盘,不要没事就测# 读取 /dev/sda1 中的数据,写入到 /dev/null 这个黑洞中(只测读取)# 块大小还是 8k,即偏向随机读dd if=/dev/sda1 of=/dev/null bs=8k日常监控的数值远低于上面测得的基准值的情况下,基本就可以确定磁盘没有问题。
2. 使用率
通过df -h查看磁盘的使用情况。
磁盘不足会导致各种问题,比如:
ElasticSearch 自动将索引设为只读,禁止写入。k8s 报告 "Disk Pressure",导致节点无法调度。shell 的 tab 补全无法使用,会报错。3. IO 带宽(吞吐量)以及 IOPS
使用 iostat 查看磁盘 io 的状态(需要安装 sysstat):
# 每个磁盘一列,给出所有磁盘的当前状态iostat -d -k 3 # 以 kb 为单位,3 秒刷新一次iostat -d -m 3 # 以 mb 为单位,其他不变# 每个进程一列,可用于排查各进程的磁盘使用状态iotop将监控值与前述测试得到的基准值进行对比,低很多的话,基本就可以确认磁盘没问题。
4)Network网络指标
和 IO 指标类似,网络指标主要有:
socket 连接 连接数存在上限,该上限与 Linux 的文件描述符上限等参数有关。广为人知的 DDOS 攻击,通过 TCP 连接的 ACK 洪泛来使服务器瘫痪,针对的就是 TCP 协议的一个弱点。网络带宽(吞吐量)PPS(Packets Per Second) 数据包的收发速率网络延迟:一般通过 ping 来确定网络延迟和丢包率丢包率等等DNS 解析客户端与服务器之间的整条网络链路的任何一部分出现故障或配置不当,都可能导致上述的监控参数异常,应用无法正常运行。典型的如交换机、负载均衡器、Kubernetes 配置、Linux 系统参数(sysctl/ulimit)配置不当等。
1. 网络带宽监控
nethogs: 每个进程的带宽监控,并且进程是按带宽排序的 使用:sudo nethogs快速分析出占用大量带宽的进程tcpdump/tshark/mitmproxy: 命令行的网络抓包工具,mitmproxy 提供 Web UI 界面,而 tshark 是 wireshark 的命令行版本。 tcpdump -i eth0 -w dump.pcap: 使用 tcpdump 抓 eth0 的数据包,保存到 dump.pcap 中。之后可以通过 scp/ssh 等命令将该 pcap 文件拷贝下来,使用 wireshark 进行分析。2. Socket
Socket 的状态查看方法:
# 查看 socket 连接的统计信息# 主要统计处于各种状态的 tcp sockets 数量,以及其他 sockets 的统计信息ss --summaryss -s # 缩写# 查看哪个进程在监听 80 端口# --listening 列出所有正在被监听的 socket# --processes 显示出每个 socket 对应的 process 名称和 pid# --numeric 直接打印数字端口号(不解析协议名称)ss --listening --processes --numeric | grep 80ss -nlp | grep 80 # 缩写ss -lp | grep http # 解析协议名称,然后通过协议名搜索监听## 使用过时的 netstat### -t tcp### -u udpnetstat -tunlp | grep ":80"# 查看 sshd 当前使用的端口号ss --listening --processes | grep sshd## 使用过时的 netstatnetstat -tunlp | grep <pid> # pid 通过 ps 命令获得# 列出所有的 tcp sockets,包括所有的 socket 状态ss --tcp --all# 只列出正在 listen 的 socketss --listening# 列出所有 ESTABLISHED 的 socket(默认行为)ss# 统计 TCP 连接数ss | grep ESTAB | wc -l# 列出所有 ESTABLISHED 的 socket,并且给出连接的计时器ss --options# 查看所有来自 192.168.5 的 socketsss dst 192.168.1.5# 查看本机与服务器 192.168.1.100 建立的 socketsss src 192.168.1.5# 查看路由表routel3. 网络延迟、丢包率
通过 ping 命令进行测试,使用 pathping (仅 Windows)进行分段网络延迟与丢包率测试。
4. DNS故障排查
dig +trace baidu.com # 诊断 dns 的主要工具,非常强大host -a baidu.com # host 基本就是 dig 的弱化版,不过 host 有个有点就是能打印出它测试过的所有 FQDNnslookup baidu.com # 和 host 没啥大差别,多个交互式查询不过一般用不到whois baidu.com # 查询域名注册信息,内网诊断用不到TCP 连接数受 Linux 文件描述符上限控制,可以通过如下方法查看已用文件句柄的数量。
# 已用文件描述符数量lsof | wc -l# 文件描述符上限ulimit -n Docker 容器有自己的 namespace,直接通过宿主机的 ss 命令是查看不到容器的 socket 信息的。
比较直观的方法是直接通过 docker exec 在容器中通过 ss 命令。但是这要求容器中必须自带 ss 等程序,有的精简镜像可能不会自带它。
因此用的更多的方法,有两种:
1. 通过 nsenter 直接在目标容器的 namespace 中使用宿主机的命令。
这个适合单机 docker 的网络诊断,用法如下:
# 1. 查询到容器对应的 pidPID=$(docker inspect --format {{.State.Pid}} <container_name_or_ID>)# 2. nsenter 通过 pid 进入容器的 network namespace,执行 ss 查看 socket 信息nsenter --target $PID --net ss -snsenter 这个工具貌似是 docker 自带的,只要装了 docker,ubuntu/centos 都可以直接使用这个命令。
2. 使用专用的网络诊断镜像进行容器网络诊断(SideCar)
这种方式一般用于容器集群的诊断,K8s 社区提供了一个工具 kubectl-debug,以这种 SideCar 的方式进行容器诊断。
5)其他
如果服务器出现问题,但是上述四项参数都没有明显异常,就要考虑是不是系统配置或者应用配置的问题了。
1. 僵尸进程
僵尸进程过多,可以在上述指标都非常正常的情况下,使系统响应变得特别慢。
如果通过 top 命令观察到存在僵尸进程,可以使用如下命令将僵尸进程查找出来:
ps -ef| grep defunc2. sysctl/ulimit 参数设置
sysctl/ulimit 设置不当,可以在上述指标都非常正常的情况下,使系统响应变得特别慢。
案例:为了方便,我在系统的初始化脚本 configure_server.py 里一次性将 redis/elasticsearch/网络 等 sysctl/ulimit 参数全部配置好。结果 elasticsearch 需要设置的 vm.max_map_count 参数导致 redis 服务器在长时间运行后响应变慢。
4、Linux性能优化
高并发和响应快对应着性能优化的两个核心指标:吞吐和延时。

应用负载角度:直接影响了产品终端的用户体验
系统资源角度:资源使用率、饱和度等
性能问题的本质就是系统资源已经到达瓶颈,但请求的处理还不够快,无法支撑更多的请求。性能分析实际上就是找出应用或系统的瓶颈,设法去避免或缓解它们。
选择指标评估应用程序和系统性能
为应用程序和系统设置性能目标
进行性能基准测试
性能分析定位瓶颈
性能监控和告警
对于不同的性能问题要选取不同的性能分析工具。下面是常用的Linux Performance Tools以及对应分析的性能问题类型。

到底应该怎么理解"平均负载"
平均负载:单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数。它和我们传统意义上理解的CPU使用率并没有直接关系。
其中不可中断进程是正处于内核态关键流程中的进程(如常见的等待设备的I/O响应)。不可中断状态实际上是系统对进程和硬件设备的一种保护机制。
平均负载多少时合理
实际生产环境中将系统的平均负载监控起来,根据历史数据判断负载的变化趋势。当负载存在明显升高趋势时,及时进行分析和调查。当然也可以当设置阈值(如当平均负载高于CPU数量的70%时)
现实工作中我们会经常混淆平均负载和CPU使用率的概念,其实两者并不完全对等:
CPU密集型进程,大量CPU使用会导致平均负载升高,此时两者一致
I/O密集型进程,等待I/O也会导致平均负载升高,此时CPU使用率并不一定高
大量等待CPU的进程调度会导致平均负载升高,此时CPU使用率也会比较高
平均负载高时可能是CPU密集型进程导致,也可能是I/O繁忙导致。具体分析时可以结合mpstat/pidstat工具辅助分析负载来源。
CPU上下文切换
CPU上下文切换,就是把前一个任务的CPU上下文(CPU寄存器和PC)保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的位置,运行新任务。其中,保存下来的上下文会存储在系统内核中,待任务重新调度执行时再加载,保证原来的任务状态不受影响。
按照任务类型,CPU上下文切换分为:
进程上下文切换
线程上下文切换
中断上下文切换
进程上下文切换
Linux进程按照等级权限将进程的运行空间分为内核空间和用户空间。从用户态向内核态转变时需要通过系统调用来完成。
一次系统调用过程其实进行了两次CPU上下文切换:
CPU寄存器中用户态的指令位置先保存起来,CPU寄存器更新为内核态指令的位置,跳转到内核态运行内核任务;
系统调用结束后,CPU寄存器恢复原来保存的用户态数据,再切换到用户空间继续运行。
系统调用过程中并不会涉及虚拟内存等进程用户态资源,也不会切换进程。和传统意义上的进程上下文切换不同。因此系统调用通常称为特权模式切换。
进程是由内核管理和调度的,进程上下文切换只能发生在内核态。因此相比系统调用来说,在保存当前进程的内核状态和CPU寄存器之前,需要先把该进程的虚拟内存,栈保存下来。再加载新进程的内核态后,还要刷新进程的虚拟内存和用户栈。
进程只有在调度到CPU上运行时才需要切换上下文,有以下几种场景:CPU时间片轮流分配,系统资源不足导致进程挂起,进程通过sleep函数主动挂起,高优先级进程抢占时间片,硬件中断时CPU上的进程被挂起转而执行内核中的中断服务。
线程上下文切换
线程上下文切换分为两种:
前后线程同属于一个进程,切换时虚拟内存资源不变,只需要切换线程的私有数据,寄存器等;
前后线程属于不同进程,与进程上下文切换相同。
同进程的线程切换消耗资源较少,这也是多线程的优势。
中断上下文切换
中断上下文切换并不涉及到进程的用户态,因此中断上下文只包括内核态中断服务程序执行所必须的状态(CPU寄存器,内核堆栈,硬件中断参数等)。
中断处理优先级比进程高,所以中断上下文切换和进程上下文切换不会同时发生。
CPU上下文切换(下)
通过vmstat可以查看系统总体的上下文切换情况:
vmstat 5 #每隔5s输出一组数据procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 1 0 0 103388 145412 511056 0 0 18 60 1 1 2 1 96 0 0 0 0 0 103388 145412 511076 0 0 0 2 450 1176 1 1 99 0 0 0 0 0 103388 145412 511076 0 0 0 8 429 1135 1 1 98 0 0 0 0 0 103388 145412 511076 0 0 0 0 431 1132 1 1 98 0 0 0 0 0 103388 145412 511076 0 0 0 10 467 1195 1 1 98 0 0 1 0 0 103388 145412 511076 0 0 0 2 426 1139 1 0 99 0 0 4 0 0 95184 145412 511108 0 0 0 74 500 1228 4 1 94 0 0 0 0 0 103512 145416 511076 0 0 0 455 723 1573 12 3 83 2 0cs (context switch) 每秒上下文切换次数
in (interrupt) 每秒中断次数
r (runnning or runnable)就绪队列的长度,正在运行和等待CPU的进程数
b (Blocked) 处于不可中断睡眠状态的进程数
要查看每个进程的详细情况,需要使用pidstat来查看每个进程上下文切换情况:
pidstat -w 514时51分16秒 UID PID cswch/s nvcswch/s Command14时51分21秒 0 1 0.80 0.00 systemd14时51分21秒 0 6 1.40 0.00 ksoftirqd/014时51分21秒 0 9 32.67 0.00 rcu_sched14时51分21秒 0 11 0.40 0.00 watchdog/014时51分21秒 0 32 0.20 0.00 khugepaged14时51分21秒 0 271 0.20 0.00 jbd2/vda1-814时51分21秒 0 1332 0.20 0.00 argusagent14时51分21秒 0 5265 10.02 0.00 AliSecGuard14时51分21秒 0 7439 7.82 0.00 kworker/0:214时51分21秒 0 7906 0.20 0.00 pidstat14时51分21秒 0 8346 0.20 0.00 sshd14时51分21秒 0 20654 9.82 0.00 AliYunDun14时51分21秒 0 25766 0.20 0.00 kworker/u2:114时51分21秒 0 28603 1.00 0.00 python3cswch 每秒自愿上下文切换次数 (进程无法获取所需资源导致的上下文切换)
nvcswch 每秒非自愿上下文切换次数 (时间片轮流等系统强制调度)
vmstat 1 1 #首先获取空闲系统的上下文切换次数sysbench --threads=10 --max-time=300 threads run #模拟多线程切换问题vmstat 1 1 #新终端观察上下文切换情况此时发现cs数据明显升高,同时观察其他指标:r列: 远超系统CPU个数,说明存在大量CPU竞争us和sy列:sy列占比80%,说明CPU主要被内核占用in列: 中断次数明显上升,说明中断处理也是潜在问题说明运行/等待CPU的进程过多,导致大量的上下文切换,上下文切换导致系统的CPU占用率高:
pidstat -w -u 1 #查看到底哪个进程导致的问题从结果中看出是sysbench导致CPU使用率过高,但是pidstat输出的上下文次数加起来也并不多。分析sysbench模拟的是线程的切换,因此需要在pidstat后加-t参数查看线程指标。
另外对于中断次数过多,我们可以通过/proc/interrupts文件读取:
watch -d cat /proc/interrupts发现次数变化速度最快的是重调度中断(RES),该中断用来唤醒空闲状态的CPU来调度新的任务运行。分析还是因为过多任务的调度问题,和上下文切换分析一致。
某个应用的CPU使用率达到100%,怎么办?
Linux作为多任务操作系统,将CPU时间划分为很短的时间片,通过调度器轮流分配给各个任务使用。为了维护CPU时间,Linux通过事先定义的节拍率,触发时间中断,并使用全局变了jiffies记录开机以来的节拍数。时间中断发生一次该值+1.
CPU使用率,除了空闲时间以外的其他时间占总CPU时间的百分比。可以通过/proc/stat中的数据来计算出CPU使用率。因为/proc/stat时开机以来的节拍数累加值,计算出来的是开机以来的平均CPU使用率,一般意义不大。可以间隔取一段时间的两次值作差来计算该段时间内的平均CPU使用率。性能分析工具给出的都是间隔一段时间的平均CPU使用率,要注意间隔时间的设置。
CPU使用率可以通过top 或 ps来查看。分析进程的CPU问题可以通过perf,它以性能事件采样为基础,不仅可以分析系统的各种事件和内核性能,还可以用来分析指定应用程序的性能问题。
perf top / perf record / perf report (-g 开启调用关系的采样)
sudo docker run --name nginx -p 10000:80 -itd feisky/nginxsudo docker run --name phpfpm -itd --network container:nginx feisky/php-fpmab -c 10 -n 100 http://XXX.XXX.XXX.XXX:10000/ #测试Nginx服务性能发现此时每秒可承受请求给长少,此时将测试的请求数从100增加到10000。在另外一个终端运行top查看每个CPU的使用率。发现系统中几个php-fpm进程导致CPU使用率骤升。
接着用perf来分析具体是php-fpm中哪个函数导致该问题。
perf top -g -p XXXX #对某一个php-fpm进程进行分析发现其中sqrt和add_function占用CPU过多, 此时查看源码找到原来是sqrt中在发布前没有删除测试代码段,存在一个百万次的循环导致。将该无用代码删除后发现nginx负载能力明显提升
系统的CPU使用率很高,为什么找不到高CPU的应用?
sudo docker run --name nginx -p 10000:80 -itd feisky/nginx:spsudo docker run --name phpfpm -itd --network container:nginx feisky/php-fpm:spab -c 100 -n 1000 http://XXX.XXX.XXX.XXX:10000/ #并发100个请求测试实验结果中每秒请求数依旧不高,我们将并发请求数降为5后,nginx负载能力依旧很低。
此时用top和pidstat发现系统CPU使用率过高,但是并没有发现CPU使用率高的进程。
出现这种情况一般时我们分析时遗漏的什么信息,重新运行top命令并观察一会。发现就绪队列中处于Running状态的进行过多,超过了我们的并发请求次数5. 再仔细查看进程运行数据,发现nginx和php-fpm都处于sleep状态,真正处于运行的却是几个stress进程。
下一步就利用pidstat分析这几个stress进程,发现没有任何输出。用ps aux交叉验证发现依旧不存在该进程。说明不是工具的问题。再top查看发现stress进程的进程号变化了,此时有可能时以下两种原因导致:
进程不停的崩溃重启(如段错误/配置错误等),此时进程退出后可能又被监控系统重启;
短时进程导致,即其他应用内部通过exec调用的外面命令,这些命令一般只运行很短时间就结束,很难用top这种间隔较长的工具来发现
可以通过pstree来查找 stress的父进程,找出调用关系。
pstree | grep stress发现是php-fpm调用的该子进程,此时去查看源码可以看出每个请求都会调用一个stress命令来模拟I/O压力。之前top显示的结果是CPU使用率升高,是否真的是由该stress命令导致的,还需要继续分析。代码中给每个请求加了verbose=1的参数后可以查看stress命令的输出,在中断测试该命令结果显示stress命令运行时存在因权限问题导致的文件创建失败的bug。
此时依旧只是猜测,下一步继续通过perf工具来分析。性能报告显示确实时stress占用了大量的CPU,通过修复权限问题来优化解决即可。
系统中出现大量不可中断进程和僵尸进程怎么办?
进程状态
R Running/Runnable,表示进程在CPU的就绪队列中,正在运行或者等待运行;
D Disk Sleep,不可中断状态睡眠,一般表示进程正在跟硬件交互,并且交互过程中不允许被其他进程中断;
Z Zombie,僵尸进程,表示进程实际上已经结束,但是父进程还没有回收它的资源;
S Interruptible Sleep,可中断睡眠状态,表示进程因为等待某个事件而被系统挂起,当等待事件发生则会被唤醒并进入R状态;
I Idle,空闲状态,用在不可中断睡眠的内核线程上。该状态不会导致平均负载升高;
T Stop/Traced,表示进程处于暂停或跟踪状态(SIGSTOP/SIGCONT, GDB调试);
X Dead,进程已经消亡,不会在top/ps中看到。
对于不可中断状态,一般都是在很短时间内结束,可忽略。但是如果系统或硬件发生故障,进程可能会保持不可中断状态很久,甚至系统中出现大量不可中断状态,此时需注意是否出现了I/O性能问题。
僵尸进程一般多进程应用容易遇到,父进程来不及处理子进程状态时子进程就提前退出,此时子进程就变成了僵尸进程。大量的僵尸进程会用尽PID进程号,导致新进程无法建立。
磁盘O_DIRECT问题:
sudo docker run --privileged --name=app -itd feisky/app:iowaitps aux | grep '/app'可以看到此时有多个app进程运行,状态分别时Ss+和D+。其中后面s表示进程是一个会话的领导进程,+号表示前台进程组。
其中进程组表示一组相互关联的进程,子进程是父进程所在组的组员。会话指共享同一个控制终端的一个或多个进程组。
用top查看系统资源发现:1)平均负载在逐渐增加,且1分钟内平均负载达到了CPU个数,说明系统可能已经有了性能瓶颈;2)僵尸进程比较多且在不停增加;3)us和sys CPU使用率都不高,iowait却比较高;4)每个进程CPU使用率也不高,但有两个进程处于D状态,可能在等待IO。
分析目前数据可知:iowait过高导致系统平均负载升高,僵尸进程不断增长说明有程序没能正确清理子进程资源。
用dstat来分析,因为它可以同时查看CPU和I/O两种资源的使用情况,便于对比分析。
dstat 1 10 #间隔1秒输出10组数据可以看到当wai(iowait)升高时磁盘请求read都会很大,说明iowait的升高和磁盘的读请求有关。接下来分析到底时哪个进程在读磁盘。
之前top查看的处于D状态的进程号,用pidstat -d -p XXX 展示进程的I/O统计数据。发现处于D状态的进程都没有任何读写操作。在用pidstat -d 查看所有进程的I/O统计数据,看到app进程在进行磁盘读操作,每秒读取32MB的数据。进程访问磁盘必须使用系统调用处于内核态,接下来重点就是找到app进程的系统调用。
sudo strace -p XXX #对app进程调用进行跟踪报错没有权限,因为已经时root权限了。所以遇到这种情况,首先要检查进程状态是否正常。ps命令查找该进程已经处于Z状态,即僵尸进程。
这种情况下top pidstat之类的工具无法给出更多的信息,此时像第5篇一样,用perf record -d和perf report进行分析,查看app进程调用栈。
看到app确实在通过系统调用sys_read()读取数据,并且从new_sync_read和blkdev_direct_IO看出进程时进行直接读操作,请求直接从磁盘读,没有通过缓存导致iowait升高。
通过层层分析后,root cause是app内部进行了磁盘的直接I/O。然后定位到具体代码位置进行优化即可。
僵尸进程
上述优化后iowait显著下降,但是僵尸进程数量仍旧在增加。首先要定位僵尸进程的父进程,通过pstree -aps XXX,打印出该僵尸进程的调用树,发现父进程就是app进程。
查看app代码,看看子进程结束的处理是否正确(是否调用wait()/waitpid(),有没有注册SIGCHILD信号的处理函数等)。
碰到iowait升高时,先用dstat pidstat等工具确认是否存在磁盘I/O问题,再找是哪些进程导致I/O,不能用strace直接分析进程调用时可以通过perf工具分析。
对于僵尸问题,用pstree找到父进程,然后看源码检查子进程结束的处理逻辑即可。
CPU性能指标
CPU使用率
用户CPU使用率, 包括用户态(user)和低优先级用户态(nice). 该指标过高说明应用程序比较繁忙.
系统CPU使用率, CPU在内核态运行的时间百分比(不含中断). 该指标高说明内核比较繁忙.
等待I/O的CPU使用率, iowait, 该指标高说明系统与硬件设备I/O交互时间比较长.
软/硬中断CPU使用率, 该指标高说明系统中发生大量中断.
steal CPU / guest CPU, 表示虚拟机占用的CPU百分比.
平均负载
理想情况下平均负载等于逻辑CPU个数,表示每个CPU都被充分利用. 若大于则说明系统负载较重.
进程上下文切换
包括无法获取资源的自愿切换和系统强制调度时的非自愿切换. 上下文切换本身是保证Linux正常运行的一项核心功能. 过多的切换则会将原本运行进程的CPU时间消耗在寄存器,内核占及虚拟内存等数据保存和恢复上
CPU缓存命中率
CPU缓存的复用情况,命中率越高性能越好. 其中L1/L2常用在单核,L3则用在多核中。
性能工具
平均负载案例
先用uptime查看系统平均负载
判断负载在升高后再用mpstat和pidstat分别查看每个CPU和每个进程CPU使用情况.找出导致平均负载较高的进程.
上下文切换案例
先用vmstat查看系统上下文切换和中断次数
再用pidstat观察进程的自愿和非自愿上下文切换情况
最后通过pidstat观察线程的上下文切换情况
进程CPU使用率高案例
先用top查看系统和进程的CPU使用情况,定位到进程
再用perf top观察进程调用链,定位到具体函数
系统CPU使用率高案例
先用top查看系统和进程的CPU使用情况,top/pidstat都无法找到CPU使用率高的进程
重新审视top输出
从CPU使用率不高,但是处于Running状态的进程入手
perf record/report发现短时进程导致 (execsnoop工具)
不可中断和僵尸进程案例
先用top观察iowait升高,发现大量不可中断和僵尸进程
strace无法跟踪进程系统调用
perf分析调用链发现根源来自磁盘直接I/O
软中断案例
top观察系统软中断CPU使用率高
查看/proc/softirqs找到变化速率较快的几种软中断
sar命令发现是网络小包问题
tcpdump找出网络帧的类型和来源, 确定SYN FLOOD攻击导致
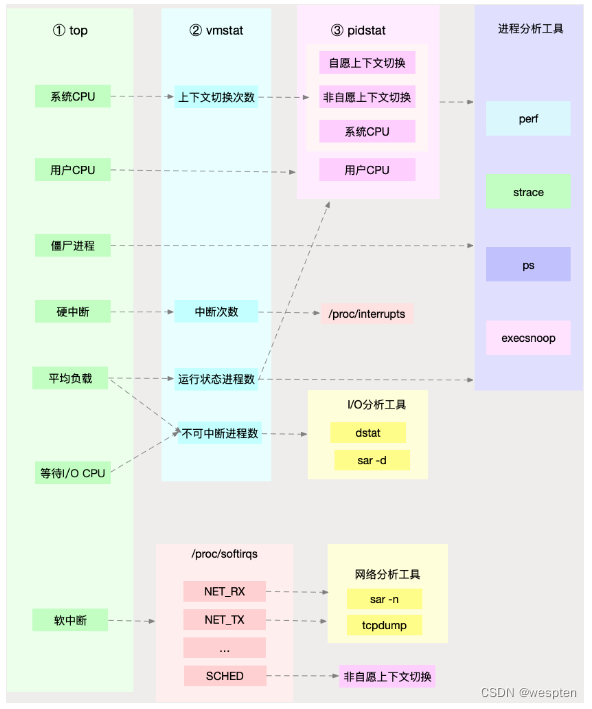
根据不同的性能指标来找合适的工具:
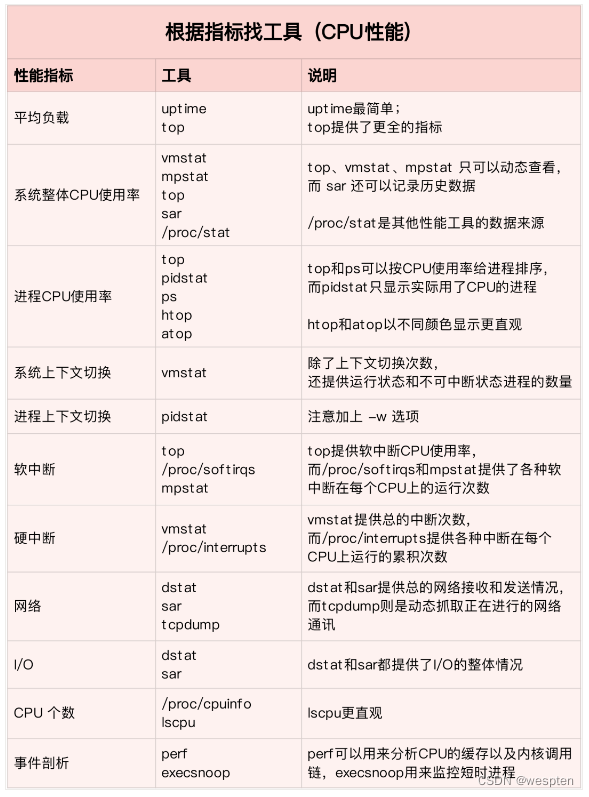
在生产环境中往往开发者没有权限安装新的工具包,只能最大化利用好系统中已经安装好的工具. 因此要了解一些主流工具能够提供哪些指标分析:

先运行几个支持指标较多的工具, 如top/vmstat/pidstat,根据它们的输出可以得出是哪种类型的性能问题. 定位到进程后再用strace/perf分析调用情况进一步分析. 如果是软中断导致用/proc/softirqs。
CPU优化
应用程序优化
编译器优化: 编译阶段开启优化选项, 如gcc -O2
算法优化
异步处理: 避免程序因为等待某个资源而一直阻塞,提升程序的并发处理能力. (将轮询替换为事件通知)
多线程代替多进程: 减少上下文切换成本
善用缓存: 加快程序处理速度
系统优化
CPU绑定: 将进程绑定要1个/多个CPU上,提高CPU缓存命中率,减少CPU调度带来的上下文切换
CPU独占: CPU亲和性机制来分配进程
优先级调整:使用nice适当降低非核心应用的优先级
为进程设置资源显示: cgroups设置使用上限,防止由某个应用自身问题耗尽系统资源
NUMA优化: CPU尽可能访问本地内存
中断负载均衡: irpbalance,将中断处理过程自动负载均衡到各个CPU上
TPS、QPS、系统吞吐量的区别和理解
QPS(TPS)
并发数
响应时间
QPS(TPS)=并发数/平均相应时间
用户请求服务器
服务器内部处理
服务器返回给客户
QPS类似TPS,但是对于一个页面的访问形成一个TPS,但是一次页面请求可能包含多次对服务器的请求,可能计入多次QPS
QPS (Queries Per Second)每秒查询率,一台服务器每秒能够响应的查询次数.
TPS (Transactions Per Second)每秒事务数,软件测试的结果.
系统吞吐量, 包括几个重要参数:
内存
Linux内存是怎么工作的
内存映射
大多数计算机用的主存都是动态随机访问内存(DRAM),只有内核才可以直接访问物理内存。Linux内核给每个进程提供了一个独立的虚拟地址空间,并且这个地址空间是连续的。这样进程就可以很方便的访问内存(虚拟内存)。
虚拟地址空间的内部分为内核空间和用户空间两部分,不同字长的处理器地址空间的范围不同。32位系统内核空间占用1G,用户空间占3G。64位系统内核空间和用户空间都是128T,分别占内存空间的最高和最低处,中间部分为未定义。
并不是所有的虚拟内存都会分配物理内存,只有实际使用的才会。分配后的物理内存通过内存映射管理。为了完成内存映射,内核为每个进程都维护了一个页表,记录虚拟地址和物理地址的映射关系。页表实际存储在CPU的内存管理单元MMU中,处理器可以直接通过硬件找出要访问的内存。
当进程访问的虚拟地址在页表中查不到时,系统会产生一个缺页异常,进入内核空间分配物理内存,更新进程页表,再返回用户空间恢复进程的运行。
MMU以页为单位管理内存,页大小4KB。为了解决页表项过多问题Linux提供了多级页表和HugePage的机制。
虚拟内存空间分布
用户空间内存从低到高是五种不同的内存段:
只读段 代码和常量等
数据段 全局变量等
堆 动态分配的内存,从低地址开始向上增长
文件映射 动态库、共享内存等,从高地址开始向下增长
栈 包括局部变量和函数调用的上下文等,栈的大小是固定的。一般8MB
内存分配与回收
分配
malloc对应到系统调用上有两种实现方式:
brk() 针对小块内存(<128K),通过移动堆顶位置来分配。内存释放后不立即归还内存,而是被缓存起来。
**mmap()**针对大块内存(>128K),直接用内存映射来分配,即在文件映射段找一块空闲内存分配。
前者的缓存可以减少缺页异常的发生,提高内存访问效率。但是由于内存没有归还系统,在内存工作繁忙时,频繁的内存分配/释放会造成内存碎片。
后者在释放时直接归还系统,所以每次mmap都会发生缺页异常。在内存工作繁忙时,频繁内存分配会导致大量缺页异常,使内核管理负担增加。
上述两种调用并没有真正分配内存,这些内存只有在首次访问时,才通过缺页异常进入内核中,由内核来分配
回收
内存紧张时,系统通过以下方式来回收内存:
回收缓存:LRU算法回收最近最少使用的内存页面;
回收不常访问内存:把不常用的内存通过交换分区写入磁盘
杀死进程:OOM内核保护机制 (进程消耗内存越大oom_score越大,占用CPU越多oom_score越小,可以通过/proc手动调整oom_adj)
echo -16 > /proc/$(pidof XXX)/oom_adj如何查看内存使用情况?
free来查看整个系统的内存使用情况
top/ps来查看某个进程的内存使用情况
VIRT 进程的虚拟内存大小
RES 常驻内存的大小,即进程实际使用的物理内存大小,不包括swap和共享内存
SHR 共享内存大小,与其他进程共享的内存,加载的动态链接库以及程序代码段
%MEM 进程使用物理内存占系统总内存的百分比
怎样理解内存中的Buffer和Cache?
buffer是对磁盘数据的缓存,cache是对文件数据的缓存,它们既会用在读请求也会用在写请求中。
如何利用系统缓存优化程序的运行效率
缓存命中率
缓存命中率是指直接通过缓存获取数据的请求次数,占所有请求次数的百分比。命中率越高说明缓存带来的收益越高,应用程序的性能也就越好。
安装bcc包后可以通过cachestat和cachetop来监测缓存的读写命中情况。
安装pcstat后可以查看文件在内存中的缓存大小以及缓存比例。
#首先安装Goexport GOPATH=~/goexport PATH=~/go/bin:$PATHgo get golang.org/x/sys/unixgo ge github.com/tobert/pcstat/pcstatdd缓存加速:
dd if=/dev/sda1 of=file bs=1M count=512 #生产一个512MB的临时文件echo 3 > /proc/sys/vm/drop_caches #清理缓存pcstat file #确定刚才生成文件不在系统缓存中,此时cached和percent都是0cachetop 5dd if=file of=/dev/null bs=1M #测试文件读取速度#此时文件读取性能为30+MB/s,查看cachetop结果发现并不是所有的读都落在磁盘上,读缓存命中率只有50%。dd if=file of=/dev/null bs=1M #重复上述读文件测试#此时文件读取性能为4+GB/s,读缓存命中率为100%pcstat file #查看文件file的缓存情况,100%全部缓存O_DIRECT选项绕过系统缓存:
cachetop 5sudo docker run --privileged --name=app -itd feisky/app:io-directsudo docker logs app #确认案例启动成功#实验结果表明每读32MB数据都要花0.9s,且cachetop输出中显示1024次缓存全部命中但是凭感觉可知如果缓存命中读速度不应如此慢,读次数时1024,页大小为4K,五秒的时间内读取了1024*4KB数据,即每秒0.8MB,和结果中32MB相差较大。说明该案例没有充分利用缓存,怀疑系统调用设置了直接I/O标志绕过系统缓存。因此接下来观察系统调用。
strace -p $(pgrep app)#strace 结果可以看到openat打开磁盘分区/dev/sdb1,传入参数为O_RDONLY|O_DIRECT这就解释了为什么读32MB数据那么慢,直接从磁盘读写肯定远远慢于缓存。找出问题后我们再看案例的源代码发现flags中指定了直接IO标志。删除该选项后重跑,验证性能变化。
内存泄漏,如何定位和处理?
对应用程序来说,动态内存的分配和回收是核心又复杂的一个逻辑功能模块。管理内存的过程中会发生各种各样的“事故”:
没正确回收分配的内存,导致了泄漏
访问的是已分配内存边界外的地址,导致程序异常退出
内存的分配与回收
虚拟内存分布从低到高分别是只读段,数据段,堆,内存映射段,栈五部分。其中会导致内存泄漏的是:
堆:由应用程序自己来分配和管理,除非程序退出这些堆内存不会被系统自动释放。
内存映射段:包括动态链接库和共享内存,其中共享内存由程序自动分配和管理
内存泄漏的危害比较大,这些忘记释放的内存,不仅应用程序自己不能访问,系统也不能把它们再次分配给其他应用。 内存泄漏不断累积甚至会耗尽系统内存.
如何检测内存泄漏
预先安装systat,docker,bcc:
sudo docker run --name=app -itd feisky/app:mem-leaksudo docker logs appvmstat 3可以看到free在不断下降,buffer和cache基本保持不变。说明系统的内存一致在升高。但并不能说明存在内存泄漏。此时可以通过memleak工具来跟踪系统或进程的内存分配/释放请求:
/usr/share/bcc/tools/memleak -a -p $(pidof app)从memleak输出可以看到,应用在不停地分配内存,并且这些分配的地址并没有被回收。通过调用栈看到是fibonacci函数分配的内存没有释放。定位到源码后查看源码来修复增加内存释放函数即可。
为什么系统的Swap变高
系统内存资源紧张时通过内存回收和OOM杀死进程来解决。其中可回收内存包括:
缓存/缓冲区,属于可回收资源,在文件管理中通常叫做文件页
在应用程序中通过fsync将脏页同步到磁盘
交给系统,内核线程pdflush负责这些脏页的刷新
被应用程序修改过暂时没写入磁盘的数据(脏页),要先写入磁盘然后才能内存释放
内存映射获取的文件映射页,也可以被释放掉,下次访问时从文件重新读取
对于程序自动分配的堆内存,也就是我们在内存管理中的匿名页,虽然这些内存不能直接释放,但是Linux提供了Swap机制将不常访问的内存写入到磁盘来释放内存,再次访问时从磁盘读取到内存即可。
Swap原理
Swap本质就是把一块磁盘空间或者一个本地文件当作内存来使用,包括换入和换出两个过程:
换出:将进程暂时不用的内存数据存储到磁盘中,并释放这些内存
换入:进程再次访问内存时,将它们从磁盘读到内存中
Linux如何衡量内存资源是否紧张?
直接内存回收 新的大块内存分配请求,但剩余内存不足。此时系统会回收一部分内存;
kswapd0 内核线程定期回收内存。为了衡量内存使用情况,定义了pages_min,pages_low,pages_high三个阈值,并根据其来进行内存的回收操作。
剩余内存 < pages_min,进程可用内存耗尽了,只有内核才可以分配内存
pages_min < 剩余内存 < pages_low,内存压力较大,kswapd0执行内存回收,直到剩余内存 > pages_high
pages_low < 剩余内存 < pages_high,内存有一定压力,但可以满足新内存请求
剩余内存 > pages_high,说明剩余内存较多,无内存压力
pages_low = pages_min 5 / 4 pages_high = pages_min 3 / 2
NUMA 与 SWAP
很多情况下系统剩余内存较多,但SWAP依旧升高,这是由于处理器的NUMA架构。
在NUMA架构下多个处理器划分到不同的Node,每个Node都拥有自己的本地内存空间。在分析内存的使用时应该针对每个Node单独分析:
numactl --hardware #查看处理器在Node的分布情况,以及每个Node的内存使用情况内存三个阈值可以通过/proc/zoneinfo来查看,该文件中还包括活跃和非活跃的匿名页/文件页数。
当某个Node内存不足时,系统可以从其他Node寻找空闲资源,也可以从本地内存中回收内存。通过/proc/sys/vm/zone_raclaim_mode来调整。
0表示既可以从其他Node寻找空闲资源,也可以从本地回收内存
1,2,4表示只回收本地内存,2表示可以会回脏数据回收内存,4表示可以用Swap方式回收内存。
swappiness
在实际回收过程中Linux根据/proc/sys/vm/swapiness选项来调整使用Swap的积极程度,从0-100,数值越大越积极使用Swap,即更倾向于回收匿名页;数值越小越消极使用Swap,即更倾向于回收文件页。
注意:这只是调整Swap积极程度的权重,即使设置为0,当剩余内存+文件页小于页高阈值时,还是会发生Swap。
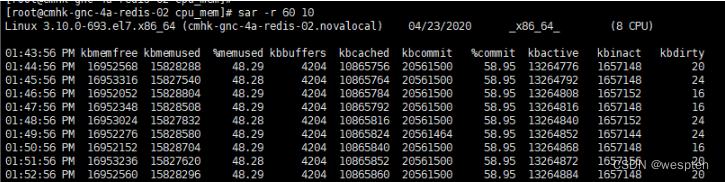
Swap升高时如何定位分析:
free #首先通过free查看swap使用情况,若swap=0表示未配置Swap#先创建并开启swapfallocate -l 8G /mnt/swapfilechmod 600 /mnt/swapfilemkswap /mnt/swapfileswapon /mnt/swapfilefree #再次执行free确保Swap配置成功dd if=/dev/sda1 of=/dev/null bs=1G count=2048 #模拟大文件读取sar -r -S 1 #查看内存各个指标变化 -r内存 -S swap#根据结果可以看出,%memused在不断增长,剩余内存kbmemfress不断减少,缓冲区kbbuffers不断增大,由此可知剩余内存不断分配给了缓冲区#一段时间之后,剩余内存很小,而缓冲区占用了大部分内存。此时Swap使用之间增大,缓冲区和剩余内存只在小范围波动停下sar命令cachetop5 #观察缓存#可以看到dd进程读写只有50%的命中率,未命中数为4w+页,说明正式dd进程导致缓冲区使用升高watch -d grep -A 15 ‘Normal’ /proc/zoneinfo #观察内存指标变化#发现升级内存在一个小范围不停的波动,低于页低阈值时会突然增大到一个大于页高阈值的值说明剩余内存和缓冲区的波动变化正是由于内存回收和缓存再次分配的循环往复。有时候Swap用的多,有时候缓冲区波动更多。此时查看swappiness值为60,是一个相对中和的配置,系统会根据实际运行情况来选去合适的回收类型.
如何“快准狠”找到系统内存存在的问题
内存性能指标
系统内存指标
已用内存/剩余内存
共享内存 (tmpfs实现)
可用内存:包括剩余内存和可回收内存
缓存:磁盘读取文件的页缓存,slab分配器中的可回收部分
缓冲区:原始磁盘块的临时存储,缓存将要写入磁盘的数据
进程内存指标
虚拟内存:5大部分
常驻内存:进程实际使用的物理内存,不包括Swap和共享内存
共享内存:与其他进程共享的内存,以及动态链接库和程序的代码段
Swap内存:通过Swap换出到磁盘的内存
缺页异常
可以直接从物理内存中分配,次缺页异常
需要磁盘IO介入(如Swap),主缺页异常。此时内存访问会慢很多
内存性能工具
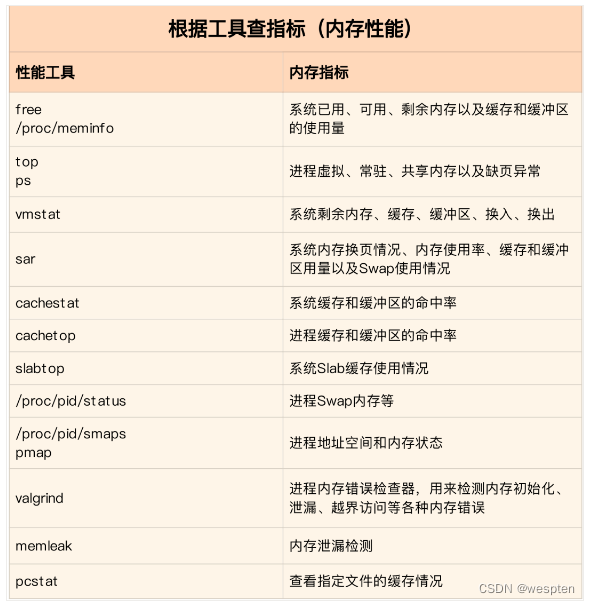
根据不同的性能指标来找合适的工具:
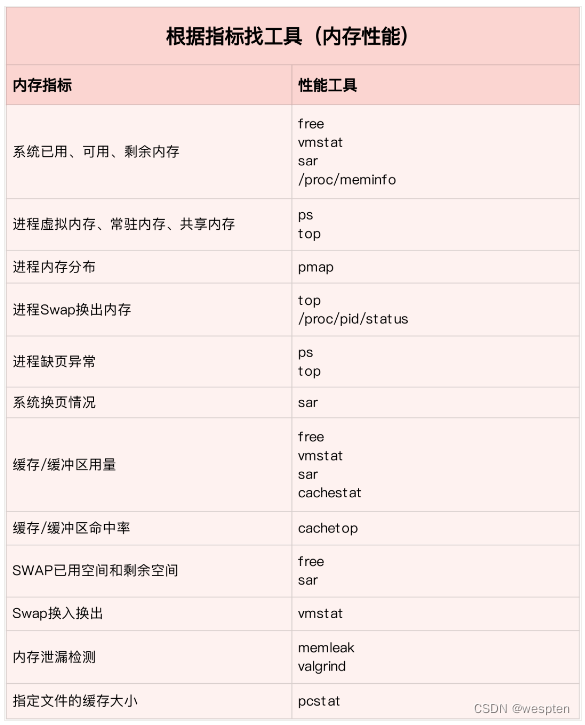
内存分析工具包含的性能指标:
如何迅速分析内存的性能瓶颈
通常先运行几个覆盖面比较大的性能工具,如free,top,vmstat,pidstat等
先用free和top查看系统整体内存使用情况
再用vmstat和pidstat,查看一段时间的趋势,从而判断内存问题的类型
最后进行详细分析,比如内存分配分析,缓存/缓冲区分析,具体进程的内存使用分析等
常见的优化思路:
最好禁止Swap,若必须开启则尽量降低swappiness的值
减少内存的动态分配,如可以用内存池,HugePage等
尽量使用缓存和缓冲区来访问数据。如用堆栈明确声明内存空间来存储需要缓存的数据,或者用Redis外部缓存组件来优化数据的访问
cgroups等方式来限制进程的内存使用情况,确保系统内存不被异常进程耗尽
/proc/pid/oom_adj调整核心应用的oom_score,保证即使内存紧张核心应用也不会被OOM杀死
vmstat使用详解
vmstat命令是最常见的Linux/Unix监控工具,可以展现给定时间间隔的服务器的状态值,包括服务器的CPU使用率,内存使用,虚拟内存交换情况,IO读写情况。可以看到整个机器的CPU,内存,IO的使用情况,而不是单单看到各个进程的CPU使用率和内存使用率(使用场景不一样)。
vmstat 2procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 1 0 0 1379064 282244 11537528 0 0 3 104 0 0 3 0 97 0 0 0 0 0 1372716 282244 11537544 0 0 0 24 4893 8947 1 0 98 0 0 0 0 0 1373404 282248 11537544 0 0 0 96 5105 9278 2 0 98 0 0 0 0 0 1374168 282248 11537556 0 0 0 0 5001 9208 1 0 99 0 0 0 0 0 1376948 282248 11537564 0 0 0 80 5176 9388 2 0 98 0 0 0 0 0 1379356 282256 11537580 0 0 0 202 5474 9519 2 0 98 0 0 1 0 0 1368376 282256 11543696 0 0 0 0 5894 8940 12 0 88 0 0 1 0 0 1371936 282256 11539240 0 0 0 10554 6176 9481 14 1 85 1 0 1 0 0 1366184 282260 11542292 0 0 0 7456 6102 9983 7 1 91 0 0 1 0 0 1353040 282260 11556176 0 0 0 16924 7233 9578 18 1 80 1 0 0 0 0 1359432 282260 11549124 0 0 0 12576 5495 9271 7 0 92 1 0 0 0 0 1361744 282264 11549132 0 0 0 58 8606 15079 4 2 95 0 0 1 0 0 1367120 282264 11549140 0 0 0 2 5716 9205 8 0 92 0 0 0 0 0 1346580 282264 11562644 0 0 0 70 6416 9944 12 0 88 0 0 0 0 0 1359164 282264 11550108 0 0 0 2922 4941 8969 3 0 97 0 0 1 0 0 1353992 282264 11557044 0 0 0 0 6023 8917 15 0 84 0 0# 结果说明- r 表示运行队列(就是说多少个进程真的分配到CPU),我测试的服务器目前CPU比较空闲,没什么程序在跑,当这个值超过了CPU数目,就会出现CPU瓶颈了。这个也和top的负载有关系,一般负载超过了3就比较高,超过了5就高,超过了10就不正常了,服务器的状态很危险。top的负载类似每秒的运行队列。如果运行队列过大,表示你的CPU很繁忙,一般会造成CPU使用率很高。- b 表示阻塞的进程,这个不多说,进程阻塞,大家懂的。- swpd 虚拟内存已使用的大小,如果大于0,表示你的机器物理内存不足了,如果不是程序内存泄露的原因,那么你该升级内存了或者把耗内存的任务迁移到其他机器。- free 空闲的物理内存的大小,我的机器内存总共8G,剩余3415M。- buff Linux/Unix系统是用来存储,目录里面有什么内容,权限等的缓存,我本机大概占用300多M- cache cache直接用来记忆我们打开的文件,给文件做缓冲,我本机大概占用300多M(这里是Linux/Unix的聪明之处,把空闲的物理内存的一部分拿来做文件和目录的缓存,是为了提高 程序执行的性能,当程序使用内存时,buffer/cached会很快地被使用。)- si 每秒从磁盘读入虚拟内存的大小,如果这个值大于0,表示物理内存不够用或者内存泄露了,要查找耗内存进程解决掉。我的机器内存充裕,一切正常。- so 每秒虚拟内存写入磁盘的大小,如果这个值大于0,同上。- bi 块设备每秒接收的块数量,这里的块设备是指系统上所有的磁盘和其他块设备,默认块大小是1024byte,我本机上没什么IO操作,所以一直是0,但是我曾在处理拷贝大量数据(2-3T)的机器上看过可以达到140000/s,磁盘写入速度差不多140M每秒- bo 块设备每秒发送的块数量,例如我们读取文件,bo就要大于0。bi和bo一般都要接近0,不然就是IO过于频繁,需要调整。- in 每秒CPU的中断次数,包括时间中断- cs 每秒上下文切换次数,例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的数目,例如在apache和nginx这种web服务器中,我们一般做性能测试时会进行几千并发甚至几万并发的测试,选择web服务器的进程可以由进程或者线程的峰值一直下调,压测,直到cs到一个比较小的值,这个进程和线程数就是比较合适的值了。系统调用也是,每次调用系统函数,我们的代码就会进入内核空间,导致上下文切换,这个是很耗资源,也要尽量避免频繁调用系统函数。上下文切换次数过多表示你的CPU大部分浪费在上下文切换,导致CPU干正经事的时间少了,CPU没有充分利用,是不可取的。- us 用户CPU时间,我曾经在一个做加密解密很频繁的服务器上,可以看到us接近100,r运行队列达到80(机器在做压力测试,性能表现不佳)。- sy 系统CPU时间,如果太高,表示系统调用时间长,例如是IO操作频繁。- id 空闲CPU时间,一般来说,id + us + sy = 100,一般我认为id是空闲CPU使用率,us是用户CPU使用率,sy是系统CPU使用率。- wt 等待IO CPU时间pidstat 使用详解
pidstat主要用于监控全部或指定进程占用系统资源的情况,如CPU,内存、设备IO、任务切换、线程等。
使用方法:
pidstat –d interval times 统计各个进程的IO使用情况
pidstat –u interval times 统计各个进程的CPU统计信息
pidstat –r interval times 统计各个进程的内存使用信息
pidstat -w interval times 统计各个进程的上下文切换
p PID 指定PID
1、统计IO使用情况
pidstat -d 1 1003:02:02 PM UID PID kB_rd/s kB_wr/s kB_ccwr/s Command03:02:03 PM 0 816 0.00 918.81 0.00 jbd2/vda1-803:02:03 PM 0 1007 0.00 3.96 0.00 AliYunDun03:02:03 PM 997 7326 0.00 1904.95 918.81 java03:02:03 PM 997 8539 0.00 3.96 0.00 java03:02:03 PM 0 16066 0.00 35.64 0.00 cmagent03:02:03 PM UID PID kB_rd/s kB_wr/s kB_ccwr/s Command03:02:04 PM 0 816 0.00 1924.00 0.00 jbd2/vda1-803:02:04 PM 997 7326 0.00 11156.00 1888.00 java03:02:04 PM 997 8539 0.00 4.00 0.00 javaUID
PID
kB_rd/s: 每秒进程从磁盘读取的数据量 KB 单位 read from disk each second KB
kB_wr/s: 每秒进程向磁盘写的数据量 KB 单位 write to disk each second KB
kB_ccwr/s: 每秒进程向磁盘写入,但是被取消的数据量,This may occur when the task truncates some dirty pagecache.
iodelay: Block I/O delay, measured in clock ticks
Command: 进程名 task name
2、统计CPU使用情况
# 统计CPUpidstat -u 1 1003:03:33 PM UID PID %usr %system %guest %CPU CPU Command03:03:34 PM 0 2321 3.96 0.00 0.00 3.96 0 ansible03:03:34 PM 0 7110 0.00 0.99 0.00 0.99 4 pidstat03:03:34 PM 997 8539 0.99 0.00 0.00 0.99 5 java03:03:34 PM 984 15517 0.99 0.00 0.00 0.99 5 java03:03:34 PM 0 24406 0.99 0.00 0.00 0.99 5 java03:03:34 PM 0 32158 3.96 0.00 0.00 3.96 2 ansibleUID
PID
%usr: 进程在用户空间占用 cpu 的百分比
%system: 进程在内核空间占用 CPU 百分比
%guest: 进程在虚拟机占用 CPU 百分比
%wait: 进程等待运行的百分比
%CPU: 进程占用 CPU 百分比
CPU: 处理进程的 CPU 编号
Command: 进程名
3、统计内存使用情况
# 统计内存pidstat -r 1 10Average: UID PID minflt/s majflt/s VSZ RSS %MEM CommandAverage: 0 1 0.20 0.00 191256 3064 0.01 systemdAverage: 0 1007 1.30 0.00 143256 22720 0.07 AliYunDunAverage: 0 6642 0.10 0.00 6301904 107680 0.33 javaAverage: 997 7326 10.89 0.00 13468904 8395848 26.04 javaAverage: 0 7795 348.15 0.00 108376 1233 0.00 pidstatAverage: 997 8539 0.50 0.00 8242256 2062228 6.40 javaAverage: 987 9518 0.20 0.00 6300944 1242924 3.85 javaAverage: 0 10280 3.70 0.00 807372 8344 0.03 aliyun-serviceAverage: 984 15517 0.40 0.00 6386464 1464572 4.54 javaAverage: 0 16066 236.46 0.00 2678332 71020 0.22 cmagentAverage: 995 20955 0.30 0.00 6312520 1408040 4.37 javaAverage: 995 20956 0.20 0.00 6093764 1505028 4.67 javaAverage: 0 23936 0.10 0.00 5302416 110804 0.34 javaAverage: 0 24406 0.70 0.00 10211672 2361304 7.32 javaAverage: 0 26870 1.40 0.00 1470212 36084 0.11 promtailUID
PID
Minflt/s : 每秒次缺页错误次数 (minor page faults),虚拟内存地址映射成物理内存地址产生的 page fault 次数
Majflt/s : 每秒主缺页错误次数 (major page faults), 虚拟内存地址映射成物理内存地址时,相应 page 在 swap 中
VSZ virtual memory usage : 该进程使用的虚拟内存 KB 单位
RSS : 该进程使用的物理内存 KB 单位
%MEM : 内存使用率
Command : 该进程的命令 task name
4、查看具体进程使用情况
pidstat -T ALL -r -p 20955 1 1003:12:16 PM UID PID minflt/s majflt/s VSZ RSS %MEM Command03:12:17 PM 995 20955 0.00 0.00 6312520 1408040 4.37 java03:12:16 PM UID PID minflt-nr majflt-nr Command03:12:17 PM 995 20955 0 0 java二、跑机器脚本与工具
1、stress
安装 stress 和 sysstat 包:
apt install stress sysstatsudo apt install stressCPU 密集型进程
运行 stress 命令,模拟一个 CPU 使用率 100% 的场景:
在一个终端执行:
stress --cpu 1 --timeout 600在另一个终端执行:
watch -d uptime在第三个终端运行 mpstat 查看 CPU 使用率的变化情况。
-P ALL 表示监控所有 CPU,后面数字 5 表示间隔 5 秒后输出一组数据:
root@davinci-mini:/home/HwHiAiUser# mpstat -P ALL 5Linux 4.19.90+ (davinci-mini) 12/23/21 _aarch64_ (8 CPU)查看哪个进程导致了 CPU 使用率高,可以使用 pidstat 来查询。
间隔 5 秒后输出一组数据:
root@davinci-mini:/home/HwHiAiUser# pidstat -u 5 1Linux 4.19.90+ (davinci-mini) 12/23/21 _aarch64_ (8 CPU)I/O 密集型进程
行 stress 命令,但这次模拟 I/O 压力,即不停地执行 sync:
在一个终端执行:
stress -i 1 --timeout 600在第二个终端运行 uptime 查看平均负载的变化情况:
watch -d uptime第三个终端运行 mpstat 查看 CPU 使用率的变化情况。
显示所有 CPU 的指标,并在间隔 5 秒输出一组数据:
mpstat -P ALL 5 1可以看到iowait导致平均负载升高。
哪个进程,导致 iowait 这么高呢? 我们还是用 pidstat 来查询。
间隔 5 秒后输出一组数据,-u 表示 CPU 指标:
pidstat -u 5 1可以发现,是 stress 进程导致的。
大量进程的场景
当系统中运行进程超出 CPU 运行能力时,就会出现等待 CPU 的进程。
我们使用 stress,但这次模拟的是 8 个进程:
stress -c 8 --timeout 600由于系统只有 2 个 CPU,明显比 8 个进程要少得多,因而,系统的 CPU 处于严重过载状态, 平均负载高达 7.97:
uptime..., load average: 7.97, 5.93, 3.02接着再运行 pidstat 来看一下进程的情况。
间隔 5 秒后输出一组数据,-u 表示 CPU 指标:
pidstat -u 5 18 个进程在争抢 2 个 CPU,每个进程等待 CPU 的时间(也就是代码块中的 %wait 列)高达 75%。这些超出 CPU 计算能力的进程,最终导致 CPU 过载。
总结:
平均负载高有可能是 CPU 密集型进程导致的。
平均负载高并不一定代表 CPU 使用率高,还有可能是 I/O 更繁忙了。
当发现负载高的时候,你可以使用 mpstat、pidstat 等工具,辅助分析负载的来源。
2、sysbench
使用 sysbench 来模拟系统多线程调度切换的情况。
先安装 sysbench 和 sysstat 包:
apt install sysbench sysstat上下文切换导致负载高
vmstat是一个常用的系统性能分析工具,主要用来分析系统的内存使用情况,也常用来分析 CPU 上下文切换和中断的次数:
cs(context switch)是每秒上下文切换的次数。in(interrupt)则是每秒中断的次数。r(Running or Runnable)是就绪队列的长度,也就是正在运行和等待 CPU 的进程数。b(Blocked)则是处于不可中断睡眠状态的进程数。vmstat 只给出了系统总体的上下文切换情况,要想查看每个进程的详细情况,就需要使用我们 前面提到过的 pidstat 了。给它加上 -w 选项,你就可以查看每个进程上下文切换的情况了。
这个结果中有两列内容是我们的重点关注对象:
一个是 cswch ,表示每秒自愿上下文切换 (voluntary context switches)的次数。另一个则是 nvcswch ,表示每秒非自愿上下文切换 (non voluntary context switches)的次数。运行sysbench ,模拟系统多线程调度的瓶颈。
以 10 个线程运行 5 分钟的基准测试,模拟多线程切换的问题:
sysbench --threads=10 --max-time=300 threads run在第二个终端运行 vmstat ,观察上下文切换情况:
每隔 1 秒输出 1 组数据(需要 Ctrl+C 才结束):
$ vmstat 1你应该可以发现,cs 列的上下文切换次数从之前的 35 骤然上升到了 139 万。同时,注意观察 其他几个指标:
r 列:就绪队列的长度已经到了 8,远远超过了系统 CPU 的个数 2,所以肯定会有大量的 CPU 竞争。us(user)和 sy(system)列:这两列的 CPU 使用率加起来上升到了 100%,其中系统 CPU 使用率,也就是 sy 列高达 84%,说明 CPU 主要是被内核占用了。in 列:中断次数也上升到了 1 万左右,说明中断处理也是个潜在的问题。综合这几个指标,我们可以知道,系统的就绪队列过长,也就是正在运行和等待 CPU 的进程数过多,导致了大量的上下文切换,而上下文切换又导致了系统 CPU 的占用率升高。
那么到底是什么进程导致了这些问题呢?
在第三个终端再用 pidstat 来看一下, CPU 和进程上下文切换的情况:
HwHiAiUser@davinci-mini:~$ pidstat -w -u 1Linux 4.19.90+ (davinci-mini) 12/23/21 _aarch64_ (8 CPU)19:05:01 UID PID %usr %system %guest %wait %CPU CPU Command19:05:02 0 10 0.00 0.98 0.00 0.00 0.98 1 rcu_sched19:05:02 0 1483 0.98 0.00 0.00 0.00 0.98 3 prometheus19:05:02 0 1904 5.88 0.00 0.00 0.00 5.88 1 java19:05:02 0 2452 1.96 2.94 0.00 0.00 4.90 1 stream19:05:02 0 21148 82.35 22.55 0.00 0.00 100.00 5 vmr-lite19:05:02 0 22155 99.02 11.76 0.00 0.00 100.00 1 analyzer19:05:02 1000 23640 0.98 0.98 0.00 0.00 1.96 3 pidstat-w 参数表示输出进程切换指标,而 -u 参数则表示输出 CPU 使用指标,-wt 参数表示输出线程的上下文切换指标。
中断
从 /proc/interrupts 这个只读文件中读取。/proc 实际上是 Linux 的一个虚拟文 件系统,用于内核空间与用户空间之间的通信。/proc/interrupts 就是这种通信机制的一部分, 提供了一个只读的中断使用情况。
-d 参数表示高亮显示变化的区域:
$ watch -d cat /proc/interrupts。总结:
首先通过uptime查看系统负载,然后使用mpstat结合pidstat来初步判断到底是cpu计算量大还是进程争抢过大或者是io过多,接着使用vmstat分析切换次数,以及切换类型,来进一步判断到底是io过多导致问题还是进程争抢激烈导致问题。
3、ab
ab是Apache超文本传输协议(HTTP)的性能测试工具。 其设计意图是描绘当前所安装的Apache的执行性能, 主要是显示你安装的Apache每秒可以处理多少个请求。
语法:
ab [ -A auth-username ] [ -c concurrency ] [ -C cookie-name=value ] [ -d ] [ -e csv-file ] [ -g gnuplot-file ] [ -h ] [ -H custom-header ] [ -i ] [ -k ] [ -n requests ] [ -p POST-file ] [ -P proxy-auth-username ] [ -q ] [ -s ] [ -S ] [ -t timelimit ] [ -T content-type ] [ -v verbosity] [ -V ] [ -w ] [ -x <table>-attributes ] [ -X proxy[] ] [ -y <tr>-attributes ] [ -z <td>-attributes ] [http://]hostname[:port]/path参数:
-A auth-username:password对服务器提供BASIC认证信任。 用户名和密码由一个:隔开,并以base64编码形式发送。 无论服务器是否需要(即, 是否发送了401认证需求代码),此字符串都会被发送。-c concurrency一次产生的请求个数。默认是一次一个。-C cookie-name=value对请求附加一个Cookie:行。 其典型形式是name=value的一个参数对。 此参数可以重复。-d不显示"percentage served within XX [ms] table"的消息(为以前的版本提供支持)。-e csv-file产生一个以逗号分隔的(CSV)文件, 其中包含了处理每个相应百分比的请求所需要(从1%到100%)的相应百分比的(以微妙为单位)时间。 由于这种格式已经“二进制化”,所以比'gnuplot'格式更有用。-g gnuplot-file把所有测试结果写入一个'gnuplot'或者TSV (以Tab分隔的)文件。 此文件可以方便地导入到Gnuplot, IDL, Mathematica, Igor甚至Excel中。 其中的第一行为标题。-h显示使用方法。-H custom-header对请求附加额外的头信息。 此参数的典型形式是一个有效的头信息行,其中包含了以冒号分隔的字段和值的对 (如, "Accept-Encoding: zip/zop;8bit").-i执行HEAD请求,而不是GET。-k启用HTTP KeepAlive功能,即, 在一个HTTP会话中执行多个请求。 默认时,不启用KeepAlive功能.-n requests在测试会话中所执行的请求个数。 默认时,仅执行一个请求,但通常其结果不具有代表意义。-p POST-file包含了需要POST的数据的文件.-P proxy-auth-username:password对一个中转代理提供BASIC认证信任。 用户名和密码由一个:隔开,并以base64编码形式发送。 无论服务器是否需要(即, 是否发送了401认证需求代码),此字符串都会被发送。-q如果处理的请求数大于150, ab每处理大约10%或者100个请求时,会在stderr输出一个进度计数。 此-q标记可以抑制这些信息。-s用于编译中(ab -h会显示相关信息)使用了SSL的受保护的https, 而不是http协议的时候。此功能是实验性的,也是很简陋的。最好不要用。-S不显示中值和标准背离值, 而且在均值和中值为标准背离值的1到2倍时,也不显示警告或出错信息。 默认时,会显示 最小值/均值/最大值等数值。(为以前的版本提供支持).-t timelimit测试所进行的最大秒数。其内部隐含值是-n 50000。 它可以使对服务器的测试限制在一个固定的总时间以内。默认时,没有时间限制。-T content-typePOST数据所使用的Content-type头信息。-v verbosity设置显示信息的详细程度 - 4或更大值会显示头信息, 3或更大值可以显示响应代码(404, 200等), 2或更大值可以显示警告和其他信息。-V显示版本号并退出。-w以HTML表的格式输出结果。默认时,它是白色背景的两列宽度的一张表。-x <table>-attributes设置<table>属性的字符串。 此属性被填入<table 这里 >.-X proxy[:port]对请求使用代理服务器。-y <tr>-attributes设置<tr>属性的字符串.-z <td>-attributes设置<td>属性的字符串.ab性能指标:
1、吞吐率(Requests per second)服务器并发处理能力的量化描述,单位是reqs/s,指的是在某个并发用户数下单位时间内处理的请求数。某个并发用户数下单位时间内能处理的最大请求数,称之为最大吞吐率。记住:吞吐率是基于并发用户数的。这句话代表了两个含义:a、吞吐率和并发用户数相关b、不同的并发用户数下,吞吐率一般是不同的计算公式:总请求数/处理完成这些请求数所花费的时间,即Request per second=Complete requests/Time taken for tests必须要说明的是,这个数值表示当前机器的整体性能,值越大越好。2、并发连接数(The number of concurrent connections)并发连接数指的是某个时刻服务器所接受的请求数目,简单的讲,就是一个会话。3、并发用户数(Concurrency Level)要注意区分这个概念和并发连接数之间的区别,一个用户可能同时会产生多个会话,也即连接数。在HTTP/1.1下,IE7支持两个并发连接,IE8支持6个并发连接,FireFox3支持4个并发连接,所以相应的,我们的并发用户数就得除以这个基数。4、用户平均请求等待时间(Time per request)计算公式:处理完成所有请求数所花费的时间/(总请求数/并发用户数),即:Time per request=Time taken for tests/(Complete requests/Concurrency Level)5、服务器平均请求等待时间(Time per request:across all concurrent requests)计算公式:处理完成所有请求数所花费的时间/总请求数,即:Time taken for/testsComplete requests可以看到,它是吞吐率的倒数。同时,它也等于用户平均请求等待时间/并发用户数,即Time per request/Concurrency Level并发 1000 个请求测试 Nginx 性能,总共测试 10000 个请求:
$ ab -c 1000 -n 10000 http://127.0.0.1/sw3560/index.htmlThis is ApacheBench, Version 2.0.40-dev <$Revision: 1.146 $> apache-2.0Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/Copyright 2006 The Apache Software Foundation, http://www.apache.org/Benchmarking 127.0.0.1 (be patient)Completed 100 requestsCompleted 200 requestsCompleted 300 requestsCompleted 400 requestsCompleted 500 requestsCompleted 600 requestsCompleted 700 requestsCompleted 800 requestsCompleted 900 requestsFinished 1000 requestsServer Software: Apache/2.2.3Server Hostname: 127.0.0.1Server Port: 80Document Path: /sw3560/index.htmlDocument Length: 5767 bytesConcurrency Level: 1000 #并发的用户数Time taken for tests: 3.85301 seconds #表示所有这些请求被处理完成所花费的时间总和Complete requests: 1000 Failed requests: 0Write errors: 0Total transferred: 6034000 bytes #所有请求的响应数据长度总和HTML transferred: 5767000 bytes #所有请求的响应数据中正文数据的总和Requests per second: 324.12 [#/sec] (mean) #重点:吞吐率,他等于Complete requests / Time taken for tests(相当于 LR 中的 每秒事务数 ,后面括号中的 mean 表示这是一个平均值)Time per request: 3085.301 [ms] (mean) #用户平均请求等待时间,他等于Time taken for tests /(Complete requests / Concurrency Level)【相当于 LR 中的 平均事务响应时间】Time per request: 3.085 [ms] (mean, across all concurrent requests) #服务器平均请求处理时间他等于Time taken for tests / Complete requests (每个请求实际运行时间的平均值)Transfer rate: 1909.70 [Kbytes/sec] received #请求在单位时间内从服务器获取数据的长度他等于Total transferred / Time taken for tests 这个统计选项可以很好的说明服务器在处理能力达到极限时其出口带宽的需求量Connection Times (ms) min mean[+/-sd] median maxConnect: 0 30 16.6 30 59Processing: 21 924 975.9 612 3027Waiting: 20 923 976.0 612 3026Total: 21 954 987.4 637 3084Percentage of the requests served within a certain time (ms) 50% 637 66% 1437 75% 1455 80% 1462 90% 3068 95% 3076 98% 3081 99% 3083100% 3084 (longest request)#用于描述每个请求处理时间的分布情况,例如:50% 1 50%请求处理时间不超过1秒 (这里所指的处理时间是指:Time per request )说明:
通过上图,测试结果也一目了然,apache测试出的吞吐率为:Requests per second:324.12[#/sec](mean)。
Server Software表示被测试的Web服务器软件名称。Server Hostname表示请求的URL主机名。Server Port表示被测试的Web服务器软件的监听端口。Document Path表示请求的URL中的根绝对路径,通过该文件的后缀名,我们一般可以了解该请求的类型。Document Length表示HTTP响应数据的正文长度。Concurrency Level表示并发用户数,这是我们设置的参数之一。Time taken for tests表示所有这些请求被处理完成所花费的总时间。Complete requests表示总请求数量,这是我们设置的参数之一。Failed requests表示失败的请求数量,这里的失败是指请求在连接服务器、发送数据等环节发生异常,以及无响应后超时的情况。如果接收到的HTTP响应数据的头信息中含有2XX以外的状态码,则会在测试结果中显示另一个名为“Non-2xx responses”的统计项,用于统计这部分请求数,这些请求并不算在失败的请求中。Total transferred表示所有请求的响应数据长度总和,包括每个HTTP响应数据的头信息和正文数据的长度。注意这里不包括HTTP请求数据的长度,仅仅为web服务器流向用户PC的应用层数据总长度。TML transferred表示所有请求的响应数据中正文数据的总和,也就是减去了Total transferred中HTTP响应数据中的头信息的长度。Requests per second吞吐率,计算公式:Complete requests/Time taken for testsTime per request用户平均请求等待时间,计算公式:Time token for tests/(Complete requests/Concurrency Level)。Time per requet(across all concurrent request)服务器平均请求等待时间,计算公式:Time taken for tests/Complete requests,正好是吞吐率的倒数。也可以这么统计:Time per request/Concurrency Level。Transfer rate表示这些请求在单位时间内从服务器获取的数据长度,计算公式:Total trnasferred/ Time taken for tests,这个统计很好的说明服务器的处理能力达到极限时,其出口宽带的需求量。Percentage of requests served within a certain time(ms)这部分数据用于描述每个请求处理时间的分布情况,比如以上测试,80%的请求处理时间都不超过6ms,这个处理时间是指前面的Time per request,即对于单个用户而言,平均每个请求的处理时间。4、dd
在磁盘测试中我们一般最关心的几个指标分别为:iops(每秒执行的IO次数)、bw(带宽,每秒的吞吐量)、lat(每次IO操作的延迟)。
当每次IO操作的block较小时,如512bytes/4k/8k等,测试的主要是iops。
当每次IO操作的block较大时,如256k/512k/1M等,测试的主要是bw。
dd是linux自带的磁盘读写工具,可用于测试顺序读写。
一般而言,磁盘读写有两种方式:BufferIO、DirectIO,DirectIO可以更好的了解纯磁盘读写的性能。
参数:
if=file:输入文件名,缺省为标准输入 of=file:输出文件名,缺省为标准输出 ibs=bytes:一次读入 bytes 个字节(即一个块大小为 bytes 个字节) obs=bytes:一次写 bytes 个字节(即一个块大小为 bytes 个字节) bs=bytes:同时设置读写块的大小为 bytes ,可代替 ibs 和 obs cbs=bytes:一次转换 bytes 个字节,即转换缓冲区大小 skip=blocks:从输入文件开头跳过 blocks 个块后再开始复制 seek=blocks:从输出文件开头跳过 blocks 个块后再开始复制。(通常只有当输出文件是磁盘或磁带时才有效) count=blocks:仅拷贝 blocks 个块,块大小等于 ibs 指定的字节数 conv=ASCII:把EBCDIC码转换为ASCIl码。 conv=ebcdic:把ASCIl码转换为EBCDIC码。 conv=ibm:把ASCIl码转换为alternate EBCDIC码。 conv=block:把变动位转换成固定字符。 conv=ublock:把固定位转换成变动位。 conv=ucase:把字母由小写转换为大写。 conv=lcase:把字母由大写转换为小写。 conv=notrunc:不截短输出文件。 conv=swab:交换每一对输入字节。 conv=noerror:出错时不停止处理。 conv=sync:把每个输入记录的大小都调到ibs的大小(用NUL填充)。 FLAGS参数说明:
append -append mode (makes sense only for output; conv=notrunc sug-gested) direct:读写数据采用直接IO方式; directory:读写失败除非是directory; dsync:读写数据采用同步IO; sync:同上,但是针对是元数据 fullblock:堆积满block(accumulate full blocks of input )(iflag only); nonblock:读写数据采用非阻塞IO方式 noatime:读写数据不更新访问时间 注意:指定数字的地方若以下列字符结尾乘以相应的数字:b=512, c=1, k=1024, w=2, xm=number m,kB=1000,K=1024,MB=1000*1000,M=1024*1024,GB=1000*1000*1000,G=1024*1024*1024
if=xxx 从xxx读取,如if=/dev/zero,该设备无穷尽地提供0,(不产生读磁盘IO)
of=xxx 向xxx写出,可以写文件,可以写裸设备。如of=/dev/null,"黑洞",它等价于一个只写文件. 所有写入它的内容都会永远丢失. (不产生写磁盘IO)。
从0设备读入数据并写入zero.img 文件,最后一个参数是为了排除cache的问题:
dd if=/dev/zero of=./zero.img bs=10M count=100 oflag=dsyncdd测试DirectIO:
iops——写测试 dd if=/dev/zero of=./a.dat bs=8k count=1M oflag=direct iops——读测试 dd if=./a.dat of=/dev/null bs=8k count=1M iflag=direct bw——写测试 dd if=/dev/zero of=./a.dat bs=1M count=8k oflag=direct bw——读测试 dd if=./a.dat of=/dev/null bs=1M count=8k iflag=direct 
BufferIO主要出现在一些大文件读写的场景,由于使用内存做Cache所以读写性能上和DirectIO相比,通常会高很多,尤其是读,所以这个场景下我们仅关心bw即可。
用dd测试BufferIO的写时,需要增加一个conv=fdatasync,使用该参数,在完成所有读写后会调用一个sync确保数据全部刷到磁盘上(期间操作系统也有可能会主动flush),否则就是主要在测内存读写了;
另外还有一个参数是oflag=dsync 将跳过内存缓存,direct 读写数据采用直接IO方式。使用该参数也是走的BufferIO,但却是会在每次IO操作后都执行一个sync。
测试纯写入性能:
time dd if=/dev/zero of=/tmp/foo bs=4k count=10000 oflag=direct这个命令时往磁盘的文件/tmp/foo中写入一个4G大小的文件,当然文件的内容全部是空字符了,同时用/usr/bin/time来对命令的执行进行计时,命令中的bs指的是写入文件时的块大小,其实就相当于Oracle中的block大小了,count是写入的块数。采取这种方法来写入数据时只是测试的连续读磁盘的性能,而不是随机读的性能,不能采取这种方法检查一个机器的IOPS的,只能检查磁盘的吞吐率。
测试纯读取性能:
time dd if=test of=/dev/null bs=4k count=10000 iflag=direct1. time有计时作用,dd用于复制,从if读出,写到of;
2. if=/dev/zero不产生IO,因此可以用来测试纯写速度;
3. 同理of=/dev/null不产生IO,可以用来测试纯读速度;
4. 将/tmp/test拷贝到/var则同时测试了读写速度;
5. bs是每次读或写的大小,即一个块的大小,count是读写块的数量;
测试的仅仅是最大的读取性能,而不是随机IO的性能。
读写同时测试:
/usr/bin/time dd if=/tmp/foo of=/tmp/foo2 bs=4k通常conv=fdatasync更符合大文件读写的场景,所以这里以其作为参数进行测试。
dd测试BufferIO:
bw——写测试 dd if=/dev/zero of=./a.dat bs=1M count=8k conv=fdatasync bw——读测试 dd if=./a.dat of=/dev/null bs=1M count=8k 
死循环跑dd:
#!/bin/shwhile :do dd if=/dev/zero of=./a.dat bs=8k count=100M oflag=direct usleep 1donedd if=/dev/zero of=./a.dat bs=100 count=100 oflag=syncdd if=/dev/zero of=./a.dat bs=512 count=100 oflag=direct 测试网络IO请求
Server1使用nc监听17480端口的网络I/O请求:
[root@server1 ~]# nc -v -l -n 17480 > /dev/nullNcat: Version 6.40 ( http://nmap.org/ncat )Ncat: Listening on :::17480Ncat: Listening on 0.0.0.0:17480Ncat: Connection from 192.168.0.97.Ncat: Connection from 192.168.0.97:39156.在Server2节点上发起网络I/O请求:
[root@server2 ~]# time dd if=/dev/zero | nc -v -n 192.168.0.99 17480Ncat: Version 6.40 ( http://nmap.org/ncat )Ncat: Connected to 192.168.0.99:17480.^C记录了34434250+0 的读入记录了34434249+0 的写出17630335488字节(18 GB)已复制,112.903 秒,156 MB/秒real 1m52.906suser 1m23.308ssys 2m22.487s注意:
dd命令用到了time命令对操作进行计时,这样才能正确的进行判断。要记住的一点是dd命令只能够提供一个大概的测试,通过这个简单的命令可以对磁盘系统的最大性能有一个大概的了解。
dd测试是运维常用来测试磁盘读写性能的,配合iostat的一起使用观察磁盘性能。dd测试是顺序写入磁盘,结果是参考值,常用标准块4K测试,根据实际需要调整bs参数。测试时一定加direct值,无缓存测试。需要和线上正常磁盘比对,否则没有参考价值。
5、fio工具
fio是专门用于测试磁盘IO的工具,与dd相比那是要强大非常多,它可以用于测试顺序读写、随机读写、顺序混合读写、随机混合读写,并且可以调整IO并发量,在测试完成后还会生成一份测试报告,相当给力。
参数:
filename=/home/test 测试文件名称,通常选择需要测试的盘的data目录。direct=1 测试过程绕过机器自带的buffer。使测试结果更真实。rw=randwrite 测试随机写的I/Orw=randrw 测试随机写和读的I/Obs=4k 单次io的块文件大小为4ksize=2g 本次的测试文件大小为2g,以每次4k的io进行测试。numjobs=64 本次的测试线程为64.runtime=20 测试时间为20秒,如果不写则一直将2g文件分4k每次写完为止。100%随机,100%读, 4K:
fio -filename=/dev/emcpowerb -direct=1 -iodepth 1 -thread -rw=randread -ioengine=psync -bs=4k -size=1000G -numjobs=50 -runtime=180 -group_reporting -name=rand_100read_4k test-rand-read: (groupid=0, jobs=64): err= 0: pid=4619read : io=72556KB, bw=3457.4KB/s, iops=864 , runt= 20986msec//随机读,带宽3457.4KB/s, iops=864100%随机,100%写, 4K:
fio -filename=/dev/emcpowerb -direct=1 -iodepth 1 -thread -rw=randwrite -ioengine=psync -bs=4k -size=1000G -numjobs=50 -runtime=180 -group_reporting -name=rand_100write_4k test-rand-write: (groupid=0, jobs=64): err= 0: pid=4685write: io=129264KB, bw=6432.4KB/s, iops=1608 , runt= 20097msec//随机写,带宽6432.4KB/s, iops=1608100%顺序,100%读 ,4K:
fio -filename=/dev/emcpowerb -direct=1 -iodepth 1 -thread -rw=read -ioengine=psync -bs=4k -size=1000G -numjobs=50 -runtime=180 -group_reporting -name=sqe_100read_4k test-read: (groupid=0, jobs=4): err= 0: pid=4752read : io=839680KB, bw=76823KB/s, iops=75 , runt= 10930msec//顺序读,带宽76823KB/s,iops 75100%顺序,100%写 ,4K:
fio -filename=/dev/emcpowerb -direct=1 -iodepth 1 -thread -rw=write -ioengine=psync -bs=4k -size=1000G -numjobs=50 -runtime=180 -group_reporting -name=sqe_100write_4k test-write: (groupid=0, jobs=4): err= 0: pid=4758write: io=899072KB, bw=42854KB/s, iops=41 , runt= 20980msec//顺序写,带宽42854KB/s, iops=41100%随机,70%读,30%写 4K:
fio -filename=/dev/emcpowerb -direct=1 -iodepth 1 -thread -rw=randrw -rwmixread=70 -ioengine=psync -bs=4k -size=1000G -numjobs=50 -runtime=180 -group_reporting -name=randrw_70read_4k 6、iozone
测试文件系统性能最全面的工具iozone,可以测试不同的操作系统中文件系统的读写性能。可以测试 Read, write, re-read,re-write, read backwards, read strided, fread, fwrite, random read, pread, mmap, aio_read, aio_write 等等不同的模式下的硬盘的性能。
IO测试的定义:
Write: 测试向一个新文件写入的性能。当一个新文件被写入时,不仅仅是那些文件中的数据需要被存储,还包括那些用于定位数据存储在存储介质的具体位置的额外信息。这些额外信息被称作“元数据”。它包括目录信息,所分配的空间和一些与该文件有关但又并非该文件所含数据的其他数据。拜这些额外信息所赐,Write的性能通常会比Re-write的性能低。Re-write: 测试向一个已存在的文件写入的性能。当一个已存在的文件被写入时,所需工作量较少,因为此时元数据已经存在。Re-write的性能通常比Write的性能高。Read: 测试读一个已存在的文件的性能。Re-Read: 测试读一个最近读过的文件的性能。Re-Read性能会高些,因为操作系统通常会缓存最近读过的文件数据。这个缓存可以被用于读以提高性能。Random Read: 测试读一个文件中的随机偏移量的性能。许多因素可能影响这种情况下的系统性能,例如:操作系统缓存的大小,磁盘数量,寻道延迟和其他。Random Write: 测试写一个文件中的随机偏移量的性能。同样,许多因素可能影响这种情况下的系统性能,例如:操作系统缓存的大小,磁盘数量,寻道延迟和其他。Random Mix: 测试读写一个文件中的随机偏移量的性能。同样,许多因素可能影响这种情况下的系统性能,例如:操作系统缓存的大小,磁盘数量,寻道延迟和其他。这个测试只有在吞吐量测试模式下才能进行。每个线程/进程运行读或写测试。这种分布式读/写测试是基于round robin 模式的。最好使用多于一个线程/进程执行此测试。Backwards Read: 测试使用倒序读一个文件的性能。这种读文件方法可能看起来很可笑,事实上,有些应用确实这么干。MSC Nastran是一个使用倒序读文件的应用程序的一个例子。它所读的文件都十分大(大小从G级别到T级别)。尽管许多操作系统使用一些特殊实现来优化顺序读文件的速度,很少有操作系统注意到并增强倒序读文件的性能。Record Rewrite: 测试写与覆盖写一个文件中的特定块的性能。这个块可能会发生一些很有趣的事。如果这个块足够小(比CPU数据缓存小),测出来的性能将会非常高。如果比CPU数据缓存大而比TLB小,测出来的是另一个阶段的性能。如果比此二者都大,但比操作系统缓存小,得到的性能又是一个阶段。若大到超过操作系统缓存,又是另一番结果。Strided Read: 测试跳跃读一个文件的性能。举例如下:在0偏移量处读4Kbytes,然后间隔200Kbytes,读4Kbytes,再间隔200Kbytes,如此反复。此时的模式是读4Kbytes,间隔200Kbytes并重复这个模式。这又是一个典型的应用行为,文件中使用了数据结构并且访问这个数据结构的特定区域的应用程序常常这样做。 许多操作系统并没注意到这种行为或者针对这种类型的访问做一些优化。同样,这种访问行为也可能导致一些有趣的性能异常。一个例子是在一个数据片化的文件系统里,应用程序的跳跃导致某一个特定的磁盘成为性能瓶颈。Fwrite: 测试调用库函数fwrite()来写文件的性能。这是一个执行缓存与阻塞写操作的库例程。缓存在用户空间之内。如果一个应用程序想要写很小的传输块,fwrite()函数中的缓存与阻塞I/O功能能通过减少实际操作系统调用并在操作系统调用时增加传输块的大小来增强应用程序的性能。 这个测试是写一个新文件,所以元数据的写入也是要的。Frewrite:测试调用库函数fwrite()来写文件的性能。这是一个执行缓存与阻塞写操作的库例程。缓存在用户空间之内。如果一个应用程序想要写很小的传输块,fwrite()函数中的缓存与阻塞I/O功能能通过减少实际操作系统调用并在操作系统调用时增加传输块的大小来增强应用程序的性能。 这个测试是写入一个已存在的文件,由于无元数据操作,测试的性能会高些。Fread:测试调用库函数fread()来读文件的性能。这是一个执行缓存与阻塞读操作的库例程。缓存在用户空间之内。如果一个应用程序想要读很小的传输块,fwrite()函数中的缓存与阻塞I/O功能能通过减少实际操作系统调用并在操作系统调用时增加传输块的大小来增强应用程序的性能。Freread: 这个测试与上面的fread 类似,除了在这个测试中被读文件是最近才刚被读过。这将导致更高的性能,因为操作系统缓存了文件数据。 几个特殊测试: Mmap:许多操作系统支持mmap()的使用来映射一个文件到用户地址空间。映射之后,对内存的读写将同步到文件中去。这对一些希望将文件当作内存块来使用的应用程序来说很方便。一个例子是内存中的一块将同时作为一个文件保存在于文件系统中。 mmap 文件的语义和普通文件略有不同。如果发生了对内存的存储,并不是立即发生相应的文件I/O操作。使用MS_SYNC 和MS_ASYNC标志位的 msyc()函数调用将控制内存和文件的一致性。调用msync() 时将MS_SYNC置位将强制把内存里的内容写到文件中去并等待直到此操作完成才返回。而MS_ASYNC 置位则告诉操作系统使用异步机制将内存刷新到磁盘,这样应用程序可以直接返回而不用等待此操作的完成。 这个测试就是测量使用mmap()机制完成I/O的性能。 Async I/O: 许多操作系统支持的另外一种I/O机制是POSIX 标准的异步I/O。本程序使用POSIX标准异步I/O接口来完成此测试功能。 例如: aio_write(), aio_read(), aio_error()。这个测试测量POSIX异步I/O机制的性能。语法:
Usage: iozone [-s filesize_Kb] [-r record_size_Kb ] [-f [path]filename] [-i test] [-E] [-p] [-a] [-A] [-z] [-Z] [-m] [-M] [-t children] [-h] [-o] [-l min_number_procs] [-u max_number_procs] [-v] [-R] [-x] [-d microseconds] [-F path1 path2...] [-V pattern] [-j stride] [-T] [-C] [-B] [-D] [-G] [-I] [-H depth] [-k depth] [-U mount_point] [-S cache_size] [-O] [-K] [-L line_size] [-g max_filesize_Kb] [-n min_filesize_Kb] [-N] [-Q] [-P start_cpu] [-c] [-e] [-b filename] [-J milliseconds] [-X filename] [-Y filename] [-w] [-W] [-y min_recordsize_Kb] [-q max_recordsize_Kb] [-+m filename] [-+u ] [ -+d ] [-+p percent_read] [-+r] [-+t ] [-+A #]参数:
-a全自动模式测试。测试记录块大小从4k到16M,测试文件从64k到512M-A使用自动模式虽然测试比较全面,但是比较花时间。-a选项将在文件大于32MB时停止使用低于64k一下记录块,来节省时间。-A通知iozone不要节省时间,进行所有测试。注:在3.61版本以后不建议使用,用-az代替-aA-B使用mmap()。这将使用mmap()接口来创建并访问所有测试用的临时文件。一些应用程序倾向于将文件当作内存的一块来看待。这些应用程序对文件执行mmap()调用,然后就可以以读写内存的方式访问那个块来完成文件I/O。-c计算时间将close()包括进来-C显示吞吐量测试中每个客户端的字节数。-D对mmap文件使用MSYNC(MS_ASYNC)。告诉操作系统在mmap空间的所有数据需要被异步的写到磁盘上。-e测试时间是包含flush(fsync, fflush)-f filename指定用来测试临时文件,在测试完成后将被自动删除-F filename filename ...指定测试中每个临时文件名,文件名的数量应该和指定的进程或线程数相同-g #在自动模式下设置文件最大值,可以使用#k #m #g分别表示kb,mb,gb-G对mmap文件使用msync(MS_SYNC)。告诉操作系统在mmap空间的所有数据需要被同步的写到磁盘上-h显示帮助-i #指定运行于哪种模式测试。可以使用-i # -i # -i #进行多个测试0=write/rewrite1=read/re-read2=random read/random write3=backwards read4=re-write-record5=stride-read6=fwirte/re-fwrite7=fread/re-fread8=random mix9=pwrite/re-pwrite10=pread/re-pread11=pwritev/re-pwritev12=preadv/re-preadv-I对所有文件操作使用DIRECT I/O。通知文件系统所有操作跳过缓存直接在磁盘上操作-j #设置访问文件的跨度为(# * 块)。stride read测试将使用这个跨度来读块-J #(毫秒)在每个I/O操作之前产生指定毫秒的计算延迟。看-X和-Y获取控制计算延迟的其他参数-l #设置程序最小进程数。在测试过程允许用户设置的最小进程或线程数。需要配合-u选项使用。-L #设置处理器交换信息的单位量为#(bytes)。可以加速测试。-miozone将在内部使用多个缓存。一些程序反复复写一块缓存,还有就是设置多个缓存块。此参数将允许使用这两种模式。iozone默认行为是重复使用内部一个缓存。此选项将允许在内部使用多个缓存块。-M调用uname(),将返回字符串放在输出文件中-n #设置自动模式下测试文件的最小值-N报告结果以毫秒每操作的方式显示-o写方式是同步写到磁盘上-O报告结果以操作每秒方式显示-q #在自动模式下设置记录块的最大值,可以使用#k(kb),#m(mb),#g(gb)。使用-y可以设置最小值-r #设置记录块大小为#-R使用Excel显示结果-s #设置测试文件大小-S #设置处理器的缓存大小-t #设置测试程序的线程或进程数-T 使用POSIX的pthreads进行测试-u #设置最大进程或线程数,需要配合-l参数使用-U mountpoint在测试开始之前,iozone将unmount和remount挂载点。这将保证测试中缓存不包含任何文件-w在测试结束后不要删除临时文件。临时文件将在测试过后保存下来-W在测试过程中,当读或写文件时锁住文件-y #设置记录块最小值-z同-a一起使用,进行全部测试-Z允许mmap I/O和file I/O混合使用常用的参数说明:
-n -g 用于指定测试的filesize的范围,相对应的-s指定一个确定值;-y -q 用于指定每次读写的blocksize范围,相对应的-r指定一个定值;-l -u用于指定使用的用户数从多少到多少;-a 如果你指定了范围类的参数,那么不加-a,最后的结果只有第一列有数据;-i 指定测试那种类型的读写,1-12可供选择;-I 跳过缓存直接读写磁盘;-f 指定输入文件的具体位置,这个文件一定要在你要测的那个磁盘上;-F 如果你用了 -l -u 的话,那么里面有多少个用户,就要用这个参数指定多少个文件,文件之间用空格分隔,如:-F tmp.1 tmp.2 tmp.3;-w 测试之后不删除测试文件;-R 产生Excel到标准输出-b 指定输出到指定文件上. 比如 -Rb ttt.xls-Rb filename.xls 将结果写到Excel表格中;测试的时候请注意,设置的测试文件的大小一定要大过你的内存(最佳为内存的两倍大小),不然linux会给你的读写的内容进行缓存。会使数值非常不真实。
iozone -i 0 -i 2 -Rc -a -q 500k -g 1m -n 100k -b test_result.xls 参数说明如下:
-i 代表测试场景,0 代表运行顺序写测试,1代表运行随机读写测试。还有很多场景可选,具体可见iozone -h说明-R 代表生成Excel报告文件。-c 代表每次读写测试完毕都发送关闭连接的命令,主要用于测试NFS系统。-a 代表自动模式。-q 代表最大的记录大小。-g 代表最大的文件大小。-n 代表最小的文件大小。-b 输出的生成的Excel报告文件名字。生成报告如下:
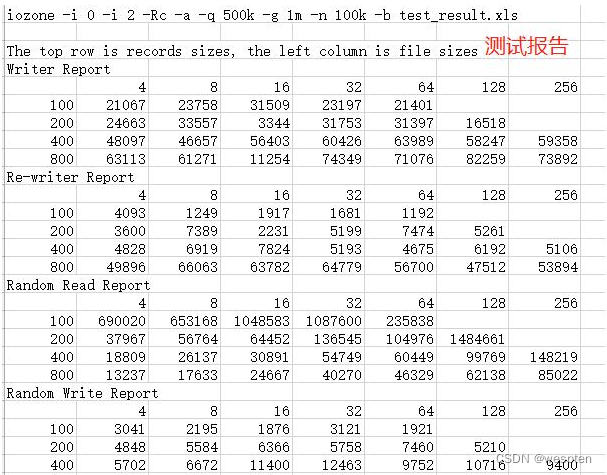
自动模式开启,以4k到16M为记录块,读写从64k到512M大小的文件的读写速度(默认以KB为单位)。
./iozone -aR如果想以图表形式显示测试结果,可以使用,iozone将测试结果放在Excel中:
./iozone -a -i 0 -i 1 -i 2 -i 6 -i 7 -i 8 -n 64m -g 256m -y 256 -q 8192 -I -f /mnt/mfs/1m.tmp -w -Rb ./xls/mfs_i.xls 结果的片段如下:

第一行,就是-i指定的那个参数,比如:表中使Writer Report,那么参数中就有 -i 2, 当然也有可能是-a自动加的;
第二行,各列值就是由"-y 256 -q 8192"指定的,单位是K,表示每次读写多大,当然在指定的时候也可以写M、G但是B是不起作用的;
第一列,各行就是由"-n 64m -g 256m"指定的,表示读写的文件依次从64m到256m,以2倍的形式增长;
中间的数据单位都是Kb/s表示读写速度;
另外可以看见标红色字体的部分,就是由于指定了"-I"参数,说明磁盘很希望你用每次读2048K的大小读取128M的文件。
如果内存大于512MB,则测试文件需要更大;最好测试文件是内存的两倍。例如内存为1G,将测试文件设置最大为2G:
./iozone -Ra -g 2g如果我们只关心文件磁盘的read/write性能,而不必花费时间在其他模式上测试,则我们需要指定测试模式:
./iozone -Ra -g 2g -i 0 -i 1只进行read/write测试,测试文件大小是4G,记录块从2k到8m,并将测试数据输出到Excel文件中:
./iozone -a -s 4g -i 0 -i 1 -f /tmp/testfile -y 2k -q 8m -Rb output.xls如果我们测试的NFS,将使用-c,这通知iozone在测试过程中执行close()函数。使用close()将减少NFS客户端缓存的影响。但是如果测试文件比内存大,就没有必要使用参数-c:
./iozone -Rac 多线程下的同步I/O读写测试
分别针对128K,16M,256M,2G文件大小和8进程,64进程,128进程数进行测试。
主要测试文件写和重复写、读和重复读、随即读写、后向读、文件内随即点写、大间隔文件点读、文件内的随即点读写等测试项,记录大小1M cpu cache 2048kbyte。
128k 文件性能测试:
iozone -s 128k -i 0 -i 1 -i 2 -i 3 -i 4 -i 5 -i 8 -t 8 -G -o -B -Rb iozone.xlsiozone -s 128k -i 0 -i 1 -i 2 -i 3 -i 4 -i 5 -i 8 -t 64 -G -o -B -Rb iozone.xlsiozone -s 128k -i 0 -i 1 -i 2 -i 3 -i 4 -i 5 -i 8 -t 128 -G -o -B -Rb iozone.xls16M文件性能测试:
iozone -s 16M -i 0 -i 1 -i 2 -i 3 -i 4 -i 5 -i 8 -t 8 -G -o -B -Rb iozone.xlsiozone -s 16M -i 0 -i 1 -i 2 -i 3 -i 4 -i 5 -i 8 -t 64 -G -o -B -Rb iozone.xlsiozone -s 16M -i 0 -i 1 -i 2 -i 3 -i 4 -i 5 -i 8 -t 128 -G -o -B -Rb iozone.xls256M文件性能测试:
iozone -s 256M -i 0 -i 1 -i 2 -i 3 -i 4 -i 5 -i 8 -t 8 -G -o -B -Rb iozone.xlsiozone -s 256M -i 0 -i 1 -i 2 -i 3 -i 4 -i 5 -i 8 -t 64 -G -o -B -Rb iozone.xlsiozone -s 256M -i 0 -i 1 -i 2 -i 3 -i 4 -i 5 -i 8 -t 128 -G -o -B -Rb iozone.xls2G文件性能测试:
iozone -s 2G -i 0 -i 1 -i 2 -i 3 -i 4 -i 5 -i 8 -t 8 -G -o -B -Rb iozone.xlsiozone -s 2G -i 0 -i 1 -i 2 -i 3 -i 4 -i 5 -i 8 -t 64 -G -o -B -Rb iozone.xlsiozone -s 2G -i 0 -i 1 -i 2 -i 3 -i 4 -i 5 -i 8 -t 128 -G -o -B -Rb iozone.xls多线程下的异步I/O读写测试
分别针对128K,16M,256M,2G文件大小和8进程,64进程,128进程数进行测试。
主要测试文件写和重复写、读和重复读、随即读写、后向读、文件内随即点写、大间隔文件点读、文件内的随即点读写等测试项。
128k 文件性能测试:
iozone -s 128k -i 0 -i 1 -i 2 -i 3 -i 4 -i 5 -i 8 -t 8 -D -o -B -Rb iozone.xlsiozone -s 128k -i 0 -i 1 -i 2 -i 3 -i 4 -i 5 -i 8 -t 64 -D -o -B -Rb iozone.xlsiozone -s 128k -i 0 -i 1 -i 2 -i 3 -i 4 -i 5 -i 8 -t 128 -D -o -B -Rb iozone.xls16M文件性能测试:
iozone -s 16M -i 0 -i 1 -i 2 -i 3 -i 4 -i 5 -i 8 -t 8 -D -o -B -Rb iozone.xlsiozone -s 16M -i 0 -i 1 -i 2 -i 3 -i 4 -i 5 -i 8 -t 64 -D -o -B -Rb iozone.xlsiozone -s 16M -i 0 -i 1 -i 2 -i 3 -i 4 -i 5 -i 8 -t 128 -D -o -B -Rb iozone.xls256M文件性能测试:
iozone -s 256M -i 0 -i 1 -i 2 -i 3 -i 4 -i 5 -i 8 -t 8 -D -o -B -Rb iozone.xlsiozone -s 256M -i 0 -i 1 -i 2 -i 3 -i 4 -i 5 -i 8 -t 64 -D -o -B -Rb iozone.xlsiozone -s 256M -i 0 -i 1 -i 2 -i 3 -i 4 -i 5 -i 8 -t 128 -D -o -B -Rb iozone.xls2G文件性能测试:
iozone -s 2G -i 0 -i 1 -i 2 -i 3 -i 4 -i 5 -i 8 -t 8 -D -o -B -Rb iozone.xlsiozone -s 2G -i 0 -i 1 -i 2 -i 3 -i 4 -i 5 -i 8 -t 64 -D -o -B -Rb iozone.xlsiozone -s 2G -i 0 -i 1 -i 2 -i 3 -i 4 -i 5 -i 8 -t 128 -D -o -B -Rb iozone.xls7、Iperf
Iperf是一个网络性能测试工具,Iperf可以测试TCP和UDP带宽质量。
Iperf可以测量最大TCP带宽,具有多种参数和UDP特性。Iperf可以报告带宽,延迟抖动和数据包丢失。
参数:
-s 以server模式启动,eg:iperf -s-c host以client模式启动,host是server端地址,eg:iperf -c 222.35.11.23通用参数-f [k|m|K|M] 分别表示以Kbits, Mbits, KBytes, MBytes显示报告,默认以Mbits为单位,eg:iperf -c 222.35.11.23 -f K-i sec 以秒为单位显示报告间隔,eg:iperf -c 222.35.11.23 -i 2-l 缓冲区大小,默认是8KB,eg:iperf -c 222.35.11.23 -l 16-m 显示tcp最大mtu值-o 将报告和错误信息输出到文件eg:iperf -c 222.35.11.23 -o c:\iperflog.txt-p 指定服务器端使用的端口或客户端所连接的端口eg:iperf -s -p 9999;iperf -c 222.35.11.23 -p 9999-u 使用udp协议-w 指定TCP窗口大小,默认是8KB-B 绑定一个主机地址或接口(当主机有多个地址或接口时使用该参数)-C 兼容旧版本(当server端和client端版本不一样时使用)-M 设定TCP数据包的最大mtu值-N 设定TCP不延时-V 传输ipv6数据包server专用参数-D 以服务方式运行ipserf,eg:iperf -s -D-R 停止iperf服务,针对-D,eg:iperf -s -Rclient端专用参数-d 同时进行双向传输测试-n 指定传输的字节数,eg:iperf -c 222.35.11.23 -n 100000-r 单独进行双向传输测试-t 测试时间,默认10秒,eg:iperf -c 222.35.11.23 -t 5-F 指定需要传输的文件-T 指定ttl值8、memtester
Memtester 主要是捕获内存错误和一直处于很高或者很低的坏位,其测试的主要项目有随机值,异或比较,减法,乘法,除法,与或运算等等。通过给定测试内存的大小和次数,可以对系统现有的内存进行压力测试。
官网:https://pyropus.ca./software/memtester/
语法:
memtester [-p PHYSADDR] <MEMORY> [ITERATIONS]MEMORY 申请测试内存的数量,单位默认是 megabytes (兆),也可以是 B K M GITERATIONS 测试的次数,默认是无限申请 10M 内存:

对内存进行压力测试,申请大内存,放入后台无限测试:
nohup memtester 2G > /tmp/memtest.log &9、消耗CPU脚本
让CPU使用率达到100%
方法一:
for i in `seq 1 $(cat /proc/cpuinfo |grep "physical id" |wc -l)`; do dd if=/dev/zero of=/dev/null & done说明:
cat /proc/cpuinfo |grep "physical id" | wc -l 可以获得CPU的个数, 我们将其表示为N;
seq 1 N 用来生成1到N之间的数字;
for i in `seq 1 N`; 就是循环执行命令,从1到N;
dd if=/dev/zero of=/dev/null 执行dd命令, 输出到/dev/null, 实际上只占用CPU,没有IO操作;
由于连续执行N个(N是CPU个数)的dd 命令,且使用率为100%,这时调度器会调度每个dd命令在不同的CPU上处理;
最终就实现所有CPU占用率100%。
另外,上述程序的结束可以使用:
1. fg 后按 ctrl + C (因为该命令是放在后台执行)
2. pkill -9 dd
3. kill -9 <Top最高的那个名字为dd的进程>
脚本方式运行:
vim killCPU.sh#/bin/bashfor i in `seq 1 $(cat /proc/cpuinfo |grep "physical id" |wc -l)`; do dd if=/dev/zero of=/dev/null & donevim highCPU.sh#/bin/bashwhile true; do sh killCPU.sh $1 ; sleep 2; done可以使用top命令查看效果,预计效果如下所示:
top - 18:19:48 up 14 days, 3:48, 3 users, load average: 0.31, 0.43, 0.46Tasks: 121 total, 3 running, 118 sleeping, 0 stopped, 0 zombie%Cpu(s): 21.5 us, 78.1 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.3 si, 0.0 stKiB Mem : 1883884 total, 129612 free, 1266472 used, 487800 buff/cacheKiB Swap: 2097148 total, 2064212 free, 32936 used. 420084 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND17133 root 20 0 107948 612 516 R 99.0 0.0 0:08.38 dd 1806 cpic 20 0 4022952 1.125g 12148 S 1.0 62.6 148:11.10 java 401 root 20 0 0 0 0 S 0.3 0.0 6:07.16 xfsaild/dm-0 1 root 20 0 129124 4196 2180 S 0.0 0.2 0:20.00 systemd方法二:
Super PI是利用CPU的浮点运算能力来计算出π(圆周率),所以目前普遍被超频玩家用做测试系统稳定性和测试CPU计算完后特定位数圆周率所需的时间。
官方网站:The domain name super-computing.org is for sale
wget ftp://pi.super-computing.org/Linux/super_pi.tar.gztar -xzvf super_pi.tar.gz./super_pi 2020为位数。表示要算2的多少次方位,如通常要算小数点后1M位。
通过bc命令计算特别函数:
cat a.shwhile :doecho 2^2^20|bc &>/dev/nulldoneecho "scale=5000; 4*a(1)" | bc -l -q函数说明:
s (x) The sine of x, x is in radians. 正玄函数 c (x) The cosine of x, x is in radians. 余玄函数 a (x) The arctangent of x, arctangent returns radians. 反正切函数 l (x) The natural logarithm of x. log函数(以2为底) e (x) The exponential function of raising e to the value x. e的指数函数 j (n,x) The bessel function of integer order n of x. 贝塞尔函数 方法三:
使用死循环消耗CPU资源,如果服务器是有多颗CPU,可以选择消耗多少颗CPU的资源:
vim eatcpu.sh#! /bin/sh # filename killcpu.sh if [ $# != 1 ] ; then echo "USAGE: $0 <CPUs>" exit 1; fifor i in `seq $1` do echo -ne " i=0; while true do i=i+1; done" | /bin/sh & pid_array[$i]=$! ; donetime=$(date "+%Y-%m-%d %H:%M:%S")echo "${time}"for i in "${pid_array[@]}"; do echo 'kill ' $i ';'; donesleep 60for i in "${pid_array[@]}"; do kill $i;done 消耗3颗cpu,持续60s(可自己设置):
./eatcpu.sh 3kill 30104 ;kill 30106 ;kill 30108 ;[root@test02 ~]# top top - 15:27:31 up 264 days, 23:39, 4 users, load average: 0.86, 0.25, 0.19Tasks: 185 total, 5 running, 180 sleeping, 0 stopped, 0 zombieCpu0 : 100.0% us, 0.0% sy, 0.0% ni, 0.0% id, 0.0% wa, 0.0% hi, 0.0% siCpu1 : 0.0% us, 0.0% sy, 0.0% ni, 100.0% id, 0.0% wa, 0.0% hi, 0.0% siCpu2 : 100.0% us, 0.0% sy, 0.0% ni, 0.0% id, 0.0% wa, 0.0% hi, 0.0% siCpu3 : 100.0% us, 0.0% sy, 0.0% ni, 0.0% id, 0.0% wa, 0.0% hi, 0.0% siMem: 8165004k total, 8095880k used, 69124k free, 53672k buffersSwap: 2031608k total, 103548k used, 1928060k free, 6801364k cached使用方法很简单,参数3表示消耗3颗CPU的资源,运行后,会有一堆 kill 命令,方便 kill 进程。
交互式脚本改进:
#! /bin/sh # filename killcpu.shif [ $# != 1 ] ; then echo "USAGE: $0 <CPUs>" exit 1;fifor i in `seq $1`do echo -ne " i=0; while truedoi=i+1; done" | /bin/sh & pid_array[$i]=$! ;done for i in "${pid_array[@]}"; do echo 'kill ' $i ';';done10、消耗内存脚本
方法一:
占用1GB内存1个小时. 注意需要可以mount的权限:
#!/bin/bashmkdir /tmp/memorymount -t tmpfs -o size=1024M tmpfs /tmp/memorydd if=/dev/zero of=/tmp/memory/blocksleep 3600rm /tmp/memory/blockumount /tmp/memoryrmdir /tmp/memory方法二:
备份大数据:
#!/bin/bash################################################################# mem used script# eg. ./mem.sh 60G & to start testing# eg. ./mem.sh stop to stop testing and clear env# update: 2019-1-22 pansaky################################################################num=$1user=`root` start(){if [ -d /tmp/memory ];then echo "the dir "/tmp/memory" is already exist!, use it." >> mem.logelse sudo mkdir /tmp/memory mount -t tmpfs -o size=$num tmpfs /tmp/memoryfidd if=/dev/zero of=/tmp/memory/block >> mem.log 2>&1} stop(){ rm -rf /tmp/memory/blockumount /tmp/memoryrmdir /tmp/memoryif [ -d /tmp/memory ];then echo "Do not remove the dir \"/tmp/memory\", please check "else echo "clear env is done!"fi}main(){if [ $num == 'stop' ];then stopelif [ $user != "root" ];then echo "please use the \"root\" excute script!" exit 1else startfi} if [ $# = 2 -o $# = 1 ];then mainelse echo 'Usage: <./mem.sh 60G &> to start or <./mem.sh stop> to clear env'fi说明:
1: mkdir -p创建多级目录2: mount -t tmpfs -o sizet 表示类型,也就是挂载文件系统的类型,表面你是挂载tmpfs文件系统;O 表示选项: 选项里的size=10240M表示10G.挂载10G到/tmp/skyfans/memory3: dd if=/dev/zero of=/tmp/memory/block表示将/dev/zero 全盘数据备份到指定路径的block文件dd:用指定大小的块拷贝一个文件,并在拷贝的同时进行指定的转换。注意:指定数字的地方若以下列字符结尾,则乘以相应的数字:b=512;c=1;k=1024;w=2if=文件名,输入文件名,缺省为标准输入。即指定源文件。< if=input file >of=文件名:输出文件名,缺省为标准输出。即指定目的文件。< of=output file >4:umount /tmp/memory卸载挂载点5:rmdir /tmp/memory删除多级目录脚本执行:
./mem_test.sh 3G &内存测试,每间隔10秒采集一次,共计采集10次:
方法三:
c脚本消耗内存
1)在your_directory目录下,创建文件eatmem.c ,输入以下内容:
#include <unistd.h>#include <errno.h>#include <stdlib.h>#include <stdio.h>#include <string.h> // Destription : release memory// 1.parameters# gcc test_eatMem.c -o test_eatMem// 2.parameters# ./test_eatMem// Date : 2015-1-12 #define block 4 // eat times 4 block=1Gvoid eatMem(){ int i =0; int j = 0; int cell = 256 * 1024 * 1024; //256M char * pMem[block]={0}; // init all pointer to NULL. for(i = 0; i < block; i++) { pMem[i] = (char*)malloc(cell); // eat... if(NULL == pMem[i]) // failed to eat. { printf("Insufficient memory avalible ,Cell %d Failure\n", i); break; } memset(pMem[i], 0, cell); printf("[%d]%d Bytes.\n", i, cell); fflush(stdout); sleep(1); } //Read&Write 10 次,维持内存消耗的时间 可自己设置 int nTimes = 0; for(nTimes = 0; nTimes < 10; nTimes++) { for(i=0; i<block; i++) { printf("Read&Write [%d] cell.\n", i); if(NULL == pMem[i]) { continue; } char ch=0; int j=0; for(j=0; j<cell; j+=1024) { ch = pMem[i][j]; pMem[i][j] = 'a'; } memset(pMem[i], 0, cell); fflush(stdout); sleep(5); } sleep(5); } printf("Done! Start to release memory.\n"); //释放内存核心代码: for(i = 0; i < block; i++) { printf("free[%d]\n", i); if(NULL != pMem[i]) { free(pMem[i]); pMem[i] = NULL; } fflush(stdout); sleep(2); } printf("Operation successfully!\n"); fflush(stdout); } int main(int argc,char * args[]){ eatMem();}2)编译:
gcc eatmem.c -o eatmem3) 创建定时任务,每15分钟执行:crontab -e 输入:
*/15 * * * * /your_directory/eatmem >> /your_directory/memcron.log#include <stdlib.h>#include <stdio.h>#include <unistd.h>#define UNIT (1024*1024) int main(int argc, char *argv[]){ long long i = 0; int size = 0; if (argc != 2) { printf(" === argc must 2\n"); return 1; } size = strtoull(argv[1], NULL, 10); if (size == 0) { printf(" argv[1]=%s not good\n", argv[1]); return 1; } char *buff = (char *) malloc(size * UNIT); if (buff) printf(" we malloced %d Mb\n", size); buff[0] = 1; for (i = 1; i < (size * UNIT); i++) { if (i%1024 == 0) buff[i] = buff[i-1]/8; else buff[i] = i/2; } pause();}使用:gcc mem.c -o mem.out 后使用./mem.out 100 & 消耗对应数字MB单位的内存,释放时杀掉对应进程即可。
11、编程实现cpu、内存、硬盘、jvm使用率动态获取
1)C语言实现
通过程序将cpu使用率、内存使用情况保存到文件中:
// test.cpp#include <stdio.h>#include <unistd.h>#include <stdlib.h>int main(){system("top -n 1 |grep Cpu | cut -d \",\" -f 1 | cut -d \":\" -f 2 >cpu.txt");system("top -n 1 |grep Cpu | cut -d \",\" -f 2 >>cpu.txt");system("top -n 1 |grep Mem | cut -d \",\" -f 1 | cut -d \":\" -f 2 >>cpu.txt");system("top -n 1 |grep Mem | cut -d \",\" -f 2 >>cpu.txt");return 0;}编译、运行:
[root@localhost study]# g++ test.cpp[root@localhost study]# ./a.out[root@localhost study]# cat cpu.txt2.1%us1.5%sy2066240k total1619784k used脚本说明:
[root@localhost utx86]# top -n 1top - 14:23:20 up 5:14, 14 users, load average: 0.00, 0.04, 0.01Tasks: 183 total, 1 running, 181 sleeping, 1 stopped, 0 zombieCpu(s): 1.8%us, 1.4%sy, 0.0%ni, 95.8%id, 0.7%wa, 0.1%hi, 0.2%si, 0.0%stMem: 2066240k total, 1507316k used, 558924k free, 190472k buffersSwap: 2031608k total, 88k used, 2031520k free, 1087184k cached1、获取cpu占用情况[root@localhost utx86]# top -n 1 |grep CpuCpu(s): 1.9%us, 1.3%sy, 0.0%ni, 95.9%id, 0.6%wa, 0.1%hi, 0.2%si, 0.0%st解释:1.9%us是用户占用cpu情况1.3%sy,是系统占用cpu情况得到具体列的值:[root@localhost utx86]# top -n 1 |grep Cpu | cut -d "," -f 1 | cut -d ":" -f 21.9%us[root@localhost utx86]# top -n 1 |grep Cpu | cut -d "," -f 21.3%sy2、获得内存占用情况[root@localhost utx86]# top -n 1 |grep MemMem: 2066240k total, 1515784k used, 550456k free, 195336k buffers获得内存情况指定列:[root@localhost c++_zp]# top -n 1 |grep Mem | cut -d "," -f 1 | cut -d ":" -f 22066240k total[root@localhost c++_zp]# top -n 1 |grep Mem | cut -d "," -f 21585676k used使用ps查看进程的资源占用:
ps -aux查看进程信息时,第三列就是CPU占用。[root@localhost utx86]# ps -aux | grep my_processWarning: bad syntax, perhaps a bogus '-'? See /usr/share/doc/procps-3.2.7/FAQroot 14415 3.4 0.9 37436 20328 pts/12 SL+ 14:18 0:05 ./my_processroot 14464 0.0 0.0 3852 572 pts/3 S+ 14:20 0:00 grep my_process每一列含义如下USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND即my_process进程当前占用cpu 3.4%, 内存0.9%2)Java实现
linux下cpu 内存 磁盘 jvm的使用监控:
import java.io.*; public class TT { /*** 获取cpu使用情况* @return* @throws Exception*/public double getCpuUsage() throws Exception { double cpuUsed = 0; Runtime rt = Runtime.getRuntime(); Process p = rt.exec("top -b -n 1");// 调用系统的“top"命令 BufferedReader in = null; try { in = new BufferedReader(new InputStreamReader(p.getInputStream())); String str = null; String[] strArray = null; while ((str = in.readLine()) != null) { int m = 0; if (str.indexOf(" R ") != -1) {// 只分析正在运行的进程,top进程本身除外 && strArray = str.split(" "); for (String tmp : strArray) { if (tmp.trim().length() == 0) continue; if (++m == 9) { // 第9列为CPU的使用百分比(RedHat cpuUsed += Double.parseDouble(tmp); } } } } } catch (Exception e) { e.printStackTrace(); } finally { in.close(); } return cpuUsed; } /*** 内存监控* @return* @throws Exception*/public double getMemUsage() throws Exception { double menUsed = 0; Runtime rt = Runtime.getRuntime(); Process p = rt.exec("top -b -n 1");// 调用系统的“top"命令 BufferedReader in = null; try { in = new BufferedReader(new InputStreamReader(p.getInputStream())); String str = null; String[] strArray = null; while ((str = in.readLine()) != null) { int m = 0; if (str.indexOf(" R ") != -1) {// 只分析正在运行的进程,top进程本身除外 && // // System.out.println("------------------3-----------------"); strArray = str.split(" "); for (String tmp : strArray) { if (tmp.trim().length() == 0) continue; if (++m == 10) { //第10列为mem的使用百分比(RedHat 9) menUsed += Double.parseDouble(tmp); } } } } } catch (Exception e) { e.printStackTrace(); } finally { in.close(); } return menUsed; } /*** 获取磁盘空间大小* * @return* @throws Exception*/public double getDeskUsage() throws Exception { double totalHD = 0; double usedHD = 0; Runtime rt = Runtime.getRuntime(); Process p = rt.exec("df -hl");//df -hl 查看硬盘空间 BufferedReader in = null; try { in = new BufferedReader(new InputStreamReader(p.getInputStream())); String str = null; String[] strArray = null; int flag = 0; while ((str = in.readLine()) != null) { int m = 0; //if (flag > 0) { //flag++; strArray = str.split(" "); for (String tmp : strArray) { if (tmp.trim().length() == 0) continue; ++m; //System.out.println("----tmp----" + tmp); if (tmp.indexOf("G") != -1) { if (m == 2) { //System.out.println("---G----" + tmp); if (!tmp.equals("") && !tmp.equals("0")) totalHD += Double.parseDouble(tmp.substring(0, tmp.length() - 1)) * 1024; } if (m == 3) { //System.out.println("---G----" + tmp); if (!tmp.equals("none") && !tmp.equals("0")) usedHD += Double.parseDouble(tmp.substring(0, tmp.length() - 1)) * 1024; } } if (tmp.indexOf("M") != -1) { if (m == 2) { // System.out.println("---M---" + tmp); if (!tmp.equals("") && !tmp.equals("0")) totalHD += Double.parseDouble(tmp.substring(0, tmp.length() - 1)); } if (m == 3) { //System.out.println("---M---" + tmp); if (!tmp.equals("none") && !tmp.equals("0")) usedHD += Double.parseDouble(tmp.substring( 0, tmp.length() - 1)); // System.out.println("----3----" + usedHD); } } } // } } } catch (Exception e) { e.printStackTrace(); } finally { in.close(); } return (usedHD / totalHD) * 100; } public static void main(String[] args) throws Exception { TT cpu = new TT(); System.out.println("---------------cpu used:" + cpu.getCpuUsage() + "%"); System.out.println("---------------mem used:" + cpu.getMemUsage() + "%"); System.out.println("---------------HD used:" + cpu.getDeskUsage() + "%"); System.out.println("------------jvm监控----------------------"); Runtime lRuntime = Runtime.getRuntime(); System.out.println("--------------Free Momery:" + lRuntime.freeMemory()+"K"); System.out.println("--------------Max Momery:" + lRuntime.maxMemory()+"K"); System.out.println("--------------Total Momery:" + lRuntime.totalMemory()+"K"); System.out.println("---------------Available Processors :"+ lRuntime.availableProcessors()); } }3)shell实现
监视磁盘hda1:
#!/bin/sh# disk_mon# monitor the disk space# get percent column and strip off header row from dfLOOK_OUT=0until [ "$LOOK_OUT" -gt "90" ]do LOOK_OUT=`df | grep /hda1 | awk '{print $5}' | sed 's/%//g'` echo $LOOK_OUT% sleep 1doneecho "Disk hda1 is nearly full!"监视CPU:
vim GetCPU.sh#!/bin/shwhile truedoawk '$1=="cpu"{Total=$2+$3+$4+$5+$6+$7;print "Free: " $5/Total*100"%" " Used: " (Total-$5)*100/Total"%"}' </proc/statsleep 1done./GetCPU.shFree: 99.4532% Used: 0.546814%Free: 99.4532% Used: 0.546813%Free: 99.4532% Used: 0.546813%Free: 99.4532% Used: 0.546813%#!/bin/shawk '$0 ~/cpu[0-9]/' /proc/stat | while read linedoecho "$line" | awk '{total=$2+$3+$4+$5+$6+$7+$8;free=$5;\ print$1" Free "free/total*100"%",\ "Used " (total-free)/total*100"%"}'donechmod +x cpu.sh#./cpu.shcpu0 Free 99.7804% Used 0.219622%cpu1 Free 99.8515% Used 0.148521%cpu2 Free 99.6632% Used 0.336765%cpu3 Free 99.6241% Used 0.375855%监视网络流量情况:
#!/bin/shecho "name ByteRec PackRec ByteTran PackTran"awk ' NR>2' /proc/net/dev | while read linedoecho "$line" | awk -F ':' '{print " "$1" " $2}' |\ awk '{print $1" "$2 " "$3" "$10" "$11}'done./if.shname ByteRec PackRec ByteTran PackTranlo 2386061 17568 2386061 17568eth0 1159936483 150753251 190980687 991835eth1 0 0 0 0sit0 0 0 0 0监视内存:
cat /proc/meminfo | grep "MemTotal"cat /rpco/meninfo | grep "MemFree"主机端口扫描:
#!/bin/shusage(){echo "usage: $0 tcp/udp/all"}tcp(){if test -f "temp" then rm -f "temp"fiawk -F ':' 'NR != 1 {print $2$3$4$5$6}' /proc/net/tcp > tempcat temp | while read sipdo #echo "$sip" echo "$sip"| awk '{print substr($sip,7,2)"."substr($sip,5,2)"."\ substr($sip,3,2)"."substr($sip, 1,2)":"substr($sip,9,4)"=>"\ substr($sip,20,2)"."substr($sip,18,2)"."substr($sip,16,2)"."\ substr($sip,14,2)":"substr($sip,22,4)" status: " substr($sip, 27,2)}'donerm -f "temp"if test -f "/proc/net/tcp6"then awk -F ':' 'NR != 1 {print $2$3$4$5$6}' /proc/net/tcp6 > temp cat temp | while read sip do echo "$sip"| awk '{print substr($sip,29,4)"."substr($sip,25,4)"."\ substr($sip,21,2)"."substr($sip,17,4)":"substr($sip,13,4)"."\ substr($sip,9,4)"."substr($sip,5,4)"."substr($sip,1,4)":"\ substr($sip,33,4)"=>"\ substr($sip,66,4)"."substr($sip,62,4)"."\ substr($sip,58,4)"."substr($sip,54,4)":"substr($sip,50,4)"."\ substr($sip,46,4)"."substr($sip,42,4)"."substr($sip,38,4)\ ":"substr($sip,70,4)" status: "substr($sip,75,2)}' donefi}udp(){ if test -f "temp" then rm -f "temp"fiawk -F ':' 'NR != 1 {print $2$3$4$5$6}' /proc/net/udp > tempcat temp | while read sipdo echo "$sip"| awk '{print substr($sip,7,2)"."substr($sip,5,2)"."\ substr($sip,3,2)"."substr($sip, 1,2)":"substr($sip,9,4)"=>*.*"}'donerm -f "temp"if test -f "/proc/net/udp6"then awk -F ':' 'NR != 1 {print $2$3$4$5$6}' /proc/net/udp6 > temp cat temp | while read sip do echo "$sip"| awk '{print substr($sip,29,4)"."substr($sip,25,4)"."\ substr($sip,21,2)"."substr($sip,17,4)":"substr($sip,13,4)"."\ substr($sip,9,4)"."substr($sip,5,4)"."substr($sip,1,4)":"\ substr($sip,33,4)"=>*.*"}' donefi}if [ $# -ne 1 ]then usageexit 0elsecase "$1" in tcp) tcp ;;udp) udp;;all) tcp udp ;;*)usage ;;esacexit 0fi12、Netdata
Netdata 是一款 Linux 性能实时监测工具.。以web的可视化方式展示系统及应用程序的实时运行状态(包括cpu、内存、硬盘输入/输出、网络等linux性能的数据)。
Netdata文档地址:GitHub - netdata/netdata: Real-time performance monitoring, done right! https://www.netdata.cloud

13、sar
在使用 Linux系统时,常常会遇到各种各样的问题,比如系统容易死机或者运行速度突然变慢,这时我们常常猜测:是否硬盘空间不足,是否内存不足,是否 I/O出现瓶颈,还是系统的核心参数出了问题?这时,我们应该考虑使用 sar工具对系统做一个全面了解,分析系统的负载状况。
sar(System ActivityReporter)是系统活动情况报告的缩写。sar工具将对系统当前的状态进行取样,然后通过计算数据和比例来表达系统的当前运行状态。它的特点是可以连续对系统取样,获得大量的取样数据;取样数据和分析的结果都可以存入文件,所需的负载很小。 sar是目前 Linux上最为全面的系统性能分析工具之一,可以从多方面对系统的活动进行报告,包括:文件的读写情况、系统调用的使用情况、磁盘I/O、CPU效率、内存使用状况、进程活动及IPC有关的活动等。为了提供不同的信息,sar提供了丰富的选项、因此使用较为复杂。
语法:
# sar -helpUsage: sar [ options ] [ <interval> [ <count> ] ]Options are:[ -A ] [ -b ] [ -B ] [ -C ] [ -d ] [ -h ] [ -m ] [ -p ] [ -q ] [ -r ] [ -R ][ -S ] [ -t ] [ -u [ ALL ] ] [ -v ] [ -V ] [ -w ] [ -W ] [ -y ][ -I { <int> [,...] | SUM | ALL | XALL } ] [ -P { <cpu> [,...] | ALL } ][ -n { <keyword> [,...] | ALL } ][ -o [ <filename> ] | -f [ <filename> ] ][ -i <interval> ] [ -s [ <hh:mm:ss> ] ] [ -e [ <hh:mm:ss> ] ]其中:
interval :为取样时间间隔count :为输出次数,若省略此项,默认值为 1参数:
| -A | 等价于 -bBcdqrRuvwWy -I SUM -I XALL -n ALL -P ALL |
| -b | 显示I/O和传送速率的统计信息 |
| -B | 输出内存页面的统计信息 |
| -c | 输出进程统计信息,每秒创建的进程数 |
| -d | 输出每一个块设备的活动信息 |
| -i interval | 指定间隔时长,单位为秒 |
| -p | 显示友好设备名字,以方便查看,也可以和-d和-n参数结合使用,比如 -dp或-np |
| -q | 输出进程队列长度和平均负载状态统计信息 |
| -r | 输出内存和交换空间的统计信息 |
| -R | 输出内存页面的统计信息 |
| -t | 读取 /var/log/sa/saDD的数据时显示其中记录的原始时间,如果没有这个参数使用用户的本地时间 |
| -u | 输出CPU使用情况的统计信息 |
| -v | 输出inode、文件和其他内核表的统计信息 |
| -V | 输出版本号信息 |
| -w | 输出系统交换活动信息 |
| -W | 输出系统交换的统计信息 |
| -y | 输出TTY设备的活动信息 |
| -n {DEV|EDEV|NFS|NFSD|SOCK|ALL} | 分析输出网络设备状态统计信息。 |
| DEV | 报告网络设备的统计信息 |
| EDEV | 报告网络设备的错误统计信息 |
| NFS | 报告 NFS客户端的活动统计信息 |
| NFSD | 报告 NFS服务器的活动统计信息 |
| SOCK | 报告网络套接字(sockets)的使用统计信息 |
| ALL | 报告所有类型的网络活动统计信息 |
| -x {pid|SELF|ALL} | 输出指定进程的统计信息。 |
| pid | 用 pid指定特定的进程 |
| SELF | 表示 sar自身 |
| ALL | 表示所有进程 |
| -X {pid|SELF|ALL} | 输出指定进程的子进程的统计信息 |
| -I {irq|SUM|ALL|XALL} | 输出指定中断的统计信息。 |
| irq | 指定中断号 |
| SUM | 指定输出每秒接收到的中断总数 |
| ALL | 指定输出前16个中断 |
| XALL | 指定输出全部的中断信息 |
| -P {cpu|ALL} | 输出指定 CPU的统计信息 |
| -o filename | 将输出信息保存到文件 filename |
| -f filename | 从文件 filename读取数据信息。filename是使用-o选项时生成的文件。 |
| -s hh:mm:ss | 指定输出统计数据的起始时间 |
| -e hh:mm:ss | 指定输出统计数据的截至时间,默认为18:00:00 |
1. CPU资源监控(-u,或-P ALL)
每10秒采样一次,连续采样3次,观察CPU 的使用情况,并将采样结果以二进制形式存入当前目录下的文件test中,需键入如下命令:
sar -u -o test 10 317:06:16 CPU %user %nice %system %iowait %steal %idle17:06:26 all 0.00 0.00 0.20 0.00 0.00 99.8017:06:36 all 0.00 0.00 0.20 0.00 0.00 99.8017:06:46 all 0.00 0.00 0.10 0.00 0.00 99.90Average: all 0.00 0.00 0.17 0.00 0.00 99.83输出项说明:
CPU:all 表示统计信息为所有 CPU 的平均值。%user:显示在用户级别(application)运行使用 CPU 总时间的百分比。%nice:显示在用户级别,用于nice操作,所占用 CPU 总时间的百分比。%system:在核心级别(kernel)运行所使用 CPU 总时间的百分比。%iowait:显示用于等待I/O操作占用 CPU 总时间的百分比。%steal:管理程序(hypervisor)为另一个虚拟进程提供服务而等待虚拟 CPU 的百分比。%idle:显示 CPU 空闲时间占用 CPU 总时间的百分比。1. 若 %iowait 的值过高,表示硬盘存在I/O瓶颈2. 若 %idle 的值高但系统响应慢时,有可能是 CPU 等待分配内存,此时应加大内存容量3. 若 %idle 的值持续低于1,则系统的 CPU 处理能力相对较低,表明系统中最需要解决的资源是 CPU 。如果要查看二进制文件test中的内容,需键入如下sar命令:
sar -u -f test2. inode、文件和其他内核表监控(-v)
每10秒采样一次,连续采样3次,观察核心表的状态,需键入如下命令:
sar -v 10 317:10:49 dentunusd file-nr inode-nr pty-nr17:10:59 6301 5664 12037 417:11:09 6301 5664 12037 417:11:19 6301 5664 12037 4Average: 6301 5664 12037 4输出项说明:
dentunusd:目录高速缓存中未被使用的条目数量file-nr:文件句柄(file handle)的使用数量inode-nr:索引节点句柄(inode handle)的使用数量pty-nr:使用的pty数量3. 内存和交换空间监控(-r)
每10秒采样一次,连续采样3次,监控内存和交换空间监控:
sar -r 10 3
输出项说明:
kbmemfree:这个值和free命令中的free值基本一致,所以它不包括buffer和cache的空间.kbmemused:这个值和free命令中的used值基本一致,所以它包括buffer和cache的空间.%memused:这个值是kbmemused和内存总量(不包括swap)的一个百分比.kbbuffers和kbcached:这两个值就是free命令中的buffer和cache.kbcommit:保证当前系统所需要的内存,即为了确保不溢出而需要的内存(RAM+swap).%commit:这个值是kbcommit与内存总量(包括swap)的一个百分比.4. 内存分页监控
每10秒采样一次,连续采样3次,监控内存分页:
sar -B 10 3输出项说明:
pgpgin/s:表示每秒从磁盘或SWAP置换到内存的字节数(KB)pgpgout/s:表示每秒从内存置换到磁盘或SWAP的字节数(KB)fault/s:每秒钟系统产生的缺页数,即主缺页与次缺页之和(major + minor)majflt/s:每秒钟产生的主缺页数.pgfree/s:每秒被放入空闲队列中的页个数pgscank/s:每秒被kswapd扫描的页个数pgscand/s:每秒直接被扫描的页个数pgsteal/s:每秒钟从cache中被清除来满足内存需要的页个数%vmeff:每秒清除的页(pgsteal)占总扫描页(pgscank+pgscand)的百分比5. I/O和传送速率监控(-b)
每10秒采样一次,连续采样3次,报告缓冲区的使用情况,需键入如下命令:
sar -b 10 318:51:05 tps rtps wtps bread/s bwrtn/s18:51:15 0.00 0.00 0.00 0.00 0.0018:51:25 1.92 0.00 1.92 0.00 22.6518:51:35 0.00 0.00 0.00 0.00 0.00Average: 0.64 0.00 0.64 0.00 7.59输出项说明:
tps:每秒钟物理设备的 I/O 传输总量rtps:每秒钟从物理设备读入的数据总量wtps:每秒钟向物理设备写入的数据总量bread/s:每秒钟从物理设备读入的数据量,单位为 块/sbwrtn/s:每秒钟向物理设备写入的数据量,单位为 块/s6. 进程队列长度和平均负载状态监控
每10秒采样一次,连续采样3次,监控进程队列长度和平均负载状态:
sar -q 10 319:25:50 runq-sz plist-sz ldavg-1 ldavg-5 ldavg-1519:26:00 0 259 0.00 0.00 0.0019:26:10 0 259 0.00 0.00 0.0019:26:20 0 259 0.00 0.00 0.00Average: 0 259 0.00 0.00 0.00输出项说明:
runq-sz:运行队列的长度(等待运行的进程数)plist-sz:进程列表中进程(processes)和线程(threads)的数量ldavg-1:最后1分钟的系统平均负载(System load average)ldavg-5:过去5分钟的系统平均负载ldavg-15:过去15分钟的系统平均负载7. 系统交换活动信息监控
每10秒采样一次,连续采样3次,监控系统交换活动信息:
sar -W 10 319:39:50 pswpin/s pswpout/s19:40:00 0.00 0.0019:40:10 0.00 0.0019:40:20 0.00 0.00Average: 0.00 0.00输出项说明:
pswpin/s:每秒系统换入的交换页面(swap page)数量pswpout/s:每秒系统换出的交换页面(swap page)数量8. 设备使用情况监控(-d)
每10秒采样一次,连续采样3次,报告设备使用情况,需键入如下命令:
sar -d 10 3 –p17:45:54 DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util17:46:04 scd0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.0017:46:04 sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.0017:46:04 vg_livedvd-lv_root 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.0017:46:04 vg_livedvd-lv_swap 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00输出项说明:
参数-p可以打印出sda,hdc等磁盘设备名称,如果不用参数-p,设备节点则有可能是dev8-0,dev22-0tps:每秒从物理磁盘I/O的次数.多个逻辑请求会被合并为一个I/O磁盘请求,一次传输的大小是不确定的.rd_sec/s:每秒读扇区的次数.wr_sec/s:每秒写扇区的次数.avgrq-sz:平均每次设备I/O操作的数据大小(扇区).avgqu-sz:磁盘请求队列的平均长度.await:从请求磁盘操作到系统完成处理,每次请求的平均消耗时间,包括请求队列等待时间,单位是毫秒(1秒=1000毫秒).svctm:系统处理每次请求的平均时间,不包括在请求队列中消耗的时间.%util:I/O请求占CPU的百分比,比率越大,说明越饱和.1. avgqu-sz 的值较低时,设备的利用率较高。2. 当%util的值接近 1% 时,表示设备带宽已经占满。9. 网络统计(-n)
使用-n选项可以对网络使用情况进行显示,-n后接关键词”DEV”可显示eth0、eth1等网卡的信息:
sar -n DEV 1 1Linux 2.6.32-358.el6.x86_64 (host_linux)01/17/2018 _x86_64_(2 CPU)01:39:36 PM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s01:39:37 PM lo 0.00 0.00 0.00 0.00 0.00 0.00 0.0001:39:37 PM eth0 23.23 1.01 1.55 0.10 0.00 0.00 0.00Average: IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/sAverage: lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00Average: eth0 23.23 1.01 1.55 0.10 0.00 0.00 0.00显示lo、eth0、eth1等信息:
sar -n DEV 1 2输出项说明:
IFACE:就是网络设备的名称; rxpck/s:每秒钟接收到的包数目 txpck/s:每秒钟发送出去的包数目 rxbyt/s:每秒钟接收到的字节数 txbyt/s:每秒钟发送出去的字节数 rxcmp/s:每秒钟接收到的压缩包数目 txcmp/s:每秒钟发送出去的压缩包数目 txmcst/s:每秒钟接收到的多播包的包数目针对网络设备回报其失败情况 :
sar -n EDEV 1 3输出项说明:
rxerr/s:每秒钟接收到的损坏的包的数目 txerr/s:当发送包时,每秒钟发生的错误数 coll/s:当发送包时,每秒钟发生的冲撞(collisions)数(这个是在半双工模式下才有) rxdrop/s:由于缓冲区满,网络设备接收端,每秒钟丢掉的网络包的数目 txdrop/s:由于缓冲区满,网络设备发送端,每秒钟丢掉的网络包的数目 txcarr/s:当发送数据包时,每秒钟载波错误发生的次数 rxfram/s:在接收数据包时,每秒钟发生的帧对齐错误的次数 rxfifo/s:在接收数据包时,每秒钟缓冲区溢出错误发生的次数 txfifo/s:在发送数据包时,每秒钟缓冲区溢出错误发生的次数针对socket连接进行汇报:
sar -n SOCK 1 3 输出项说明:
totsck:被使用的socket的总数目 tcpsck:当前正在被使用于TCP的socket数目 udpsck:当前正在被使用于UDP的socket数目 rawsck:当前正在被使用于RAW的socket数目 ip-frag:当前的IP分片的数目上述DEV、EDEV和SOCK三者的综合:
sar -n FULL 1 310. sar日志保存(-o)
使用-o选项,我们可以把sar统计信息保存到一个指定的文件,对于保存的日志,我们可以使用-f选项读取:
linux:~ # sar -n DEV 1 10 -o sar.out linux:~ # sar -d 1 10 -f sar.out 相比将结果重定向到一个文件,使用-o选项,可以保存更多的系统资源信息。
11. sar监控非实时数据
我们想查看本月27日,从0点到23点的内存资源:
sar -f /var/log/sa/sa27 -s 00:00:00 -e 23:00:00 -rsar也可以监控非实时数据,通过cron周期的运行到指定目录下。
sa27就是本月27日,指定具体的时间可以通过-s(start)和-e(end)来指定.
14、Collectl
Linux 系统管理员可以找到有很多工具来帮助自己监控和显示系统中的进程,例如 top 和 htop ,但是这些工具都不能与collectl相媲美。
collectl是一款非常优秀并且有着丰富的命令行功能的实用程序,你可以用它来采集描述当前系统状态的性能数据。不同于大多数其它的系统监控工具,collectl 并非仅局限于有限的系统度量,相反,它可以收集许多不同类型系统资源的相关信息,如 cpu 、disk、memory 、network 、sockets 、 tcp 、inodes 、infiniband 、 lustre 、memory、nfs、processes、quadrics、slabs和buddyinfo等。
使用 collectl 的另一个好处就是它可以替代那些特定用途的工具如: top、ps、iotop、vmstat等等其它工具。
参数:
b – buddy info (内存碎片)c – CPUd – Diskf – NFS V3 Datai – Inode and File Systemj – Interruptsl – Lustrem – Memoryn – Networkss – Socketst – TCPx – Interconnecty – Slabs (系统对象缓存)不加任何参数执行 collectl 会显示下面子系统的信息:
cpu磁盘网络# collectl waiting for 1 second sample...##cpu sys inter ctxsw KBRead Reads KBWrit Writes KBIn PktIn KBOut PktOut 13 5 790 1322 0 0 92 7 4 13 0 5 10 2 719 1186 0 0 0 0 3 9 0 4 12 0 753 1188 0 0 52 3 2 5 0 6 13 2 733 1063 0 0 0 0 1 1 0 1 25 2 834 1375 0 0 0 0 1 1 0 1 28 2 870 1424 0 0 36 7 1 1 0 1 19 3 949 2271 0 0 44 3 1 1 0 1 17 2 809 1384 0 0 0 0 1 6 0 6 16 2 732 1348 0 0 0 0 1 1 0 1 22 4 993 1615 0 0 56 3 1 2 0 3提示:在这里,一个子系统就是每一种可以测量的系统资源。
你也可以显示除slabs以外各个子系统的统计数据,这要结合下面的 -all 选项来实现:
# collectl --all waiting for 1 second sample...##cpu sys inter ctxsw Cpu0 Cpu1 Free Buff Cach Inac Slab Map Fragments KBRead Reads KBWrit Writes KBIn PktIn KBOut PktOut IP Tcp Udp Icmp Tcp Udp Raw Frag Handle Inodes Reads Writes Meta Comm 16 3 817 1542 430 390 1G 175M 1G 683M 193M 1G nsslkjjebbk 0 0 24 3 1 1 0 1 0 0 0 0 623 0 0 0 8160 240829 0 0 0 0 11 1 745 1324 316 426 1G 175M 1G 683M 193M 1G nsslkjjebbk 0 0 0 0 0 3 0 2 0 0 0 0 622 0 0 0 8160 240828 0 0 0 0 15 2 793 1683 371 424 1G 175M 1G 683M 193M 1G ssslkjjebbk 0 0 0 0 1 1 0 1 0 0 0 0 622 0 0 0 8160 240829 0 0 0 0 16 2 872 1875 427 446 1G 175M 1G 683M 193M 1G ssslkjjebbk 0 0 24 3 1 1 0 1 0 0 0 0 622 0 0 0 8160 240828 0 0 0 0 24 2 842 1383 473 368 1G 175M 1G 683M 193M 1G ssslkjjebbk 0 0 168 6 1 1 0 1 0 0 0 0 622 0 0 0 8160 240828 0 0 0 0 27 3 844 1099 478 365 1G 175M 1G 683M 193M 1G nsslkjjebbk 0 0 0 0 1 6 1 9 0 0 0 0 622 0 0 0 8160 240828 0 0 0 0 26 5 823 1238 396 428 1G 175M 1G 683M 193M 1G ssslkjjebbk 0 0 0 0 2 11 3 9 0 0 0 0 622 0 0 0 8160 240828 0 0 0 0 15 1 753 1276 361 391 1G 175M 1G 683M 193M 1G ssslkjjebbk 0 0 40 3 1 2 0 3 0 0 0 0 623 0 0 0 8160 240829 0 0 0 0但是,你如何用它来监控 cpu 的使用情况呢? ‘-s’ 选项可以用来控制哪个子系统的数据需要收集和回放。
例如下面的命令可以用来对cpu使用情况进行一个总结:
# collectl -sc waiting for 1 second sample...##cpu sys inter ctxsw 15 2 749 1155 16 3 772 1445 14 2 793 1247 27 4 887 1292 24 1 796 1258 16 1 743 1113 15 1 743 1179 14 1 706 1078 15 1 764 1268默认选项是“cdn”,它代表cpu、硬盘和网络数据。运行带这个选项的 collectl 命令的输出和“collectl -scn”的输出一样:
# collectl -scdn waiting for 1 second sample...##cpu sys inter ctxsw KBRead Reads KBWrit Writes KBIn PktIn KBOut PktOut 25 4 943 3333 0 0 0 0 1 1 0 2 27 3 825 2910 0 0 0 0 1 1 0 1 27 5 886 2531 0 0 0 0 0 0 0 1 20 4 872 2406 0 0 0 0 1 1 0 1 26 1 854 2091 0 0 20 2 1 1 0 1 39 4 1004 3398 0 0 0 0 2 8 3 6 41 6 955 2464 0 0 40 3 1 2 0 3 25 7 890 1609 0 0 0 0 1 1 0 1 16 2 814 1165 0 0 796 43 2 2 0 2 14 1 779 1383 0 0 48 6 1 1 0 1 11 2 795 1285 0 0 0 0 2 14 1 14采集内存的数据:
# collectl -sm waiting for 1 second sample...##Free Buff Cach Inac Slab Map 1G 177M 1G 684M 193M 1G 1G 177M 1G 684M 193M 1G 1G 177M 1G 684M 193M 1G 1G 177M 1G 684M 193M 1G 1G 177M 1G 684M 193M 1G 1G 177M 1G 684M 193M 1G 1G 177M 1G 684M 193M 1G 1G 177M 1G 684M 193M 1G搜集tcp 的数据:
# collectl -st waiting for 1 second sample...## IP Tcp Udp Icmp 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0将 tcp 的“t”选项和关于 cpu 的“c”选项组合到一起:
# collectl -stc waiting for 1 second sample...##cpu sys inter ctxsw IP Tcp Udp Icmp 23 8 961 3136 0 0 0 0 24 5 916 3662 0 0 0 0 21 8 848 2408 0 0 0 0 30 10 916 2674 0 0 0 0 38 3 826 1752 0 0 0 0 31 3 820 1408 0 0 0 0 15 5 781 1335 0 0 0 0 17 3 802 1314 0 0 0 0 17 3 755 1218 0 0 0 0 14 2 788 1321 0 0 0 0监控硬盘使用情况:
# collectl -sd waiting for 1 second sample...##KBRead Reads KBWrit Writes 0 0 0 0 0 0 0 0 0 0 92 7 0 0 0 0 0 0 36 3 0 0 0 0 0 0 0 0 0 0 100 7 0 0 0 0使用“-sD”选项来采集单个硬盘的数据:
# collectl -sD waiting for 1 second sample... # DISK STATISTICS (/sec)# Pct#Name KBytes Merged IOs Size KBytes Merged IOs Size RWSize QLen Wait SvcTim Utilsda 0 0 0 0 52 11 2 26 26 1 8 8 1sda 0 0 0 0 0 0 0 0 0 0 0 0 0sda 0 0 0 0 24 0 2 12 12 0 0 0 0sda 0 0 0 0 152 0 4 38 38 0 0 0 0sda 0 0 0 0 192 45 3 64 64 1 20 20 5sda 0 0 0 0 204 0 2 102 102 0 0 0 0sda 0 0 0 0 0 0 0 0 0 0 0 0 0sda 0 0 0 0 116 26 3 39 38 1 16 16 4sda 0 0 0 0 0 0 0 0 0 0 0 0 0sda 0 0 0 0 0 0 0 0 0 0 0 0 0sda 0 0 0 0 32 5 3 11 10 1 16 16 4sda 0 0 0 0 0 0 0 0 0 0 0 0 0可以使用其它详细的子系统来采集详细的数据:
C – CPUD – DiskE – Environmental data (fan, power, temp), via ipmitoolF – NFS DataJ – InterruptsL – Lustre OST detail OR client Filesystem detailN – NetworksT – 65 TCP counters only available in plot formatX – InterconnectY – Slabs (system object caches)Z – Processes将 collectl 当作 top 来使用:
# collectl --top # TOP PROCESSES sorted by time (counters are /sec) 13:11:02# PID User PR PPID THRD S VSZ RSS CP SysT UsrT Pct AccuTime RKB WKB MajF MinF Command^COuch!tecmint 20 1 40 R 1G 626M 0 0.01 0.14 15 28:48.24 0 0 0 109 /usr/lib/firefox/firefox 3403 tecmint 20 1 40 R 1G 626M 1 0.00 0.20 20 28:48.44 0 0 0 600 /usr/lib/firefox/firefox 5851 tecmint 20 4666 0 R 17M 13M 0 0.02 0.06 8 00:01.28 0 0 0 0 /usr/bin/perl 1682 root 20 1666 2 R 211M 55M 1 0.02 0.01 3 03:10.24 0 0 0 95 /usr/bin/X 3454 tecmint 20 3403 8 S 216M 45M 1 0.01 0.02 3 01:23.32 0 0 0 0 /usr/lib/firefox/plugin-container 4658 tecmint 20 4657 3 S 207M 17M 1 0.00 0.02 2 00:08.23 0 0 0 142 gnome-terminal 2890 tecmint 20 2571 3 S 340M 68M 0 0.00 0.01 1 01:19.95 0 0 0 0 compiz 3521 tecmint 20 1 24 S 710M 148M 1 0.01 0.00 1 01:47.84 0 0 0 0 skype 1 root 20 0 0 S 3M 2M 0 0.00 0.00 0 00:02.57 0 0 0 0 /sbin/init 2 root 20 0 0 S 0 0 1 0.00 0.00 0 00:00.00 0 0 0 0 kthreadd 3 root 20 2 0 S 0 0 0 0.00 0.00 0 00:00.60 0 0 0 0 ksoftirqd/0 5 root 0 2 0 S 0 0 0 0.00 0.00 0 00:00.00 0 0 0 0 kworker/0:0H 7 root 0 2 0 S 0 0 0 0.00 0.00 0 00:00.00 0 0 0 0 kworker/u:0H 8 root RT 2 0 S 0 0 0 0.00 0.00 0 00:04.42 0 0 0 0 migration/0 9 root 20 2 0 S 0 0 0 0.00 0.00 0 00:00.00 0 0 0 0 rcu_bh 10 root 20 2 0 R 0 0 0 0.00 0.00 0 00:02.22 0 0 0 0 rcu_sched 11 root RT 2 0 S 0 0 0 0.00 0.00 0 00:00.05 0 0 0 0 watchdog/0 12 root RT 2 0 S 0 0 1 0.00 0.00 0 00:00.07 0 0 0 0 watchdog/1 13 root 20 2 0 S 0 0 1 0.00 0.00 0 00:00.73 0 0 0 0 ksoftirqd/1 14 root RT 2 0 S 0 0 1 0.00 0.00 0 00:01.96 0 0 0 0 migration/1 16 root 0 2 0 S 0 0 1 0.00 0.00 0 00:00.00 0 0 0 0 kworker/1:0H 17 root 0 2 0 S 0 0 1 0.00 0.00 0 00:00.00 0 0 0 0 cpuset将 collectl 用作 ps 工具:
# collectl -c1 -sZ -i:1 waiting for 1 second sample... ### RECORD 1 >>> tecmint-vgn-z13gn <<< (1397979716.001) (Sun Apr 20 13:11:56 2014) ### # PROCESS SUMMARY (counters are /sec)# PID User PR PPID THRD S VSZ RSS CP SysT UsrT Pct AccuTime RKB WKB MajF MinF Command 1 root 20 0 0 S 3M 2M 0 0.00 0.00 0 00:02.57 0 0 0 0 /sbin/init 2 root 20 0 0 S 0 0 1 0.00 0.00 0 00:00.00 0 0 0 0 kthreadd 3 root 20 2 0 S 0 0 0 0.00 0.00 0 00:00.60 0 0 0 0 ksoftirqd/0 5 root 0 2 0 S 0 0 0 0.00 0.00 0 00:00.00 0 0 0 0 kworker/0:0H 7 root 0 2 0 S 0 0 0 0.00 0.00 0 00:00.00 0 0 0 0 kworker/u:0H 8 root RT 2 0 S 0 0 0 0.00 0.00 0 00:04.42 0 0 0 0 migration/0 9 root 20 2 0 S 0 0 0 0.00 0.00 0 00:00.00 0 0 0 0 rcu_bh 10 root 20 2 0 S 0 0 0 0.00 0.00 0 00:02.24 0 0 0 0 rcu_sched 11 root RT 2 0 S 0 0 0 0.00 0.00 0 00:00.05 0 0 0 0 watchdog/0 12 root RT 2 0 S 0 0 1 0.00 0.00 0 00:00.07 0 0 0 0 watchdog/1 13 root 20 2 0 S 0 0 1 0.00 0.00 0 00:00.73 0 0 0 0 ksoftirqd/1 14 root RT 2 0 S 0 0 1 0.00 0.00 0 00:01.96 0 0 0 0 migration/1 16 root 0 2 0 S 0 0 1 0.00 0.00 0 00:00.00 0 0 0 0 kworker/1:0H 17 root 0 2 0 S 0 0 1 0.00 0.00 0 00:00.00 0 0 0 0 cpuset 18 root 0 2 0 S 0 0 1 0.00 0.00 0 00:00.00 0 0 0 0 khelper 19 root 20 2 0 S 0 0 0 0.00 0.00 0 00:00.00 0 0 0 0 kdevtmpfs 20 root 0 2 0 S 0 0 0 0.00 0.00 0 00:00.00 0 0 0 0 netns 21 root 20 2 0 S 0 0 0 0.00 0.00 0 00:00.00 0 0 0 0 bdi-default 22 root 0 2 0 S 0 0 0 0.00 0.00 0 00:00.00 0 0 0 0 kintegrityd详情,参考:
man collectl三、Linux CPU负载状态分析
衡量CPU性能的指标:
1、用户使用CPU的情况:
CPU运行常规用户进程
CPU运行niced process
CPU运行实时进程
2、系统使用CPU情况:
用于I/O管理:中断和驱动
用于内存管理:页面交换
用户进程管理:进程开始和上下文切换
3、WIO:
用于进程等待磁盘I/O而使CPU处于空闲状态的比率。
4、CPU的空闲率:除了上面的WIO以外的空闲时间
5、CPU用于上下文交换的比率
6、nice
7、real-time
8、运行进程队列的长度
9、平均负载
当系统运行缓慢,应先调整应用程序对CPU的占用情况,使得应用程序能够更有效的使用CPU。同时可以考虑增加更多的CPU,关于CPU的使用情况还可以结合mpstat、ps aux 、top、prstat –a等等一些相应的命令来综合考虑关于具体的CPU的使用情况,和那些进程在占用大量的CPU时间.一般情况下,应用程序的问题会比较大一些,比如一些SQL语句不合理等等都会造成这样的现象。
查看物理CPU个数:
cat /proc/cpuinfo | grep “pysical id” | sort | uniq | wc -l查看每个物理CPU中core的个数(即核数):
cat /proc/cpuinfo | grep “cpu cores” | uniq查看逻辑CPU的个数:
cat /proc/cpuinfo | grep “processor” | wc -l查看CPU信息(型号):
cat /proc/cpuinfo | grep name | cut -f2 -d: | uniq -c网络io消耗:
cat /proc/interruptes 物理CPU:
很好理解,实际服务器插槽上的cpu个数。
逻辑CPU:
CPU使用超线程技术,在逻辑上在分一倍数量的cpu core出来。
1逻辑cpu = 物理cpu * 单个cpu核心数 * 2。
CPU核心数:
官方话说就是一块CPU上面能处理数据的芯片组的数量。
1、uptime
uptime命令能够打印系统总共运行了多长时间和系统的平均负载。uptime命令可以显示的信息显示依次为:现在时间、系统已经运行了多长时间、目前有多少登陆用户、系统在过去的1分钟、5分钟和15分钟内的平均负载。
查看系统运行时间、用户数、负载:
[root@www2 init.d]# uptime7:51pm up 2 days, 5:43, 2 users, load average: 8.13, 5.90, 4.9输出说明:
19:51:30 //系统当前时间up 2 days, 5:43 //主机已运行时间,时间越大,说明你的机器越稳定。2 user //用户连接数,是总连接数而不是用户数load average: 8.13, 5.90, 4.9 // 系统平均负载,统计最近1,5,15分钟的系统平均负载那么什么是系统平均负载呢? 系统平均负载是指在特定时间间隔内运行队列中的平均进程数。
如果一个进程满足以下条件则其就会位于运行队列中:
- 它没有在等待I/O操作的结果
- 它没有主动进入等待状态(也就是没有调用’wait’)
- 没有被停止(例如:等待终止)
一般来说只要每个CPU的当前活动进程数不大于3那么系统的性能就是良好的,如果每个CPU的任务数大于5,那么就表示这台机器的性能有严重问题。对于上面的例子来说,假设系统有两个CPU,那么其每个CPU的当前任务数为:8.13/2=4.065。这表示该系统的性能是可以接受的。
如果你的linux主机是1个双核CPU的话,当Load Average为6的时候说明机器已经被充分使用了。
查看系统负载:
cat /proc/loadavg 1.63 0.61 0.22 1/228 24871.63(1分钟平均负载) 0.61(5分钟平均负载) 0.22(15分钟平均负载) 1/228(分子是当前正在运行的进程数,分母是总的进程数) 2487(最近运行进程的ID)
这里的平均负载也就是可运行的进程的平均数。
前三个值分别对应系统在1分钟、5分钟、15分钟内的平均负载
第四个值的分子是正在运行的进程数,分母是进程总数,最后一个是最近运行的进程ID号
2、top
top命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器。可以了解到CPU消耗,可以根据用户指定的时间来更新显示。
语法:
top [-d number] | top [-bnp]参数:
-d:number代表秒数,表示top命令显示的页面更新一次的间隔,当然用户可以使用s交互命令来改变之-p:指定特定的pid进程号进行观察-n:与-b配合使用,表示需要进行几次top命令的输出结果-b:以批次的方式执行top-q 该选项将使top没有任何延迟的进行刷新。如果调用程序有超级用户权限,那么top将以尽可能高的优先级运行-S:指定累计模式-s:使top命令在安全模式中运行。这将去除交互命令所带来的潜在危险-i:使top不显示任何闲置或者僵死进程-c:显示整个命令行而不只是显示命令名快键键:
Ctrl+L 擦除并且重写屏幕。h或者? 显示帮助画面,给出一些简短的命令总结说明。k 终止一个进程。系统将提示用户输入需要终止的进程PID,以及需要发送给该进程什么样的信号。一般的终止进程可以使用15信号;如果不能正常结束那就使用信号9强制结束该进程。默认值是信号15。在安全模式中此命令被屏蔽。i 忽略闲置和僵死进程。这是一个开关式命令。q 退出程序(用ctrl+c也可以退出top)。r 重新安排一个进程的优先级别(nice)。系统提示用户输入需要改变的进程PID以及需要设置的进程优先级值。输入一个正值将使优先级降低,反之则可以使该进程拥有更高的优先权。默认值是10。S 切换到累计模式。s 改变两次刷新之间的延迟时间。系统将提示用户输入新的时间,单位为s。如果有小数,就换算成m s。输入0值则系统将不断刷新,默认值是5 s。需要注意的是如果设置太小的时间,很可能会引起不断刷新,从而根本来不及看清显示的情况,而且系统负载也会大大增加。f或者F 从当前显示中添加或者删除项目。o或者O 改变显示项目的顺序。l 切换显示平均负载和启动时间信息。m 切换显示内存信息。t 切换显示进程和CPU状态信息。c 切换显示命令名称和完整命令行。M 根据驻留内存大小进行排序。P 根据CPU使用百分比大小进行排序。T 根据时间/累计时间进行排序。W 将当前设置写入~/.toprc文件中。这是写top配置文件的推荐方法。常用组合:
# top //每隔5秒显式所有进程的资源占用情况# top -d 2 //每隔2秒显式所有进程的资源占用情况# top -c //每隔5秒显式进程的资源占用情况,并显示进程的命令行参数(默认只有进程名)# top -p 12345 -p 6789 //每隔5秒显示pid是12345和pid是6789的两个进程的资源占用情况# top -d 2 -c -p 123456 //每隔2秒显示pid是12345的进程的资源使用情况,并显式该进程启动的命令行参数运行 top 命令后,CPU 使用状态会以全屏的方式显示,并且会处在对话的模式 -- 用基于 top 的命令,可以控制显示方式等等。退出 top 的命令为 q (在 top 运行中敲 q 键一次)。

top命令的汇总区域显示了五个方面的系统性能信息:
1.负载:时间,登陆用户数,系统平均负载;
2.进程:运行,睡眠,停止,僵尸;
3.cpu:用户态,核心态,NICE,空闲,等待IO,中断等;
4.内存:总量,已用,空闲(系统角度),缓冲,缓存;
5.交换分区:总量,已用,空闲
任务区域默认显示:进程ID,有效用户,进程优先级,NICE值,进程使用的虚拟内存,物理内存和共享内存,进程状态,CPU占用率,内存占用率,累计CPU时间,进程命令行信息。
第1行:top - 05:43:27 up 4:52, 2 users, load average: 0.58, 0.41, 0.30
第1行是任务队列信息,其参数如下:
| 内容 | 含义 |
|---|---|
| 05:43:27 | 表示当前时间 |
| up 4:52 | 系统运行时间 格式为时:分 |
| 2 users | 当前登录用户数 |
| load average: 0.58, 0.41, 0.30 | 系统负载,即任务队列的平均长度。 三个数值分别为 1分钟、5分钟、15分钟前到现在的平均值。 |
load average: 如果这个数除以逻辑CPU的数量,结果高于5的时候就表明系统在超负荷运转了。
第2行:Tasks: 159 total, 1 running, 158 sleeping, 0 stopped, 0 zombie
第3行:%Cpu(s): 37.0 us, 3.7 sy, 0.0 ni, 59.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
第2、3行为进程和CPU的信息,当有多个CPU时,这些内容可能会超过两行,其参数如下:
| 内容 | 含义 |
|---|---|
| 159 total | 进程总数 |
| 1 running | 正在运行的进程数 |
| 158 sleeping | 睡眠的进程数 |
| 0 stopped | 停止的进程数 |
| 0 zombie | 僵尸进程数 |
| 37.0 us | 用户空间占用CPU百分比 |
| 3.7 sy | 内核空间占用CPU百分比 |
| 0.0 ni | 用户进程空间内改变过优先级的进程占用CPU百分比 |
| 59.3 id | 空闲CPU百分比 |
| 0.0 wa | 等待输入输出的CPU时间百分比 |
| 0.0 hi | 硬中断(Hardware IRQ)占用CPU的百分比 |
| 0.0 si | 软中断(Software Interrupts)占用CPU的百分比 |
| 0.0 st |
第4行:KiB Mem: 1530752 total, 1481968 used, 48784 free, 70988 buffers
第5行:KiB Swap: 3905532 total, 267544 used, 3637988 free. 617312 cached Mem
第4、5行为内存信息,其参数如下:
| 内容 | 含义 |
|---|---|
| KiB Mem: 1530752 total | 物理内存总量 |
| 1481968 used | 使用的物理内存总量 |
| 48784 free | 空闲内存总量 |
| 70988 buffers(buff/cache) | 用作内核缓存的内存量 |
| KiB Swap: 3905532 total | 交换区总量 |
| 267544 used | 使用的交换区总量 |
| 3637988 free | 空闲交换区总量 |
| 617312 cached Mem | 缓冲的交换区总量。 |
| 3156100 avail Mem | 代表可用于进程下一次分配的物理内存数量 |
上述最后提到的缓冲的交换区总量,这里解释一下,所谓缓冲的交换区总量,即内存中的内容被换出到交换区,而后又被换入到内存,但使用过的交换区尚未被覆盖,该数值即为这些内容已存在于内存中的交换区的大小。相应的内存再次被换出时可不必再对交换区写入。
计算可用内存数有一个近似的公式: 第四行的free + 第四行的buffers + 第五行的cached。
进程信息:
| 列名 | 含义 |
|---|---|
| PID | 进程id |
| PPID | 父进程id |
| RUSER | Real user name |
| UID | 进程所有者的用户id |
| USER | 进程所有者的用户名 |
| GROUP | 进程所有者的组名 |
| TTY | 启动进程的终端名。不是从终端启动的进程则显示为 ? |
| PR | 优先级 |
| NI | nice值。负值表示高优先级,正值表示低优先级 |
| P | 最后使用的CPU,仅在多CPU环境下有意义 |
| %CPU | 上次更新到现在的CPU时间占用百分比 |
| TIME | 进程使用的CPU时间总计,单位秒 |
| TIME+ | 进程使用的CPU时间总计,单位1/100秒 |
| %MEM | 进程使用的物理内存百分比 |
| VIRT | 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES |
| SWAP | 进程使用的虚拟内存中,被换出的大小,单位kb |
| RES | 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA |
| CODE | 可执行代码占用的物理内存大小,单位kb |
| DATA | 可执行代码以外的部分(数据段+栈)占用的物理内存大小,单位kb |
| SHR | 共享内存大小,单位kb |
| nFLT | 页面错误次数 |
| nDRT | 最后一次写入到现在,被修改过的页面数。 |
| S | 进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程 |
| COMMAND | 命令名/命令行 |
| WCHAN | 若该进程在睡眠,则显示睡眠中的系统函数名 |
| Flags | 任务标志 |
top里的%CPU和us%:
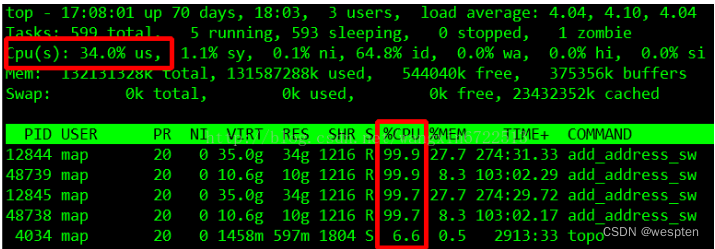
其实都是对的,只是表达的意思不一样。
官方解释如下
Cpu(s):34.0% us: 用户空间占用CPU百分比;
%CPU:上次更新到现在的CPU时间占用百分比;
读到这里我也不是十分理解他们俩的关系,我一直以为%CPU是每个进程占用的cpu百分比,按理来说所有进程的该值加在一起应该等于us。
但事实并非如此,多U多核CPU监控,在top基本视图中,按键盘数字“1”可以监控每个逻辑CPU的状况:

这时候我们可以清晰得看到每个cpu的运行状态。上面显示的有有8个逻辑CPU,实际上是1个物理CPU。如果不按1,则在top视图里面显示的是所有cpu的平均值。
通过上面的显示我们发现Cpu(s)表示的是 所有用户进程占用整个cpu的平均值,由于每个核心占用的百分比不同,所以按平均值来算比较有参考意义。而%CPU显示的是进程占用一个核的百分比,而不是整个cpu(8核)的百分比,有时候可能大于100,那是因为该进程启用了多线程占用了多个核心,所以有时候我们看该值得时候会超过100%,但不会超过总核数*100。
敲击键盘‘b’(打开关闭加亮效果)top视图变换如下:
PID为16283为当前top视图中唯一的运行态进程。也可以敲击键盘‘y’来打开或者关闭运行态进程的加亮效果。
敲击键盘‘x’(打开/关闭排序列的加亮效果),top视图变换如下:
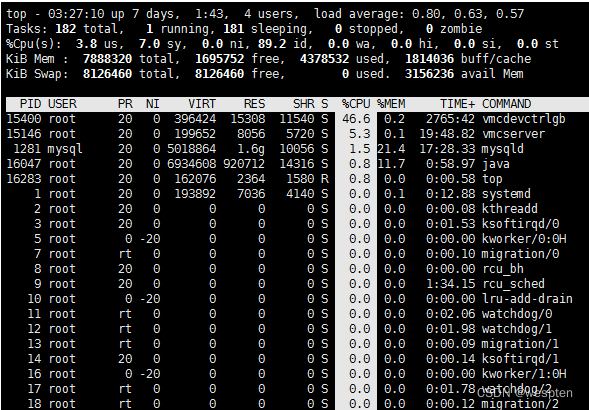
可以看到现在是按"%CPU"进行排序的,可以按”shift+>”或者”shift+<”左右改变排序序列。
4、改变进程显示字段
在top基本视图中,敲击”f”进入另一个视图,在这里可以编辑基本视图中的显示字段:
这里列出了所有可在top基本视图中显示的进程字段,有”*”并且标注为大写字母的字段是可显示的,没有”*”并且是小写字母的字段是不显示的。如果要在基本视图中显示“CODE”和“DATA”两个字段,可以通过敲击“r”和“s”键:
用上下键选择选项,按下空格键可以决定是否在基本视图中显示这个选项。
top命令是一个非常强大的功能,但是它监控的最小单位是进程,如果想监控更小单位时,就需要用到ps或者netstate命令来满足我们的要求。
3、htop
htop 是Linux系统中的一个互动的进程查看器,一个文本模式的应用程序(在控制台或者X终端中),需要ncurses。
htop可让用户交互式操作,支持颜色主题,可横向或纵向滚动浏览进程列表,并支持鼠标操作。
与top相比,htop有以下优点:
▪ 可以横向或者纵向滚动浏览进程列表,以便看到所有的进程和完整的命令行。
▪ 在启动上,比top更快。
▪ 杀进程时不需要输入进程号。
▪ htop支持鼠标操作。
4、mpstat
mpstat 是Multiprocessor Statistics的缩写,是实时系统监控工具,不但能查看所有CPU的平均信息,还能查看指定CPU的信息。
其报告与CPU的一些统计信息,这些信息存放在/proc/stat文件中。在多CPU系统里,其不但能查看所有CPU的平均状况信息,而且能够查看特定CPU的信息。
语法:
mpstat [-P {|ALL}] [internal [count]]参数:
-P {|ALL} 表示监控哪个CPU, cpu在[0,cpu个数-1]中取值internal 相邻的两次采样的间隔时间count 采样的次数,count只能和delay一起使用当没有参数时,mpstat则显示系统启动以后所有信息的平均值。有interval时,第一行的信息自系统启动以来的平均信息。从第二行开始,输出为前一个interval时间段的平均信息。
要查看cpu波动情况的,尤其是多核机器上,可使用:
mpstat -P ALL 5 //需要注意的P和ALL一定要大写17时22分24秒 CPU %user %nice %sys %iowait %irq %soft %steal %idle intr/s17时22分29秒 all 0.30 0.00 0.10 0.67 0.02 0.07 0.00 98.83 821.4017时22分29秒 0 1.00 0.00 0.60 1.00 0.20 0.60 0.00 96.60 560.0017时22分29秒 1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.20 0.0017时22分29秒 2 0.60 0.00 0.20 0.20 0.00 0.20 0.00 99.00 250.2017时22分29秒 3 0.00 0.00 0.00 4.00 0.00 0.00 0.00 96.00 11.2017时22分29秒 4 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.20 0.0017时22分29秒 5 0.80 0.00 0.00 0.00 0.00 0.00 0.00 99.20 0.0017时22分29秒 6 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 0.0017时22分29秒 7 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 0.00该命令可间隔5秒钟采样一次CPU的使用情况,每个核的情况都会显示出来,例如,每个核的idle情况等。
输出说明:
上面信息我们可以看出,有8个CPU。%user :在internal时间段里,即为用户态的CPU时间,及登录用户所消耗的CPU时间比。%sys :在internal时间段里,负进程消耗的CPU时间,占所有CPU的百分比%nice :优先进程占用时间%iowait:在internal时间段里,所有未等待磁盘IO操作进程占CPU的百分比%irq : 这个还是未知%soft : 在internal时间段里,软中断时间(%) softirq/total*100%idle : 在internal时间段里,CPU除去等待磁盘IO操作外的因为任何原因而空闲的时间闲置时间 (%)intr/s: 在internal时间段里,每秒CPU接收的中断的次数 从/proc/stat获得数据:
CPU 处理器IDuser 在internal时间段里,用户态的CPU时间(%) ,不包含 nice值为负 进程 dusr/dtotal*100nice 在internal时间段里,nice值为负进程的CPU时间(%) dnice/dtotal*100system 在internal时间段里,核心时间(%) dsystem/dtotal*100iowait 在internal时间段里,硬盘IO等待时间(%) diowait/dtotal*100irq 在internal时间段里,软中断时间(%) dirq/dtotal*100soft 在internal时间段里,软中断时间(%) dsoftirq/dtotal*100idle 在internal时间段里,CPU除去等待磁盘IO操作外的因为任何原因而空闲的时间闲置时间 (%) didle/dtotal*100intr/s 在internal时间段里,每秒CPU接收的中断的次数 dintr/dtotal*100CPU总的工作时间=total_cur=user+system+nice+idle+iowait+irq+softirqtotal_pre=pre_user+ pre_system+ pre_nice+ pre_idle+ pre_iowait+ pre_irq+ pre_softirqduser=user_cur – user_predtotal=total_cur-total_pre其中_cur 表示当前值,_pre表示interval时间前的值。上表中的所有值可取到两位小数点。5、sar
sar是System Activity Reporter(系统活跃情况报告)的缩写。顾名思义,sar工具将对系统当前的状态进行采样,然后通过计算数据和比例来表达系统的当前运行状态。它的特点是可以连续对系统采样,获得大量的采样数据;采样数据和分析的结果都可以存入文件,所需的负载很小。这些是检查历史数据和一些近来的系统事件。
sar 用于检查的性能数据类似于vmstat, mpstat和 iostat的显示。 sar的数据是一段时间保存的内容,因此可以察看过去的信息。 lastcomm可以现在系统最近被执行的命令。这些可以用在系统审计中。sar可以在BSD和Linux中找到,它给用户在系统审计中更多的选项来收集信息。
sar 反馈的与CPU相关的信息包括:
(1)多少任务在运行
(2)CPU使用的情况
(3)CPU收到多少中断
(4)发生多少上下文切换
语法:
sar [options] [-A] [-o file] t [n]在命令行中,n 和t 两个参数组合起来定义采样间隔和次数,t为采样间隔,是必须有的参数,n为采样次数,是可选的,默认值是1,-o file表示将命令结果以二进制格式存放在文件中,file 在此处不是关键字,是文件名。
参数:
-A:所有报告的总和。-u:CPU利用率-v:进程、I节点、文件和锁表状态。-d:硬盘使用报告。-r:内存和交换空间的使用统计。-g:串口I/O的情况。-b:缓冲区使用情况。-a:文件读写情况。-c:系统调用情况。-q:报告队列长度和系统平均负载-R:进程的活动情况。-y:终端设备活动情况。-w:系统交换活动。-x { pid | SELF | ALL }:报告指定进程ID的统计信息,SELF关键字是sar进程本身的统计,ALL关键字是所有系统进程的统计。用sar进行CPU利用率的分析:
sar -u 2 10Linux 2.6.18-53.el5PAE (localhost.localdomain) 03/28/200907:40:17 PM CPU %user %nice %system %iowait %steal %idle07:40:19 PM all 12.44 0.00 6.97 1.74 0.00 78.8607:40:21 PM all 26.75 0.00 12.50 16.00 0.00 44.7507:40:23 PM all 16.96 0.00 7.98 0.00 0.00 75.0607:40:25 PM all 22.50 0.00 7.00 3.25 0.00 67.2507:40:27 PM all 7.25 0.00 2.75 2.50 0.00 87.5007:40:29 PM all 20.05 0.00 8.56 2.93 0.00 68.4607:40:31 PM all 13.97 0.00 6.23 3.49 0.00 76.3107:40:33 PM all 8.25 0.00 0.75 3.50 0.00 87.5007:40:35 PM all 13.25 0.00 5.75 4.00 0.00 77.0007:40:37 PM all 10.03 0.00 0.50 2.51 0.00 86.97Average: all 15.15 0.00 5.91 3.99 0.00 74.95输出说明:
%user:CPU处在用户模式下的时间百分比。%nice:CPU处在带NICE值的用户模式下的时间百分比。%system:CPU处在系统模式下的时间百分比。%iowait:CPU等待输入输出完成时间的百分比。%steal:管理程序维护另一个虚拟处理器时,虚拟CPU的无意识等待时间百分比。%idle:CPU空闲时间百分比。在所有的显示中,我们应主要注意%iowait和%idle,%iowait的值过高,表示硬盘存在I/O瓶颈,%idle值高,表示CPU较空闲,如果%idle值高但系统响应慢时,有可能是CPU等待分配内存,此时应加大内存容量。
%idle值如果持续低于10,那么系统的CPU处理能力相对较低,表明系统中最需要解决的资源是CPU。
用sar进行运行进程队列长度分析:
sar -q 2 10Linux 2.6.18-53.el5PAE (localhost.localdomain) 03/28/200907:58:14 PM runq-sz plist-sz ldavg-1 ldavg-5 ldavg-1507:58:16 PM 0 493 0.64 0.56 0.4907:58:18 PM 1 491 0.64 0.56 0.4907:58:20 PM 1 488 0.59 0.55 0.4907:58:22 PM 0 487 0.59 0.55 0.4907:58:24 PM 0 485 0.59 0.55 0.4907:58:26 PM 1 483 0.78 0.59 0.5007:58:28 PM 0 481 0.78 0.59 0.5007:58:30 PM 1 480 0.72 0.58 0.5007:58:32 PM 0 477 0.72 0.58 0.5007:58:34 PM 0 474 0.72 0.58 0.50Average: 0 484 0.68 0.57 0.49输出说明:
runq-sz 准备运行的进程运行队列。plist-sz 进程队列里的进程和线程的数量ldavg-1 前一分钟的系统平均负载(load average)ldavg-5 前五分钟的系统平均负载(load average)ldavg-15 前15分钟的系统平均负载(load average)6、vmstat
vmstat是Virtual Meomory Statistics(虚拟内存统计)的缩写, 是实时系统监控工具。该命令通过使用knlist子程序和/dev/kmen伪设备驱动器访问这些数据,输出信息直接打印在屏幕。vmstat反馈的与CPU相关的信息包括:
(1)多少任务在运行
(2)CPU使用的情况
(3)CPU收到多少中断
(4)发生多少上下文切换
只能查看所有CPU的平均信息,查看cpu队列信息。
[root@localhost ~]#vmstat -n 3 (每个3秒刷新一次)procs-----------memory--------------------swap-- ----io---- --system---- ------cpu--------r b swpd free buff cache si so bi bo in cs us sy id wa10 144 186164 105252 2386848 0 0 18 166 83 2 48 21 31 020 144 189620 105252 2386848 0 0 0 177 1039 1210 34 10 56 000 144 214324 105252 2386848 0 0 0 10 1071 670 32 5 63 000 144 202212 105252 2386848 0 0 0 189 1035 558 20 3 77 020 144 158772 105252 2386848 0 0 0 203 1065 2832 70 14 15 0vmstat命令输出分成六个部分:
进程procs:
r:在运行队列中等待的进程数b:在等待io的进程数内存memoy:
swpd:现时可用的交换内存(单位KB)free:空闲的内存(单位KB)buff: 缓冲去中的内存数(单位:KB)cache:被用来做为高速缓存的内存数(单位:KB)swap交换页面:
si: 从磁盘交换到内存的交换页数量,单位:KB/秒so: 从内存交换到磁盘的交换页数量,单位:KB/秒o块设备:
bi: 发送到块设备的块数,单位:块/秒bo: 从块设备接收到的块数,单位:块/秒system系统:
in: 每秒的中断数,包括时钟中断cs: 每秒的环境(上下文)切换次数cpu中央处理器:
cs:用户进程使用的时间 ,以百分比表示sy:系统进程使用的时间,以百分比表示id:中央处理器的空闲时间,以百分比表示如果 r经常大于 4 ,且id经常小于40,表示中央处理器的负荷很重。 如果bi,bo 长期不等于0,表示物理内存容量太小。
procs
r 列表示运行和等待cpu时间片的进程数,如果长期大于在系统中的CPU的个数,且运行比较慢,说明CPU不足,有多数的进程等待CPU,需要增加CPU。
b 列表示在等待资源的进程数,比如正在等待I/O、或者内存交换等。
cpu表示cpu的使用状态
us 列显示了用户方式下所花费 CPU 时间的百分比。us的值比较高时,说明用户进程消耗的cpu时间多,但是如果长期大于50%,需要考虑优化程序算法或者进行加速(比如PHP/PERL)。
sy 列显示了内核进程所花费的cpu时间的百分比。sy的值高时,说明系统内核消耗的CPU资源多,这并不是良性表现,我们应该检查原因。
这里us + sy的参考值为80%,如果us+sy 大于 80%说明可能存在CPU不足。
wa 列显示了IO等待所占用的CPU时间的百分比。wa的值高时,说明IO等待比较严重,这可能由于磁盘大量作随机访问造成,也有可能磁盘出现瓶颈(块操作)。
这里wa的参考值为30%,如果wa超过30%,说明IO等待严重,这可能是磁盘大量随机访问造成的,也可能磁盘或者磁盘访问控制器的带宽瓶颈造成的(主要是块操作)。
id 列显示了cpu处在空闲状态的时间百分比,如果空闲时间(cpu id)持续为0并且系统时间(cpu sy)是用户时间的两倍(cpu us) 系统则面临着CPU资源的短缺。
system 显示采集间隔内发生的中断数。
in列表示在某一时间间隔中观测到的每秒设备中断数。
cs列表示每秒产生的上下文切换次数,如当 cs 比磁盘 I/O 和网络信息包速率高得多,都应进行进一步调查。
上面2个值越大,会看到由内核消耗的CPU时间会越大
memory
swpd 切换到内存交换区的内存数量(k表示)。如果swpd的值不为0,或者比较大,比如超过了100m,只要si、so的值长期为0,系统性能还是正常
free 当前的空闲页面列表中内存数量(k表示)
buff 作为buffer cache的内存数量,一般对块设备的读写才需要缓冲。
cache: 作为page cache的内存数量,一般作为文件系统的cache,如果cache较大,说明用到cache的文件较多,如果此时IO中bi比较小,说明文件系统效率比较好。
swap
si 由内存进入内存交换区数量。
so由内存交换区进入内存数量。
IO
bi 从块设备读入数据的总量(读磁盘)(每秒kb)。
bo 块设备写入数据的总量(写磁盘)(每秒kb)
这里我们设置的bi+bo参考值为1000,如果超过1000,而且wa值较大应该考虑均衡磁盘负载,可以结合iostat输出来分析。
7、iostat
只能查看所有CPU的平均信息:
iostat -c 2 10Linux 2.6.18-53.el5PAE (localhost.localdomain) 03/28/2009avg-cpu: %user %nice %system %iowait %steal %idle 30.10 0.00 4.89 5.63 0.00 59.38avg-cpu: %user %nice %system %iowait %steal %idle 8.46 0.00 1.74 0.25 0.00 89.55avg-cpu: %user %nice %system %iowait %steal %idle 22.06 0.00 11.28 1.25 0.00 65.41详细输出:
iostat -xLinux 2.4.21-9.30AX (localhost) 2004年07月14日avg-cpu: %user %nice %sys %idle3.85 0.00 0.95 95.20Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util/dev/hda 1.70 1.70 0.82 0.82 19.88 20.22 9.94 10.11 24.50 11.83 57.81 610.76 99.96/dev/hda1 0.00 0.00 0.00 0.00 0.01 0.00 0.00 0.00 12.92 0.00 10.77 10.77 0.00/dev/hda5 0.02 0.00 0.00 0.00 0.03 0.00 0.02 0.00 6.60 0.00 6.44 6.04 0.00/dev/hda6 0.01 0.38 0.05 0.03 0.43 3.25 0.21 1.62 46.90 0.15 193.96 52.25 0.41/dev/hda7 1.66 1.33 0.76 0.79 19.41 16.97 9.70 8.49 23.44 0.79 51.13 19.79 3.07输出说明:
rrqm/s: 每秒进行 merge 的读操作数目。即 delta(rmerge)/swrqm/s: 每秒进行 merge 的写操作数目。即 delta(wmerge)/sr/s: 每秒完成的读 I/O 设备次数。即 delta(rio)/sw/s: 每秒完成的写 I/O 设备次数。即 delta(wio)/srsec/s: 每秒读扇区数。即 delta(rsect)/swsec/s: 每秒写扇区数。即 delta(wsect)/srkB/s: 每秒读K字节数。是 rsect/s 的一半,因为每扇区大小为512字节。wkB/s: 每秒写K字节数。是 wsect/s 的一半。avgrq-sz: 平均每次设备I/O操作的数据大小 (扇区)。即 delta(rsect+wsect)/delta(rio+wio)avgqu-sz: 平均I/O队列长度。即 delta(aveq)/s/1000 (因为aveq的单位为毫秒)。await: 平均每次设备I/O操作的等待时间 (毫秒)。即 delta(ruse+wuse)/delta(rio+wio)svctm: 平均每次设备I/O操作的服务时间 (毫秒)。即 delta(use)/delta(rio+wio)%util: 一秒中有百分之多少的时间用于 I/O 操作,或者说一秒中有多少时间 I/O 队列是非空的。即 delta(use)/s/1000 (因为use的单位为毫秒)如果 %util 接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈。
svctm 一般要小于 await (因为同时等待的请求的等待时间被重复计算了),svctm 的大小一般和磁盘性能有关,CPU/内存的负荷也会对其有影响,请求过多也会间接导致 svctm 的增加。await 的大小一般取决于服务时间(svctm) 以及 I/O 队列的长度和 I/O 请求的发出模式。如果 svctm 比较接近 await,说明 I/O 几乎没有等待时间;如果 await 远大于 svctm,说明 I/O 队列太长,应用得到的响应时间变慢,如果响应时间超过了用户可以容许的范围,这时可以考虑更换更快的磁盘,调整内核 elevator 算法,优化应用,或者升级 CPU。
队列长度(avgqu-sz)也可作为衡量系统 I/O 负荷的指标,但由于 avgqu-sz 是按照单位时间的平均值,所以不能反映瞬间的 I/O 洪水。
四、Linux内存状态分析
1、free
CentOS6:
在CentOS6及以前的版本中,free命令输出是这样的:
$free -m total used free shared buffers cachedMem: 1002 769 233 0 62 421-/+ buffers/cache: 286 716Swap: 1153 0 1153free -m (-m,单位是m,如果是-g,单位是g)查看可用内存:
total-used=free+buff/cache。
我们通过free命令查看机器空闲内存时,会发现free的值很小。这主要是因为,在linux中有这么一种思想,内存不用白不用,因此它尽可能的cache和buffer一些数据,以方便下次使用。但实际上这些内存也是可以立刻拿来使用的。
第一行:
系统内存主要分为四部分:used(程序已使用内存),free(空闲内存),buffers(buffer cache),cached(Page cache)。
系统总内存total = used + free; buffers和cached被算在used里,因此第一行系统已使用内存used = buffers + cached + 第二行系统已使用内存used
由于buffers和cached在系统需要时可以被回收使用,因此系统可用内存 = free + buffers + cached;
shared为程序共享的内存空间,往往为0。
第二行:
正因为buffers和cached在系统需要时可以被回收使用,因此buffer和cached其实可以可以算作可用内存,因此:
系统可用内存,即第二行的free = 第一行的free + buffers + cached。
系统已使用内存,即第二行的used = total - 第二行free
第三行:
swap内存交换空间使用情况。
数据什么时候跑到磁盘上面去的?
1. 数据来源于磁盘上的一个文件。之前以缓存的目的读入到内存中来过,但是内存紧张了,为了节省内存所以把数据回写到磁盘上去了;数据来源于磁盘上的一个文件,从来还没有读入到内存中来过,只是设置了页表项,这种情况一般出现在内存映射时。
2. 数据由进程动态产生的,譬如堆栈的内存空间,由于内存紧张被换出到磁盘上去了。
什么时候换出内存?
内核联合使用了如下两种机制:
1. 一个周期性的守护进程(kswapd)在后台运行,该进程不断检查当前的内存使用情况,以使在达到特定的阀值时发起页的交换操作。使用该方法,确保了不会出现突然需要换出大量页的情况。这种情况将导致系统出现很长的等待时间,必须不惜一切代价防止。
2. 但内核在某些情况下,必须能够预期可能突然出现的严重内存不足,例如在通过伙伴系统(Linux分配内存的一种机制)分配一大块内存时,或创建缓冲区时。如果没有足够的物理内存可用来满足对内存的请求,内核必须尽快换出页,以期释放一些内存空间。在紧急情况下的换出操作,属于直接回收(direct reclamin)的一部分。
上面这两种方式的底层实现是相似的,只不过对于第二种方式来说如果内存不足的时候采取的措施更强硬一些。毕竟第一种方式只是例行检查,尽量保证内存使用量在一个健康的水平;而第二种方式则是在“有内存需要的时候采取的紧急措施“,所以方式会更强硬一些,譬如函数会一直等待内存数据写入到了磁盘上之后才返回、回收一些并不是那个“不经常使用”的内存。
如果内核无法满足对内存的请求,甚至在换出页以后也是如此,内么虚拟内存子系统(默认的选择)将通过OOM(out of memory,内存不足)killer了结束一个进程。虽然OOM killer有时候可能导致严重的损失,但比系统完全崩溃要好。如果在内存不足的情况下不采取措施,很可能导致系统崩溃
交换与回写什么关系?
上面说的叙述中可以看出交换和回写(writeback,又做写回)其实是差不多的,都是在操作系统感受到内存空间不足的时候,腾出来内存空间的一种方式。区别的地方在于:
交换是针对那些由进程动态产生的、不存在对应的磁盘文件的数据;而回写则是有对应的磁盘文件的数据,还需要说明一下上面提到的根据PCPC中存放的地址去内存中取指令(也就是数据,也就是数据了)的操作过程中,如果指令不在内存中,那么指令一定是被写回到磁盘上去了。因为,一个进程的指令总是在创建进程的时候通过分析加载可执行文件读入到内存中的。(不考虑一些特殊的情况,譬如堆栈溢出攻击)
所以交换机制要做的很重要的一个事情就是图三步骤③中的,建立原来在内存中的数据到磁盘中的数据的映射。即给定一个进程的线性地址L1L1能够找到与之对应的磁盘逻辑地址D1D1(如果数据不再内存中的话)。从操作系统程序猿的角度去看,一个磁盘就相当于非常非常大的数组,磁盘的逻辑地址D1D1就相当于该数组的索引值,每个数组元素都是一个扇区的大小,这是磁盘寻址的最小单元,通常为512byte512byte。
那么,步骤③更详细的叙述为 : 操作系统通过交换机制建立起来的映射,找到L1L1对应的D1D1。然后分配一块至少能够放得下一个扇区的内存,内存的物理地址为P1P1。下一步将二元组(D1,P1)(D1,P1)交给下层的虚拟文件层。虚拟文件层需要上层传递的这两个主要的参数,即可将磁盘逻辑地址D1D1中的数据读入到内存物理地址P1P1去。到此为止内核就完成了步骤③的工作。不了解虚拟文件层没有关系,只需要知道其上述功能即可;而且,也就是说交换机制不会涉及数据是如何写入到磁盘中去的,又是如何从磁盘中读出来的,这些都是文件系统和驱动的工作。
CentOS7:
CentOS7及以后free命令的输出如下:
# free -m total used free shared buff/cache availableMem: 3440 213 2276 168 950 2778Swap: 0 0 0buffer和cached被合成一组,加入了一个available,关于此available,文档上的说明如下:
MemAvailable: An estimate of how much memory is available for starting new applications, without swapping.即系统可用内存,之前说过由于buffer和cache可以在需要时被释放回收,系统可用内存即 free + buffer + cache,在CentOS7之后这种说法并不准确,因为并不是所有的buffer/cache空间都可以被回收。
即available = free + buffer/cache - 不可被回收内存(共享内存段、tmpfs、ramfs等)。
因此在CentOS7之后,用户不需要去计算buffer/cache,即可以看到还有多少内存可用,更加简单直观。
表示从应用程序的角度来看,系统还剩下多少内存可用-其实大概等于buff/cache+free的值。
centos6:
Mem/used值:代表已经使用的内存(total-free)包含buffers和cached分配出去的量(与7used区别。
物理已用内存 = 实际已用内存 - 缓冲 - 缓存 = 6811M - 350M - 5114M。
centos7:
Mem/used值:代表已经使用的内存(total-free-buffers-cached)不包含buffers和cached分配出去的量。
Mem/available值:代表系统还剩下多少内存可用-其实大概等于buff/cache+free的值。
free -m | sed -n '2p' | awk '{print "used mem is "$3"M,total mem is "$2"M,used percent is "$3/$2*100"%"}'buffer/cache
buffer 和 cache 是两个在计算机技术中被用滥的名词,放在不通语境下会有不同的意义。在 Linux 的内存管理中,这里的 buffer 指 Linux 内存的: Buffer cache 。这里的 cache 指 Linux 内存中的: Page cache 。翻译成中文可以叫做缓冲区缓存和页面缓存。在历史上,它们一个( buffer )被用来当成对 io 设备写的缓存,而另一个( cache )被用来当作对 io 设备的读缓存,这里的 io 设备,主要指的是块设备文件和文件系统上的普通文件。但是现在,它们的意义已经不一样了。
在当前的内核中, page cache 顾名思义就是针对内存页的缓存,说白了就是,如果有内存是以 page 进行分配管理的,都可以使用 page cache 作为其缓存来管理使用。当然,不是所有的内存都是以页( page )进行管理的,也有很多是针对块( block )进行管理的,这部分内存使用如果要用到 cache 功能,则都集中到 buffer cache 中来使用。(从这个角度出发,是不是 buffer cache 改名叫做 block cache 更好?)然而,也不是所有块( block )都有固定长度,系统上块的长度主要是根据所使用的块设备决定的,而页长度在 X86 上无论是 32 位还是 64 位都是 4k 。
明白了这两套缓存系统的区别,就可以理解它们究竟都可以用来做什么了。
什么是 page cache?
Page cache 主要用来作为文件系统上的文件数据的缓存来用,尤其是针对当进程对文件有 read / write 操作的时候。如果你仔细想想的话,作为可以映射文件到内存的系统调用: mmap 是不是很自然的也应该用到 page cache ?在当前的系统实现里, page cache 也被作为其它文件类型的缓存设备来用,所以事实上 page cache 也负责了大部分的块设备文件的缓存工作。
什么是 buffer cache?
Buffer cache 则主要是设计用来在系统对块设备进行读写的时候,对块进行数据缓存的系统来使用。这意味着某些对块的操作会使用 buffer cache 进行缓存,比如我们在格式化文件系统的时候。一般情况下两个缓存系统是一起配合使用的,比如当我们对一个文件进行写操作的时候, page cache 的内容会被改变,而 buffer cache 则可以用来将 page 标记为不同的缓冲区,并记录是哪一个缓冲区被修改了。这样,内核在后续执行脏数据的回写( writeback )时,就不用将整个 page 写回,而只需要写回修改的部分即可。
如何回收 cache ?
Linux 内核会在内存将要耗尽的时候,触发内存回收的工作,以便释放出内存给急需内存的进程使用。一般情况下,这个操作中主要的内存释放都来自于对 buffer / cache 的释放。尤其是被使用更多的 cache 空间。既然它主要用来做缓存,只是在内存够用的时候加快进程对文件的读写速度,那么在内存压力较大的情况下,当然有必要清空释放 cache ,作为 free 空间分给相关进程使用。所以一般情况下,我们认为 buffer/cache 空间可以被释放,这个理解是正确的。
但是这种清缓存的工作也并不是没有成本。理解 cache 是干什么的就可以明白清缓存必须保证 cache 中的数据跟对应文件中的数据一致,才能对 cache 进行释放。所以伴随着 cache 清除的行为的,一般都是系统 IO 飙高。因为内核要对比 cache 中的数据和对应硬盘文件上的数据是否一致,如果不一致需要写回,之后才能回收。
在系统中除了内存将被耗尽的时候可以清缓存以外,我们还可以使用下面这个文件来人工触发缓存清除的操作:
[root@tencent64 ~]# cat /proc/sys/vm/drop_caches 1方法是:
echo 1 > /proc/sys/vm/drop_caches当然,这个文件可以设置的值分别为 1 、 2 、 3 。它们所表示的含义为:
echo 1 > /proc/sys/vm/drop_caches:表示清除 pagecache 。
echo 2 > /proc/sys/vm/drop_caches:表示清除回收 slab 分配器中的对象(包括目录项缓存和 inode 缓存)。 slab 分配器是内核中管理内存的一种机制,其中很多缓存数据实现都是用的 pagecache 。
echo 3 > /proc/sys/vm/drop_caches:表示清除 pagecache 和 slab 分配器中的缓存对象。
cat /proc/meminfo内存的详细信息:
[root@localhost proc]# cat /proc/meminfoMemTotal: 1001332 kBMemFree: 99592 kBMemAvailable: 420940 kBBuffers: 1064 kBCached: 405292 kBSwapCached: 0 kBActive: 412548 kBInactive: 250192 kBActive(anon): 205264 kBInactive(anon): 58460 kBActive(file): 207284 kBInactive(file): 191732 kBUnevictable: 0 kBMlocked: 0 kBSwapTotal: 2097148 kBSwapFree: 2097140 kBDirty: 0 kBWriteback: 0 kBAnonPages: 256416 kBMapped: 103344 kBShmem: 7340 kBSlab: 126408 kBSReclaimable: 69912 kBSUnreclaim: 56496 kBKernelStack: 10416 kBPageTables: 15520 kBNFS_Unstable: 0 kBBounce: 0 kBWritebackTmp: 0 kBCommitLimit: 2597812 kBCommitted_AS: 1578872 kBVmallocTotal: 34359738367 kBVmallocUsed: 170756 kBVmallocChunk: 34359564288 kBHardwareCorrupted: 0 kBAnonHugePages: 75776 kBHugePages_Total: 0HugePages_Free: 0HugePages_Rsvd: 0HugePages_Surp: 0Hugepagesize: 2048 kBDirectMap4k: 73600 kBDirectMap2M: 974848 kBDirectMap1G: 0 kBMemTotal总内存,MemFree可用内存。
centos6内存使用率计算方式,通过/proc/meminfo计算内存使用率:
MEMUsedPerc=100*(MemTotal-MemFree-Buffers-Cached)/MemTotal2、vmstat--虚拟内存统计
vmstat(VirtualMeomoryStatistics,虚拟内存统计) 是Linux中监控内存的常用工具,可对操作系统的虚拟内存、进程、CPU等的整体情况进行监视。
vmstat的常规用法:vmstat interval times即每隔interval秒采样一次,共采样times次,如果省略times,则一直采集数据,直到用户手动停止为止。
简单举个例子:

可以使用ctrl+c停止vmstat采集数据。
第一行显示了系统自启动以来的平均值,第二行开始显示现在正在发生的情况,接下来的行会显示每5秒间隔发生了什么,每一列的含义在头部,如下所示:
▪ procs:r这一列显示了多少进程在等待cpu,b列显示多少进程正在不可中断的休眠(等待IO)。
▪ memory:swapd列显示了多少块被换出了磁盘(页面交换),剩下的列显示了多少块是空闲的(未被使用),多少块正在被用作缓冲区,以及多少正在被用作操作系统的缓存。
▪ swap:显示交换活动:每秒有多少块正在被换入(从磁盘)和换出(到磁盘)。
▪ io:显示了多少块从块设备读取(bi)和写出(bo),通常反映了硬盘I/O。
▪ system:显示每秒中断(in)和上下文切换(cs)的数量。
▪ cpu:显示所有的cpu时间花费在各类操作的百分比,包括执行用户代码(非内核),执行系统代码(内核),空闲以及等待IO。
内存不足的表现:free memory急剧减少,回收buffer和cacher也无济于事,大量使用交换分区(swpd),页面交换(swap)频繁,读写磁盘数量(io)增多,缺页中断(in)增多,上下文切换(cs)次数增多,等待IO的进程数(b)增多,大量CPU时间用于等待IO(wa)
五、Linux进程堆栈状态分析
在两种情况下会导致一个进程在逻辑上不能运行,
1. 进程挂起是自身原因,遇到I/O阻塞,便要让出CPU让其他进程去执行,这样保证CPU一直在工作
2. 与进程无关,是操作系统层面,可能会因为一个进程占用时间过多,或者优先级等原因,而调用其他的进程去使用CPU。
因而一个进程有三种状态:
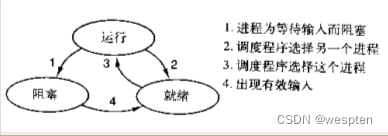
在Linux系统“一切都是文件”的思想贯彻指导下,所有进程的运行状态都可以用文件来获取。
proc文件系统是一个伪文件系统,它只存在内存当中,而不占用外存空间。它以文件系统的方式为内核与进程提供通信的接口。用户和应用程序可以通过/proc得到系统的信息,并可以改变内核的某些参数。由于系统的信息,如进程,是动态改变的,所以用户或应用程序读取/proc目录中的文件时,proc文件系统是动态从系统内核读出所需信息并提交的。
系统根目录/proc中,每一个数字子目录的名字都是运行中的进程的PID,进入任一个进程目录,可通过其中文件或目录来观察进程的各项运行指标。此外,在Linux2.6.0-test6以上的版本中/proc/pid目录中有一个task目录,/proc/pid/task目录中也有一些以该进程所拥有的线程的线程号命名的目录/proc/pid/task/tid,它们是读取线程信息的接口。
task目录就是用来描述进程中线程的,因此也可以通过下面的方法获取某进程中运行中的线程数量(PID指的是进程ID):
ls /proc/PID/task | wc -l查看某个进程的状态信息:
[root@QLB data]# cat /proc/4256/statusName:mysqldState:S (sleeping)SleepAVG:98%Tgid:4256Pid:4256PPid:3988TracerPid:0Uid:102102102102Gid:501501501501FDSize:512Groups:501 VmPeak: 410032 kBVmSize: 410032 kBVmLck: 0 kBVmHWM: 204356 kBVmRSS: 199920 kBVmData: 372332 kBVmStk: 88 kBVmExe: 8720 kBVmLib: 3544 kBVmPTE: 608 kBStaBrk:0ed3d000 kBBrk:136ae000 kBStaStk:7fff2268a570 kBThreads:16SigQ:0/69632SigPnd:0000000000000000ShdPnd:0000000000000000SigBlk:0000000000087007SigIgn:0000000000001006SigCgt:00000001800066e9CapInh:0000000000000000CapPrm:0000000000000000CapEff:0000000000000000Cpus_allowed:00000000,00000000,00000000,00000000,00000000,00000000,00000000,0000000fMems_allowed:00000000,00000001在linux中还有一个命令pmap,来输出进程内存的状况,可以用来分析线程堆栈:
pmap PID大家都熟悉Linux下可以通过top命令来查看所有进程的内存,CPU等信息。除此之外,还有其他一些命令,可以得到更详细的信息,例如进程相关:
cat /proc/your_PID/status 内存相关:
cat /proc/meminfo 查看cpu的配置信息可用:
cat /proc/cpuinfo 它能显示诸如CPU核心数,时钟频率、CPU型号等信息。
通过读取/proc/stat 、/proc/<pid>/stat、/proc/<pid>/task/<tid>/stat以及/proc/cpuinfo这几个文件获取总的Cpu时间、进程的Cpu时间、线程的Cpu时间以及Cpu的个数的信息,然后通过一定的算法进行计算(采样两个足够短的时间间隔的Cpu快照与进程快照来计算进程的Cpu使用率)。
/proc/stat文件包含了所有CPU活动的信息,该文件中的所有值都是从系统启动开始累计到当前时刻:
cat /proc/statcpu 38082 627 27594 89390812256 581 895 0 0第一行的数值表示的是CPU总的使用情况,所以我们只要用第一行的数字计算就可以了。下表解析第一行各数值的含义:
参数 解析(单位:jiffies)(jiffies是内核中的一个全局变量,用来记录自系统启动一来产生的节拍数,在linux中,一个节拍大致可理解为操作系统进程调度的最小时间片,不同linux内核可能值有不同,通常在1ms到10ms之间)user (38082) 从系统启动开始累计到当前时刻,处于用户态的运行时间,不包含 nice值为负进程。nice (627) 从系统启动开始累计到当前时刻,nice值为负的进程所占用的CPU时间system (27594) 从系统启动开始累计到当前时刻,处于核心态的运行时间idle (893908) 从系统启动开始累计到当前时刻,除IO等待时间以外的其它等待时间iowait (12256) 从系统启动开始累计到当前时刻,IO等待时间(since 2.5.41)irq (581) 从系统启动开始累计到当前时刻,硬中断时间(since 2.6.0-test4)softirq (895) 从系统启动开始累计到当前时刻,软中断时间(since2.6.0-test4)stealstolen(0) which is the time spent in otheroperating systems when running in a virtualized environment(since 2.6.11)guest(0) whichis the time spent running a virtual CPU for guest operating systems under the control ofthe Linux kernel(since 2.6.24)总的cpu时间:
totalCpuTime = user + nice+ system + idle + iowait + irq + softirq + stealstolen + guest/proc/<pid>/stat文件包含了某一进程所有的活动的信息,该文件中的所有值都是从系统启动开始累计到当前时刻。
cat /proc/6873/stat参数 解释pid=6873 进程号utime=1587 该任务在用户态运行的时间,单位为jiffiesstime=41958 该任务在核心态运行的时间,单位为jiffiescutime=0 所有已死线程在用户态运行的时间,单位为jiffiescstime=0 所有已死在核心态运行的时间,单位为jiffies进程的总Cpu时间:
processCpuTime = utime +stime + cutime + cstime,该值包括其所有线程的cpu时间。/proc/<pid>/task/<tid>/stat该文件包含了某一进程所有的活动的信息,该文件中的所有值都是从系统启动开始累计到当前时刻。
该文件的内容格式以及各字段的含义同/proc/<pid>/stat文件。
线程Cpu时间:
threadCpuTime = utime +stime注意,该文件中的tid字段表示的不再是进程号,而是linux中的轻量级进程(lwp),即我们通常所说的线程。
1、ps--显示当前进程的状态
s命令用于报告当前系统的进程状态。ps命令是最基本同时也是非常强大的进程查看命令,使用该命令可以确定有哪些进程正在运行和运行的状态、进程是否结束、进程有没有僵死、哪些进程占用了过多的资源等等,总之大部分信息都是可以通过执行该命令得到的。
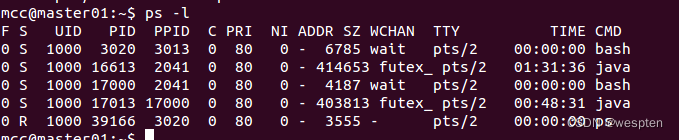
输出说明:
F 代表这个程序的旗标 (flag), 4 代表使用者为 super user;S 代表这个程序的状态 (STAT);PID 程序的 ID ;C CPU 使用的资源百分比PRI 这个是 Priority (优先执行序) 的缩写;NI 这个是 Nice 值。ADDR 这个是 kernel function,指出该程序在内存的那个部分。如果是个running # 的程序,一般就是『-』SZ 使用掉的内存大小;WCHAN 目前这个程序是否正在运作当中,若为 - 表示正在运作;TTY 登入者的终端机位置;TIME 使用掉的 CPU 时间。CMD 所下达的指令ps参数太多,具体使用方法可以参考man ps,常用的方法:
[root@localhost ~]# ps -efUID PID PPID C STIME TTY TIME CMDroot 1 0 0 09:26 ? 00:00:03 /usr/lib/systemd/systemd --switched-root --system --deserialize 21root 2 0 0 09:26 ? 00:00:00 [kthreadd]root 3 2 0 09:26 ? 00:00:00 [ksoftirqd/0]root 6 2 0 09:26 ? 00:00:00 [kworker/u256:0]root 7 2 0 09:26 ? 00:00:00 [migration/0]root 8 2 0 09:26 ? 00:00:00 [rcu_bh]root 9 2 0 09:26 ? 00:00:00 [rcuob/0]root 10 2 0 09:26 ? 00:00:00 [rcuob/1]root 11 2 0 09:26 ? 00:00:00 [rcuob/2]root 12 2 0 09:26 ? 00:00:00 [rcuob/3]root 13 2 0 09:26 ? 00:00:00 [rcuob/4]root 14 2 0 09:26 ? 00:00:00 [rcuob/5]root 15 2 0 09:26 ? 00:00:00 [rcuob/6]root 16 2 ps -aux可以看到进程占用CPU、内存情况:
[root@localhost ~]# ps -auxUSER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMANDroot 1 0.0 0.6 126124 6792 ? Ss 09:26 0:03 /usr/lib/systemd/systemd --switched-root --system --deserialize 21root 2 0.0 0.0 0 0 ? S 09:26 0:00 [kthreadd]root 3 0.0 0.0 0 0 ? S 09:26 0:00 [ksoftirqd/0]root 6 0.0 0.0 0 0 ? S 09:26 0:00 [kworker/u256:0]root 7 0.0 0.0 0 0 ? S 09:26 0:00 [migration/0]root 8 0.0 0.0 0 0 ? S 09:26 0:00 [rcu_bh]root 9 0.0 0.0 0 0 ? S 09:26 0:00 [rcuob/0]root 10 0.VSZ、RSS、TTY、STAT、 VIRT、RES、SHR、DATA的含义:
VSZ–进程的虚拟大小RSS–驻留集的大小,可以理解为内存中页的数量TTY–控制终端的IDSTAT–也就是当前进程的状态,其中S-睡眠,s-表示该进程是会话的先导进程,N-表示进程拥有比普通优先级更低的优先级,R-正在运行,D-短期等待,Z-僵死进程,T-被跟踪或者被停止等等STRAT–这个很简单,就是该进程启动的时间TIME–进程已经消耗的CPU时间,注意是消耗CPU的时间COMMOND–命令的名称和参数VIRT:virtual memory usage 虚拟内存
1、进程“需要的”虚拟内存大小,包括进程使用的库、代码、数据等
2、假如进程申请100m的内存,但实际只使用了10m,那么它会增长100m,而不是实际的使用量
RES:resident memory usage 常驻内存
1、进程当前使用的内存大小,但不包括swap out
2、包含其他进程的共享
3、如果申请100m的内存,实际使用10m,它只增长10m,与VIRT相反
4、关于库占用内存的情况,它只统计加载的库文件所占内存大小
SHR:shared memory 共享内存
1、除了自身进程的共享内存,也包括其他进程的共享内存
2、虽然进程只使用了几个共享库的函数,但它包含了整个共享库的大小
3、计算某个进程所占的物理内存大小公式:RES – SHR
4、swap out后,它将会降下来
DATA
1、数据占用的内存。如果top没有显示,按f键可以显示出来。
2、真正的该程序要求的数据空间,是真正在运行中要使用的。
杀掉某一程序的方法:
ps aux | grep mysqld | grep –v grep | awk ‘{print $2 }’ xargs kill -9杀掉僵尸进程:
ps –eal | awk ‘{if ($2 == “Z”){print $4}}’ | xargs kill -9查看单个进程的内存cpu:
ps -e -o 'pid,comm,args,pcpu,rsz,vsz,stime,user,uid'|grep Listen其中rsz是是实际内存。
这个命令首先指定参数'H',显示线程相关的信息,格式输出中包含:user,pid,ppid,tid,time,%cpu,cmd,然后再用%cpu字段进行排序。
这样就可以找到占用处理器的线程了。
直接使用 ps Hh -eo pid,tid,pcpu | sort -nk3 |tail 获取对于的进程号和线程号,然后查看哪个进程线程占用cpu过高; top / ps -aux, 获得进程号,确定哪个线程占用cpu过高,进入进程号的目录:/proc/pid/task,执行:grep SleepAVG **/status | sort -k2,2 | head, 确定cpu占用较高的线程号。
使用kill -3 pid 会打印线程堆栈的情况。
Linux查看进程/子进程/线程信息:
查看进程ID:
[root@QLB data]# ps -ef | grep mysqld | grep -v "grep"root 3988 1 0 Feb20 ? 00:00:00 /bin/sh /usr/local/mysql/bin/mysqld_safe --user=mysqlmysql 4256 3988 2 Feb20 ? 01:08:10 /usr/local/mysql/bin/mysqld --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data --plugin-dir=/usr/local/mysql/lib/plugin --user=mysql --log-error=/usr/local/mysql/data/QLB.err --pid-file=/usr/local/mysql/data/QLB.pid --socket=/tmp/mysqld.sock --port=3306查看某个进程的所有线程:
[root@QLB data]# ps mp 4256 -o THREAD,tidUSER %CPU PRI SCNT WCHAN USER SYSTEM TIDmysql 2.5 - - - - - -mysql 0.0 24 - - - - 4256mysql 0.0 14 - futex_ - - 4258mysql 0.0 23 - futex_ - - 4259mysql 0.0 24 - futex_ - - 4260mysql 0.0 24 - futex_ - - 4261mysql 0.0 23 - futex_ - - 4262mysql 0.0 24 - futex_ - - 4263mysql 0.0 24 - futex_ - - 4264mysql 0.0 24 - futex_ - - 4265mysql 0.0 24 - futex_ - - 4266mysql 0.0 24 - futex_ - - 4267mysql 0.0 24 - futex_ - - 4269mysql 0.0 24 - futex_ - - 4270mysql 0.0 21 - futex_ - - 4271mysql 0.0 24 - futex_ - - 4272mysql 0.0 20 - - - - 4273获取占用CPU资源最多的10个进程:
ps aux|head -1;ps aux|grep -v PID|sort -rn -k +3|head
获取占用内存资源最多的10个进程:
ps aux|head -1;ps aux|grep -v PID|sort -rn -k +4|headps -aux | sort -k4nr | head -K如果是10个进程,K=10,如果是最高的三个,K=3。
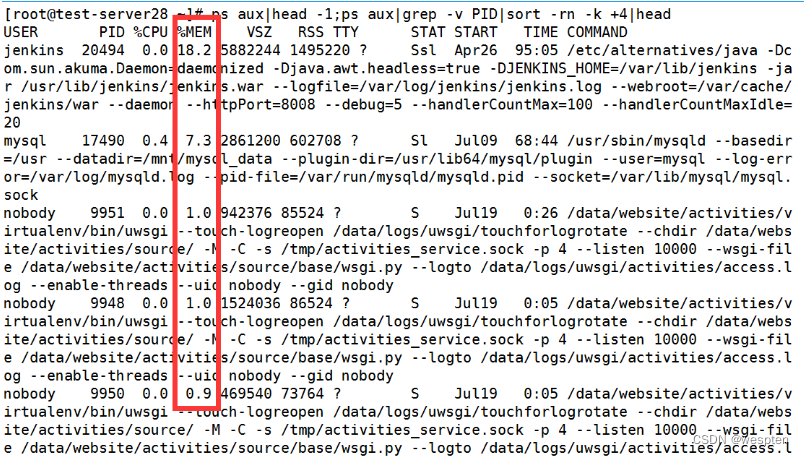
命令组合解释:
ps aux|head -1ps aux|grep -v PID|sort -rn -k +3|head其中第一句主要是为了获取标题(USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND)。
接下来的grep -v PID是将ps aux命令得到的标题去掉,即grep不包含PID这三个字母组合的行,再将其中结果使用sort排序。
sort -rn -k +3该命令中的-rn的r表示是结果倒序排列,n为以数值大小排序,而-k +3则是针对第3列的内容进行排序,再使用head命令获取默认前10行数据。(其中的|表示管道操作)
将 cpu 占用率高的线程找出来:
ps H -eo user,pid,ppid,tid,time,%cpu,cmd --sort=%cpups -e -o 'pid,comm,args,pcpu,rsz,vsz,stime,user,uid' | grep java | sort -nrk5系统中进程的监控pstree:

列出PID为3988的进程的进程状态树的命令:
[root@QLB data]# pstree -p 3988mysqld_safe(3988)───mysqld(4256)─┬─{mysqld}(4258) ├─{mysqld}(4259) ├─{mysqld}(4260) ├─{mysqld}(4261) ├─{mysqld}(4262) ├─{mysqld}(4263) ├─{mysqld}(4264) ├─{mysqld}(4265) ├─{mysqld}(4266) ├─{mysqld}(4267) ├─{mysqld}(4269) ├─{mysqld}(4270) ├─{mysqld}(4271) ├─{mysqld}(4272) └─{mysqld}(4273)kill命令的功能:把一个信号发送给一个或多个进程。默认发送终止信号。
终止PID为3852的进程的命令:
kill 3852
pgrep命令通过名称或其他属性查找进程:

pkill 命令通过名称或其他属性发信号杀死进程:
pkill -9 firefoxpmap命令用于报告进程的内存映射关系:
$ pmap -d 16613
ps使用总结
首先,得到进程的pid:
ps -ef | grep process_name | grep -v “grep” | awk ‘{print $2}’查看进程的所有线程:
# ps mp 6648 -o THREAD,tidUSER %CPU PRI SCNT WCHAN USER SYSTEM TIDroot 0.0 – - – - – -root 0.0 24 – - – - 6648root 0.0 21 – - – - 6650root 1.0 24 – - – - 14214root 0.0 23 – futex_ – - 14216root 0.0 22 – 184466 – - 15374root 0.0 23 – 184466 – - 15376root 0.0 23 – 184466 – - 15378root 0.0 23 – 184466 – - 15380root 0.0 23 – 184466 – - 15392root 0.0 23 – 184466 – - 15394root 0.0 23 – 184466 – - 15398查看所有子进程:
# pstree -p 6648agent_executor(6648)─┬─tar(15601)───gzip(15607)├─{agent_executor}(6650)├─{agent_executor}(14214)├─{agent_executor}(14216)├─{agent_executor}(15374)├─{agent_executor}(15376)├─{agent_executor}(15378)├─{agent_executor}(15380)├─{agent_executor}(15392)├─{agent_executor}(15394)└─{agent_executor}(15398)查看/proc/pid/status可以看到一些进程的当前状态:
Name: bashState: S (sleeping)SleepAVG: 98%Tgid: 11237Pid: 11237PPid: 11235TracerPid: 0Uid: 0 0 0 0Gid: 0 0 0 0FDSize: 256Groups: 0 1 2 3 4 6 10VmPeak: 66260 kBVmSize: 66228 kBVmLck: 0 kBVmHWM: 1684 kBVmRSS: 1684 kBVmData: 456 kBVmStk: 88 kBVmExe: 712 kBVmLib: 1508 kBVmPTE: 68 kBStaBrk: 008c3000 kBBrk: 011b1000 kBStaStk: 7fff8b728170 kBThreads: 1SigQ: 1/30222SigPnd: 0000000000000000ShdPnd: 0000000000000000SigBlk: 0000000000010000SigIgn: 0000000000384004SigCgt: 000000004b813efbCapInh: 0000000000000000CapPrm: 00000000fffffeffCapEff: 00000000fffffeffCpus_allowed: 00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000003Mems_allowed: 1监控Java线程数:
ps -eLf | grep java | wc -l查看java线程信息:
jstack pid | grep 'nid=0x9999' 上下文切换性能偏高(cs sy消耗比较高),定位:
jstack -l pid2、pidstat--监控系统资源情况
pidstat主要用于监控全部或指定进程占用系统资源的情况,如CPU、内存、设备IO、任务切换、线程等。
使用方法:
pidstat –d intervalpidstat还可以用以统计CPU使用信息:
pidstat –u interval统计内存信息:
pidstat –r intervalio消耗:
pidstat -d -t -p pid 1 100 3、IPCDump
IPCDump这款工具可以帮助广大研究人员在Linux操作系统上跟踪进程间通信(IPC)。该工具覆盖了大多数常见的IPC机制,比如说管道、FIFO、Unix套接字、基于环回的网络和伪终端等等。
该工具有助于研究和调试多进程引用程序,而且还可以帮助了解操作系统通信过程中不同组件之间的关联。IPCDump可以跟踪此通信的元数据和内容,它特别适合在短生命周期的进程之间跟踪IPC,而这种任务对于传统的调试工具来说比较困难,如strace或gdb。
它还有一些基本的过滤功能,可以帮助你筛选大量的事件。IPCDump收集的大部分信息来自放置在内核中关键函数的kprobes和跟踪点上的BPF钩子。为此,IPCDump使用了gobpf,它可以为bcc框架提供Golang绑定功能。
功能介绍
支持管道和FIFO;
回环IPC;
信号(常规和实时);
Unix流和数据图表;
基于伪终端的IPC;
基于进程PID或进程名的事件过滤器;
可读性高或JSON格式的输出数据;
4、strace
strace常用来跟踪进程执行时的系统调用和所接收的信号,帮助分析程序或命令执行中遇到的异常情况。Linux看进程不能直接访问硬件设备,当需要访问硬件设备(比如读取磁盘文件,接收网络数据等等)时,必须由用户态模式切换至内核态模式,通过系统调用访问硬件设备。strace可以跟踪到一个进程产生的系统调用,包括参数,返回值,执行消耗的时间。
参数:
-c 统计每一系统调用的所执行的时间,次数和出错的次数等. -d 输出strace关于标准错误的调试信息. -f 跟踪由fork调用所产生的子进程. -ff 如果提供-o filename,则所有进程的跟踪结果输出到相应的filename.pid中,pid是各进程的进程号. -F 尝试跟踪vfork调用.在-f时,vfork不被跟踪. -h 输出简要的帮助信息. -i 输出系统调用的入口指针. -q 禁止输出关于脱离的消息. -r 打印出相对时间关于,,每一个系统调用. -t 在输出中的每一行前加上时间信息. -tt 在输出中的每一行前加上时间信息,微秒级. -ttt 微秒级输出,以秒了表示时间. -T 显示每一调用所耗的时间. -v 输出所有的系统调用.一些调用关于环境变量,状态,输入输出等调用由于使用频繁,默认不输出. -V 输出strace的版本信息. -x 以十六进制形式输出非标准字符串 -xx 所有字符串以十六进制形式输出.-a column 设置返回值的输出位置.默认 为40. -e expr 指定一个表达式,用来控制如何跟踪-o filename 将strace的输出写入文件filename -p pid 跟踪指定的进程pid. 一般用于跟踪后台程序-s strsize 指定输出的字符串的最大长度.默认为32. -u username 以username 的UID和GID执行被跟踪的命令跟踪nginx, 看其启动时都访问了哪些文件:
strace -tt -T -f -e trace=file -o /data/log/strace.log -s 1024 2>&1 ./nginx定位程序异常退出:
strace -ttf -T -p 10893 -o tmp -e trace=process 2>&1程序启动加载文件:
strace -e open,acces ./sh 2>&1 | grep fileName查选程序耗时:
strace -c -p 11084链接服务器失败:
strace -e poll,select,connect,recvfrom,sendto nc www.baidu.com 80查看mysqld在linux上加载哪种配置文件:
strace –e stat64 mysqld –print –defaults > /dev/nullphp线程执行时执行的系统函数:
[on@B4471 ~]$ ps -ef | grep phproot 10984 1 0 19:13 ? 00:00:00 php-fpm: master process (/opt/soft/php7/etc/php-fpm.conf)www 10985 10984 0 19:13 ? 00:00:00 php-fpm: pool www www 10986 10984 0 19:13 ? 00:00:00 php-fpm: pool www#追踪线程 10985,如下会列出执行过程中的系统调用函数[on@B4471 ~]$ strace -p 10985 fstat(10, {st_mode=S_IFREG|0644, st_size=0, ...}) = 0lseek(10, 0, SEEK_CUR) = 0write(10, "{\"url\":\"http:\\/\\/newapi.shouji.b"..., 3790) = 3790close(10) = 0chdir("/home/onlinedev") = -1 EACCES (Permission denied)times({tms_utime=3, tms_stime=0, tms_cutime=0, tms_cstime=0}) = 3013530754setitimer(ITIMER_PROF, {it_interval={0, 0}, it_value={0, 0}}, NULL) = 0fcntl(3, F_SETLK, {type=F_UNLCK, whence=SEEK_SET, start=0, len=0}) = 0write(4, "\1\6\0\1\0\6\2\0000\"}}]}\0\0\1\3\0\1\0\10\0\0\0\0\0\0\0.10", 32) = 32shutdown(4, SHUT_WR) = 0recvfrom(4, "\1\5\0\1\0\0\0\0", 8, 0, NULL, NULL) = 8recvfrom(4, "", 8, 0, NULL, NULL) = 0close(4) = 0munmap(0x7f7838000000, 2097152) = 0setitimer(ITIMER_PROF, {it_interval={0, 0}, it_value={0, 0}}, NULL) = 0accept(0,常见系统调用函数列表如下:
fork 创建一个新进程 clone 按指定条件创建子进程 execve 运行可执行文件 exit 中止进程 nanosleep 使进程睡眠指定的时间 pause 挂起进程,等待信号 wait 等待子进程终止 waitpid 等待指定子进程终止 socket 建立socket bind 绑定socket到端口 connect 连接远程主机 accept 响应socket连接请求 send 通过socket发送信息 recv 通过socket接收信息 mmap 映射虚拟内存页munmap 去除内存页映射 mremap 重新映射虚拟内存地址 msync 将映射内存中的数据写回磁盘 listen 监听socket端口 select 对多路同步I/O进行轮询 shutdown 关闭socket上的连接 readv 从文件读入数据到缓冲数组中 writev 将缓冲数组里的数据写入文件 pread 对文件随机读 pwrite 对文件随机写 lseek 移动文件指针 dup 复制已打开的文件描述字 flock 文件加/解锁 poll I/O多路转换 truncate 截断文件 另外strace的-e trace选项详细-e trace=file 跟踪和文件访问相关的调用(参数中有文件名)-e trace=process 和进程管理相关的调用,比如fork/exec/exit_group-e trace=network 和网络通信相关的调用,比如socket/sendto/connect-e trace=signal 信号发送和处理相关,比如kill/sigaction-e trace=desc 和文件描述符相关,比如write/read/select/epoll等-e trace=ipc 进程见同学相关,比如shmget等5、lsof
lsof(list open files)是一个列出当前系统打开文件的工具。通过lsof工具能够查看这个列表对系统检测及排错。
常见的用法
查看文件系统阻塞:
lsof /boot查看端口号被哪个进程占用:
lsof -i : 3306查看用户打开哪些文件:
lsof –u username查看进程打开哪些文件:
lsof –p 4838查看远程已打开的网络链接:
lsof –i @192.168.34.1286、perf
perf是Linux kernel自带的系统性能优化工具。优势在于与Linux Kernel的紧密结合,它可以最先应用到加入Kernel的new feature,用于查看热点函数,查看cashe miss的比率,从而帮助开发者来优化程序性能。
性能调优工具如 perf,Oprofile 等的基本原理都是对被监测对象进行采样,最简单的情形是根据 tick 中断进行采样,即在 tick 中断内触发采样点,在采样点里判断程序当时的上下文。假如一个程序 90% 的时间都花费在函数 foo() 上,那么 90% 的采样点都应该落在函数 foo() 的上下文中。运气不可捉摸,但我想只要采样频率足够高,采样时间足够长,那么以上推论就比较可靠。因此,通过 tick 触发采样,我们便可以了解程序中哪些地方最耗时间,从而重点分析。
7、perf_events
一款随 Linux 内核代码一同发布和维护的性能诊断工具,由内核社区维护和发展。
Perf 不仅可以用于应用程序的性能统计分析,也可以应用于内核代码的性能统计和分析。
8、eBPF tools
一款使用bcc进行的性能追踪的工具,eBPF map可以使用定制的eBPF程序被广泛应用于内核调优方面,也可以读取用户级的异步代码。
重要的是这个外部的数据可以在用户空间管理。这个k-v格式的map数据体是通过在用户空间调用bpf系统调用创建、添加、删除等操作管理的。
9、perf-tools
一款基于 perf_events (perf) 和 ftrace 的Linux性能分析调优工具集。Perf-Tools 依赖库少,使用简单。支持Linux 3.2 及以上内核版本。
GitHub - brendangregg/perf-tools: Performance analysis tools based on Linux perf_events (aka perf) and ftrace
10、bcc(BPF Compiler Collection)
一款使用eBPF的perf性能分析工具。一个用于创建高效的内核跟踪和操作程序的工具包,包括几个有用的工具和示例。利用扩展的BPF(伯克利数据包过滤器),正式称为eBPF,一个新的功能,首先被添加到Linux 3.15。多用途需要Linux 4.1以上BCC。
GitHub - iovisor/bcc: BCC - Tools for BPF-based Linux IO analysis, networking, monitoring, and more
11、ktap
一种新型的linux脚本动态性能跟踪工具。允许用户跟踪Linux内核动态。ktap是设计给具有互操作性,允许用户调整操作的见解,排除故障和延长内核和应用程序。它类似于Linux和Solaris DTrace SystemTap。
GitHub - ktap/ktap: A lightweight script-based dynamic tracing tool for Linux
12、Flame Graphs
是一款使用perf,system tap,ktap可视化的图形软件,允许最频繁的代码路径快速准确地识别。
https://github.com/brendangregg/flamegraph
六、Linux磁盘IO状态分析
在Linux中,我们可以通过一些工具分析磁盘I/O子系统的使用情况,展示那些磁盘或分区已被使用,每个磁盘处理了多少I/O,发给这些磁盘的I/O请求要等多久才被处理。
磁盘I/O介绍
在学习性能工具之前,我们来了解Linux磁盘I/O系统是怎样构成的。
大多数现代Linux系统都有一个或多个磁盘驱动。SCSI驱动则常常被命名为sda、sdb、sdc等。
┌──[root@vms81.liruilongs.github.io]-[/]└─$lsblkNAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTsda 8:0 0 200G 0 disk|-sda1 8:1 0 150G 0 part /`-sda2 8:2 0 10G 0 part磁盘通常要分为多个分区,分区设备名称的创建方法是在基础驱动名称的后面直接添加分区编号。
一般每个独立分区要么包含一个文件系统,要么包含一个交换分区。当然也可以是一个VDO卷,分区被挂载到Linux文件系统,由/etc/fstab指定。
在Linux 中,我们可以直接对磁盘进行分区,使用文件系统格式化,也使用LVM的方式来使用管理磁盘,大多数情况下,是通过LVM来管理Linux存储。利用LVM,化零为整,可以对数据卷进行统一分配,动态扩容。
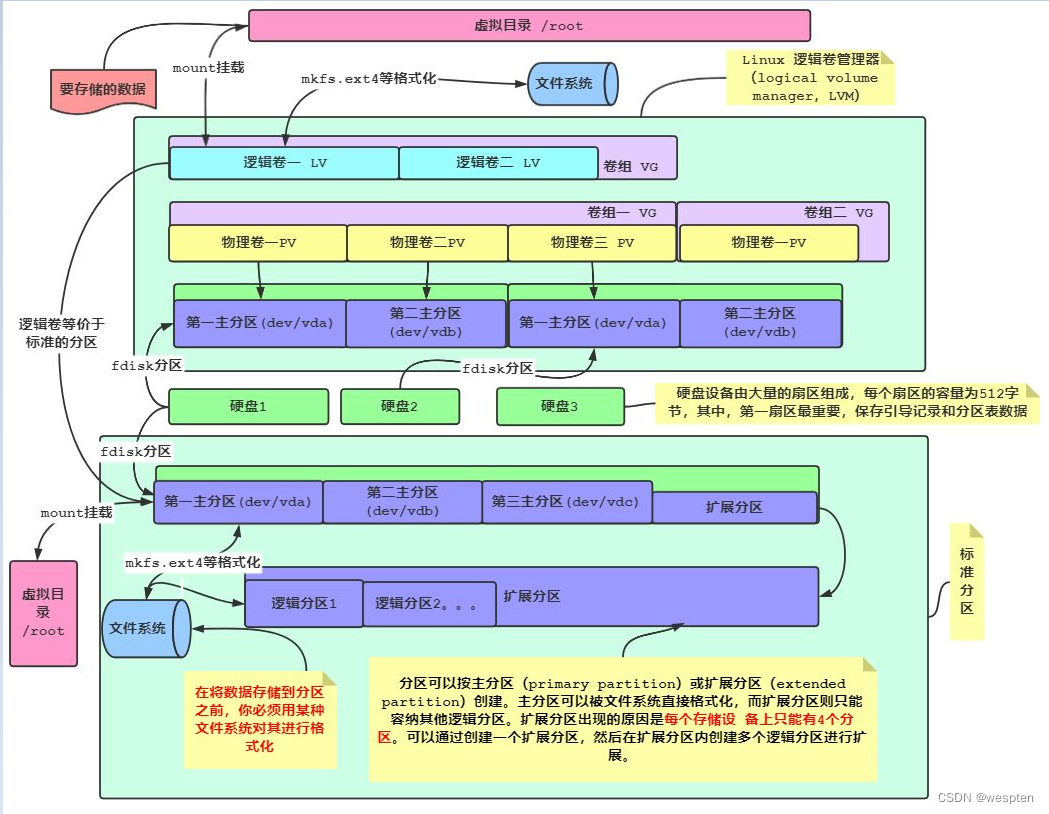
分区或者逻辑卷被指定文件系统格式化后,挂载目录。即可存放应用程序要读写的文件。
当一个应用程序进行读写时,Linux内核可以在其高速缓存或缓冲区中保存文件的副本,并且可以在不访问磁盘的情况下返回被请求的信息。但是,如果Linux内核没有在内存中保存数据副本,那它就向磁盘 I/O 队列添加一个请求。
若Linux内核注意到多个请求都指向磁盘内相邻的区域,它会把它们合并为一个大的请求。这种合并能消除第二次请求的寻道时间, 以此来提高磁盘整体性能。
当请求被放入磁盘队列,而磁盘当前不忙时,它就开始为IO请求服务。如果磁盘正忙,则请求就在队列中等待,直到该设备可用,请求将被服务。这里的等待,即我们在编程中讲的IO阻塞,尤其在涉及的并发的问题中,我们常常要考虑线程I/O阻塞情况来调整线程优先级,Java在JDK1.4 的版本中,提供NIO(采用内存映射文件的方式处理,将文件或文件的一段区域映射到内存中)来提高访问效率。
磁盘I/O分析工具
Linux 服务器在使用过程中可能会遇到各种问题,其中之一就是“没有可用空间”。
遇到这种情况,就需要进行排查,定位到消耗了磁盘的那个文件夹。
1、df
df -h 会显示各分区所有挂载点的磁盘空间使用情况。-h 表示以 1k、1M、1G 为单位。
Filesystem(文件系统) Size Used Avail Use% Mounted on(分区)/dev/mapper/centos-root 98G 6.1G 92G 7% /devtmpfs 4.8G 0 4.8G 0% /devtmpfs 4.9G 0 4.9G 0% /dev/shmtmpfs 4.9G 33M 4.8G 1% /runtmpfs 4.9G 0 4.9G 0% /sys/fs/cgroup/dev/sda1 1014M 189M 826M 19% /boottmpfs 984M 0 984M 0% /run/user/0overlay 98G 6.1G 92G 7% /var/lib/docker/overlay2/8671cfef128ee6418ab1796ebba47b23283fdf1d338431b4a4ebdc2786485000/mergedshm 64M 0 64M 0% /var/lib/docker/containers/d945d7043afb824a94ab8e11c3f61354945e40602b0212eb6cd1a794a5c2c475/mounts/shmoverlay 98G 6.1G 92G 7% /var/lib/docker/overlay2/c24f633841568bb4672931f2da809b47335be7f085bf23237af2cd15bddc27a1/mergedshm 64M 0 64M 0% /var/lib/docker/containers/e685309b470dde35837620928ba67d404722c4bba475f84ed0cb6ca823504907/mounts/shmoverlay 98G 6.1G 92G 7% /var/lib/docker/overlay2/62cc31effdbb439942c43f1341b6b07fd933200b6c27a52c6a88ac4b63ae93e6/mergedshm 64M 0 64M 0% /var/lib/docker/containers/7f7593fc8d14ddbe7dd1a946ccf08adf2bef415a7560db1c12d0ab0abb9e582a/mounts/shm可以看到主分区 / 已经使用了 7%,现在假设因为某个软件的缓存,导致这个分区 / 的可用空间不多了。现在要排查到缓存所在位置。
更多磁盘分区查看命令:
mount column -t # 查看挂接的分区状态fdisk -l # 查看所有分区 swapon -s # 查看所有交换分区 hdparm -i /dev/hda # 查看磁盘参数(仅适用于IDE设备) dmesg grep IDE # 查看启动时IDE设备检测状况swapon -s:
[root@localhost proc]# swapon -s文件名 类型 大小 已用 权限/dev/dm-1 partition 2097148 8 -12、du
df 是查看各挂载点的空间使用情况,而 du 是用于查看各目录/文件的大小。
du -sh <目录名> 查看指定目录的大小:
du -sh /root1.2G /root我们需要找到 / 分区中真正消耗掉内存的那个文件/文件夹:
[root@192-168-1-64 ~]# du -h --max-depth=1157M ./boot0 ./devdu: cannot access './proc/12646/task/12646/fd/4': No such file or directorydu: cannot access './proc/12646/task/12646/fdinfo/4': No such file or directorydu: cannot access './proc/12646/fd/4': No such file or directorydu: cannot access './proc/12646/fdinfo/4': No such file or directory0 ./proc33M ./run0 ./sys34M ./etc26M ./root4.5G ./var0 ./tmp1.6G ./usr0 ./home0 ./media0 ./mnt2.6G ./opt0 ./srv8.8G .在输出结果中找到占用磁盘过多的文件夹,cd 进去,再继续执行 du -h --max-depth=1 命令查看。
如此查看几次,一般就能定位到问题文件夹。定位到问题后,再依据该数据的重要程度,来决定是直接清空,还是如何处理它。
3、vmstat
vmstat是一个强大的工具,它能给出系统在性能方面的总览图。除了CPU和内存统计信息之外,vmstat还可以提供系统整体上的I/O性能情况。
使用的版本:
┌──[root@vms81.liruilongs.github.io]-[/]└─$vmstat -Vvmstat from procps-ng 3.3.10┌──[root@vms81.liruilongs.github.io]-[/]└─$which vmstat/usr/bin/vmstatvmstat超过其他I/O工具的主要优势是:几乎所有的Linux发行版本都包含该工具。同时 vmstat提供的扩展磁盘统计信息只用于内核版本高于2.5.70的Linux系统。
磁盘I/O性能相关的选项和输出
在使用vmstat从系统获取磁盘1/0统计信息时,要按照如下方式进行调用:
vmstat [-D] [-d] [-p partition] [interval [count]]命令行选项:
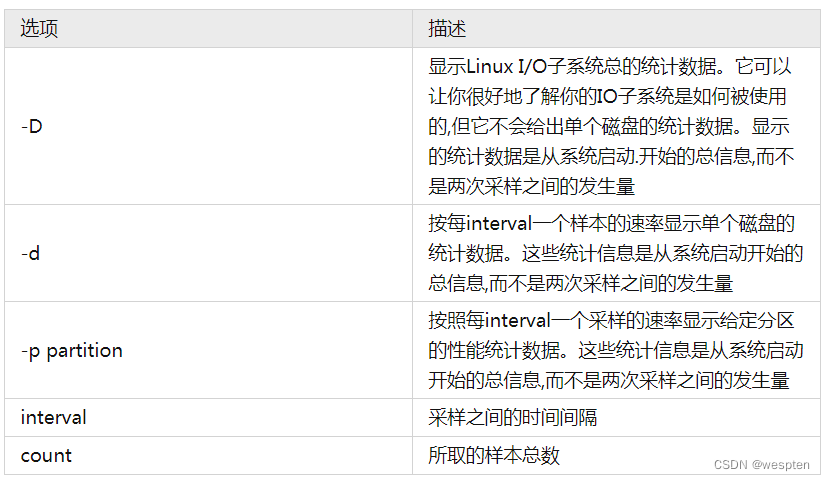
整个系统的IO统计数据
在用-D模式运行时, vmstat提供的是系统内磁盘10系统的总体统计数据。
┌──[root@vms81.liruilongs.github.io]-[/]└─$vmstat -D 1 disks 2 partitions 14661 total reads 33 merged reads 3369384 read sectors 16091 milli reading 521150 writes 5093 merged writes 5189564 written sectors 110797 milli writing 0 inprogress IO 86 milli spent IO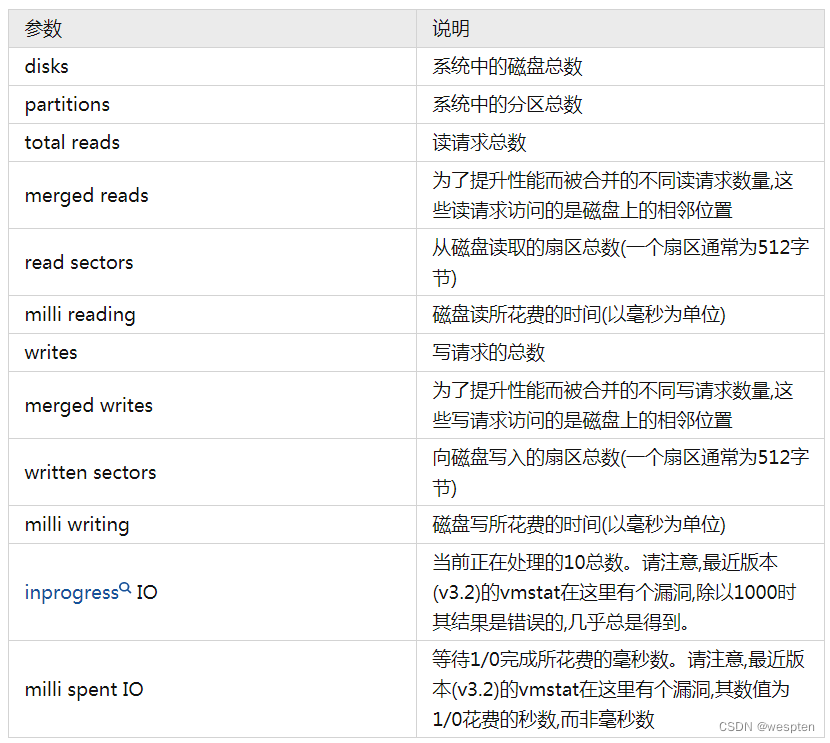
整个系统的IO性能情况
如果你在运行vmstat时只使用了[interval]和[count]参数,其他参数没有使用,那么显示的就是默认输出。该输出中包含了三列与磁盘1/0性能相关的内容: bo, bi和wa:
┌──[root@vms81.liruilongs.github.io]-[/]└─$vmstat 1 2procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 1 0 0 243708 2072 1748600 0 0 13 21 55 107 2 3 95 0 0 0 0 0 242768 2072 1748604 0 0 0 32 3352 5026 4 3 93 0 0┌──[root@vms81.liruilongs.github.io]-[/]└─$
使用vmstat取样3个样本,时间间隔为1秒:
┌──[root@vms81.liruilongs.github.io]-[/]└─$vmstat 1 3procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 1 0 0 209244 2072 1751828 0 0 13 20 88 160 2 3 95 0 0 0 0 0 209040 2072 1751828 0 0 0 12 3182 4760 2 3 95 0 0 0 0 0 209028 2072 1751828 0 0 0 58 3053 4668 2 3 96 0 0┌──[root@vms81.liruilongs.github.io]-[/]└─$我们可以看到,在第一秒的时候,io读取13块,写入了20块,第二读取0,写入12块,磁盘块的大小为1024字节,即系统读取速率为13/1024,等待IO的时间为O,说明当前系统IO读写空闲。
每个磁盘的统计信息
vmstat的-d选项显示的是每一个磁盘的I/O统计信息。这些统计数据与-D选项的数据类似:
┌──[root@vms81.liruilongs.github.io]-[/]└─$vmstat -ddisk- ------------reads------------ ------------writes----------- -----IO------ total merged sectors ms total merged sectors ms cur secsda 14661 33 3369384 16091 523799 5120 5213233 111242 0 86
[root@foundation0 ~]# vmstat -d 1 2disk- ------------reads------------ ------------writes----------- -----IO------ total merged sectors ms total merged sectors ms cur secnvme0n1 72865 5 6560405 54580 138514 1015 6715558 94026 0 149sr0 0 0 0 0 0 0 0 0 0 0loop0 49 0 2308 10 0 0 0 0 0 0loop1 93 0 19822 146 0 0 0 0 0 0loop2 77 0 3764 20 0 0 0 0 0 0loop3 88 0 20882 73 0 0 0 0 0 0loop4 463 0 64058 1904 0 0 0 0 0 0nvme0n1 72865 5 6560405 54580 138514 1015 6715558 94026 0 149sr0 0 0 0 0 0 0 0 0 0 0loop0 49 0 2308 10 0 0 0 0 0 0loop1 93 0 19822 146 0 0 0 0 0 0loop2 77 0 3764 20 0 0 0 0 0 0loop3 88 0 20882 73 0 0 0 0 0 0loop4 463 0 64058 1904 0 0 0 0 0 0[root@foundation0 ~]#统计磁盘分区的读写情况
┌──[root@vms81.liruilongs.github.io]-[/]└─$vmstat -p sda1 1 3sda1 reads read sectors writes requested writes 15036 3381024 545880 5414724 15036 3381024 545894 5414837 15036 3381024 545895 5414846上面我们可以看到,对于sda1物理分区来讲,有14(545880-545894)个写提交了。
虽然vmstat提供了单个磁盘/分区的统计信息,但是它只给出其总量,却不给出在采样过程中的变化率。因此,要分辨哪个设备的统计数据在采样期间发生了明显的变化就显得很困难。
4、iostat
iostat与vmstat相似,但它是一个专门用于显示磁盘1/0子系统统计信息的工具。
iostat提供的信息细化到每个设备和每个分区从特定磁盘读写了多少个块。(iostat中块大小一般为512字节。)
此外,iostat还可以提供大量的信息来显示磁盘是如何被利用的,以及Linux花费了多长时间来等待将请求提交到磁盘。
磁盘I/O性能相关的选项和输出
iostat用如下命令行调用:
iostat[参数][时间][次数]与vmstat很相似,iostat可以定期显示性能统计信息:
-C 显示CPU使用情况-d 显示磁盘使用情况-k 以 KB 为单位显示-m 以 M 为单位显示-N 显示磁盘阵列(LVM) 信息-n 显示NFS 使用情况-p[磁盘] 显示磁盘和分区的情况-t 显示终端和CPU的信息-x 显示详细信息-V 显示版本信息每隔2秒刷新显示,且显示3次:
iostat 2 3显示指定磁盘信息:
iostat -d /dev/sda显示tty和Cpu信息:
iostat -t以M为单位显示所有信息:
iostat -m查看设备使用率(%util)、响应时间(await):
iostat -d -x -k 1 1查看cpu状态:
iostat -c 1 1iostat设备统计信息:
[root@CT1186 ~]# iostatLinux 2.6.18-128.el5 (CT1186) 2012年12月28日avg-cpu: %user %nice %system %iowait %steal %idle 8.30 0.02 5.07 0.17 0.00 86.44Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtnsda 22.73 43.70 487.42 674035705 7517941952sda1 0.00 0.00 0.00 2658 536sda2 0.11 3.74 3.51 57721595 54202216sda3 0.98 0.61 17.51 9454172 270023368sda4 0.00 0.00 0.00 6 0sda5 6.95 0.12 108.73 1924834 1677123536sda6 2.20 0.18 31.22 2837260 481488056sda7 12.48 39.04 326.45 602094508 5035104240cpu属性值说明:
%user:CPU处在用户模式下的时间百分比。%nice:CPU处在带NICE值的用户模式下的时间百分比。%system:CPU处在系统模式下的时间百分比。%iowait:CPU等待输入输出完成时间的百分比。%steal:管理程序维护另一个虚拟处理器时,虚拟CPU的无意识等待时间百分比。%idle:CPU空闲时间百分比。备注:
如果%iowait的值过高,表示硬盘存在I/O瓶颈。
如果%idle值高,表示CPU较空闲。
如果%idle值高但系统响应慢时,可能是CPU等待分配内存,应加大内存容量。
如果%idle值持续低于cpu核数,表明CPU处理能力相对较低,系统中最需要解决的资源是CPU。

┌──[root@vms81.liruilongs.github.io]-[/]└─$iostat -d 1 3Linux 3.10.0-693.el7.x86_64 (vms81.liruilongs.github.io) 06/14/22 _x86_64_ (2 CPU)Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtnsda 8.17 24.33 39.40 1694756 2744300Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtnsda 9.00 0.00 37.00 0 37Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtnsda 0.00 0.00 0.00 0 0┌──[root@vms81.liruilongs.github.io]-[/]└─$当你使用-x参数调用iostat时,它会显示更多关于磁盘I/O子系统的统计信息:
┌──[root@vms81.liruilongs.github.io]-[/]└─$iostat -x -dk 1 3 /dev/sda1Linux 3.10.0-693.el7.x86_64 (vms81.liruilongs.github.io) 06/14/22 _x86_64_ (2 CPU)Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %utilsda1 0.00 0.08 0.22 7.96 24.21 39.39 15.57 0.00 0.23 1.10 0.21 0.16 0.13Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %utilsda1 0.00 0.00 0.00 15.00 0.00 60.00 8.00 0.00 0.27 0.00 0.27 0.27 0.40Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %utilsda1 0.00 0.00 0.00 8.00 0.00 32.00 8.00 0.00 0.25 0.00 0.25 0.25 0.20┌──[root@vms81.liruilongs.github.io]-[/]└─$显示扩展的设备统计:

第一行显示的是自系统启动以来的平均值,然后显示增量的平均值,每个设备一行。
常见linux的磁盘IO指标的缩写习惯:rq是request,r是read,w是write,qu是queue,sz是size,a是verage,tm是time,svc是service。
iostat的扩展磁盘统计信息:

简要说明:
rrqm/s: 每秒进行 merge 的读操作数目。即 rmerge/swrqm/s: 每秒进行 merge 的写操作数目。即 wmerge/sr/s: 每秒完成的读 I/O 设备次数。即 rio/sw/s: 每秒完成的写 I/O 设备次数。即 wio/srsec/s: 每秒读扇区数。即 rsect/swsec/s: 每秒写扇区数。即 wsect/srkB/s: 每秒读K字节数。是 rsect/s 的一半,因为每扇区大小为512字节。wkB/s: 每秒写K字节数。是 wsect/s 的一半。avgrq-sz: 平均每次设备I/O操作的数据大小 (扇区)。avgqu-sz: 平均I/O队列长度。await: 平均每次设备I/O操作的等待时间 (毫秒)。svctm: 平均每次设备I/O操作的服务时间 (毫秒)。%util: 一秒中有百分之多少的时间用于 I/O 操作,即被io消耗的cpu百分比备注:
如果%util 接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈。
如果 svctm 比较接近 await,说明 I/O 几乎没有等待时间。
如果 await 远大于 svctm,说明I/O 队列太长,io响应太慢,则需要进行必要优化。
如果avgqu-sz比较大,也表示有当量io在等待。
当avgqu-sz的值特别大的时候,且请求等待时间await远远高于请求服务svctm所花费时间,且利用率%util为100%的时候,表明该磁盘处于饱和状态。
%util高 应用延迟高案例:
经过长时间监控,发现iostat 中的%util居高不下,一直在98%上下,说明带宽占用率极高,遇到了瓶颈。且读写速度很慢,经过排查,发现是HBA卡出现问题,更换后,用dd if命令测试,磁盘的读写速度均得到了10倍以上的提升。
但更换HBA卡后,虽然读写速度上去了,但应用还是有延迟,数据库日志中SQL语句都在毫秒级别,最后重启服务器,后正常。
重启后,%util也降下来了,但时间一长又会提高。最终通过扩展内存的方式,%util恢复正常。
注意:
在判断磁盘是否达到极限性能时,只通过 iostat -x 中的 %util 指标来确认磁盘是否带宽带宽或IOPS瓶颈,其实这是不对的。
磁盘是否达到真正极限瓶颈,需要参考通过fio等工具压测出的极限带宽和IOPS值。
%util表示该设备有I/O(即非空闲)的时间比率,不考虑I/O有多少,只考虑有没有。
由于现代硬盘设备都有并行处理多个I/O请求的能力,所以%util即使达到100%也不意味着设备饱和了。
举个简化的例子:某硬盘处理单个I/O需要0.1秒,有能力同时处理10个I/O请求,那么当10个I/O请求依次顺序提交的时候,需要1秒才能全部完成,在1秒的采样周期里%util达到100%;而如果10个I/O请求一次性提交的话,0.1秒就全部完成,在1秒的采样周期里%util只有10%。
可见,即使%util高达100%,硬盘也仍然有可能还有余力处理更多的I/O请求,即没有达到饱和状态。
5、sar
sar可以收集Linux系统多个不同方面的性能统计信息。除了CPU和内存之外,它还可以收集关于磁盘I/O子系统的信息。
磁盘I/O性能相关的选项和输出
当使用sar 来监视磁盘I/O统计数据时,你可以用如下命令行来调用它:
sar -d [interval [count] ]通常,sar显示的是系统中CPU使用的相关信息。若要显示磁盘使用情况的统计信息,你必须使用-d选项。sar只能在高于2.5.70的内核版本中显示磁盘I/O统计数据。
显示信息进行了说明:
┌──[root@vms81.liruilongs.github.io]-[/]└─$sar -d 1 3Linux 3.10.0-693.el7.x86_64 (vms81.liruilongs.github.io) 06/14/22 _x86_64_ (2 CPU)23:31:21 DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util23:31:22 dev8-0 7.00 0.00 56.00 8.00 0.00 0.29 0.29 0.2023:31:22 DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util23:31:23 dev8-0 1.00 0.00 10.00 10.00 0.00 0.00 0.00 0.0023:31:23 DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util23:31:24 dev8-0 12.00 0.00 96.00 8.00 0.00 0.33 0.25 0.30Average: DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %utilAverage: dev8-0 6.67 0.00 54.00 8.10 0.00 0.30 0.25 0.17┌──[root@vms81.liruilongs.github.io]-[/]└─$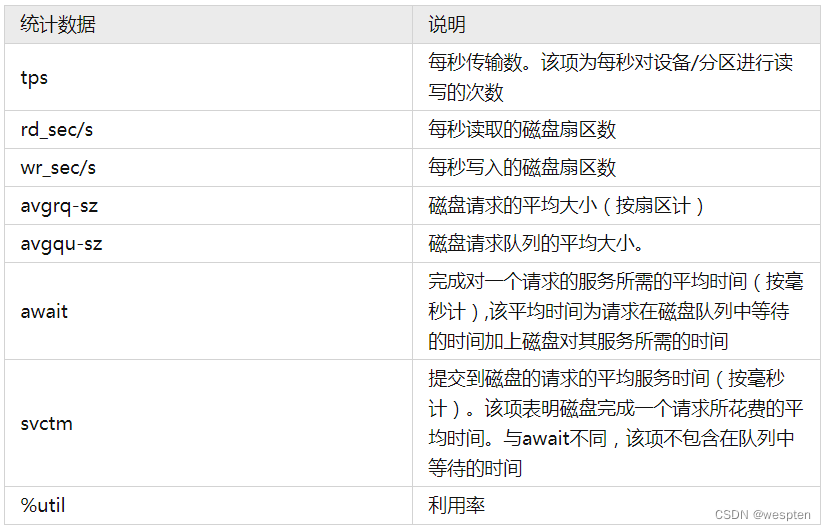
查看磁盘历史IO信息:
sar -d 1 1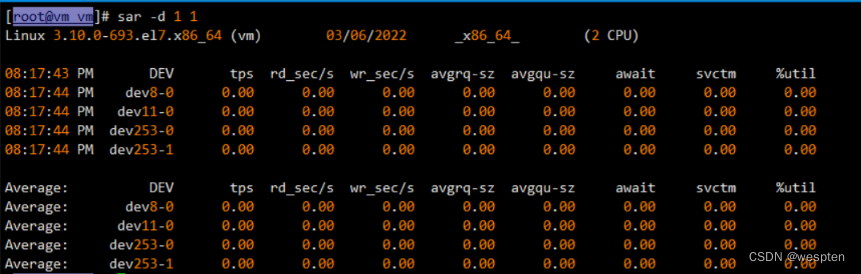
6、 lsof(列出打开文件)
lsof提供了一种方法来确定哪些进程打开了一个特定的文件。除了跟踪单个文件的用户外,lsof还可以显示使用了特定目录下文件的进程。同时,它还可以递归搜索整个目录树,并列出使用了该目录树内文件的进程。在要筛选哪些应用程序产生了I/O时,lsof是很有用的。
磁盘I/O性能相关的选项和输出
你可以使用如下命令行调用lsof来找出进程打开了哪些文件:
1sof [-r delay] [+D directory] [+d directory] [file]┌──[root@vms81.liruilongs.github.io]-[/]└─$yum -y install lsof通常,lsof显示的是使用给定文件的进程。但是,通过使用+d和+D选项,它可以显示多个文件的相关信息。表6-10解释了1sof的命令行选项,它们可用于追踪I/O性能问题。
lsof 命令行选项:
┌──[root@vms81.liruilongs.github.io]-[/]└─$lsof -r 2 +D /usr/bin/COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAMEdbus-daem 539 dbus txt REG 8,1 442080 268592945 /usr/bin/dbus-daemonVGAuthSer 544 root txt REG 8,1 128488 268979997 /usr/bin/VGAuthServicevmtoolsd 545 root txt REG 8,1 48976 268980000 /usr/bin/vmtoolsdfirewalld 636 root txt REG 8,1 7136 268591652 /usr/bin/python2.7tuned 951 root txt REG 8,1 7136 268591652 /usr/bin/python2.7kubelet 957 root txt REG 8,1 153350040 270317939 /usr/bin/kubeletcontainer 961 root txt REG 8,1 48766984 268964765 /usr/bin/containerddockerd 1073 root txt REG 8,1 96765968 268963237 /usr/bin/dockerdcontainer 1735 root txt REG 8,1 8617984 268592410 /usr/bin/containerd-shim-runc-v2container 1782 root txt REG 8,1 8617984 268592410 /usr/bin/containerd-shim-runc-v2container 1853 root txt REG 8,1 8617984 268592410 /usr/bin/containerd-shim-runc-v 
可以通过DEVICE来查看对应的设备位置:
┌──[root@vms81.liruilongs.github.io]-[/]└─$ls -la /dev/ | grep sdbrw-rw---- 1 root disk 8, 0 Jun 12 14:58 sdabrw-rw---- 1 root disk 8, 1 Jun 12 14:58 sda1brw-rw---- 1 root disk 8, 2 Jun 12 14:58 sda2┌──[root@vms81.liruilongs.github.io]-[/]└─$当我们通过前面的命令确定了饱和的磁盘设备。那么我们可以通过lsof来根据磁盘找到对应的文件,从而确认对应的PID。
7、iotop
iotop命令是一个专门用来监视磁盘I/O使用状况的top类工具。是一个用来监视磁盘I/O使用状况的top类工具,具有与top相似的UI,其中包括PID、用户、I/O、进程等相关信息。
Linux下的IO统计工具如iostat,nmon等大多数是只能统计到per设备的读写情况,如果你想知道每个进程是如何使用IO的就比较麻烦,iotop可以显示IO负载具体是由哪个进程产生的。
可以以非交互的方式使用:iotop –bod interval,查看每个进程的I/O,可以使用pidstat,pidstat –d instat。
与iostat工具比较,iostat是系统级别的IO监控,而iotop是进程级别IO监控。
yum -y install iotop命令行选项:
• --version #显示版本号• -h, --help #显示帮助信息• -o, --only #显示进程或者线程实际上正在做的I/O,而不是全部的,可以随时切换按o• -b, --batch #运行在非交互式的模式• -n NUM, --iter=NUM #在非交互式模式下,设置显示的次数,• -d SEC, --delay=SEC #设置显示的间隔秒数,支持非整数值• -p PID, --pid=PID #只显示指定PID的信息• -u USER, --user=USER #显示指定的用户的进程的信息• -P, --processes #只显示进程,一般为显示所有的线程• -a, --accumulated #显示从iotop启动后每个线程完成了的IO总数• -k, --kilobytes #以千字节显示• -t, --time #在每一行前添加一个当前的时间• -q, --quiet #suppress some lines of header (implies --batch). This option can be specified up to three times to remove header lines.• -q column names are only printed on the first iteration,• -qq column names are never printed,• -qqq the I/O summary is never printed.iotop快捷键:
• 左右箭头 #改变排序方式,默认是按IO排序• r #改变排序顺序• o #只显示有IO输出的进程• p #进程/线程的显示方式的切换• a #显示累积使用量• q #退出使用:
$ iotop –b –n 3 –d 5
注:DISK TEAD:n=磁盘读/每秒 DISK WRITE:n=磁盘写/每秒。标黄的可查看磁盘的读写速率,下面可以看到使用的io。
查看当前磁盘IO读写:
sar -b 1 1019时54分35秒 tps rtps wtps bread/s bwrtn/s19时54分36秒 0.00 0.00 0.00 0.00 0.0019时54分37秒 0.00 0.00 0.00 0.00 0.00平均时间: 0.00 0.00 0.00 0.00 0.00tps: 每秒向磁盘设备请求数据的次数,包括读、写请求,为rtps与wtps的和。出于效率考虑,每一次IO下发后并不是立即处理请求,而是将请求合并(merge),这里tps指请求合并后的请求计数。rtps: 每秒向磁盘设备的读请求次数wtps: 每秒向磁盘设备的写请求次数bread: 每秒从磁盘读的bytes数量bwrtn: 每秒向磁盘写的bytes数量注:每1秒显示1次,显示10次。
8、dstat
dstat显示了cpu使用情况,磁盘io情况,网络发包情况和换页情况,输出是彩色的,可读性较强,相对于vmstat和iostat的输入更加详细且较为直观。在使用时,直接输入命令即可,当然也可以使用特定参数。
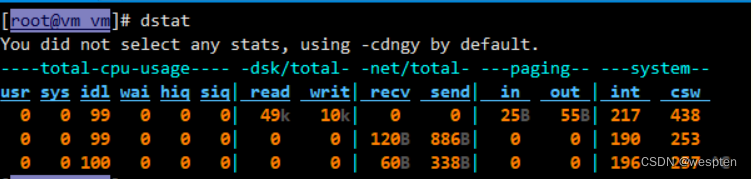
dstat –cdlmnpsy:
七、Linux网络带宽状态分析
socket 信息可以帮我们回答下列问题:
我的程序是不是真的在监听我指定的端口?我的程序是在监听 127.0.0.1(本机),还是在监听 0.0.0.0(整个网络)进程们分别在使用哪些端口?我的连接数是否达到了上限?Socket状态变迁图
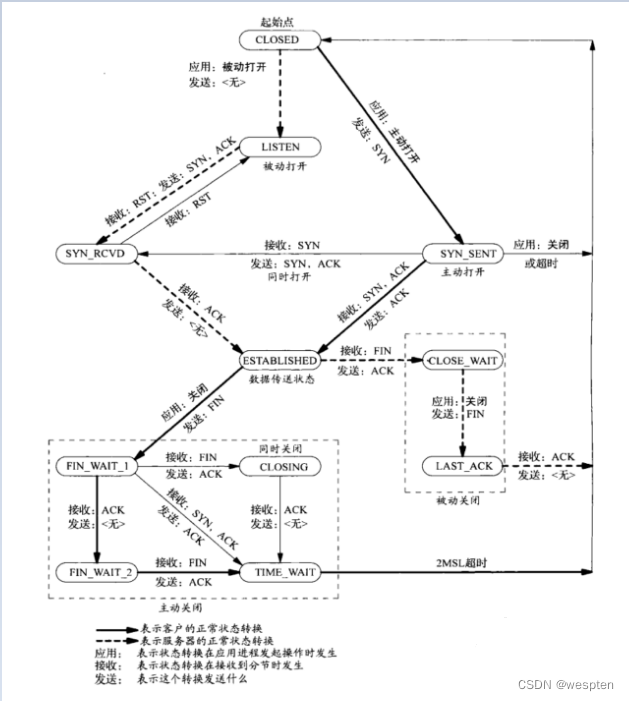
Socket编程中连接状态为CLOSED CLOSE_WITE LAST_ACK等的进程有以下几种:
| CLOSED | 没有使用这个套接字 |
| LISTEN | 套接字正在监听入境连接 |
| SYN_SENT | 套接字正在试图主动建立连接 |
| SYN_RECEIVED | 正在处于连接的初始同步状态 |
| ESTABLISHED | 连接已建立 |
| CLOSE_WAIT | 远程套接字已经关闭:正在等待关闭这个套接字 |
| FIN_WAIT_1 | 套接字已关闭,正在关闭连接 |
| CLOSING | 套接字已关闭,远程套接字正在关闭,暂时挂起关闭确认 |
| LAST_ACK | 远程套接字已关闭,正在等待本地套接字的关闭确认 |
| FIN_WAIT_2 | 套接字已关闭,正在等待远程套接字关闭 |
| TIME_WAIT | 这个套接字已经关闭,正在等待远程套接字的关闭传送 |
先在本机(IP地址为:192.168.1.10)配置FTP服务,然后在其它计算机(IP地址为:192.168.1.1)访问FTP服务,从TCPView看看端口的状态变化:

1、CLOSED
这个没什么好说的了,表示初始状态。
2、LISTENING
表示服务器端的某个SOCKET处于监听状态,可以接受连接了。FTP服务启动后首先处于侦听(LISTENING)状态。State显示是LISTENING时表示处于侦听状态,就是说该端口是开放的,等待连接,但还没有被连接。就像你房子的门已经敞开的,但还没有人进来。从TCPView可以看出本机开放FTP的情况。它的意思是:程序inetinfo.exe开放了21端口,FTP默认的端口为21,可见在本机开放了FTP服务。目前正处于侦听状态。inetinfo.exe:1260 TCP 0.0.0.0:21 0.0.0.0:0 LISTENING
3、SYN_RCVD
这个状态表示接受到了SYN报文,在正常情况下,这个状态是服务器端的SOCKET在建立TCP连接时的三次握手会话过程中的一个中间状态,很短暂,基本上用netstat你是很难看到这种状态的,除非你特意写了一个客户端测试程序,故意将三次TCP握手过程中最后一个ACK报文不予发送。因此这种状态时,当收到客户端的ACK报文后,它会进入到ESTABLISHED状态。
4、SYN_SENT
当客户端SOCKET执行CONNECT连接时,它首先发送SYN报文,因此也随即它会进入到了SYN_SENT状态,并等待服务端的发送三次握手中的第2个报文。
SYN_SENT状态表示客户端已发送SYN报文,当你要访问其它的计算机的服务时首先要发个同步信号给该端口,此时状态为SYN_SENT,如果连接成功了就变为ESTABLISHED,此时SYN_SENT状态非常短暂。但如果发现SYN_SENT非常多且在向不同的机器发出,那你的机器可能中了冲击波或震荡波之类的病毒了。这类病毒为了感染别的计算机,它就要扫描别的计算机,在扫描的过程中对每个要扫描的计算机都要发出了同步请求,这也是出现许多SYN_SENT的原因。
下面显示的是本机连接www.baidu.com网站时的开始状态,如果你的网络正常的,那很快就变为ESTABLISHED的连接状态。
IEXPLORE.EXE:2928 TCP 192.168.1.10:1035 202.108.250.249:80 SYN_SENT
5、ESTABLISHED
表示连接已经建立了。
下面显示的是本机正在访问www.baidu.com网站。如果你访问的网站有许多内容比如访问www.yesky.com,那会发现一个地址有许多ESTABLISHED,这是正常的,网站中的每个内容比如图片、flash等都要单独建立一个连接。看ESTABLISHED状态时一定要注意是不是IEXPLORE.EXE程序(IE)发起的连接,如果是EXPLORE.EXE之类的程序发起的连接,那也许是你的计算机中了木马了。
IEXPLORE.EXE:3120 TCP 192.168.1.10:1045 202.108.250.249:80 ESTABLISHED
6、FIN_WAIT_1
这个状态要好好解释一下,其实FIN_WAIT_1和FIN_WAIT_2状态的真正含义都是表示等待对方的FIN报文。而这两种状态的区别是:FIN_WAIT_1状态实际上是当SOCKET在ESTABLISHED状态时,它想主动关闭连接,向对方发送了FIN报文,此时该SOCKET即进入到FIN_WAIT_1状态。而当对方回应ACK报文后,则进入到FIN_WAIT_2状态,当然在实际的正常情况下,无论对方何种情况下,都应该马上回应ACK报文,所以FIN_WAIT_1状态一般是比较难见到的,而FIN_WAIT_2状态还有时常常可以用netstat看到。
7、FIN_WAIT_2
上面已经详细解释了这种状态,实际上FIN_WAIT_2状态下的SOCKET,表示半连接,也即有一方要求close连接,但另外还告诉对方,我暂时还有点数据需要传送给你,稍后再关闭连接。
8、TIME_WAIT
表示收到了对方的FIN报文,并发送出了ACK报文,就等2MSL后即可回到CLOSED可用状态了。如果FIN_WAIT_1状态下,收到了对方同时带FIN标志和ACK标志的报文时,可以直接进入到TIME_WAIT状态,而无须经过FIN_WAIT_2状态。
现在从192.168.1.1这台计算机结束访问192.168.1.10的FTP服务。在本机的TCPView可以看出端口状态变为TIME_WAIT。TIME_WAIT的意思是结束了这次连接。说明21端口曾经有过访问,但访问结束了。
[System Process]:0 TCP 192.168.1.10:21 192.168.1.1:3009 TIME_WAIT
9、CLOSING
这种状态比较特殊,实际情况中应该是很少见,属于一种比较罕见的例外状态。正常情况下,当你发送FIN报文后,按理来说是应该先收到(或同时收到)对方的ACK报文,再收到对方的FIN报文。但是CLOSING状态表示你发送FIN报文后,并没有收到对方的ACK报文,反而却也收到了对方的FIN报文。什么情况下会出现此种情况呢?其实细想一下,也不难得出结论:那就是如果双方几乎在同时close一个SOCKET的话,那么就出现了双方同时发送FIN报文的情况,也即会出现CLOSING状态,表示双方都正在关闭SOCKET连接。
10、CLOSE_WAIT
这种状态的含义其实是表示在等待关闭。怎么理解呢?当对方close一个SOCKET后发送FIN报文给自己,你系统毫无疑问地会回应一个ACK报文给对方,此时则进入到CLOSE_WAIT状态。接下来呢,实际上你真正需要考虑的事情是察看你是否还有数据发送给对方,如果没有的话,那么你也就可以close这个SOCKET,发送FIN报文给对方,也即关闭连接。所以你在CLOSE_WAIT状态下,需要完成的事情是等待你去关闭连接。
11、LAST_ACK
这个状态还是比较容易好理解的,它是被动关闭一方在发送FIN报文后,最后等待对方的ACK报文。当收到ACK报文后,也即可以进入到CLOSED可用状态了。
建立连接协议(三次握手)
(1)客户端发送一个带SYN标志的TCP报文到服务器。这是三次握手过程中的报文1。
(2) 服务器端回应客户端的,这是三次握手中的第2个报文,这个报文同时带ACK标志和SYN标志。因此它表示对刚才客户端SYN报文的回应;同时又标志SYN给客户端,询问客户端是否准备好进行数据通讯。
(3) 客户必须再次回应服务段一个ACK报文,这是报文段3。
连接终止协议(四次挥手)
由于TCP连接是全双工的,因此每个方向都必须单独进行关闭。这原则是当一方完成它的数据发送任务后就能发送一个FIN来终止这个方向的连接。收到一个 FIN只意味着这一方向上没有数据流动,一个TCP连接在收到一个FIN后仍能发送数据。首先进行关闭的一方将执行主动关闭,而另一方执行被动关闭。
(1) TCP客户端发送一个FIN,用来关闭客户到服务器的数据传送(报文段4)。
(2) 服务器收到这个FIN,它发回一个ACK,确认序号为收到的序号加1(报文段5)。和SYN一样,一个FIN将占用一个序号。
(3) 服务器关闭客户端的连接,发送一个FIN给客户端(报文段6)。
(4) 客户段发回ACK报文确认,并将确认序号设置为收到序号加1(报文段7)。
常规流程
常规流程就是指,客户端连接服务器,交互完成后,客户端主动关闭连接。其大致代码为:
// 客户端clientfd = socket(...);struct sockaddr_in servaddr ...;connect(clientfd, &servaddr, ...); // ②send(...)recv(...)close(clientfd); // ④// 服务器serverfd = socket(...);listen(serverfd, ...); // ①while(true){ clientfd = accept(serverfd,...); // ③ recv(...) send(...)}close(serverfd); // 此处关闭的是服务端的监听socket,不是与客户端建立TCP连接的socket对应的状态转移图如下:
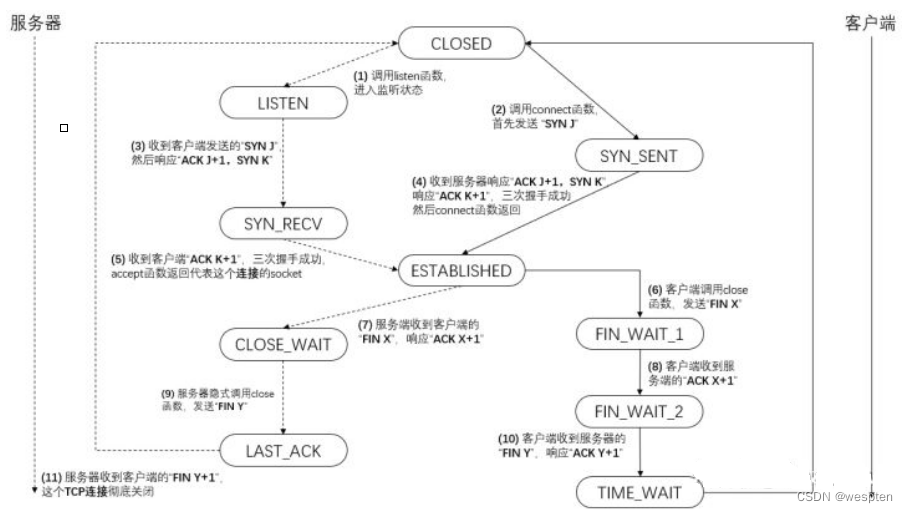
图中虚线表示服务器的状态转移,实现表示客户端的状态转移。
需要注意的是,listen状态的socket和其后状态(如SYN_RECV)的socket其实不是一个socket,每当客户端想服务器发起连接时,服务器都会创建一个新socket,这个socket用(协议,服务器IP,服务端监听端口,客户端IP,客户端端口)进行标识,表示一个TCP连接,收到的网络层数据都会根据这个五元组分发到对应的socket上。所以调用close关闭的其实是这个连接,服务端的监听sokcet并没有被关闭。
服务端主动关闭连接
与常规流程不同的是,是服务器先调用close关闭连接,客户端被动关闭,一般没有keepalive的HTTP协议就是这种模式。
// 客户端clientfd = socket(...);struct sockaddr_in servaddr ...;connect(clientfd, &servaddr, ...); // ②send(...)recv(...)...// 服务器serverfd = socket(...);listen(serverfd, ...); // ①while(true){ clientfd = accept(serverfd,...); // ③ recv(...); send(...); close(clientfd); // ④}状态转移图为:
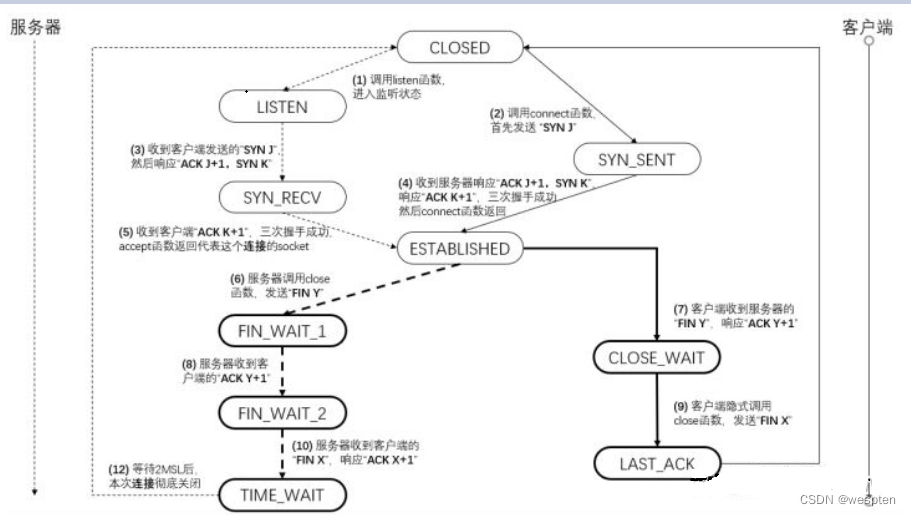
其他情景
上述两种情况是常见的场景,还有两种场景是不太常见的。
服务端和客户端同时close
当服务端和客户端同时调用close时,那么这个TCP连接两端的socket就都进入了FIN_WAIT_1状态。
如果两端的FIN包也同时到达,那么状态转换如下:
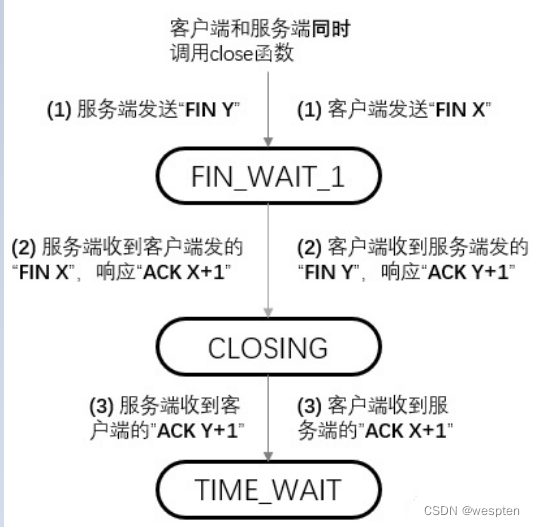
如果一方的FIN先到达,假设客户端先收到服务端的FIN,那么状态转换如下:
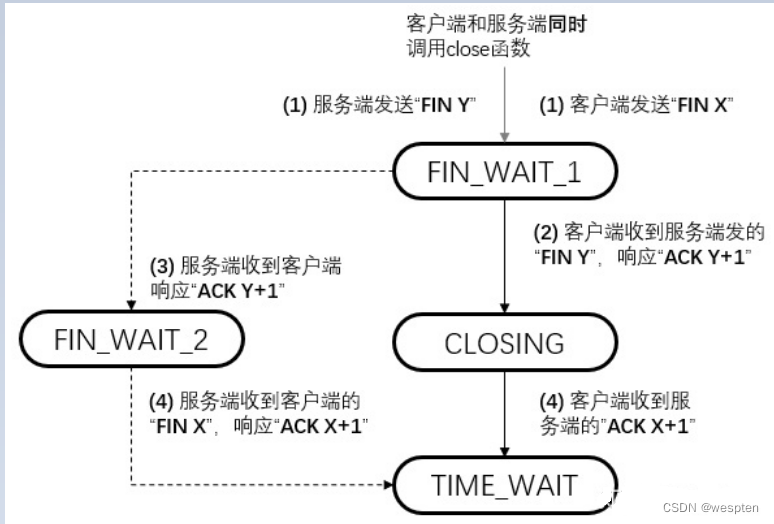
TIME_WAIT状态总结
主动调用close关闭TCP连接的一方,会进入TIME_WAIT状态,建立TIME_WAIT状态的目的有两个
确保连接被可靠的关闭:最后一个ACK总是有主动调用close的一方发送,为了确保这个ACK被另一方接收,就必须等待2MSL时间。一个MSL时间代表一个TCP报文能够在网络中存在的最长时间,超过这个时间,TCP报文就一定不会被发送到接收方。从ACK发出到接收,最长的时间就是1个MSL,如果接收方没有在这个时间里收到ACK,就会重传,再次发送FIN包,这个FIN从发送到接收又是一个MSL。这样就可保证,如果发送方没有在2MSL时间内再次收到FIN,那么连接就可靠的关闭了
确保重复的TCP报文在网络中消逝,以防止干扰下一个同样标识的连接。因为一个TCP报文的能存在的最长时间是1个MSL,所以等待一个MSL就可以保证网络中不会再有本次连接的报文了。
最后有2个问题:
1、 为什么建立连接协议是三次握手,而关闭连接却是四次握手呢?
这是因为服务端的LISTEN状态下的SOCKET当收到SYN报文的建连请求后,它可以把ACK和SYN(ACK起应答作用,而SYN起同步作用)放在一个报文里来发送。但关闭连接时,当收到对方的FIN报文通知时,它仅仅表示对方没有数据发送给你了;但未必你所有的数据都全部发送给对方了,所以你可以未必会马上会关闭SOCKET,也即你可能还需要发送一些数据给对方之后,再发送FIN报文给对方来表示你同意现在可以关闭连接了,所以它这里的ACK报文和FIN报文多数情况下都是分开发送的。
2、 为什么TIME_WAIT状态还需要等2MSL后才能返回到CLOSED状态?
这是因为:虽然双方都同意关闭连接了,而且握手的4个报文也都协调和发送完毕,按理可以直接回到CLOSED状态(就好比从SYN_SEND状态到ESTABLISH状态那样);但是因为我们必须要假想网络是不可靠的,你无法保证你最后发送的ACK报文会一定被对方收到,因此对方处于LAST_ACK状态下的SOCKET可能会因为超时未收到ACK报文,而重发FIN报文,所以这个TIME_WAIT状态的作用就是用来重发可能丢失的ACK报文。
Linux网络带宽状态分析工具
1、netstat
netstat命令用于显示与IP、TCP、UDP和ICMP协议相关的统计数据,一般用于检验本机各端口的网络连接情况。netstat是在内核中访问网络及相关信息的程序,它能提供TCP连接,TCP和UDP监听,进程内存管理的相关报告。
如果你的计算机有时候接收到的数据报导致出错数据或故障,你不必感到奇怪,TCP/IP可以容许这些类型的错误,并能够自动重发数据报。但如果累计的出错情况数目占到所接收的IP数据报相当大的百分比,或者它的数目正迅速增加,那么你就应该使用netstat查一查为什么会出现这些情况了。
语法:
netstat [address_family_options] [–tcp|-t] [–udp|-u] [–raw|-w] [–listening|-l] [–all|-a][–numeric|-n] [–numeric-hosts][–numeric-ports][–numeric-ports] [–symbolic|-N][–extend|-e[–extend|-e]] [–timers|-o] [–program|-p] [–verbose|-v] [–continuous|-c] [delay]netstat {–route|-r} [address_family_options] [–extend|-e[–extend|-e]] [–verbose|-v] [–numeric|-n][–numeric-hosts][–numeric-ports][–numeric-ports] [–continuous|-c] [delay]netstat {–interfaces|-i} [iface] [–all|-a] [–extend|-e[–extend|-e]] [–verbose|-v] [–program|-p][–numeric|-n] [–numeric-hosts][–numeric-ports][–numeric-ports] [–continuous|-c] [delay]netstat {–groups|-g} [–numeric|-n] [–numeric-hosts][–numeric-ports][–numeric-ports] [–continu-ous|-c] [delay]netstat {–masquerade|-M} [–extend|-e] [–numeric|-n] [–numeric-hosts][–numeric-ports][–numeric-ports] [–continuous|-c] [delay]netstat {–statistics|-s} [–tcp|-t] [–udp|-u] [–raw|-w] [delay]netstat {–version|-V}netstat {–help|-h}address_family_options:
[–protocol={inet,unix,ipx,ax25,netrom,ddp}[,…]] [–unix|-x] [–inet|–ip] [–ax25] [–ipx][–netrom] [–ddp]参数:
-a或–all 显示所有连线中的Socket。-A<网络类型>或–<网络类型> 列出该网络类型连线中的相关地址。-c或–continuous 持续列出网络状态。-C或–cache 显示路由器配置的快取信息。-e或–extend 显示网络其他相关信息。-F或–fib 显示FIB。-g或–groups 显示多重广播功能群组组员名单。-h或–help 在线帮助。-i或–interfaces 显示网络界面信息表单。-l或–listening 显示监控中的服务器的Socket。-M或–masquerade 显示伪装的网络连线。-n或–numeric 直接使用IP地址,而不通过域名服务器。-N或–netlink或–symbolic 显示网络硬件外围设备的符号连接名称。-o或–timers 显示计时器。-p或–programs 显示正在使用Socket的程序识别码和程序名称。-r或–route 显示Routing Table。-s或–statistice 显示网络工作信息统计表。-t或–tcp 显示TCP传输协议的连线状况。-u或–udp 显示UDP传输协议的连线状况。-v或–verbose 显示指令执行过程。-V或–version 显示版本信息。-w或–raw 显示RAW传输协议的连线状况。-x或–unix 此参数的效果和指定”-A unix”参数相同。–ip或–inet 此参数的效果和指定”-A inet”参数相同。无参数使用:
$ netstatActive Internet connections (w/o servers)Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 268 192.168.120.204:ssh 10.2.0.68:62420 ESTABLISHED udp 0 0 192.168.120.204:4371 10.58.119.119:domain ESTABLISHED Active UNIX domain sockets (w/o servers)Proto RefCnt Flags Type State I-Node Pathunix 2 [ ] DGRAM 1491 @/org/kernel/udev/udevdunix 4 [ ] DGRAM 7337 /dev/logunix 2 [ ] DGRAM 708823 unix 2 [ ] DGRAM 7539 unix 3 [ ] STREAM CONNECTED 7287 unix 3 [ ] STREAM CONNECTED 7286 netstat输出的字段的解释:
OUTPUT Active Internet connections (TCP, UDP, raw) Proto The protocol (tcp, udp, raw) used by the socket. Recv-Q The count of bytes not copied by the user program connected to this socket. // 是接受队列里的数据,就是还没传给上层的应用程序的 Send-Q The count of bytes not acknowledged by the remote host. // 是发送出去,但是还没有被确认的数据 Local Address Address and port number of the local end of the socket. Unless the –numeric (-n) option is specified, the socket address is resolved to its canonical host name (FQDN), and the port number is translated into the corresponding service name. Foreign Address Address and port number of the remote end of the socket. Analogous to "Local Address." State The state of the socket. Since there are no states in raw mode and usually no states used in UDP, this column may be left blank. Normally this can be one of several values: ESTABLISHED The socket has an established connection. SYN_SENT The socket is actively attempting to establish a connection. SYN_RECV A connection request has been received from the network. FIN_WAIT1 The socket is closed, and the connection is shutting down. FIN_WAIT2 Connection is closed, and the socket is waiting for a shutdown from the remote end. TIME_WAIT The socket is waiting after close to handle packets still in the network. CLOSED The socket is not being used. CLOSE_WAIT The remote end has shut down, waiting for the socket to close. LAST_ACK The remote end has shut down, and the socket is closed. Waiting for acknowledgement. LISTEN The socket is listening for incoming connections. Such sockets are not included in the output unless you specify the –listening (-l) or –all (-a) option. CLOSING Both sockets are shut down but we still don’t have all our data sent. UNKNOWN The state of the socket is unknown. User The username or the user id (UID) of the owner of the socket. PID/Program name Slash-separated pair of the process id (PID) and process name of the process that owns the socket. –program causes this column to be included. You will also need superuser privileges to see this information on sockets you don’t own. This identification information is not yet available for IPX sockets. Timer (this needs to be written) Active UNIX domain Sockets Proto The protocol (usually unix) used by the socket. RefCnt The reference count (i.e. attached processes via this socket). Flags The flags displayed is SO_ACCEPTON (displayed as ACC), SO_WAITDATA (W) or SO_NOSPACE (N). SO_ACCECPTON is used on unconnected sockets if their corresponding processes are waiting for a connect request. The other flags are not of normal interest. Type There are several types of socket access: SOCK_DGRAM The socket is used in Datagram (connectionless) mode. SOCK_STREAM This is a stream (connection) socket. SOCK_RAW The socket is used as a raw socket. SOCK_RDM This one serves reliably-delivered messages. SOCK_SEQPACKET This is a sequential packet socket. SOCK_PACKET Raw interface access socket. UNKNOWN Who ever knows what the future will bring us – just fill in here ? State This field will contain one of the following Keywords: FREE The socket is not allocated LISTENING The socket is listening for a connection request. Such sockets are only included in the output if you spec- ify the –listening (-l) or –all (-a) option. CONNECTING The socket is about to establish a connection. CONNECTED The socket is connected. DISCONNECTING The socket is disconnecting. (empty) The socket is not connected to another one. UNKNOWN This state should never happen. PID/Program name Process ID (PID) and process name of the process that has the socket open. More info available in Active Internet connections section written above. Path This is the path name as which the corresponding processes attached to the socket.从整体上看,netstat的输出结果可以分为两个部分:
一个是Active Internet connections,称为有源TCP连接,其中"Recv-Q"和"Send-Q"指的是接收队列和发送队列。这些数字一般都应该是0。如果不是则表示软件包正在队列中堆积。这种情况只能在非常少的情况见到。另一个是Active UNIX domain sockets,称为有源Unix域套接口(和网络套接字一样,但是只能用于本机通信,性能可以提高一倍)。Proto显示连接使用的协议,RefCnt表示连接到本套接口上的进程号,Types显示套接口的类型,State显示套接口当前的状态,Path表示连接到套接口的其它进程使用的路径名。
套接口类型:
-t :TCP-u :UDP-raw :RAW类型--unix :UNIX域类型--ax25 :AX25类型--ipx :ipx类型--netrom :netrom类型状态说明:
LISTEN:侦听来自远方的TCP端口的连接请求SYN-SENT:再发送连接请求后等待匹配的连接请求(如果有大量这样的状态包,检查是否中招了)SYN-RECEIVED:再收到和发送一个连接请求后等待对方对连接请求的确认(如有大量此状态,估计被flood攻了)ESTABLISHED:代表一个打开的连接FIN-WAIT-1:等待远程TCP连接中断请求,或先前的连接中断请求的确认FIN-WAIT-2:从远程TCP等待连接中断请求CLOSE-WAIT:等待从本地用户发来的连接中断请求CLOSING:等待远程TCP对连接中断的确认LAST-ACK:等待原来的发向远程TCP的连接中断请求的确认(不是什么好东西,此项出现,检查是否被攻击)TIME-WAIT:等待足够的时间以确保远程TCP接收到连接中断请求的确认CLOSED:没有任何连接状态列出所有端口:
$ netstat -aActive Internet connections (servers and established)Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 localhost:smux *:* LISTEN tcp 0 0 *:svn *:* LISTEN tcp 0 0 *:ssh *:* LISTEN tcp 0 284 192.168.120.204:ssh 10.2.0.68:62420 ESTABLISHED udp 0 0 localhost:syslog *:* udp 0 0 *:snmp *:* Active UNIX domain sockets (servers and established)Proto RefCnt Flags Type State I-Node Pathunix 2 [ ACC ] STREAM LISTENING 708833 /tmp/ssh-yKnDB15725/agent.15725unix 2 [ ACC ] STREAM LISTENING 7296 /var/run/audispd_eventsunix 2 [ ] DGRAM 1491 @/org/kernel/udev/udevdunix 4 [ ] DGRAM 7337 /dev/logunix 2 [ ] DGRAM 708823 unix 2 [ ] DGRAM 7539 unix 3 [ ] STREAM CONNECTED 7287 unix 3 [ ] STREAM CONNECTED 7286 说明:
显示一个所有的有效连接信息列表,包括已建立的连接(ESTABLISHED),也包括监听连接请(LISTENING)的那些连接。
显示当前UDP连接状况:
$ netstat -nuActive Internet connections (w/o servers)Proto Recv-Q Send-Q Local Address Foreign Address State udp 0 0 ::ffff:192.168.12:53392 ::ffff:192.168.9.120:10000 ESTABLISHED udp 0 0 ::ffff:192.168.12:56723 ::ffff:192.168.9.120:10000 ESTABLISHED udp 0 0 ::ffff:192.168.12:56480 ::ffff:192.168.9.120:10000 ESTABLISHED udp 0 0 ::ffff:192.168.12:58154 ::ffff:192.168.9.120:10000 ESTABLISHED udp 0 0 ::ffff:192.168.12:44227 ::ffff:192.168.9.120:10000 ESTABLISHED udp 0 0 ::ffff:192.168.12:36954 ::ffff:192.168.9.120:10000 ESTABLISHED udp 0 0 ::ffff:192.168.12:53984 ::ffff:192.168.9.120:10000 ESTABLISHED udp 0 0 ::ffff:192.168.12:57703 ::ffff:192.168.9.120:10000 ESTABLISHED udp 0 0 ::ffff:192.168.12:53613 ::ffff:192.168.9.120:10000 ESTABLISHED 显示UDP端口号的使用情况:
$ netstat -apuActive Internet connections (servers and established)Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name udp 0 0 0.0.0.0:890 0.0.0.0:* 726/rpcbind udp 0 0 0.0.0.0:sunrpc 0.0.0.0:* 1/systemd udp 0 0 localhost:323 0.0.0.0:* 760/chronyd udp6 0 0 [::]:890 [::]:* 726/rpcbind udp6 0 0 [::]:sunrpc [::]:* 1/systemd udp6 0 0 localhost:323 [::]:* 760/chronyd 显示网卡列表:
$ netstat -iKernel Interface tableIface MTU RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flgdocker0 1500 0 0 0 0 0 0 0 0 BMUeth0 1500 1450 0 0 0 1637 0 0 0 BMRUlo 65536 72 0 0 0 72 0 0 0 LRU显示组播组的关系:
$ netstat -g\IPv6/IPv4 Group MembershipsInterface RefCnt Group--------------- ------ ---------------------lo 1 all-systems.mcast.neteth0 1 all-systems.mcast.netdocker0 1 all-systems.mcast.netlo 1 ff02::1lo 1 ff01::1eth0 1 ff02::1:ffc0:4599eth0 1 ff02::1eth0 1 ff01::1docker0 1 ff02::1docker0 1 ff01::1显示网络统计信息:
$ netstat -sIp: 1254 total packets received 0 forwarded 0 incoming packets discarded 1254 incoming packets delivered 1140 requests sent out 16 dropped because of missing routeIcmp: 37 ICMP messages received 0 input ICMP message failed. ICMP input histogram: destination unreachable: 37 37 ICMP messages sent 0 ICMP messages failed ICMP output histogram: destination unreachable: 37IcmpMsg: InType3: 37 OutType3: 37Tcp: 4 active connections openings 2 passive connection openings 0 failed connection attempts 0 connection resets received 2 connections established 869 segments received 1047 segments send out 0 segments retransmited 0 bad segments received. 0 resets sentUdp: 163 packets received 37 packets to unknown port received. 0 packet receive errors 339 packets sent 0 receive buffer errors 0 send buffer errorsUdpLite:TcpExt: 4 TCP sockets finished time wait in fast timer 24 delayed acks sent 2 packets directly queued to recvmsg prequeue. 274 packet headers predicted 229 acknowledgments not containing data payload received 249 predicted acknowledgments TCPRcvCoalesce: 3 TCPAutoCorking: 8 TCPOrigDataSent: 850 TCPHystartTrainDetect: 1 TCPHystartTrainCwnd: 18IpExt: InBcastPkts: 147 InOctets: 111816 OutOctets: 767452 InBcastOctets: 14228 InNoECTPkts: 1260说明:
按照各个协议分别显示其统计数据。如果我们的应用程序(如Web浏览器)运行速度比较慢,或者不能显示Web页之类的数据,那么我们就可以用本选项来查看一下所显示的信息。我们需要仔细查看统计数据的各行,找到出错的关键字,进而确定问题所在。
显示监听的套接口:
$ netstat -lActive Internet connections (only servers)Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 localhost:smtp 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:sunrpc 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:ssh 0.0.0.0:* LISTEN tcp6 0 0 localhost:smtp [::]:* LISTEN tcp6 0 0 [::]:sunrpc [::]:* LISTEN tcp6 0 0 [::]:ssh [::]:* LISTEN udp 0 0 0.0.0.0:890 0.0.0.0:* udp 0 0 0.0.0.0:sunrpc 0.0.0.0:* udp 0 0 localhost:323 0.0.0.0:* udp6 0 0 [::]:890 [::]:* udp6 0 0 [::]:sunrpc [::]:* udp6 0 0 localhost:323 [::]:* raw6 0 0 [::]:ipv6-icmp [::]:* 7 Active UNIX domain sockets (only servers)Proto RefCnt Flags Type State I-Node Pathunix 2 [ ACC ] STREAM LISTENING 23300 /var/run/docker.sockunix 2 [ ACC ] STREAM LISTENING 17690 /run/dbus/system_bus_socketunix 2 [ ACC ] STREAM LISTENING 23342 /var/run/docker/libcontainerd/docker-containerd.sock显示所有已建立的有效连接:
$ netstat -nActive Internet connections (w/o servers)Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 52 192.168.211.15:22 192.168.211.1:49878 ESTABLISHEDtcp 0 0 192.168.211.15:22 192.168.211.1:64318 ESTABLISHEDActive UNIX domain sockets (w/o servers)Proto RefCnt Flags Type State I-Node Pathunix 2 [ ] DGRAM 19782 /var/run/chrony/chronyd.sockunix 2 [ ] DGRAM 12252 /run/systemd/shutdowndunix 3 [ ] DGRAM 9450 /run/systemd/notify显示关于以太网的统计数据:
$ netstat -eActive Internet connections (w/o servers)Proto Recv-Q Send-Q Local Address Foreign Address State User Inode tcp 0 52 localhost.localdoma:ssh 192.168.211.1:49878 ESTABLISHED root 40280 tcp 0 0 localhost.localdoma:ssh 192.168.211.1:64318 ESTABLISHED root 25954 Active UNIX domain sockets (w/o servers)Proto RefCnt Flags Type State I-Node Pathunix 2 [ ] DGRAM 19782 /var/run/chrony/chronyd.sockunix 2 [ ] DGRAM 12252 /run/systemd/shutdowndunix 3 [ ] DGRAM 9450 /run/systemd/notify显示关于路由表的信息:
$ netstat -rKernel IP routing tableDestination Gateway Genmask Flags MSS Window irtt Ifacedefault gateway 0.0.0.0 UG 0 0 0 eth0172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0192.168.211.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0列出所有 tcp 端口:
$ netstat -atActive Internet connections (servers and established)Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 localhost:smtp 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:sunrpc 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:ssh 0.0.0.0:* LISTEN tcp 0 52 localhost.localdoma:ssh 192.168.211.1:49878 ESTABLISHEDtcp 0 0 localhost.localdoma:ssh 192.168.211.1:64318 ESTABLISHEDtcp6 0 0 localhost:smtp [::]:* LISTEN tcp6 0 0 [::]:sunrpc [::]:* LISTEN tcp6 0 0 [::]:ssh [::]:* LISTEN 统计机器中网络连接各个状态个数:
$ netstat -a | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'ESTABLISHED 1423 (有1423个正常数据传输状态)FIN_WAIT1 1FIN_WAIT2 262SYN_RECV 2 (SYN连接请求收到2个 等待确认)SYN_SENT 1TIME_WAIT 962 (等待结束的请求962个)可返回的所有状态解释:
CLOSED:无连接是活动的或正在进行LISTEN:服务器在等待进入呼叫SYN_RECV:一个连接请求已经到达,表示正在等待处理的请求数SYN_SENT:应用已经开始,打开一个连接ESTABLISHED:表示正常数据传输状态FIN_WAIT1:主动断开的主机A发送完FIN后,等待主机B的ACK的状态FIN_WAIT2:接收到主机B的ACK后,等待主机B发送FIN的状态ITMED_WAIT:等待所有分组死掉CLOSING:两边同时尝试关闭TIME_WAIT:表示处理完毕,等待超时结束的请求数LAST_ACK:等待所有分组死掉如果只想看正常的并发连接,使用如下命令:
netstat -nat|grep ESTABLISHED|wc -l 总并发连接,用这个查出来的值是跟服务器可承载总访问量去对比:
netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a,S[a]}'netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a,S[a]}' |grep 'ESTABLISHED' |awk -F ' ' '{print $2}'所有已建立链接的ip:
netstat -na|grep ESTABLISHED|awk '{print $5}'|awk -F: '{print $1}' 用这个查看192.29.1.95 服务器当前的并发访问量:
netstat -na|grep ESTABLISHED|grep "192.29.1.95" |wc -l 统计服务器所有url被请求的数量,即服务器当前并发访问量:
netstat -pntnetstat -pnt | grep :80netstat -pnt | grep :80 | wc -ltcp 0 0 192.168.201.154:80 192.168.25.127:6318 ESTABLISHED 8531/nginx: workertcp 0 0 192.168.201.154:80 192.168.25.127:6319 ESTABLISHED 8531/nginx: worker因为服务器本身占用一个连接,所以此时并发数是1个用户访问,后面的ESTABLISHED表示服务器正在被访问。
[root@localhost ~]# netstat -pnt | grep :80tcp 0 0 192.168.201.154:80 192.168.25.127:6220 FIN_WAIT2 -tcp 0 0 192.168.201.154:80 192.168.25.127:6221 FIN_WAIT2 -[root@localhost ~]# netstat -pnt | grep :80 | wc -l0当关闭网页后输入命令会发现还是2个用户,实际上查看详细信息都是从ESTABLISHED变成了FIN_WAIT2超时状态,因为http有一个保持连接的时间,过一会再查看用户数就为0了,此时说明所有连接都彻底断开了,访问一个页面后再访问另一个页面,之前的http超时时间将加快,所以当连续访问网站时,连接总体上还是保持稳定。
已经建立链接的IP:
netstat -na|grep ESTABLISHED|awk '{print $5}'|awk -F: '{print $1}' 单个IP与服务器建立的并发链接数:
netstat -na|grep ESTABLISHED|grep "192.73.1.49" |wc -l 查看服务器当前的并发访问量:
netstat -pnt | grep :80 netstat -pnt | grep :80 | wc -l 把状态全都取出来后使用uniq -c统计后再进行排序:
$ netstat -nat |awk '{print $6}'|sort|uniq -c 1 established 2 ESTABLISHED 1 Foreign 6 LISTENnetstat -nat |awk '{print $6}'|sort|uniq -c|sort -rn 6 LISTEN 2 ESTABLISHED 1 Foreign 1 established找出程序运行的端口:
$ netstat -ap | grep sshtcp 0 0 0.0.0.0:ssh 0.0.0.0:* LISTEN 1116/sshd tcp 0 52 localhost.localdoma:ssh 192.168.211.1:49878 ESTABLISHED 3406/sshd: root@pts tcp 0 0 localhost.localdoma:ssh 192.168.211.1:64318 ESTABLISHED 1716/sshd: root@pts tcp6 0 0 [::]:ssh [::]:* LISTEN 1116/sshd unix 2 [ ] DGRAM 25487 1716/sshd: root@pts unix 2 [ ] DGRAM 40335 3406/sshd: root@pts unix 3 [ ] STREAM CONNECTED 22118 1116/sshd 在 netstat 输出中显示 PID 和进程名称:
$ netstat -ptActive Internet connections (w/o servers)Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name tcp 0 52 localhost.localdoma:ssh 192.168.211.1:49878 ESTABLISHED 3406/sshd: root@pts tcp 0 0 localhost.localdoma:ssh 192.168.211.1:64318 ESTABLISHED 1716/sshd: root@pts netstat -p 可以与其它开关一起使用,就可以添加 “PID/进程名称” 到 netstat 输出中,这样 debugging 的时候可以很方便的发现特定端口运行的程序。
找出运行在指定端口的进程:
$ netstat -anpt | grep ':22'tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1116/sshd tcp 0 52 192.168.211.15:22 192.168.211.1:49878 ESTABLISHED 3406/sshd: root@pts tcp 0 0 192.168.211.15:22 192.168.211.1:64318 ESTABLISHED 1716/sshd: root@pts tcp6 0 0 :::22 :::* LISTEN 1116/sshd 其他使用:
netstat -nut|grep 22|wc -lnetstat -ntu | awk '{print $5}' | sed 's/::ffff://g' | cut -d: -f1 | sort | uniq -c | sort -n | grep -v -E '127.0|0.0|Address|server'netstat -na > /root/桌面/1.txtnetstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}' netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a,S[a]}' |grep 'ESTABLISHED' |awk -F ' ' '{print $2}'netstat -na|grep ESTABLISHED|grep %s |wc -l2、SS
ss 是 Socket Statistics 的首字母缩写。ss命令用于显示socket状态,可以显示PACKET sockets, TCP sockets, UDP sockets, DCCP sockets, RAW sockets, Unix domain sockets等等统计. 它比其他工具展示等多tcp和state信息. 它是一个非常实用、快速、有效的跟踪IP连接和sockets的新工具.SS命令可以提供如下信息:
所有的TCP sockets所有的UDP sockets所有ssh/ftp/ttp/https持久连接所有连接到Xserver的本地进程使用state(例如:connected, synchronized, SYN-RECV, SYN-SENT,TIME-WAIT)、地址、端口过滤所有的state FIN-WAIT-1 tcpsocket连接以及更多ss 命令由 iproute2 软件包提供:
yum install iprouteiproute 2 包中的命令可以完全替代 net-tools 包中的 ifconfig、netstat、route 等命令。
当服务器的socket连接数量变得非常大时,无论是使用netstat命令还是直接cat /proc/net/tcp,执行速度都会很慢。可能你不会有切身的感受,但请相信我,当服务器维持的连接达到上万个的时候,使用netstat等于浪费 生命,而用ss才是节省时间。
ss之所以快,它利用到了TCP协议栈中tcp_diag。tcp_diag是一个用于分析统计的模块,可以获得Linux 内核中第一手的信息,这就确保了ss的快捷高效。当然,如果你的系统中没有tcp_diag,ss也可以正常运行,只是效率会变得稍慢。
比较ss和netstat的效率:
[root@node1 ~]# time netstat -tan|grep -i estab |wc -l127real0m0.600suser0m0.048ssys0m0.312s[root@node1 ~]# time ss -tan|grep -i estab |wc -l126real0m0.028suser0m0.001ssys0m0.007s从结果可以看出ss比netstat效率快了一个数量级。
ss常用的参数:
-n --numeric不解析服务名称-r --resolve 解析主机名-l --listening 显示监听状态的套接字(sockets)-a --all显示所有套接字-o --options 显示计时器信息-e --extended 显示详细的套接字(socket)的内存使用情况-p --processed 显示使用套接字的进程-i --info 显示 tcp 内部信息-s --summary 显示套接字(socket)使用概况-4 --IPv4 仅显示 IPv4的套接字-6-0(零) --packet 显示 PACKET 套接字-t --tcp 仅显示 TCP 套接字-u --udp 仅显示 UDP套接字-d --dccp 仅显示 DCCP 套接字-w --raw 仅显示 RAW 套接字-x --Unix 仅显示 Unix 套接字-f --family=FAMILY 显示 FAMILY 类型的套接字,FAMILY可选 Unix, inet, inet6, link , netlink -A --query=QUERY, --socket=QUERY QUERY := {all| inet| tcp| udp | raw | unix | packet | netlink } [QUERY]-D --diag=FILE 将原始TCP 套接字信息转储到文件-F --filter=FILE 从文件中都去过滤信息 FLITER := [ state TCP-STATE ] [ EXPRESSION ]显示已建立的网络连接:
# ssNetid State Recv-Q Send-Q Local Address:Port Peer Address:Porttcp ESTAB 0 0 10.0.2.10:ssh 10.0.2.2:52316上述输出结果中的 ESTAB 代表网络连接的状态是“已建立”(Established)。
选项 -a (--all)用于显示所有的网络连接:监听中和非监听中(对于 tcp,就是监听中和已建立):
# ss -aNetid State Recv-Q Send-Q Local Address:Port Peer Address:Porttcp ESTAB 0 0 10.0.2.10:ssh 10.0.2.2:52316tcp LISTEN 0 128 [::]:ssh [::]:*--summary显示套接字(socket)摘要:
主要统计处于各种状态的 tcp sockets 数量,以及其他 sockets 的统计信息。
[root@node1 ~]# ss -sTotal: 759 (kernel 1071)TCP: 174 (estab 87, closed 31, orphaned 0, synrecv 0, timewait 29/0), ports 0Transport Total IP IPv6* 1071 - - RAW 1 0 1 UDP 10 6 4 TCP 143 108 35 INET 154 114 40 FRAG 0 0 0 选项 -n (--numeric)用于显示端口号,而非使用该端口号的服务:
# ss -nNetid State Recv-Q Send-Q Local Address:Port Peer Address:Porttcp ESTAB 0 0 10.0.2.10:22 10.0.2.2:52316使用选项 -n 后,显示端口号 22,而非使用 22 端口号的 ssh。
用TCP 状态过滤 sockets:
ss -4 state FILTER-NAME-HEREss -6 state FILTER-NAME-HEREFILTER-NAME-HERE 可以代表以下任何一个:
establishedsyn-sentsyn-recvfin-wait-1fin-wait-2time-waitclosedclose-waitlast-acklistenclosingall 所有以上状态connected 除了listen and closed 的所有状态synchronized 所有已连接的状态除了 syn-sentbucket 显示状态为 maintained as minisockets, 如 time-wait 和 syn-recv.big 和bucket 相反显示所有TCP套接字:
ss -ta State Recv-Q Send-Q Local Address:Port Peer Address:Port LISTEN 0 128 *:ssh *:* LISTEN 0 100 127.0.0.1:smtp *:* ESTAB 0 96 192.168.172.101:ssh 192.168.172.1:52859 LISTEN 0 128 :::ssh :::* LISTEN 0 100 ::1:smtp :::* 显示所有UDP sockets:
选项 -u(--udp),仅显示 udp 端口。
ss -u -a查看所有处于监听状态的连接:
[root@node1 ~]# ss -lNetid State Recv-Q Send-Q Local Address:Port Peer Address:Port tcp LISTEN 0 128 10.0.0.61:fs-agent *:* tcp LISTEN 0 50 *:7180 *:* tcp LISTEN 0 128 10.0.0.61:1004 *:* tcp LISTEN 0 128 *:50060 *:* tcp LISTEN 0 50 *:bmcpatrolagent *:* tcp LISTEN 0 128 127.0.0.1:45677 *:* tcp LISTEN 0 50 *:7182 *:* tcp LISTEN 0 50 10.0.0.61:1006 *:* tcp LISTEN 0 128 *:50030 *:* tcp LISTEN 0 128 *:sunrpc *:* tcp LISTEN 0 50 *:ndmp *:* tcp LISTEN 0 128 10.0.0.61:19888 *:* tcp LISTEN 0 128 10.0.0.61:10033 *:* tcp LISTEN 0 5 *:vop *:* tcp LISTEN 0 128 10.0.0.61:oa-system *:* tcp LISTEN 0 128 10.0.0.61:50070 *:* tcp LISTEN 0 5 127.0.0.1:7190 *:* tcp LISTEN 0 128 *:ssh *:* tcp LISTEN 0 5 *:7191 *:* tcp LISTEN 0 100 *:irisa *:* tcp LISTEN 0 128 10.0.0.61:radan-http *:* tcp LISTEN 0 1 127.0.0.1:metasys *:* tcp LISTEN 0 50 *:44697 *:* tcp LISTEN 0 128 127.0.0.1:19001 *:* tcp LISTEN 0 100 127.0.0.1:smtp *:* tcp LISTEN 0 128 *:13562 *:* tcp LISTEN 0 50 *:emc-pp-mgmtsvc *:* tcp LISTEN 0 80 :::mysql :::* 查看主机监听的端口:
[root@centos7 mnt]# ss -tlnrState Recv-Q Send-Q Local Address:Port Peer Address:Port LISTEN 0 128 *:111 *:* LISTEN 0 5 centos7:53 *:* LISTEN 0 128 *:22 *:* LISTEN 0 128 localhost:631 *:* LISTEN 0 100 localhost:25 *:* LISTEN 0 128 localhost:6010 *:* LISTEN 0 128 :::111 :::* LISTEN 0 128 :::80 :::* LISTEN 0 128 :::22 :::* LISTEN 0 128 localhost:631 :::* LISTEN 0 100 localhost:25 :::* LISTEN 0 128 localhost:6010 :::* 我们可以看到,本地本机开启了 111,53,22,631,25,6010,80,25这几个tcp端口,也就是smtp服务-25,ssh-22,dns-53,http-80,xshell-631,cupsd-6010,docker的桥接网卡-111。
通过 -r 选项解析 IP 和端口号:
[root@centos7 mnt]# ss -tlrState Recv-Q Send-Q Local Address:Port Peer Address:Port LISTEN 0 128 *:rpc.portmapper *:* LISTEN 0 5 centos7:domain *:* LISTEN 0 128 *:ssh *:* LISTEN 0 128 localhost:ipp *:* LISTEN 0 100 localhost:smtp *:* LISTEN 0 128 localhost:x11-ssh-offset *:* LISTEN 0 128 :::rpc.portmapper :::* LISTEN 0 128 :::http :::* LISTEN 0 128 :::ssh :::* LISTEN 0 128 localhost:ipp :::* LISTEN 0 100 localhost:smtp :::* LISTEN 0 128 localhost:x11-ssh-offset :::* 查看进程使用的套接字:
选项 -p(--processes),显示端口对应的进程名和进程号 PID。
[root@node1 ~]# ss -plNetid State Recv-Q Send-Q Local Address:Port Peer Address:Port tcp LISTEN 0 128 10.0.0.61:fs-agent *:* users:(("java",pid=3544,fd=216))tcp LISTEN 0 50 *:7180 *:* users:(("java",pid=1182,fd=261))tcp LISTEN 0 128 10.0.0.61:1004 *:* users:(("jsvc",pid=4435,fd=166))tcp LISTEN 0 128 *:50060 *:* users:(("java",pid=2580,fd=157))tcp LISTEN 0 50 *:bmcpatrolagent *:* users:(("java",pid=2620,fd=37))tcp LISTEN 0 128 127.0.0.1:45677 *:* users:(("java",pid=2580,fd=147))tcp LISTEN 0 50 *:7182 *:* users:(("java",pid=1182,fd=247))tcp LISTEN 0 50 10.0.0.61:1006 *:* users:(("jsvc",pid=4435,fd=168))tcp LISTEN 0 128 *:50030 *:* users:(("java",pid=3050,fd=154))tcp LISTEN 0 128 *:sunrpc *:* users:(("rpcbind",pid=535,fd=4),("systemd",pid=1,fd=36))tcp LISTEN 0 50 *:ndmp *:* users:(("java",pid=2451,fd=378))tcp LISTEN 0 128 10.0.0.61:19888 *:* users:(("java",pid=3546,fd=191))tcp LISTEN 0 128 10.0.0.61:10033 *:* users:(("java",pid=3546,fd=180))tcp LISTEN 0 5 *:vop *:* users:(("python2.7",pid=1772,fd=8))tcp LISTEN 0 50 *:documentum *:* users:(("java",pid=2451,fd=379))tcp LISTEN 0 50 *:sdr *:* users:(("java",pid=2620,fd=23))tcp LISTEN 0 128 10.0.0.61:qbdb *:* users:(("java",pid=3031,fd=180))tcp LISTEN 0 128 10.0.0.61:intu-ec-svcdisc *:* users:(("java",pid=3075,fd=206))tcp LISTEN 0 128 10.0.0.61:intu-ec-client *:* users:(("java",pid=3050,fd=143))tcp LISTEN 0 50 *:macbak *:* users:(("java",pid=2620,fd=35))tcp LISTEN 0 50 *:ezmeeting-2 *:* users:(("java",pid=2643,fd=233))ss -pl | grep 3306列出所有ssh连接中state为estab的连接:
[root@node1 ~]# ss -o state established '( sport = :22 )'Netid Recv-Q Send-Q Local Address:Port Peer Address:Port tcp 0 0 10.0.0.61:ssh 10.0.0.1:park-agent timer:(keepalive,2min28sec,0)[root@node1 ~]# ss -o state established '( sport = :ssh )'Netid Recv-Q Send-Q Local Address:Port Peer Address:Port tcp 0 0 10.0.0.61:ssh 10.0.0.1:park-agent timer:(keepalive,1min57sec,0)列出所有http的连接:
[root@node1 ~]# ss -o state established '( sport = :http or dport = :http )'ss列出本地哪个进程连接到x server:
[root@node1 ~]# ss -x src /tmp/.X11-unix/* ss列出处在FIN-WAIT-1状态的http、https连接:
[root@node1 ~]# ss -o state fin-wait-1 '( sport = :http or sport = :https )'显示所有状态为 Established 的 HTTP 连接:
ss -o state established `(dport = :http or sport = :http)` 显示所有状态为 established 的 SMTP 连接:
ss -o state established `( dport =: smtp or sport = : smtp )`ss常用的state状态:
establishedsyn-sentsyn-recvfin-wait-1fin-wait-2time-waitclosedclose-waitlast-acklistenclosingall : All of the above statesconnected: all the states except for listen and closedsynchronized - all the connected states except for syn-sentbucket - states, which are maintained as minisockets, i.e. time-wait and syn-recvbig - opposite to bucketss使用IP地址进行筛选:
ss src ADDRESS_PATTERN:proto/portsrc 表示源地址dst 表示目标地址ADDRESS_PATTERN 表示地址规则(可以是一个地址段)proto/port 为协议或者端口列出所有源地址为10.0.0.61的连接:
[root@node1 ~]# ss src 10.0.0.61Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port udp ESTAB 0 0 10.0.0.61:51808 10.0.0.62:kerberos tcp ESTAB 0 0 10.0.0.61:55082 10.0.0.61:mysql tcp FIN-WAIT-2 0 0 10.0.0.61:44396 10.0.0.61:eforward tcp ESTAB 0 0 10.0.0.61:54070 10.0.0.61:mysql tcp ESTAB 0 0 10.0.0.61:51742 10.0.0.61:7182 列出所有源地址是10.0.0.61的mysql连接:
[root@node1 ~]# ss src 10.0.0.61:mysqlNetid State Recv-Q Send-Q Local Address:Port Peer Address:Port tcp ESTAB 0 0 ::ffff:10.0.0.61:mysql ::ffff:10.0.0.61:54066 tcp ESTAB 0 0 ::ffff:10.0.0.61:mysql ::ffff:10.0.0.61:55154 tcp ESTAB 0 0 ::ffff:10.0.0.61:mysql ::ffff:10.0.0.61:54926 tcp ESTAB 0 0 ::ffff:10.0.0.61:mysql ::ffff:10.0.0.61:54068 tcp ESTAB 0 0 ::ffff:10.0.0.61:mysql ::ffff:10.0.0.61:42944 tcp ESTAB 0 0 ::ffff:10.0.0.61:mysql ::ffff:10.0.0.61:44244 tcp ESTAB 0 0 ::ffff:10.0.0.61:mysql ::ffff:10.0.0.61:54150 tcp ESTAB 0 0 ::ffff:10.0.0.61:mysql ::ffff:10.0.0.61:54920 tcp ESTAB 0 0 ::ffff:10.0.0.61:mysql ::ffff:10.0.0.61:55408 tcp ESTAB 0 0 ::ffff:10.0.0.61:mysql ::ffff:10.0.0.61:54924 列出所有目标地址是10.0.0.61的mysql连接:
[root@node1 ~]# ss dst 10.0.0.61:3306Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port tcp ESTAB 0 0 10.0.0.61:55082 10.0.0.61:mysql tcp ESTAB 0 0 10.0.0.61:54070 10.0.0.61:mysql tcp ESTAB 0 0 10.0.0.61:54922 10.0.0.61:mysql tcp ESTAB 0 0 10.0.0.61:55152 10.0.0.61:mysql tcp ESTAB 0 0 10.0.0.61:54928 10.0.0.61:mysql tcp ESTAB 0 0 10.0.0.61:39996 10.0.0.61:mysql 筛选端口:
ss dport/sport OP PORTOP:运算符PORT:端口dport/sport: 过滤的目标/源端口运算符:
<= or le: 小于等于>= or ge: 大于等于== or eq: 等于!= : 不等于< or lt: 小于> or gt: 大于过滤案例:
[root@node1 ~]# ss sport = :mysqlNetid State Recv-Q Send-Q Local Address:Port Peer Address:Port tcp ESTAB 0 0 ::ffff:10.0.0.61:mysql ::ffff:10.0.0.61:54066 tcp ESTAB 0 0 ::ffff:10.0.0.61:mysql ::ffff:10.0.0.61:55154 tcp ESTAB 0 0 ::ffff:10.0.0.61:mysql ::ffff:10.0.0.61:54926 tcp ESTAB 0 0 ::ffff:10.0.0.61:mysql ::ffff:10.0.0.61:54068 [root@node1 ~]# ss sport = :3306Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port tcp ESTAB 0 0 ::ffff:10.0.0.61:mysql ::ffff:10.0.0.61:54066 tcp ESTAB 0 0 ::ffff:10.0.0.61:mysql ::ffff:10.0.0.61:55154 [root@node1 ~]# ss dport > :1024Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port u_str ESTAB 0 0 * 16252 * 16253 u_str ESTAB 0 0 * 35028 * 35027 u_str ESTAB 0 0 * 16791 * 16813 u_str ESTAB 0 0 * 297984 * 299009 [root@node1 ~]# ss sport > :20000Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port u_str ESTAB 0 0 * 35028 * 35027 u_str ESTAB 0 0 * 297984 * 299009 u_str ESTAB 0 0 * 41350 * 0 u_str ESTAB 0 0 * 23010 * 23009 u_str ESTAB 0 0 * 38302 * 0 u_str ESTAB 0 0 * 37222 * 0 [root@node1 ~]# ss ( sport = :mysql or sport = :ssh )Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port tcp ESTAB 0 0 10.0.0.61:ssh 10.0.0.1:5449 tcp ESTAB 0 0 10.0.0.61:ssh 10.0.0.1:6034 tcp ESTAB 0 0 ::ffff:10.0.0.61:mysql ::ffff:10.0.0.61:54066 tcp ESTAB 0 0 ::ffff:10.0.0.61:mysql ::ffff:10.0.0.61:55154 tcp ESTAB 0 0 ::ffff:10.0.0.61:mysql ::ffff:10.0.0.61:54926 tcp ESTAB 0 0 ::ffff:10.0.0.61:mysql ::ffff:10.0.0.61:54068 tcp ESTAB 0 0 ::ffff:10.0.0.61:mysql ::ffff:10.0.0.61:50806 tcp ESTAB 0 0 ::ffff:10.0.0.61:mysql ::ffff:10.0.0.61:42944 tcp ESTAB 0 0 ::ffff:10.0.0.61:mysql ::ffff:10.0.0.61:44244 [root@node1 ~]# ss state connected sport = :mysqlNetid State Recv-Q Send-Q Local Address:Port Peer Address:Port tcp ESTAB 0 0 ::ffff:10.0.0.61:mysql ::ffff:10.0.0.61:54066 tcp ESTAB 0 0 ::ffff:10.0.0.61:mysql ::ffff:10.0.0.61:55154 tcp ESTAB 0 0 ::ffff:10.0.0.61:mysql ::ffff:10.0.0.61:54926 tcp ESTAB 0 0 ::ffff:10.0.0.61:mysql ::ffff:10.0.0.61:54068 tcp ESTAB 0 0 ::ffff:10.0.0.61:mysql ::ffff:10.0.0.61:50806 tcp ESTAB 0 0 ::ffff:10.0.0.61:mysql ::ffff:10.0.0.61:42944 tcp ESTAB 0 0 ::ffff:10.0.0.61:mysql ::ffff:10.0.0.61:44244 tcp ESTAB 0 0 ::ffff:10.0.0.61:mysql ::ffff:10.0.0.61:54150 [root@node1 ~]# ss -o state fin-wait-1 ( dport = :mysql or sport = :ssh )或者用单引号的形式[root@node1 ~]# ss -o state fin-wait-1 '( dport = :mysql or sport = :ssh )'3、sar
查看网卡流量:
sar -n DEV 1 10每1秒 显示 1次 显示 10次。
平均时间: IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s平均时间: lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00平均时间: eth0 1.30 0.90 0.08 0.36 0.00 0.00 0.00参数说明:
lo # 回环地址eth0 # 网卡IFACE: 就是网络设备的名称;rxpck/s: 每秒钟接收到的包数目txpck/s: 每秒钟发送出去的包数目rxbyt/s: 每秒钟接收到的字节数txbyt/s: 每秒钟发送出去的字节数rxcmp/s: 每秒钟接收到的压缩包数目txcmp/s: 每秒钟发送出去的压缩包数目txmcst/s: 每秒钟接收到的多播包的包数目-f 选项查看有一天的网卡流量历史,后面跟某天对应的文件名:
sar -n DEV -f /var/log/sa/sa174、dig
查看dns运行状态工具。
yum install bind-utils参数:
@<服务器地址>:指定进行域名解析的域名服务器;-b<ip地址>:当主机具有多个IP地址,指定使用本机的哪个IP地址向域名服务器发送域名查询请求;-f<文件名称>:指定dig以批处理的方式运行,指定的文件中保存着需要批处理查询的DNS任务信息;-P:指定域名服务器所使用端口号;-t<类型>:指定要查询的DNS数据类型;-x<IP地址>:执行逆向域名查询;-4:使用IPv4;-6:使用IPv6;-h:显示指令帮助信息。使用:
[root@localhost ~]# dig www.linuxde.net; <<>> DiG 9.3.6-P1-RedHat-9.3.6-20.P1.el5_8.1 <<>> www.linuxde.net;; global options: printcmd;; Got answer:;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 2115;; flags: qr rd ra; QUERY: 1, ANSWER: 2, AUTHORITY: 2, ADDITIONAL: 0;; QUESTION SECTION:;www.linuxde.net. IN A;; ANSWER SECTION:www.linuxde.net. 0 IN CNAME host.1.linuxde.net.host.1.linuxde.net. 0 IN A 100.42.212.8;; AUTHORITY SECTION:linuxde.net. 8 IN NS f1g1ns2.dnspod.net.linuxde.net. 8 IN NS f1g1ns1.dnspod.net.;; Query time: 0 msec;; SERVER: 202.96.104.15#53(202.96.104.15);; WHEN: Thu Dec 26 11:14:37 2013;; MSG SIZE rcvd: 1215、route
查看路由表:
[root@localhost proc]# route -nKernel IP routing tableDestination Gateway Genmask Flags Metric Ref Use Iface0.0.0.0 192.168.174.2 0.0.0.0 UG 100 0 0 eth0172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0192.168.122.0 0.0.0.0 255.255.255.0 U 0 0 0 virbr0192.168.174.0 0.0.0.0 255.255.255.0 U 100 0 0 eth06、ethtool
带宽查看:
ethtool ens192Settings for ens192: Supported ports: [ TP ] Supported link modes: 1000baseT/Full 10000baseT/Full Supported pause frame use: No Supports auto-negotiation: No Advertised link modes: Not reported Advertised pause frame use: No Advertised auto-negotiation: No <span style="color:#ff0000;">Speed: 10000Mb/s</span> Duplex: Full Port: Twisted Pair PHYAD: 0 Transceiver: internal Auto-negotiation: off MDI-X: Unknown Supports Wake-on: uag Wake-on: d Link detected: yesSpeed: 10000Mb/s Duplex: Full Port: Twisted Pair PHYAD: 0 Transceiver: internal Auto-negotiation: off MDI-X: Unknown Supports Wake-on: uag Wake-on: d Link detected: yes7、lsof
某端口使用情况:
[root@localhost mysql]# lsof -i:22COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAMEsshd 1150 root 3u IPv4 18264 0t0 TCP *:ssh (LISTEN)sshd 1150 root 4u IPv6 18273 0t0 TCP *:ssh (LISTEN)sshd 2617 root 3u IPv4 20437 0t0 TCP localhost.localdomain:ssh->192.168.174.1:60426 (ESTABLISHED)[root@localhost mysql]# 输出说明:
COMMAND:进程的名称PID:进程标识符USER:进程所有者FD:文件描述符,应用程序通过文件描述符识别该文件。如cwd、txt等TYPE:文件类型,如DIR、REG等DEVICE:指定磁盘的名称SIZE:文件的大小NODE:索引节点(文件在磁盘上的标识)NAME:打开文件的确切名称8、tcpdump
使用 tcpdump进行抓包。
参数:
-a:尝试将网络和广播地址转换成名称;-c<数据包数目>:收到指定的数据包数目后,就停止进行倾倒操作;-d:把编译过的数据包编码转换成可阅读的格式,并倾倒到标准输出;-dd:把编译过的数据包编码转换成C语言的格式,并倾倒到标准输出;-ddd:把编译过的数据包编码转换成十进制数字的格式,并倾倒到标准输出;-e:在每列倾倒资料上显示连接层级的文件头;-f:用数字显示网际网络地址;-F<表达文件>:指定内含表达方式的文件;-i<网络界面>:使用指定的网络截面送出数据包;-l:使用标准输出列的缓冲区;-n:不把主机的网络地址转换成名字;-N:不列出域名;-O:不将数据包编码最佳化;-p:不让网络界面进入混杂模式;-q :快速输出,仅列出少数的传输协议信息;-r<数据包文件>:从指定的文件读取数据包数据;-s<数据包大小>:设置每个数据包的大小;-S:用绝对而非相对数值列出TCP关联数;-t:在每列倾倒资料上不显示时间戳记;-tt: 在每列倾倒资料上显示未经格式化的时间戳记;-T<数据包类型>:强制将表达方式所指定的数据包转译成设置的数据包类型;-v:详细显示指令执行过程;-vv:更详细显示指令执行过程;-x:用十六进制字码列出数据包资料;-w<数据包文件>:把数据包数据写入指定的文件。基本使用:
tcpdump #可以抓包,默认抓第一个网卡。tcpdump –i eth1 #指定网卡。tcpdump –nn #将主机名列为数字。tcpdump –nn –so #列出所有完整的包。tcpdump –nn tcp #只抓TCP的包。tcpdump –nn tcp host IP地址 #只抓这个ip的包。tcpdump –nn tcp host IP地址 and port 80 #指定监听端口。tcpdump –nn tcp host IP地址 and port 80 –c 100 –w 1.cap #指定个数写入二进制文件。tcpdump –nn tcp host IP地址 and port 80 –c 100 > 2.cap #指定个数写入文件。
tcpdump的输出格式与协议有关,大部分常用的格式:
链路层头、TCP数据包、UDP数据包、SMB/CIFS解码、AFS请求和回应、KIP APPLETalk协议、IP数据包、时间戳01:05:14.876525 IP 192.168.1.111.ssh > 192.168.1.150.51602: Flags [P.], seq 308912:309200, ack 129, win 725, length 288解析:
01:05:14.876525 # 详细时间IP 192.168.1.111.ssh # 源IP地址.协议端口> # 到哪里192.168.1.150.51602 # 目标IP地址.协议端口: Flags [P.], seq 308912:309200, # 数据ack 129, # ack包 长度win 725, # 字节长度length 288 # 数据商都监视指定主机的数据包:
# 直接启动tcpdump将监视第一个网络接口上所有流过的数据包tcpdump# 监视指定网络接口的数据包tcpdump -i eth1打印所有进入或离开sundown的数据包。tcpdump host sundown# 也可以指定ip,例如截获所有210.27.48.1 的主机收到的和发出的所有的数据包tcpdump host 210.27.48.1# 打印helios 与 hot 或者与 ace 之间通信的数据包tcpdump host helios and \( hot or ace \)# 截获主机210.27.48.1 和主机210.27.48.2 或210.27.48.3的通信tcpdump host 210.27.48.1 and \ (210.27.48.2 or 210.27.48.3 \)# 打印ace与任何其他主机之间通信的IP 数据包, 但不包括与helios之间的数据包.tcpdump ip host ace and not helios# 如果想要获取主机210.27.48.1除了和主机210.27.48.2之外所有主机通信的ip包,使用命令:tcpdump ip host 210.27.48.1 and ! 210.27.48.2#截获主机hostname发送的所有数据tcpdump -i eth0 src host hostname# 监视所有送到主机hostname的数据包tcpdump -i eth0 dst host hostname监视指定主机和端口的数据包:
# 如果想要获取主机210.27.48.1接收或发出的telnet包,使用如下命令tcpdump tcp port 23 host 210.27.48.1# 对本机的udp 123 端口进行监视 123 为ntp的服务端口tcpdump udp port 123监视指定网络的数据包:
# 打印本地主机与Berkeley网络上的主机之间的所有通信数据包tcpdump net ucb-ether注:ucb-ether此处可理解为“Berkeley网络”的网络地址,此表达式最原始的含义可表达为:打印网络地址为ucb-ether的所有数据包# 打印所有通过网关snup的ftp数据包tcpdump 'gateway snup and (port ftp or ftp-data)'注:表达式被单引号括起来了,这可以防止shell对其中的括号进行错误解析# 打印所有源地址或目标地址是本地主机的IP数据包tcpdump ip and not net localnet注:如果本地网络通过网关连到了另一网络,则另一网络并不能算作本地网络。解析cap包:
tcpdump -i eth0 tcp[20:2]=0x4745 or tcp[20:2]=0x504f -w /tmp/tcp.cap -s 512 2>&1 &sleep 10kill `ps aux | grep tcpdump | grep -v grep | awk '{print $2}'`strings /tmp/tcp.cap | grep -E "GET /|POST /|Host:" | grep --no-group-separator -B 1 "Host:" | grep --no-group-separator -A 1 -E "GET /|POST /" | awk '{url=$2;getline;host=$2;printf ("%s\n",host""url)}' > url.txt(( qps=$(wc -l /tmp/url.txt | cut -d' ' -f 1) / 10 ))grep -v -i -E "\.(gif|png|jpg|jpeg|ico|js|swf|css)" /tmp/url.txt | sort | uniq -c | sort -nr | head -n 109、tshark
使用tshark进行抓包。
注:需要安装wireshar抓包工具:
yum -y install wireshark# 可以抓的包命令:tshark# 抓取mysql查询命令:tshark -n -i eth0 'mysql.query' -T fields -e 'ip.src' -e 'mysql.query'# 抓取指定类型的mysql查询tshark -n -i eth0 -R 'mysql matches "SELECT|INSERT|DELETE|UPDATE"' -T fields -e 'ip.src' -e 'mysql.query'# 统计http的状态tshark -n -q -z http,stat, -z http,tree=================================================================== HTTP/Packet Counter value rate percent------------------------------------------------------------------- Total HTTP Packets 0 HTTP Request Packets 0 HTTP Response Packets 0 ???: broken 0 1xx: Informational 0 2xx: Success 0 3xx: Redirection 0 4xx: Client Error 0 5xx: Server Error 0 Other HTTP Packets 0 ======================================================================================================================================HTTP Statistics* HTTP Status Codes in reply packets* List of HTTP Request methods===================================================================10、tcptrack
tcptrack类似iftop,使用pcap库来捕获数据包,并计算各种统计信息,比如每个连接所使用的带宽。它还支持标准的pcap过滤器,这些过滤器可用来监控特定的连接。
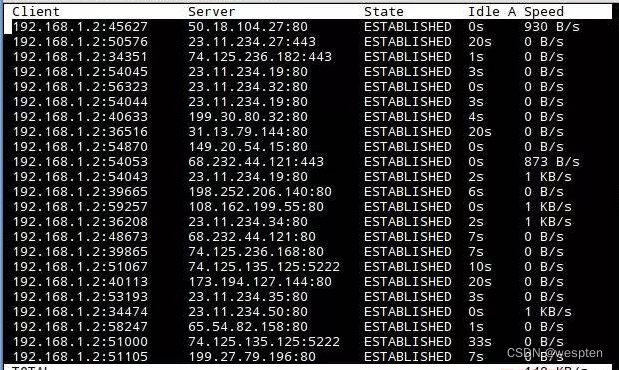
11、nload
nload是一个命令行工具,让用户可以分开来监控入站流量和出站流量。它还可以绘制图表以显示入站流量和出站流量,视图比例可以调整。用起来很简单,不支持许多选项。
所以,如果你只需要快速查看总带宽使用情况,无需每个进程的详细情况,那么nload用起来很方便。
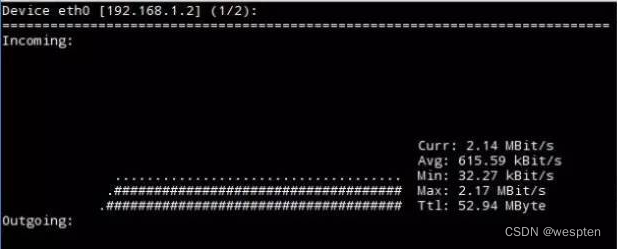
12、iftop
iftop可测量通过每一个套接字连接传输的数据;它采用的工作方式有别于nload。iftop使用pcap库来捕获进出网络适配器的数据包,然后汇总数据包大小和数量,搞清楚总的带宽使用情况。
虽然iftop报告每个连接所使用的带宽,但它无法报告参与某个套按字连接的进程名称/编号(ID)。不过由于基于pcap库,iftop能够过滤流量,并报告由过滤器指定的所选定主机连接的带宽使用情况。
注意:-n选项可以防止iftop将IP地址解析成主机名,解析本身就会带来额外的网络流量。
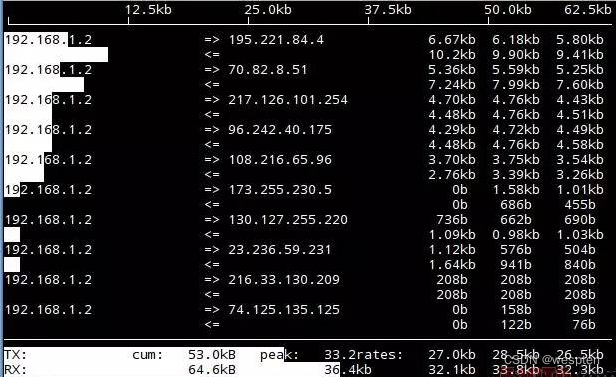
13、 iptraf
iptraf是一款交互式、色彩鲜艳的IP局域网监控工具。它可以显示每个连接以及主机之间传输的数据量。下面是屏幕截图。
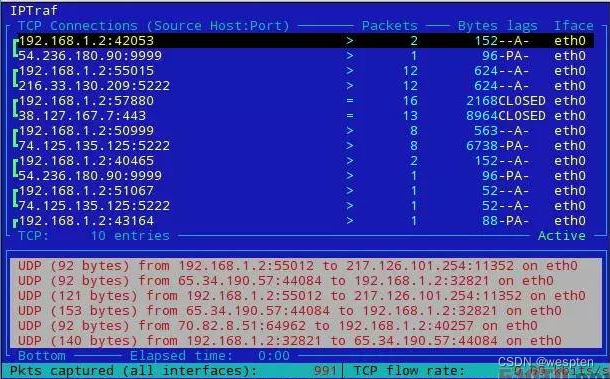
14、 nethogs
nethogs是一款小巧的"net top"工具,可以显示每个进程所使用的带宽,并对列表排序,将耗用带宽最多的进程排在最上面。万一出现带宽使用突然激增的情况,用户迅速打开nethogs,就可以找到导致带宽使用激增的进程。nethogs可以报告程序的进程编号(PID)、用户和路径。
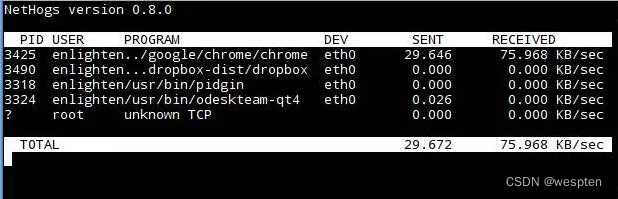
15、bmon
bmon(带宽监控器)是一款类似nload的工具,它可以显示系统上所有网络接口的流量负载。输出结果还含有图表和剖面,附有数据包层面的详细信息。
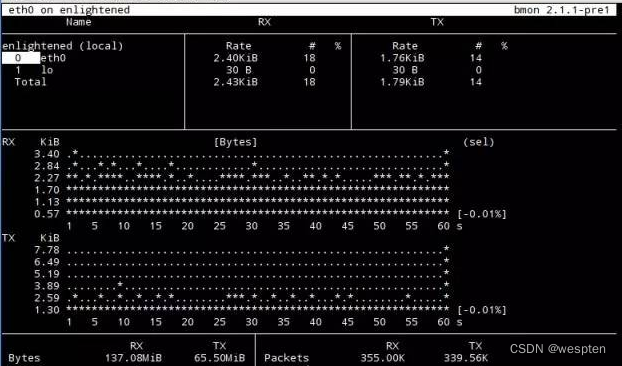
16、slurm
slurm是另一款网络负载监控器,可以显示设备的统计信息,还能显示ASCII图形。它支持三种不同类型的图形,使用c键、s键和l键即可激活每种图形。slurm功能简单,无法显示关于网络负载的任何更进一步的详细信息。

17、vnstat
vnstat与另外大多数工具有点不一样。它实际上运行后台服务/守护进程,始终不停地记录所传输数据的大小。之外,它可以用来制作显示网络使用历史情况的报告。
运行没有任何选项的vnstat,只会显示自守护进程运行以来所传输的数据总量:
$ vnstat Database updated: Mon Mar 17 15:26:59 2014 eth0 since 06/12/13 rx: 135.14 GiB tx: 35.76 GiB total: 170.90 GiB monthly rx | tx | total | avg. rate ------------------------+-------------+-------------+------------- Feb '14 8.19 GiB | 2.08 GiB | 10.27 GiB | 35.60 kbit/s Mar '14 4.98 GiB | 1.52 GiB | 6.50 GiB | 37.93 kbit/s ------------------------+-------------+-------------+------------- estimated 9.28 GiB | 2.83 GiB | 12.11 GiB | daily rx | tx | total | avg. rate ------------------------+-------------+-------------+------------- yesterday 236.11 MiB | 98.61 MiB | 334.72 MiB | 31.74 kbit/s today 128.55 MiB | 41.00 MiB | 169.56 MiB | 24.97 kbit/s ------------------------+-------------+-------------+------------- estimated 199 MiB | 63 MiB | 262 MiB | 想实时监控带宽使用情况,请使用"-l"选项(实时模式)。然后,它会显示入站数据和出站数据所使用的总带宽量,但非常精确地显示,没有关于主机连接或进程的任何内部详细信息。
$ vnstat -l -i eth0 Monitoring eth0... (press CTRL-C to stop) rx: 12 kbit/s 10 p/s tx: 12 kbit/s 11 p/s vnstat更像是一款制作历史报告的工具,显示每天或过去一个月使用了多少带宽。它并不是严格意义上的实时监控网络的工具。
18、bwm-ng
bwm-ng(下一代带宽监控器)是另一款非常简单的实时网络负载监控工具,可以报告摘要信息,显示进出系统上所有可用网络接口的不同数据的传输速度。
$ bwm-ng bwm-ng v0.6 (probing every 0.500s), press 'h' for help input: /proc/net/dev type: rate / iface Rx Tx T ot================================================================= == eth0: 0.53 KB/s 1.31 KB/s 1.84 KB lo: 0.00 KB/s 0.00 KB/s 0.00 KB------------------------------------------------------------------------------------------------------------- total: 0.53 KB/s 1.31 KB/s 1.84 KB/s 如果控制台足够大,bwm-ng还能使用curses2输出模式,为流量绘制条形图。
19、 cbm:Color Bandwidth Meter
这是一款小巧简单的带宽监控工具,可以显示通过诸网络接口的流量大小。没有进一步的选项,仅仅实时显示和更新流量的统计信息。
20、 speedometer
这是另一款小巧而简单的工具,仅仅绘制外观漂亮的图形,显示通过某个接口传输的入站流量和出站流量。

21、 pktstat
pktstat可以实时显示所有活动连接,并显示哪些数据通过这些活动连接传输的速度。它还可以显示连接类型,比如TCP连接或UDP连接;如果涉及HTTP连接,还会显示关于HTTP请求的详细信息。

22、netwatch
netwatch是netdiag工具库的一部分,它也可以显示本地主机与其他远程主机之间的连接,并显示哪些数据在每个连接上所传输的速度。
23、trafshow
与netwatch和pktstat一样,trafshow也可以报告当前活动连接、它们使用的协议以及每条连接上的数据传输速度。它能使用pcap类型过滤器,对连接进行过滤。
只监控TCP连接:

24、netload
netload命令只显示关于当前流量负载的一份简短报告,并显示自程序启动以来所传输的总字节量。没有更多的功能特性。它是netdiag的一部分。
25、ifstat
ifstat能够以批处理式模式显示网络带宽。输出采用的一种格式便于用户使用其他程序或实用工具来记入日志和分析。
$ ifstat -t -i eth0 0.5 Time eth0 HH:MM:SS KB/s in KB/s out 09:59:21 2.62 2.80 09:59:22 2.10 1.78 09:59:22 2.67 1.84 09:59:23 2.06 1.98 09:59:23 1.73 1.79 26、dstat
dstat是一款用途广泛的工具(用python语言编写),它可以监控系统的不同统计信息,并使用批处理模式来报告,或者将相关数据记入到CSV或类似的文件。这个例子显示了如何使用dstat来报告网络带宽。
$ dstat -nt -net/total- ----system---- recv send| time 0 0 |23-03 10:27:13 1738B 1810B|23-03 10:27:14 2937B 2610B|23-03 10:27:15 2319B 2232B|23-03 10:27:16 2738B 2508B|23-03 10:27:17 27、collectl
collectl以一种类似dstat的格式报告系统的统计信息;与dstat一样,它也收集关于系统不同资源(如处理器、内存和网络等)的统计信息。这里给出的一个简单例子显示了如何使用collectl来报告网络使用/带宽。
个进程的详细情况,需要使用pidstat来查看每个进程
总结:
监控总体带宽使用――nload、bmon、slurm、bwm-ng、cbm、speedometer和netload
监控总体带宽使用(批量式输出)――vnstat、ifstat、dstat和collectl
每个套接字连接的带宽使用――iftop、iptraf、tcptrack、pktstat、netwatch和trafshow
每个进程的带宽使用――nethogs