文章目录
前言一、ACON激活函数论文简介ACON familyYOLOv5中应用 二、注意力机制CBAM论文简介CBAM注意力机制YOLOv5中应用 CA论文简介Coordinate AttentionYOLOv5中应用加入CA后无法显示GFLOPs信息 三、BiFPN特征融合论文简介双向加权特征金字塔BiFPNYOLOv5中应用(作者自己改的)进一步结合BiFPN References
前言
【魔改YOLOv5-6.x(上)】:结合轻量化网络Shufflenetv2、Mobilenetv3和Ghostnet
本文使用的YOLOv5版本为v6.1,对YOLOv5-6.x网络结构还不熟悉的同学们,可以移步至:【YOLOv5-6.x】网络模型&源码解析
另外,本文所使用的实验环境为1个GTX 1080 GPU,数据集为VOC2007,超参数为hyp.scratch-low.yaml,训练200个epoch,其他参数均为源码中默认设置的数值。
YOLOv5中修改网络结构的一般步骤:
models/common.py:在common.py文件中,加入要修改的模块代码models/yolo.py:在yolo.py文件内的parse_model函数里添加新模块的名称models/new_model.yaml:在models文件夹下新建模块对应的.yaml文件一、ACON激活函数
Ma, Ningning, et al. “Activate or not: Learning customized activation.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.
论文地址
论文代码
论文简介
ReLU激活函数在很长一段时间都是最佳的神经网络激活函数,主要是由于其非饱和、稀疏性等优秀的特性,但是它也同样会产生神经元坏死的严重后果。而近年来人们使用NAS搜索技术找到的Swish激活函数效果非常好,但是问题是Swish激活函数是使用NAS技术暴力搜索出来的,我们无法真正解释Swish激活函数效果这么好的真正原因是什么?
在这篇论文中,作者尝试从Swish激活函数和ReLU激活函数的公式出发,挖掘其中的平滑近似原理(Smooth Approximation),并且将这个原理应用到Maxout family激活函数,提出了一种新型的激活函数:ACON family 激活函数。通过大量实验证明,ACON family 激活函数在分类、检测等任务中性能都优于ReLU和Swish激活函数。
ACON family
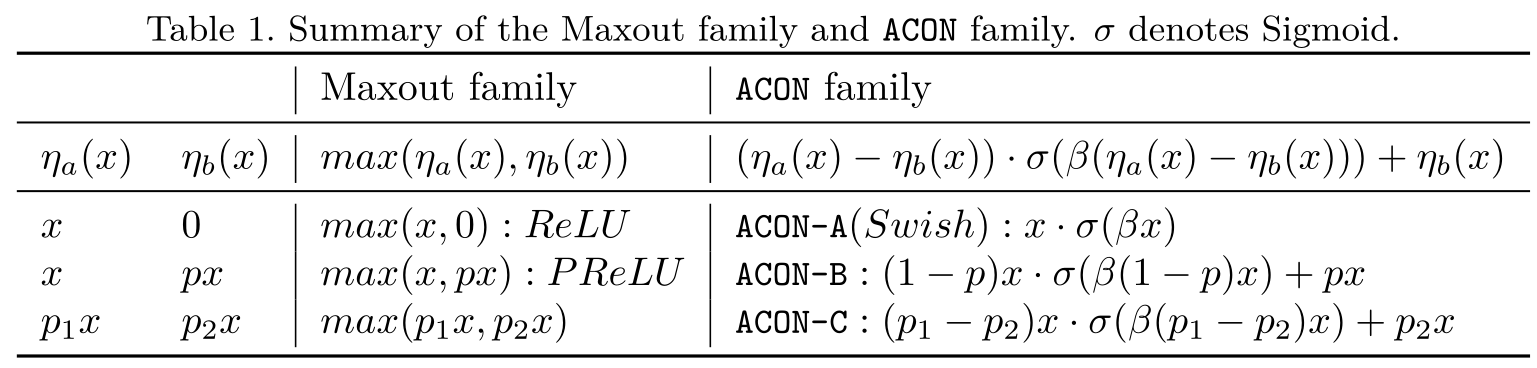
作者提出一种新颖的Swish函数解释:Swish函数是ReLU函数的平滑近似(Smoth maximum),并基于这个发现,进一步分析ReLU的一般形式Maxout系列激活函数,利用Smoth maximum将Maxout系列扩展得到简单且有效的ACON系列激活函数:ACON-A、ACON-B、ACON-C。
同时提出meta-ACON,动态的学习(自适应)激活函数的线性/非线性,控制网络每一层的非线性程度,显著提高了表现。另外还证明了ACON的参数 P 1 P_1 P1和 P 2 P_2 P2负责控制函数的上下限(这个对最终效果由很大的意义),参数 β \beta β负责动态的控制激活函数的线性/非线性。
ACON激活函数的性质:
ACON-A(Swish函数)是ReLU函数的平滑近似(Smoth maximum)ACON-C的一阶导数的上下界也是通过 P 1 P_1 P1和 P 2 P_2 P2两个参数来共同决定的,通过学习 P 1 P_1 P1和 P 2 P_2 P2,能获得性能更好的激活函数参数 β \beta β负责动态的控制激活函数的线性/非线性,这种定制的激活行为有助于提高泛化和传递性能meta-ACON激活函数中参数 β \beta β,通过一个小型卷积网络,并通过Sigmoid函数学习得到YOLOv5中应用
同Ghost模块一样,在最新版本的YOLOv5-6.1源码中,作者已经加入了ACON激活函数,并在utils\activations.py文件下,给出了ACON激活函数适用于YOLOv5中的源码:
# ACON https://arxiv.org/pdf/2009.04759.pdf ----------------------------------------------------------------------------class AconC(nn.Module): r""" ACON activation (activate or not). AconC: (p1*x-p2*x) * sigmoid(beta*(p1*x-p2*x)) + p2*x, beta is a learnable parameter according to "Activate or Not: Learning Customized Activation" <https://arxiv.org/pdf/2009.04759.pdf>. """ def __init__(self, c1): super().__init__() # nn.Parameter的作用是:将一个不可训练的类型Tensor转换成可以训练的类型parameter # 并且会向宿主模型注册该参数 成为其一部分 即model.parameters()会包含这个parameter # 从而在参数优化的时候可以自动一起优化 self.p1 = nn.Parameter(torch.randn(1, c1, 1, 1)) self.p2 = nn.Parameter(torch.randn(1, c1, 1, 1)) self.beta = nn.Parameter(torch.ones(1, c1, 1, 1)) def forward(self, x): dpx = (self.p1 - self.p2) * x return dpx * torch.sigmoid(self.beta * dpx) + self.p2 * xclass MetaAconC(nn.Module): r""" ACON activation (activate or not). MetaAconC: (p1*x-p2*x) * sigmoid(beta*(p1*x-p2*x)) + p2*x, beta is generated by a small network according to "Activate or Not: Learning Customized Activation" <https://arxiv.org/pdf/2009.04759.pdf>. """ def __init__(self, c1, k=1, s=1, r=16): # ch_in, kernel, stride, r super().__init__() # 为了减少参数我们在两个中间的channel加了个缩放参数r,默认设置为16 c2 = max(r, c1 // r) self.p1 = nn.Parameter(torch.randn(1, c1, 1, 1)) self.p2 = nn.Parameter(torch.randn(1, c1, 1, 1)) self.fc1 = nn.Conv2d(c1, c2, k, s, bias=True) self.fc2 = nn.Conv2d(c2, c1, k, s, bias=True) # self.bn1 = nn.BatchNorm2d(c2) # self.bn2 = nn.BatchNorm2d(c1) def forward(self, x): # 自适应函数的设计空间包含了layer-wise, channel-wise, pixel-wise这三种空间 分别对应的是层, 通道, 像素 # 这里我们选择了channel-wise 首先分别对H, W维度求均值 然后通过两个卷积层 使得每一个通道所有像素共享一个权重 # 最后由sigmoid激活函数求得beta y = x.mean(dim=2, keepdims=True).mean(dim=3, keepdims=True) # batch-size 1 bug/instabilities https://github.com/ultralytics/yolov5/issues/2891 # beta = torch.sigmoid(self.bn2(self.fc2(self.bn1(self.fc1(y))))) # bug/unstable beta = torch.sigmoid(self.fc2(self.fc1(y))) # bug patch BN layers removed dpx = (self.p1 - self.p2) * x return dpx * torch.sigmoid(beta * dpx) + self.p2 * x因此我们直接在models\common.py中的Conv函数进行替换(替换nn.SiLU())即可:
from utils.activations import MetaAconCclass Conv(nn.Module): # Standard convolution def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups super().__init__() self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False) self.bn = nn.BatchNorm2d(c2) # 这里的nn.Identity()不改变input,直接return input # self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity()) self.act = MetaAconC(c1=c2) if act is True else (act if isinstance(act, nn.Module) else nn.Identity()) def forward(self, x): return self.act(self.bn(self.conv(x))) # 前向加速推理模块 # 用于Model类的fuse函数,融合conv+bn 加速推理 一般用于测试/验证阶段 def forward_fuse(self, x): return self.act(self.conv(x))
二、注意力机制
CBAM
Woo, Sanghyun, et al. “Cbam: Convolutional block attention module.” Proceedings of the European conference on computer vision (ECCV). 2018.
论文地址
论文代码
论文简介
作者提出了一种轻量的注意力模块,可以在通道和空间维度上进行 Attention,核心算法其实就是:通道注意力模块(Channel Attention Module,CAM) +空间注意力模块(Spartial Attention Module,SAM) ,分别进行通道与空间上的 Attention,通道上的 Attention 机制在 2017 年的 SENet 就被提出,CBAM中的CAM 与 SENet 相比,只是多了一个并行的 Max Pooling 层。
CBAM注意力机制
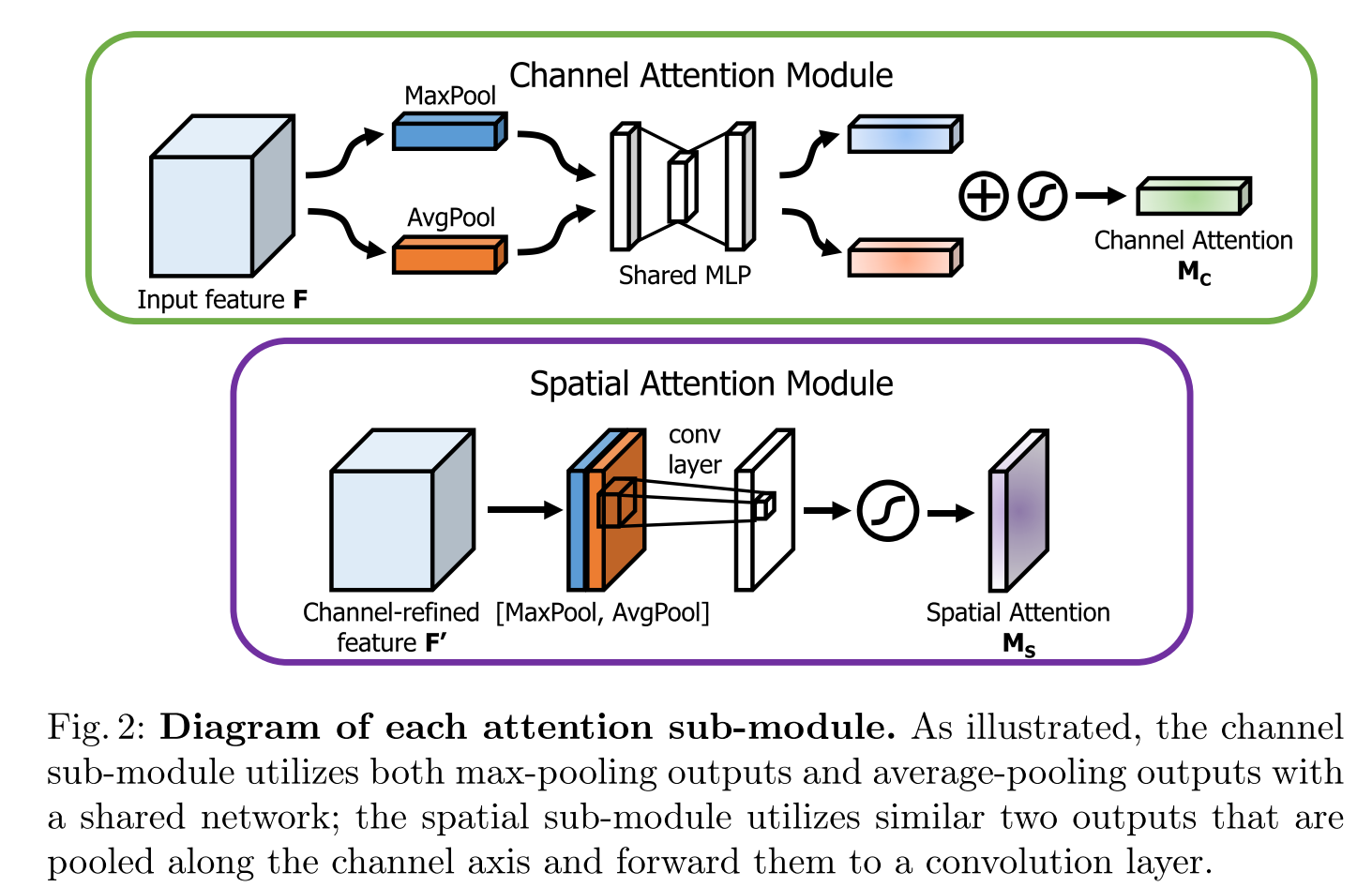
CBAM可以分为channel attention和spatial attention两个模块,至于哪个在前,哪个在后,作者通过实验发现,先channel在spatial效果更好一些:
Channel Attention:将输入的特征图F( H × W × C H×W×C H×W×C)分别经过基于width和height(对每一个channel)的Global Max Pooling(GMP 全局最大池化)和Global Average Pooling(GAP 全局平均池化),得到两个 1 × 1 × C 1×1×C 1×1×C的特征图,接着,再将它们分别送入一个两层的神经网络(MLP),第一层神经元个数为 C / r C/r C/r(r为减少率),激活函数为 Relu,第二层神经元个数为 C C C,这个两层的神经网络是共享的。而后,将MLP输出的特征进行基于element-wise的add操作,再经过sigmoid归一化操作,生成最终的channel attention feature,即 M c M_c Mc 在channel attention中,作者对于pooling的使用进行了实验对比,发现avg & max的并行池化的效果要更好,这里也有可能是池化丢失的信息太多,avg&max的并行连接方式比单一的池化丢失的信息更少,所以效果会更好一点 Spatial Attention:将Channel Attention模块输出的特征图 F ′ F' F′作为本模块的输入特征图。首先做一个基于channel的GMP和GAP,得到两个 H × W × 1 H×W×1 H×W×1的特征图,然后将这2个特征图基于channel 做concat操作(通道拼接)。然后经过一个7×7卷积(7×7比3×3效果要好)操作,降维为1个channel,即 H × W × 1 H×W×1 H×W×1。再经过sigmoid生成spatial attention feature,即 M s M_s Ms。最后将 M s M_s Ms和该模块的输入feature做乘法,得到最终生成的特征图YOLOv5中应用
YOLOv5结合注意力机制有两种策略:
注意力机制结合Bottleneck,替换backbone中的所有C3模块在backbone最后单独加入注意力模块这里展示第一种策略,在介绍CA注意力时,展示第二种策略。另外根据实验结果,第二种策略效果会更好。
common.py文件修改:直接在最下面加入如下代码# ---------------------------- CBAM start ---------------------------------class ChannelAttention(nn.Module): def __init__(self, in_planes, ratio=16): super(ChannelAttention, self).__init__() self.avg_pool = nn.AdaptiveAvgPool2d(1) self.max_pool = nn.AdaptiveMaxPool2d(1) # in_planes // ratio 这里会出现如下警告: # UserWarning: __floordiv__ is deprecated(被舍弃了), and its behavior will change in a future version of pytorch. # It currently rounds toward 0 (like the 'trunc' function NOT 'floor'). # This results in incorrect rounding for negative values. # To keep the current behavior, use torch.div(a, b, rounding_mode='trunc'), # or for actual floor division, use torch.div(a, b, rounding_mode='floor'). # kernel = torch.DoubleTensor([*(x[0].shape[2:])]) // torch.DoubleTensor(list((m.output_size,))).squeeze() self.f1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False) self.relu = nn.ReLU() self.f2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False) # 写法二,亦可使用顺序容器 # self.sharedMLP = nn.Sequential( # nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False), nn.ReLU(), # nn.Conv2d(in_planes // rotio, in_planes, 1, bias=False)) self.sigmoid = nn.Sigmoid() def forward(self, x): # 全局平均池化—>MLP两层卷积 avg_out = self.f2(self.relu(self.f1(self.avg_pool(x)))) # 全局最大池化—>MLP两层卷积 max_out = self.f2(self.relu(self.f1(self.max_pool(x)))) out = self.sigmoid(avg_out + max_out) return outclass SpatialAttention(nn.Module): def __init__(self, kernel_size=7): super(SpatialAttention, self).__init__() assert kernel_size in (3, 7), 'kernel size must be 3 or 7' padding = 3 if kernel_size == 7 else 1 self.conv = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False) self.sigmoid = nn.Sigmoid() def forward(self, x): # 基于channel的全局平均池化(channel=1) avg_out = torch.mean(x, dim=1, keepdim=True) # 基于channel的全局最大池化(channel=1) max_out, _ = torch.max(x, dim=1, keepdim=True) # channel拼接(channel=2) x = torch.cat([avg_out, max_out], dim=1) # channel=1 x = self.conv(x) return self.sigmoid(x) class CBAMBottleneck(nn.Module): # ch_in, ch_out, shortcut, groups, expansion, ratio, kernel_size def __init__(self, c1, c2, shortcut=True, g=1, e=0.5, ratio=16, kernel_size=7): super(CBAMBottleneck, self).__init__() c_ = int(c2 * e) # hidden channels self.cv1 = Conv(c1, c_, 1, 1) self.cv2 = Conv(c_, c2, 3, 1, g=g) self.add = shortcut and c1 == c2 # 加入CBAM模块 self.channel_attention = ChannelAttention(c2, ratio) self.spatial_attention = SpatialAttention(kernel_size) def forward(self, x): # 考虑加入CBAM模块的位置:bottleneck模块刚开始时、bottleneck模块中shortcut之前,这里选择在shortcut之前 x2 = self.cv2(self.cv1(x)) # x和x2的channel数相同 # 在bottleneck模块中shortcut之前加入CBAM模块 out = self.channel_attention(x2) * x2 # print('outchannels:{}'.format(out.shape)) out = self.spatial_attention(out) * out return x + out if self.add else outclass C3CBAM(C3): # C3 module with CBAMBottleneck() def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): super().__init__(c1, c2, n, shortcut, g, e) # 引入C3(父类)的属性 c_ = int(c2 * e) # hidden channels self.m = nn.Sequential(*(CBAMBottleneck(c_, c_, shortcut) for _ in range(n)))# ----------------------------- CBAM end ----------------------------------yolo.py文件修改:在yolo.py的parse_model函数中,加入CBAMBottleneck, C3CBAM两个模块
新建yaml文件:在model文件下新建yolov5-cbam.yaml文件,复制以下代码即可
# YOLOv5 ? by Ultralytics, GPL-3.0 license# Parametersnc: 20 # number of classesdepth_multiple: 0.33 # model depth multiplewidth_multiple: 0.50 # layer channel multipleanchors: - [10,13, 16,30, 33,23] # P3/8 - [30,61, 62,45, 59,119] # P4/16 - [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbone# 第二种加入方法 全部替换 C3 模块backbone: # [from, number, module, args] [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2 [-1, 1, Conv, [128, 3, 2]], # 1-P2/4 [-1, 3, C3CBAM, [128]], [-1, 1, Conv, [256, 3, 2]], # 3-P3/8 [-1, 6, C3CBAM, [256]], [-1, 1, Conv, [512, 3, 2]], # 5-P4/16 [-1, 9, C3CBAM, [512]], [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32 [-1, 3, C3CBAM, [1024]], [-1, 1, SPPF, [1024, 5]], # 9 ]# YOLOv5 v6.0 headhead: [[-1, 1, Conv, [512, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 6], 1, Concat, [1]], # cat backbone P4 [-1, 3, C3, [512, False]], # 13 [-1, 1, Conv, [256, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 4], 1, Concat, [1]], # cat backbone P3 [-1, 3, C3, [256, False]], # 17 (P3/8-small) [-1, 1, Conv, [256, 3, 2]], [[-1, 14], 1, Concat, [1]], # cat head P4 [-1, 3, C3, [512, False]], # 20 (P4/16-medium) [-1, 1, Conv, [512, 3, 2]], [[-1, 10], 1, Concat, [1]], # cat head P5 [-1, 3, C3, [1024, False]], # 23 (P5/32-large) [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5) ]
CA
Hou, Qibin, Daquan Zhou, and Jiashi Feng. “Coordinate attention for efficient mobile network design.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.
论文地址
论文代码
论文简介
作者提出了一种新的高效注意力机制,为了缓解2D全局池化造成的位置信息丢失,作者将通道注意力分解为两个并行(x和y方向)的1D特征编码过程,有效地将空间坐标信息整合到生成的注意图中。更具体来说,作者利用两个一维全局池化操作分别将垂直和水平方向的输入特征聚合为两个独立的方向感知特征图;
然后,这两个嵌入特定方向信息的特征图分别被编码为两个注意力图,每个注意力图都捕获了输入特征图沿着一个空间方向的长程依赖。因此,位置信息就被保存在生成的注意力图里了,两个注意力图接着被乘到输入特征图上来增强特征图的表示能力。由于这种注意力操作能够区分空间方向(即坐标)并且生成坐标感知的特征图,因此将提出的方法称为坐标注意力(coordinate attention)。
Coordinate Attention
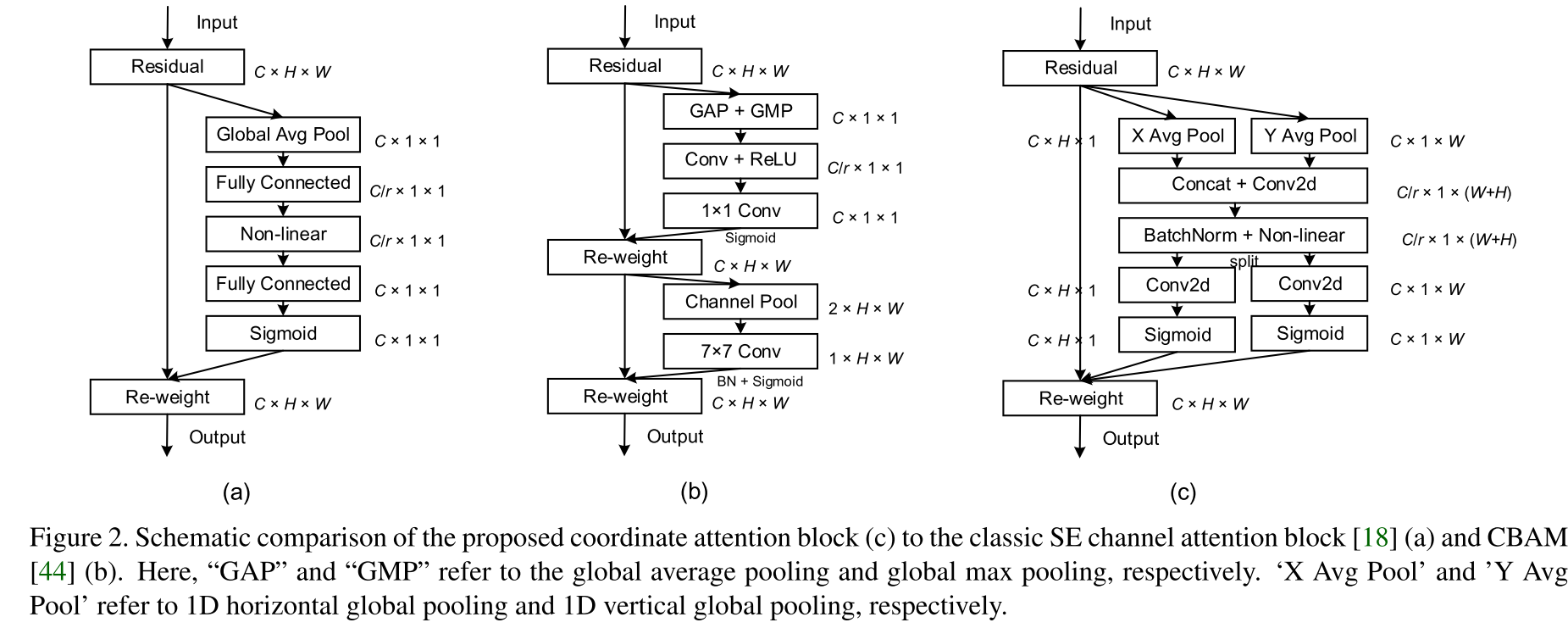
核心算法分为两个步骤:坐标信息嵌入(coordinate information embedding)和坐标注意力生成(coordinate attention generation)
坐标信息嵌入(对应上图的X Avg Pool和Y Avg Pool操作):全局池化常用于通道注意力中来全局编码空间信息为通道描述符,因此难以保存位置信息。为了促进注意力模块能够捕获具有精确位置信息的空间长程依赖,作者将全局池化分解为一对一维特征编码操作。具体而言,对输入 X X X,先使用尺寸 ( H , 1 ) (H,1) (H,1)和 ( 1 , W ) (1,W) (1,W)的池化核沿着水平坐标方向和竖直坐标方向对每个通道进行编码,这两个变换沿着两个空间方向进行特征聚合,返回一对方向感知注意力图
坐标注意力生成(对应上图剩余部分):首先级联(concat)之前模块生成的两个特征图,然后使用一个共享的 1 × 1 1×1 1×1卷积进行变换,生成的 F ′ F' F′是对空间信息在水平方向和竖直方向的中间特征图,这里的 r r r表示下采样比例,用来控制模块大小,接着对 F ′ F' F′进行切分、卷积、归一化等操作,最终生成注意力权重
YOLOv5中应用
YOLOv5结合注意力机制有两种策略:
注意力机制结合Bottleneck,替换backbone中的所有C3模块在backbone最后单独加入注意力模块这里展示第二种策略,在介绍CBAM注意力时,展示第一种策略。另外根据实验结果,第二种策略效果会更好。
common.py文件修改:直接在最下面加入如下代码# ----------------------------- CABlock start ----------------------------------class h_sigmoid(nn.Module): def __init__(self, inplace=True): super(h_sigmoid, self).__init__() self.relu = nn.ReLU6(inplace=inplace) def forward(self, x): return self.relu(x + 3) / 6class h_swish(nn.Module): def __init__(self, inplace=True): super(h_swish, self).__init__() self.sigmoid = h_sigmoid(inplace=inplace) def forward(self, x): return x * self.sigmoid(x) class CABlock(nn.Module): def __init__(self, inp, oup, reduction=32): super(CABlock, self).__init__() # height方向上的均值池化 self.pool_h = nn.AdaptiveAvgPool2d((None, 1)) # width方向上的均值池化 self.pool_w = nn.AdaptiveAvgPool2d((1, None)) mip = max(8, inp // reduction) self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0) self.bn1 = nn.BatchNorm2d(mip) self.act = h_swish() self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0) self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0) def forward(self, x): identity = x n, c, h, w = x.size() x_h = self.pool_h(x) x_w = self.pool_w(x).permute(0, 1, 3, 2) y = torch.cat([x_h, x_w], dim=2) y = self.conv1(y) y = self.bn1(y) y = self.act(y) x_h, x_w = torch.split(y, [h, w], dim=2) x_w = x_w.permute(0, 1, 3, 2) a_h = self.conv_h(x_h).sigmoid() a_w = self.conv_w(x_w).sigmoid() out = identity * a_w * a_h return out# ----------------------------- CABlock end ----------------------------------yolo.py文件修改:在yolo.py的parse_model函数中,加入h_sigmoid, h_swish, CABlock三个模块
新建yaml文件:在model文件下新建yolov5-ca.yaml文件,复制以下代码即可(注意backbone层数的变化,neck部分中concat操作对应的参数也要变化)
# YOLOv5 ? by Ultralytics, GPL-3.0 license# Parametersnc: 20 # number of classesdepth_multiple: 0.33 # model depth multiplewidth_multiple: 0.50 # layer channel multipleanchors: - [10,13, 16,30, 33,23] # P3/8 - [30,61, 62,45, 59,119] # P4/16 - [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbonebackbone: # [from, number, module, args] [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2 [-1, 1, Conv, [128, 3, 2]], # 1-P2/4 [-1, 3, C3, [128]], [-1, 1, Conv, [256, 3, 2]], # 3-P3/8 [-1, 6, C3, [256]], [-1, 1, Conv, [512, 3, 2]], # 5-P4/16 [-1, 9, C3, [512]], [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32 [-1, 3, C3, [1024]], [-1, 1, CABlock, [1024, 32]], # 9 CA <-- Coordinate Attention [out_channel, reduction] [-1, 1, SPPF, [1024, 5]], # 10 ]# YOLOv5 v6.0 headhead: [[-1, 1, Conv, [512, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 6], 1, Concat, [1]], # cat backbone P4 [-1, 3, C3, [512, False]], # 14 [-1, 1, Conv, [256, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 4], 1, Concat, [1]], # cat backbone P3 [-1, 3, C3, [256, False]], # 18 (P3/8-small) [-1, 1, Conv, [256, 3, 2]], [[-1, 15], 1, Concat, [1]], # cat head P4 [-1, 3, C3, [512, False]], # 21 (P4/16-medium) [-1, 1, Conv, [512, 3, 2]], [[-1, 11], 1, Concat, [1]], # cat head P5 [-1, 3, C3, [1024, False]], # 24 (P5/32-large) [[18, 21, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5) ]
加入CA后无法显示GFLOPs信息
【YOLOv5-6.x】解决加入CA注意力机制不显示FLOPs的问题
三、BiFPN特征融合
[Cite]Tan, Mingxing, Ruoming Pang, and Quoc V. Le. “Efficientdet: Scalable and efficient object detection.” Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020.
论文地址
论文代码
论文简介
本文系统地研究了用于目标检测的神经网络结构设计选择,并提出了几个关键的优化方法以提高效率
首先,提出了一种加权双向特征金字塔网络(BiFPN),该网络可以实现简单快速的多尺度特征融合
其次,提出了一种Compound Scaling方法,该方法可以同时对所有主干网络、特征网络和盒类预测网络的分辨率、深度和宽度进行统一标度
基于这些优化措施和EfficientNet backbone,开发了一个新的对象检测器系列,称为EfficientDet
双向加权特征金字塔BiFPN
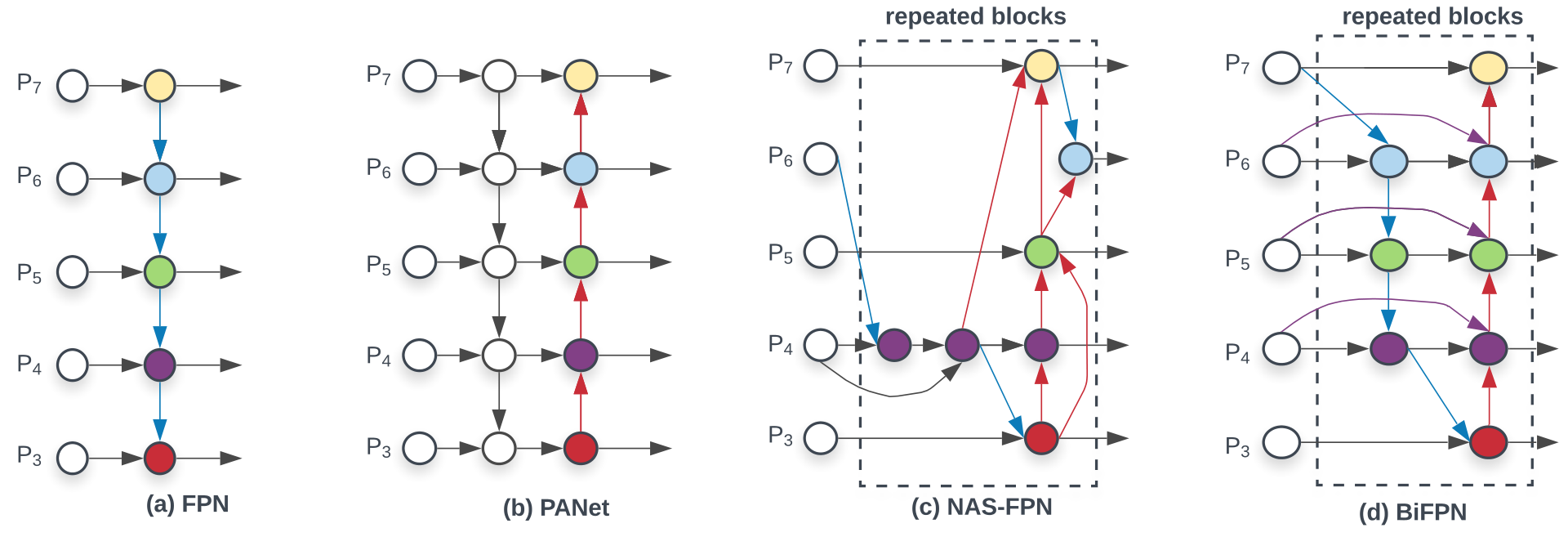
对于多尺度融合,在融合不同的输入特征时,以往的研究(FPN以及一些对FPN的改进工作)大多只是没有区别的将特征相加;然而,由于这些不同的输入特征具有不同的分辨率,我们观察到它们对融合输出特征的贡献往往是不平等的。
为了解决这一问题,作者提出了一种简单而高效的加权(类似与attention)双向特征金字塔网络(BiFPN),它引入可学习的权值来学习不同输入特征的重要性,同时反复应用自顶向下和自下而上的多尺度特征融合:
新的Neck部分—BiFPN:多尺度特征融合的目的,是聚合不同分辨率的特征;以往的特征融合方法对所有输入特征一视同仁,为了解决这个问题,BiFPN引入了加权策略(类似于attention,SENet中的注意力通道)
FPN: P 3 − P 7 P_3-P_7 P3−P7是输入图像的下采样,分辨率依次为输入图像的 1 / 2 i 1/2^i 1/2i倍,最后特征融合的公式是: P 3 o u t = C o n v ( P 3 i n + R e s i z e ( P 4 o u t ) ) P_3^{out}=Conv(P_3^{in}+Resize(P_4^{out})) P3out=Conv(P3in+Resize(P4out)), R e s i z e Resize Resize操作通常是upsampling加权:加上一个可学习的权重,也就是 O = ∑ i w i ⋅ I i O=\sum_{i}w_i·I_i O=∑iwi⋅Ii,但是如果不对 w i w_i wi的范围进行限制,很容易导致训练不稳定,于是很自然的想到对每一个权重用softmax,就是 O = ∑ i e w i ∑ j e w j O=\sum_i\frac{e^{w_i}}{\sum_je^{w_j}} O=∑i∑jewjewi,但是这样速度太慢了,于是又提出了快速的限制方法 O = ∑ i w i ϵ + ∑ j w j O=\sum_i\frac{w_i}{\epsilon+\sum_jw_j} O=∑iϵ+∑jwjwi
为了保证weight大于0,weight前采用relu函数双向:最终的特征图输出结合了当前层与上下两层,一共三层的特征
YOLOv5中应用(作者自己改的)
同Ghost模块、ACON激活函数一样,在最新版本的YOLOv5-6.1源码中,作者已经加入了BiFPN特征融合的yaml文件,并在models\hub\yolov5-bifpn.yaml文件下,给出了BiFPN适用于YOLOv5中的源码:
# YOLOv5 ? by Ultralytics, GPL-3.0 license# Parametersnc: 80 # number of classesdepth_multiple: 1.0 # model depth multiplewidth_multiple: 1.0 # layer channel multipleanchors: - [10,13, 16,30, 33,23] # P3/8 - [30,61, 62,45, 59,119] # P4/16 - [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbonebackbone: # [from, number, module, args] [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2 [-1, 1, Conv, [128, 3, 2]], # 1-P2/4 [-1, 3, C3, [128]], [-1, 1, Conv, [256, 3, 2]], # 3-P3/8 [-1, 6, C3, [256]], [-1, 1, Conv, [512, 3, 2]], # 5-P4/16 [-1, 9, C3, [512]], [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32 [-1, 3, C3, [1024]], [-1, 1, SPPF, [1024, 5]], # 9 ]# YOLOv5 v6.0 BiFPN headhead: [[-1, 1, Conv, [512, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 6], 1, Concat, [1]], # cat backbone P4 [-1, 3, C3, [512, False]], # 13 [-1, 1, Conv, [256, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 4], 1, Concat, [1]], # cat backbone P3 [-1, 3, C3, [256, False]], # 17 (P3/8-small) [-1, 1, Conv, [256, 3, 2]], [[-1, 14, 6], 1, Concat, [1]], # cat P4 <--- BiFPN change [-1, 3, C3, [512, False]], # 20 (P4/16-medium) [-1, 1, Conv, [512, 3, 2]], [[-1, 10], 1, Concat, [1]], # cat head P5 [-1, 3, C3, [1024, False]], # 23 (P5/32-large) [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5) ]可以看到,这里仅仅对neck部分的19层加了一层尺度,并没有设置学习权重,因此严格意义上并不是BiFPN。
进一步结合BiFPN
想要尝试进一步设置学习权重,来结合BiFPN的同志,可以参考这篇博客:【YOLOv5-6.x】通过设置可学习参数来结合BiFPN
References
【论文复现】ACON Activation(2021)
yolov5加入CBAM,SE,CA,ECA注意力机制,纯代码(22.3.1还更新)
pytorch中加入注意力机制(CBAM),以yolov5为例
令人拍案叫绝的EfficientNet和EfficientDet