本文先进行之前所学决策树的简单回顾,后进行ID3决策树模型的python代码手动实现,sklearn中cart决策树的使用,以及生成树的可视化操作。
其实回过头来再次学习,已经比第一遍简单太多太多,too much too much了。所以无论困难与否,学习始终是一件让人进步的事情。
前篇: AI遮天传 ML-初识决策树_老师我作业忘带了的博客-CSDN博客
文章目录
一、回顾决策树
1.1 基础认识
1.2 决策树ID3算法
1.2.1 最佳决策属性->Impurity->IG
1.2.2 停止分裂
1.2.3 优缺点、归纳偏置
1.3 处理过拟合问题->预剪枝-后剪枝
1.3.1 对于预剪枝
1.3.2 对于后剪枝
1.4 拓展
二、ID3决策树模型代码实现
三、sklearn里的决策树
3.1 介绍
3.2 分类 DecisionTreeClassifier()
3.3 回归 DecisionTreeRegressor()
3.4 复杂度分析
3.5 使用技巧
四、决策树可视化
方法1: plot_tree
方法2:graphviz
一、回顾决策树
以下是回顾内容,建议无基础的小伙伴从上方连接看起。
1.1 基础认识
在过去学习的日子里,我们简简单单认识了决策树:
想象一个已经生成好了的树状的结构,假如今天:
天气(晴)-->温度(正常)-->湿度(正常)-->风力(小) ,那么我们出去玩;
但如果:
天气(阴)-->温度(正常)-->湿度(高)-->风力(大),那么我们不出去玩。
以上两条路皆是我们从树的顶部走到最后,根据 不同特征 的 不同取值 选择在这个特征节点下一步要走的方向,直到做出决策。
我们介绍了决策树适用的经典目标问题
带有非数值特征的分类问题离散特征没有相似度的特征无序
1.2 决策树ID3算法
我们还介绍了决策树的经典ID3算法:
它是一种 自顶向下的贪心搜索,是一种递归算法(树),它的核心循环步骤如下:
A :找出下一步 最佳 决策属性将 A 作为当前节点决策属性对属性A (vi )的每个值,创建与其对应的新的子节点根据属性值将训练样本分配到各个节点如果 训练样本被完美分类,则退出循环,否则进入递归状态继续向下探分裂新的叶节点
1.2.1 最佳决策属性->Impurity->IG
为了找出最佳决策属,我们引入了混杂度(Impurity) 这个概念,衡量混杂度的方法一般这三种:
熵(Entropy)Gini 混杂度错分类混杂度知道了特征节点混杂度以后我们继续引入 信息增益(IG),即原始节点的熵值 减去 经过属性分类以后的期望熵值,来计算混杂度的变化。
由于我们倾向于树 越简洁越好 (奥卡姆剃刀:偏向于符合数据的最短的假设),即下图左边比右边好:

所以我们每次想要这棵树经过每次分类后,不确定的信息减少的多一点,也就是剩下的更“纯”一点,所以Gain也就是信息增益的值越大越好,我们由此判断出哪个属性或者特征来做根节点/下一个节点更好。
1.2.2 停止分裂
为了确定 训练样本被完美分类,也就是何时停止分裂,我们考虑了3种情况:
情形 1: 如果当前子集中所有数据 有完全相同的输出类别,那么终止情形 2: 如果当前子集中所有数据 有完全相同的输入特征,那么终止 比如:晴天-无风-湿度正常-温度合适,最后有的去了有的没去。此时即使不终止也没办法了,因为能用的信息已经用完了。这意味着:1、数据有噪声noise。需要进行清理,如果噪声过多说明数据质量不够好。2、漏掉了重要的Feature,比如漏掉了当天是否有课,有课就没办法出去玩。可能的情形3: 如果 所有属性分裂的信息增益为0, 那么终止。但这不是一个好的想法,如果IG=0甚至在第一步就无法选择任何属性,无法生成一个树~
即ID3算法只有上面两种情况会停止分裂,如果IG=0就随便选一个好了。
1.2.3 优缺点、归纳偏置
我们还说了一些ID3决策树的优缺点:
假设空间是完备的(即能处理属性的析取又能处理属性的合取) 目标函数一定在假设空间里输出单个假设(沿着树的一条路走下去) 不超过20个问题(根据经验,一般feature不超过20个,过于复杂树比较长也容易产生过拟合)没有回溯(以A1做根节点,没办法退回去看A2做根节点怎么样) 局部最优在每一步中使用子集的所有数据(比如梯度下降算法里权值的更新策略是每条数据更新一次的话,那就是每次只使用一条数据) 数据驱动的搜索选择对噪声数据有鲁棒性
ID3中的归纳偏置(Inductive Bias)
假设空间 H 是作用在样本集合 X 上的 没有对假设空间作限制偏向于在靠近根节点处的属性具有更大信息增益的树 该算法的偏置在于对某些假设具有一些偏好 (搜索偏置,尝试找到最短的树), 而不是对假设空间 H 做限制(描述偏置).奥卡姆剃刀(Occam’s Razor)*:偏向于符合数据的最短的假设
1.3 处理过拟合问题->预剪枝-后剪枝
决策树过拟合的一个极端例子:
每个叶节点都对应单个训练样本 —— 每个训练样本都被完美地分类整个树相当于仅仅是一个 数据查表 算法的简单实现
为了避免过拟合问题,我们介绍了 预剪枝 和 后剪枝
对决策树来说有两种方法避免过拟合
当数据的分裂在统计意义上并不显著(如样例少)时,就停止增长:预剪枝构建一棵完全树,然后再做后剪枝
1.3.1 对于预剪枝
对于预剪枝我们很难估计最后树的大小
方式1:基于样本数量的预剪枝(按照特定比例停止)
通常一个节点不再继续分裂,当:
到达一个节点的训练样本数小于训练集合的一个特定比例 (例如 5%),无论混杂度或错误率是多少,我们都让其停止分裂。因为基于过少数据样本的决定会带来较大误差和泛化错误(盲人摸象)。
方式2: 基于信息增益的阈值
我们一般设定一个较小的阈值,如果 信息增益IG<阈值,就停止分裂。
这样做的好处是 1. 用到了所有训练数据 2. 叶节点可能在树中的任何一层
但缺点是 很难设定一个好的阈值
1.3.2 对于后剪枝
方法1:错误降低后剪枝
此时树已经生成,我们可以在 验证集 上测试剪去每个可能节点(和以其为根的子树)。
我们 从后到前,在验证集上一点点减枝。贪心地去掉某个可以提升验证集准确率的节点,直到再剪就会对损害性能。
剪掉某个或某些长度不等的枝干后,我们要对其进行最后结果的赋值:
赋值成最常见的类别(60个data,50个+10个-,那就+)给这个节点多类别的标签 每个类别有一个支持度(5/6:1/6) (根据训练集中每种标签的数目)测试时: 依据概率(5/6:1/6)选择某个类别或选择多个标签如果是一个回归树 (数值标签),可以做平均或加权平均……
方法2:规则后剪枝
1. 把树转换成等价的由规则构成的集合
• e.g. if (outlook=sunny)^ (humidity=high) then playTennis = no
2. 对每条规则进行剪枝,去除哪些能够提升该规则准确率的规则前件
• i.e. (outlook=sunny)60%, (humidity=high)85%,(outlook=sunny)^ (humidity=high)80%
3. 将规则排序成一个序列 (验证集:根据规则的准确率从高往低排序)
4. 用该序列中的最终规则对样本进行分类(依次查看是否满足规则序列,即在规则集合上一条一条往下走直到能判断出来)
注:在规则被剪枝后,它可能不再能恢复成一棵树。
这是一种被广泛使用的方法,例如C4.5。
1.4 拓展
以及一些拓展,也就是处理数据用来使其适合决策树的方法:处理连续属性值、具有过多取值的属性、未知属性、有代价的属性等...
详细文章:AI遮天传 ML-初识决策树_老师我作业忘带了的博客-CSDN博客
实战案例:英雄联盟胜负预测--简易肯德基上校_老师我作业忘带了的博客-CSDN博客
二、ID3决策树模型代码实现
思路其实以及很清晰了,模型完成的方式有很多种,但流程其实都是一样的。
下方计算混杂度的方式只写了 熵 与 gini ,因为在n类时,最大错分类混杂度与gini混杂度是一样的。
# 定义决策树类class DecisionTree(object): def __init__(self, classes, features, max_depth=10, min_samples_split=10, impurity_t='entropy'): ''' 传入一些可能用到的模型参数,也可能不会用到 classes表示模型分类总共有几类 features是每个特征的名字,也方便查询总的共特征数 max_depth表示构建决策树时的最大深度 min_samples_split表示构建决策树分裂节点时,如果到达该节点的样本数小于该值则不再分裂 impurity_t表示计算混杂度(不纯度)的计算方式,例如entropy或gini ''' self.classes = classes self.features = features self.max_depth = max_depth self.min_samples_split = min_samples_split self.impurity_t = impurity_t self.root = None # 定义根节点,未训练时为空 def impurity(self, data): ''' 计算某个特征下的信息增益 :param data: ,numpy一维数组 :return: 混杂度 ''' cnt = Counter(data) # 计数每个值出现的次数 probability_lst = [1.0 * cnt[i] / len(data) for i in cnt] if self.impurity_t == 'entropy': # 如果是信息熵 return -np.sum([p * np.log2(p) for p in probability_lst if p > 0]), cnt # 返回熵 和可能用到的数据次数(方便以后使用) return 1 - np.sum([p * p for p in probability_lst]), cnt # 否则返回gini系数 def gain(self, feature, label): ''' 计算某个特征下的信息增益 :param feature: 特征的值,numpy一维数组 :param label: 对应的标签,numpy一维数组 :return: 信息增益 ''' c_impurity, _ = self.impurity(label) # 不考虑特征时标签的混杂度 # 记录特征的每种取值所对应的数组下标 f_index = {} for idx, v in enumerate(feature): if v not in f_index: f_index[v] = [] f_index[v].append(idx) # 计算根据该特征分裂后的不纯度,根据特征的每种值的数目加权和 f_impurity = 0 for v in f_index: # 根据该特征取值对应的数组下标 取出对应的标签列表 比如分支1有多少个正负例 分支2有... f_l = label[f_index[v]] f_impurity += self.impurity(f_l)[0] * len(f_l) / len(label) # 循环结束得到各分支混杂度的期望 gain = c_impurity - f_impurity # 得到gain # 有些特征取值很多,天然不纯度高、信息增益高,模型会偏向于取值很多的特征比如日期,但很可能过拟合 # 计算信息增益率可以缓解该问题 splitInformation = self.impurity(feature)[0] # 计算该特征在标签无关时的不纯度 gainRatio = gain / splitInformation if splitInformation > 0 else gain # 除数不为0时为信息增益率 return gainRatio, f_index # 返回信息增益率,以及每个特征取值的数组下标(方便以后使用) def expand_node(self, feature, label, depth, skip_features=set()): ''' 递归函数分裂节点 :param feature:二维numpy(n*m)数组,每行表示一个样本,n行,有m个特征 :param label:一维numpy(n)数组,表示每个样本的分类标签 :param depth:当前节点的深度 :param skip_features:表示当前路径已经用到的特征 在当前ID3算法离散特征的实现下,一条路径上已经用过的特征不会再用(其他实现有可能会选重复特征) ''' l_cnt = Counter(label) # 计数每个类别的样本出现次数 if len(l_cnt) <= 1: # 如果只有一种类别了,无需分裂,已经是叶节点 return label[0] # 只需记录类别 if len(label) < self.min_samples_split or depth > self.max_depth: # 如果达到了最小分裂的样本数或者最大深度的阈值 return l_cnt.most_common(1)[0][0] # 则只记录当前样本中最多的类别 f_idx, max_gain, f_v_index = -1, -1, None # 准备挑选分裂特征 for idx in range(len(self.features)): # 遍历所有特征 if idx in skip_features: # 如果当前路径已经用到,不用再算 continue f_gain, fv = self.gain(feature[:, idx], label) # 计算特征的信息增益,fv是特征每个取值的样本下标 # if f_gain <= 0: # 如果信息增益不为正,跳过该特征 # continue if f_idx < 0 or f_gain > max_gain: # 如果个更好的分裂特征 f_idx, max_gain, f_v_index = idx, f_gain, fv # 则记录该特征 # if f_idx < 0: # 如果没有找到合适的特征,即所有特征都没有信息增益 # return l_cnt.most_common(1)[0][0] # 则只记录当前样本中最多的类别 decision = {} # 用字典记录每个特征取值所对应的子节点,key是特征取值,value是子节点 skip_features = set([f_idx] + [f for f in skip_features]) # 子节点要跳过的特征包括当前选择的特征 for v in f_v_index: # 遍历特征的每种取值 decision[v] = self.expand_node(feature[f_v_index[v], :], label[f_v_index[v]], # 取出该特征取值所对应的样本 depth=depth + 1, skip_features=skip_features) # 深度+1,递归调用节点分裂 # 返回一个元组,有三个元素 # 第一个是选择的特征下标,第二个特征取值和对应的子节点(字典),第三个是到达当前节点的样本中最多的类别 return (f_idx, decision, l_cnt.most_common(1)[0][0]) def traverse_node(self, node, feature): ''' 预测样本时从根节点开始遍历节点,根据特征路由。 :param node: 当前到达的节点,例如self.root :param feature: 长度为m的numpy一维数组 ''' assert len(self.features) == len(feature) # 要求输入样本特征数和模型定义时特征数目一致 if type(node) is not tuple: # 如果到达了一个节点是叶节点(不再分裂),则返回该节点类别 return node fv = feature[node[0]] # 否则取出该节点对应的特征值,node[0]记录了特征的下标 if fv in node[1]: # 根据特征值找到子节点,注意需要判断训练节点分裂时到达该节点的样本是否有该特征值(分支) return self.traverse_node(node[1][fv], feature) # 如果有,则进入到子节点继续遍历 return node[-1] # 如果没有,返回训练时到达当前节点的样本中最多的类别 def fit(self, feature, label): ''' 训练模型 :param feature:feature为二维numpy(n*m)数组,每行表示一个样本,有m个特征 :param label:label为一维numpy(n)数组,表示每个样本的分类标签 ''' assert len(self.features) == len(feature[0]) # 输入数据的特征数目应该和模型定义时的特征数目相同 self.root = self.expand_node(feature, label, depth=1) # 从根节点开始分裂,模型记录根节点 def predict(self, feature): ''' 预测 :param feature:输入feature可以是一个一维numpy数组也可以是一个二维numpy数组 如果是一维numpy(m)数组则是一个样本,包含m个特征,返回一个类别值 如果是二维numpy(n*m)数组则表示n个样本,每个样本包含m个特征,返回一个numpy一维数组 ''' assert len(feature.shape) == 1 or len(feature.shape) == 2 # 只能是1维或2维 if len(feature.shape) == 1: # 如果是一个样本 return self.traverse_node(self.root, feature) # 从根节点开始路由 return np.array([self.traverse_node(self.root, f) for f in feature]) # 如果是很多个样本 def get_params(self, deep): # 要调用sklearn的cross_validate需要实现该函数返回所有参数 return {'classes': self.classes, 'features': self.features, 'max_depth': self.max_depth, 'min_samples_split': self.min_samples_split, 'impurity_t': self.impurity_t} def set_params(self, **parameters): # 要调用sklearn的GridSearchCV需要实现该函数给类设定所有参数 for parameter, value in parameters.items(): setattr(self, parameter, value) return self # 定义决策树模型,传入算法参数DT = DecisionTree(classes=[0, 1], features=feature_names, max_depth=5, min_samples_split=10, impurity_t='gini') DT.fit(x_train, y_train) # 在训练集上训练p_test = DT.predict(x_test) # 在测试集上预测,获得预测值print(p_test) # 输出预测值test_acc = accuracy_score(p_test, y_test) # 将测试预测值与测试集标签对比获得准确率print('accuracy: {:.4f}'.format(test_acc)) # 输出准确率
三、sklearn里的决策树
来源官网: 1.10. 决策树 - sklearn (scikitlearn.com.cn)
3.1 介绍
ID3(Iterative Dichotomiser 3)由 Ross Quinlan 在1986年提出。该算法创建一个多路树,找到每个节点(即以贪心的方式)分类特征,这将产生分类目标的最大信息增益。决策树发展到其最大尺寸,然后通常利用剪枝来提高树对未知数据的泛华能力。
C4.5 是 ID3 的后继者,并且通过动态定义将连续属性值分割成一组离散间隔的离散属性(基于数字变量),消除了特征必须被明确分类的限制。C4.5 将训练的树(即,ID3算法的输出)转换成 if-then 规则的集合。然后评估每个规则的这些准确性,以确定应用它们的顺序。如果规则的准确性没有改变,则需要决策树的树枝来解决。
C5.0 是 Quinlan 根据专有许可证发布的最新版本。它使用更少的内存,并建立比 C4.5 更小的规则集,同时更准确。
CART(Classification and Regression Trees (分类和回归树))与 C4.5 非常相似,但它不同之处在于它支持数值目标变量(回归),并且不计算规则集。CART 使用在每个节点产生最大信息增益的特征和阈值来构造二叉树。
scikit-learn 使用 CART 算法的优化版本。
Decision Trees (DTs) 是一种用来 classification 和 regression 的无参监督学习方法。其目的是创建一种模型从数据特征中学习简单的决策规则来预测一个目标变量的值。
决策树的优势:
便于理解和解释。树的结构可以可视化出来。
需要的训练数据少。其他机器学习模型通常需要数据规范化,比如构建虚拟变量和移除缺失值,不过请注意,这种模型不支持缺失值。
由于训练决策树的数据点的数量导致了决策树的使用开销呈指数分布(训练树模型的时间复杂度是参与训练数据点的对数值)。能够处理数值型数据和分类数据。其他的技术通常只能用来专门分析某一种变量类型的数据集。详情请参阅算法。能够处理多路输出的问题。使用白盒模型。如果某种给定的情况在该模型中是可以观察的,那么就可以轻易的通过布尔逻辑来解释这种情况。相比之下,在黑盒模型中的结果就是很难说明清 楚地。可以通过数值统计测试来验证该模型。这对事解释验证该模型的可靠性成为可能。即使该模型假设的结果与真实模型所提供的数据有些违反,其表现依旧良好。决策树的缺点包括:
决策树模型容易产生一个过于复杂的模型,这样的模型对数据的泛化性能会很差。这就是所谓的过拟合.一些策略像剪枝、设置叶节点所需的最小样本数或设置数的最大深度是避免出现该问题最为有效地方法。决策树可能是不稳定的,因为数据中的微小变化可能会导致完全不同的树生成。这个问题可以通过决策树的集成来得到缓解。注意是可能,比如刚好到中间的判断值,本身还是具有鲁棒性的。在多方面性能最优和简单化概念的要求下,学习一棵最优决策树通常是一个NP难问题。因此,实际的决策树学习算法是基于启发式算法,例如在每个节点进 行局部最优决策的贪心算法。这样的算法不能保证返回全局最优决策树。这个问题可以通过集成学习来训练多棵决策树来缓解,这多棵决策树一般通过对特征和样本有放回的随机采样来生成。有些概念很难被决策树学习到,因为决策树很难清楚的表述这些概念。例如XOR,奇偶或者复用器的问题。如果某些类在问题中占主导地位会使得创建的决策树有偏差。因此,我们建议在拟合前先对数据集进行平衡。
3.2 分类 DecisionTreeClassifier()
既能用于多分类也能用于二分类
简单形式:
from sklearn import tree# 创建分类决策树clf = tree.DecisionTreeClassifier()# 训练测试集clf.fit(x_train, y_train)# 对x_test进行预测 返回预测结果p_test = clf.predict(x_test)比如以红酒数据为例:
from sklearn import treefrom sklearn.datasets import load_winewine = load_wine()X_wine = wine.datay_wine = wine.targetx_train, x_test, y_train, y_test = train_test_split(X_wine,y_wine)x_train.shape, x_test.shape, y_train.shape, y_test.shapeclf = tree.DecisionTreeClassifier()clf.fit(x_train, y_train)p_test = clf.predict(x_test)p_test其实,该类是继承于 ClassifierMixin, BaseDecisionTree 这两个父类的,其参数如下:
def __init__(
self,
*,
criterion="gini", # 混杂度 可选:{“gini”, “entropy”, “log_loss”}
splitter="best", # 每个节点上选择拆分的策略 {“best”, “random”}
max_depth=None, # 树的最大深度。如果为 None,则扩展节点,直到所有叶子都是纯的,或者直到所有叶子包含少于 min_samples_split 个样本。
min_samples_split=2, # 拆分内部节点所需的最小样本数
min_samples_leaf=1, # 叶节点所需的最小样本数。仅当任何深度的分割点至少在左右分支中留下训练样本时,才会考虑拆分点。这可能会对模型进行平滑处理,尤其是在回归中。
min_weight_fraction_leaf=0.0, # 叶节点上所需的权重总和(所有输入样本)的最小加权分数。未提供sample_weight时,样品具有相同的权重。
max_features=None, # int、float 或 {“auto”、“sqrt”、“log2”},default=None寻找最佳拆分时要考虑的功能数量
random_state=None, # 控制估计器的随机性。
max_leaf_nodes=None, # 以最好的第一种方式种植一棵树。最佳节点定义为杂质的相对减少。如果为“无”,则叶节点数不受限制。
min_impurity_decrease=0.0, # 如果节点的拆分导致杂质减少大于或等于此值,则节点将被拆分。
class_weight=None, # 与窗体中的类关联的权重
ccp_alpha=0.0, # 用于最小成本-复杂性修剪的复杂性参数。成本复杂度最大且小于所选的子树。默认情况下,不执行修剪。
)
参数这部分或是这个类的整体想详细了解的话建议还是去看看官方文档:sklearn.tree.DecisionTreeClassifier
上面虽然参数很多也各有各的用法,但其实一般我们也不全都用到。
我们可以通过K折交叉验证完成参数的选取
import numpy as npfrom sklearn import treefrom sklearn.datasets import load_winefrom sklearn.model_selection import train_test_split,GridSearchCV,cross_validatefrom sklearn.metrics import accuracy_scorewine = load_wine()X_wine = wine.datay_wine = wine.targetx_train, x_test, y_train, y_test = train_test_split(X_wine,y_wine)best = None # 记录最佳结果for impurity_t in ['entropy', 'gini']: # 遍历不纯度的计算方式 for max_depth in range(1, 6): # 遍历最大树深度 for min_samples_split in [2,5,10,20]: # 遍历节点分裂最小样本数的阈值 DT = tree.DecisionTreeClassifier(max_depth=max_depth, min_samples_split=min_samples_split, criterion=impurity_t) cv_result = cross_validate(DT, x_train, y_train, scoring=('accuracy'), cv=5) # 5折交叉验证 cv_acc = np.mean(cv_result['test_score']) # 5折平均准确率 current = (cv_acc, max_depth, min_samples_split, impurity_t) # 记录参数和结果 if best is None or cv_acc > best[0]: # 如果是比当前最佳更好的结果 best = current # 记录最好结果 print('better cv_accuracy: {:.4f}, max_depth={}, min_samples_split={}, impurity_t={}'.format(*best)) # 输出准确率和参数 else: print('cv_accuracy: {:.4f}, max_depth={}, min_samples_split={}, impurity_t={}'.format(*current)) # 输出准确率和参数 DT = tree.DecisionTreeClassifier(max_depth=best[1], min_samples_split=best[2], criterion=best[3]) # 取最佳参数DT.fit(x_train, y_train) # 在训练集上训练p_test = DT.predict(x_test) # 在测试集上预测,获得预测值print(p_test) # 输出预测值test_acc = accuracy_score(p_test, y_test) # 将测试预测值与测试集标签对比获得准确率print('accuracy: {:.4f}'.format(test_acc)) # 输出准确率也可以使用自带的多线程GridSearchCV,原理同上,更快一些。
import numpy as npfrom sklearn import treefrom sklearn.datasets import load_winefrom sklearn.model_selection import train_test_split,GridSearchCV,cross_validatefrom sklearn.metrics import accuracy_scorewine = load_wine()X_wine = wine.datay_wine = wine.targetx_train, x_test, y_train, y_test = train_test_split(X_wine,y_wine)parameters = {'criterion':['entropy', 'gini'], 'max_depth': range(1, 6), 'min_samples_split': [2,5,10,20]} # 定义需要遍历的参数DT = tree.DecisionTreeClassifier()grid_search = GridSearchCV(DT, parameters, scoring='accuracy', cv=5, verbose=100, n_jobs=4) # 传入模型和要遍历的参数grid_search.fit(x_train, y_train) # 在所有数据上搜索参数print(grid_search.best_score_, grid_search.best_params_) # 输出最佳指标和最佳参数DT = tree.DecisionTreeClassifier(**grid_search.best_params_) # 取最佳参数DT.fit(x_train, y_train) # 在训练集上训练p_test = DT.predict(x_test) # 在测试集上预测,获得预测值print(p_test) # 输出预测值test_acc = accuracy_score(p_test, y_test) # 将测试预测值与测试集标签对比获得准确率print('accuracy: {:.4f}'.format(test_acc)) # 输出准确率
3.3 回归 DecisionTreeRegressor()
在下面的图片中,决策树通过if-then-else的决策规则来学习数据从而估测数一个正弦图像。决策树越深入,决策规则就越复杂并且对数据的拟合越好。
import numpy as npfrom sklearn.tree import DecisionTreeRegressorimport matplotlib.pyplot as plt# Create a random datasetrng = np.random.RandomState(1)X = np.sort(5 * rng.rand(80, 1), axis=0)y = np.sin(X).ravel()y[::5] += 3 * (0.5 - rng.rand(16))# Fit regression modelregr_1 = DecisionTreeRegressor(max_depth=2)regr_2 = DecisionTreeRegressor(max_depth=5)regr_1.fit(X, y)regr_2.fit(X, y)# PredictX_test = np.arange(0.0, 5.0, 0.01)[:, np.newaxis]y_1 = regr_1.predict(X_test)y_2 = regr_2.predict(X_test)# Plot the resultsplt.figure()plt.scatter(X, y, s=20, edgecolor="black", c="darkorange", label="data")plt.plot(X_test, y_1, color="cornflowerblue", label="max_depth=2", linewidth=2)plt.plot(X_test, y_2, color="yellowgreen", label="max_depth=5", linewidth=2)plt.xlabel("data")plt.ylabel("target")plt.title("Decision Tree Regression")plt.legend()plt.show()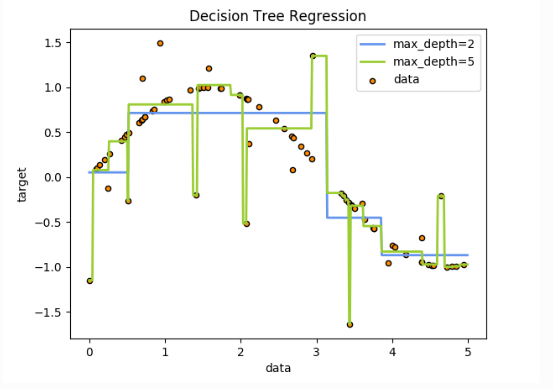
使用决策树说明多输出回归的示例。
决策树用于在给定单个基础特征的情况下同时预测圆的噪声 x 和 y 观测值。结果,它学习近似圆的局部线性回归。
我们可以看到,如果树的最大深度(由参数控制)设置得太高,决策树就会学习训练数据的细节,并从噪声中学习,即它们过拟合。
import numpy as npimport matplotlib.pyplot as pltfrom sklearn.tree import DecisionTreeRegressor# Create a random datasetrng = np.random.RandomState(1)X = np.sort(200 * rng.rand(100, 1) - 100, axis=0)y = np.array([np.pi * np.sin(X).ravel(), np.pi * np.cos(X).ravel()]).Ty[::5, :] += 0.5 - rng.rand(20, 2)# Fit regression modelregr_1 = DecisionTreeRegressor(max_depth=2)regr_2 = DecisionTreeRegressor(max_depth=5)regr_3 = DecisionTreeRegressor(max_depth=8)regr_1.fit(X, y)regr_2.fit(X, y)regr_3.fit(X, y)# PredictX_test = np.arange(-100.0, 100.0, 0.01)[:, np.newaxis]y_1 = regr_1.predict(X_test)y_2 = regr_2.predict(X_test)y_3 = regr_3.predict(X_test)# Plot the resultsplt.figure()s = 25plt.scatter(y[:, 0], y[:, 1], c="navy", s=s, edgecolor="black", label="data")plt.scatter( y_1[:, 0], y_1[:, 1], c="cornflowerblue", s=s, edgecolor="black", label="max_depth=2",)plt.scatter(y_2[:, 0], y_2[:, 1], c="red", s=s, edgecolor="black", label="max_depth=5")plt.scatter( y_3[:, 0], y_3[:, 1], c="orange", s=s, edgecolor="black", label="max_depth=8")plt.xlim([-6, 6])plt.ylim([-6, 6])plt.xlabel("target 1")plt.ylabel("target 2")plt.title("Multi-output Decision Tree Regression")plt.legend(loc="best")plt.show()
3.4 复杂度分析

3.5 使用技巧
对于拥有大量特征的数据决策树会出现过拟合的现象。获得一个合适的样本比例和特征数量十分重要,因为在高维空间中只有少量的样本的树是十分容易过拟合的。考虑事先进行降维( PCA , ICA ),使您的树更好地找到具有分辨性的特征。通过export 功能可以可视化您的决策树。使用 max_depth=3 作为初始树深度,让决策树知道如何适应您的数据,然后再增加树的深度。请记住,填充树的样本数量会增加树的每个附加级别。使用 max_depth 来控制输的大小防止过拟合。通过使用 min_samples_split 和 min_samples_leaf 来控制叶节点上的样本数量。当这个值很小时意味着生成的决策树将会过拟合,然而当这个值很大时将会不利于决策树的对样本的学习。所以尝试 min_samples_leaf=5 作为初始值。如果样本的变化量很大,可以使用浮点数作为这两个参数中的百分比。两者之间的主要区别在于 min_samples_leaf 保证叶结点中最少的采样数,而 min_samples_split 可以创建任意小的叶子,尽管在文献中 min_samples_split 更常见。在训练之前平衡您的数据集,以防止决策树偏向于主导类.可以通过从每个类中抽取相等数量的样本来进行类平衡,或者优选地通过将每个类的样本权重 (sample_weight) 的和归一化为相同的值。还要注意的是,基于权重的预修剪标准 (min_weight_fraction_leaf) 对于显性类别的偏倚偏小,而不是不了解样本权重的标准,如 min_samples_leaf 。如果样本被加权,则使用基于权重的预修剪标准 min_weight_fraction_leaf 来优化树结构将更容易,这确保叶节点包含样本权重的总和的至少一部分。所有的决策树内部使用 np.float32 数组 ,如果训练数据不是这种格式,将会复制数据集。如果输入的矩阵X为稀疏矩阵,建议您在调用fit之前将矩阵X转换为稀疏的csc_matrix ,在调用predict之前将 csr_matrix 稀疏。当特征在大多数样本中具有零值时,与密集矩阵相比,稀疏矩阵输入的训练时间可以快几个数量级。
四、决策树可视化
方法1: plot_tree
from sklearn import treefrom sklearn.datasets import load_irisiris = load_iris()clf = tree.DecisionTreeClassifier()clf = clf.fit(iris.data, iris.target)import matplotlib.pyplot as pltdef tree_vi(clf): fig = plt.figure(figsize=(30, 10)) tree.plot_tree(clf, fontsize=8) # fig.savefig(os.path.join(fig_dir, "tree.png")) tree_vi(clf)
当然如果设置参数改变树的形状,上面的图也会变。
方法2:graphviz
生成如下图片:

下载安装方法请见连接:决策树可视化-graphviz安装_老师我作业忘带了的博客-CSDN博客