目录
0. 添加方法1. SE1.1 SE1.2 C3-SE 2. CBAM2.1 CBAM2.2 C3-CBAM 3. ECA3.1 ECA3.2 C3-ECA 4. CA4.1 CA4.2 C3-CA
0. 添加方法
主要步骤:
(1)在models/common.py中注册注意力模块
(2)在models/yolo.py中的parse_model函数中添加注意力模块
(3)修改配置文件yolov5s.yaml
(4)运行yolo.py进行验证
各个注意力机制模块的添加方法类似,各注意力模块的修改参照SE。
本文添加注意力完整代码:https://github.com/double-vin/yolov5_attention
1. SE
Squeeze-and-Excitation Networks
https://github.com/hujie-frank/SENet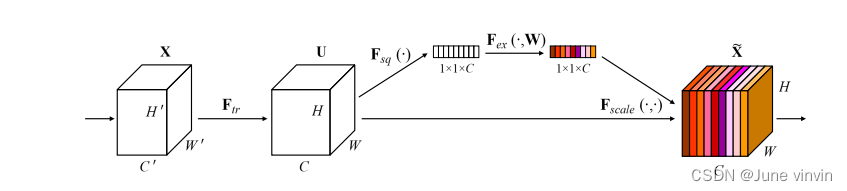
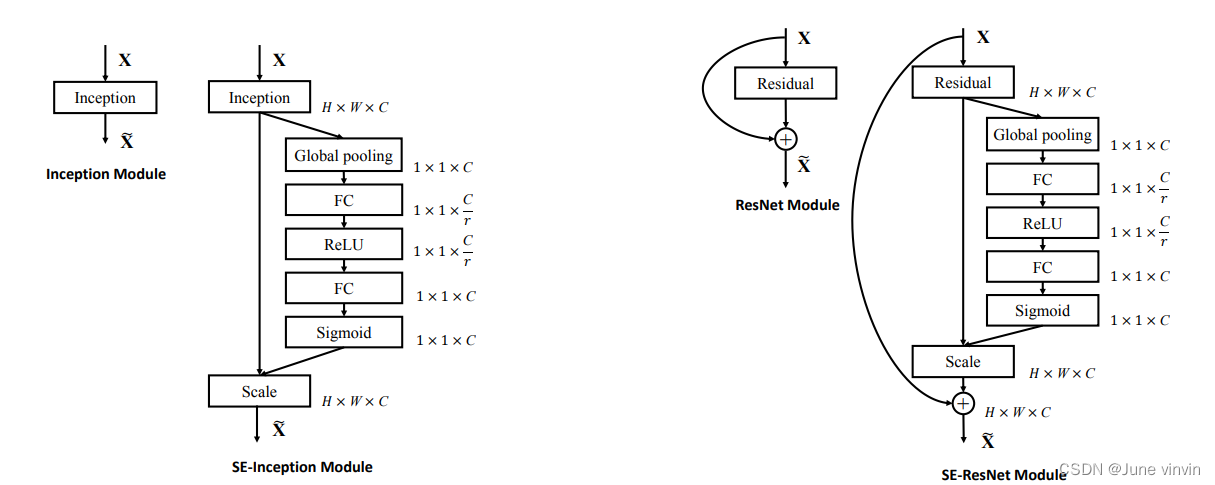
1.1 SE
在models/common.py中注册SE模块 class SE(nn.Module): def __init__(self, c1, c2, ratio=16): super(SE, self).__init__() #c*1*1 self.avgpool = nn.AdaptiveAvgPool2d(1) self.l1 = nn.Linear(c1, c1 // ratio, bias=False) self.relu = nn.ReLU(inplace=True) self.l2 = nn.Linear(c1 // ratio, c1, bias=False) self.sig = nn.Sigmoid() def forward(self, x): b, c, _, _ = x.size() y = self.avgpool(x).view(b, c) y = self.l1(y) y = self.relu(y) y = self.l2(y) y = self.sig(y) y = y.view(b, c, 1, 1) return x * y.expand_as(x)models/yolo.py中的parse_model函数中添加SE模块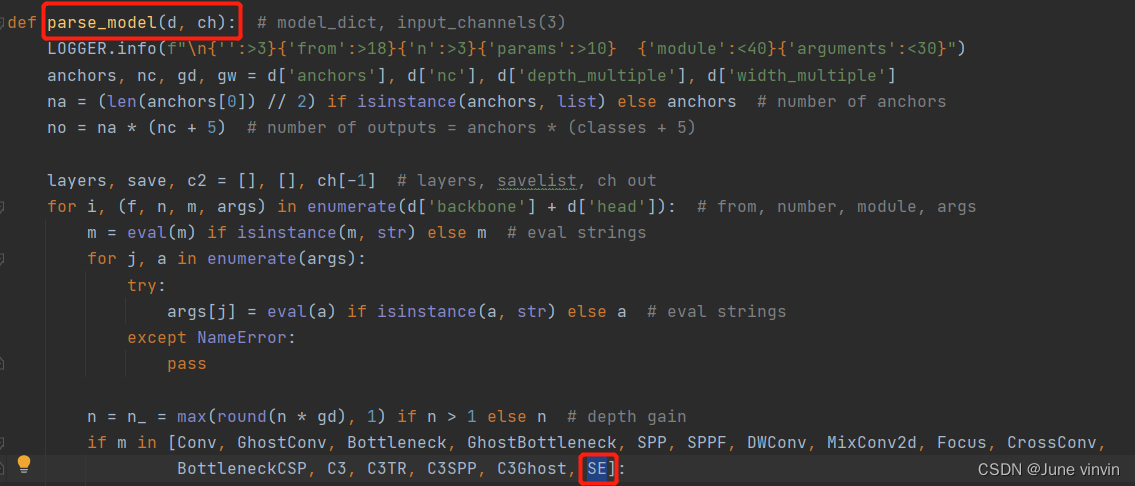 修改配置文件
修改配置文件yolov5s.yaml。添加注意力的两种方法:一是在backbone的最后一层添加注意力;二是将backbone中的C3全部替换。
这里使用第一种,第二种见下文中的
C3SE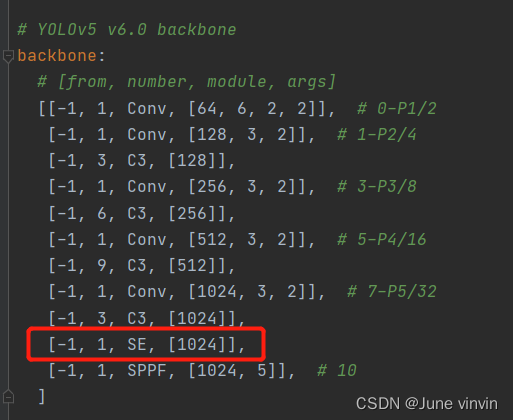
注意:SE添加至第9层,第9层之后所有的编号都要+1,则:
1>
两个Concat的from系数分别由[-1, 14],[-1, 10]改为[-1, 15],[-1, 11]2>
Detect的from系数由[17, 20, 23]改为[18,21,24]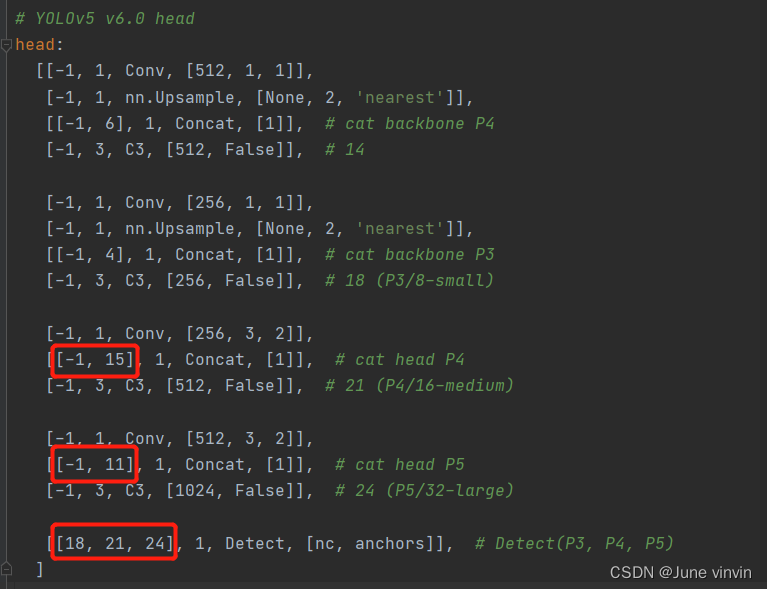 验证:运行
验证:运行yolo.py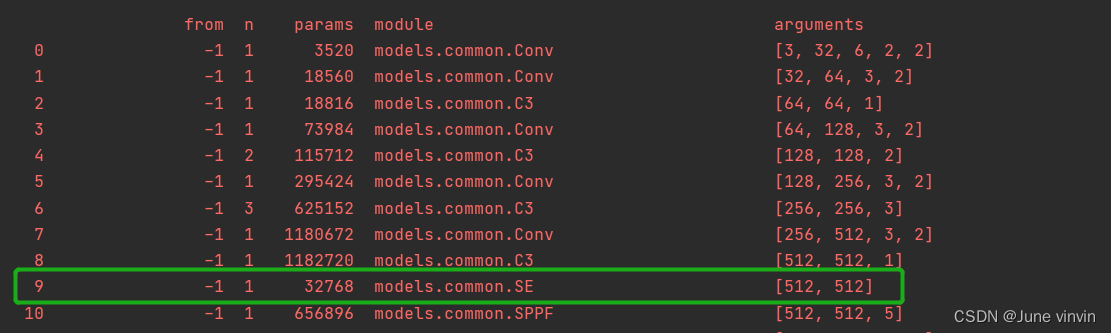
1.2 C3-SE
在models/common.py中注册C3SE模块: class SEBottleneck(nn.Module): # Standard bottleneck def __init__(self, c1, c2, shortcut=True, g=1, e=0.5, ratio=16): # ch_in, ch_out, shortcut, groups, expansion super().__init__() c_ = int(c2 * e) # hidden channels self.cv1 = Conv(c1, c_, 1, 1) self.cv2 = Conv(c_, c2, 3, 1, g=g) self.add = shortcut and c1 == c2 # self.se=SE(c1,c2,ratio) self.avgpool = nn.AdaptiveAvgPool2d(1) self.l1 = nn.Linear(c1, c1 // ratio, bias=False) self.relu = nn.ReLU(inplace=True) self.l2 = nn.Linear(c1 // ratio, c1, bias=False) self.sig = nn.Sigmoid() def forward(self, x): x1 = self.cv2(self.cv1(x)) b, c, _, _ = x.size() y = self.avgpool(x1).view(b, c) y = self.l1(y) y = self.relu(y) y = self.l2(y) y = self.sig(y) y = y.view(b, c, 1, 1) out = x1 * y.expand_as(x1) # out=self.se(x1)*x1 return x + out if self.add else outclass C3SE(C3): # C3 module with SEBottleneck() def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): super().__init__(c1, c2, n, shortcut, g, e) c_ = int(c2 * e) # hidden channels self.m = nn.Sequential(*(SEBottleneck(c_, c_, shortcut) for _ in range(n)))models/yolo.py中的parse_model函数中添加C3SE模块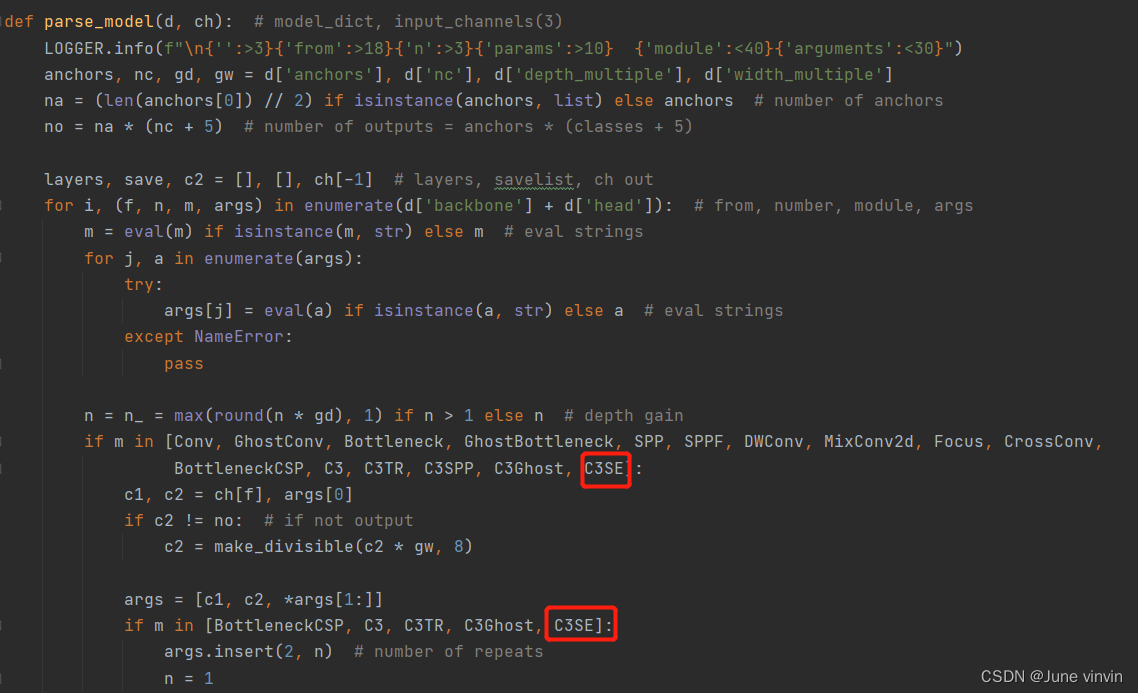 修改配置文件
修改配置文件yolov5s.yaml。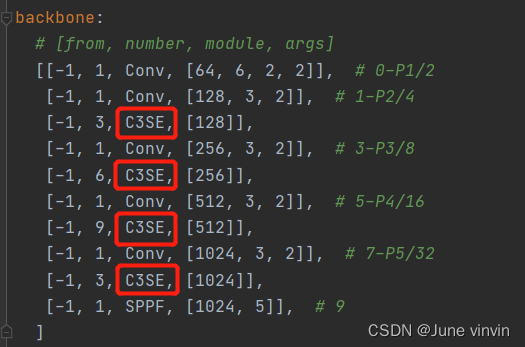 验证:运行
验证:运行yolo.py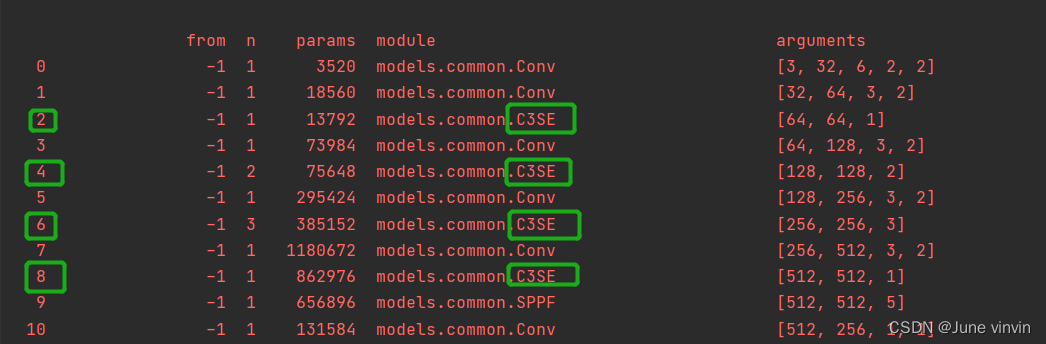
2. CBAM
《CBAM: Convolutional Block Attention Module》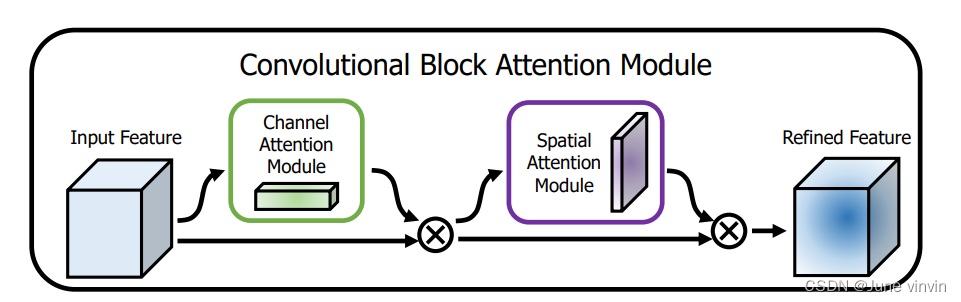
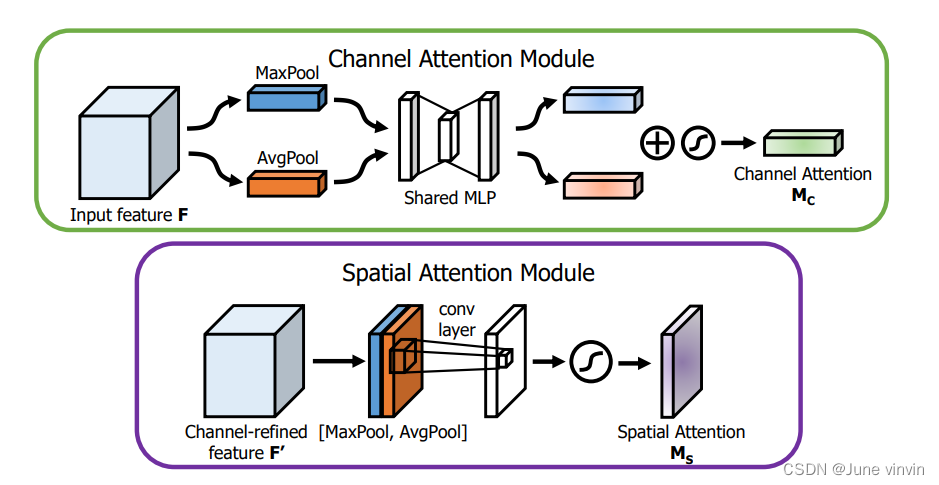
2.1 CBAM
class ChannelAttention(nn.Module): def __init__(self, in_planes, ratio=16): super(ChannelAttention, self).__init__() self.avg_pool = nn.AdaptiveAvgPool2d(1) self.max_pool = nn.AdaptiveMaxPool2d(1) self.f1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False) self.relu = nn.ReLU() self.f2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False) self.sigmoid = nn.Sigmoid() def forward(self, x): avg_out = self.f2(self.relu(self.f1(self.avg_pool(x)))) max_out = self.f2(self.relu(self.f1(self.max_pool(x)))) out = self.sigmoid(avg_out + max_out) return outclass SpatialAttention(nn.Module): def __init__(self, kernel_size=7): super(SpatialAttention, self).__init__() assert kernel_size in (3, 7), 'kernel size must be 3 or 7' padding = 3 if kernel_size == 7 else 1 # (特征图的大小-算子的size+2*padding)/步长+1 self.conv = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False) self.sigmoid = nn.Sigmoid() def forward(self, x): # 1*h*w avg_out = torch.mean(x, dim=1, keepdim=True) max_out, _ = torch.max(x, dim=1, keepdim=True) x = torch.cat([avg_out, max_out], dim=1) #2*h*w x = self.conv(x) #1*h*w return self.sigmoid(x)class CBAM(nn.Module): # CSP Bottleneck with 3 convolutions def __init__(self, c1, c2, ratio=16, kernel_size=7): # ch_in, ch_out, number, shortcut, groups, expansion super(CBAM, self).__init__() self.channel_attention = ChannelAttention(c1, ratio) self.spatial_attention = SpatialAttention(kernel_size) def forward(self, x): out = self.channel_attention(x) * x # c*h*w # c*h*w * 1*h*w out = self.spatial_attention(out) * out return out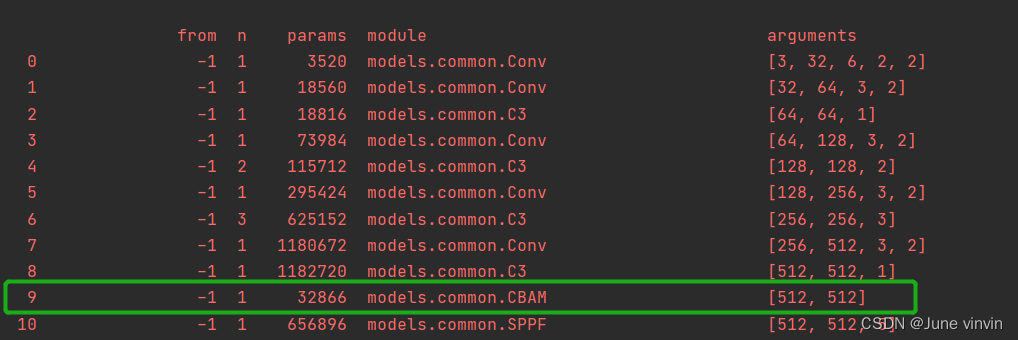
2.2 C3-CBAM
class CBAMBottleneck(nn.Module): # Standard bottleneck def __init__(self, c1, c2, shortcut=True, g=1, e=0.5,ratio=16,kernel_size=7): # ch_in, ch_out, shortcut, groups, expansion super(CBAMBottleneck,self).__init__() c_ = int(c2 * e) # hidden channels self.cv1 = Conv(c1, c_, 1, 1) self.cv2 = Conv(c_, c2, 3, 1, g=g) self.add = shortcut and c1 == c2 self.channel_attention = ChannelAttention(c2, ratio) self.spatial_attention = SpatialAttention(kernel_size) #self.cbam=CBAM(c1,c2,ratio,kernel_size) def forward(self, x): x1 = self.cv2(self.cv1(x)) out = self.channel_attention(x1) * x1 # print('outchannels:{}'.format(out.shape)) out = self.spatial_attention(out) * out return x + out if self.add else outclass C3CBAM(C3): # C3 module with CBAMBottleneck() def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): super().__init__(c1, c2, n, shortcut, g, e) c_ = int(c2 * e) # hidden channels self.m = nn.Sequential(*(CBAMBottleneck(c_, c_, shortcut) for _ in range(n)))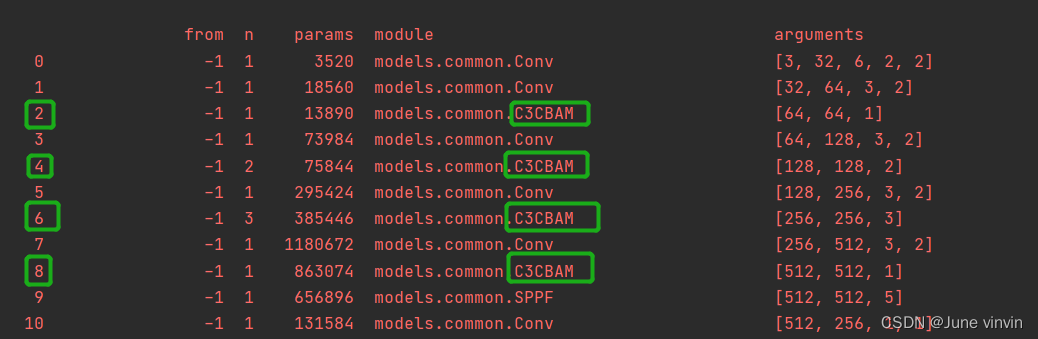
3. ECA
《ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks》
https://github.com/BangguWu/ECANet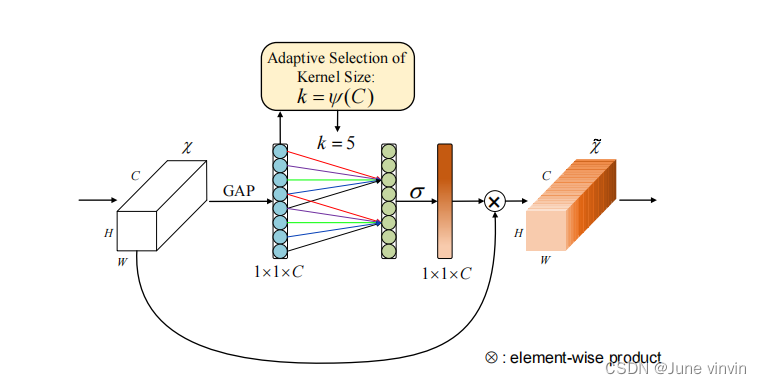
3.1 ECA
class ECA(nn.Module): """Constructs a ECA module. Args: channel: Number of channels of the input feature map k_size: Adaptive selection of kernel size """ def __init__(self, c1, c2, k_size=3): super(ECA, self).__init__() self.avg_pool = nn.AdaptiveAvgPool2d(1) self.conv = nn.Conv1d(1, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False) self.sigmoid = nn.Sigmoid() def forward(self, x): # feature descriptor on the global spatial information y = self.avg_pool(x) # print(y.shape,y.squeeze(-1).shape,y.squeeze(-1).transpose(-1, -2).shape) # Two different branches of ECA module # 50*C*1*1 # 50*C*1 # 50*1*C y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1) # Multi-scale information fusion y = self.sigmoid(y) return x * y.expand_as(x)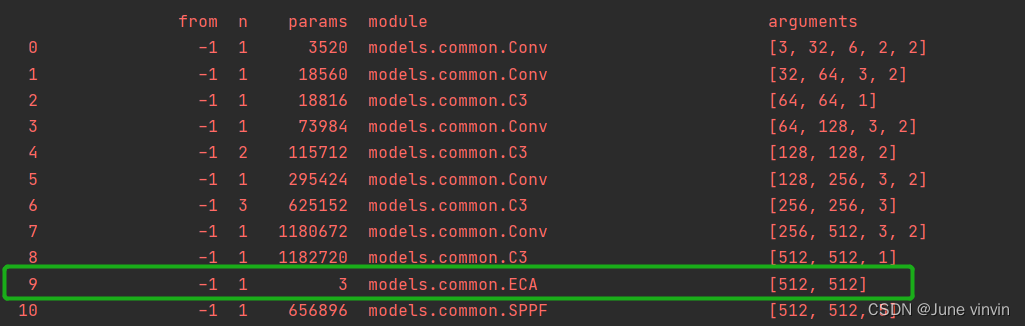
3.2 C3-ECA
class ECABottleneck(nn.Module): # Standard bottleneck def __init__(self, c1, c2, shortcut=True, g=1, e=0.5, ratio=16, k_size=3): # ch_in, ch_out, shortcut, groups, expansion super().__init__() c_ = int(c2 * e) # hidden channels self.cv1 = Conv(c1, c_, 1, 1) self.cv2 = Conv(c_, c2, 3, 1, g=g) self.add = shortcut and c1 == c2 # self.eca=ECA(c1,c2) self.avg_pool = nn.AdaptiveAvgPool2d(1) self.conv = nn.Conv1d(1, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False) self.sigmoid = nn.Sigmoid() def forward(self, x): x1 = self.cv2(self.cv1(x)) # out=self.eca(x1)*x1 y = self.avg_pool(x1) y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1) y = self.sigmoid(y) out = x1 * y.expand_as(x1) return x + out if self.add else outclass C3ECA(C3): # C3 module with ECABottleneck() def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): super().__init__(c1, c2, n, shortcut, g, e) c_ = int(c2 * e) # hidden channels self.m = nn.Sequential(*(ECABottleneck(c_, c_, shortcut) for _ in range(n)))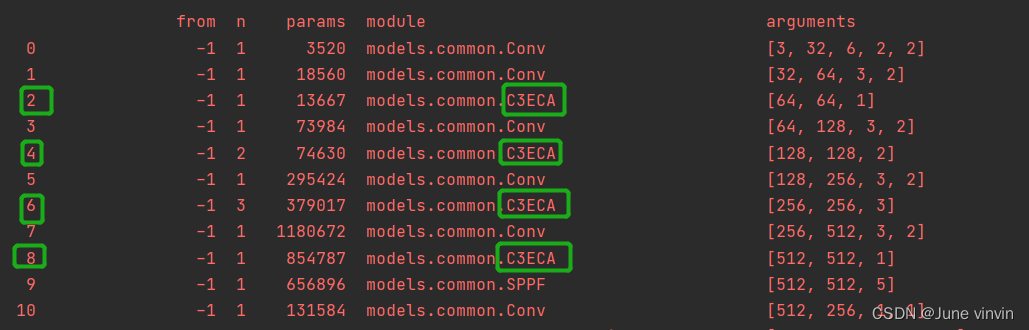
4. CA
Coordinate Attention for Efficient Mobile Network Design
https://github.com/Andrew-Qibin/CoordAttention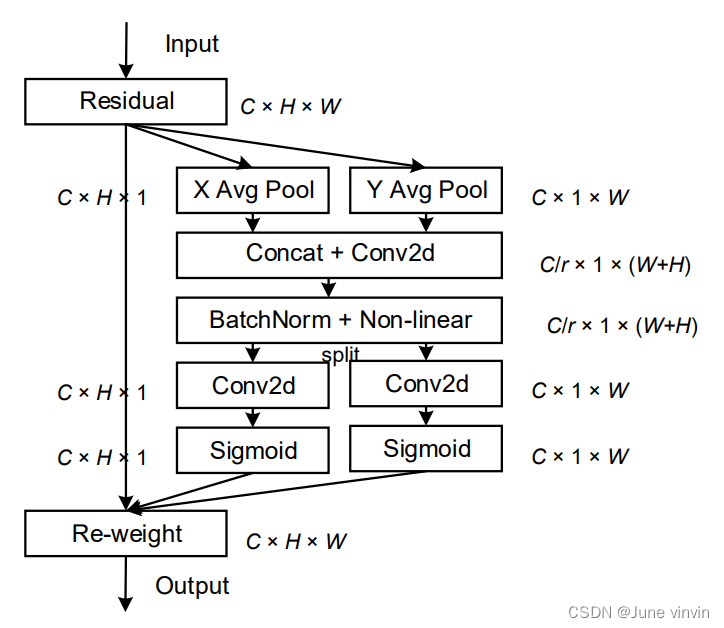
4.1 CA
class h_sigmoid(nn.Module): def __init__(self, inplace=True): super(h_sigmoid, self).__init__() self.relu = nn.ReLU6(inplace=inplace) def forward(self, x): return self.relu(x + 3) / 6class h_swish(nn.Module): def __init__(self, inplace=True): super(h_swish, self).__init__() self.sigmoid = h_sigmoid(inplace=inplace) def forward(self, x): return x * self.sigmoid(x)class CoordAtt(nn.Module): def __init__(self, inp, oup, reduction=32): super(CoordAtt, self).__init__() self.pool_h = nn.AdaptiveAvgPool2d((None, 1)) self.pool_w = nn.AdaptiveAvgPool2d((1, None)) mip = max(8, inp // reduction) self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0) self.bn1 = nn.BatchNorm2d(mip) self.act = h_swish() self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0) self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0) def forward(self, x): identity = x n, c, h, w = x.size() # c*1*W x_h = self.pool_h(x) # c*H*1 # C*1*h x_w = self.pool_w(x).permute(0, 1, 3, 2) y = torch.cat([x_h, x_w], dim=2) # C*1*(h+w) y = self.conv1(y) y = self.bn1(y) y = self.act(y) x_h, x_w = torch.split(y, [h, w], dim=2) x_w = x_w.permute(0, 1, 3, 2) a_h = self.conv_h(x_h).sigmoid() a_w = self.conv_w(x_w).sigmoid() out = identity * a_w * a_h return out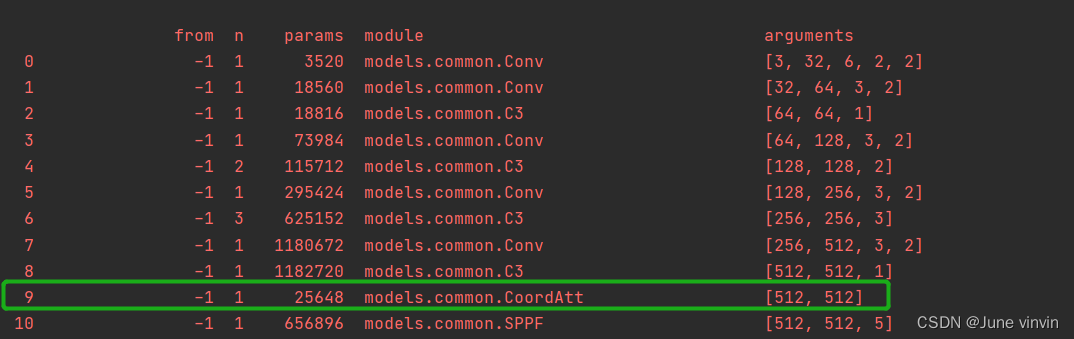
4.2 C3-CA
class CABottleneck(nn.Module): # Standard bottleneck def __init__(self, c1, c2, shortcut=True, g=1, e=0.5, ratio=32): # ch_in, ch_out, shortcut, groups, expansion super().__init__() c_ = int(c2 * e) # hidden channels self.cv1 = Conv(c1, c_, 1, 1) self.cv2 = Conv(c_, c2, 3, 1, g=g) self.add = shortcut and c1 == c2 # self.ca=CoordAtt(c1,c2,ratio) self.pool_h = nn.AdaptiveAvgPool2d((None, 1)) self.pool_w = nn.AdaptiveAvgPool2d((1, None)) mip = max(8, c1 // ratio) self.conv1 = nn.Conv2d(c1, mip, kernel_size=1, stride=1, padding=0) self.bn1 = nn.BatchNorm2d(mip) self.act = h_swish() self.conv_h = nn.Conv2d(mip, c2, kernel_size=1, stride=1, padding=0) self.conv_w = nn.Conv2d(mip, c2, kernel_size=1, stride=1, padding=0) def forward(self, x): x1=self.cv2(self.cv1(x)) n, c, h, w = x.size() # c*1*W x_h = self.pool_h(x1) # c*H*1 # C*1*h x_w = self.pool_w(x1).permute(0, 1, 3, 2) y = torch.cat([x_h, x_w], dim=2) # C*1*(h+w) y = self.conv1(y) y = self.bn1(y) y = self.act(y) x_h, x_w = torch.split(y, [h, w], dim=2) x_w = x_w.permute(0, 1, 3, 2) a_h = self.conv_h(x_h).sigmoid() a_w = self.conv_w(x_w).sigmoid() out = x1 * a_w * a_h # out=self.ca(x1)*x1 return x + out if self.add else outclass C3CA(C3): # C3 module with CABottleneck() def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): super().__init__(c1, c2, n, shortcut, g, e) c_ = int(c2 * e) # hidden channels self.m = nn.Sequential(*(CABottleneck(c_, c_,shortcut) for _ in range(n)))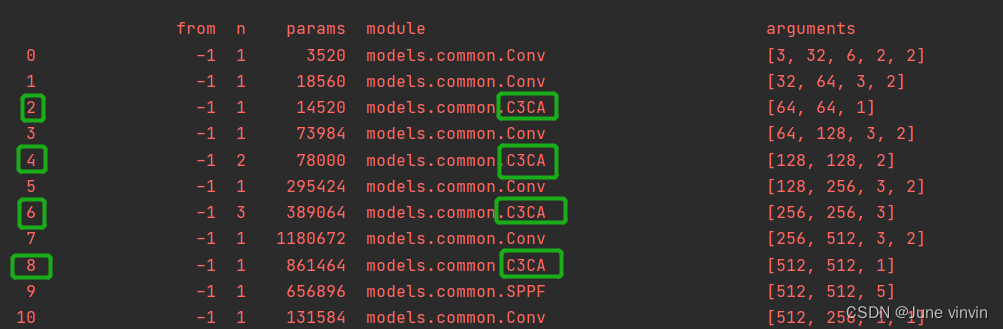
Tips:添加注意力的位置不局限,可以尝试各种排列组合
参考:
多种注意力介绍
添加注意力视频讲解
添加CBAM