jieba是优秀的中文分词第三方库
中文文本需要通过分词获得单个的词语
jieba是优秀的中文分词第三方库,需要额外安装
jieba库提供三种分词模式,最简单只需安装一个函数。
jieba库是通过中文词库的方式来识别分词的。
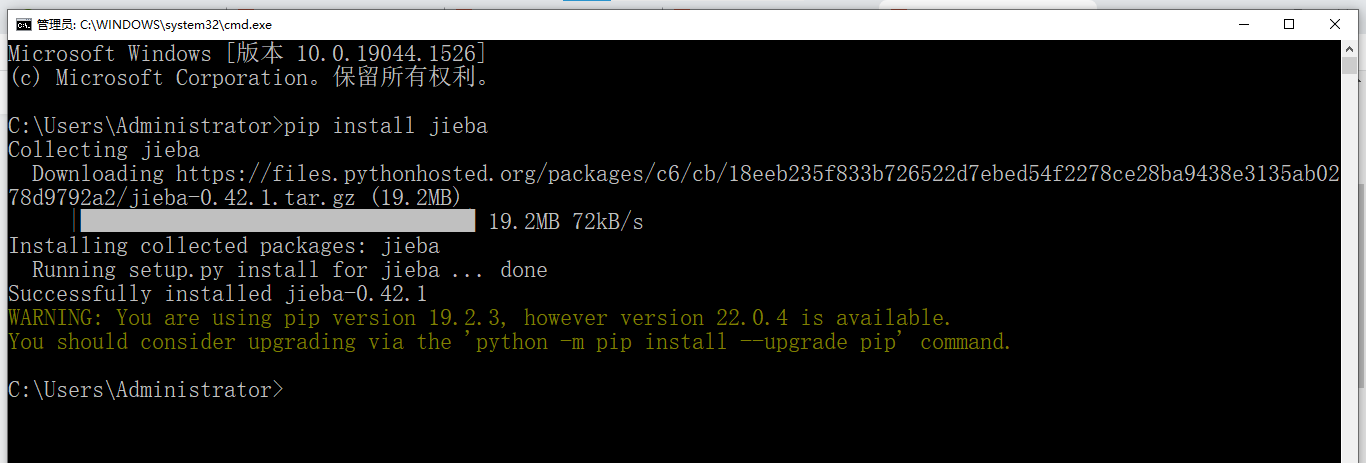
安装命令如下:
点击windows+r,进入命令提示符输入cmd,进入界面后,输入pip install jieba。即可安装,示例如下:
![]()
安装界面如下:
jieba库分词依靠中文词库
利用一个中文词库,确定汉字之间的关联概念
汉字间概率大的组成词组,形成分词结果
除了分词,用户还可以添加自定义的词组。
jieba分词的三种模式:
精确模式、全模式、搜索引擎模式
精确模式:把文本精确的切分开,不存在冗余单词
全模式:把文本中所有可能的词语都扫描出来,有冗余。
搜索引擎模式:在精确模式基础上,对长词进行切分。
jieba库的主要方法如下:
1.jieba.lcut(s) 精确模式,返回一个列表类型的分词结果
代码示例如下:
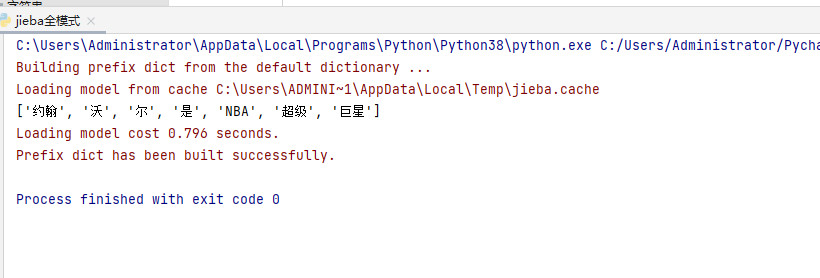
import jiebaa=jieba.lcut("约翰沃尔是NBA超级巨星")print(a) 运行界面如下:

2.jieba.lcut(s,cut_all=True)全模式,返回一个列表类型的分词结果,存在冗余。
代码示例如下:
import jiebaa=jieba.lcut("约翰沃尔是NBA超级巨星",cut_all=True)print(a) 运行界面如下:
3.jieba.lcut_for_search(s)搜索引擎模式。
代码示例如下:
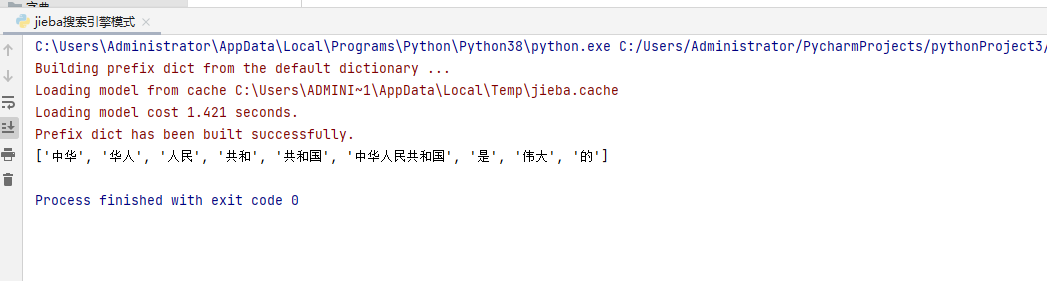
import jiebaa=jieba.lcut_for_search("中华人民共和国是伟大的")print(a) 运行界面如下:4.
4.jieba.add_word(w),向分词词典增加新词w。
代码示例如下:
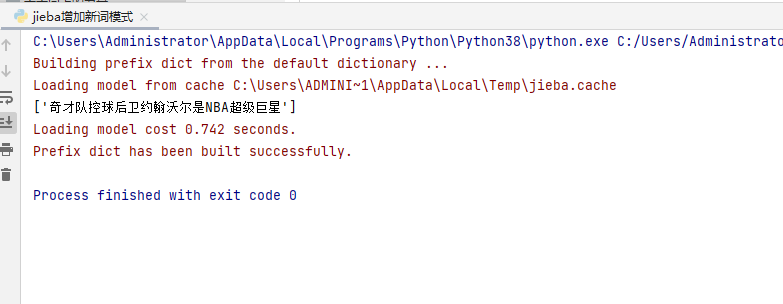
import jiebaa=jieba.add_word("奇才队控球后卫约翰沃尔是NBA超级巨星")b=jieba.lcut("奇才队控球后卫约翰沃尔是NBA超级巨星")print(b) 运行界面如下:
jieba.lcuts(s),能够将字符串s进行精确的分词处理,并且返回一个列表类型。