
前 言
? 作者简介:半旧518,长跑型选手,立志坚持写10年博客,专注于java后端
☕专栏简介:相当硬核,黑皮书《数据库系统概念》读书笔记,讲解:
1.数据库系统的基本概念(数据库设计过程、关系型数据库理论、数据库应用的设计与开发…)
2.大数据分析(大数据存储系统,键值存储,Nosql系统,MapReduce,Apache Spark,流数据和图数据库等…)
3.数据库系统的实现技术(数据存储结构,缓冲区管理,索引结构,查询执行算法,查询优化算法,事务的原子性、一致性、隔离型、持久性等基本概念,并发控制与故障恢复技术…)
4.并行和分布式数据库(集中式、客户-服务器、并行和分布式,基于云系统的计算机体系结构…)
5.更多数据库高级主题(LSM树及其变种、位图索引、空间索引、动态散列等索引结构的拓展,高级应用开发中的性能调整,应用程序移植和标准化,数据库与区块链等…)
? 文章简介:上篇文章我们把数据库的增删改查讲解的透透的了,这篇文章我们将学习具有更复杂形式的SQL查询,视图定义,事务,完整性约束等。
文章目录
1.连接表达式1.1 自然连接1.2 连接条件1.3 外连接 2.视图2.1 视图定义2.2 在SQL查询中使用视图2.3 物化视图2.4 视图更新 3.事务4.完整性约束4.1 非空约束4.2 唯一性约束4.3 check子句4.4 引用完整性4.5 给约束赋名4.6 事务中对完整性约束的违反4.7 复杂check条件与断言 5.SQL的数据类型与模式5.1 SQL中的日期和时间类型5.2 类型转换和格式化函数5.3 缺省值5.4 大对象类型5.5 属性的时态有效性5.6 用户自定义类型5.7 生成唯一码值5.8 create table的扩展5.9 模式、目录与环境 6.SQL中的索引定义7.授权7.1 权限的授予与收回7.2 角色7.3 视图的授权7.4 模式的授权7.5 权限的转移7.6 权限的级联收回7.7 行级授权
1.连接表达式
前一篇文章我们使用笛卡尔积运算符来组合来自多个关系的信息,本文介绍“连接”查询,允许程序员以一种更自然的方式编写一些查询,并表达只用笛卡尔积很难表达的查询。
本节所用的示例设计student和takes两个关系,如下图所示。请注意对于ID为98988的学生,在2018年夏季选修的BIO-301课程的1号课程段的grade属性为空值,该空值表示它尚未得到成绩。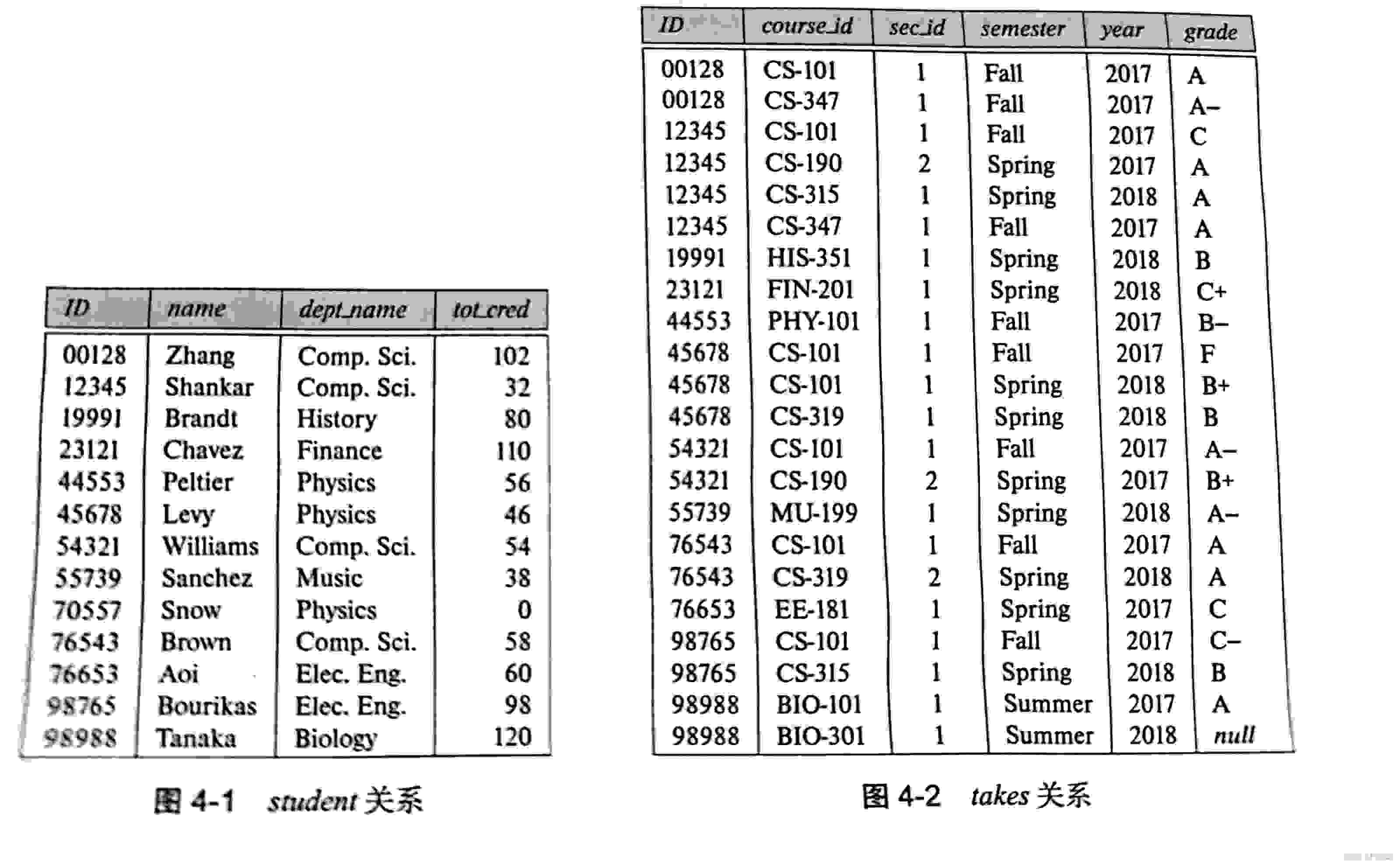
1.1 自然连接
请考虑以下SQL查询,该查询为每名学生计算该学生已经选修的课程的集合。
select name,curse_idfrom student,takeswhere student.ID = takes.ID;请注意,此查询仅输出已选修某些课程的学生,未选修任何课程的学生不会被输出。请注意上面连接条件中student.ID与takes.ID具有相同的属性名ID,这在实际的SQL查询中含常见,自然连接被设计出来简化上述情况的查询。
自然连接运算作用于两个关系,并产生一个关系作为结果。与两个关系的笛卡尔积不同,自然连接只考虑在两个关系的模式中都出现的那些属性上取值相同的元组对,而笛卡尔积将第一个关系的每个元组与第二个关系的每个元组进行串接。
上面的SQL也可以这么写。
student natural join takes其查询结果如下,注意属性的列出顺序,受限是两个关系模式中的公共属性,其次是第一个关系模式中的那些属性,最后是只出现在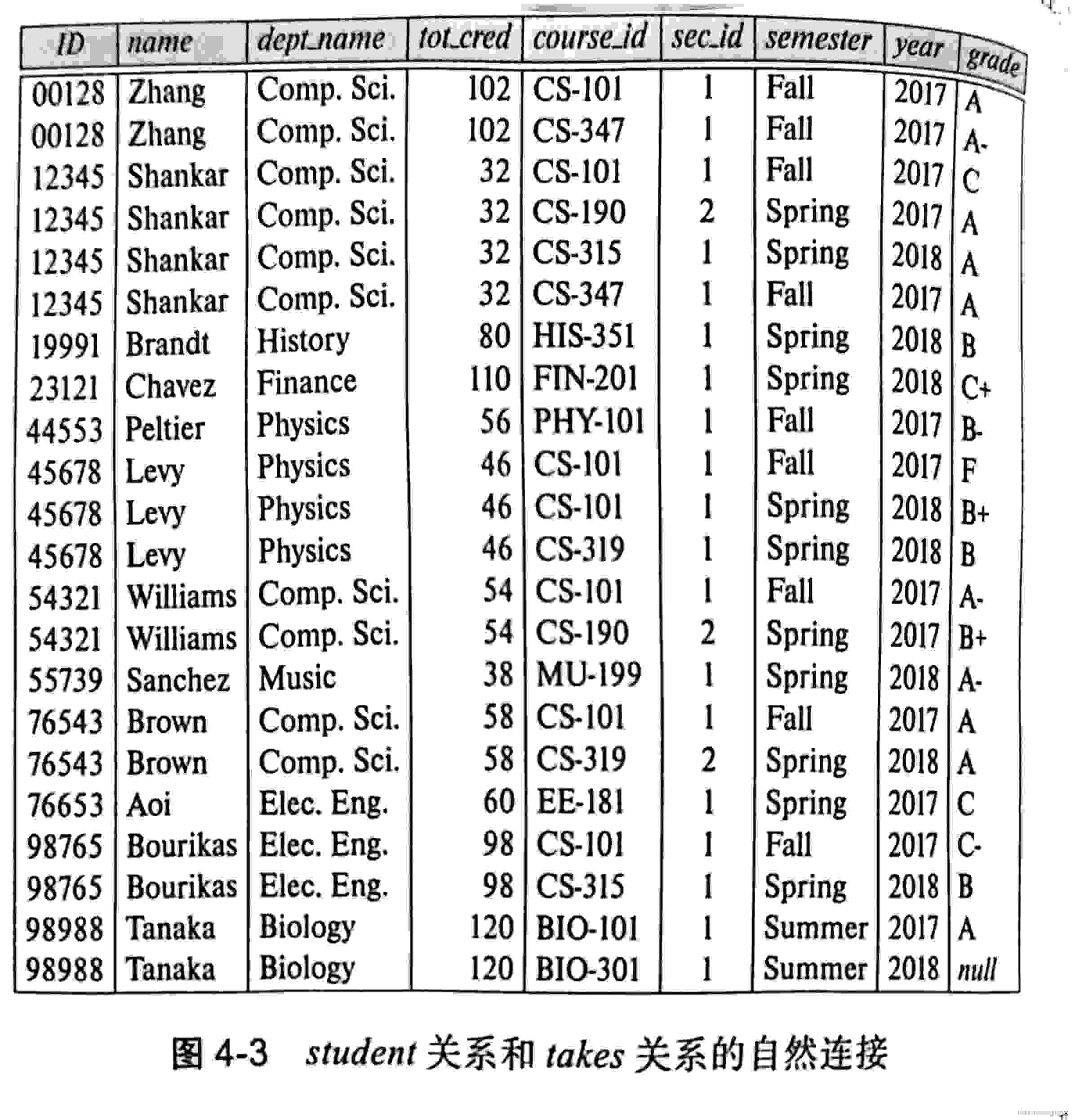
第二个关系中的那些属性。
之前有一个查询,"对于大学中已经选课的所有学生,找出他们的姓名以及他们选修的所有课程的标识。”我们可以这么写。
select name, course_idfrom student natural join takes;在一条SQL查询的from字句中,可以用自然连接把多个关系结合在一起。
select A1,A2....Anfrom r1 natural join r2 natural join r3... natural join rmwhere P;更一般地,from子句可以写为如下形式。
from E1,E2...En每个Ei可以是单个关系或者一个涉及自然连接的表达式。例如,假设我们要查询“列出学生的姓名和他们所选择的课程的名称”。可以写。
select name,titlefrom student natural join takes, coursewhere takes.course_id = course.course_id;受限计算studnet和takes的自然连接,再计算该结果与course的笛卡尔积,where字句从结果中再过滤,过滤条件是course_id相匹配。
思考如下sql与上面的sql是否会等价。
select name,titlefrom student natural join takes natural join course不是!!!
请注意student和takes做自然连接后包含的属性是(ID,name,dept_name,tot_cred,course_id,sec_id),而course包含的属性是(course_id,titile,dept_name,credits)。上面二者做自然连接,不仅需要course_id取值相同,还需要dept_name取值相同。
为了避免这样的错误出现,我们可以这样做。
select name,titlefrom (student natural join takes) join course using (course_id);1.2 连接条件
除了上面的join using外,还可以使用on关键字指定连接条件。
select * from student join takes on student.ID = takes.ID; 这与自然查询的结构是一样的,唯一的区别在于查询结果ID出现两次,一次是student中的,一次是takes结果中的。如果希望ID只出现一次,可以这么做。
select student.ID as ID,name,dept_name,tot_cred,course_id,sec_id,semester,year,gradefrom student join takes on student.ID = takes.ID; 爱思考的读者会发现,on关键字似乎可以被where所替代,那它是不是一个冗余的语法?实际上,on关键字在外连接中与where表现是不同的,其次,如果使用on作为连接条件,并在where字句中出现其余的条件,sql查询会更加清晰易懂。
1.3 外连接
假设我们希望查询所有学生的个人信息与选修的课程,可能会想到如下检索。
select * from student natural join takes不过如果一个学生没有选修课程,就不会出现在这个结果中。
我们可以改用外连接来实现我们的需求。外连接与我们已经学习过的连接运算类似,但是它会通过在结果中创建包含空值的元组,来保留那些在连接中会丢失的元组。
外连接分为三种,
左外连接。只保留连接关键字之前的关系的元组。右外连接。只保留连接关键字之后的关系的元组。全外连接。保留出现在两个关系中的元组。相比较而言,我们之前学习的不保留未匹配元组的连接运算被称为内连接运算。
比如"查询所有学生的个人信息与选修的课程"可以这样用左外连接实现。
select * from student natural left outer join takes;查询“一门课程也没有选修的学生”。
select IDfrom student natural left outer join takeswhere course_id is null;左外连接与右外连接是对称的,用右外连接实现"查询所有学生的个人信息与选修的课程"。
select * from take natural right outer join student ;全外连接可以看做左外连接与右外连接的并运算。考虑查询,“显示Comp.Sci系中所有学生以及他们在2017年春季选修的所有课程段的列表。在2017年春季选修的所有课程段都必须显示。”
select *from (select * from studentwhere dept_name = 'Comp.Sci')natural full outer join(select *from takeswhere semester = 'Spring' and year = 2017);在外连接中,where和on关键字表现是不同的。on会作为外连接声明的一部分,而where却不是。使用where时不会补全具有空值的元组,使用on则会。
另外,常规连接也被称为内连接,可以使用缺省的关键字inner。
2.视图
让所有用户看到数据库关系中的完整集合并不合适,我们可以通过SQL授权来限制对关系的访问,但是如果仅需要向用户隐藏一个关系中的特定数据,可以使用视图。
除了安全型的考虑,视图还可以通过定制化更好的匹配特定用户的需求。
2.1 视图定义
创建视图语法是。
create view v as <查询表达式>;考虑需要访问instrutor除了salary外的所有数据的职员。
create view faculty asselect ID,name,dept_namefrom instructor;视图在概念上包含查询结果中的元组,但是不进行预计算和存储。我通俗的理解成,创建视图是创建了一个规则,使用视图时再根据规则进行计算。
2.2 在SQL查询中使用视图
创建视图后可以像使用数据表一样使用视图。如。
select ID from faculty ;可以显示的指定视图的属性名称。
create view department_total_salary(dept_name, total_salary) asselect dept_name,sum(salary)from instructorgroup by dept_name;直观的说,任意给定时刻,视图关系几种的元组集都是使用定义视图查询表达式求值的结果,因此如果定义并存储一个视图关系,一旦定义视图的关系被修改,那么视图就会过期。
一个视图还可以被用到另一个视图的定义中去。
2.3 物化视图
某些数据库系统中的视图关系保证:如果定义视图的实际关系发生改变,则视图也跟着修改以保持更新,这样的视图被称为物化视图。如果视图是物化的,则其计算结果会被存储在计算机中,从而在使用视图时可以更快的运行。
既然物化视图会预计算并存储,那么就需要保持物化视图的更新,保持物化视图一直在最新的状态的过程被称为物化视图维护,或者视图维护。这种维护策略可以是实时维护,周期维护,惰性维护(被使用时才更新),人工维护等,支持的策略与数据库产品有关。
物化视图对于频繁使用的视图有帮助,对大型关系的聚集运算也较为适用,需要平衡其存储代价与性能开销。
2.4 视图更新
对视图进行增删改可能会带来严重的问题,因为用视图表达的修改必须被翻译为对数据库关系的实际修改。一般不允许对视图进行更新。不同的数据库可能会指定不同的条件,在满足这些条件的前提下可以对视图进行更新,具体可以参考其系统手册。
一般说来,如果定义视图的查询满足下面条件,那么称SQL视图是可更新的。
from字句中只有一个数据库关系select子句中只包含关系的属性名,并不包含任何的表达式、聚集或者distinct声明。没有出现在select子句中的任何属性都可以取null值。也就是说,这些属性没有非空约束,也不构成主码的一部分。查询中不包含有group by或者having子句。不过要注意,即使满足上面的限制条件,仍然不一定可以将数据顺利插入视图。定义如下视图。
create view history_instructors asselect *from instructorwhere dept_name = 'History';考虑如下查询。尝试向history_instructors视图中插入元组(‘25566’,‘Brown’,‘Biology’,10000)。这个元组可以被插入instructor关系中,但是不满足视图的选择要求dept_name = 'History'。他不应该出现在视图history_instructors中。
我们可以在视图定义的末尾添加with check option子句做到这一点,如果新值满足where子句的条件,就可以插入视图,否则,数据库系统会拒绝该插入操作。
SQL:1999对于视图有更加复杂的规则集。这里不讨论。
触发器机制提供了另外一种视图修改数据库的机制,它更加可取,后续文章将详细介绍。
3.事务
事务有查询或者更新语句的序列组成。SQL标准规定当一条SQL语句被执行时,就隐式的开始了一个事务。下列SQL语句之一会结束该事务。
commit work,事务提交。一个事务提交后就在数据库中称为了永久性的,会自动开始一个新的事务。rollback work,事务回滚,也就是它会撤销事务中的SQL语句执行的所有更新。关键字work在两条语句中都是可选的。
考虑下面场景,如果一个学生成功修完了一个课程,需要对takes关系进行更新,也需要对student关系进行更新。如果更新完其中一个关系,却没有更新完另外一个关系就出现了系统故障,会出现数据不一致的情况。这种情况不应该出现,两个关系要么同时被更新,要么同时不被更新。这就是事务的原子性,
在包括Mysql和PostgreSQL在内的很多SQL实现中,在缺省方式下每条SQL自动组成一个事务,且语句一旦执行完立刻提交该事务。很多数据库实现支持关闭自动提交。
一种更好的备选方案是,作为SQL:1999标准的一部分,允许多条SQL语句被包含在关键字begin atomic ... end之间,这样关键字之间的语句就构成了一个单一的事务,如果执行到end语句,则该事务被默认提交。只有诸如SQL Server的某些数据库支持上述语法。诸如MySQL和PostgreSQL的其他几个数据库支持的是begin语句,该语句启动包含所有后续SQL语句的事务,但是并不支持end语句,事务必须通过commiy work或者rollback work命令来结束。
但是使用诸如Oracle的数据库,自动提交并不是DML语句的缺省设置,请保证在添加或者修改数据后发出commit命令。不过Oracle会自动提交DDL语句。虽然Oracle已经关闭了自动提交,不过期缺省设置可能被本地设置所覆盖。
4.完整性约束
完整性约束保证授权用户对数据库所做的修改不会导致数据一致性的丢失。他可以在数据库关系定义是作为create table的一部分被声明。也可以通过使用alter table table-name add constraint命令将完整性约束添加到已有关系上。
4.1 非空约束
我们可以用非空约束限制属性非空。在创建表时就可以声明属性非空约束,语法是。
name varchar(20) not null主码中禁止出现空值,不需要显示的指定非空约束。
4.2 唯一性约束
可以采用unique约束属性唯一,注意唯一性约束允许属性为null。请回忆一下,空值不等于其他任何值。
4.3 check子句
check§可以制定一个谓词P,灵活的给所有元组增加约束。
比如在crate table命令中的check(budget>0)子句将保证budget的取值非负。
check子句不能够限制属性非空,因为当check子句的计算结果为未知时,也被认为满足谓词P(结果不是false即满足),需要限制非空必须指定单独的非空约束。
根据定义,check子句中的谓词可以任意,不过当前还没有一个被广泛使用的数据库允许其包含子查询的谓词。
4.4 引用完整性
我们常常希望一个关系中的给定属性在另外一个关系中也出现。这就是引用完整性约束。外码是引用完整性约束的一种形式,其中被引用的属性构成被引用关系的主码。
比如对course表的定义有一个声明"foreign key(dept_name) references department ".这个约束说明,对于每个课程元组,元组中指定的系名必须在department关系中存在,这样即可避免为一门课程指定一个并不存在的系名。
在缺省情况下(Mysql 并不支持缺省),SQL中外码引用的是被引用表的主码属性。SQL还支持显示指定被引用关系的属性列表的引用子句版本。例如,course关系的外码声明可以指定为
foreign key(dept_name) references department(dept_name)注意被指定的属性列表必须声明为被引用关系的超码,要么使用主码约束,要么使用唯一性约束来进行这种声明。
在更为普遍的引用完整性约束里,被引用的属性不必是候选码,但是这样的形式不能在SQL中直接声明。SQL标准为其提供了更为普遍的结构,但是,任何广泛使用的数据库系统都不支持这些替代结构。
当违反引用完整性约束时,通常的处理时拒绝执行破坏完整性的操作(即执行更新操作的事务回滚)。但是,在外码子句中可以显示指定其他策略。请考虑course关系上一个完整性约束的如下定义。
create table course(...foreign key (dept_name) references departmenton delete casecadeon update casecase,...);上面制定了外码声明相关联的级联删除子句,如果删除department中的一个元组导致违反了这种引用完整性约束,则系统并不拒绝该删除,而是进行级联删除,即删除引用了被删除的系(department)的课程(course)元组。
除了级联,还可以指定其他策略,比如使用set null将引用域(这里是dept_name)置为null,或者置为该域的缺省值(set default)
如果存在跨多个关系的外码依赖链,则在链的一端所做的删除或者更新可能级联传递至整个链上。
空值会使SQL的引用完整性约束变得更加复杂,这里我们暂时不讨论。
4.5 给约束赋名
我们可以使用关键字contranit为完整性约束赋名,这样在删除约束时很有用。比如。
salary numeric(8,2), constraint minsalary check(salary > 29000),当我们删除约束时,可以
alter table drop constraint minsalary;如果名称缺失,就需要用特定于系统的功能来识别出约束的系统分配名称。并非所有系统都支持这样的功能,但是在比如Oracle中,系统表user_constraints就包含了这样的信息。
4.6 事务中对完整性约束的违反
事务可能包含多个步骤,在某一步也许会暂时违反完整性约束,但是后面的某一步也许就会消除这个违反。例如,假设我们有一个主码为name的person关系,还有一个spouse属性,并且假设spouse是在person上的一个外码。也就是说,该约束要求spouse属性必须是在person表中出现的姓名。假设我们在关系中插入两个元组,一个是关于John的,另一个是关于Mary的,他们互为配偶,无论先插入哪个,都会导致违反该外码约束,直到另一个元组也被插入。
为了处理这样的情况,SQL标准允许将initially deferred子句加入约束声明中,这样约束就不是在事务的中间步骤去检查,而是在事务的结束时去检查。一个约束可以被指定为可延迟的(deferrable),这样在缺省情况它会被立即检查,但是在需要时可以延迟检查。对于这种约束,将使用set constraints constraint-list deferred语句的的执行将作为事务的一部分,从而导致对约束的检查被延迟到事务结束时执行。在约束列表中出现的约束必须指定名称。缺省方式是立刻检查约束,并且许多数据库实现不支持延迟约束检查。
如果spouse可以置为null,可以在插入John和Mary元组时,将其spouse属性置为null,后面再更新值,但这会加大编程量,但属性必须非空时,这种方法就不可行。
4.7 复杂check条件与断言
在SQL标准中还有其它结构用于指定大多数系统当前不支持的完整性约束。可以通过check子句中复杂谓词实现更复杂的数据完整性需求,这里我们不赘述。
一个断言就是一个谓词,他表达我们希望数据库总能满足的一个条件,比如:每个教师不能在同一个学期的同一个时间段在两个不同的教室授课。
断言和复杂check条件都需要相当大的开销,如果系统支持触发器,可以使用触发器实现等价的功能。
5.SQL的数据类型与模式
5.1 SQL中的日期和时间类型
SQL中支持的日期和时间相关的数据类型有:
日期(date)。年月日。必须按照2018-04-05这种格式指定。时间(time)。时分秒。可以使用变量time(p)来指定秒的小数点后的数字位数(缺省值为0),通过指定time with timezone,还可以把时区信息连同时间一起存储。必须按照09:20:00格式指定,秒后的小数点位数可以变长。时间戳(timestamo):date和time的结合。可以使用变量timesamp(p)来指定秒的小数点后的数字位数(缺省值为6)。通过指定with timezone,可以把时区信息连同时间一起存储。必须按照2018-04-25 10:29:01.45格式指定,秒后的小数点位数可以变长。 我们可以利用extract(field from d)来从date或time值d中提取出单独的域,这里的域(field)可以是year,month,day,hour,minute或者second中的一种。时区信息可以使用timezone_hour和timezone_minute来提取。
SQL定义了一些函数来获取当前的日期和时间。例如,current_date返回当前日期,current_time返回当前时间(带有时区),还有localtime返回当前的本地时间(不带时区)。时间戳(日期加上时间)由current_timestamp(带有时区)以及localtimestamp(本地,不带时区)返回。
保留Mysql在内的某些系统提供了datetime数据类型用来表示时区不可调整的时间。在实践中,时间规范会有许多的特殊情况。
SQL还支持interval数据类型,它表示时间区间。
5.2 类型转换和格式化函数
我们可以使用形如cast(e as t)的表达式来将表达式e转换为类型t。可能需要数据类型转换来执行特定的操作或者强制保证特定的排序次序。例如,请考虑instructor的ID属性,我们已经将其指定为字符串(varchar(5)),如果我们按此属性排序输出,则ID11111位于ID9之前,因为第一个字符‘1’在‘9’之前。我们可以强转获得我们想要的排序。
select cast(ID as numeric(5)) as inst_idfrom instructororder by inst_id;作为查询结果显示的数据可能需要不同类型的转换,例如,我们可能希望数值以特定位的数字显示,或者数据以特定格式来显示。显示格式的转换并不是数据类型的转换,而是格式的转换。不同数据库产品提供了不同的格式化函数。Mysql提供了format函数,Oracle和PostgreSQL提供了一组函数,to_char,to_number和to_date.SQL Server提供了convert函数。
结果显示的另一个问题就是处理空值,在本书中,我们使用null来使阅读更清晰,但是大多数系统的缺省设置只是将字段留空。可以使用coalesce函数来选择在查询结果中输出空值的方式。该函数接受任意数量的参数(所有参数必须是相同的类型),并返回第一个非空参数。例如,如果我们希望显示教师的ID和工资,但是将空工资显示为0,我们会写:
select ID,coalesce(salary, 0) as salaryfrom instructorcoalesce的一个限制就是所有参数必须是相同的类型,如果我们希望将空工资显示为N/A以表示为不可用,就无法使用coalesce。诸如Oracle提供了**解码(decode)**函数允许这种转换,解码的一般形式是:
decode(value, match-1,replacement-1,match-2,replacement-2,...,match-n,replacement-n,default-replacement);它将value与match值进行比较,匹配则替换,有点类似程序语言中的switch-case结构。
我们可以这样实现前面的需求
select ID,decode(salary, null, 'N/A', salary) as salaryfrom instructor;5.3 缺省值
可以在创建表时指定属性缺省值。
create table student(ID varchar(5),name varchar(20) not null,to_cred numeric(3,0) default 0,primary key(ID));5.4 大对象类型
SQL为字符型数据(clob)和二进制数据(blob)提供了大对象数据类型(large-object data type)。例如,
book_review clob(10KB)image blob(10MB)把一个大对象放入内存是非常低效而且不显示的,应用程序通常用一个SQL查询出大对象的"定位器",然后用宿主语言操作这个对象,例如JDBC应用程序接口允许获取一个定位器,用这个定位器来一点一点取出这个大对象,而不是一次全部取出。
5.5 属性的时态有效性
在某些情况下可能需存储历史数据,比如,我们希望不仅存储每位教师的当前工资,而且存储整个工资历史,可通过向instructor关系模式添加两个属性来指定给定工资值的开始时间和结束时间,这些开始日期和结束日期被称为相对应工资值的有效时间值。
请注意在这种情况下,instructor关系中可能存在不止一个具有相同ID值得元组,后续文章将讨论在时态数据的上下文中特定主码和外码约束的问题。
对支持这种时态结构的数据库系统来说,第一步就是提供语法来支持指定特定属性来定义有效的时间区间,比如我们使用Oracle12的语法示例。使用如下的period声明来扩充instructor的SQL DDL,以表明start_date和end_date属性指定了一个有效的时间区间。
create table instructor(...start_date date,end_date date,period for valid_time(start_date, end_date),...);在进行查询时则使用as of period for结构,以仅获取其特定有效时间的那些元组。比如
select name,salary,start_date,end_datefrom instructor as of period for valid_time '20-JAN-2014';结合between and可以查找时间段。
5.6 用户自定义类型
SQL支持两种形式的用户自定义数据类型,第一种是独特类型(distinct type),另一种是结构化数据类型(structured data type),允许创建具有嵌套记录结构、数组和多重集的复杂数据结构,本文介绍前者,后续文章将介绍结构化数据类型。
教师姓名和系的姓名都是字符串,然而我们通常并不认为把一个教师的姓名赋给一个系名,把一个以美元表示的货币值与以英镑表示的货币值进行直接比较是合法的。一个好的类型系统应该能够检测出这类赋值或者比较,为了支持这种检测,SQL提供了distinct type的概念,可以定义新类型,如:
create type Dollars as numeric(12,2) final;create type Pounds as numeric(12,2) final;这样我们就可以创建下表。
create table department(dept_name varchar(20),building varchar(15),budget Dollars);由于强类型转换,表达还(department.budget + 20)将不被接受,可以将budget 强转为numeric,但是如果需要存回Dollars类型的属性中,又需要转换为Dollars类型。
可以使用drop type和alter type子句删除或者修改以前创建过的类型。
SQL-1999提出创建类型前,还有一个类似概念,创建域domain,二者其实有重大差异,不过大多数数据库实现并没有支持创建类型和创建域,这里不做展开。
一个创建域的例子是。
create domain degree_level varchar(10)constraint degree_level_testcheck (value in 'Bachelors','Masters','Dectorate'));5.7 生成唯一码值
数据库系统提供了生成唯一码值的自动管理,具体语法依赖于数据库实现。这里我们展示的语法接近Oracle和DB2的语法。
ID number(5) generated always as identity当使用always选项是,在insert语句是必须避免为相关属性指定值。如果使用by default则可以选择是否指定我们自己挑选的ID。
在PostgreSQL中,我们可以将ID类型定义为serial,它告诉PostgreSQL要自动生成标识。在Mysql中,我们使用auto_increment来实现自动生成唯一自增码值。
此外,许多数据库都支持创建序列结构,该结构创建域任何关系分离的序列计数器对象,并允许SQL查询从序列中获得下一个值,每次获得的值递增。这样,多个关系之间的(如student.ID与instructor.ID)也可以保持唯一。
5.8 create table的扩展
应用常常要求创建域现有的某个表模式相同的表,SQL提供了语法支持。
create table temp like instructor;在编写一个复杂查询时,把查询的结果存储成一个新表通常是有用的。SQL:2003提供了一种简单的支持。
create table t1 as(select *from instuctorwhere dept_name = 'music')with data;上面SQL创建了临时表t1并且把查询的数据存储到了t1。通过在关系名后面列出列名,还可以显示的指定列的名称。
许多数据库实现还支持缺省with data但也载入数据,不同数据库对create table ...like和create table ...as的语法支持并不完全相同,请查阅文档。
我们发现create table ... as与create view很相似,两者都是用查询来定义的。当表创建时表的内容就被加载了,但是视图内容总是反应当前查询的结构。
5.9 模式、目录与环境
现代的数据库系统提供了三层体系结构用于关系的命名。
体系结构的最顶层由目录(catalog)构成(一些数据库实现也将这层称为数据库),每个目录都可以包含模式,视图和关系等SQL对象都包含在模式中。
为了在数据库上执行任何操作,用户(或程序)都必须先连接到数据库。用户必须提供用户名,通常还需要提供密码来验证身份。每个用户有一个唯一的缺省目录和模式,当一个用户连接到数据库系统时,系统将为其连接缺省的目录和模式。
我们可以这么唯一表示一个关系
catalog2.univ_schema.course如果目录(模式)为缺省目录(模式),可以省略。
缺省的目录和模式是为了每个连接建立的**SQL环境(SQL environment)**的一部分,环境还包括用户标识(也称为授权标识(authorization identifier))。所有通常的SQL语句都在一个模式的环境中运行。
可以使用create schema和drop schema语句来创建和删除模式。在大多数数据库系统中,模式还随着用户账户的创建而自动创建,此时模式名被置为用户账户名。模式要么建立在缺省目录中,要么建立在创建用户是所指定的目录中,新创建的模式将成为该用户的缺省模式。
目录的创建和删除根据数据库的实现不同而不同,这并不是SQL标准的一部分。
6.SQL中的索引定义
关系属性上索引(index)是一种数据结构,它允许数据库系统高效的找到元组,而不必扫描整个数据库的所有元组。
其语法是
create index dept_idx on instructor(dept_name);上面创建了关于dept_name的索引,这样在查找dept_name为’music’的instructor元组时效率会变高。
如果我们想要声明一个搜索码就是候选码,那么需要在索引定义是增加属性unique
create unique index dept_idx on instructor(dept_name);如果我们输入create unique index时,dept_name并不是一个候选码,那么系统会显示错误信息,索引创建会失败。如果索引创建成功,则后面违反候选码声明的任何元组插入企图将会失败。请注意,如果数据库系统支持标准的唯一性声明,这里的唯一性特性就是多余的。
删除索引。
drop index dept_idx;7.授权
7.1 权限的授予与收回
SQL标准包括的权限由:选择(select)、插入(insert)、更新(update)、删除(delete),所有权限(all previlege)。创建一个关系的用户默认被授予该关系的所有权限。一个授权的sql示例是:
grant select on department to Amit,Satoshi;更新授权可以指定属性列表,缺省时为所有属性。
grant update(budget) on department to Amit,Satoshi;关系上得插入授权也可以指定属性列表,对关系的任何插入只针对这些属性,系统的其余属性要么赋缺省值(定义缺省值前提下),要么将其置空。
删除与查询权限类似。
public代指系统的所有当前用户及将来的用户,对public授权隐含着对当前所有用户和将来的用户授权。
在缺省情况下,权限接受者不可将权限授予其他用户,但是SQL可以授予权限接受者进一步将权限授予给其他用户、角色。
使用invoke可以收回权限。与授权的语法几乎一致。
invoke select on department from Amit,Satoshi;如果被收回权限的用户已经把权限授予给了其他用户,那么权限的收回会更加复杂,后文讨论。
7.2 角色
教师、学生是不同的角色(role),一个角色类型可能需要同样的权限。比如教师需要授予一类权限,无论何时指派一个新的教师,都应该获取这些权限。
可以授予用户的任何权限都可以授予角色。创建角色语法如下。
create role instructor;授予角色权限的语法与用户也一样。
grant select on takes to instructor;角色可以授予用户,也可以授予其他角色。
create role dean;grant instructor to dean;grant dean to Satoshi;用户或者角色被授予了角色后,就会继承该角色的所有权限。
7.3 视图的授权
考虑一个工作人员需要知道地质系的所有员工工资,但是无权看到其他系中的员工相关信息。可以通过给该工作人员视图授权实现需求。
创建视图必须要首先拥有关系的选择权限,并且,视图的创建者并不会获得视图的所有权限。如果一个用户在关系上没有更新权限,即使它创建了该关系的视图,也不能在视图上获得更新权限。
在函数和过程上可以授予执行权限,以允许用户执行该函数和过程。在缺省情况下,函数和过程拥有其创建者所拥有的所有权限。在效果上,函数和过程的运行就像他被其创建者调用了一样(实际上不一定其创建者就是其调用者)。在SQL:2003开始,如果函数定义有一个额外的sql security invorker子句,那么它就在调用该函数的用户权限下执行,而不是函数定义者的权限下执行。
7.4 模式的授权
SQL标准为数据库模式指定了一种基本的授权机制:只有模式的拥有者才能够执行对模式的任何修改,比如创建删除关系,对关系的属性增删改查等等。
但是,SQL提供了一种引用(reference)权限,它允许一个用户在创建关系时声明外码。语法如下。
grant references(dept_name) on department to Mariano;为何需要对引用授权呢?乍一看没必要限制用户引用其他关系的外码。但是,请回想下:外码约束限制了被引用关系的删除和更新操作。假如Mariano在关系r上创建了一个外码,引用department的dept_name属性,然后在r中插入一条属于地质系的元组,那么除非同时修改关系r,否则再也不可能将地质系在department中删除了~
参考如下示例,创建一个复杂check约束的情况,可能会影响被引用关系time_slot的更新,也需要授予time_slot上的引用权限,原因与外码约束一样。
check(time_slot_id in (select time_slot_id from time_slot)) 7.5 权限的转移
可以增加参数with grant option允许获得权限的用户将权限授权给其他用户。
grant select on department to Amit,Satoshi with grant option;权限的传递可以用授权图表示,节点就是用户。
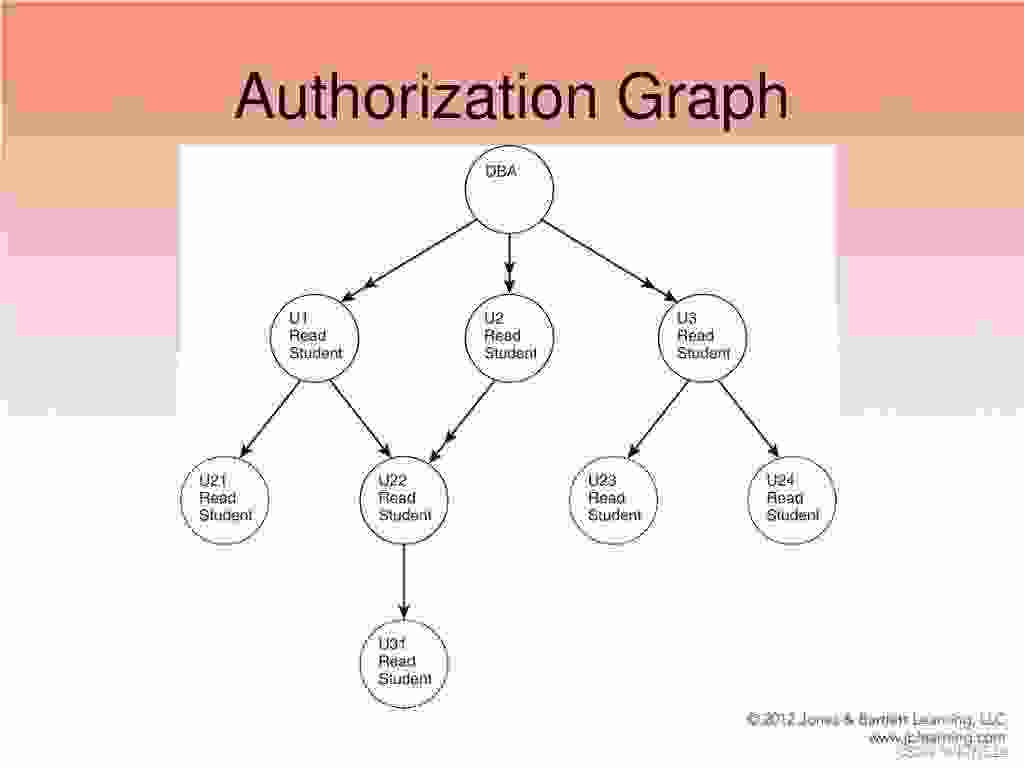
一个用户获得权限的充要条件是,当且仅当存在授权图的根到该用户节点的路径。
7.6 权限的级联收回
上游用户的权限回收,会导致下游用户的权限也被回收。比如回收U1的权限,则U21也会被回收权限,但是U22还存在上游U2,因此还拥有权限。这被称为级联收权(cascading revocation)。大多数数据库系统中,级联收权是默认缺省方式,但是收权语句可以限定来防止级联收权。
revoke select on department from Amit restrict;可以把授权权限当成普通权限回收。下面就是回收授权权限,但并不会回收选择权限。注意并不是所有数据库都支持该语法。
revoke grant option for select on department from Amit restrict;级联收权在许多情况下是不合适的,比如Satishi具有Dean角色,他将instructor权限授予了Amit,即使Satishi退休权限被回收了,Amit还是一个好老师。
为了避免这种情况,SQL允许权限通过角色来授予,而不是通过用户来授予。SQL有一个与会话相关的当前角色概念。在缺省情况下,一个会话所关联的当前角色是空。可以通过set role rolename来指定当前会话的角色,在当前会话角色不为空的情况下,我们可以在授权时以角色的身份授权而不是用户的身份授权。具体语法是为授权语句增加子句:
granted by current_role7.7 行级授权
一些数据库系统(Oracle,SQL Server和PostgreSQL)在特定的元组级别提供了细粒度的授权机制。
假如我们允许学生在takes中查看他自己的数据但是不允许查看其他用户的数据,可以使用行级授权。
Oracle虚拟私有数据库(Virtual Private Database,VPD)功能支持如下所示的行级授权,允许系统管理员将函数与关系相关联,该函数返回一个谓词,该谓词会自动被添加到使用该关系的任何查询中。该谓词可以使用sys_context函数,它返回代表正在执行查询的用户的标识。对于需求:允许学生在takes中查看他自己的数据但是不允许查看其他用户的数据,可以指定如下谓词:
ID = sys_context('USERENV','SESSION_USER')系统将此谓词添加到使用takes关系的每个查询的where子句中,每个学生就只能看到与其ID相匹配的那些takes元组。但这样做有一个显著的隐患,就是可能改变查询的含义,比如一个用户需要查找所有课程的平均成绩,最后只会得到它的成绩的平均值。