OpenCV实战项目 -- 口罩识别
每次我忘记戴口罩去食堂吃饭的时候,门口都会有志愿者学生提醒你:“你好,麻烦戴下口罩。” 进门后里面那块大屏幕还会发出声音:“请佩戴口罩”。
上次博客仿照宿舍楼下那块大屏幕写了个人脸考勤,所以这次我打算弄一个口罩识别。
实现口罩识别的方式有很多种,也并非是一件难事。重要的是要学会把学到的知识运用到生活中去。为此,我特地翻出了吃灰的“树莓派”主板,打算放到宿舍门口。无他,卷一卷督促室友学习。
一、简单流程思路分析
相信大多数初学人工智能的小伙伴,最早接触的一定是CNN处理图像分类的问题,本次项目的核心也就是CNN分类了。所以,这只是前面所学知识的结合,不做过多赘述。
A. 训练模型
在此之前,我们要弄到数据集:佩戴口罩、未佩戴口罩、佩戴口罩不规范 的图片。然后对数据集进行预处理。搭建CNN网络模型并进行图片分类。此时,我们便拿到了模型权重文件!
B. 处理摄像头输入
打开摄像头,然后捕捉到我们的照片。处理输入图片,裁剪出人脸区域。裁剪后的图片作为神经网络的输入,得到网络预测分类结果。将结果显示在屏幕上。
C. 树莓派部署
不难,但是有点花时间,这里不做过多说明。
二、CNN实现口罩佩戴图片分类
1. 数据集处理
无论是机器学习还是深度学习,最重要的便是数据集,之后才是相关的模型和算法。
在这里,我们首先处理图片,把每一张佩戴口罩的照片裁剪出人脸部分,之后为了便于计算和训练我们将图片进行压缩。相关方法之前博客已经介绍过这里不做赘述。
大家可以自己到网上下载数据集,也可以使用我参考的这份,数据量比较小,用于演示:链接
# 人脸检测函数def face_detect(img): #转为Blob img_blob = cv2.dnn.blobFromImage(img,1,(300,300),(104,177,123),swapRB=True) # 输入 face_detector.setInput(img_blob) # 推理 detections = face_detector.forward() # 获取原图尺寸 img_h,img_w = img.shape[:2] # 人脸框数量 person_count = detections.shape[2] for face_index in range(person_count): # 通过置信度选择 confidence = detections[0,0,face_index,2] if confidence > 0.5: locations = detections[0,0,face_index,3:7] * np.array([img_w,img_h,img_w,img_h]) # 获得坐标 记得取整 l,t,r,b = locations.astype('int') return img[t:b,l:r] return None效果:

# 转为Blob格式函数def imgBlob(img): # 转为Blob img_blob = cv2.dnn.blobFromImage(img,1,(100,100),(104,177,123),swapRB=True) # 维度压缩 img_squeeze = np.squeeze(img_blob).T # 旋转 img_rotate = cv2.rotate(img_squeeze,cv2.ROTATE_90_CLOCKWISE) # 镜像 img_flip = cv2.flip(img_rotate,1) # 去除负数,并归一化 img_blob = np.maximum(img_flip,0) / img_flip.max() return img_blob效果:

有了这两个函数,我们就可以进行数据集的处理了:
import tqdmimport os,globlabels = os.listdir('images/')img_list = []label_list = []for label in labels: # 获取每类文件列表 file_list =glob.glob('images/%s/*.jpg' % (label)) for img_file in tqdm.tqdm( file_list ,desc = "处理文件夹 %s " % (label)): # 读取文件 img = cv2.imread(img_file) # 裁剪人脸 img_crop = face_detect(img) # 转为Blob if img_crop is not None: img_blob = imgBlob(img_crop) img_list.append(img_blob) label_list.append(label)最后,我们将其转换为npz格式文件:
X = np.asarray(img_list)Y = np.asarray(label_list)np.savez('./data/imageData.npz',X,Y)
2. 模型训练
首先我们读取之前保存的npz文件:
import numpy as nparr = np.load('./data/imageData.npz')img_list = arr['arr_0']label_list =arr['arr_1']print(img_list.shape,label_list.shape)((5328, 100, 100, 3), (5328,))
设置为onehot独热编码:
from sklearn.preprocessing import OneHotEncoderonehot = OneHotEncoder()# 编码y_onehot =onehot.fit_transform(label_list.reshape(-1,1))y_onehot_arr = y_onehot.toarray()划分数据集:
from sklearn.model_selection import train_test_splitx_train,x_test,y_train,y_test=train_test_split(img_list,y_onehot_arr,test_size=0.2,random_state=123)x_train.shape,x_test.shape,y_train.shape,y_test.shape((4262, 100, 100, 3), (1066, 100, 100, 3), (4262, 3), (1066, 3))
构建并编译模型:
from tensorflow import kerasfrom tensorflow.keras import layers,modelsimport tensorflow as tfgpus = tf.config.list_physical_devices("GPU")if gpus: gpu0 = gpus[0] #如果有多个GPU,仅使用第0个GPU tf.config.experimental.set_memory_growth(gpu0, True) #设置GPU显存用量按需使用 tf.config.set_visible_devices([gpu0],"GPU")model = models.Sequential([ layers.Conv2D(16,3,padding='same',input_shape=(100,100,3),activation='relu'), layers.MaxPool2D(), layers.Conv2D(32,3,padding='same',activation='relu'), layers.MaxPool2D(), layers.Conv2D(64,3,padding='same',activation='relu'), layers.MaxPool2D(), layers.Flatten(), layers.Dense(166,activation='relu'), layers.Dense(22,activation='relu'), layers.Dense(3,activation='sigmoid')])# 编译模型model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001), loss=tf.keras.losses.categorical_crossentropy, metrics=['accuracy'])model.summary()Model: "sequential"_________________________________________________________________Layer (type) Output Shape Param # =================================================================conv2d (Conv2D) (None, 100, 100, 16) 448 _________________________________________________________________max_pooling2d (MaxPooling2D) (None, 50, 50, 16) 0 _________________________________________________________________conv2d_1 (Conv2D) (None, 50, 50, 32) 4640 _________________________________________________________________max_pooling2d_1 (MaxPooling2 (None, 25, 25, 32) 0 _________________________________________________________________conv2d_2 (Conv2D) (None, 25, 25, 64) 18496 _________________________________________________________________max_pooling2d_2 (MaxPooling2 (None, 12, 12, 64) 0 _________________________________________________________________flatten (Flatten) (None, 9216) 0 _________________________________________________________________dense (Dense) (None, 166) 1530022 _________________________________________________________________dense_1 (Dense) (None, 22) 3674 _________________________________________________________________dense_2 (Dense) (None, 3) 69 =================================================================Total params: 1,557,349Trainable params: 1,557,349Non-trainable params: 0_________________________________________________________________
训练模型:
history = model.fit(x=x_train, y=y_train, validation_data=(x_test,y_test), batch_size=30, epochs=15)模型评估:
acc = history.history['accuracy']val_acc = history.history['val_accuracy']loss = history.history['loss']val_loss = history.history['val_loss']epochs_range = range(len(loss))plt.figure(figsize=(12, 4))plt.subplot(1, 2, 1)plt.plot(epochs_range, acc, label='Training Accuracy')plt.plot(epochs_range, val_acc, label='Validation Accuracy')plt.legend(loc='lower right')plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)plt.plot(epochs_range, loss, label='Training Loss')plt.plot(epochs_range, val_loss, label='Validation Loss')plt.legend(loc='upper right')plt.title('Training and Validation Loss')plt.show()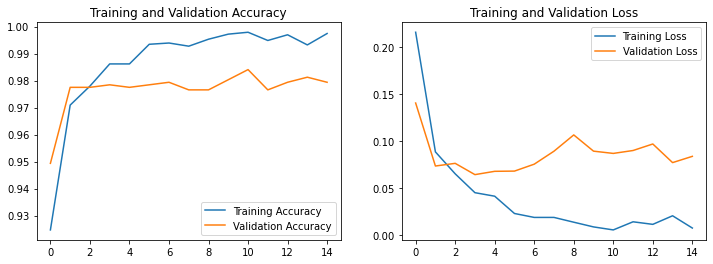
保存模型:
model.save('./data/face_mask_model')
三、模型测试
我们上面可以看到,简单的数据集和模型已经可以使准确率达到98%了,我们接下来就可以打开摄像头,然后获取自己的图片放入模型进行预测了!
在这之前,可以简单测试一下模型:
# 加载模型model = tf.keras.models.load_model('./data/face_mask_model/')# 挑选测试图片img = cv2.imread('./images/2.no/0_0_caizhuoyan_0009.jpg')plt.imshow(cv2.cvtColor(img,cv2.COLOR_BGR2RGB))plt.axis("off")
由于我们训练的时候,数据集是什么样的,做过什么处理,我们输入就要对其做同样的处理,才能保证预测的准确率:
# 裁剪人脸img_crop = face_detect(img)# 转为Blobimg_blob = imgBlob(img_crop)# reshapeimg_input = img_blob.reshape(1,100,100,3)# 预测result = model.predict(img_input)预测结果:
labels = os.listdir('./images/')labels[result.argmax()]
四、处理摄像头输入
就像上面说的,模型的输入要与训练时一致,所以我们同样要对其进行裁剪、格式转换、压缩、归一化的操作。
下面直接附上完整代码。
五、项目代码
权重文件和数据集:链接
大家可以根据自己需求更改代码。
import cv2import timeimport numpy as npimport tensorflow as tfclass MaskDetection: def __init__(self,mode='rasp'): """ 加载人脸检测模型 和 口罩模型 """ gpus = tf.config.list_physical_devices("GPU") if gpus: gpu0 = gpus[0] #如果有多个GPU,仅使用第0个GPU tf.config.experimental.set_memory_growth(gpu0, True) #设置GPU显存用量按需使用 tf.config.set_visible_devices([gpu0],"GPU") self.mask_model = tf.keras.models.load_model('./data/face_mask_model.h5') # 类别标签 self.labels = ['正常','未佩戴','不规范'] # 标签对应颜色,BGR顺序,绿色、红色、黄色 self.colors = [(0,255,0),(0,0,255),(0,255,255)] # 获取label显示的图像 self.zh_label_img_list = self.getLabelPngList() def getLabelPngList(self): """ 获取本地label显示的图像的列表 """ overlay_list = [] for i in range(3): fileName = './label_img/%s.png' % (i) overlay = cv2.imread(fileName,cv2.COLOR_RGB2BGR) overlay = cv2.resize(overlay,(0,0), fx=0.3, fy=0.3) overlay_list.append(overlay) return overlay_list def imageBlob(self,face_region): """ 将图像转为blob """ if face_region is not None: blob = cv2.dnn.blobFromImage(face_region,1,(100,100),(104,117,123),swapRB=True) blob_squeeze = np.squeeze(blob).T blob_rotate = cv2.rotate(blob_squeeze,cv2.ROTATE_90_CLOCKWISE) blob_flip = cv2.flip(blob_rotate,1) # 对于图像一般不用附属,所以将它移除 # 归一化处理 blob_norm = np.maximum(blob_flip,0) / blob_flip.max() return blob_norm else: return None def detect(self): """ 识别 """ face_detector = cv2.dnn.readNetFromCaffe('./weights/deploy.prototxt.txt','./weights/res10_300x300_ssd_iter_140000.caffemodel') cap = cv2.VideoCapture(0) frame_w = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)) frame_h = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)) frameTime = time.time() videoWriter = cv2.VideoWriter('./record_video/out'+str(time.time())+'.mp4', cv2.VideoWriter_fourcc(*'H264'), 10, (960,720)) while True: ret,frame = cap.read() frame = cv2.flip(frame,1) frame_resize = cv2.resize(frame,(300,300)) img_blob = cv2.dnn.blobFromImage(frame_resize,1.0,(300,300),(104.0, 177.0, 123.0),swapRB=True) face_detector.setInput(img_blob) detections = face_detector.forward() num_of_detections = detections.shape[2] # 记录人数(框) person_count = 0 # 遍历多个 for index in range(num_of_detections): # 置信度 detection_confidence = detections[0,0,index,2] # 挑选置信度 if detection_confidence>0.5: person_count+=1 # 位置坐标 记得放大 locations = detections[0,0,index,3:7] * np.array([frame_w,frame_h,frame_w,frame_h]) l,t,r,b = locations.astype('int') # 裁剪人脸区域 face_region = frame[t:b,l:r] # 转为blob格式 blob_norm = self.imageBlob(face_region) if blob_norm is not None: # 模型预测 img_input = blob_norm.reshape(1,100,100,3) result = self.mask_model.predict(img_input) # softmax分类器处理 result = tf.nn.softmax(result[0]).numpy() # 最大值索引 max_index = result.argmax() # 最大值 max_value = result[max_index] # 标签 label = self.labels[max_index] # 对应中文标签 overlay = self.zh_label_img_list[max_index] overlay_h,overlay_w = overlay.shape[:2] # 覆盖范围 overlay_l,overlay_t = l,(t - overlay_h-20) overlay_r,overlay_b = (l + overlay_w),(overlay_t+overlay_h) # 判断边界 if overlay_t > 0 and overlay_r < frame_w: overlay_copy=cv2.addWeighted(frame[overlay_t:overlay_b, overlay_l:overlay_r ],1,overlay,20,0) frame[overlay_t:overlay_b, overlay_l:overlay_r ] = overlay_copy cv2.putText(frame, str(round(max_value*100,2))+"%", (overlay_r+20, overlay_t+40), cv2.FONT_ITALIC, 0.8, self.colors[max_index], 2) # 人脸框 cv2.rectangle(frame,(l,t),(r,b),self.colors[max_index],5) now = time.time() fpsText = 1 / (now - frameTime) frameTime = now cv2.putText(frame, "FPS: " + str(round(fpsText,2)), (20, 40), cv2.FONT_ITALIC, 0.8, (0, 255, 0), 2) cv2.putText(frame, "Person: " + str(person_count), (20, 60), cv2.FONT_ITALIC, 0.8, (0, 255, 0), 2) videoWriter.write(frame) cv2.imshow('demo',frame) if cv2.waitKey(10) & 0xFF == ord('q'): break videoWriter.release() cap.release() cv2.destroyAllWindows() mask_detection = MaskDetection()mask_detection.detect()效果如下:

登录后可发表评论
点击登录