目录
项目概述
1.1项目来源
1.2需求描述
数据获取
2.1数据源的选取
2.2数据的获取
2.2.1 设计
2.2.2 实现
2.2.3 效果
数据预处理
3.1 设计
3.2 实现
3.3 效果
数据分析及可视化
4.1 歌单播放量Top10
4.1.1 实现
4.1.2 结果
4.1.3 可视化
4.2 歌单收藏量Top10
4.2.1 实现
4.2.2 结果
4.2.3 可视化
4.3 歌单评论数Top10
4.3.1 实现
4.3.2 结果
4.3.3 可视化
4.4 歌单歌曲收录情况分布
4.4.1 实现
4.4.2 效果及可视化
4.4.3 分析
4.5 歌单标签图
4.5.1 实现
4.5.2 结果
4.5.3 可视化
4.5.4 分析
4.6 歌单贡献up主Top10
4.6.1 实现
4.6.2 结果
4.6.3 可视化
4.7歌单名生成词云
4.4.1 实现
4.7.2 结果及可视化
4.8 代码实现
结束语
项目概述
1.1项目来源
网易云音乐是一款由网易开发的音乐产品,是网易杭州研究院的成果 ,依托专业音乐人、DJ、好友推荐及社交功能,在线音乐服务主打歌单、社交、大牌推荐和音乐指纹,以歌单、DJ节目、社交、地理位置为核心要素,主打发现和分享。对网易云音乐官网歌单部分进行爬取,对网易云音乐歌单进行数据获取,获取某一歌曲风格的所有歌单,并获取歌单的名称、标签、介绍、收藏量、播放量、歌单收录的歌曲数目,以及评论数。
1.2需求描述
对爬取到的数据进行预处理,在对预处理的数据进行分析,对歌单播放量、歌单收藏量、歌单评论量、歌单歌曲收录情况,、歌单标签,歌单贡献up主等进行分析,并进行可视化,将分析结果更直观的反映出来。
数据获取
2.1数据源的选取
听音乐音乐是当今很多年轻人抒发情感的方式,网易云音乐是一个大众化的音乐平台,可以通过对网易云音乐的歌单情况进行分析,从而了解到当今社会年轻人所面对的问题,以及各方面情感压力;还可以了解到用户的喜好,分析出什么样的歌歌单最受大众欢迎,还可以反应大众的喜好,对音乐创作人的创作也有着很重要的作用。从广大普通用户的角度来看,对于歌单的创建者,创建歌单一方面便于对自己收藏的音乐曲库进行分类管理,另一方面,生产出优质的歌单可以凸显自己的音乐品味,收获点赞与评论,得到极大的成就感与满足感。而对于歌单的消费者来说,基于“歌单”听歌可以大大地提升听歌的用户体验。对于音乐人以及电台主持等类型的歌单创建者来讲,通过“歌单”可以更好地传播自己的音乐与作品,也可以更好地与粉丝互动并扩大知名度。
本次项目爬取的是网易云官网华语歌单部分的数据,爬取地址为:华语歌单 - 歌单 - 网易云音乐
2.2数据的获取
2.2.1 设计
进入每一个页面,获取该页面的每一个歌单,进入单个歌单中,歌单名,收藏量,评论数,标签,介绍,歌曲总数,播放量,收录的歌名等数据都存放在网页的同一个div内,通过selector选择器选择各个内容。
2.2.2 实现
from bs4 import BeautifulSoup import requests import time headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36' } for i in range(0, 1330, 35): print(i) time.sleep(2) url = 'https://music.163.com/discover/playlist/?cat=华语&order=hot&limit=35&offset=' + str(i)#修改这里即可 response = requests.get(url=url, headers=headers) html = response.text soup = BeautifulSoup(html, 'html.parser') # 获取包含歌单详情页网址的标签 ids = soup.select('.dec a') # 获取包含歌单索引页信息的标签 lis = soup.select('#m-pl-container li') print(len(lis)) for j in range(len(lis)): # 获取歌单详情页地址 url = ids[j]['href'] # 获取歌单标题 title = ids[j]['title'] # 获取歌单播放量 play = lis[j].select('.nb')[0].get_text() # 获取歌单贡献者名字 user = lis[j].select('p')[1].select('a')[0].get_text() # 输出歌单索引页信息 print(url, title, play, user) # 将信息写入CSV文件中 with open('playlist.csv', 'a+', encoding='utf-8-sig') as f: f.write(url + ',' + title + ',' + play + ',' + user + '\n') from bs4 import BeautifulSoup import pandas as pd import requests import time df = pd.read_csv('playlist.csv', header=None, error_bad_lines=False, names=['url', 'title', 'play', 'user']) headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36' } for i in df['url']: time.sleep(2) url = 'https://music.163.com' + i response = requests.get(url=url, headers=headers) html = response.text soup = BeautifulSoup(html, 'html.parser') # 获取歌单标题 title = soup.select('h2')[0].get_text().replace(',', ',') # 获取标签 tags = [] tags_message = soup.select('.u-tag i') for p in tags_message: tags.append(p.get_text()) # 对标签进行格式化 if len(tags) > 1: tag = '-'.join(tags) else: tag = tags[0] # 获取歌单介绍 if soup.select('#album-desc-more'): text = soup.select('#album-desc-more')[0].get_text().replace('\n', '').replace(',', ',') else: text = '无' # 获取歌单收藏量 collection = soup.select('#content-operation i')[1].get_text().replace('(', '').replace(')', '') # 歌单播放量 play = soup.select('.s-fc6')[0].get_text() # 歌单内歌曲数 songs = soup.select('#playlist-track-count')[0].get_text() # 歌单评论数 comments = soup.select('#cnt_comment_count')[0].get_text() # 输出歌单详情页信息 print(title, tag, text, collection, play, songs, comments) # 将详情页信息写入CSV文件中 with open('music_message.csv', 'a+', encoding='utf-8') as f: # f.write(title + '/' + tag + '/' + text + '/' + collection + '/' + play + '/' + songs + '/' + comments + '\n') f.write(title + ',' + tag + ',' + text + ',' + collection + ',' + play + ',' + songs + ',' + comments + '\n')
2.2.3 效果
将相关内容存放至相应的.csv文件中,music_message.csv文件中存放了获取歌单的名称、标签、介绍、收藏量、播放量、歌单收录的歌曲数目,以及评论数。playlist.csv文件中存放了歌单详情页地址,歌单标题,歌单播放量,以及歌单贡献者名字。结果如图2-1、2-2所示。
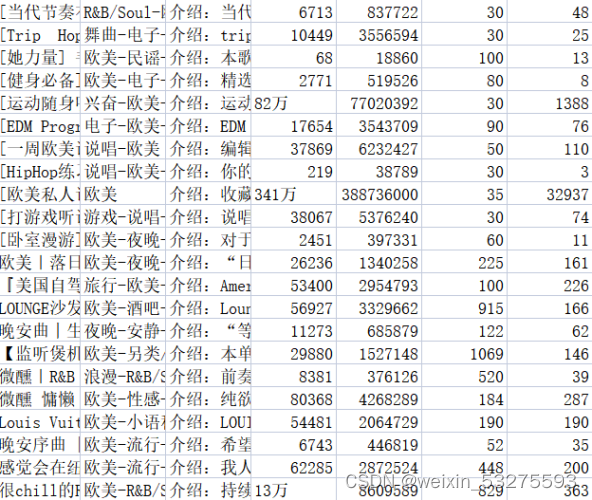
图2-1 music_message.csv文件内容
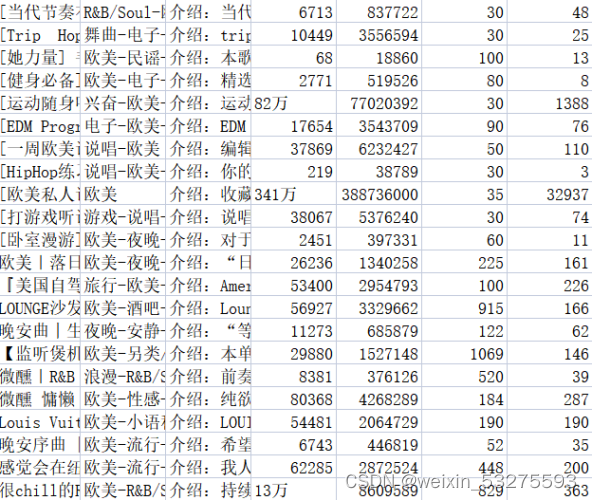
图2-2 playlist.csv文件内容
数据预处理
关于数据的清洗,实际上在上一部分抓取数据的过程中已经做了一部分,包括:后台返回的空歌单信息、重复数据的去重等。除此之外,还要进行一些清洗:将评论量数据统一格式等。
3.1 设计
将评论数中数据带“万”的数据,用“0000”替换“万”便于后续的数据分析,将评论数中数据统计出错的数据用“0”填充,不参与后续统计。
3.2 实现
df['collection'] = df['collection'].astype('string').str.strip() df['collection'] = [int(str(i).replace('万','0000')) for i in df['collection']] df['text'] = [str(i)[3:] for i in df['text']] df['comments'] = [0 if '评论' in str(i).strip() else int(i) for i in df['comments']] 3.3 效果

图3-1 程序运行截图
数据分析及可视化
4.1 歌单播放量Top10
4.1.1 实现
df_play = df[['title','play']].sort_values('play',ascending=False) df_play[:10] df_play = df_play[:10] _x = df_play['title'].tolist() _y = df_play['play'].tolist() df_play = get_matplot(x=_x,y=_y,chart='barh',title='网易云音乐华语歌单播放 TOP10',ha='left',size=8,color=color[0]) df_play 4.1.2 结果
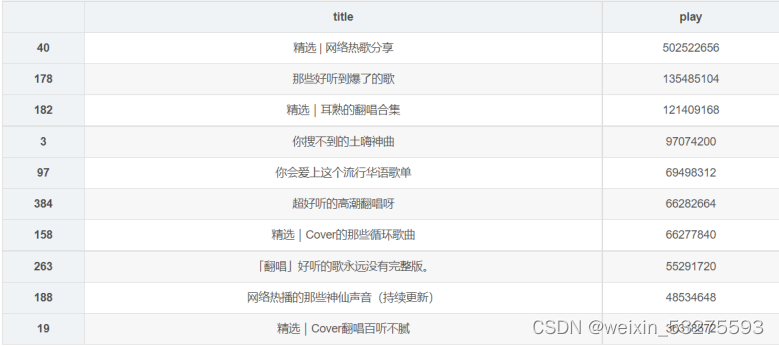
图4-1 程序运行结果截图
4.1.3 可视化
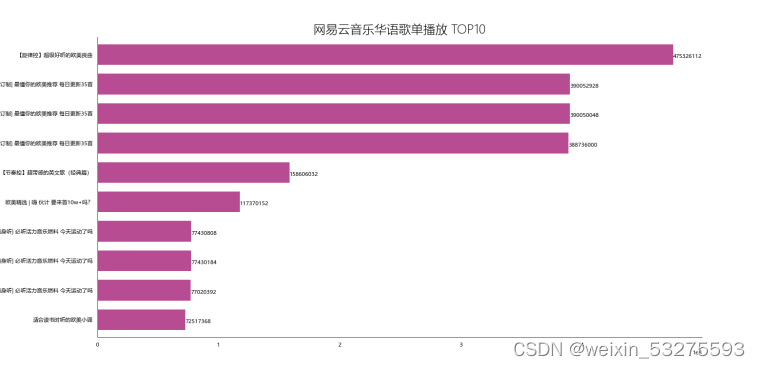
图4-2 网易云音乐华语歌单播放 TOP10
4.2 歌单收藏量Top10
4.2.1 实现
df_col = df[['title','collection']].sort_values('collection',ascending=False) df_col[:10] df_col = df_col[:10] _x = df_col['title'].tolist() _y = df_col['collection'].tolist() df_col = get_matplot(x=_x,y=_y,chart='barh',title='网易云音乐华语歌单收藏 TOP10',ha='left',size=8,color=color[1]) df_col 4.2.2 结果
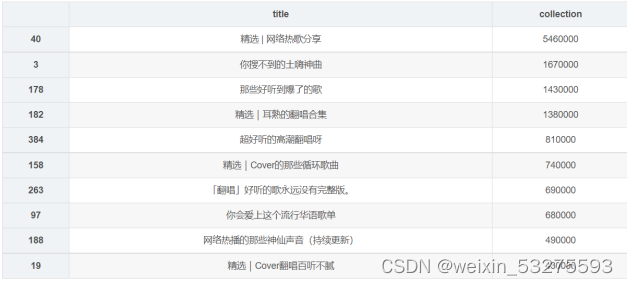
图4-3 程序运行结果截图
4.2.3 可视化
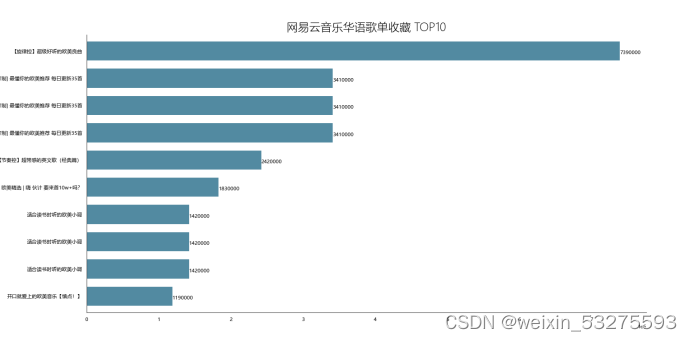
图4-4 网易云音乐华语歌单收藏 TOP10
4.3 歌单评论数Top10
4.3.1 实现
df_com = df[['title','comments']].sort_values('comments',ascending=False) df_com[:10] df_com = df_com[:10] _x = df_com['title'].tolist() _y = df_com['comments'].tolist() df_com = get_matplot(x=_x,y=_y,chart='barh',title='网易云音乐华语歌单评论数 TOP10',ha='left',size=8,color=color[2]) df_com 4.3.2 结果
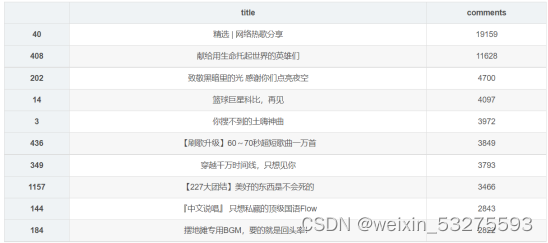
图4-5 程序运行结果截图
4.3.3 可视化

图4-6 网易云音乐华语歌单评论 TOP10
4.4 歌单歌曲收录情况分布
4.4.1 实现
df_songs = np.log(df['songs']) df_songs df_songs = get_matplot(x=0,y=df_songs,chart='hist',title='华语歌单歌曲收录分布情况',ha='left',size=10,color=color[3]) df_songs 4.4.2 效果及可视化
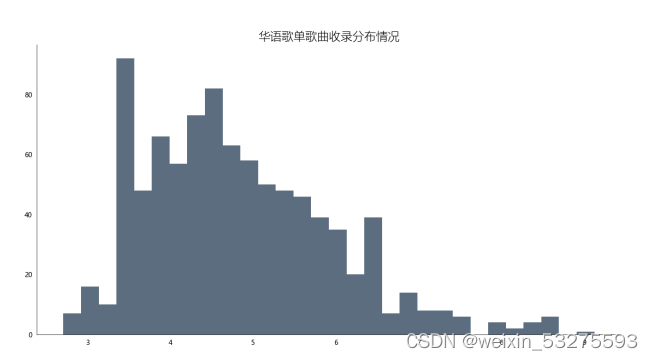
图4-7 华语歌单收录分布情况
4.4.3 分析
通过对柱形图分析发现,歌单对歌曲的收录情况多数集中在20-60首歌曲,至多超过80首,也存在空歌单现象,但绝大多数歌单收录歌曲均超过10首左右。通过本次可视化分析可以使得后续创作者对自己创作歌单的歌曲收录情况提供帮助。也能够更受大众欢迎。
4.5 歌单标签图
4.5.1 实现
def get_tag(df): df = df['tag'].str.split('-') datalist = list(set(x for data in df for x in data)) return datalist df_tag = get_tag(df) # df_tag def get_lx(x,i): if i in str(x): return 1 else: return 0 for i in list(df_tag):#这里的df['all_category'].unique()也可以自己用列表构建,我这里是利用了前面获得的 df[i] = df['tag'].apply(get_lx,i=f'{i}') # df.head() Series = df.iloc[:,7:].sum().sort_values(0,ascending=False) df_tag = [tag for tag in zip(Series.index.tolist(),Series.values.tolist())] df_tag[:10] df_iex = [index for index in Series.index.tolist()][:20] df_tag = [tag for tag in Series.values.tolist()][:20] df_tagiex = get_matplot(x=df_iex,y=df_tag,chart='plot',title='网易云音乐华语歌单标签图',size=10,ha='center',color=color[3]) df_tagiex 4.5.2 结果
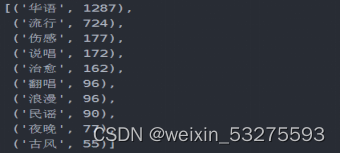
图4-8 华语歌单标签情况
4.5.3 可视化

图4-9 歌单标签图
4.5.4 分析
可以通过此标签图看出歌单的风格,可以分析出目前的主流歌曲的情感,以及大众的需求,也网易云音乐用户的音乐偏好,据此可以看出,网易云音乐用户,在音乐偏好上比较多元化:国内流行、欧美流行、电子、 等各种风格均有涉及。
4.6 歌单贡献up主Top10
4.6.1 实现
df_user = pd.read_csv('playlist.csv',encoding="unicode_escape",header=0,names=['url','title','play','user'],sep=',') df_user.shape df_user = df_user.iloc[:,1:] df_user['count'] = 0 df_user = df_user.groupby('user',as_index=False)['count'].count() df_user = df_user.sort_values('count',ascending=False)[:10] df_user df_user = df_user[:10] names = df_user['user'].tolist() nums = df_user['count'].tolist() df_u = get_matplot(x=names,y=nums,chart='barh',title='歌单贡献UP主 TOP10',ha='left',size=10,color=color[4]) df_u 4.6.2 结果

图4-10 歌单贡献up主前十
4.6.3 可视化
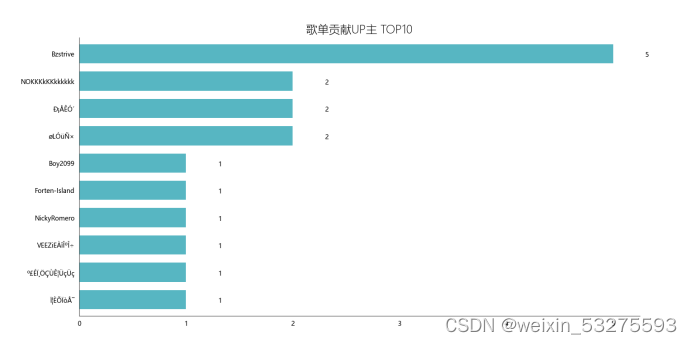
图4-11 歌单贡献up主Top10
4.7歌单名生成词云
4.4.1 实现
import wordcloud import pandas as pd import numpy as np from PIL import Image data = pd.read_excel('music_message.xlsx') #根据播放量排序,只取前五十个 data = data.sort_values('play',ascending=False).head(50) #font_path指明用什么样的字体风格,这里用的是电脑上都有的微软雅黑 w1 = wordcloud.WordCloud(width=1000,height=700, background_color='black', font_path='msyh.ttc') txt = "\n".join(i for i in data['title']) w1.generate(txt) w1.to_file('F:\\词云.png') 4.7.2 结果及可视化

图4-11 歌单名称生成的词云
4.8 代码实现
为了简化代码,构建了通用函数
get_matplot(x,y,chart,title,ha,size,color)
x表示充当x轴数据;
y表示充当y轴数据;
chart表示图标类型,这里分为三种barh、hist、squarify.plot;
ha表示文本相对朝向;
size表示字体大小;
color表示图表颜色;
def get_matplot(x,y,chart,title,ha,size,color): # 设置图片显示属性,字体及大小 plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] plt.rcParams['font.size'] = size plt.rcParams['axes.unicode_minus'] = False # 设置图片显示属性 fig = plt.figure(figsize=(16, 8), dpi=80) ax = plt.subplot(1, 1, 1) ax.patch.set_color('white') # 设置坐标轴属性 lines = plt.gca() # 设置显示数据 if x ==0: pass else: x.reverse() y.reverse() data = pd.Series(y, index=x) # 设置坐标轴颜色 lines.spines['right'].set_color('none') lines.spines['top'].set_color('none') lines.spines['left'].set_color((64/255, 64/255, 64/255)) lines.spines['bottom'].set_color((64/255, 64/255, 64/255)) # 设置坐标轴刻度 lines.xaxis.set_ticks_position('none') lines.yaxis.set_ticks_position('none') if chart == 'barh': # 绘制柱状图,设置柱状图颜色 data.plot.barh(ax=ax, width=0.7, alpha=0.7, color=color) # 添加标题,设置字体大小 ax.set_title(f'{title}', fontsize=18, fontweight='light') # 添加歌曲出现次数文本 for x, y in enumerate(data.values): plt.text(y+0.3, x-0.12, '%s' % y, ha=f'{ha}') elif chart == 'hist': # 绘制直方图,设置柱状图颜色 ax.hist(y, bins=30, alpha=0.7, color=(21/255, 47/255, 71/255)) # 添加标题,设置字体大小 ax.set_title(f'{title}', fontsize=18, fontweight='light') elif chart == 'plot': colors = ['#adb0ff', '#ffb3ff', '#90d595', '#e48381', '#aafbff', '#f7bb5f', '#eafb50', '#adb0ff', '#ffb3ff', '#90d595', '#e48381', '#aafbff', '#f7bb5f', '#eafb50', '#adb0ff', '#ffb3ff', '#90d595', '#e48381', '#aafbff', '#f7bb5f', '#eafb50', '#adb0ff', '#ffb3ff', '#90d595', '#e48381', '#aafbff', '#f7bb5f', '#eafb50', '#adb0ff', '#ffb3ff', '#90d595', '#e48381', '#aafbff', '#f7bb5f', '#eafb50', '#adb0ff', '#ffb3ff', '#90d595', '#e48381', '#aafbff', '#f7bb5f', '#eafb50', '#adb0ff', '#ffb3ff', '#90d595', '#e48381', '#aafbff'] plot = squarify.plot(sizes=y, label=x, color=colors, alpha=1, value=y, edgecolor='white', linewidth=1.5) # 设置标签大小为1 plt.rc('font', size=6) # 设置标题大小 plot.set_title(f'{title}', fontsize=13, fontweight='light') # 除坐标轴 plt.axis('off') # 除上边框和右边框刻度 plt.tick_params(top=False, right=False) # 显示图片 plt.show() #构建color序列 color = [(153/255, 0/255, 102/255),(8/255, 88/255, 121/255),(160/255, 102/255, 50/255),(136/255, 43/255, 48/255),(16/255, 152/255, 168/255),(153/255, 0/255, 102/255)] 结束语
我在完成大作业的过程中,学到了很多新的东西,也将本学期在课堂上学习的知识串联了起来。碰到一些记忆模糊的问题,通过翻看课本以及以往的直播回放也都能完美的解决而且加深了自己对这种问题的印象,下次碰到同样的问题也可以给出解决办法;碰到未涉及过的问题,我积极在网络上查找资料,对找到的解决办法进行实践,直到可以真正的解决问题。我知道每个人在实际操作过程中都会遇到各种各样的问题,也有自己不了解的领域,以及随着网络的发展,各种各样的东西也不断进行着更新,我所获取到的知识也需要更新,所以在网上准确查找资料以及快速找到解决办法这都是我们的必修课。
在本次作业完成过程中,我也遇到了很多问题,例如数据爬取出现错误,可视化失败,代码看不懂等问题。遇到问题后,我会先自己检查一下我的代码,发现错误就及时修改,如果碰到无法解决的问题,我会对程序运行的报错信息进行搜索,寻找这种错误的解决办法。在本次作业完成过程中很幸运自己出现的问题都得到了解决。
本次作业完成过程中,苦乐参杂,不断的学习过程中,既有遇见问题无法解决的紧张无措,也有着成功解决问题的成就感。我自己也相应的学到了许多知识,获得了一定的技能。感谢老师及同学们提供的帮助,以后我会更加认真,努力提高自己的能力,更努力的去学习python以及数据分析方面的技术。