1、Datax简要描述
DataX 是阿里云 DataWorks数据集成 的开源版本,在阿里巴巴集团内被广泛使用的离线数据同步工具/平台。DataX 实现了包括 MySQL、Oracle、OceanBase、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、Hologres、DRDS 等各种异构数据源之间高效的数据同步功能。
2、Datax网址
文档地址:https://github.com/alibaba/DataX
下载地址:http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
源码地址:https://github.com/alibaba/DataX
3、Datax的设计
为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。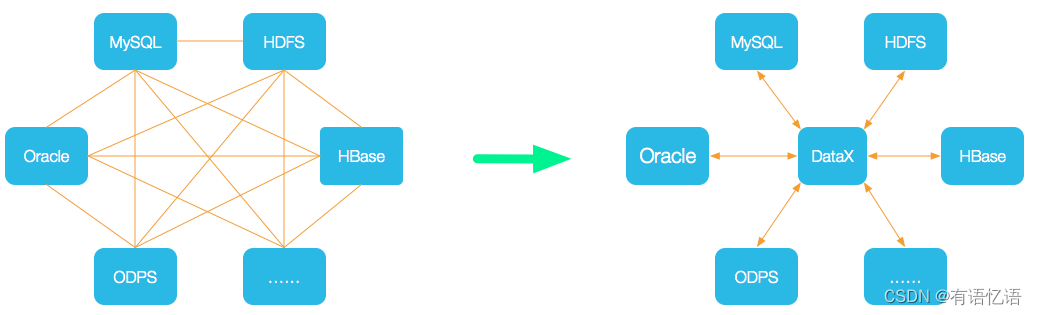
4、框架设计

Datax本身作为离线数据同步框架,采用Framework+plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。
5、运行原理
Datax 3.0 开源版本支持单机多线程模式同步作业运行,本小结按一个DataX作业生命周期的时序图,从整体架构设计非常简要说明DataX各个模块相互关系。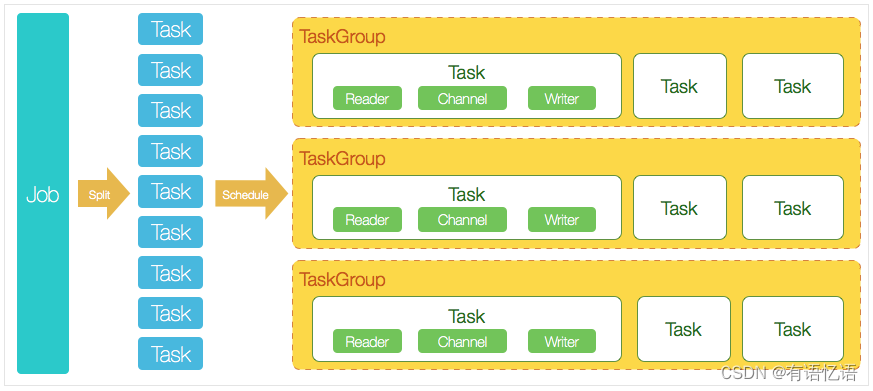
核心模块介绍:
6、简要安装
6.1 前置要求
LinuxJDK(1.8以上,推荐1.8)Python(2或3都可以) Apache Maven 3.x (Compile DataX)6.2 安装
1. Datax 部署
1)方法一
方法一、直接下载DataX工具包:DataX下载地址
下载后解压至本地某个目录,进入bin目录,即可运行同步作业:
$ cd {YOUR_DATAX_HOME}/bin$ python datax.py {YOUR_JOB.json}自检脚本:
python {YOUR_DATAX_HOME}/bin/datax.py {YOUR_DATAX_HOME}/job/job.json
2)方法二
方法二、下载DataX源码,自己编译:DataX源码
(1)、下载DataX源码:
$ git clone git@github.com:alibaba/DataX.git(2)、通过maven打包:
$ cd {DataX_source_code_home}$ mvn -U clean package assembly:assembly -Dmaven.test.skip=true打包成功,日志显示如下:
[INFO] BUILD SUCCESS[INFO] -----------------------------------------------------------------[INFO] Total time: 08:12 min[INFO] Finished at: 2015-12-13T16:26:48+08:00[INFO] Final Memory: 133M/960M[INFO] -----------------------------------------------------------------打包成功后的DataX包位于 {DataX_source_code_home}/target/datax/datax/ ,结构如下:
$ cd {DataX_source_code_home}$ ls ./target/datax/datax/binconfjoblibloglog_perfpluginscripttmp2. 使用
1)从stream读取数据并打印到控制台
第一步、创建作业的配置文件(json格式)
可以通过命令查看配置模板: python datax.py -r {YOUR_READER} -w {YOUR_WRITER}```shell$ cd {YOUR_DATAX_HOME}/bin$ python datax.py -r streamreader -w streamwriterDataX (UNKNOWN_DATAX_VERSION), From Alibaba !Copyright (C) 2010-2015, Alibaba Group. All Rights Reserved.Please refer to the streamreader document: https://github.com/alibaba/DataX/blob/master/streamreader/doc/streamreader.md Please refer to the streamwriter document: https://github.com/alibaba/DataX/blob/master/streamwriter/doc/streamwriter.md Please save the following configuration as a json file and use python {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json to run the job.{ "job": { "content": [ { "reader": { "name": "streamreader", "parameter": { "column": [], "sliceRecordCount": "" } }, "writer": { "name": "streamwriter", "parameter": { "encoding": "", "print": true } } } ], "setting": { "speed": { "channel": "" } } }}```根据模板配置json如下:```json#stream2stream.json{ "job": { "content": [ { "reader": { "name": "streamreader", "parameter": { "sliceRecordCount": 10, "column": [ { "type": "long", "value": "10" }, { "type": "string", "value": "hello,你好,世界-DataX" } ] } }, "writer": { "name": "streamwriter", "parameter": { "encoding": "UTF-8", "print": true } } } ], "setting": { "speed": { "channel": 5 } } }}```第二步:启动DataX(执行任务)
```shell$ cd {YOUR_DATAX_DIR_BIN}$ python datax.py ./stream2stream.json ```第三步:查看结果(验证结果)
同步结束,显示日志如下:```shell...2022-12-17 11:20:25.263 [job-0] INFO JobContainer - 任务启动时刻 : 2022-12-17 11:20:15任务结束时刻 : 2022-12-17 11:20:25任务总计耗时 : 10s任务平均流量 : 205B/s记录写入速度 : 5rec/s读出记录总数 : 50读写失败总数 : 0```2)读取MySQL中的数据存放到HDFS
第一步、查看官方模板,并创建作业配置文件
可以通过命令查看配置模板: python datax.py -r mysqlreader -w hdfswriter
[pgxl@airflow-10-67 bin]$ python datax.py -r mysqlreader -w hdfswriterDataX (DATAX-OPENSOURCE-3.0), From Alibaba !Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.Please refer to the mysqlreader document: https://github.com/alibaba/DataX/blob/master/mysqlreader/doc/mysqlreader.md Please refer to the hdfswriter document: https://github.com/alibaba/DataX/blob/master/hdfswriter/doc/hdfswriter.md Please save the following configuration as a json file and use python {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json to run the job.{ "job": { "content": [ { "reader": { "name": "mysqlreader", "parameter": { "column": [], "connection": [ { "jdbcUrl": [], "table": [] } ], "password": "", "username": "", "where": "" } }, "writer": { "name": "hdfswriter", "parameter": { "column": [], "compress": "", "defaultFS": "", "fieldDelimiter": "", "fileName": "", "fileType": "", "path": "", "writeMode": "" } } } ], "setting": { "speed": { "channel": "" } } }}mysqlreader参数解析
hdfswriter参数解析
第二步、执行任务
第三步、查看结果
3)读取HDFS数据写入MySQL
4)从Oracle中读取数据到Mysql
5)读取Oracle的数据到HDFS
6)读取HDFS数据到Doris
7)读取HDFS数据到ClickHouse
7、DataX常见问题
1、DataX在同步数据的时候,使用sql模式,需要处理特殊字符,REPLACE(REPLACE(REPLACE(column_name,‘\n’,‘’),‘\r’,’ ‘),’\t’,’ ')