目录
序列介绍
列表
列表的创建
range()创建整数列表
推导式生成列表
列表对象常用方法汇总
列表元素的访问和计数
通过索引直接访问元素
成员资格判断
切片操作
列表遍历
列表相关的其他内置函数汇总
多维列表
二维列表
编辑
元组tuple
元组的创建
1.通过()创建元组,小括号可以省略
编辑
2.通过tuple()创建元组
元组的元素访问和计数
ZIP
生成器推导式创建元组
字典
字典的创建
2.通过zip()创建字典对象
字典元素的访问
字典元素添加、修改删除
序列解包
表格数据使用字典和列表存储,并实现访问
字典核心底层原理(非常重要)
集合
集合的创建和删除
集合相关操作
总结(列表、元组、字典、集合区别)
序列介绍
字符串、列表、元组、集合都是序列,序列是什么呢?序列是一种数据存储方式,用来存储一系列的数据。在内存中,序列就是一块用来存放多个值的连续的内存空间。比如说一个整数序列,[10,20,30,40],可以这样表示:
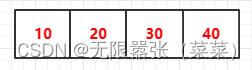
如下图理解,我们将 10、20、30、40每一个对象的地址分别存储到列表的内存,最后将整个列表的地址赋给变量a。也就是我们先通过变量a找到列表的地址,再通过索引找到列表元素的地址,再通过列表元素的地址找到对象。
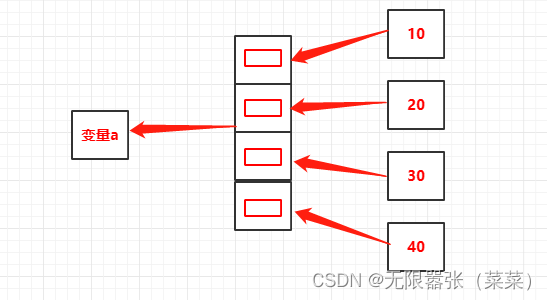
在序列中,存储的是对象的地址,而不是对象的值,上一篇博客我们着重对字符串进行介绍,接下来,我们将对列表、元组、集合进行介绍。
列表
列表可以用来存储任意数目、任意类型的数据集合,列表是内置可变序列,是包含多个元素的有序连续的内存空间。列表定义的标准语法格式如下:
a = [10,20,30,40]
其中10,20,30,40这些称为列表a的元素。而列表中的元素不要求类型相同,可以类型不同,比如:
a = [10,20,‘yyq’,True]
里边既可以有数字、也可以有字符串、还可以有布尔型。
列表的创建
基本语法[]创建
list = [1,2,'3',True,2,3];print(list)list()创建
使用list()可以将任何迭代的数据转化成列表。
a = list()print(a)b = list(range(10))print(b)# 将字符串转化为列表c = list('I Love you yyq')print(c)
range()创建整数列表
range()可以帮助我们非常方便的创建整数列表,这在开发中非常重要,语法格式如下:
range([start,end,step])
start参数:可选,表示起始数字,默认是0;
end参数:可选,表示结尾数字;
step参数:可选,表示步长,默认是1.
在Python3中range()返回的是一个range对象,而不是列表,我们需要通过list()方法将其转化成列表对象。
# range 产生的是整数a = list(range(2,10,3))print(a)b = list(range(-8,20,2))print(b)
如果倒序怎么办?我们将步长换成负数即可。
推导式生成列表
使用列表推导式,可以非常方便的创建列表,在开发中经常使用。他一般和控制语句结合使用。
a = [x*3 for x in range(8)]print(a)b = [x*3 for x in range(8) if x%2==0]print(b)
列表对象常用方法汇总
| 序号 | 方法 | 要点 | 描述 |
| 1 | list.append(x) | 增加元素 | 将元素x增加到列表的尾部 |
| 2 | list.extend(alist) | 增加元素 | 将列表alist的所有元素增加到列表尾部 |
| 3 | list.insert(index,x) | 增加元素 | 在列表list,指定位置index插入元素x |
| 4 | list.remove(x) | 删除元素 | 在列表list删除首次出现的指定元素x |
| 5 | list.pop([index]) | 删除元素 | 删除并返回列表list指定位置index处的元素,默认是最后一个元素,索引是从0开始的 |
| 6 | list.clear() | 删除所有元素 | 删除列表所有元素,并不是列表对象,此时对象的地址还存在 |
| 7 | list.index(x) | 访问元素 | 返回第一个x索引位置,若不存在x元素抛出异常 |
| 8 | list.count(x) | 计数 | 返回指定元素x在列表list出现的次数 |
| 9 | len(list) | 列表长度 | 返回列表中包含元素的个数 |
| 10 | list.reverse() | 翻转列表 | 所有元素原地翻转 |
| 11 | list.sort() | 排序 | 所有元素原地排序 |
| 12 | list.copy | 浅拷贝 | 所有列表对象的浅拷贝 |
示例说明:
1.将元素插入列表尾部
当列表增加和删除元素时,列表会自动进行内存管理,大大减少程序员的负担。但这个特点涉及列表元素的大量移动,效率低下,除非必要,否则我们只在列表尾部进行添加元素或者删除元素,这会大大提高列表的操作效率。而+运算符操作,并不是真正尾部添加元素,而是创建新的列表对象,将原列表元素和新列表元素依次复制到新的列表中,对于操作大量元素,不建议使用。
k = [1,2,'3',True];# 将'yyq'增加到列表的尾部k.append('yyq')c = k+['yyq']print(k,c)print(id(k),id(c))
2.将列表alist的所有元素插入列表list之后,在原地拼接,不涉及新的对象的创建。
list = [1,2,'3',True];alist = ['I','','','Love','','You','','yyq']# 将列表alist 的所有元素插入到list 列表之后list.extend(alist)print(list)
3.将列表list指定位置插入元素
使用insert()方法可以将指定的元素插入到列表对象的任意位置。这样会让插入位置后面所有的元素进行移动,会影响处理速度。涉及大量元素时,尽量避免使用,类似发生这种移动函数的还有:remove()、pop()、del(),他们在删除非尾部元素时也会发生操作位置后面元素的移动,也涉及到数组的移动与拷贝。
list = [1,2,'3',True];# 将列表list指定位置插入元素list.insert(2,False)print(list)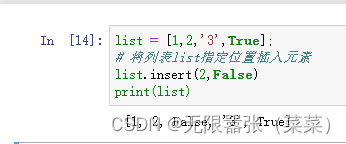
4.在列表list删除首次出现的指定元素x
list = [1,2,'3',True,2];# 在列表list删除首次出现的指定元素xlist.remove(2)print(list)
5.删除并返回列表list指定位置index处的元素,或者del list[2],默认是最后一个元素,索引是从0开始的.看似是元素的删除,实际里边涉及到数组的移动和拷贝。将字符’3’删除以后,将索引3位置移动到索引2位置,将索引4位置移动到索引3的位置。别的列表中间操作,同理。
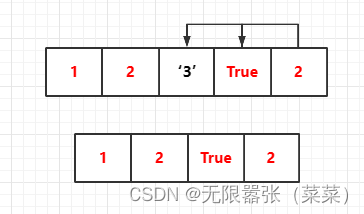
list = [1,2,'3',True,2];# 删除并返回列表list指定位置index处的元素list.pop(2)print(list)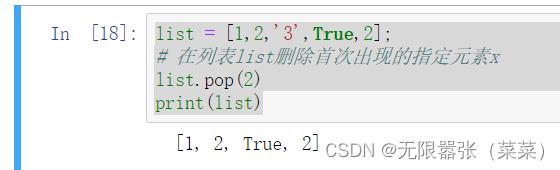
6.删除列表所有元素,并不是列表对象,此时对象的地址还存在
list = [1,2,'3',True,2];list.clear()print(list)print(id(list)) 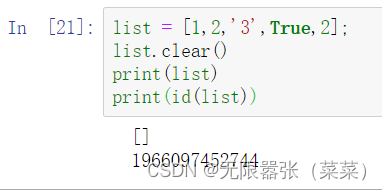
7.返回第一个x索引位置,若不存在x元素抛出异常
list = [1,2,'3',True,2];a = list.index(2)print(a) 
8.返回指定元素x在列表list出现的次数
list = [1,2,'3',True,2];a = list.count(2)print(a)
9. 返回列表中包含元素的个数
list = [1,2,'3',True,2];a = len(list)print(a) 
10.所有元素原地翻转,也就是前后顺序颠倒
list = [1,2,'3',True,2];list.reverse()print(list)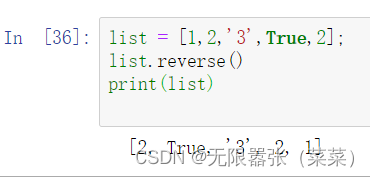
11.所有元素原地排序,必须都是数字,不需要创建新列表排序,列表中不能是字符串。
list = [1,2,5,6,100,0.1,6,2];list.sort()print(list)
注意:如果是降序排序,则为a.sort(reverse=True),我们也可以通过内置函数sorted()进行排序,这个方法是返回新的列表,不对原列表做修改。
12. 所有列表对象的浅拷贝
list = [1,2,'3',True,2,3];list.copy()print(list)
13.列表的乘法扩展
使用乘法扩展列表,生成一个新列表时,对原列表进行多次操作。
a = ['I',520]b = a*3;print(b)
根据上述示例可知:Python的列表大小可变,根据实际需要,可以调整列表的大小,字符串和列表都是序列类型,一个字符串是一个序列,一个列表是任何元素的序列,我上一篇博客https://blog.csdn.net/zywcxz/article/details/128317597详细介绍了字符串的应用详解,在列表中的应用几乎一模一样,有需要的小伙伴看一下。
列表元素的访问和计数
通过索引直接访问元素
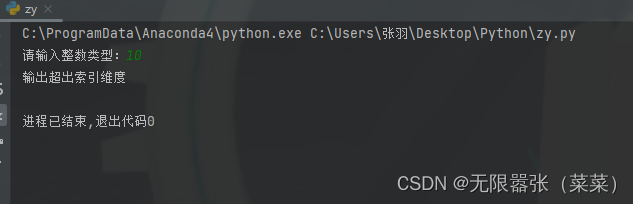
我们可以通过索引直接访问元素,索引的区间是[0,len(list)-1]这个范围,超出这个范围将会抛出异常。
a = list(x for x in range(10) if x % 3 == 0)b = len(a)m = input('请输入整数类型:')if int(m) > (b-1): print('输出超出索引维度')else: c = a[int(m)] print(a, b, c) 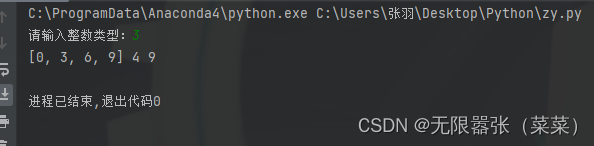
成员资格判断
判断列表中是否存在指定元素,我们可以用count()方法,返回0则表示不存在,返回大于0表示存在。但是,一般我们会使用更加简洁的in关键字来判断。直接返回True和False。
a = list(x for x in range(10) if x % 3 == 0 ) 20 in a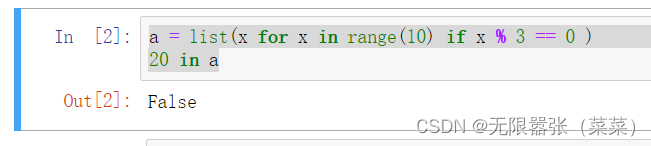
切片操作
切片是Python 序列及其重要的操作,适用于列表,元祖,字符串等等,按照索引查找。切片格式如下:
[起始偏移量start:终止偏移量:步长step]
b = list(n for n in range(100) if n%30 ==0)# 提取所有字符c = b[::]#从开始到结尾d = b[2::]#从开始到end-1e = b[0:3:]#从开始到结尾,步长为2f = b[0:3:2]print(b)print(c)print(d)print(e)print(f)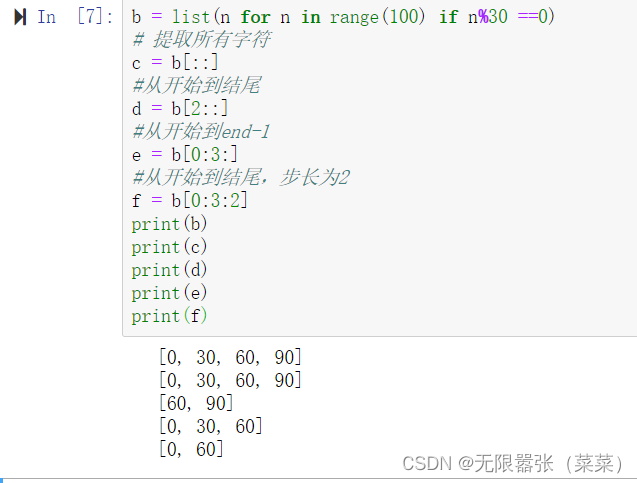
切片操作时,起始偏移和终止偏移量不在[0,字符串长度-1]这个范围,也不会报错。其实偏移量小于0则会当做0,终止偏移量大于len(list)-1,则会被当成len(list)-1,eg:
a = list(range(0,100,10))print(a)a[1:100]
列表遍历
格式如下:
for obj in list(Obj)
print(obj)
eg:
g = [0, 10, 20, 30, 40, 50, 60, 70, 80, 90]for x in g: print(x)
列表相关的其他内置函数汇总
1.max 和 min
用于返回列表中的最大值和最小值
a = list(x for x in range(100) if x % 10 == 0)b = min(a)c = max(a)print(a,b,c)
2.sum
对数值型列表的所有元素求和,对非数值型列表,会报错
a = list(x for x in range(100) if x % 10 == 0)b = sum(a)print(b)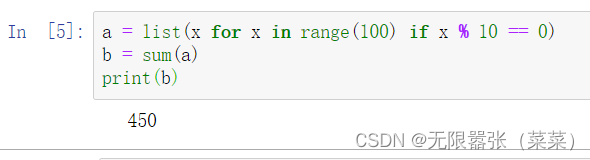
多维列表
二维列表
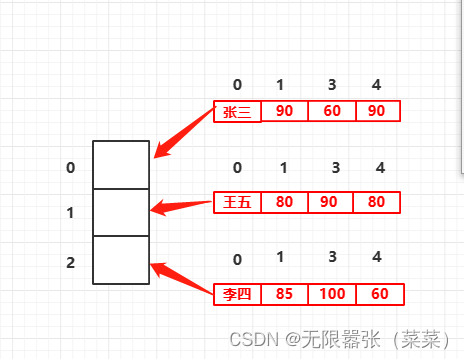
一维列表可以帮助我们存储一维,线性的数据,二维列表可以帮助我们存储二维,表格的数据。
| 姓名 | 语文成绩 | 数学成绩 | 英语成绩 |
| 张三 | 90 | 60 | 90 |
| 王五 | 80 | 90 | 80 |
| 李四 | 85 | 100 | 60 |
内存结构图如下:我们通过找到二维列表对象的索引找到里边的列表对象,再通过里边的列表对象索引找到最里边的元素,对其进行操作。
a=[ ['张三',90,60,90], ['王五',80,90,80], ['李四',85,100,60],]for m in range(3): # 行操作 for n in range(4): # 列操作 print(a[m][n],end='\t') print()# 打印完换行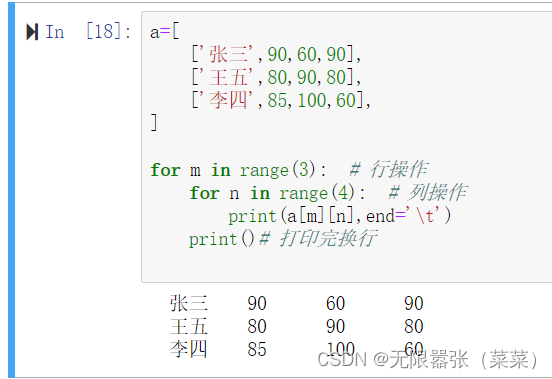
元组tuple
列表属于可变序列,可以任意修改列表中的元素,元组属于不可变序列,不能改变元组中的元素。因此元组没有增加元素、删除元素的相关方法。因此只需要学习元组的创建和删除,元组元素的访问计数即可。元组支持如下操作:1、索引访问 2、切片操作 3、连接操作 4、成员关系操作 5、比较运算操作 6、计数:元组长度len()、最大值max()、最小值min()、求和sum()等。
元组的创建
1.通过()创建元组,小括号可以省略
如果元组只有一个元素,则必须后面加逗号,这是因为解释器会把(1)解释为整数,而1,(1,)则解释我将会解释为元组。
c = (10,20,30)d = 10,10,30print(type(c),type(d))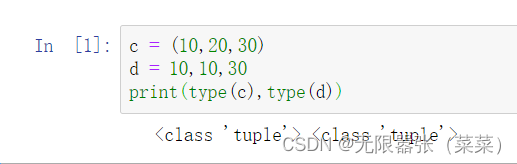
2.通过tuple()创建元组
tuple(可迭代的对象)
eg:
b = tuple() # 创建一个空元组对象c = tuple("abc")d = tuple(range(3))e = tuple([2,3,4])f = tuple(['1',2,3]) # 将列表转化为元组print(b,c,d,e,f)
总结:tuple() 可以接收列表、字符串、其他序列类型,迭代器等生成元组。
list()可以接收元组、字符串、其他序列类型、迭代器等生成列表。
元组的元素访问和计数
1.元组的元素不能修改
2.元组的元素访问和列表一样,只不过返回的仍然是元组
3.列表关于排序的方法list.sorted()是修改原列表对象,元组没有该方法,如果要对元组排序,只能使用内置函数sqrted(tupleObj),并生成新的列表对象。sorted生成的都是列表,不管你传的是列表还是元组。
ZIP
zip(列表1,列表2,...)将多个列表对应位置的元素组合为元组,并返回这个zip对象。
a = [10,20,30]b = [40,50,60]c = [70,80,90]d = zip(a,b,c)print(list(d))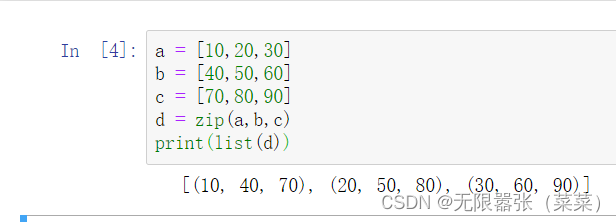
生成器推导式创建元组
从形式上看,生成器推导式与列表推导式类似,只是生成器推导式使用小括号,列表推导式生成列表对象,生成器推导式生成的不是列表也不是元组,而是一个生成器对象。我们可以通过生成器对象,转化成列表或者元组。也可以使用生成器对象的_next_()方法进行遍历,或者直接作为迭代器对象来使用。不管什么方式使用,元素访问结束后,如果需要重新访问其中的元素,必须重新创建该生成器对象,只能用一次。
s = (x*2 for x in range(5))print(tuple(s))print(tuple(s))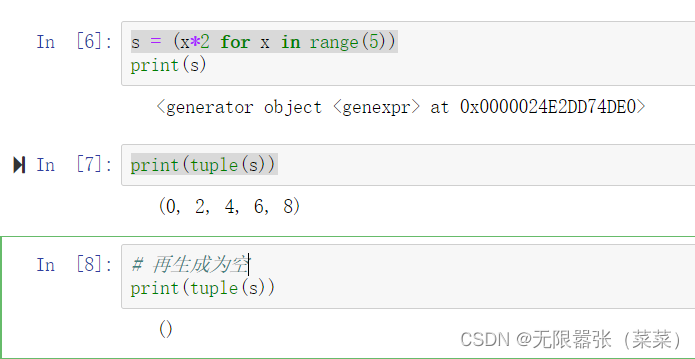
用s.__next__()指针来移动操作,根据序列去取值,指针以此后移
s = (x*2 for x in range(5))print(s.__next__())print(s.__next__())print(s.__next__())print(s.__next__())print(s.__next__())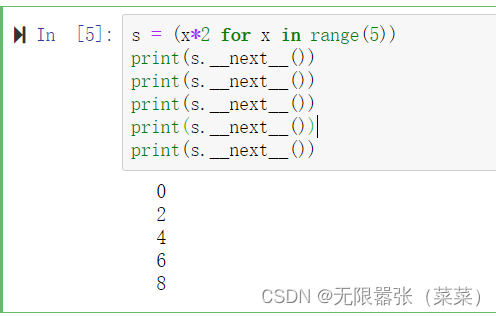
字典
字典是"键值对"的无序可变序列,键值对是成对存储的。通过对来操作值。来字典中每一个元素都是一个“键值对”,包含:"键对象”和值对象。可以通过“键对象”实现快速获取、删除、更新对象的“值对象”。
列表中我们通过“下标数字”找到对象。字典中通过“键对象”找到对应的值对象。“键”是任意的不可变数据,比如:整数、浮点数、字符串、元组。但是,列表、字典、集合这些可变对象,不能作为“键”。并且键不可重复。“值”可以是任意的数据,并且“键不可重复”。
字典的定义方式:
a = {'name':'gaoqi','age':18,'job':'programmer'}
其中有三个键值对,'name'、'age'、'job'是键,'gaoqi','18','programmer'是对.
其中我们传入 'name'这个键就可以找到'gaoqi'这个对。利用a.get(‘name’),我感觉和C语言结构体类似。
字典的创建
1.(1)我们可以通过{}(2)dict()来创建字典对象
(1)通过{}
a = {'name':'gaoqi','age':18,'job':'programmer'}a.get('name')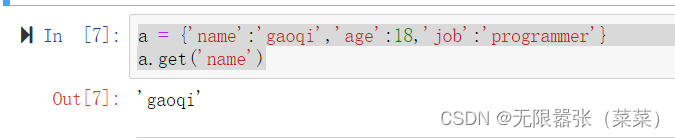
(2)dict()来创建字典对象
①注意,键不加字符号,且用的‘=’而不是冒号,注意区别
b = dict(姓名='小花',年龄=18,工作='村花')print(b)
②把键值和对放在一块,并且用[]表示,注意是,而不是:
b = dict([('姓名','小花'),('年龄',18),('工作','村花')])print(b)
2.通过zip()创建字典对象
k = ['姓名','年龄','工作']v = ['小花',18,'村花']m = dict(zip(k,v))print(m)
3.通过fromkeys创建值为空的字典,只有键没有值
a = dict.fromkeys(['姓名','年龄','工作'])print(a)
字典元素的访问
1.通过键获得“值”,若键不存在,则抛出异常。
k = ['姓名','年龄','工作']v = ['小花',18,'村花']m = dict(zip(k,v))print(m)m['姓名']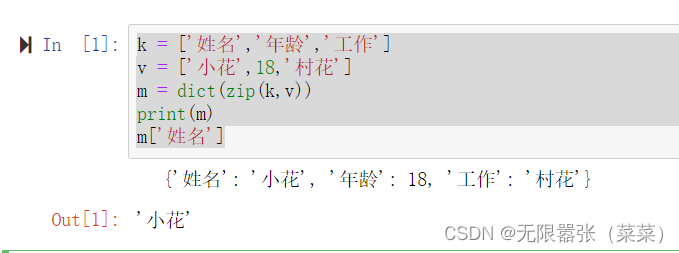
2.通过get()方法获得值,推荐使用。有点是:指定键不存在,返回None;也可以设定指定键不存在默认返回的对象。推荐使用get()获取值对象。
k = ['姓名','年龄','工作']v = ['小花',18,'村花']m = dict(zip(k,v))print(m)m.get('年龄')
3.列出所有的键值对,进行遍历,是一个列表,里边包含元组

4.列出所有的键a.keys(),列出所有的值a.value()
5.键值对的个数用len()函数查看
6.检测一个“键”是否在字典中,用 in
字典元素添加、修改删除
1.给字典新增“键值对”。如果“键已经存在”,则覆盖就得键值对;如果“键不存在”,则新增“键值对”。
k = ['姓名','年龄','工作']v = ['小花',18,'村花']m = dict(zip(k,v))print(m)m['地址']='女儿国'print(m)
2.使用update()将新字典中所有键值对全部添加到旧字典对象,如果key有重复直接覆盖。
3.字典元素中的删除,可以使用del方法;或者clear()删除所有的建值对;pop删除指定的键值对,并返回对应的‘值对象’。
k = ['姓名','年龄','工作']v = ['小花',18,'村花']m = dict(zip(k,v))o = ['姓名','属相','生日']p = ['小花','兔','5.21']r = dict(zip(o,p))print(m)del(m['姓名'])b = r.pop('属相')print(m)print(b)
4.popitem():随机删除和返回该键值对。字典是“无序可变序列”,因此没有第一个元素,最后一个元素的概念;popitem弹出随机项,因为字典并没有“最后元素”或者其他顺序的概念。若想一个接一个地移除,这个方法是非常有效的(因为不用首先获取键的列表)。
k = ['姓名','年龄','工作']v = ['小花',18,'村花']m = dict(zip(k,v))o = ['姓名','属相','生日']p = ['小花','兔','5.21']r = dict(zip(o,p))print(m)m.popitem()m.popitem()m.popitem()
序列解包
序列解包可以用于元组、列表、字典。序列解包可以让我们方便的对多个变量赋值。
x,y,z = (20,30,10)(x,y,z) = (20,30,10)[a,b,c] = [10,20,30]序列解包用于字典时,默认是对“键”进行操作;如果需要对键值对操作,则需要使用items(),如果需要对“值”进行操作,则需要使用values();方便对多个变量赋值。时
k = ['姓名','年龄','工作']v = ['小花',18,'村花']m = dict(zip(k,v))o = ['姓名','属相','生日']p = ['小花','兔','5.21']r = dict(zip(o,p))print(m)a,b,c = m #默认对键进行操作print(a,b,c)a,b,c = m.items() #对键值对进行操作print(a,b,c)a,b,c = m.values() #对值进行操作print(a,b,c)
表格数据使用字典和列表存储,并实现访问
在我们今后的学习中, 格
| 姓名 | 语文成绩 | 数学成绩 | 英语成绩 |
| 张三 | 90 | 60 | 90 |
| 王五 | 80 | 90 | 80 |
| 李四 | 85 | 100 | 60 |
a1 = {'姓名': '张三', '语文成绩': 90, '数学成绩': '60', '英语成绩': '90'}a2 = {'姓名': '王五', '语文成绩': 80, '数学成绩': '90', '英语成绩': '80'}a3 = {'姓名': '李四', '语文成绩': 85, '数学成绩': '100', '英语成绩': '60'}tb = [a1, a2, a3]# 获得语文成绩for i in range(len(tb)): print(tb[i].get('语文成绩'))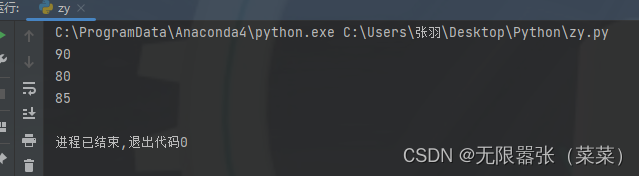
字典核心底层原理(非常重要)
字典对象的核心是散列表。散列表是一个稀疏数据(总是有空白元素的数组),数组的每个单元叫做bucket.每个bucket有两部分:一个是键对象的引用,一个是值对象的引用。由于,所有bucket结构和大小一致,我们通过偏移量来读取指定bucket.
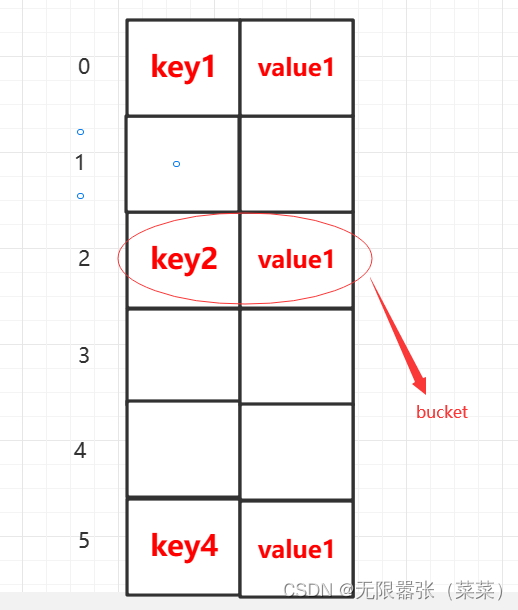
理解:key既可以数值也可以字符串,怎么把一个key值对应成一个索引值?分两个步骤:
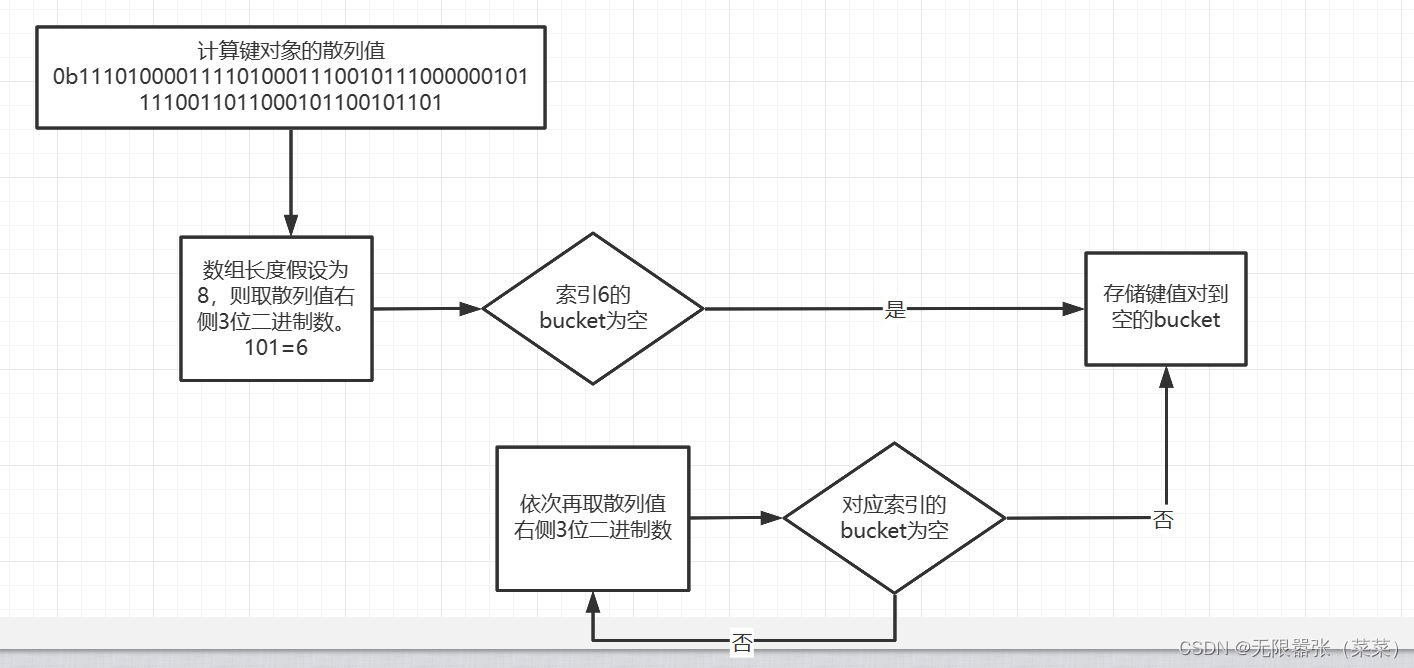
①将一个键值对放进字典的底层过程
a = {}a["name"] = "yyq"print(a)假设字典a对象创建完后,数组长度为8,我们如何把它变成0-7的数字索引,最后将他放进去呢?我们要把“name”=“yyq”这个键值对放进字典对象a中,首先第一步需要计算键“name”的散列值。Python中通过hash()来计算。
a = {}a["name"] = "yyq"print(bin(hash("name")))print(a)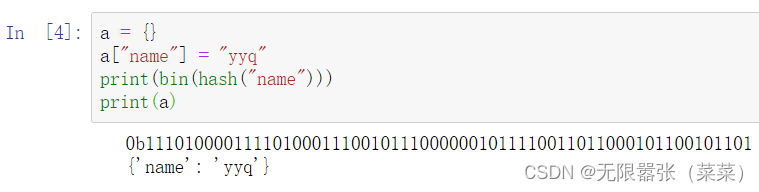
由于数组长度为8,我们可以拿计算出的散列值的最右边3位数字作为偏移量,即“101”,十进制是数字5。我们查看偏移量5,对应的bucket是否为空。如果为空,则将键值对放不进去。如果不为空,则依次取右边3位作为偏移量,即 "100",十进制是数字。如果都满了,数组将扩容。
再查看偏移量为4的bucket是否为空。直到找到为空的bucket将键值对放进去,流程图如下:
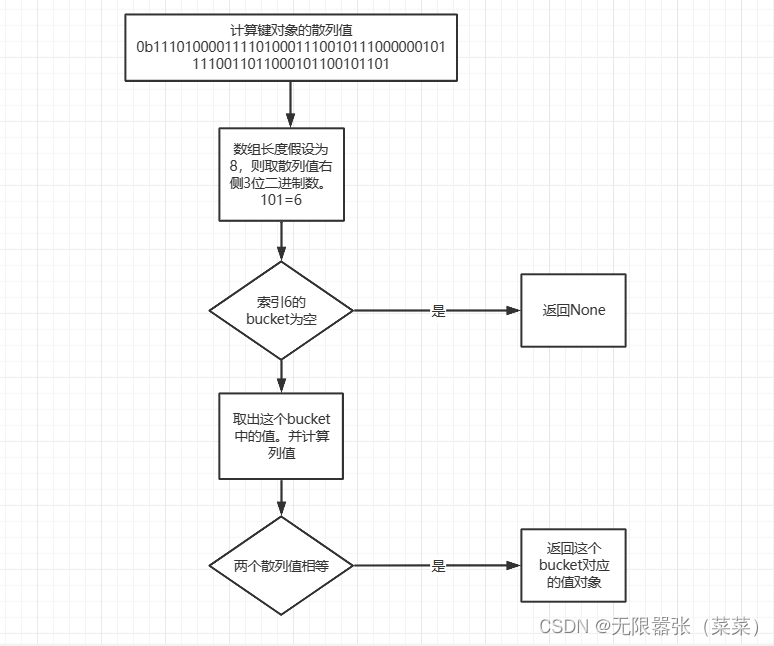
②根据键查找“键值对”的底层过程
和存储的底层流程算法一致,也是依次取散列值的不同位置的数字,假设数组长度为8,我们可以拿计算出的散列值的最右边3位数字作为偏移量,即“101”,十进制是数字5。我们查看偏移量5,对应的bucket是否为空。如果为空,则返回None。如果不为空,则将这个bucket的键对象计算对应的散列值,和我们的散列值进行比较,如果相等。则将对应的”值对象”返回。如果不相等,则依次取其他几位数字,重新计算偏移量。重新取完后仍然没有找到,则返回None,流程图如下:
字典用法总结:
1.键必须可散列
(1)数字、字符串、元组都是可散列。
(2)自定义对象需要支持下面三点:
①支持hash()函数
②支持通过_eq_()方法检测相等性
③若a == b为真,则has(a)==has(b)也为真
2.字典在内存中开销巨大,典型中的空间换时间。
3.键查询速度很快。
4.往字典里面添加新建可能导致扩容,导致散列表中键的次序变化。因此,不要在遍历字典的同时进行字典的修改。
集合
集合是无序可变,元素不能重复。实际上,集合底层是字典的实现,集合的所有元素都是字典中的“键对象”,因此不能重复的且唯一的。
集合的创建和删除
1.使用{}创建集合对象,并使用add()方法添加元素
a = {1,2,3}a.add(4)print(a)2.使用set(),将列表、元组等可迭代对象转成集合。如果原来数据存在重复数据,则只保留一个。
b = ['a','x','c']set(b)print(b)3.remove()删除指定元素;clear()清空整个集合。
c = ['a','x','c']c.remove('a')c.clear()print(c)集合相关操作
像数学中概念一样,Python对集合也提供了并集、交集、差集等运算,示例如下:
a = {1,3,'sxt'}b = {'he','it','sxt'}c = a|b # 并集d = a-b # 差集e = a&b # 交集f = a.union(b) # 并集g = a.difference(b) # 差集h = a.intersection(b) # 交集print(c,d,e,end = '\t')print(f,g,h,end = '\t')
总结(列表、元组、字典、集合区别)
1.列表与元组、字典、集合的区别
①列表与元组区别:列表内的值是可以修改的,元组不能修改;列表是可变类型而元组是不可变类型
②列表与字典区别:列表存储值,而字典存储键值对;列表是有序序列而字典是无序序列
③列表与集合区别: 列表是有序序列,集合是无序序列;列表内可以存储重复数据,集合内不能存储重复数据
2.元组与字典、集合的区别
①元组与字典区别:元组是不可变类型,字典式可变类型;元组是有序序列,字典是无序序列;元组值不可以更改,字典的值是可以更改的;
②元组与集合区别:元组是不可变类型,集合是可变类型,元组是有序序列,集合是无序序列;元组存储的值可以重复,集合存储的值不能重复
3.字典与集合区别
字典与集合区别:字典存储的值可重复,集合存储的值是不可重复;