文章目录
一、drop():删除指定行列1. 删除指定行2. 删除指定列 二、del():删除指定列三、isnull():判断是否为缺失1. 判断是否为缺失2. 判断哪些列存在缺失3. 统计缺失个数 四、notnull():判断是否不为缺失五、dropna():删除缺失值1. 导入数据2. 删除含有NaN值的所有行3. 删除含有NaN值的所有列4. 删除元素都是NaN值的行5. 删除元素都是NaN值的列6. 删除指定列中含有缺失的行 六. fillna():缺失值填充1. 导入数据2. 默认全部填充3. 用前一行的值填补空值4. 用后一列的值填补空值5. 设置填充个数 七、ffill():用前一个元素填充八、bfill():用后一个元素填充九、duplicated():判断序列元素是否重复十、drop_duplicates():删除重复行1. 判断所有列2. 按照指定列进行判断 十一、replace():替换元素1. 单个值替换2. 多个值替换一个值3. 多个值替换多个值4. 使用正则表达式: 十二、str.replace():替换元素十三、str.split.str():分割元素
一、drop():删除指定行列
drop()函数用于删除指定行,指定列,同时可以删除多行多列
语法格式:
DataFrame.drop( self, labels=None, axis: Axis = 0, index=None, columns=None, level: Level | None = None, inplace: bool = False, errors: str = "raise", )参数说明:
labels:要删除的行列的名字,接收列表参数,列表内有多个参数时表示删除多行或者多列axis:要删除的轴,与labels参数配合使用。默认为0,指删除行;axis=1,删除列index:直接指定要删除的行columns:直接指定要删除的列inplace:是否直接在原数据上进行删除操作,默认为False(删除操作不改变原数据),而是返回一个执行删除操作后的新dataframe;inplace=True,直接在原数据上修改。1. 删除指定行
当 axis=0 时,删除指定行
import numpy as npimport pandas as pddf_obj = pd.DataFrame({'data1': ['a', 'a', 'a', 'b', 'b', 'b', 'c', 'c'], 'data2': [1, 1, 2, 3, 4, 5, 5, 5]},index=list('abcdefgh'))print(df_obj)# 删除第一行df_obj.drop(labels='a', axis=0, inplace=True)print(df_obj)运行结果: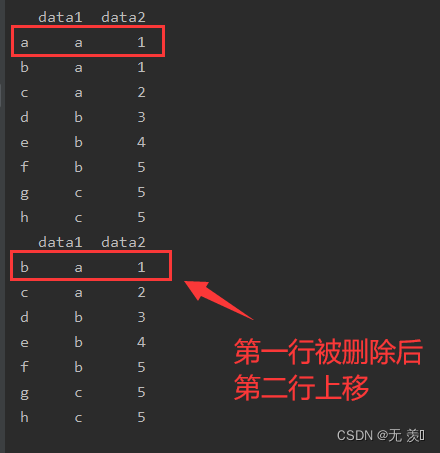
2. 删除指定列
当 axis=1 时,删除指定列
import numpy as npimport pandas as pddf_obj = pd.DataFrame({'data1': ['a', 'a', 'a', 'b', 'b', 'b', 'c', 'c'], 'data2': [1, 1, 2, 3, 4, 5, 5, 5]}, index=list('abcdefgh'))print(df_obj)# 删除data2 df_obj.drop(labels='data2', axis=1, inplace=True)print(df_obj)运行结果: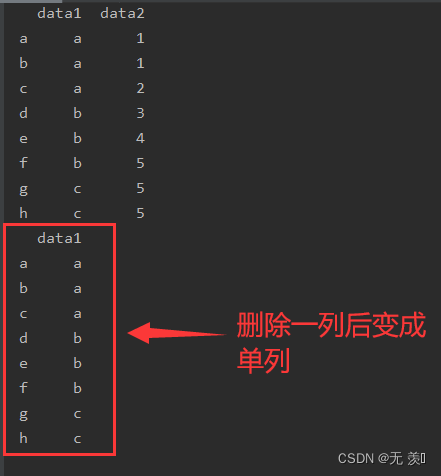
二、del():删除指定列
del()函数与drop()函数相比就没有那么灵活了,此操作会对原数据df进行删除,且一次只能删除一列。
语法格式:
del df[‘列名’]案例:
import numpy as npimport pandas as pddf_obj = pd.DataFrame({'data1': ['a', 'a', 'a', 'b', 'b', 'b', 'c', 'c'], 'data2': [1, 1, 2, 3, 4, 5, 5, 5]}, index=list('abcdefgh'))print(df_obj)# 删除data1del df_obj['data1']print(df_obj)运行结果: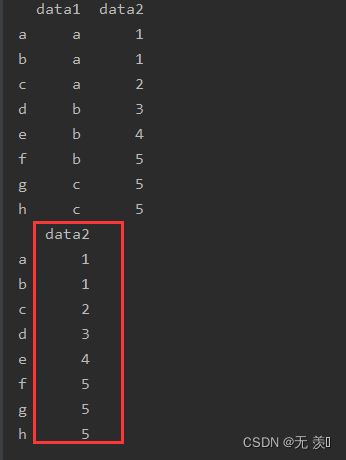
三、isnull():判断是否为缺失
判断序列元素是否为缺失(返回与序列长度一样的bool值)
1. 判断是否为缺失
示例代码:
import numpy as npimport pandas as pddf_obj = pd.DataFrame({'data1': ['a', 'a', 'b', 'b', 'c'], 'data2': [1, 2, 3, 4, 5], 'data3': np.NaN})print(df_obj)print(df_obj.isnull())运行结果: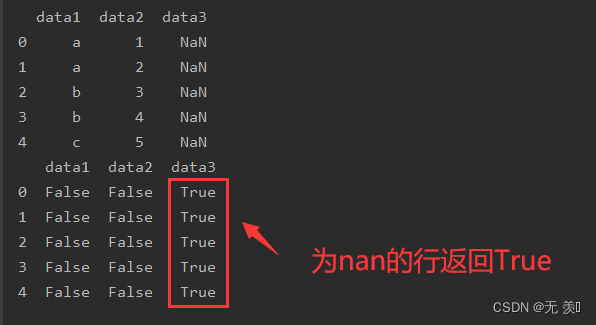
2. 判断哪些列存在缺失
isnull().any()会判断哪些”列”存在缺失值,数据清洗中经常用的小技巧
print(df_obj.isnull().any())运行结果: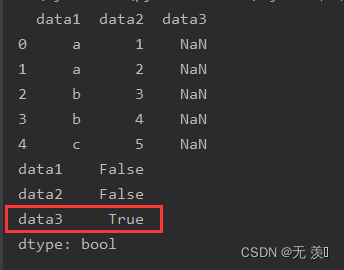
3. 统计缺失个数
isnull().sum()统计每一列的缺失个数
print(df_obj.isnull().sum())运行结果: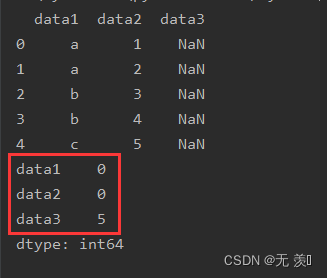
四、notnull():判断是否不为缺失
判断序列元素是否不为缺失(返回与序列长度一样的bool值),用法与isnull()相似
print(df_obj.notnull())运行结果: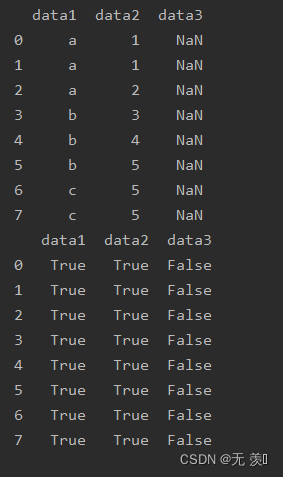
五、dropna():删除缺失值
dropna()函数可以删除缺失值
语法格式:
DataFrame.dropna( self, axis: Axis = 0, how: str = "any", thresh=None, subset=None, inplace: bool = False, )参数说明:
axis:移除行或列,默认为0,即行含有空值移除行how:‘all’所有值为空移除,'any’默认值,包含空值移除thresh:包含thresh个空值时移除subset:axis轴上,指定需要处理的标签名称列表inplace:是否替换原始数据,默认False1. 导入数据
import numpy as npimport pandas as pddf_obj = pd.DataFrame({'data1': ['a', 'a', np.NaN, 'b', 'c'], 'data2': [1, 2, np.NaN, 4, 5], 'data3': np.NaN, 'data4': [1, 2, 3, 4, 5]})print(df_obj)运行结果: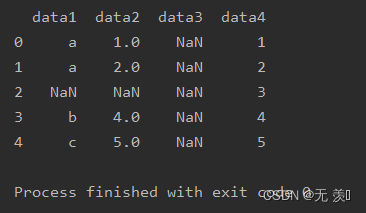
2. 删除含有NaN值的所有行
默认 axis=0
print(df_obj.dropna())运行结果: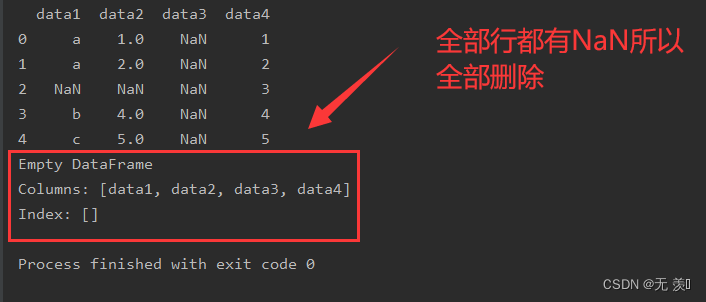
3. 删除含有NaN值的所有列
设置 axis=1 删除列
print(df_obj.dropna(axis=1))运行结果: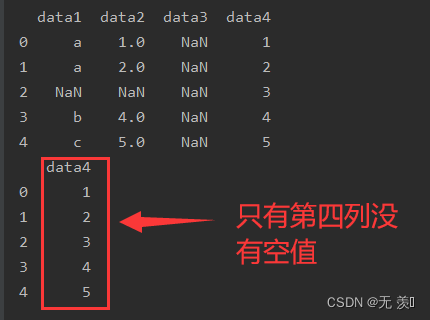
4. 删除元素都是NaN值的行
设置参数 how="all",只有行一整行数据都是NaN的时候才会删除
print(df_obj.dropna(axis=0,how="all"))运行结果:由于所有行都有至少有一个有效值,所有都没删除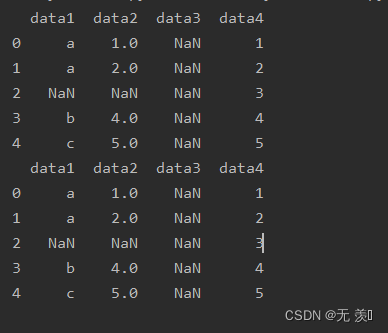
5. 删除元素都是NaN值的列
print(df_obj.dropna(axis=1,how="all"))运行结果:
6. 删除指定列中含有缺失的行
subset参数设置指定列
# 删除data1列有含有缺失的行print(df_obj.dropna(subset=["data1"], axis=0))运行结果: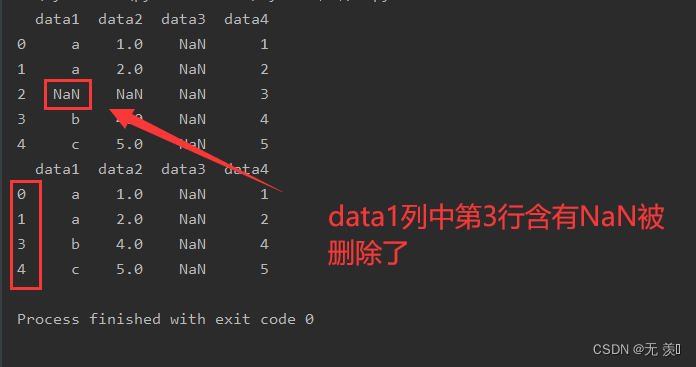
六. fillna():缺失值填充
缺失值填充
语法格式:
fillna( self, value: object | ArrayLike | None = None, method: FillnaOptions | None = None, axis: Axis | None = None, inplace: bool = False, limit=None, downcast=None, ) -> DataFrame | None参数说明:
value:用于填充的空值的值。
method: {‘backfill’, ‘bfill’, ‘pad’, ‘ffill’, None}, default None。定义了填充空值的方法, pad / ffill表示用前面行/列的值,填充当前行/列的空值, backfill / bfill表示用后面行/列的值,填充当前行/列的空值。
axis:选择轴,默认0(行),axis=1:列
inplace:是否替换原始数据
limit:int, default None。如果method被指定,对于连续的空值,这段连续区域,最多填充前 limit 个空值(如果存在多段连续区域,每段最多填充前 limit 个空值)。如果method未被指定, 在该axis下,最多填充前 limit 个空值(不论空值连续区间是否间断)
downcast:dict, default is None,字典中的项为,为类型向下转换规则。或者为字符串“infer”,此时会在合适的等价类型之间进行向下转换,比如float64 to int64 if possible。
1. 导入数据
import numpy as npimport pandas as pddf_obj = pd.DataFrame({'data1': ['a', 'a', np.NaN, 'b', 'c'], 'data2': [1, 2, np.NaN, 4, 5], 'data3': np.NaN, 'data4': [1, 2, 3, 4, 5]})print(df_obj)运行结果: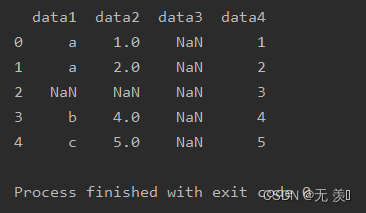
2. 默认全部填充
# 用0填补空值print(df_obj.fillna(value=0))运行结果: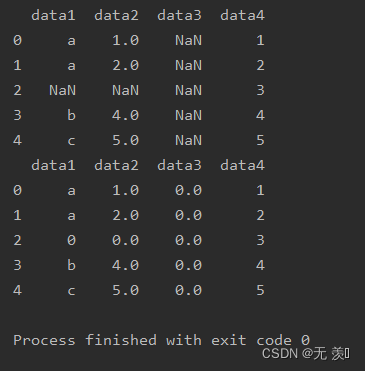
3. 用前一行的值填补空值
设置参数 method='pad' 用前一行的值填补空值
# 用前一行填充print(df_obj.fillna(method='pad',axis=0))运行结果: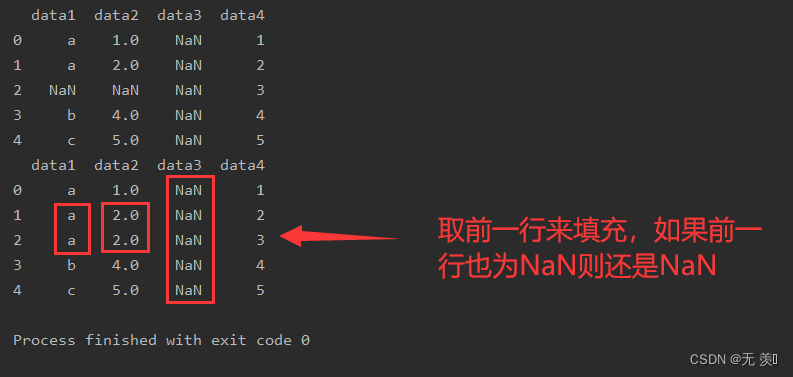
4. 用后一列的值填补空值
设置参数 method='backfill'
# 用后一列的值填补空值print(df_obj.fillna(method='backfill', axis=1))运行结果: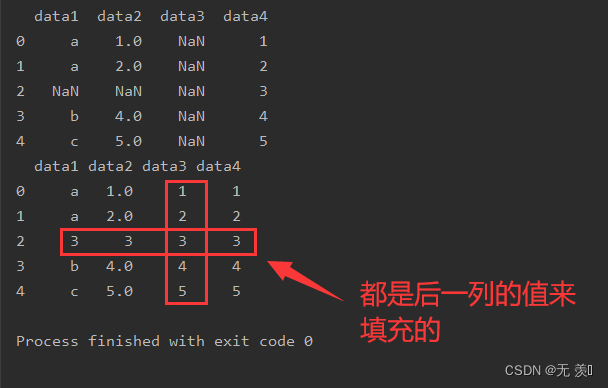
5. 设置填充个数
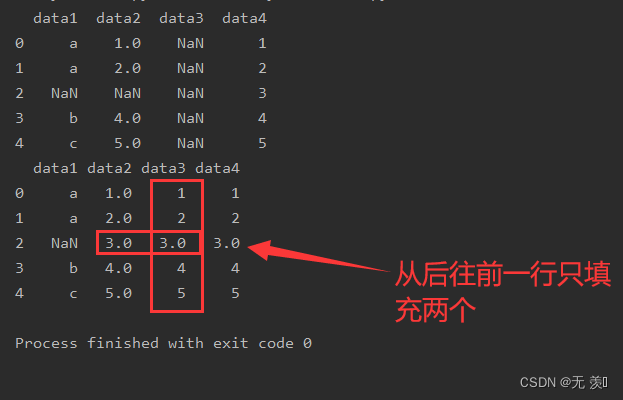
limit=数字,设置填充个数
# 用后一列的值填补空值,只填充两个print(df_obj.fillna(method='backfill', axis=1, limit=2))运行结果:
七、ffill():用前一个元素填充
前向后填充缺失值,用缺失值的前一个元素填充,与fillna()相比没有那么多可选性
语法格式:
ffill( self: DataFrame, axis: None | Axis = None, inplace: bool = False, limit: None | int = None, downcast=None, ) -> DataFrame | None案例说明:
import numpy as npimport pandas as pddf_obj = pd.DataFrame({'data1': ['a', 'a', 'a', 'b', 'b', 'b', 'c', 'c'], 'data2': [1, 1, 2, 3, np.NaN, 5, 5, np.NaN]})print(df_obj)print(df_obj.ffill())运行结果: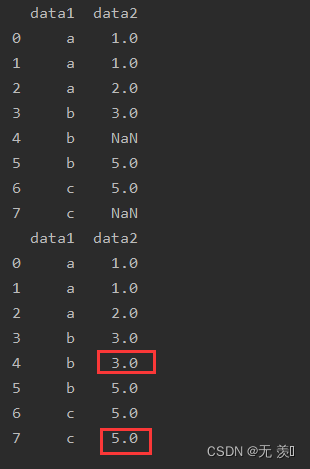
八、bfill():用后一个元素填充
后向填充缺失值,用缺失值的后一个元素填充
import numpy as npimport pandas as pddf_obj = pd.DataFrame({'data1': ['a', 'a', 'a', 'b', 'b', 'b', 'c', 'c'], 'data2': [1, 1, 2, 3, np.NaN, 5, 5, np.NaN]})print(df_obj)print(df_obj.bfill())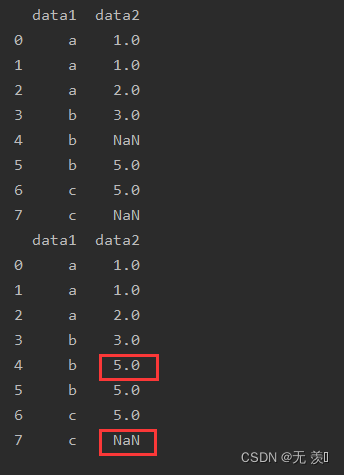
九、duplicated():判断序列元素是否重复
判断序列元素是否重复
语法格式:
DataFrame.duplicated(subset=None,keep='first')参数说明:
subset:列标签,可选, 默认使用所有列,只考虑某些列来识别重复项传入列标签或者列标签的序列
keep:{‘first’,‘last’,False},默认’first’
first:删除第一次出现的重复项。
last:删除重复项,除了最后一次出现。
false:删除所有重复项
返回布尔型Series表示每行是否为重复行
示例代码:
import numpy as npimport pandas as pddf_obj = pd.DataFrame({'data1': ['a', 'a', 'a', 'b', 'b', 'b', 'c', 'c'], 'data2': [1, 1, 2, 3, 4, 5, 5, 5]})print(df_obj)print(df_obj.duplicated())运行结果: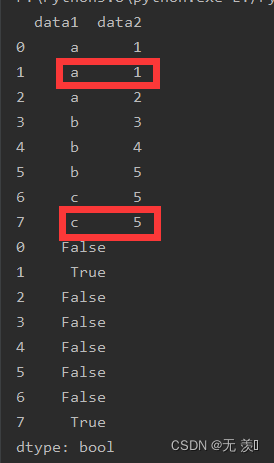
十、drop_duplicates():删除重复行
删除重复行,默认判断全部列,可指定按某些列判断
语法格式:
DataFrame.drop_duplicates( self, subset: Hashable | Sequence[Hashable] | None = None, keep: Literal["first"] | Literal["last"] | Literal[False] = "first", inplace: bool = False, ignore_index: bool = False, ) -> DataFrame | None参数说明:
subset:列标签,可选, 默认使用所有列,只考虑某些列来识别重复项传入列标签或者列标签的序列
keep:{‘first’,‘last’,False},默认’first’
first:删除第一次出现的重复项。
last:删除重复项,除了最后一次出现。
false:删除所有重复项
inplace:是否替换原数据,默认是False,生成新的对象,可以复制到新的DataFrame
ignore_index:bool,默认为False,如果为True,则生成的轴将标记为0,1,…,n-1。
1. 判断所有列
import numpy as npimport pandas as pddf_obj = pd.DataFrame({'data1': ['a', 'a', 'a', 'b', 'b', 'b', 'c', 'c'], 'data2': [1, 1, 2, 3, 4, 5, 5, 5]})print(df_obj)print(df_obj.drop_duplicates())运行结果: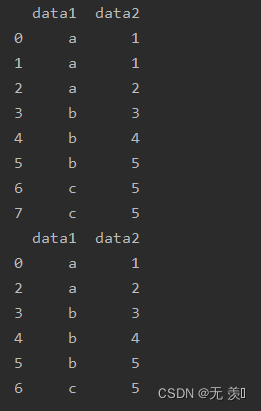
2. 按照指定列进行判断
print(df_obj.drop_duplicates('data2'))运行结果: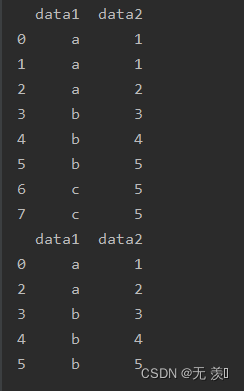
十一、replace():替换元素
替换元素,可以使用正则表达式
语法格式:
replace( self, to_replace=None, value=None, inplace: bool = False, limit=None, regex: bool = False, method: str = "pad", )参数说明:
to_replace: 需要替换的值
value:替换后的值
inplace: 是否在原数据表上更改,默认 inplace=False
limit:向前或向后填充的最大尺寸间隙,用于填充缺失值
regex: 是否模糊查询,用于正则表达式查找,默认 regex=False
method: 填充方式,用于填充缺失值
pad: 向前填充ffill: 向前填充bfill: 向后填充1. 单个值替换
to_replace接收字符串
import numpy as npimport pandas as pddf_obj = pd.DataFrame({'data1': ['a', 'a', 'a', 'b', 'b', 'b', 'c', 'c'], 'data2': [1, 1, 2, 3, np.NaN, 5, 5, np.NaN]})print(df_obj)print(df_obj.replace('a',"A"))运行结果: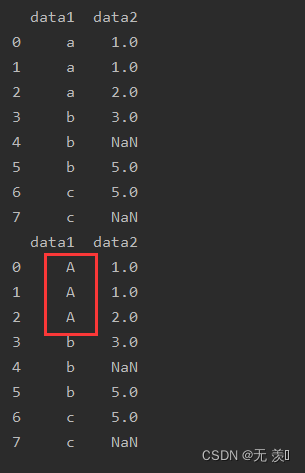
2. 多个值替换一个值
to_replace接收列表
print(df_obj.replace([1, 2], -100))运行结果: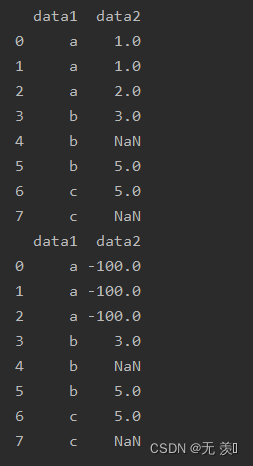
3. 多个值替换多个值
to_replace接收列表,value接收列表
print(df_obj.replace([1, 2], [-100, -200]))运行结果: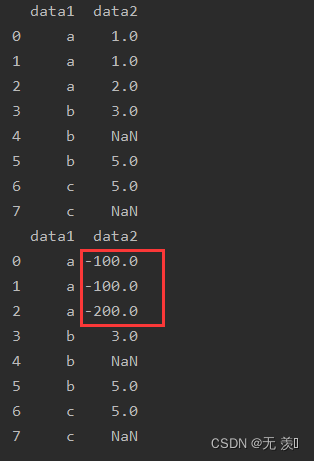
4. 使用正则表达式:
to_replace接收正则语法,设置 regex=True
import numpy as npimport pandas as pddf_obj = pd.DataFrame({'data1': ['ab', 'abc', 'aaa', 'b', 'b', 'b', 'c', 'c'], 'data2': [1, 1, 2, 3, np.NaN, 5, 5, np.NaN]})print(df_obj)# 替换a开头的print(df_obj.replace('a.?',"A",regex=True))运行结果: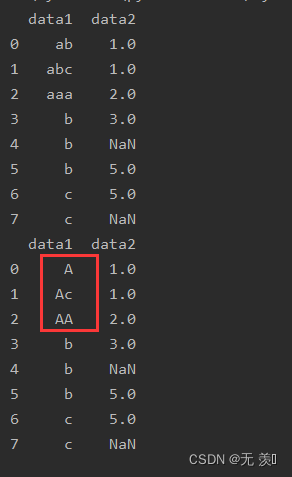
十二、str.replace():替换元素
替换元素,可使用正则表达式
import numpy as npimport pandas as pds = pd.Series(['foo', 'fuz', np.nan])print(s)print(s.str.replace('f.', 'ba', regex=True))运行结果:
十三、str.split.str():分割元素
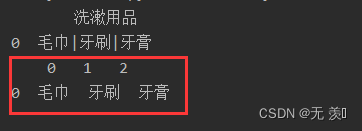
以指定字符切割列
import numpy as npimport pandas as pddata = {'洗漱用品':['毛巾|牙刷|牙膏']}df = pd.DataFrame(data)print(df)print(df['洗漱用品'].str.split('|',expand=True))运行结果: