
目录
一、缓冲区
1、缓冲区的概念
2、缓冲区的意义
3、缓冲区刷新策略
4、同一份代码,打印结果不同
5、仿写FILE
5.1myFILE.h
5.2myFILE.c
5.3main.c
6、内核缓冲区
二、了解磁盘
1、磁盘的物理结构
2、磁盘的存储结构
2.1磁盘的定位
3、磁盘的抽象存储结构
3.1为什么操作系统要将CHS抽象为LBA地址?
3.2大小为4KB的页框和页帧
4、磁盘的文件系统
4.1ext文件系统
4.2在文件系统中查找对应文件
4.3在文件系统中删除对应文件
4.4目录的内容和属性
三、软硬链接
1、软链接
1.1建立/删除软链接
1.2软链接的应用
2、硬链接
2.1建立/删除硬链接
2.2硬链接的应用
四、文件的三个时间
五、动静态库
1、静态库的制作
1.1静态库的生成
1.2将静态库和头文件合并
1.3用户如何使用静态库
2、动态库的制作
2.1动态库的生成
2.2将动态库和头文件合并
2.3用户如何使用动态库
2.4动态库的优缺点
3、动静态库的总结
一、缓冲区
1、缓冲区的概念
缓冲区的本质就是一段用作缓存的内存。
2、缓冲区的意义
节省进程进行数据IO的时间。进程使用fwrite等函数把数据拷贝到缓冲区或者外设中。
3、缓冲区刷新策略
1、立即刷新(无缓冲)——ffush()
情况很少,比如调用printf后,手动调用fflush刷新缓冲区。
2、行刷新(行缓冲)——显示器
显示器需要满足人的阅读习惯,故采用行刷新的策略而不是全缓冲的策略。
虽然全缓冲的刷新方式,可以大大降低数据IO的次数,节省时间。但若数据暂存于缓冲区,等缓冲区满后再刷出,当人阅读时面对屏幕中出现的一大堆数据,很难不懵逼。所以显示器采用行刷新的策略,既保证了人的阅读习惯,又使得数据IO效率不至于太低。
3、缓冲区满后刷新(全缓冲)——磁盘文件
4、特殊的刷新情况
用户强制刷新或进程退出。
4、同一份代码,打印结果不同
#include <stdio.h>#include <unistd.h>#include <sys/types.h>#include <sys/stat.h>#include <string.h>int main(){ printf("hello printf\n");//先打印至stdout缓冲区中 fprintf(stdout,"hello fprintf\n"); fputs("hello fputs\n",stdout); const char* msg="hello write\n"; write(1,msg,strlen(msg)); fork();//生成子进程 return 0;}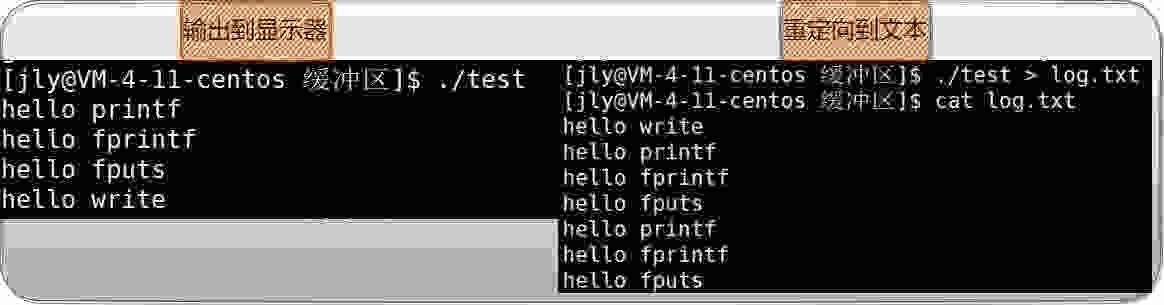
运行上方代码生成的可执行文件,在显示器上是正常打印,但是将运行结果重定向至文本,会发现C接口的打印函数打印了两次。
这个现象和缓冲区有关,从侧面说明了缓冲区并不存在内核中,否则write也会打印两次。用户级语言层面提供的缓冲区在FILE*指向的stdin/stdout/stderr中,FILE结构体会包含fd和缓冲区。需要强制刷新时,调用fflush(FILE*);关闭文件时,调用fclose(FILE*)。参数为FILE*就是为了刷新FILE*指向的FILE结构体中的缓冲区。
上方代码现象的解释:
1、stdout默认采用行刷新策略,每条打印函数都带了'\n',所以在fork之前,数据已经全部被打印到了显示器,缓冲区被并没有数据,当代码运行到fork创建子进程时,子进程对应的缓冲区当然也是没有任何数据。
2、当写入的是磁盘文件时,采用的是全缓冲的刷新策略,程序运行到fork时,缓冲区并没有被写满,数据仍存在于缓冲区中,当然被创建的子进程也拷贝了一份缓冲区的数据,当父子进程退出时,父子进程缓冲区中的数据将被刷新。所以出现了C接口函数被打印了两份的现象。
3、上面的过程与系统调用write无关,write没有FILE,使用的是fd,当然就没有C提供的缓冲区。
5、仿写FILE
5.1myFILE.h
#pragma once#include <sys/types.h>#include <unistd.h>#include <sys/stat.h>#include <fcntl.h>#include <string.h>#include <errno.h>#include <stdlib.h>#include <assert.h>#define SIZE 1024//1,2,4二进制1的位置不一样#define SYNC_NOW 1//立即刷新#define SYNC_LINE 2//行刷新#define SYNC_FULL 4//全刷新typedef struct _FILE{ int flags;//刷新方式 int fileno;//文件描述符 int cap;//buffer总容量 int size;//buffer当前使用量 char buffer[];//缓冲区}FILE_;FILE_* fopen_(const char* path_name,const char* mode);void fwrite_(const void* ptr,int num,FILE_* fp);void fclose_(FILE_* fp);void fflush_(FILE_* fp);5.2myFILE.c
#include "myStdio.h"FILE_* fopen_(const char* path_name,const char* mode){ int flags=0;//文件打开方式 int defaultMode=0666;//权限 if(strcmp(mode,"r")==0) { flags|=O_RDONLY; } else if(strcmp(mode,"w")==0) { flags|=(O_WRONLY|O_CREAT|O_TRUNC); } else if(strcmp(mode,"a")==0) { flags|=(O_WRONLY|O_CREAT|O_APPEND); } else {} int fd=0; if(flags&O_RDONLY) fd=open(path_name,flags); else fd=open(path_name,flags,defaultMode); if(fd<0)//打开失败 { const char* err=strerror(errno);//获取错误 write(2,err,strlen(err)); return NULL;//打开文件失败返回NULL的原因 } FILE_* fp=(FILE_*)malloc(sizeof(FILE_)); assert(fp); fp->flags=SYNC_LINE;//默认设置为行刷新 fp->fileno=fd; fp->cap=SIZE; fp->size=0; memset(fp->buffer,0,SIZE); return fp;//打开文件返回FILE*的指针}void fwrite_(const void* ptr,int num,FILE_* fp)//把数据写到缓冲区{ memcpy(fp->buffer+fp->size,ptr,num);//不考虑缓冲区满的情况 fp->size+=num; // 判断是否刷新 if(fp->flags&SYNC_NOW) { write(fp->fileno,fp->buffer,fp->size); fp->size=0;//清空缓冲区 } else if(fp->flags&SYNC_FULL) { if(fp->size==fp->cap) { write(fp->fileno,fp->buffer,fp->size); fp->size=0; } } else if(fp->flags&SYNC_LINE) { if(fp->buffer[fp->size-1]=='\n') { write(fp->fileno,fp->buffer,fp->size); fp->size=0; } }}void fflush_(FILE_* fp){ if(fp->size>0) { write(fp->fileno,fp->buffer,fp->size); fsync(fileno);//将数据强制刷新至磁盘 }}void fclose_(FILE_* fp)//关闭文件{ fflush_(fp);//刷新文件 close(fp->fileno);}5.3main.c
#include "myStdio.h"#include <stdio.h>int main(){ FILE_ *fp = fopen_("./log.txt", "w"); if(fp == NULL) { return 1; } int cnt = 10; const char *msg = "hello bit ";//const char *msg = "hello bit\n";//log中刷新的策略不一样 while(1) { fwrite_(msg, strlen(msg), fp); //fflush_(fp);//这样没带\n也刷 sleep(1); printf("count: %d\n", cnt); //if(cnt == 5) fflush_(fp); cnt--; if(cnt == 0) break; } fclose_(fp); return 0;}main.c中msg指向的字符串有无\n,这个程序对应的刷新策略不同。
用户级缓冲区存在于FILE结构体中。
6、内核缓冲区
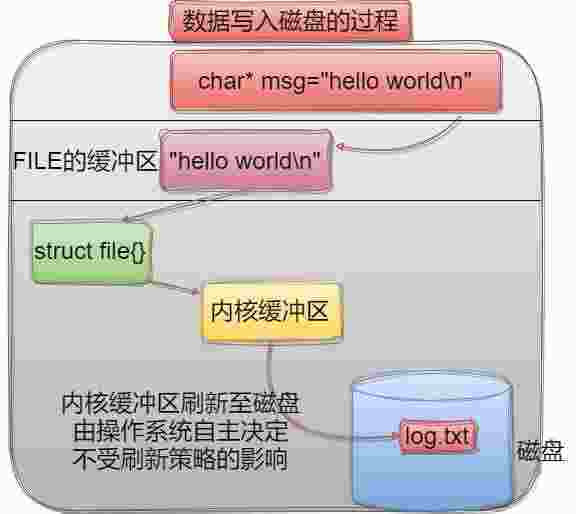
数据写入磁盘,完整的过程是先写入FILE结构体中的缓冲区,这个缓冲区的缓冲策略是立即缓冲、行缓冲、全缓冲;再通过struct file{}结构体将数据刷新至内核缓冲区;但是内核缓冲区的刷新并不遵循用户级的刷新策略,由操作系统自主决定,例如内存不足等原因均会影响操作系统的刷新。
如果操作系统突然挂了,那么内核缓冲区中的数据将会丢失。但如果是银行这种对数据安全敏感的行业呢?
#include <unistd.h>int fsync(int fd);使用fsync强制操作系统将内核缓冲区中该文件的数据立即刷新至存储设备。
二、了解磁盘
1、磁盘的物理结构
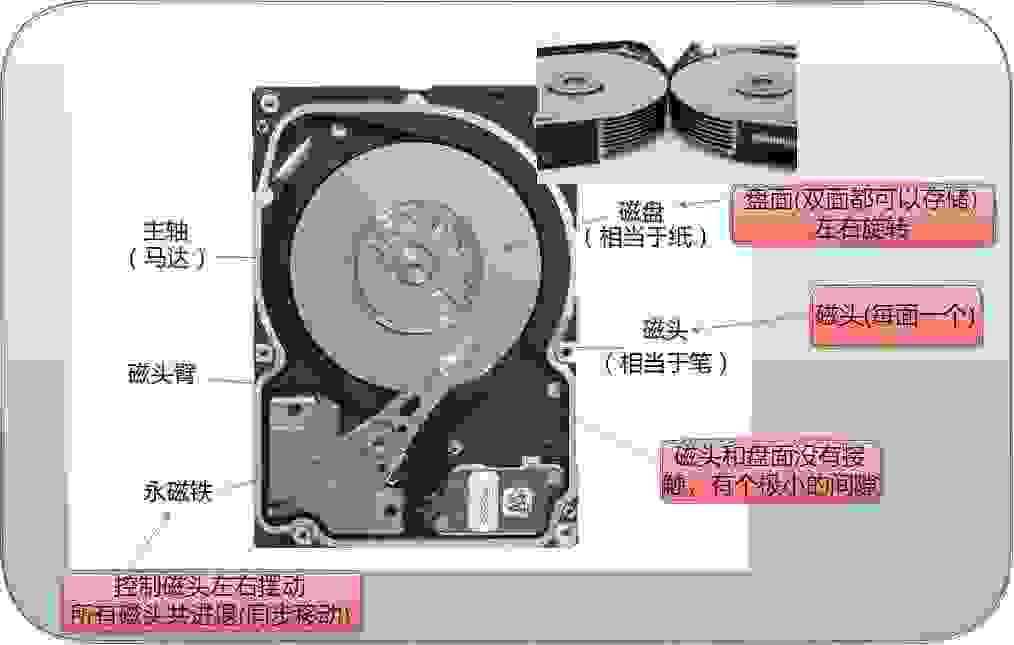
磁盘是计算机中唯一一个机械结构并且是一个外设,相对于其他存储设备来说较慢。但是价格低廉、存储量大,成为了企业存储设备的首选。磁盘磁头和盘面之间的距离极近,不能进灰尘,使用时禁止搬移抖动刮花盘面,造成数据丢失。
磁盘通过磁头充放电,完成盘面南北极的调转,即二进制数据的写入。
2、磁盘的存储结构
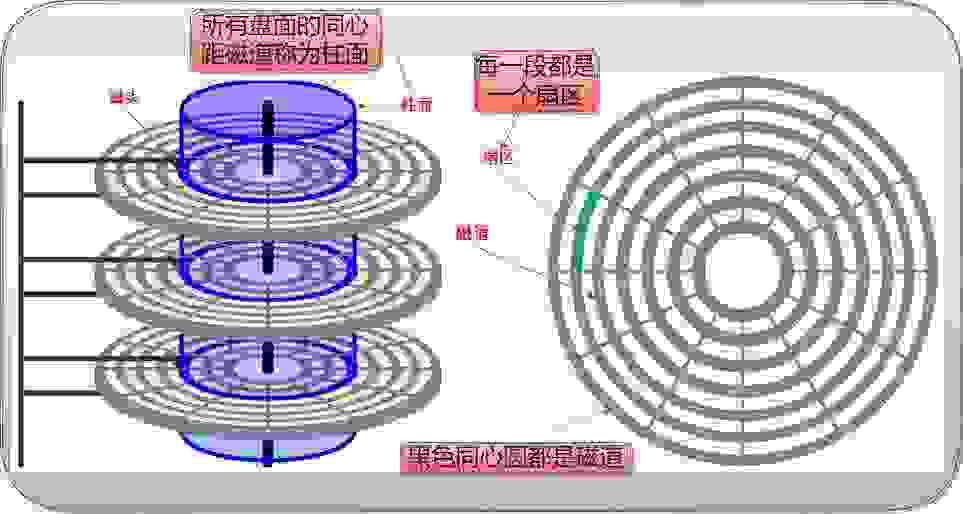
磁盘在寻址的时候,基本单位是扇区(512字节)。如图所示,绿色部分就是扇区,越靠近同心圆的扇区面积越小,越远离扇区的同心圆面积越大,但是每一个扇区的存储大小均为512字节。
2.1磁盘的定位
如何在盘面上定位扇区:通过磁头摆动确认在哪个磁道,通过盘片高速旋转让磁头定位扇区。(磁盘厂家会让磁盘转速与磁头寻址速度匹配,所以盘片旋转速度越快,该磁盘的IO效率越高。)
磁盘的所有磁头是共进退的,那么如何在磁盘中定位扇区:磁盘中定位一个扇区,硬件的定位方法采用CHS的定位法。1、先定位磁道(cylinder)(柱面)2、定位磁头(head)(即盘面)3、定位扇区(sector)。
3、磁盘的抽象存储结构
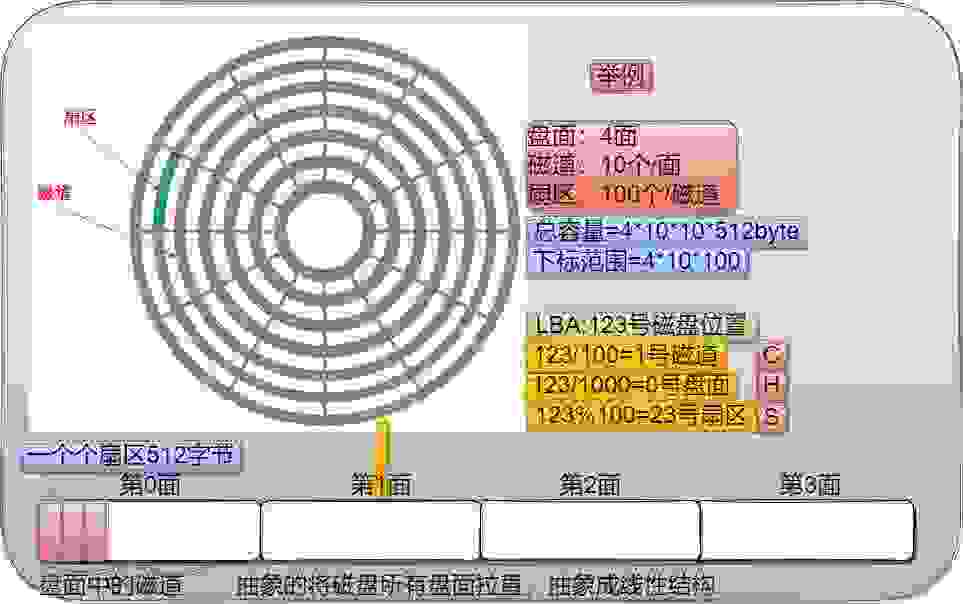
将一摞磁盘沿磁道“拉直”,就抽象成了线性结构。那么整个磁盘可以看做一个sector arr[n]数组,对磁盘数据的管理就变成了对数组的管理。只要知道了扇区的下标,就可以定位扇区。这个下标在操作系统内部称为LBA地址。根据LBA地址可以转化为CHS地址,从而找到对应扇区。
3.1为什么操作系统要将CHS抽象为LBA地址?
1、便于操作系统管理磁盘;
2、不想让操作系统的代码和硬件强耦合,硬件的变化并不会影响操作系统;
3.2大小为4KB的页框和页帧
虽然磁盘的最小单位是扇区512字节,但是太小了,操作系统的文件系统每次读取数据会以1KB、2KB、4KB为基本单位(大部分是4KB)读取至内存,哪怕用户只需要读取/修改1bit数据。这个特点也印证了顺序表缓存命中率高的优点,而链表由于节点存储地址跳跃,缓存命中率低。
以4KB为基本单位进行IO时,有时4KB数据并不能完全被利用,但这并不代表着浪费。根据局部性原理,当计算机访问某些数据时,它附近的数据也有非常大的概率被访问到,加载4KB有助于提高IO效率,同时增大缓存命中率。本质上就是一种数据预加载,以空间换时间的做法。
操作系统中内存被划分成了一块块4KB大小的空间,每个空间被称为页框。
磁盘中的文件尤其是可执行文件,也是按照4KB大小划分好的块。每个块被称为页帧。
4、磁盘的文件系统
磁盘采用分而治之的思想,例如一块500G的磁盘可以划分成4个125G进行管理,每个125G又可以分为多个5G进行管理·····
4.1ext文件系统
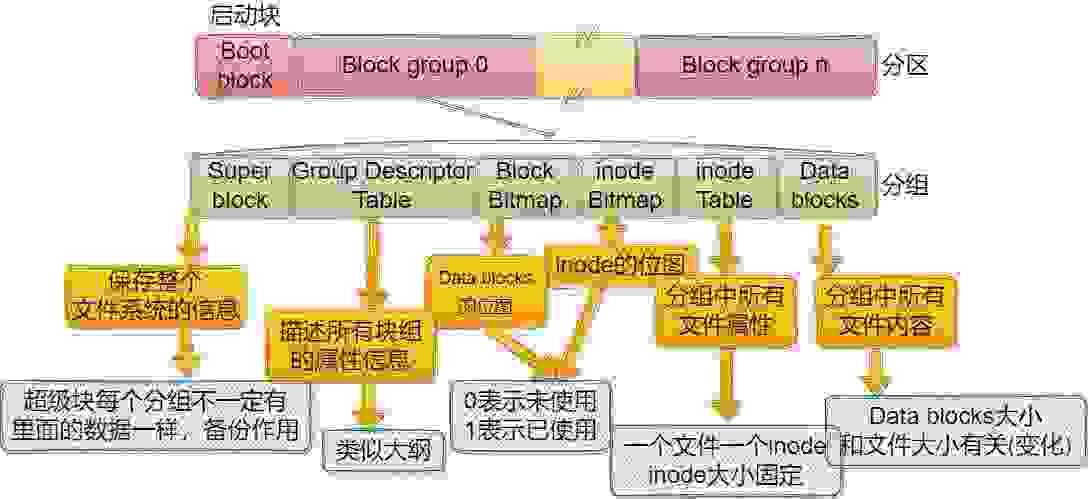
1、Super Block:存放文件系统本身的结构信息。记录的信息主要有:bolck 和 inode的总量,未使用的block和inode的数量,一个block和inode的大小,最近一次挂载的时间,最近一次写入数据的时间,最近一次检验磁盘的时间等其他文件系统的相关信息。在一个分区中超级块的数量不止一个,作用是备份。
2、GDT(Group Descriptor Table):块组描述表,描述所有块组属性信息;
3、Block Bitmap:用0表示某位没有被使用,用1表示某位数据块已经被使用。
4、inode Bitmap:用0表示某位没有被使用,用1表示某位inode已经被使用。
5、inode Table:保存了分组内部所有的可用(已使用+未使用)的inode。如果inode表中有100个inode,每个inode的大小是128字节或256字节(根据文件系统的不同Inode大小不同),inode表总大小就是100*128或100*256字节。单个inode:存放文件中几乎所有的属性,如文件大小,所有者,最近修改时间等,唯独文件名不在inode表中存储。一个文件对应一个inode,inode是固定大小。每个分组中的inode为了区分彼此,它们都有自己的ID。
6、Data blocks:保存的是分组内部所有文件的数据块。单个Data block:存放文件内容,大小随文件大小变化而变化。
4.2在文件系统中查找对应文件
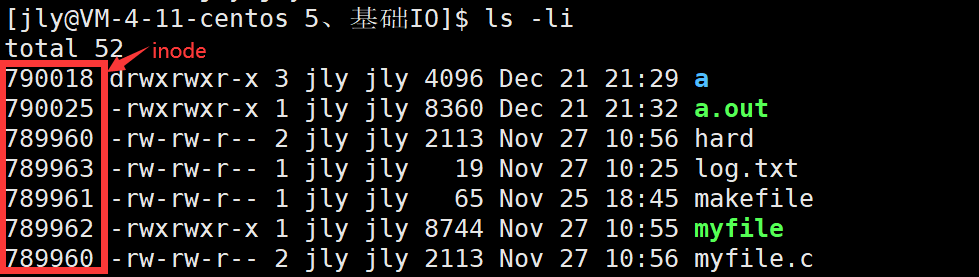
同一分区的inode是连续的,不同分区的inode是无关联的。使用inode编号找到对应块组,去inode Bitmap中查找该文件对应的比特位是不是1,是1则表示有文件属性,利用得到的inode Bitmap比特位,到inode Table中找到该文件的属性。
文件属性有了,那文件的数据如何获得?
inode结构体中除了inode编号,还保存了block[15]数据块数组。通过数组找到Data blocks中该文件对应的数据块。
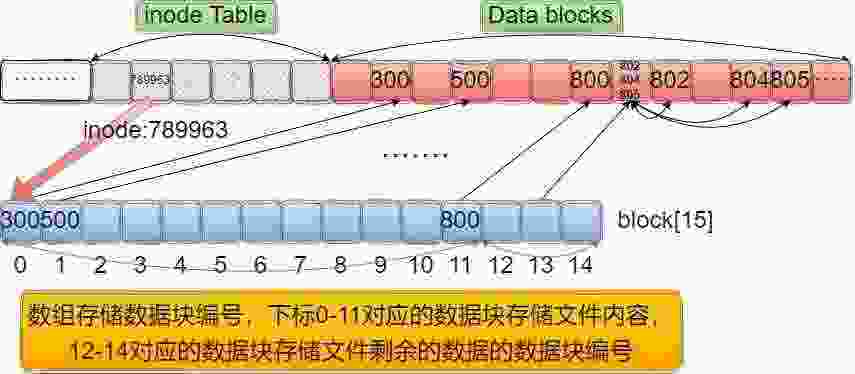
每个数据块的大小为4KB,那么操作系统是如何用15个数组空间存储任意大小的文件呢?数组前12个下标中对应的数据块直接用于存储文件内容,数组后3个空间中存放的编号对应的数据块中存放了文件剩余数据的数据块编号。其中下标12是一级索引,它对应的数据块中存储的数据块编号直接用于存文件数据;下标13是二级索引,它对应的数据块中存储的数据块编号是一级索引;下标14是三级索引;逐级展开,能存储很大的文件。
4.3在文件系统中删除对应文件
在任何文件系统中,需要删除文件只需要将inode Bitmap、Block Bitmap中文件对应的比特位由1置0,这个文件就被删除了。当然想要恢复文件的话,只需要找到被删除文件的inode编号,将inode Bitmap中的比特位由0置1,找到该文件在inode Table中的位置,根据其中的映射关系找到文件的数据块,并把Block Bitmap由0置1即可恢复文件。注意文件被误删之后不要做任何非恢复操作,防止原文件属性和内容被覆盖。
4.4目录的内容和属性
虽说文件系统是使用inode编号查找和删除文件,但是用户使用的可不是inode,而是文件名。
目录也是个普通文件,也有自己的inode和数据块,目录的inode中存储的自然是目录的属性信息,但是目录的数据块中存的是当前目录下的【文件名和inode】的映射关系。(每个文件名对应它的inode)
这也解释了为什么一个目录下不能出现同名文件,因为一个名字对应一个inode。
在Linux权限中提到:在一个目录下创建文件,必须要有写入权限,原因就是创建文件需要在目录的数据块中写入文件名和它的映射关系。
三、软硬链接
1、软链接
1.1建立/删除软链接

unlink log_s//删除软硬链接1.2软链接的应用
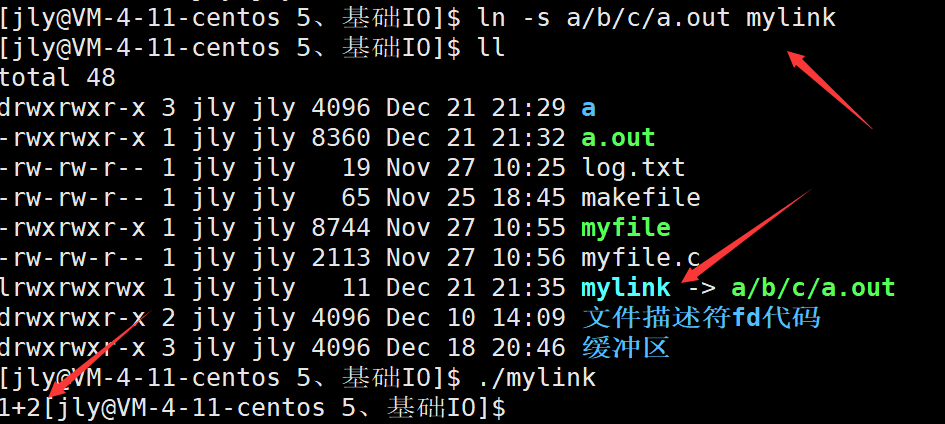
软链接类似windows中的快捷方式,快捷方式怎么用软链接就怎么用。上图是将其他路径中的可执行文件弄成软链接,直接./mylink执行即可,不用带路径。
软链接是一个独立的文件,有自己的inode属性和数据块。数据块中存储的是软链接指向目标文件的路径和文件名。
2、硬链接
2.1建立/删除硬链接
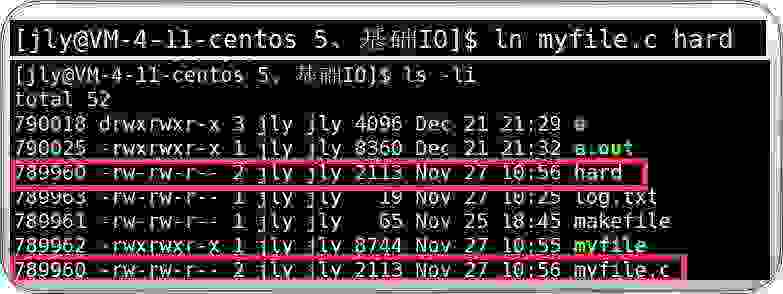
unlink hard//删除软硬链接对myfile.c建立硬链接hard,发现hard和myfile.c的inode值完全一样。硬链接没有自己的inode,根本就不是一个独立的文件,它只是对应文件的文件名和inode编号的映射关系。
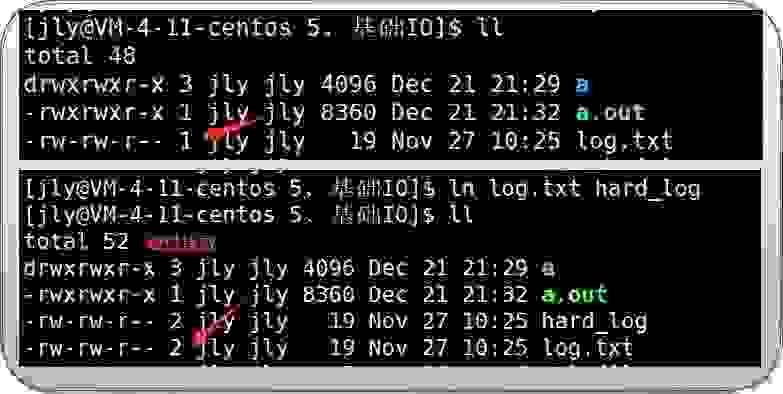
这个数字就是硬链接数。代表有几个文件指向我。这个数组保存在inode结构体对象中的ref变量中,新建该文件的硬链接,ref++;反之,ref--,当ref减为0时,这个文件才被删除。(引用计数)
2.2硬链接的应用
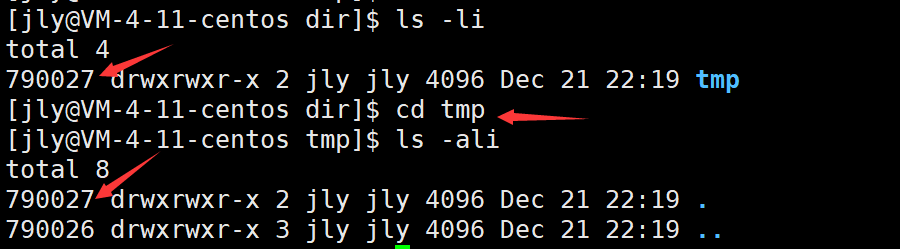
一个普通文件被创建,硬链接数是1,因为自身的存在会让ref等于1;为什么一个新建的目录的硬链接数为2,?因为除了自身之外,目录中有一个隐藏的“·”指向当前目录。
在tmp目录下继续创建目录,硬链接++,因为tmp下新建目录dir中存在“··”,指向tmp。

四、文件的三个时间
[jly@VM-4-11-centos 动静态库]$ stat makefile File: ‘makefile’ Size: 0 Blocks: 0 IO Block: 4096 regular empty fileDevice: fd01h/64769dInode: 790078 Links: 1Access: (0664/-rw-rw-r--) Uid: ( 1001/ jly) Gid: ( 1001/ jly)Access: 2022-12-22 08:31:52.313307187 +0800//文件最近被访问的时间Modify: 2022-12-22 08:31:52.313307187 +0800//最近一次修改文件内容的时间Change: 2022-12-22 08:31:52.313307187 +0800//最近一次修改文件属性的时间 Birth: -1、修改文件的内容时,Modify被改变可以理解,但为什么Change也被改变了。这是因为修改文件内容时,有可能会修改文件的属性,比如文件的大小可能被改变。
2、另一个现象是用户访问和修改文件时,Access时间大部分时候不改变。在较新的Linux内核中,Access时间不会被立即更新,经过一定的时间间隔,操作系统才对Access时间进行 一次更新。一个文件的读取或是修改,都会改变Access时间,如果当即对Access时间进行更新,操作系统会和磁盘进行大量的交互,使Linux系统变慢。Access时间的非即时更新是一个优化。
3、我们在编写完makefile后,make一下,就能生成对应的可执行程序。如果依赖的文件列表没有发生修改,gcc通过判断依赖文件的Modify time早于可执行程序的Modify time,说明依赖文件列表没有修改,那么再次make将会失败;反之,重新编译将会成功。不过多次make clean却不会失败,因为clean被.PHONY修饰,变成了一个伪目标,不受时间的约束,所以clean总是可被执行。
使用touch更新文件的三个时间:
touch makefile//makefile已存在,再次touch,将会更新makefile的三个时间五、动静态库
ldd显示可执行程序依赖的库。

查看程序是动静态的方法:
file 可执行程序
静态程序的生成及动静态链接优缺点及更多详细信息可参照博主这一篇文章。
1、静态库的制作
一套完成的库包含1、库文件本身(二进制文件,人看不懂)2、头文件(文本类型,暴露库文件中的接口)3、说明文档。
/lib64 库文件的存放目录(有些是/usr/lib)/usr/include 头文件的存放目录费尽千辛万苦写出来的代码,目的是给别人用,但是我不想让别人知道源文件中方法的实现细节,那么就需要制作静态库。
1.1静态库的生成
1、将所有库文件编译为.o(可重定向二进制目标文件),用户拿到每个模块的.o文件,自行链接即可。将所有的.o打包就是库。
使用ar -rc对多个.o进行打包。ar是gun归档工具。
gcc -c sub.c gcc -c add.c ar -rc libmymath.a sub.o add.o对应的makefile:
libmymath.a:sub.o add.oar -rc $@ $^%.o:%.cgcc -c $< 先把两个.c生成两个.o,再把两个.o打包成.a静态库。
使用ar -tv查看静态库中的内容:

1.2将静态库和头文件合并
用户仅有静态库并不清楚静态库中的信息,所以需要将.h文件一并给用户。
以下为打包+.h整合至一个文件夹,并附带了一个安装功能的makefile:
libmymath.a:sub.o add.oar -rc $@ $^%.o:%.cgcc -c $< .PHONY:cleanclean:rm -rf *.o libmymath.a output.PHONY:outputoutput:mkdir output cp -rf *.h output cp libmymath.a output.PHONY:installinstall:cp *.h /usr/include cp libmymath.a /lib641.3用户如何使用静态库

将打包好的静态库文件给到用户,用户自己写一个main函数,即可使用output中的.h文件。
不过在编译时,需要执行如下命令:
gcc test.c -I./output -L./output -lmymath-I:告诉编译器在./output路径中找头文件-L:告诉编译器在./output路径找库-l:跟库名称(去掉前缀lib,去掉后缀.so或.a)makefile:
test:test.c gcc -o $@ $^ -I./output -L./output -lmymath.PHONY:cleanclean:rm -f test使用编译器提供的库并行不需要带这些选项,是因为编译器有自己的环境变量,能够找到位于/lib64库文件的存放目录和/usr/include头文件的存放目录。
可以将静态库和头文件放入这些目录或其他相关目录下,这就是一般软件的安装过程。但是不推荐(自己写的库什么水平没点数吗?放进去会污染标准库)。
2、动态库的制作
2.1动态库的生成
同样的,将所有.o进行打包。
makefile:
#-shared:形成一个动态链接的共享库libmymath.so:add.o sub.ogcc -shared -o $@ $^#-fPIC:产生.o目标文件,程序内部的地址方案是:与位置无关,库文件可以在内存的任意位置加载,不影响其他程序的关联性%.o:*%.cgcc -fPIC -c $<.PHONY:cleanclean:rm -f libmymath.so这样就得到了一个动态库libmymath.so
2.2将动态库和头文件合并
makefile:
#-shared:形成一个动态链接的共享库libmymath.so:add.o sub.ogcc -shared -o $@ $^#-fPIC:产生.o目标文件,程序内部的地址方案是:与位置无关,库文件可以在内存的任意位置加载,不影响其他程序的关联性%.o:*%.cgcc -fPIC -c $<.PHONY:cleanclean:rm -rf libmymath.so *.o output#发布.PHONY:outputoutput:mkdir output cp ./*.h outputcp libmymath.so ./output 2.3用户如何使用动态库
makefile:
test:test.c gcc -o $@ $^ -I./output -L./output -lmymath//这里只是告知编译器头文件和库路径在哪里.PHONY:cleanclean:rm -f test动静态库的使用方式是一样的。
但是运行可执行程序会报错:没有这个文件或目录

使用ldd命令发现缺少了自己写的动态库:因为makefile只是告诉编译器头文件和库的路径,编译能通过,但是运行又不是编译器来运行,当然不知道详细库路径!

静态库能运行是因为静态链接是将所有内容全部拷贝到源文件。动态库编译/运行都需要这些路径,运行时需要通过加载器,告诉操作系统库路径在哪里。
方案一:将动态库和头文件拷贝至对应的系统库路径和头文件路径下(不推荐)
方案二:更改环境变量LD_LIBRARY_PATH
用于指定查找共享库(动态链接库)时除了默认路径(./lib和./usr/lib)之外的其他路径。export LD_LIBRARY_PATH=/home/jly/5、基础IO/动静态库/动态库/test_A/output当然这个环境变量在下次重新登录就没了,如果想让这个环境变量永久生效,可以把这个环境变量添加到登录相关的启动脚本里,下面两个都行,但是不建议,如果真要改,多开几个终端,防止改了之后登不上Linux:
vim ~/.bash_profilevim ~/.bashrc方案三:ldconfig
[jly@VM-4-11-centos test_A]$ ll /etc/ld.so.conf.d/ -ddrwxr-xr-x. 2 root root 4096 Sep 6 22:04 /etc/ld.so.conf.d//etc/ld.so.conf.d/是系统搜索动态库的路径
[jly@VM-4-11-centos ld.so.conf.d]$ sudo touch new.conf写入路径[jly@VM-4-11-centos ld.so.conf.d]$ sudo vim new.conf[jly@VM-4-11-centos ld.so.conf.d]$ cat new.conf /home/jly/5、基础IO/动静态库/动态库/test_A/output更新ldconfig[jly@VM-4-11-centos ld.so.conf.d]$ sudo ldconfig方案三重启有效。
2.4动态库的优缺点
优点:
更加节省内存并减少页面交换;库文件与程序文件独立,只要输出接口不变,更换库文件不会对程序文件造成任何影响,因而极大地提高了可维护性和可扩展性;不同编程语言编写的程序只要按照函数调用约定就可以调用同一个库函数;适用于大规模的软件开发,使开发过程独立、耦合度小,便于不同开发者和开发组织之间进行开发和测试。缺点:
运行时依赖,否则找不到库文件就会运行失败运行加载速度相较静态库慢一些需要对库版本之间的兼容性做出更多处理3、动静态库的总结
制作动静态库:
1、将所有的源文件编译为.o可重定向目标文件;
2、制作动静态库的本质就是将所有.o和头文件“打包”,静态库使用ar -rc,动态库使用-shared和gcc -fFIC
3、使用:include+.a或.so文件
静态库只能静态链接,动态库只能动态链接。一般需要提供动静态两种版本的库,gcc和g++优先默认使用动态库进行链接,想要静态链接,需要手动在编译指令后添加-static选项。
Linux操作系统中一定会存在动态库,操作系统中有很多命令是由C语言写的,它们采用动态链接。
无论是采用动态链接还是静态链接,程序在预编译的时候,都会把所包含的头文件进行展开,这里展开的仅仅是库中的声明;当程序在链接的时候,静态链接会将库函数的定义拷贝一份到程序的代码段中,而动态链接会将动态库中所需的定义通过地址偏移量的方式加载到内存而不是可执行程序中,可执行程序运行时将这些定义通过页表映射至共享区,所以动静态库的体积存在巨大的差距。