首先声明,本篇文章直接包含所有matlab源代码,直接复制粘贴即可运行,全部都是源代码,可以自己更改的源代码!(不是.p文件!!!,浅浅痛斥一下很多文章为了盈利,还给程序加密!谴责!!)都是学生时代走过来的, 大家直接来我这里复制就行了,哪里不懂直接评论区留言,我会一一解答!
好了,废话到此为止!接下来讲正文!
同样以西储大学数据集为例,选用105.mat中的X105_BA_time.mat数据。
首先进行VMD分解,采用麻雀优化算法(SSA)对VMD的两个关键参数(惩罚因子α和模态分解数K)进行优化,以最小包络熵为适应度值。其他智能优化算法同样适用,关键要学会最小包络熵代码的编写,网上的五花八门,这篇文章会对最小包络熵代码进行详细注释。
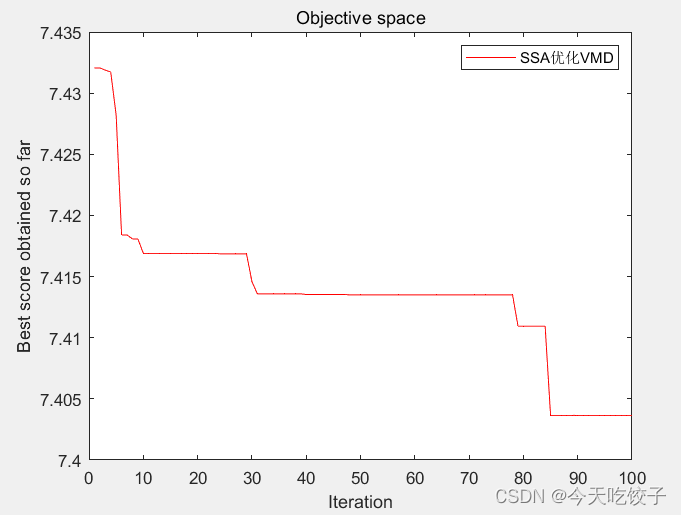
先上结果图:

实验过程中,会实时显示每次寻优后的最小包络熵值和VMD对应的两个最佳参数。本次寻优共100次(自己可以随意更改寻优次数)。
可以看到寻优100次后,最小包络熵为7.4036,对应两个vmd的最佳参数为122,8,其中惩罚因子为122,模态分解数为8。

收敛曲线如下所示:
上代码!直接复制粘贴就行!一个脚本,三个函数!
首先是主函数脚本,其中 惩罚因子α的范围是[100-2500],模态分解数K的范围是[3-10]
clear all clcaddpath(genpath(pwd))CostFunction=@(x) Cost(x); % 适应度函数的调用,包络熵值,详情请看Cost%设置SSA算法的参数Params.nVar=2; % 优化变量数目Params.VarSize=[1 Params.nVar]; % Size of Decision Variables MatrixParams.VarMin=[100 3]; % 下限值,分别是a,kParams.VarMax=[2500 10]; % 上限值Params.MaxIter=100; % 最大迭代数目Params.nPop=10; % 种群规模[particle3, GlobalBest3,SD,GlobalWorst3,Predator,Joiner] = Initialization(Params,CostFunction,'SSA'); %初始化SSA参数disp(['***采用SSA算法开始寻优***'])[GlobalBest,SSA_curve] = SSA(particle3,GlobalBest3,GlobalWorst3,SD,Predator,Joiner,Params,CostFunction); %采用SSA参数优化VMD的两个参数fMin = GlobalBest.Cost;bestX = GlobalBest.Position;%画适应度函数图figureplot(1:Params.MaxIter,SSA_curve,'Color','r')title('Objective space')xlabel('Iteration');set(gca,'xtick',0:10:Params.MaxIter);ylabel('Best score obtained so far');legend('SSA优化VMD')display(['The best solution obtained by SSA is : ', num2str(round(bestX))]); %输出最佳位置display(['The best optimal value of the objective funciton found by SSA is : ', num2str(fMin)]); %输出最佳适应度值然后是SSA的初始化脚本函数(Initialization.m),用于对SSA的粒子进行初始化的
function [particle, GlobalBest,varargout] = Initialization(Params,CostFunction,name)nPop = Params.nPop;VarMin = Params.VarMin;VarMax = Params.VarMax;VarSize = Params.VarSize;%% Initializationswitch name % 麻雀个体 case 'SSA' % 捕食者个体占比 PredatorRate = 0.5; % 警觉者占比 SDRate = 0.3; empty_particle.Position=[]; empty_particle.Cost=[]; % 捕食者和加入者 PredatorNumber = floor(nPop * PredatorRate); particle=repmat(empty_particle,nPop ,1); % 警觉者 SDNumber = floor(nPop * SDRate); SD = repmat(empty_particle,SDNumber,1); GlobalBest.Cost=inf; GlobalWorst.Cost = -inf; % 初始化 disp(['***初始化***']) for i = 1:nPop particle(i).Position = unifrnd(VarMin,VarMax,VarSize); particle(i).Cost = CostFunction(particle(i).Position); if GlobalBest.Cost > particle(i).Cost GlobalBest = particle(i); end if GlobalWorst.Cost < particle(i).Cost GlobalWorst = particle(i); end end % 警觉者初始化 for i = 1:SDNumber SD(i).Position = unifrnd(VarMin,VarMax,VarSize); SD(i).Cost = CostFunction(SD(i).Position); end % 挑选捕食者和加入者 [~,index] = sort([particle.Cost]); Predator = particle(index(1:PredatorNumber)); Joiner = particle(index(PredatorNumber+1:end)); format long; disp(['初始化后的最小包络熵为:',num2str(GlobalBest.Cost),',初始化后的最佳参数为:[',num2str(round(GlobalBest.Position)),']']) end %% 输出switch name case 'SSA' varargout{1} = SD; varargout{2} = GlobalWorst; varargout{3} = Predator; varargout{4} = Joiner; otherwise % varargout{1:4} = []; endend接下来是SSA的脚本函数(SSA.m),也是麻雀算法的主体
function [ GlobalBest,BestCost] =SSA (particle,GlobalBest,GlobalWorst,SD,Predator,Joiner,Params,CostFunction)MaxIter = Params.MaxIter;nPop = Params.nPop;VarMin = Params.VarMin;VarMax = Params.VarMax;VarSize = Params.VarSize;nVar=2;%size(VarSize,2);BestCost = zeros(1,MaxIter);%% Main loopfor i = 1:MaxIter for j = 1:length(Predator) alarm = randn ; ST = randn; if alarm < ST Predator(j).Position = Predator(j).Position .* exp( -j /MaxIter); else Predator(j).Position = Predator(j).Position + randn * ones(VarSize); end Predator(j).Position = max(VarMin,Predator(j).Position); Predator(j).Position = min(VarMax,Predator(j).Position); Predator(j).Cost = CostFunction(Predator(j).Position); end [~,idx] = min([Predator.Cost]); BestPredator = Predator(idx); % 加入者更新 for j = 1: nPop - length(Predator) if j + length(Predator)> nPop/2 Joiner(j).Position = randn .* exp( (GlobalWorst.Position - Joiner(j).Position) / j^2); else A = randi([0,1],1,nVar); A(~A) = -1; Ahat = A' / (A * A'); Joiner(j).Position = BestPredator.Position + abs(Joiner(j).Position - BestPredator.Position) * Ahat * ones(VarSize); end Joiner(j).Position = max(VarMin,Joiner(j).Position); Joiner(j).Position = min(VarMax,Joiner(j).Position); Joiner(j).Cost = CostFunction(Joiner(j).Position); end % 警觉者更新 for j = 1:length(SD) if SD(j).Cost > GlobalBest.Cost SD(j).Position = GlobalBest.Position + randn * abs( SD(j).Position - GlobalBest.Position); elseif SD(j).Cost == GlobalBest.Cost SD(j).Position = SD(j).Position + (rand*2-1) * (abs( SD(j).Position - GlobalWorst.Position)./ ((SD(j).Cost - GlobalWorst.Cost) + 0.001)); end SD(j).Position = max(VarMin,SD(j).Position); SD(j).Position = min(VarMax,SD(j).Position); SD(j).Cost = CostFunction(SD(j).Position); end % 更新particle = [Predator;Joiner;SD];for m = 1:length(particle) if GlobalBest.Cost > particle(m).Cost GlobalBest = particle(m); end if GlobalWorst.Cost < particle(m).Cost GlobalWorst = particle(m); endend BestCost(i) = GlobalBest.Cost; disp(['第',num2str(i),'次寻优的最小包络熵为:',num2str(BestCost(i)),',对应最佳参数为:[',num2str(round(GlobalBest.Position)),']']) endend最后是适应度函数!(Cost.m),最小包络熵的编写就在此函数中。
function ff = Cost(c)load 105.matX = X105_BA_time(1:2000); %加载西储大学数据的前2000个点alpha = round(c(1)); % moderate bandwidth constraint:适度的带宽约束/惩罚因子tau = 0; % noise-tolerance (no strict fidelity enforcement):噪声容限(没有严格的保真度执行)K = round(c(2)); % modes:分解的模态数DC = 0; % no DC part imposed:无直流部分init = 1; % initialize omegas uniformly :omegas的均匀初始化tol = 1e-7; %--------------- Run actual VMD code:数据进行vmd分解---------------------------[u, u_hat, omega] = VMD(X, alpha, tau, K, DC, init, tol);for i = 1:Kxx= abs(hilbert(u(i,:))); %首先对分解得到的IMF分量进行希尔伯特变换,并求取幅值xxx = xx/sum(xx); % ssum=0; for ii = 1:size(xxx,2)bb = xxx(1,ii)*log(xxx(1,ii)); %最小包络熵的计算公式 ssum=ssum+bb; %求和运算 end fitness(i,:) = -ssum; %记着加负号! 也是公式的一部分endff = min(fitness);end其中VMD.m本篇文章就不再赘述,需要的小伙伴可以在我的这篇文章中直接粘贴vmd.m程序。(5条消息) VMD分解,matlab代码,包络线,包络谱,中心频率,峭度值,能量熵,近似熵,包络熵,希尔伯特变换,包含所有程序MATLAB代码,-西储大学数据集为例_今天吃饺子的博客-CSDN博客
最后祝愿各位小伙伴,所有代码永不出错!
觉着不错的给博主留个小赞吧!您的一个小赞就是博主更新的动力!谢谢!