1、SENet
1.1 前言
SENet 是最后一届 ImageNet 2017 竞赛分类任务的冠军。SENet 网络的创新点在于关注 channel 之间的关系,希望模型可以自动学习到不同 channel 特征的重要程度。为此,SENet 提出了 Squeeze-and-Excitation(SE)模块。
对于一张图片,不同的 channel 的权重一般都是不一样的。如果我们能够把这个信息捕获出来,那么我们的网络就可以获得更多的信息,那么自然就拥有更高得准确率。
1.2 图解
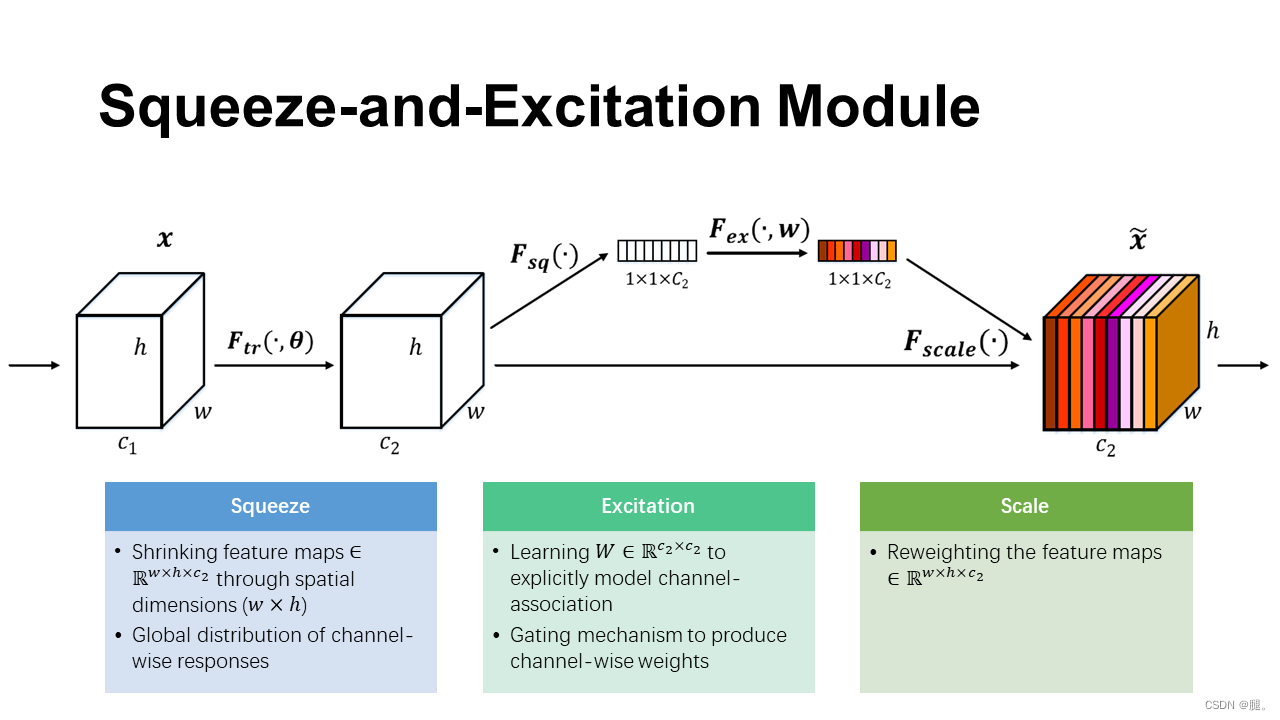
SE注意力机制的实现步骤如下:
(1)Squeeze:通过全局平均池化(nn.AdaptiveAvgPool2d(1)),将每个通道的二维特征(H*W)压缩为1个实数,将特征图从 [h, w, c] ==> [1,1,c],得到channel级的全局特征
(2)excitation:给每个特征通道生成一个权重值,论文中通过两个全连接层构建通道间的相关性,输出的权重值数目和输入特征图的通道数相同。[1,1,c] ==> [1,1,c],学习各个channel间的关系,也得到不同channel的权重
(3)Scale:将前面得到的归一化权重加权到每个通道的特征上。论文中使用的是乘法,逐通道乘以权重系数。[h,w,c]*[1,1,c] ==> [h,w,c]
本质上,SE模块是在channel维度上做attention或者gating操作,这种注意力机制让模型可以更加关注信息量最大的channel特征,而抑制那些不重要的channel特征。另外一点是SE模块是通用的,这意味着其可以嵌入到现有的网络架构中。
1.3 pytorch代码(结合模型图)
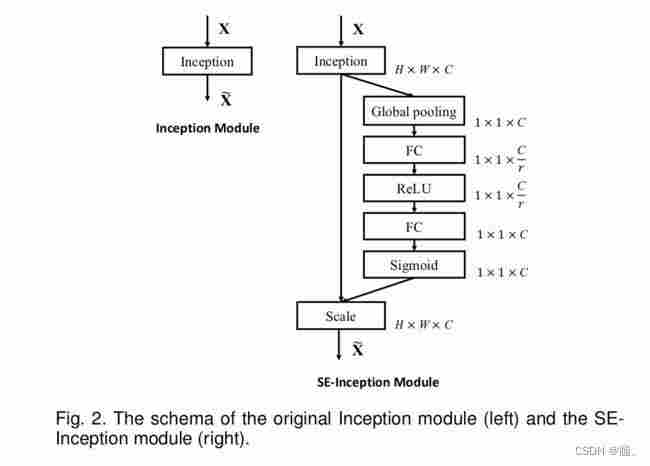
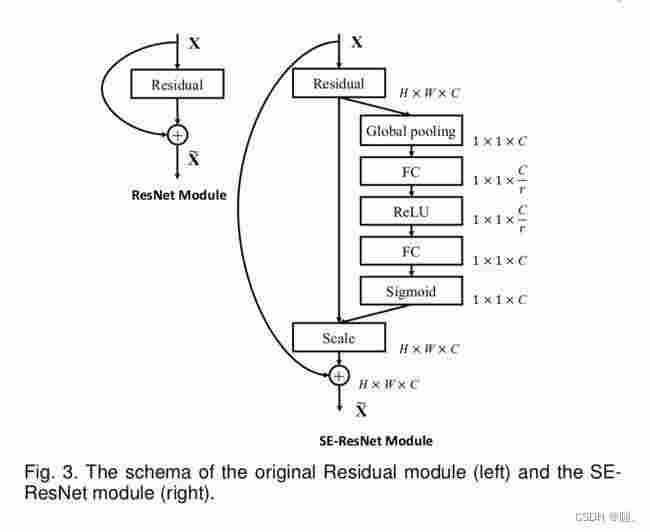
import torchfrom torch import nnclass SE(nn.Module): # ratio代表第一个全连接下降通道的倍数 def __init__(self, in_channel, ratio=4): super().__init__() # 全局平均池化,输出的特征图的宽高=1 self.avg_pool = nn.AdaptiveAvgPool2d(output_size=1) # 第一个全连接层将特征图的通道数下降4倍 self.fc1 = nn.Linear(in_features=in_channel, out_features=in_channel//ratio, bias=False) # relu激活,可自行换别的激活函数 self.relu = nn.ReLU() # 第二个全连接层恢复通道数 self.fc2 = nn.Linear(in_features=in_channel//ratio, out_features=in_channel, bias=False) # sigmoid激活函数,将权值归一化到0-1 self.sigmoid = nn.Sigmoid() # 前向传播 def forward(self, inputs): # inputs 代表输入特征图 b, c, h, w = inputs.shape # 全局平均池化 [b,c,h,w]==>[b,c,1,1] x = self.avg_pool(inputs) # 维度调整 [b,c,1,1]==>[b,c] x = x.view([b,c]) # 第一个全连接下降通道 [b,c]==>[b,c//4] x = self.fc1(x) x = self.relu(x) # 第二个全连接上升通道 [b,c//4]==>[b,c] x = self.fc2(x) # 对通道权重归一化处理 x = self.sigmoid(x) # 调整维度 [b,c]==>[b,c,1,1] x = x.view([b,c,1,1]) # 将输入特征图和通道权重相乘 outputs = x * inputs return outputs
2、CBAM
2.1 前言
CBAM注意力机制是由通道注意力机制(channel)和空间注意力机制(spatial)组成。
传统基于卷积神经网络的注意力机制更多的是关注对通道域的分析,局限于考虑特征图通道之间的作用关系。CBAM从 channel 和 spatial 两个作用域出发,引入空间注意力和通道注意力两个分析维度,实现从通道到空间的顺序注意力结构。空间注意力可使神经网络更加关注图像中对分类起决定作用的像素区域而忽略无关紧要的区域,通道注意力则用于处理特征图通道的分配关系,同时对两个维度进行注意力分配增强了注意力机制对模型性能的提升效果。
2.2 图解
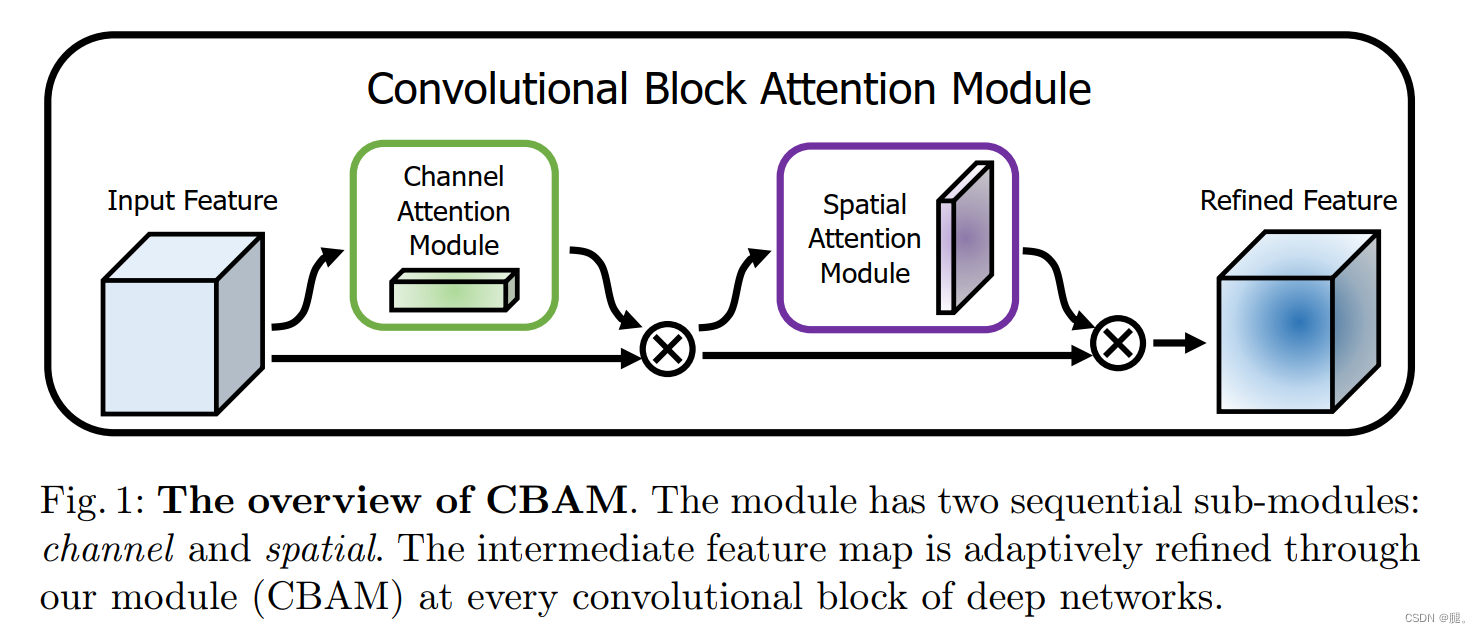
可以看到该模块由两部分组成,Channel attention module(通道注意力模块,以下简称CAM) 和 Spatial Attention Module (空间注意力模块,以下简称SAM)。
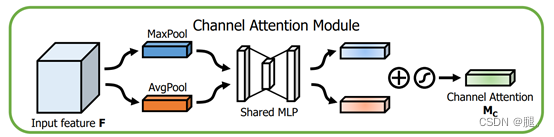
CAM和SE类似,只是SE只采用了全局平均池化, 而CAM同时使用了平局池化和最大池化,这样在一定层度上能降低池化带来的信息丢失

SAM首先做一个全局最大池化和全局平均池化,然后对于channel做从concat操作,经过一个卷积操作,将channel降为1,再经过sigmoid生成空间注意特征图,最后与通道注意特征图做乘法。
2.3 pytorch 代码
#(1)通道注意力机制class channel_attention(nn.Module): # ratio代表第一个全连接的通道下降倍数 def __init__(self, in_channel, ratio=4): super().__init__() # 全局最大池化 [b,c,h,w]==>[b,c,1,1] self.max_pool = nn.AdaptiveMaxPool2d(output_size=1) # 全局平均池化 [b,c,h,w]==>[b,c,1,1] self.avg_pool = nn.AdaptiveAvgPool2d(output_size=1) # 第一个全连接层, 通道数下降4倍(可以换成1x1的卷积,效果相同) self.fc1 = nn.Linear(in_features=in_channel, out_features=in_channel//ratio, bias=False) # 第二个全连接层, 恢复通道数(可以换成1x1的卷积,效果相同) self.fc2 = nn.Linear(in_features=in_channel//ratio, out_features=in_channel, bias=False) # relu激活函数 self.relu = nn.ReLU() # sigmoid激活函数 self.sigmoid = nn.Sigmoid() # 前向传播 def forward(self, inputs): b, c, h, w = inputs.shape # 输入图像做全局最大池化 [b,c,h,w]==>[b,c,1,1] max_pool = self.max_pool(inputs) # 输入图像的全局平均池化 [b,c,h,w]==>[b,c,1,1] avg_pool = self.avg_pool(inputs) # 调整池化结果的维度 [b,c,1,1]==>[b,c] max_pool = max_pool.view([b,c]) avg_pool = avg_pool.view([b,c]) # 第一个全连接层下降通道数 [b,c]==>[b,c//4] x_maxpool = self.fc1(max_pool) x_avgpool = self.fc1(avg_pool) # 激活函数 x_maxpool = self.relu(x_maxpool) x_avgpool = self.relu(x_avgpool) # 第二个全连接层恢复通道数 [b,c//4]==>[b,c] #(可以换成1x1的卷积,效果相同) x_maxpool = self.fc2(x_maxpool) x_avgpool = self.fc2(x_avgpool) # 将这两种池化结果相加 [b,c]==>[b,c] x = x_maxpool + x_avgpool # sigmoid函数权值归一化 x = self.sigmoid(x) # 调整维度 [b,c]==>[b,c,1,1] x = x.view([b,c,1,1]) # 输入特征图和通道权重相乘 [b,c,h,w] outputs = inputs * x return outputs
#(2)空间注意力机制class spatial_attention(nn.Module): # 卷积核大小为7*7 def __init__(self, kernel_size=7): super().__init__() # 为了保持卷积前后的特征图shape相同,卷积时需要padding padding = kernel_size // 2 # 7*7卷积融合通道信息 [b,2,h,w]==>[b,1,h,w] self.conv = nn.Conv2d(in_channels=2, out_channels=1, kernel_size=kernel_size, padding=padding, bias=False) # sigmoid函数 self.sigmoid = nn.Sigmoid() # 前向传播 def forward(self, inputs): # 在通道维度上最大池化 [b,1,h,w] keepdim保留原有深度 # 返回值是在某维度的最大值和对应的索引 x_maxpool, _ = torch.max(inputs, dim=1, keepdim=True) # 在通道维度上平均池化 [b,1,h,w] x_avgpool = torch.mean(inputs, dim=1, keepdim=True) # 池化后的结果在通道维度上堆叠 [b,2,h,w] x = torch.cat([x_maxpool, x_avgpool], dim=1) # 卷积融合通道信息 [b,2,h,w]==>[b,1,h,w] x = self.conv(x) # 空间权重归一化 x = self.sigmoid(x) # 输入特征图和空间权重相乘 outputs = inputs * x return outputs#(3)CBAM注意力机制class cbam(nn.Module): # 初始化,in_channel和ratio=4代表通道注意力机制的输入通道数和第一个全连接下降的通道数 # kernel_size代表空间注意力机制的卷积核大小 def __init__(self, in_channel, ratio=4, kernel_size=7): super().__init__() # 实例化通道注意力机制 self.channel_attention = channel_attention(in_channel=in_channel, ratio=ratio) # 实例化空间注意力机制 self.spatial_attention = spatial_attention(kernel_size=kernel_size) # 前向传播 def forward(self, inputs): # 先将输入图像经过通道注意力机制 x = self.channel_attention(inputs) # 然后经过空间注意力机制 x = self.spatial_attention(x) return x