总结一下比赛过程,省二菜鸟,欢迎大佬指教
1.比赛任务
详情见十七届比赛细则第十七届智能车竞赛智能视觉组比赛细则_卓晴的博客-CSDN博客_智能视觉组,我这里简单介绍一下。
任务流程可以概括为:小车在起点出扫描一张A4纸(A4纸上有坐标点进而获得各个目标的位置)->扫描完后出发依此到达目标附近->到达每个目标附近后对目标进行识别->识别完成后不同的类别按照要求利用电磁铁搬运到指定位置->所有目标搬运完后返回起点。
任务中用到的A4纸、和贴有目标照片的kt板如下图所示。

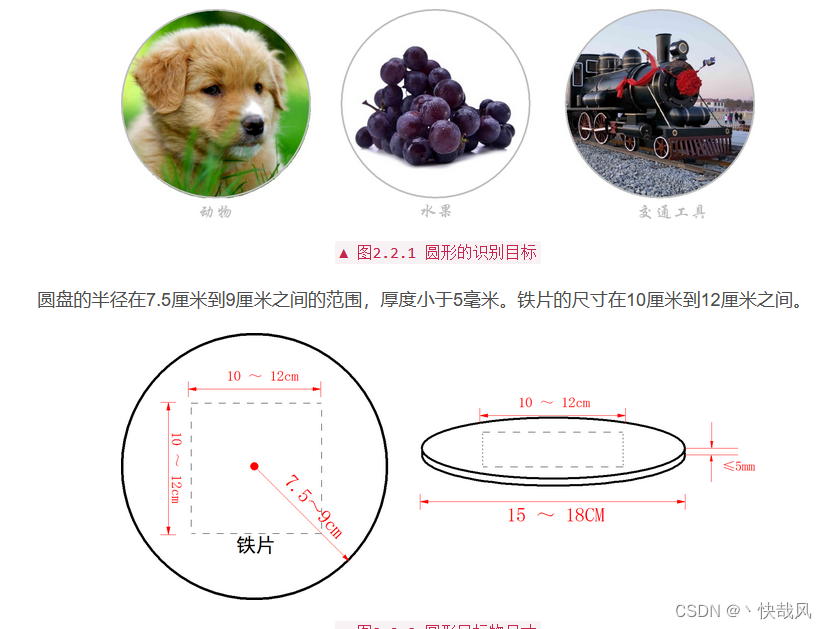
【PS:一开始规则发布是圆形的kt板,后来改成了正方形的了】
处理上面提到的内容,比赛场地周围还布置有Aptag二维码,用于帮助小车定位,不过我们这一届比赛的时候我几乎没看见有人用到这个二维码,基本上都是只用了A4纸的坐标。
2.小队分工
(1)队长:负责小车的控制(麦克纳姆轮的移动、定位、惯性导航)
(2)队友1(我):负责视觉部分(A4坐标纸的识别、小车靠近目标的微调算法、深度学习模型的训练部署)
(3)队友2:负责硬件部分
3.视觉部分
这一部分介绍我是如何完成视觉部分的各个任务的,代码还有自己拍摄的照片数据集都放在了github上【如果对您有用的话麻烦给个star,感谢】,需要的同学自取。
https://github.com/KZF-kzf/smartcar--hfut
3.1Openart-mini摄像头介绍
我们在比赛中使用了两个openartmini摄像头,没有使用总钻风。openart是openmv的一种,这里放上openmv的两个参考文档,另外b站上有星瞳科技关于openMV的教学视频,需要的同学也可以看看。
OpenMV | 星瞳科技
概述 — MicroPython 1.9.2 文档
3.2A4纸识别
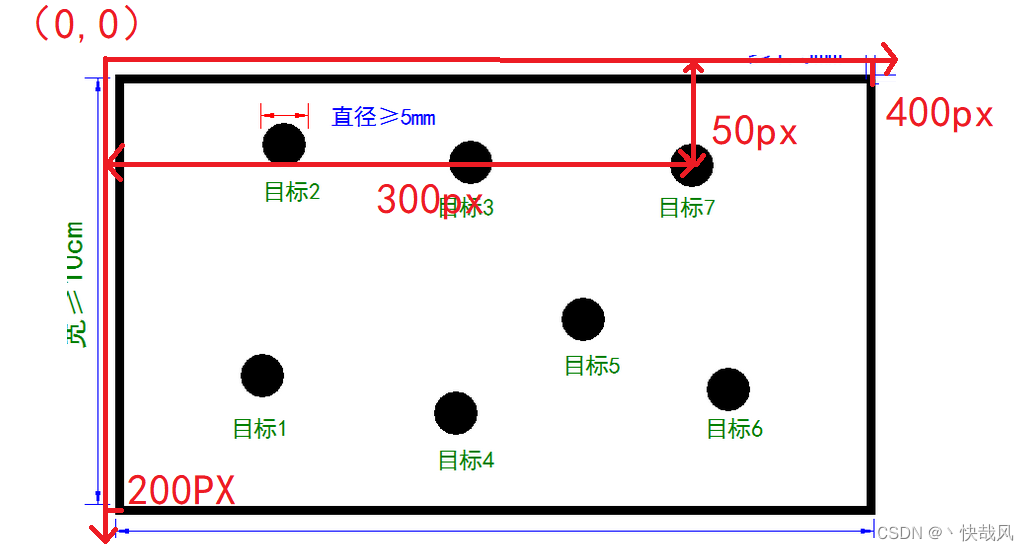
这一部分内容原理很简单,就是获得每个点在A4纸中的坐标,然后根据实际场地的大小进行放缩。假设实际场地是12*7米,如下图所示,px表示的是像素点个数,在摄像头中获得坐标都是像素点坐标。那么目标七的圆心坐标就是(300,50),而摄像头中A4纸的长宽分别为400px和200px,所以目标七在A4纸中的比例就是(300/400,50/200)用这个比例乘以实际的长宽(12,7)得到的就是目标七在实际场地中的坐标。
利用openmv实现上述A4纸识别的功能,主要思路有两个:1.用find_blob函数;2.用find_circle函数。这两种算法我都试过,后面参加的比赛的朋友也可以试试,最后比赛我用的是find_blob,不过建议后面的同学如果用find_blob函数的话想办法吧自动调整阈值的算法搞出来。
3.3微调算法
首先让我详细描述一下本小节致力于解决的问题。任何传感器都是有误差的,我们小车导航系统所用的编码器和陀螺仪自然也不例外。即使我们事先有很精确的坐标,但是确无法精确控制小车移动到该目标点。如下图所示,此时小车虽然运动到了目标的旁边,但若想要把目标搬运起来,那么位置误差不能超过5厘米。当小车移动到目标旁边时,利用openart摄像头检测目标的位置,并微微调整小车自身的位置,使电磁铁落下时可以正好吸住目标进而完成搬运任务。

具体解决思路:我们把这时图片在摄像头中的中心位置坐标设置为目标位置,而在实际运行过程中,我们把任一时刻的图片中心位置坐标和我们设置的中心位置坐标作差,如果得到的值是非0的,那么就说明小车的位置和目标位置之间存在偏差,且这个值得正负代表着方向。然后我们通过pid技术来使小车往偏差减小的方向移动,从而实现跟踪的效果,算法工作流程如下图。

3.4深度学习模型训练部署
关于深度学习这部分的话,我建议如果不是已经做过相关项目或者有很好的深度学习基础的同学,那么你可以完全的使用NXP提供的EIQ软件,这个软件基本上可以满足比赛正常需求。而且当时和一些朋友交流,他们有的自己训练然后量化的模型反而不如eiq导出的模型。
(1)模型训练量化部署全流程简述
这里只讲使用eiq的步骤
①首先,你需要把数据集导入到eiq中。这里的话可以参考往年的NXP培训视频,b站上有,不过我当时是看eiq的官方文档自己写了一个dataloader,都可以用。简而言之,就是最后要把你的数据集做成一个eiq能够打开的工程文件。这里有一点要注意一下:制作数据集时一定要把eiq打开,不然会报连接失败的错误。
②导入数据集后就可以开始训练了。eiq的训练特别简单,而且可视化程度高。这里需要提的就是数据增广的设置,这里也是推荐去看一下b站上十七届NXP的培训,里面有简单提到如何进行数据增广。然后也有一点要注意一下:不要直接用数据增广的数据集进行训练,先用原始数据集进行训练,训练至收敛后再添加数据增广,否则一开始就用数据增广的话模型可能无法收敛。
③训练完后就可以直接导出了
(2)自制数据集
就是除了用官方提供的数据集外,还要把这些图片打印下来然后用openart去拍摄制作数据集。这样做的目的是为了还原小车运行中摄像头中看到目标的真实情况。我们当初把所有数据集都打印并拍照了,这个数据集放在了上文提到的github上,需要的同学自取。另外,如果你自己也想打印出来的话,可以从淘宝上打印,注意不要被有的淘宝店铺坑了,我当时找了好几家店铺,最终找了家最便宜的才300块钱,有的黑心商家要收我700还有1000多的。
(3)识别方案
我们当时主流方案有两种,一种是一个模型直接识别十五个小类,还有一种是用三个模型,每个模型识别五个小类,我当时比赛用的是第一种,效果不太好,推荐你们试试第二种。