第五届“泰迪杯”数据分析技能赛(B题)『一等奖』,@队友:东可在编程、好同志歪歪
B题题目为“银行客户忠诚度分析”,题目给出了短期客户产品购买数据“short-customer-data.csv”和长期客户资源信息数据的训练集“long-customer-train.csv”,需要进行数据清洗和预处理,从中分析挖掘和可视化呈现。
代码见“八、”中的链接。
目录
竞赛官网
一、背景
二、目标
三、任务1:数据探索与清洗
3.1 任务1.1的解决方案和结果
3.1.1 短期数据缺失值处理
3.1.2 短期数据重复值处理
3.1.3 长期数据异常值处理
3.2 任务1.2的解决方案和结果
3.2.1 短期数据特征编码
3.2.2 编码过程及结果
四、任务2:产品营销数据可视化分析
4.1 短期数据指标相关性分析
4.2 两种产品客户量年龄分析
4.3 蓝领与学生的产品购买情况分析
4.4 产品购买结果和拜访客户的通话时长分析
五、任务3:客户流失因素可视化分析
5.1 年龄
5.2 客户信用资格和年龄
5.3 账号户龄
5.4 客户状态和资产阶段
5.4.1 特征编码
5.4.2 热力图分析
六、任务4:特征构建
七、任务5:银行客户长期忠诚度预测建模
7.1 预测模型建立
7.1.1 特征编码选取
7.1.2 预测模型建立的思路
7.1.3 预测模型建立的过程
7.2 预测模型评估
7.2.1 特征重要性排序
7.2.2 混淆矩阵分析
7.2.3 模型训练指标评价
7.3 预测模型应用
八、程序实现代码
九、参考文献
十、比赛小结
竞赛官网
第五届“泰迪杯”数据分析技能赛 赛题 https://www.tipdm.org:10010/#/competition/1557899215680741376/question
https://www.tipdm.org:10010/#/competition/1557899215680741376/question
一、背景
目前银行产品存在同质化现象,客户选择产品和服务的途径越来越多,对产品的忠诚度越来越低。为了提高客户对银行的忠诚度和银行营销量,商业银行迫切需要转变经营理念,从“产品销售导向”业务模式向“以客户为中心”转变,为客户带来极致体验和价值成长,形成路径依赖,进而实现价值共赢。
客户忠诚度主要体现为客户的行为和态度。客户行为主要表现为产品重复购买的频率,而客户态度主要表现为情感的倾向。为了有效挖掘客户忠诚度,需要从短期客户产品购买数据和长期客户资源信息中分析客户需求指标。其中,短期客户忠诚度分析是通过产品的购买数据,分析不同指标客户对银行产品的购买依赖度从而提供更好的销售服务;长期客户忠诚度分析则是从客户资源信息数据中挖掘客户流失因素、预测可能流失的客户,尽可能留住高价值客户。
二、目标
(1) 对客户数据进行预处理,并对字符型数据进行特征编码。
(2) 基于短期客户产品购买数据,分析不同指标客户对银行产品的购买依赖度,并进行可视化呈现。
(3) 基于长期客户资源信息数据,分析客户流失因素,并进行可视化呈现。
(4) 依据长期客户资源信息数据的分析结果构建相关指标,对银行客户长期忠诚度进行预测。
三、任务1:数据探索与清洗
分别对短期客户产品购买数据“short-customer-data.csv”(简称短期数据)和长期客户资源信息数据的训练集“long-customer-train.csv”(简称长期数据)进行数据探索与清洗。
任务 1.1 数据探索与预处理
(1) 探索短期数据各指标数据的缺失值和“user_id”列重复值,删除缺失值、重复值所在行数据。请在报告中给出处理过程及必要结果,完整的结果保存到文件“result1_1.xlsx”中。
(2) 长期数据中的客户年龄“Age”列存在数值为-1、0 和“-”的异常值,删除存在该情况的行数据;“Age”列存在空格和“岁”等异常字符,删除这些异常字符但须保留年龄数值,将处理后的数值存于“Age”列。请在报告中给出处理过程及必要结果,完整的结果保存到文件“result1_2.xlsx”中。
任务 1.2 对短期数据中的字符型数据进行特征编码,如将信用违约情况{‘否’,‘是’}编码为{0,1}。请在报告中给出处理思路、过程及必要结果,完整的结果保存到文件“result1_3.xlsx”中。
3.1 任务1.1的解决方案和结果
3.1.1 短期数据缺失值处理
数据中存在部分缺失值,可能对后续任务产生影响,需要对数据进行清洗。根据题目要求,包含缺失值的记录全部删去。为最大程度保留有效数据,缺失值处理在重复值处理之前进行。
短期客户产品购买数据集共有41176条记录,使用DataFrame的count()方法统计各列的非空数据量,统计结果如下表所示。
| 数据列 | 非空数据量 |
| user_id | 41176 |
| age | 41176 |
| job | 40846 |
| marital | 41096 |
| education | 39446 |
| default | 32580 |
| housing | 40186 |
| loan | 40186 |
| contact | 41176 |
| month | 41176 |
| day_of_week | 41176 |
| duration | 41176 |
| poutcome | 41176 |
| y | 41176 |
使用DataFrame的dropna()方法去除数据中包含空值的行,共剩余30478条记录。
3.1.2 短期数据重复值处理
数据中存在部分重复值,可能对后续任务产生影响,需要对数据进行清洗。根据题目要求,user_id列重复值只保留一个。
以“BA2200001”为例,去除空值的数据中存在如下图所示的重复数据。
 以“BA2200001”为例的重复数据
以“BA2200001”为例的重复数据 对此,本文仅保留在数据集中第一次出现的数据。使用drop_duplicates(subset=['user_id'])方法去除“user_id”列重复值,默认只保留第一条记录,处理后的记录数为30445条,部分结果如下图所示,完整结果保存到“result1_1.xlsx”。
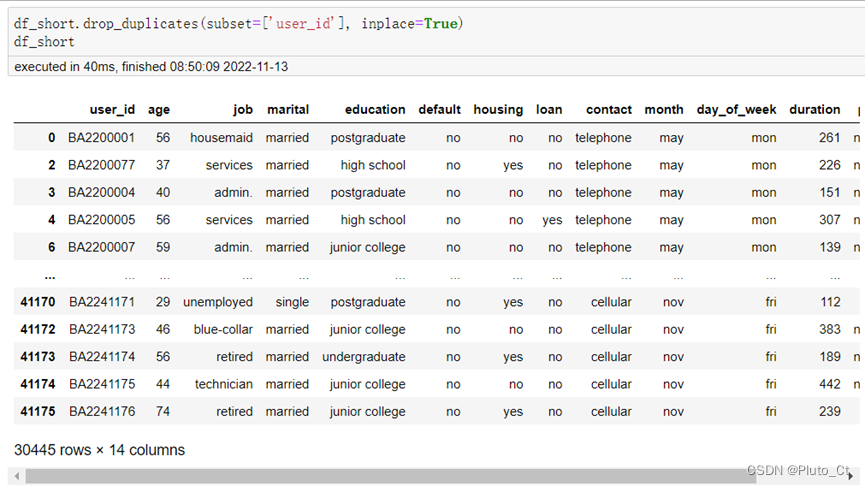 缺失值、重复值处理后部分数据
缺失值、重复值处理后部分数据 3.1.3 长期数据异常值处理
使用unique()方法对长期数据进行探索,发现“Age”列值如下图所示,存在“-”“0”以及包含文本“岁”等异常值。
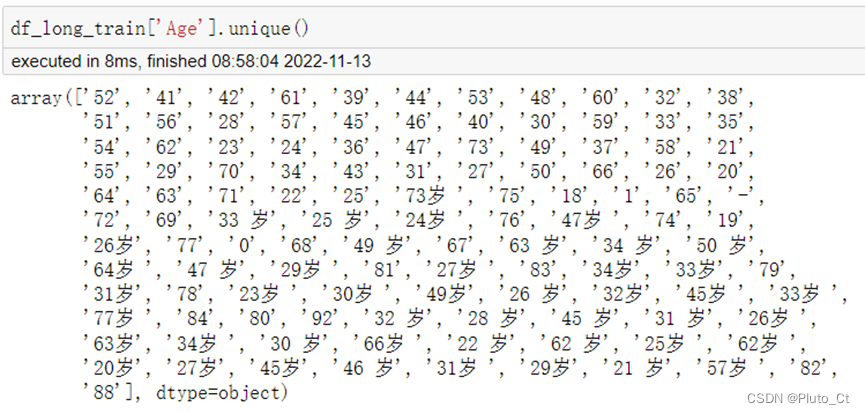
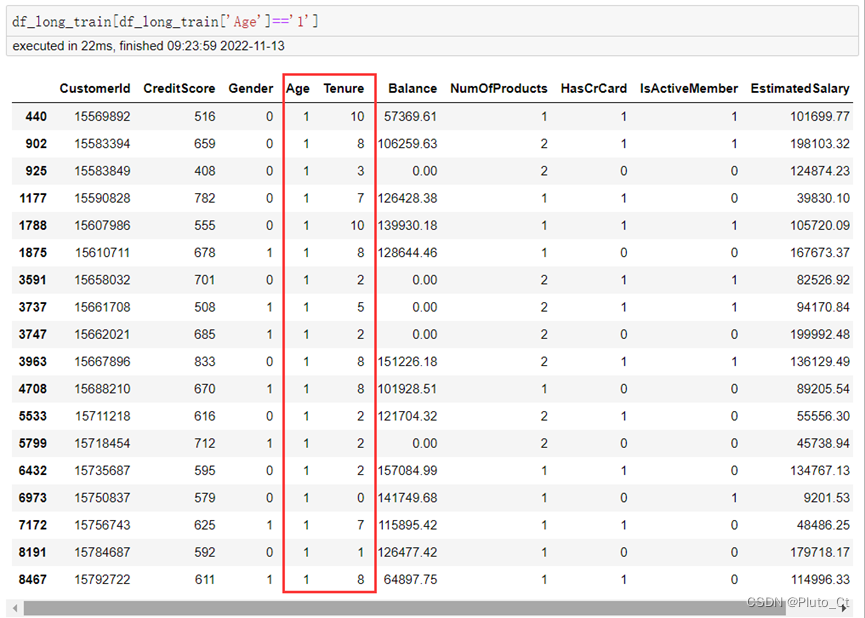
其中,在数据分析过程中,发现有18条年龄为1的记录,其中16条记录中的账号户龄超过年龄,与现实生活中的情况不相符合,且由于银行账户不可过户,同时我国银行规定办理银行卡需年满10周岁,因此本文将这些数据也视为异常值。
因此,本文对“Age”列异常值处理方法如下:首先对文本数据进行处理。使用正则表达式“(\d+)”提取其中的数值部分,未匹配到数值或数值小于10的数据按缺失值处理,予以剔除,并将剩余数据转为数值类型。处理后剩余9180条数据,部分数据如下图所示,完整结果保存到“result1_2.xlsx”。
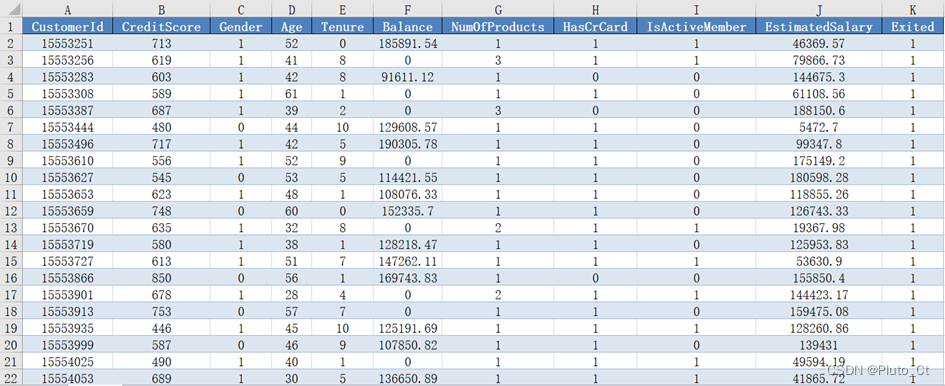 异常值处理后部分数据
异常值处理后部分数据 3.2 任务1.2的解决方案和结果
3.2.1 短期数据特征编码
对字符型数据进行特征编码,可以减小数据冗余,也为后续的数据分析处理提供便利。本题需要进行特征编码的列共有“job”、“marital”、“education”、“default”、“housing”、“loan”、“contact”、“month”、“day_of_week”、“poutcome”、“y”共11列,如下表所示。
| 列名 | 全部数据值 |
| job | housemaid, services, admin., technician, blue-collar, unemployed, retired, entrepreneur, management, student, self-employed |
| marital | married, single, divorced |
| education | postgraduate, high school, junior college, undergraduate, illiterate |
| default | no, yes |
| housing | no, yes |
| loan | no, yes |
| contact | telephone, cellular |
| month | may, jun, jul, aug, oct, nov, dec, mar, apr, sep |
| day_of_week | mon, tue, wed, thu, fri |
| poutcome | nonexistent, failure, success |
| y | no, yes |
可以将这11列分为3种类型,具体分类如下图所示。
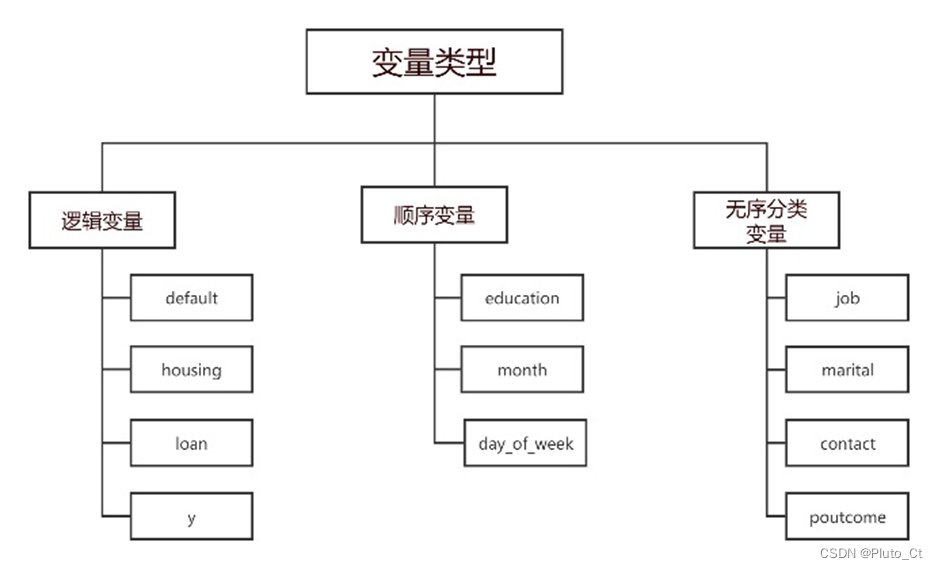
针对3种类型的数据列,采用3种不同的编码方法:
(1)对于逻辑型变量,取值范围为no和yes,分别编号为0和1;
(2)对于顺序型变量,例如“month”,按其月份顺序(may, jun, jul, aug, oct...)进行编码;
(3)对于无序分类型变量,例如“marital”,取值范围为(married, single, divorced),可进行随机编码,并保存编码表备查。
3.2.2 编码过程及结果
各列的编码表如下所示。
逻辑型
| 列名 | 编码 | 属性值 |
| default housing loan y | 0 | no |
| 1 | yes |
顺序型
| 列名 | 编码 | 属性值 |
| education | 1 | illiterate |
| 2 | high school | |
| 3 | junior college | |
| 4 | undergraduate | |
| 5 | postgraduate | |
| month | 1 | jan |
| 2 | feb | |
| 3 | mar | |
| 4 | apr | |
| 5 | may | |
| 6 | jun | |
| 7 | jul | |
| 8 | aug | |
| 9 | sep | |
| 10 | oct | |
| 11 | nov | |
| 12 | dec | |
| day_of_week | 1 | mon |
| 2 | tue | |
| 3 | wed | |
| 4 | thu | |
| 5 | fri |
无序分类型
| 列名 | 编码 | 属性值 |
| job | 1 | housemaid |
| 2 | services | |
| 3 | admin. | |
| 4 | technician | |
| 5 | blue-collar | |
| 6 | unemployed | |
| 7 | retired | |
| 8 | entrepreneur | |
| 9 | management | |
| 10 | student | |
| 11 | self-employed | |
| marital | 1 | married |
| 2 | single | |
| 3 | divorced | |
| contact | 1 | telephone |
| 2 | cellular | |
| poutcome | 1 | nonexistent |
| 2 | failure | |
| 3 | success |
将各列属性值替换为编码,部分结果如下所示,完整结果保存到“result1_3.xlsx”。

四、任务2:产品营销数据可视化分析
基于短期数据分析不同指标客户与购买银行产品行为的关联性,挖掘短期客户对银行的忠诚度。
任务 2.1 计算短期数据所有指标之间的相关性,绘制相关系数热力图,并在报告中对结果进行必要分析。
任务 2.2 在同一画布中,绘制反映两种产品购买结果下不同年龄客户量占比的分组柱状图,x 轴为年龄,y 轴为占比数值,并在报告中对结果进行必要分析。
任务 2.3 在同一画布中,绘制蓝领(blue-collar)与学生(student)的产品购买情况饼图,并设定饼图的标签,显示产品购买情况的占比。
任务 2.4 以产品购买结果为 x 轴、拜访客户的通话时长为 y 轴,绘制拜访客户的通话时长箱线图,并在报告中对结果进行必要分析。
4.1 短期数据指标相关性分析
导入任务1.2编码后的短期数据,使用DataFrame的corr()方法计算各指标间的相关性系数,并使用seaborn绘制热力图如下所示。

如图所示,短期数据中的大部分指标两两之间的相关度小于0.3,相关程度极弱,可视为不相关,其中,duration和y的相关系数为0.39,可视为低度相关。此外,duration、poutcome和contact对y的相关系数相对而言较大,可以推断最近一次拜访客户的通话时长、上一次银行活动,以及联系人通信类型对本次银行活动客户购买产品的影响较大。
4.2 两种产品客户量年龄分析
为方便绘图解释,使用任务1.1的编码前数据。由短期客户产品购买数据指标说明可知,两种购买结果分别为no和yes。对客户年龄列进行描述统计,可知客户最大年龄为95岁,最小年龄为17岁。
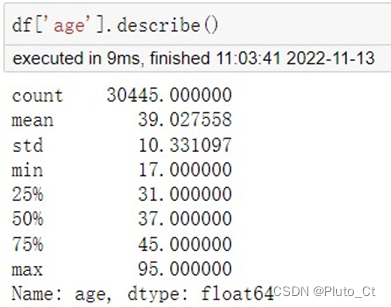
使用pd.cut()分箱统计方法,将年龄列按16-96等距分为8组,步长为10。使用groupby方法按不同的年龄层分组,统计不同产品购买结果下的客户量,并使用seaborn库绘制柱状图对数据进行可视化展现,如下图所示。
进一步对不同产品购买结果下的客户量占比情况进行描述统计和分析,结果如下表和下图所示。
| age_group | no | yes | 该年龄段no占全年龄段比 | 该年龄段yes占全年龄段比 | 年龄段内 no占比 | 年龄段内yes占比 |
| 16-25 | 1088 | 273 | 0.040919177 | 0.070798755 | 0.799412197 | 0.20058780 |
| 26-35 | 10798 | 1552 | 0.406107789 | 0.402489627 | 0.874331984 | 0.12566801 |
| 36-45 | 8288 | 886 | 0.311707849 | 0.229771784 | 0.903422716 | 0.09657728 |
| 46-55 | 4688 | 565 | 0.176313513 | 0.146524896 | 0.892442414 | 0.10755758 |
| 56-65 | 1459 | 352 | 0.054872316 | 0.091286307 | 0.805632247 | 0.19436775 |
| 66-75 | 176 | 135 | 0.006619279 | 0.035010373 | 0.565916399 | 0.43408360 |
| 76-85 | 74 | 79 | 0.002783106 | 0.020487552 | 0.483660131 | 0.51633986 |
| 86-95 | 18 | 14 | 0.000676972 | 0.003630705 | 0.5625 | 0.4375 |
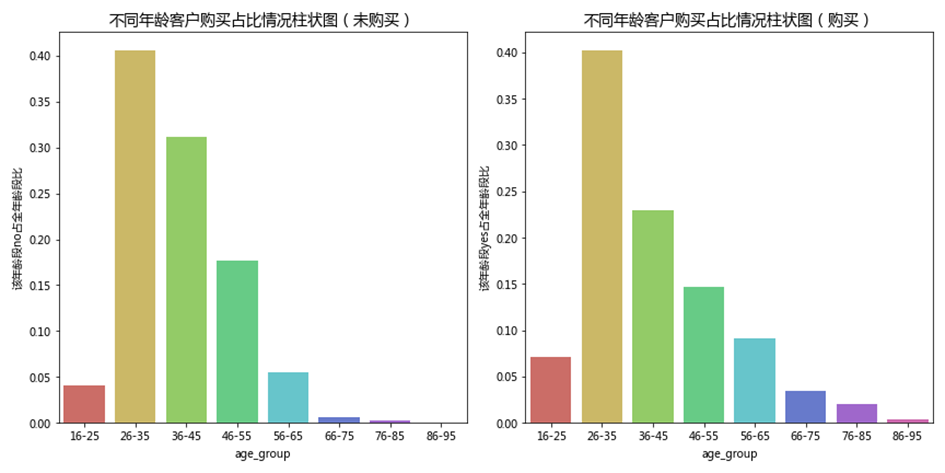
通过对柱状图及统计数据进行分析可知,26-35岁年龄层的客户量最大,其次是36-45岁年龄层。
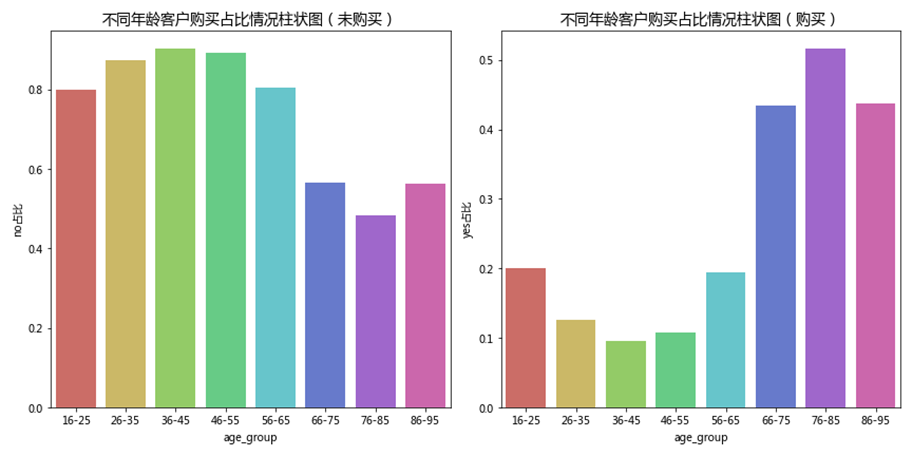
通过对柱状图及统计数据进行分析可知,年龄在36-45岁区间内的,其90.34%的客户都在本次银行活动中选择no(即不购买产品),是各年龄层中忠诚度最低的;年龄在46-55岁和26-35岁区间内的,分别有89.24%和87.43%的客户在本次银行活动中选择不购买产品,表明忠诚度较低;年龄在56-65岁区间内的,有87.43%的客户在本次银行活动中选择不购买产品,忠诚度同样不高。而在66-95岁划分出的三个年龄层内,选择购买(yes)和不购买(no)的客户数占比数值基本持平,说明这三个年龄层的客户对于银行产品有一定的购买依赖。
4.3 蓝领与学生的产品购买情况分析
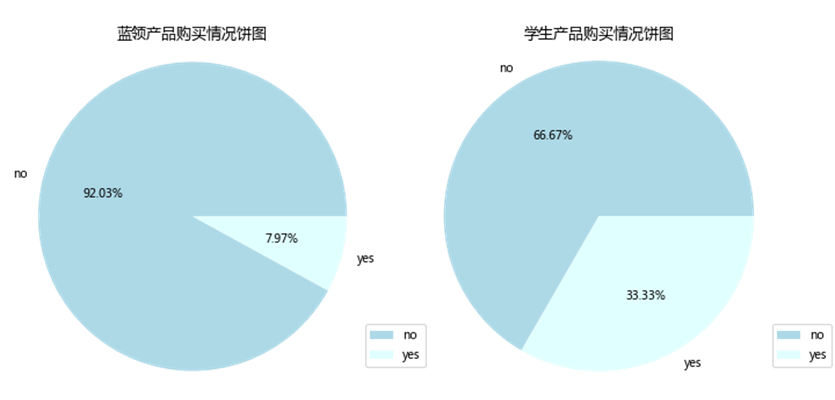
为方便绘图解释,使用任务1.1的编码前数据。使用value_count()方法分别统计蓝领和学生不同购买情况的数量,如下表所示。
| no | yes | |
| blue-collar | 5218 | 452 |
| student | 406 | 203 |
使用matplotlib的subplot将2个饼图绘制在同一画布上,如下图所示。
4.4 产品购买结果和拜访客户的通话时长分析
为方便绘图解释,使用任务1.1的编码前数据。以产品购买结果为 x 轴、拜访客户的通话时长为 y 轴,使用seaborn绘制箱线图,如下图所示。
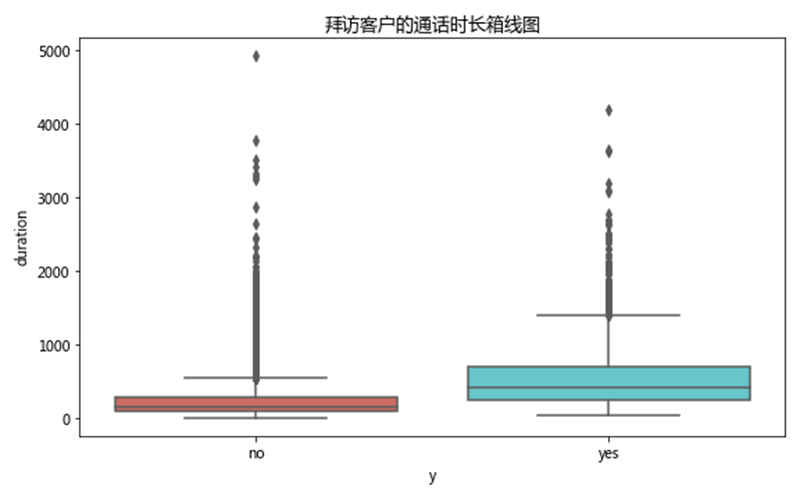
从上图可以看出,购买产品的客户的拜访客户的通话时长的平均值要高于未购买的客户。从离散程度来看,未购买产品客户的通话时长比较集中,而购买产品的客户的通话时长比较分散;从分布形状来看,两种产品购买结果的客户的通话时长均为右偏分布。可以推断出,拜访客户的通话时长对产品购买结果有积极作用。
五、任务3:客户流失因素可视化分析
基于长期数据分析导致银行客户流失的因素,并进行可视化呈现。
任务 3.1 在同一画布中,绘制反映两种流失情况下不同年龄客户量占比的折线图,x轴为年龄,y轴为占比数值。
任务 3.2 在同一画布中,绘制反映两种流失情况下客户信用资格与年龄分布的散点图,x轴为年龄,y轴为信用资格。
任务 3.3 构造包含各账号户龄在不同流失情况下的客户量占比透视表(详见表4),并在同一画布中绘制反映两种流失情况的客户各账号户龄占比量的堆叠柱状图,x轴为客户的户龄,y轴为占比量。
表4 透视表
Exited\Tenure 0 1 2 3 4 5 6 7 8 9 10
0
1
注:Tenure 中的 0,…,10 表示客户的户龄,而 Exited 中的 0 表示客户未流失,1 表示已流失。
任务 3.4 新老客户各资产阶段的客户流失情况分析。
(1) 按照表 5 和表 6 对账号户龄和客户金融资产进行划分,并分别进行特征编码作为新的客户特征,其中客户状态存于“Status”列,资产阶段存于“AssetStage”列,编码结果保存到文件“result3.xlsx”中。
表 5 账号户龄划分情况
账号户龄区间 客户状态
[0, 3] 新客户
(3, 6] 稳定客户
>6 老客户
表 5 账号户龄划分情况
账号户龄区间 客户状态
[0, 3] 新客户
(3, 6] 稳定客户
>6 老客户
(2) 统计新、老客户在各资产阶段中流失的客户量,在同一画布中绘制热力图,热力图颜色的最大和最小取值设为 1300 和 100,并在报告中对结果进行必要分析。
5.1 年龄
由长期客户资源信息数据指标说明可知,两种流失情况分别为1(已流失)和0(未流失)。同理任务2.2,对客户年龄列进行统计,且对两种流失情况下不同年龄客户量占比情况进行分析,部分结果如下图所示。

使用matplotlib绘图工具来绘制折线图对数据进行可视化展现。
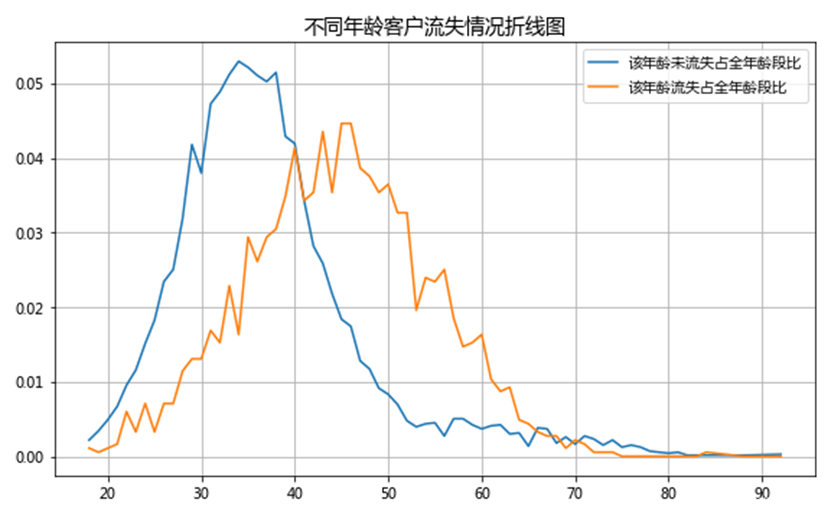
由折线图可知,30-40岁年龄区间内,未流失客户量最大,在区间左端随年龄的减小,未流失客户量递减,在区间右端随年龄增大,未流失客户量递增。40-50岁年龄区间内,流失客户量最多,在区间左端随年龄的减小,流失客户量递减,在区间右端随年龄增大,流失客户量递增。
本文进一步对两种流失情况下不同年龄客户量占比情况进行描述统计和分析,结果如下图所示。
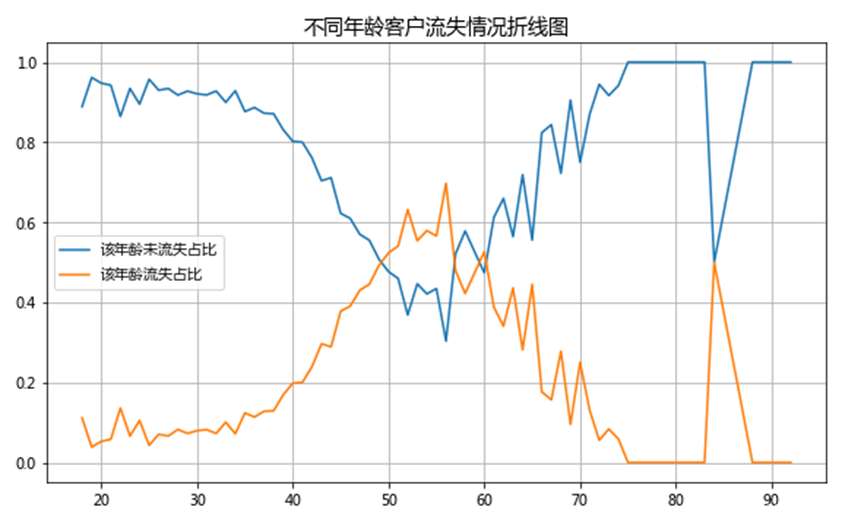
如图所示,青壮年人(18-45岁左右)和老年人(65-92岁左右)这两个年龄段的客户未流失占比较高,客户流失占比较低,说明从长期来看忠诚度较高;而中年人(45-65岁左右)的客户流失和未流失占比几乎持平,说明对银行产品的购买依赖不强。
5.2 客户信用资格和年龄
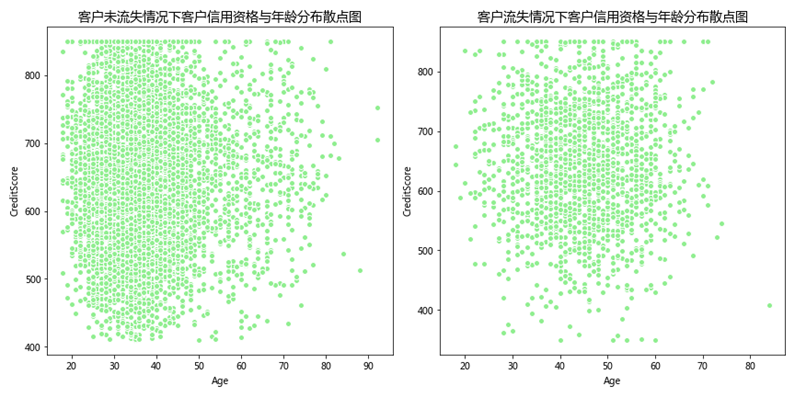
对客户CreditScore (信用资格)列进行统计分析,可知客户的信用资格数值区间为350-850,数值越大表示信用越高。对客户Age(年龄)列进行统计,客户年龄在18-92岁之间。
使用seaborn库的scatterplot()方法绘制散点图,如下图所示。
为方便对散点图进行进一步的分析,使用seaborn库的jointplot()方法绘制带有分布图的散点图,如下图所示。
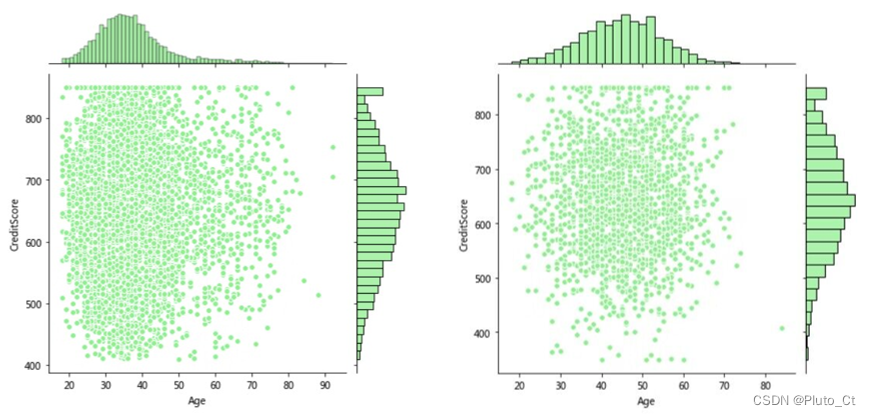
通过分析可得,信用资格处于中上游(500-850)且年龄段在40-55岁左右的中年群体的客户流失量是最大的。
5.3 账号户龄
使用value_counts()分别统计Exited=0和Exited=1的客户数量进行统计,合并为DataFrame,形成透视表,如下所示。
| Exited\Tenure | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 0 | 299 | 740 | 774 | 730 | 728 | 742 | 712 | 788 | 760 | 712 |
| 1 | 85 | 212 | 180 | 187 | 186 | 196 | 178 | 149 | 178 | 197 |
注:Tenure 中的 0,…,10 表示客户的户龄,而 Exited 中的 0 表示客户未流失,1 表示已流失。
使用matplotlib绘制堆叠柱状图,如下所示。
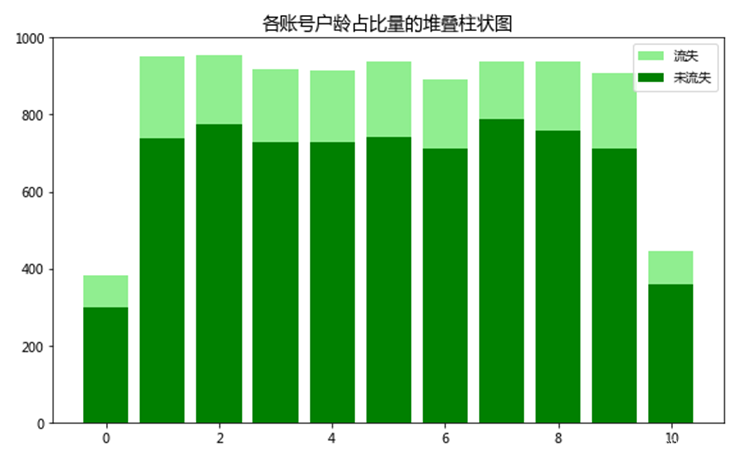
如图所示,账号户龄在0~10之间的客户的流失情况占比基本持平,未流失量是流失量的3、4倍以上,其中账号户龄是0或10的客户总量较少。由此可以推断出,账号户龄与客户的流失情况并无显著的关系。
5.4 客户状态和资产阶段
5.4.1 特征编码
使用pd.cut()函数对账号户龄和客户金融资产列进行划分,由于区间右边闭合,right参数设为True,客户状态存于“Status”列,资产阶段存于“AssetStage” 列,部分结果如下所示,完整结果保存到“result3.xlsx”。
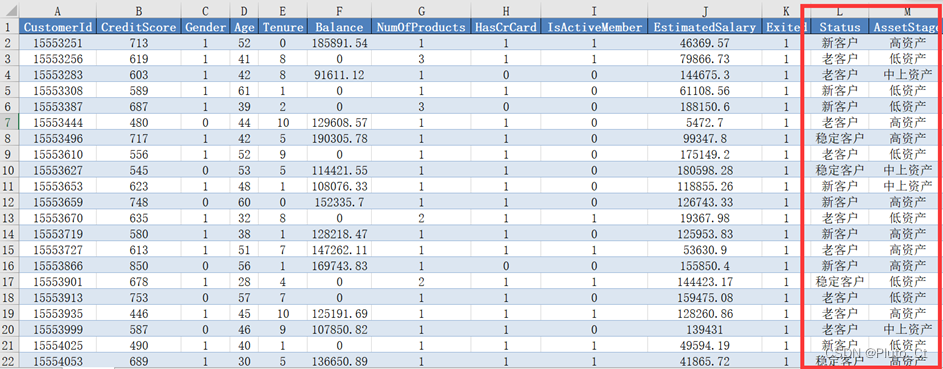
5.4.2 热力图分析
使用groupby()、count()统计新老客户在各资产阶段中流失的客户量,使用unstack()展开为二维表格,seaborn绘制热力图,如下图所示。
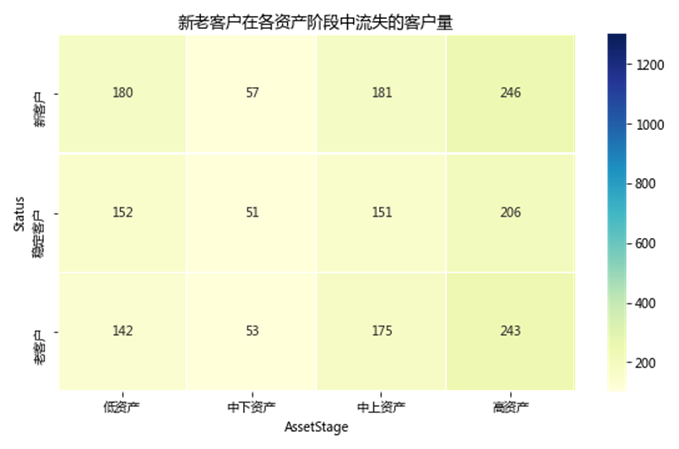
如图所示,新老客户在各资产阶段流失的客户量均较少。进一步分析,三个客户状态下均为高资产的客户流失量最大,低资产和中上资产相差无几,中下资产的客户流失量最少;四个资产阶段下各个状态的客户的流失量几乎持平。由此可以推断,资产阶段是影响客户流失的因素之一。
六、任务4:特征构建
基于长期数据提取影响客户流失的因素,构建与银行客户长期忠诚度相关的特征,将结果保存到文件“result4.xlsx”中。
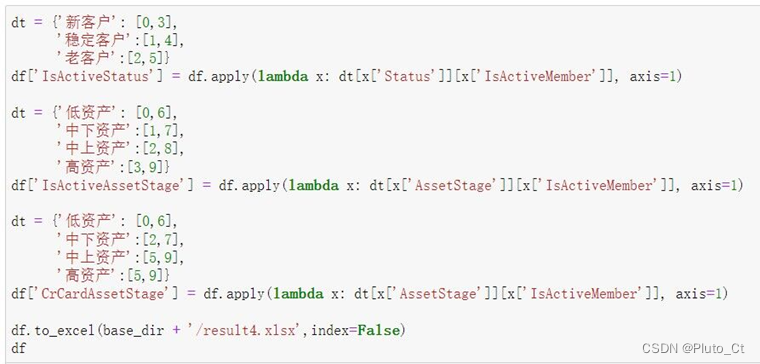
(1) 根据表 7,构建新老客户活跃程度的特征,并将结果存于“IsActiveStatus”列。
表 7 新老客户活跃程度特征构建规则
新老客户活跃程度 活跃状态(0 1)
新客户 0 3
账号户龄 稳定客户 1 4
老客户 2 5
(2) 根据表 8,构建不同金融资产客户活跃程度的特征,并将结果存于“IsActiveAssetStage”列。
表 8 不同存款额客户活跃程度特征构建规则
不同金融资产客户活跃程度 活跃状态(0 1)
资产阶段 低资产 0 6
中下资产 1 7
中上资产 2 8
高资产 3 9
(3) 根据表 9,构建不同金融资产信用卡持有状态的特征,并将结果存于“CrCardAssetStage”列。
表 9 不同金融资产信用卡持有状态特征构建规则
不同金融资产信用卡持有状态 信用卡持有状态(0 1)
资产阶段 低资产 0 6
中下资产 2 7
中上资产 5 9
高资产 5 9
根据题目给出的规则构建dict,使用DataFrame的apply方法创建新列“IsActiveStatus”列、“IsActiveAssetStage”列、“CrCardAssetStage”列,代码如下图所示。
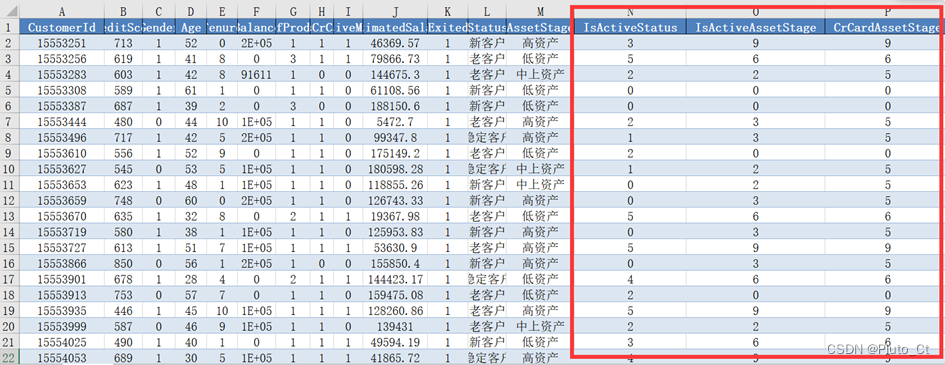
部分结果如下图所示,完整结果保存到“result4.xlsx”。
七、任务5:银行客户长期忠诚度预测建模
7.1 预测模型建立
7.1.1 特征编码选取
本文将长期客户资源信息的9个数据指标即客户信用资格(CreditScore)、性别(Gender)、年龄(Age)、户龄(Tenure)、金融资产(Balance)、客户购买产品数量(NumOfProducts)、持有信用卡状态(HasCrCard)、活动状态(IsActiveMember)、个人年收入(EstimatedSalary)和任务4构建的3中指标即不同金融资产客户活跃程度(IsActiveStatus)、不同存款额客户活跃程度(IsActiveAssetStage)和不同金融资产信用卡持有状态(CrCardAssetStage)进行结合,共选取12项客户特征,用来建立客户长期忠诚度预测模型。
7.1.2 预测模型建立的思路
对长期数据进行分析,可知其存在“Exited”特征分布不均衡、各项数值分布跨度大等问题。具体体现为:未流失客户量是已流失客户量的 3 倍以上;客户信用资格最大数值达到 25万,而客户活动状态则为 0 和 1 等,即样本不均衡和各计量指标的数量级不同。针对样本不均衡,本文采用SMOTE模型过采样实现样本均衡;针对各计量指标的数量级不同,本文用Z-score对指标进行标准化以消除量纲的差异。
之后本文使用SPSSPRO进行机器学习算法的应用与测试,对比分析,选取效果最好的算法进行下一步的预测以得到效果最佳的预测结果。
7.1.3 预测模型建立的过程
(1)Z-score标准化
针对不同属性数值差异大的问题,本文将训练数据使用Z-Score方法进行标准化处理,测试数据使用训练数据的均值和方差进行标准化。
(2)SMOTE过采样
过抽样(也叫上采样、over-sampling)方法通过增加分类中少数类样本的数量来实现样本均衡,最直接的方法是简单复制少数类样本形成多条记录;经过改进的过抽样方法通过在少数类中加入随机噪声、干扰数据或通过一定规则产生新的合成样本,例如SMOTE算法。
SMOTE算法的生成过程为:
①对于少数类中每一个样本x,以欧氏距离为标准计算它到少数类样本集中所有样本的距离,得到其k近邻。
②根据样本不平衡比例设置一个采样比例以确定采样倍率N,对于每一个少数类样本x,从其k近邻中随机选择若干个样本,假设选择的近邻为xn。
③对于每一个随机选出的近邻xn,分别与原样本按照如下的公式构建新的样本。
(3)机器学习分类算法测试与选择
使用SPSSPRO进行机器学习算法的应用与测试,选择较符合本研究目标的八种机器学习算法,按8:2划分训练集和测试集,并测试训练效果,八种机器学习算法在训练集和测试集上的表现如下表所示。
| 机器学习算法 | 训练集准确率 | 验证集准确率 |
| XGBoost | 0.99 | 0.912 |
| GBDT | 0.951 | 0.901 |
| LightGBM | 0.926 | 0.898 |
| CatBoost | 0.897 | 0.87 |
| adaboost | 0.832 | 0.827 |
| 随机森林 | 0.834 | 0.82 |
| 决策树 | 0.813 | 0.796 |
| ExtraTrees | 0.801 | 0.788 |
由上表可以发现,XGBoost在训练集都取得了最好的效果,在测试集上的表现为所有测试算法中最高,因此,选用XGBoost算法训练本文的预测模型。
7.2 预测模型评估
本文基于12个指标构建银行客户长期忠诚度预测模型,采用XGBoost机器学习算法训练分类模型,训练得到的模型取得了较好的效果,具体模型特性与评价如下。
7.2.1 特征重要性排序
对12个特征进行重要性排序,结果如下图所示。
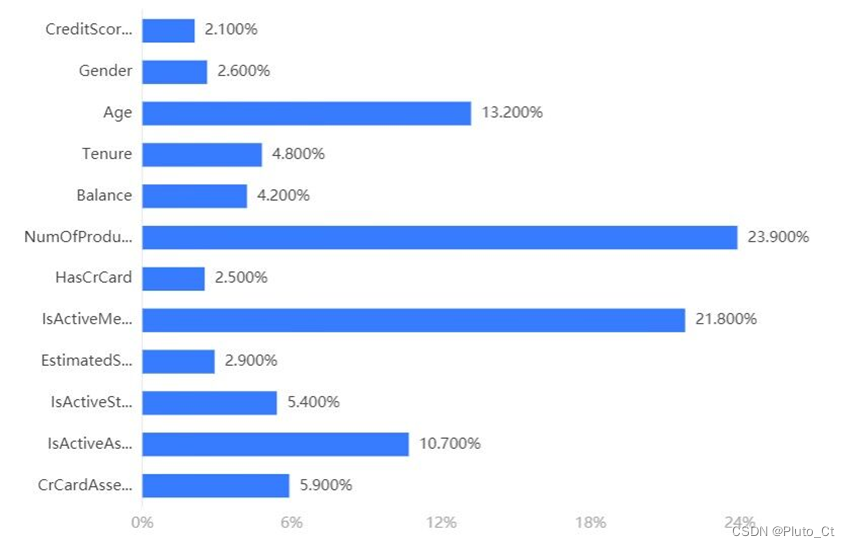
7.2.2 混淆矩阵分析
混淆矩阵(Confusion Matrix)也称误差矩阵,是一种表示精度评价的标准格式,用n行n列矩阵表示。混淆矩阵的每一列代表了预测类别,总数表示预测为该类别的数据的数目;每一行代表了数据的真实归属类别,总数表示该类别的数据实例的数目。
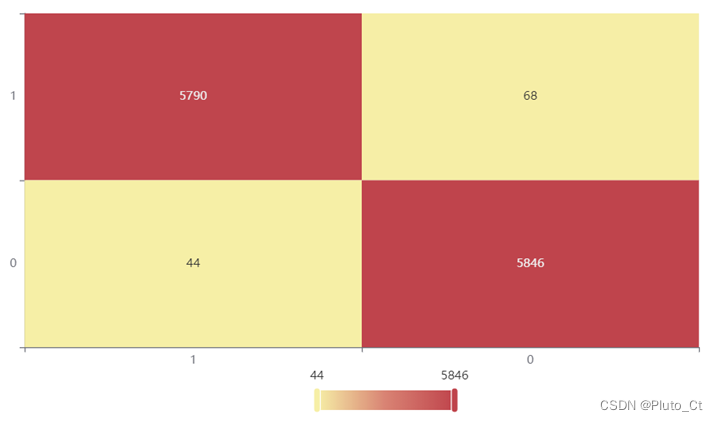 训练集上的混淆矩阵热力图
训练集上的混淆矩阵热力图 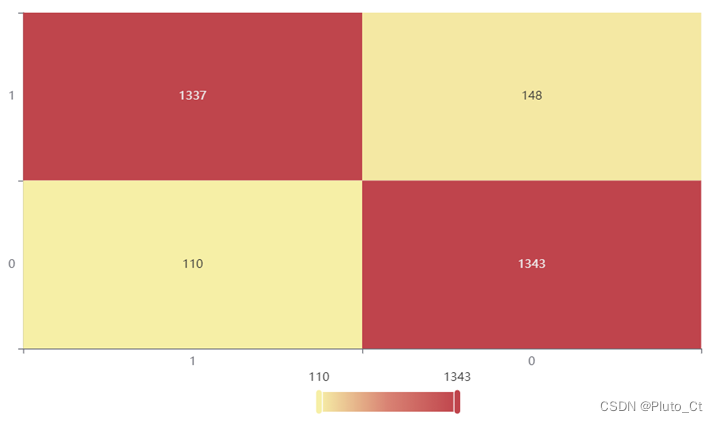 验证集上的混淆矩阵热力图
验证集上的混淆矩阵热力图 7.2.3 模型训练指标评价
| 准确率 | 召回率 | 精确率 | F1 | |
| 训练集 | 0.99 | 0.99 | 0.99 | 0.99 |
| 测试集 | 0.912 | 0.912 | 0.912 | 0.912 |
准确率:预测正确样本占总样本的比例,准确率越大越好。
召回率:实际为正样本的结果中,预测为正样本的比例,召回率越大越好。
精确率:预测出来为正样本的结果中,实际为正样本的比例,精确率越大越好。
F1值:精确率和召回率的调和平均,兼顾两者。
7.3 预测模型应用
对“long-customer-test.csv”测试数据进行预测,5 个客户 ID 的预测结果如下表所示,全部预测结果保存到文件“result5.xlsx”。
| CostomerId | Exited |
| 15579131 | 0 |
| 15674442 | 0 |
| 15719508 | 1 |
| 15730076 | 1 |
| 15792228 | 1 |
八、程序实现代码
2022泰迪杯数据分析技能赛B题代码 Jupyter Notebook https://download.csdn.net/download/u014111377/87287187
https://download.csdn.net/download/u014111377/87287187
九、参考文献
[1]李琼阳,何月华.基于特征选择的存量客户流失预警分析[J].许昌学院学报,2022,41(05):12-15.
[2]吴国华,潘德惠.顾客购买行为影响因素分析及重购概率的预测[J].管理工程学报,2005(01):104-107.
[3]廖开际,邹珂欣,庄雅云.基于改进XGBoost的电商客户流失预测[J].计算机与数字工程,2022,50(05):1115-1118+1125.
[4]祝歆,刘潇蔓,陈树广,李静,张天宇.基于机器学习融合算法的网络购买行为预测研究[J].统计与信息论坛,2017,32(12):94-100.
[5]王萍.运用数据挖掘技术预测客户购买倾向——方法与实证研究[J].情报科学,2005(05):738-741.
十、比赛小结
由于时间原因本次比赛只选择参加了B题,看到A题时发现正是我曾经做过类似的内容,颇感惋惜。本次比赛有些匆忙,还有一些不够完善的地方,再接再厉!