
更多精彩敬请期待:保护小周ღ *★,°*:.☆( ̄▽ ̄)/$:*.°★* ‘

一、 直观上的区别
HashTable 和 HashMap都是用于存储键值对的数据结构
我们一般把搜索的数据称之为关键字 (key), 与关键字 key 对应的为值(value),这种模型统称为
“key -value 的键值对”。
Map 和 Table 采用的都是 key - Value 模型,例如:有一个字符串,统计其中每个字符出现的次数,
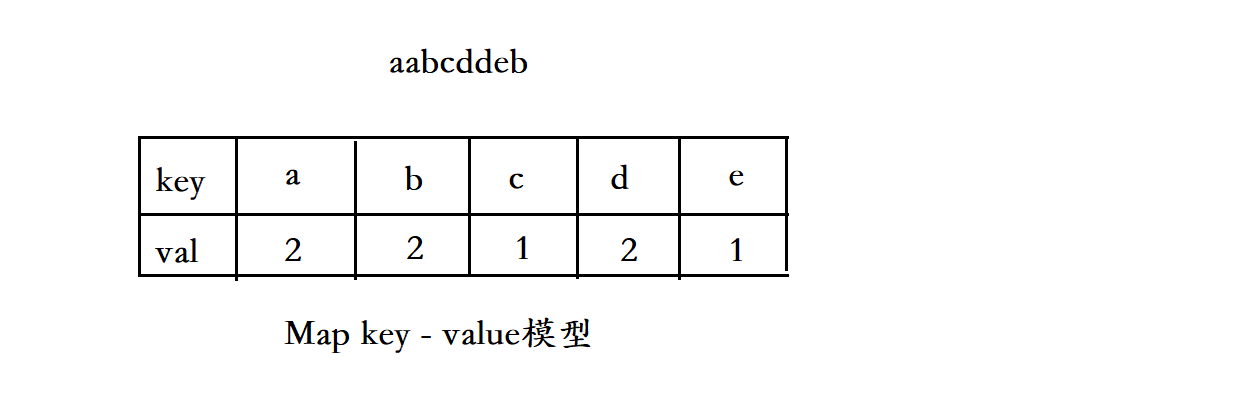
Java 中Map 中的数据结构:
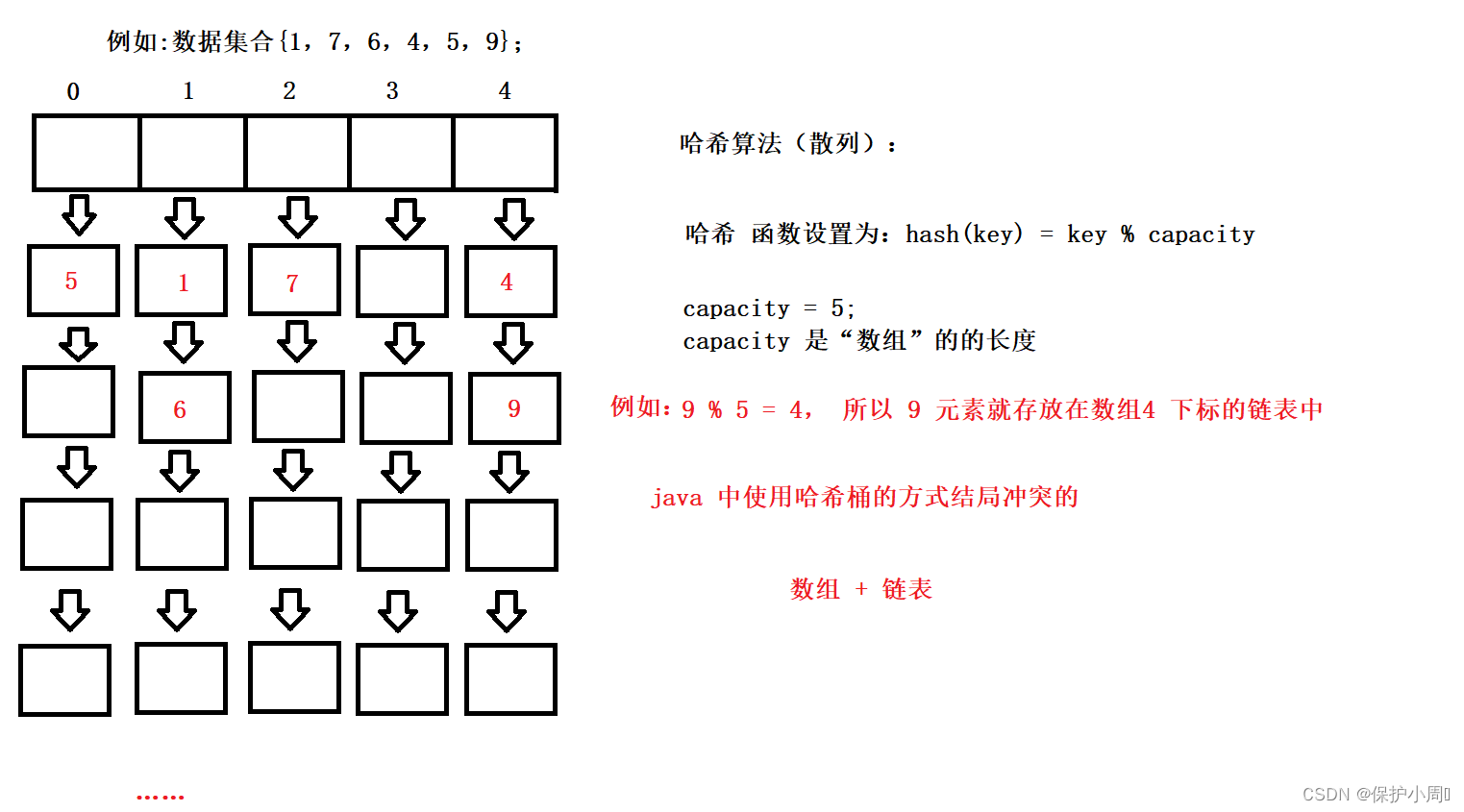
画了一个简单的图理解一下,如果详细的介绍的话恐怕就会脱离主题了。
哈希算法是HashMap的底层实现原理里面很重要的一个组成部分,它来决定数据的位置及访问记录,哈希算法也叫散列算法(Map 的底层数据的存储规则就是使用该算法),把我们存在map中的key(任意长度的值)通过此算法变成固定长度的key(地址),通过这个地址访问数据。
1. HashMap 和 HashTable 的第一点不同,底层数据结构不同: jdk1.7底层都是数组+链表的结构,但jdk1.8 HashMap加入了红黑树,
在JDK1.8之后,HashMap中的链表在满足以下两个条件时,将会转化为红黑树(自平衡的排序二叉搜索树):
1. 数组 array[ i ] 处存放的链表长度大于等于8;
2. 数组长度大于等于64;
满足以上两个条件,数组 array[ i ] 处的链表将自动转化为红黑树,其他位置如 array[ i ]处的数组元素仍为链表。当链表的长度低于 8 的时候又会由红黑树变成链表。
Map 的扩容机制 ,使用了负载因子调节,荷载因子 = 填入表中的元素个数 / 散列表的长度
Java 中限制了荷载因子的大小为 0.75,在实际开发中荷载因子根据业务需要而定,当荷载因子大于 0.75 的时候,意味着 “数组”的长度就需要扩容了,扩容意味着链表中的元素需要重新哈希(使用哈希函数重新计算元素位置并添加),这个开销是非常大的。
2. 初始化容量不同:HashMap 的初始容量为:16,Hashtable 初始容量为:11,两者的负载因子默认都是:0.75。
3. HashMap:在不指定容量的情况下的默认容量为16; 当已用容量>总容量 * 负载因子时,要求一定为2的整数次幂,扩容时将容量变为原来的2倍
Hashtable 扩容规则为当前容量翻倍 +1。
4. Hashtable:key和value都不允许出现null值; HashMap:null能够作为键(key),这样的键只有一个。
二、多线程环境使用哈希表
HashMap 是线程不安全的,在多线程的环境中,还是会存在多个线程并发对同一个共享数据进行操作从而引发的线程安全。
在多线程的环境下可以使用的哈希表有:Hashtable 和 ConcurrentHashMap
接下来就围绕这两种哈希表来展开:
2.1 Hashtable
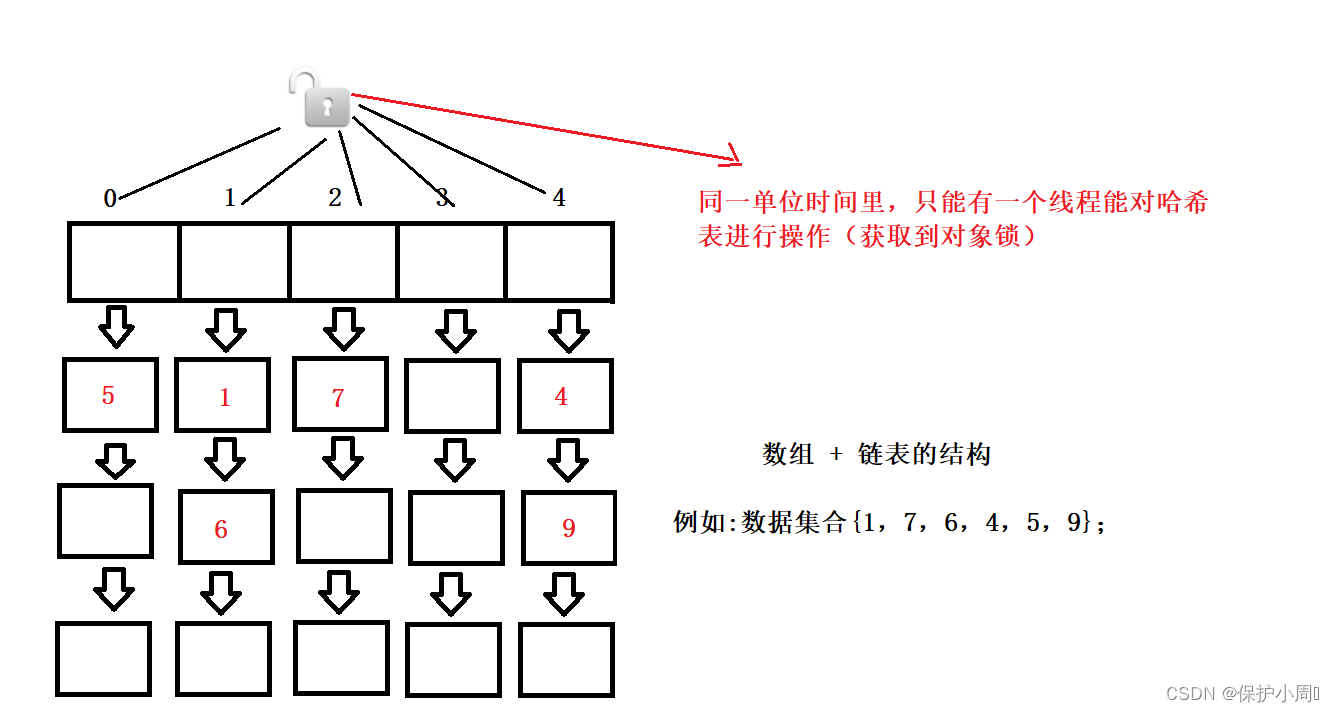
Hashtable 为了保证线程安全问题,将每个关键的方法都加上了 synchronized 关键字,这就相当于针对 hashtable 对象本身加锁,多线程并发执行,同一单位时间内,只能有一个线程能(获取到对象锁,并加锁,一个对象只有一把锁,线程只有拿到锁才能够继续执行)争对 hashtable 进行操作,其他的线程阻塞等待,加锁操作有时间消耗,包括释放锁之后唤醒其他线程来竞争锁都是一笔开销,所以 Hashtable 整体在单线程中效率是低于 hashMap 的,在多线程的环境下效率也是极低的。
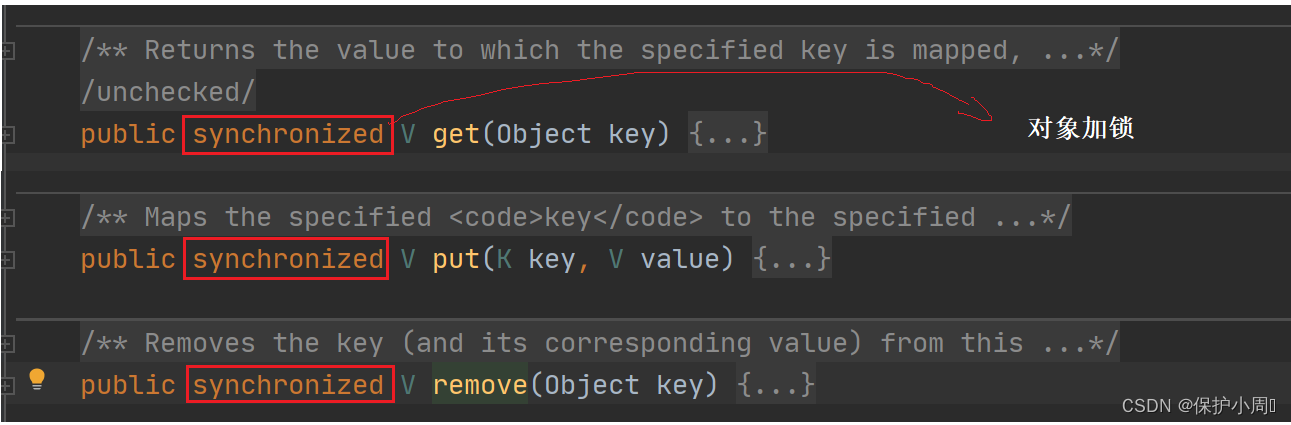
总结:
1. Hashtable保证线程的方式就是争对 Hashtable 对象本身加锁
2. 如果多线程访问同一个Hashtable 就会直接造成锁冲突。
3. 如果在多线程的环境下,一个线程在执行中触发了扩容机制,就会由该线程完成全部数据的重新哈希计算位置,涉及到大量的元素移动,在这个时间里,其他线程只能干等着,所以效率非常低。
2.1 ConcurrentHashMap
这个哈希表可以看作是 hashMap 线程安全的版本,在 JDK 1.7 的时候跟 hashMap 一样都是
数组 + 链表的结构。
在线程安全的角度也是在 hashtable 的基础上做了一系列改进和优化,hashtable 是针对整个对象加锁,在 JDK1 .7 的时候 ConcurrentHashMap 采用的分段加锁的机制,对每一个“段”来加锁。
ConcurrentHashMap由segment 数组结构和 hashEntry 数组结构构成的,即 ConcurrentHashMap 把哈希桶数组切分成小数组(Segment ),每个小数组有 n 个 HashEntry 组成。
每个segment配备一把锁,当一个线程访问其中一段数据时,就会尝试获取 segment 中的对象锁,这样在保证segment锁住的同时而不影响其他线程访问其他的segment, 在保证安全性的同时也提高了效率。
Segment数组的长度是不会被改变的,初始化如果不规定,那么就采用默认的 16,扩容只是针对segment数组内部的HashEnrty数组。

JDK1.8下的ConcurrentHashMap
JDK 1.8以后 hashMap 和 ConcurrentHashMap 底层的结构都改为 数组 + 链表 + 红黑树的结构。
在线程安全方面又做出了进一步的提升:
1. 对ConcurrentHashMap 的读操作没有加锁(get() ,根据key 返回 value 值这些只做查询的方法),而是使用了 volatile 关键字保证内存可见性(保证每次从内存中读取数据),只针对写操作加锁(put() 等方法),而且不是针对 map 对象加锁,也不是针对每一个段加锁,而是针对每个链表的头节点加锁(synchronized 关键字修饰)(每个对象都有一把锁,每个链表,都是一个list 对象,所以可以直接使用 list 的对象锁),这样就实现了更加细粒度的锁。
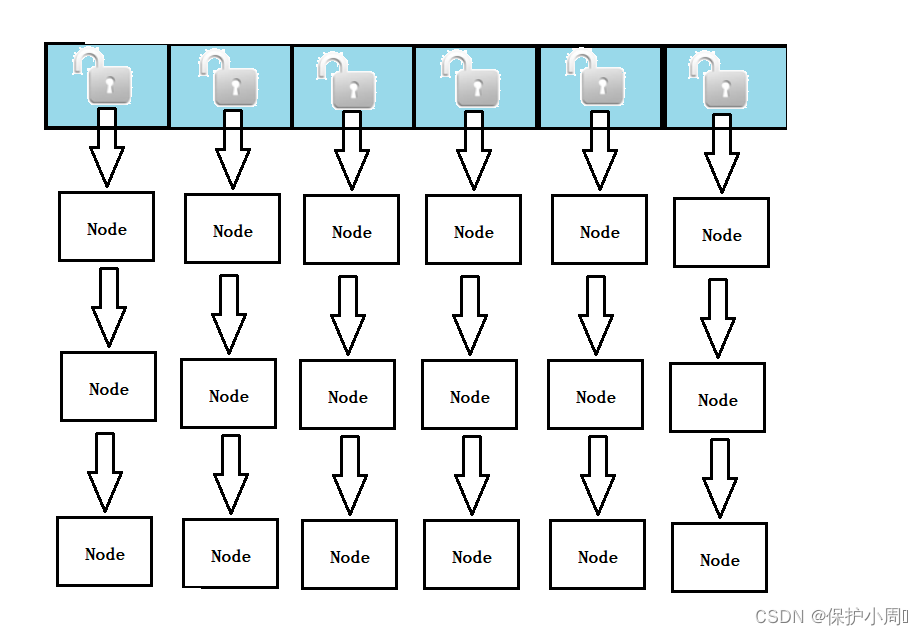
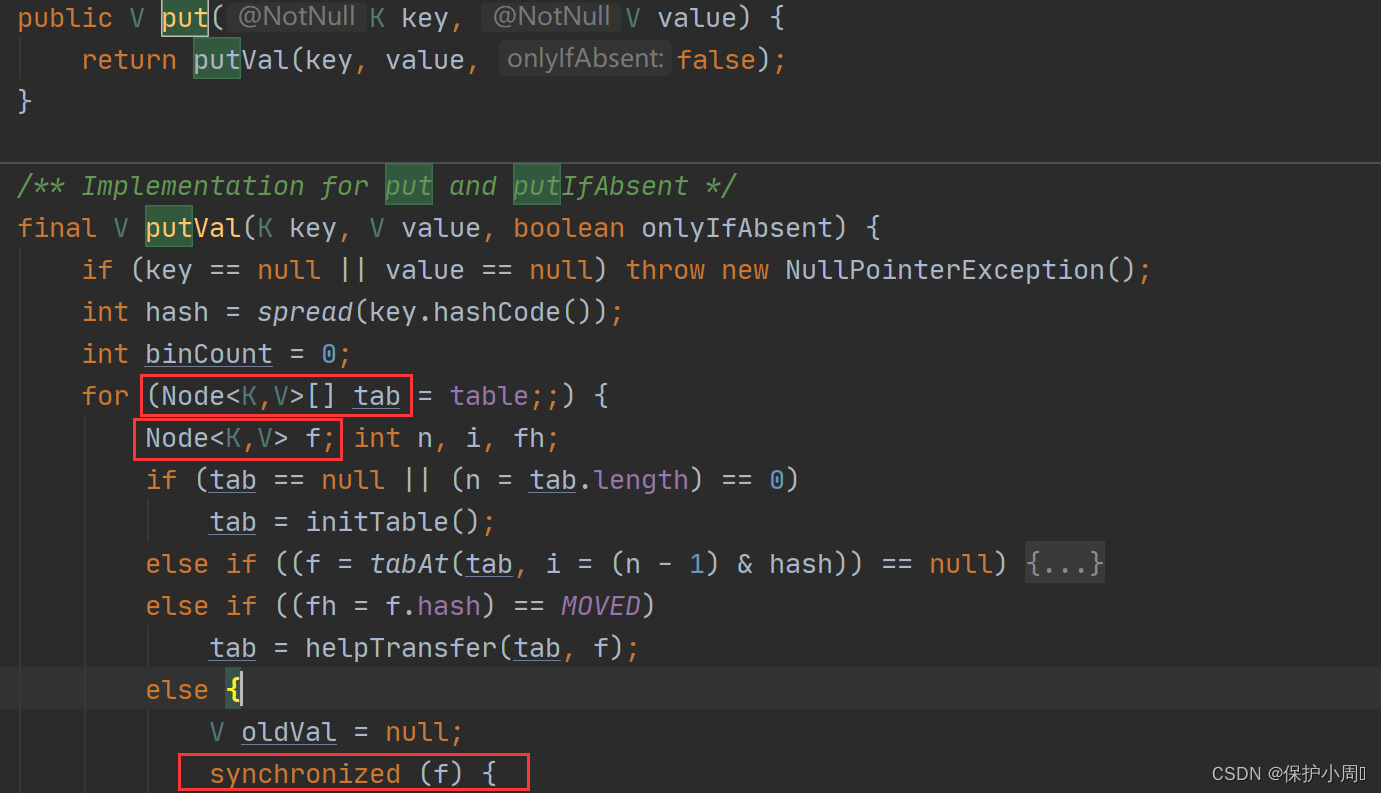
写操作,只是针对链表的加锁。
2. ConcurrentHashMap 在保证线程安全的方面使用的是 CAS(可以看作是硬件支持的原子性操作的指令,适用于无锁编程,也可以保证线程安全问题) 和 synchronized 锁 ,在锁冲突不严重的场景下使用 CAS 自旋来更新数据,可以避免出现了重量级锁的情况。
3. 扩容机制:
当某个线程对 ConcurrentHashMap 进行操作时如果触发了扩容机制,只需要创建一个新的 哈希表,将当前线程操作的链表的部分数据搬运过去,扩容期间,新、老哈希表都存在。后续每个来操作 ConcurrentHashMap 的线程,都会搬运部分元素,直到搬完老哈希表中最后一个元素,再将老哈希表删除。这个期间,插入元素只往新哈希表中添加,查找元素需要同时在新、老哈希表中查询。ConcurrentHashMap 总结:
1. ConcurrentHashMap 的读操作不会加锁,目的是为了进一步降低锁冲突的概率,但是为了保证每次都能从内存中访问数据(防止其他线程对数据更新,当前线程还不知道)使用了 volatile 关键字保证内存可见性。
2. ConcurrentHashMap 的分段锁技术是 JDK 1.7 中采用的技术,就是把若干个哈希桶分成一个“段”(Segment),针对每个分段加锁。Segment数组的长度是不会被改变的,初始化如果不规定,那么就采用默认的 16,扩容只是针对segment数组内部的HashEnrty数组。数据结构结构采用 数组 + 链表的结构;
3. ConcurrentHashMap 在JDK 1.8 中取消了分段锁的安全机制,而是给每个哈希桶(每个链表)分配一个锁,在数据结构方面改进成数组 + 链表 + 红黑树的方式,当链表大于等于8 个元素就转换成红黑树
到这里,HashMap、HashTable、ConcurrentHashMap 之间的区别,博主已经分享完了,希望对大家有所帮助,如有不妥之处欢迎批评指正。

本期收录于博主的专栏——JavaEE,适用于编程初学者,感兴趣的朋友们可以订阅,查看其它“JavaEE基础知识”。
感谢每一个观看本篇文章的朋友,更多精彩敬请期待:保护小周ღ *★,°*:.☆( ̄▽ ̄)/$:*.°★*
遇见你,所有的星星都落在我的头上……