GoogLenet
VGG在2014年由牛津大学著名研究组vGG (Visual Geometry Group)提出,斩获该年lmageNet竞赛中Localization Task (定位任务)第一名和 Classification Task (分类任务)第二名。Classification Task (分类任务)的第一名则是GoogleNet 。GoogleNet是Google研发的深度网络结构,之所以叫“GoogLeNet”,是为了向“LeNet”致敬。
GoogLenet网络亮点
1.引入了Inception结构(融合不同尺度的特征信息)
2.使用1x1的卷积核进行降维以及映射处理
3.添加两个辅助分类器帮助训练
4.丢弃全连接层,使用平均池化层(大大减少模型参数)
Inception结构
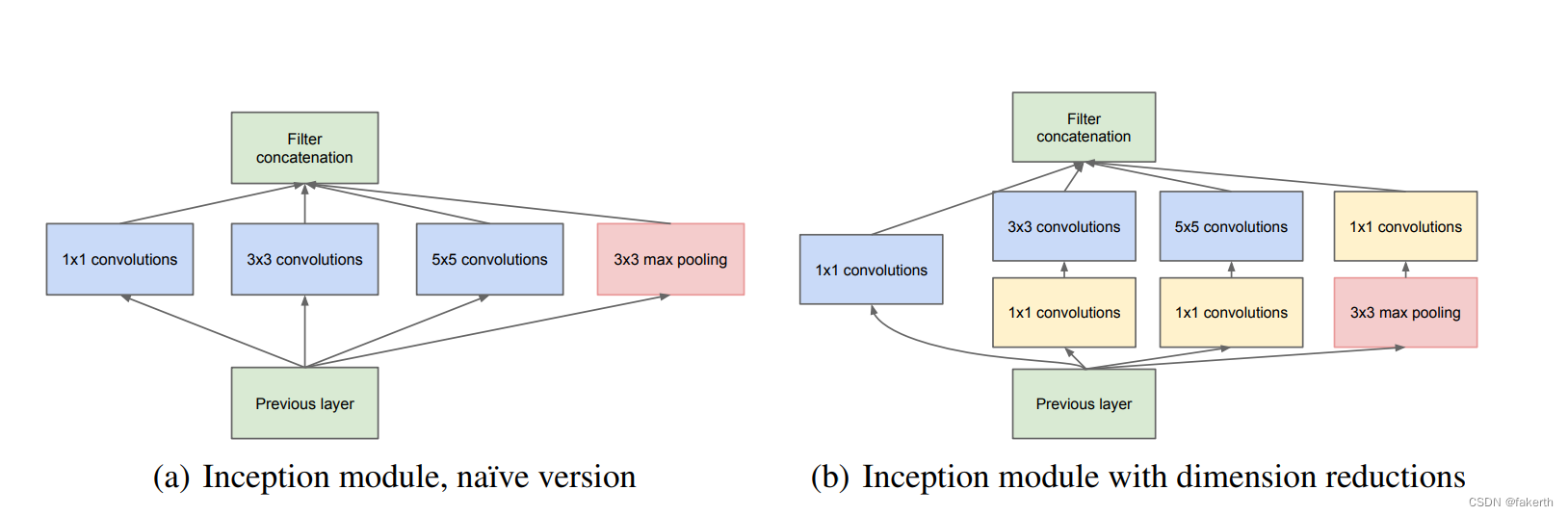
Inception Module基本组成结构有四个成分。1x1卷积,3x3卷积,5x5卷积,3x3最大池化。最后对四个成分运算结果进行通道上组合,这就是Naive Inception(上图a)的核心思想:利用不同大小的卷积核实现不同尺度的感知,最后进行融合,可以得到图像更好的表征。注意,每个分支得到的特征矩阵高和宽必须相同。但是Naive Inception有两个非常严重的问题:首先,所有卷积层直接和前一层输入的数据对接,所以卷积层中的计算量会很大;其次,在这个单元中使用的最大池化层保留了输入数据的特征图的深度,所以在最后进行合并时,总的输出的特征图的深度只会增加,这样增加了该单元之后的网络结构的计算量。所以这里使用1x1 卷积核主要目的是进行压缩降维,减少参数量,也就是上图b,从而让网络更深、更宽,更好的提取特征,这种思想也称为Pointwise Conv,简称PW。
小算一下,假设输入图像的通道是512,使用64个5x5的卷积核进行卷积,不使用1x1卷积核降维需要的参数为512x64x5x5=819200。若使用24个1x1的卷积核降维,得到图像通道为24,再与65个卷积核进行卷积,此时需要的参数为512x24x1x1+24x65x5x5=50688。
辅助分类器
根据实验数据,发现神经网络的中间层也具有很强的识别能力,为了利用中间层抽象的特征,在某些中间层中添加含有多层的分类器。如下图所示,红色边框内部代表添加的辅助分类器。GoogLeNet中共增加了两个辅助的softmax分支,作用有两点,一是为了避免梯度消失,用于向前传导梯度。反向传播时如果有一层求导为0,链式求导结果则为0。二是将中间某一层输出用作分类,起到模型融合作用。最后的loss=loss_2 + 0.3 * loss_1 + 0.3 * loss_0。实际测试时,这两个辅助softmax分支会被去掉。
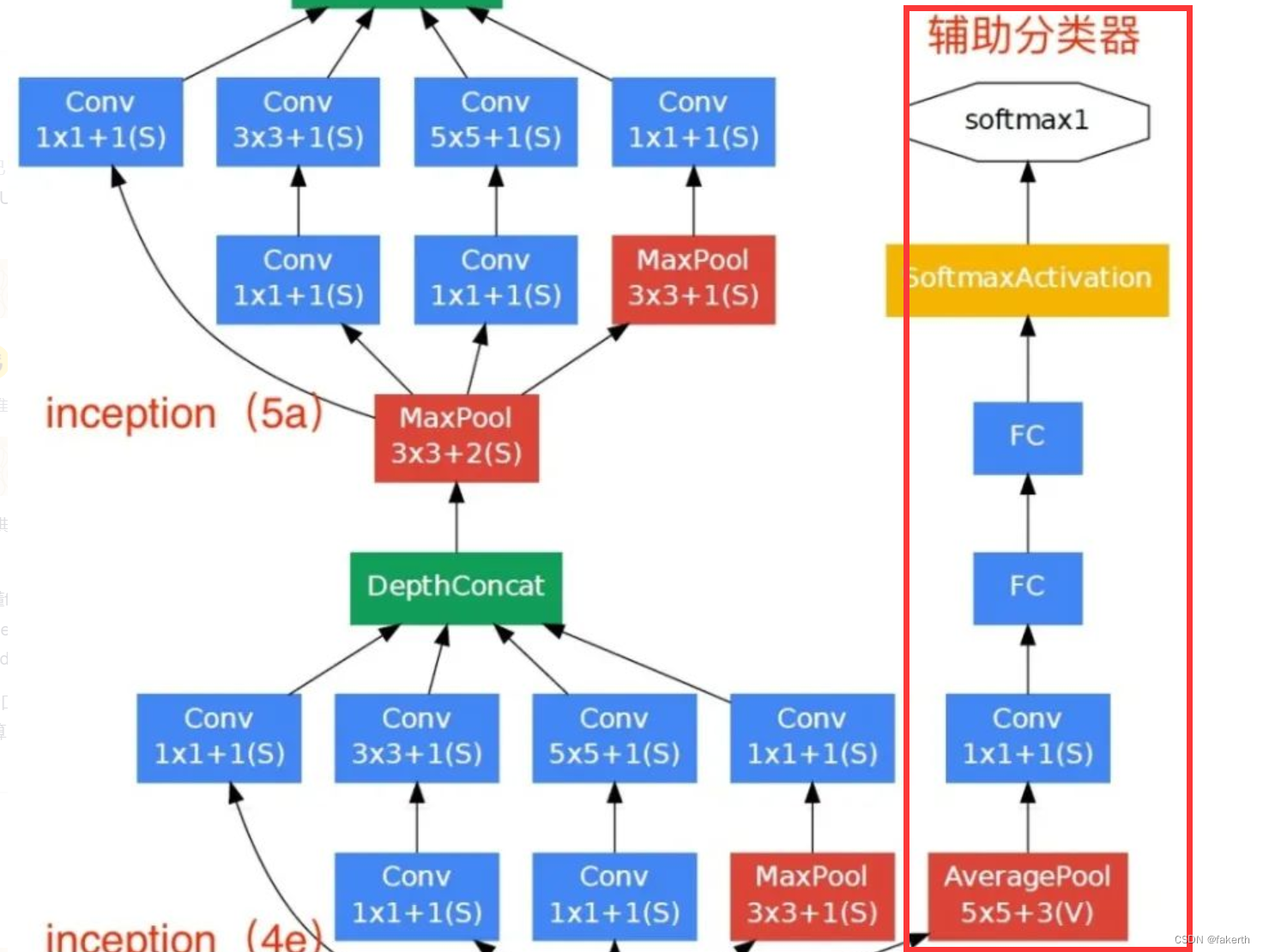
1.平均池化层
窗口大小为5×5,步幅为3,结果是(4a)的输出为4×4×512, (4d)阶段的输出为4×4×528。
2.卷积层
128个1×1卷积核进行卷积(降维),使用ReLU激活函数。
3.全连接层
1024个结点的全连接层,同样使用ReLU激活函数。
4.dropout
dropout,以70%比例随机失活神经元。
5.softmax
通过softmax输出1000个预测结果。
GoogLenet网络结构
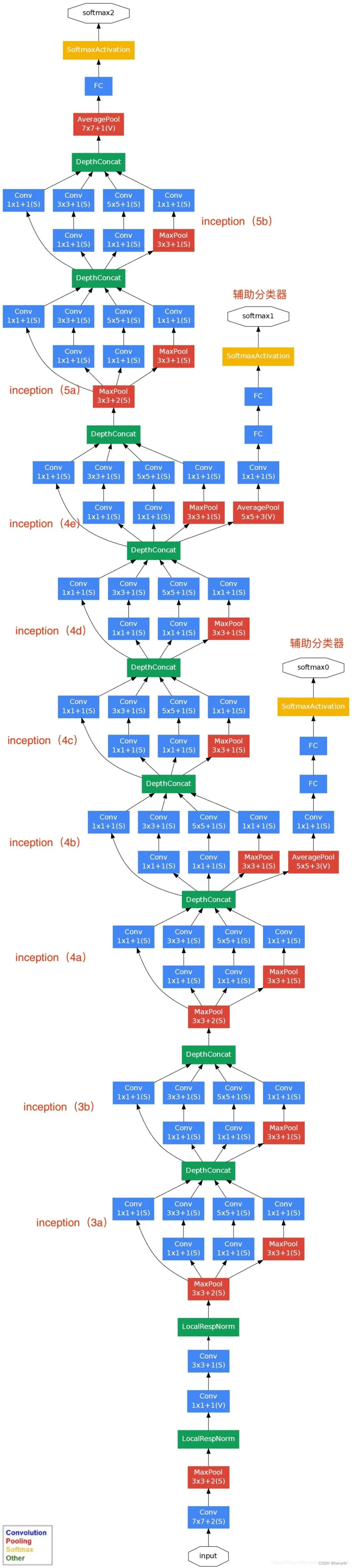
用表格的形式表示GoogLeNet的网络结构如下所示: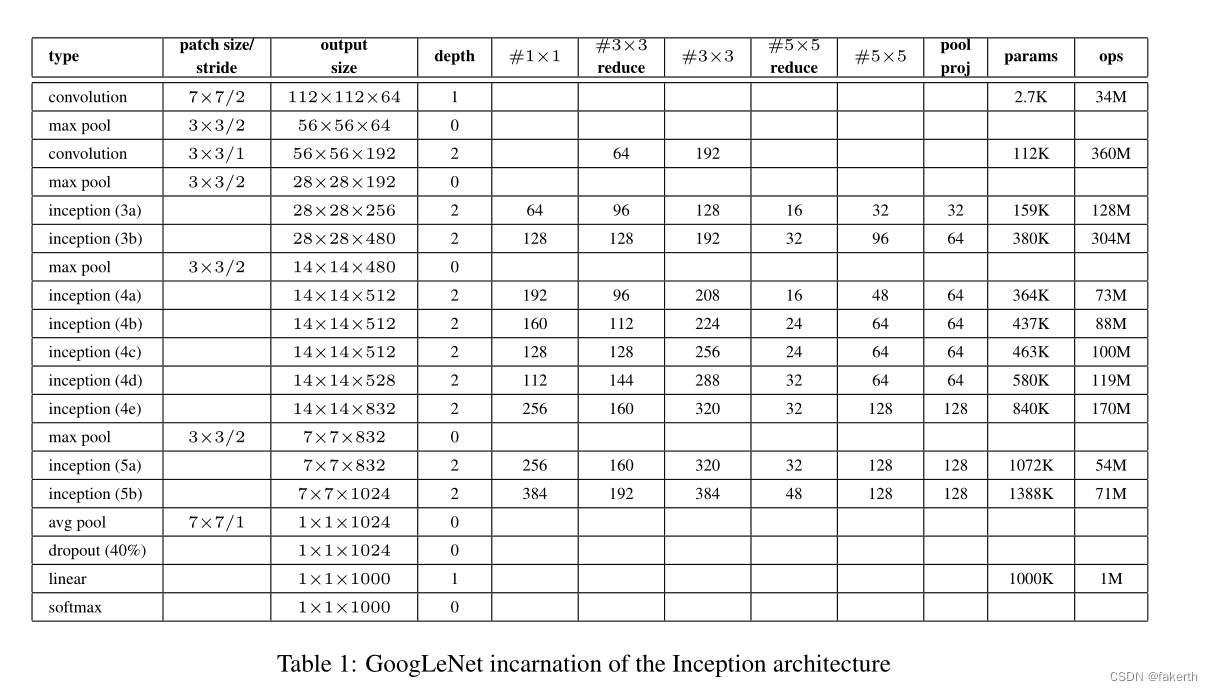
Inception结构的参数怎么看呢?在下面这张图标注出来了。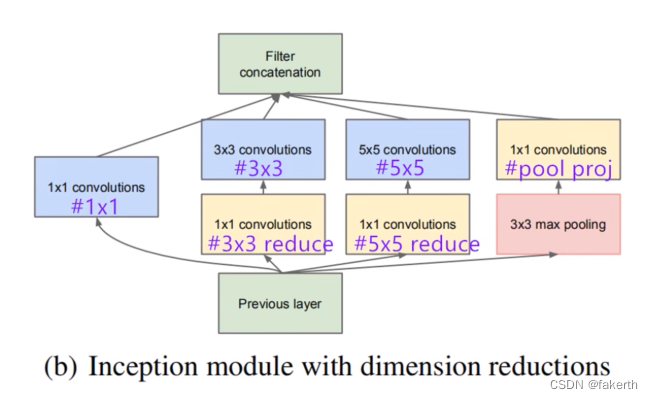
下面就来详细介绍一下GoogLeNet的模型结构。
1.卷积层

输入图像为224x224x3,卷积核大小7x7,步长为2,padding为3,输出通道数64,输出大小为(224-7+3x2)/2+1=112.5(向下取整)=112,输出为112x112x64,卷积后进行ReLU操作。
2.最大池化层

窗口大小3x3,步长为2,输出大小为((112 -3)/2)+1=55.5(向上取整)=56,输出为56x56x64。
3.两层卷积层

第一层:用64个1x1的卷积核(3x3卷积核之前的降维)将输入的特征图(56x56x64)变为56x56x64,然后进行ReLU操作。
第二层:用卷积核大小3x3,步长为1,padding为1,输出通道数192,进行卷积运算,输出大小为(56-3+1x2)/1+1=56,输出为56x56x192,然后进行ReLU操作。
4. 最大池化层

窗口大小3x3,步长为2,输出通道数192,输出为((56 - 3)/2)+1=27.5(向上取整)=28,输出特征图维度为28x28x192。
5.Inception 3a

1.使用64个1x1的卷积核,卷积后输出为28x28x64,然后RuLU操作。
2.96个1x1的卷积核(3x3卷积核之前的降维)卷积后输出为28x28x96,进行ReLU计算,再进行128个3x3的卷积,输出28x28x128。
3.16个1x1的卷积核(5x5卷积核之前的降维)卷积后输出为28x28x16,进行ReLU计算,再进行32个5x5的卷积,输出28x28x32。
4.最大池化层,窗口大小3x3,输出28x28x192,然后进行32个1x1的卷积,输出28x28x32.。
6.Inception 3b
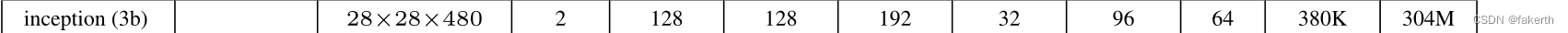
7.最大池化层

8.Inception 4a 4b 4c 4d 4e

9.最大池化层

10.Inception 5a 5b
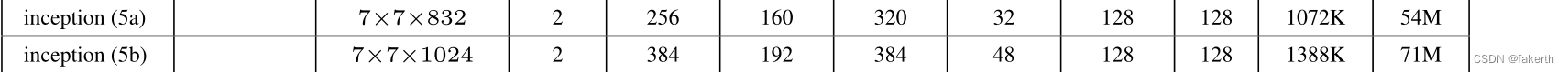
11.输出层

GoogLeNet采用平均池化层,得到高和宽均为1的卷积层;然后dropout,以40%随机失活神经元;输出层激活函数采用的是softmax。
GoogLenet实现
Inception实现
class Inception(nn.Module): def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj): super(Inception, self).__init__() self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1) self.branch2 = nn.Sequential( BasicConv2d(in_channels, ch3x3red, kernel_size=1), BasicConv2d(ch3x3red, ch3x3, kernel_size=3, padding=1) # 保证输出大小等于输入大小 ) self.branch3 = nn.Sequential( BasicConv2d(in_channels, ch5x5red, kernel_size=1), # 在官方的实现中,其实是3x3的kernel并不是5x5,这里我也懒得改了,具体可以参考下面的issue # Please see https://github.com/pytorch/vision/issues/906 for details. BasicConv2d(ch5x5red, ch5x5, kernel_size=5, padding=2) # 保证输出大小等于输入大小 ) self.branch4 = nn.Sequential( nn.MaxPool2d(kernel_size=3, stride=1, padding=1), BasicConv2d(in_channels, pool_proj, kernel_size=1) ) def forward(self, x): branch1 = self.branch1(x) branch2 = self.branch2(x) branch3 = self.branch3(x) branch4 = self.branch4(x) outputs = [branch1, branch2, branch3, branch4] return torch.cat(outputs, 1)GoogLenet实现
import torch.nn as nnimport torchimport torch.nn.functional as Fclass GoogLeNet(nn.Module): def __init__(self, num_classes=1000, aux_logits=True, init_weights=False): super(GoogLeNet, self).__init__() self.aux_logits = aux_logits self.conv1 = BasicConv2d(3, 64, kernel_size=7, stride=2, padding=3) self.maxpool1 = nn.MaxPool2d(3, stride=2, ceil_mode=True) self.conv2 = BasicConv2d(64, 64, kernel_size=1) self.conv3 = BasicConv2d(64, 192, kernel_size=3, padding=1) self.maxpool2 = nn.MaxPool2d(3, stride=2, ceil_mode=True) self.inception3a = Inception(192, 64, 96, 128, 16, 32, 32) self.inception3b = Inception(256, 128, 128, 192, 32, 96, 64) self.maxpool3 = nn.MaxPool2d(3, stride=2, ceil_mode=True) self.inception4a = Inception(480, 192, 96, 208, 16, 48, 64) self.inception4b = Inception(512, 160, 112, 224, 24, 64, 64) self.inception4c = Inception(512, 128, 128, 256, 24, 64, 64) self.inception4d = Inception(512, 112, 144, 288, 32, 64, 64) self.inception4e = Inception(528, 256, 160, 320, 32, 128, 128) self.maxpool4 = nn.MaxPool2d(3, stride=2, ceil_mode=True) self.inception5a = Inception(832, 256, 160, 320, 32, 128, 128) self.inception5b = Inception(832, 384, 192, 384, 48, 128, 128) if self.aux_logits: self.aux1 = InceptionAux(512, num_classes) self.aux2 = InceptionAux(528, num_classes) self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) self.dropout = nn.Dropout(0.4) self.fc = nn.Linear(1024, num_classes) if init_weights: self._initialize_weights() def forward(self, x): # N x 3 x 224 x 224 x = self.conv1(x) # N x 64 x 112 x 112 x = self.maxpool1(x) # N x 64 x 56 x 56 x = self.conv2(x) # N x 64 x 56 x 56 x = self.conv3(x) # N x 192 x 56 x 56 x = self.maxpool2(x) # N x 192 x 28 x 28 x = self.inception3a(x) # N x 256 x 28 x 28 x = self.inception3b(x) # N x 480 x 28 x 28 x = self.maxpool3(x) # N x 480 x 14 x 14 x = self.inception4a(x) # N x 512 x 14 x 14 if self.training and self.aux_logits: # eval model lose this layer aux1 = self.aux1(x) x = self.inception4b(x) # N x 512 x 14 x 14 x = self.inception4c(x) # N x 512 x 14 x 14 x = self.inception4d(x) # N x 528 x 14 x 14 if self.training and self.aux_logits: # eval model lose this layer aux2 = self.aux2(x) x = self.inception4e(x) # N x 832 x 14 x 14 x = self.maxpool4(x) # N x 832 x 7 x 7 x = self.inception5a(x) # N x 832 x 7 x 7 x = self.inception5b(x) # N x 1024 x 7 x 7 x = self.avgpool(x) # N x 1024 x 1 x 1 x = torch.flatten(x, 1) # N x 1024 x = self.dropout(x) x = self.fc(x) # N x 1000 (num_classes) if self.training and self.aux_logits: # eval model lose this layer return x, aux2, aux1 return x def _initialize_weights(self): for m in self.modules(): if isinstance(m, nn.Conv2d): nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu') if m.bias is not None: nn.init.constant_(m.bias, 0) elif isinstance(m, nn.Linear): nn.init.normal_(m.weight, 0, 0.01) nn.init.constant_(m.bias, 0)class Inception(nn.Module): def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj): super(Inception, self).__init__() self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1) self.branch2 = nn.Sequential( BasicConv2d(in_channels, ch3x3red, kernel_size=1), BasicConv2d(ch3x3red, ch3x3, kernel_size=3, padding=1) # 保证输出大小等于输入大小 ) self.branch3 = nn.Sequential( BasicConv2d(in_channels, ch5x5red, kernel_size=1), # 在官方的实现中,其实是3x3的kernel并不是5x5,这里我也懒得改了,具体可以参考下面的issue # Please see https://github.com/pytorch/vision/issues/906 for details. BasicConv2d(ch5x5red, ch5x5, kernel_size=5, padding=2) # 保证输出大小等于输入大小 ) self.branch4 = nn.Sequential( nn.MaxPool2d(kernel_size=3, stride=1, padding=1), BasicConv2d(in_channels, pool_proj, kernel_size=1) ) def forward(self, x): branch1 = self.branch1(x) branch2 = self.branch2(x) branch3 = self.branch3(x) branch4 = self.branch4(x) outputs = [branch1, branch2, branch3, branch4] return torch.cat(outputs, 1)class InceptionAux(nn.Module): def __init__(self, in_channels, num_classes): super(InceptionAux, self).__init__() self.averagePool = nn.AvgPool2d(kernel_size=5, stride=3) self.conv = BasicConv2d(in_channels, 128, kernel_size=1) # output[batch, 128, 4, 4] self.fc1 = nn.Linear(2048, 1024) self.fc2 = nn.Linear(1024, num_classes) def forward(self, x): # aux1: N x 512 x 14 x 14, aux2: N x 528 x 14 x 14 x = self.averagePool(x) # aux1: N x 512 x 4 x 4, aux2: N x 528 x 4 x 4 x = self.conv(x) # N x 128 x 4 x 4 x = torch.flatten(x, 1) x = F.dropout(x, 0.5, training=self.training) # N x 2048 x = F.relu(self.fc1(x), inplace=True) x = F.dropout(x, 0.5, training=self.training) # N x 1024 x = self.fc2(x) # N x num_classes return xclass BasicConv2d(nn.Module): def __init__(self, in_channels, out_channels, **kwargs): super(BasicConv2d, self).__init__() self.conv = nn.Conv2d(in_channels, out_channels, **kwargs) self.relu = nn.ReLU(inplace=True) def forward(self, x): x = self.conv(x) x = self.relu(x) return x训练模型
import osimport sysimport jsonimport torchimport torch.nn as nnfrom torchvision import transforms, datasetsimport torch.optim as optimfrom tqdm import tqdmfrom model import GoogLeNetdef main(): device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") print("using {} device.".format(device)) data_transform = { "train": transforms.Compose([transforms.RandomResizedCrop(224), transforms.RandomHorizontalFlip(), # 随机左右翻转 # transforms.RandomVerticalFlip(), # 随机上下翻转 transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5, hue=0.1), transforms.RandomRotation(degrees=5), transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]), "val": transforms.Compose([transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])} train_dataset = datasets.ImageFolder(root='./Training', transform=data_transform["train"]) train_num = len(train_dataset) flower_list = train_dataset.class_to_idx cla_dict = dict((val, key) for key, val in flower_list.items()) json_str = json.dumps(cla_dict, indent=4) with open( 'class_indices.json', 'w') as json_file: json_file.write(json_str) batch_size = 32 nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers print('Using {} dataloader workers every process'.format(nw)) train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=nw) validate_dataset = datasets.ImageFolder(root='./Test', transform=data_transform["val"]) val_num = len(validate_dataset) validate_loader = torch.utils.data.DataLoader(validate_dataset, batch_size=batch_size, shuffle=False, num_workers=nw) print("using {} images for training, {} images for validation.".format(train_num, val_num)) # test_data_iter = iter(validate_loader) # test_image, test_label = test_data_iter.next() net = GoogLeNet(num_classes=131, aux_logits=True, init_weights=True) # num_classes根据分类的数量而定 # 如果要使用官方的预训练权重,注意是将权重载入官方的模型,不是我们自己实现的模型 # 官方的模型中使用了bn层以及改了一些参数,不能混用 # import torchvision # net = torchvision.models.googlenet(num_classes=5) # model_dict = net.state_dict() # # 预训练权重下载地址: https://download.pytorch.org/models/googlenet-1378be20.pth # pretrain_model = torch.load("googlenet.pth") # del_list = ["aux1.fc2.weight", "aux1.fc2.bias", # "aux2.fc2.weight", "aux2.fc2.bias", # "fc.weight", "fc.bias"] # pretrain_dict = {k: v for k, v in pretrain_model.items() if k not in del_list} # model_dict.update(pretrain_dict) # net.load_state_dict(model_dict) net.to(device) loss_function = nn.CrossEntropyLoss() optimizer = optim.Adam(net.parameters(), lr=0.0003) epochs = 30 best_acc = 0.0 save_path = './googleNet.pth' train_steps = len(train_loader) for epoch in range(epochs): # train net.train() running_loss = 0.0 train_bar = tqdm(train_loader, file=sys.stdout) for step, data in enumerate(train_bar): images, labels = data optimizer.zero_grad() logits, aux_logits2, aux_logits1 = net(images.to(device)) loss0 = loss_function(logits, labels.to(device)) loss1 = loss_function(aux_logits1, labels.to(device)) loss2 = loss_function(aux_logits2, labels.to(device)) loss = loss0 + loss1 * 0.3 + loss2 * 0.3 loss.backward() optimizer.step() # print statistics running_loss += loss.item() train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1, epochs, loss) # validate net.eval() acc = 0.0 # accumulate accurate number / epoch with torch.no_grad(): val_bar = tqdm(validate_loader, file=sys.stdout) for val_data in val_bar: val_images, val_labels = val_data outputs = net(val_images.to(device)) # eval model only have last output layer predict_y = torch.max(outputs, dim=1)[1] acc += torch.eq(predict_y, val_labels.to(device)).sum().item() val_accurate = acc / val_num print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' % (epoch + 1, running_loss / train_steps, val_accurate)) if val_accurate > best_acc: best_acc = val_accurate torch.save(net.state_dict(), save_path) print('Finished Training')if __name__ == '__main__': main()