⭐️我叫忆_恒心,一名喜欢书写博客的在读研究生??。
如果觉得本文能帮到您,麻烦点个赞?呗!
近期会不断在专栏里进行更新讲解博客~~~ 有什么问题的小伙伴 欢迎留言提问欧,喜欢的小伙伴给个三连支持一下呗。?⭐️❤️Qt5.9专栏定期更新Qt的一些项目Demo项目与比赛专栏定期更新比赛的一些心得,面试项目常被问到的知识点。
⭐️最近在整理以前的学习资料时,看到了之前之前入门NLP的一些学习笔记,就进行了一些整理。

目录
一、热点与背景二、什么是自然语言处理三、目前自然语言处理有哪些挑战呢?四、Word2Vec4.1 为什么要学习`Word2Vec`4.2 为什么需要词向量?1、词语序的问题2、词相似性带来的问题 4.3 Word2Vec有什么意义呢?4.4 Word2Vec的维度意义一、**词向量模型训练**二、词向量模型训练--黑盒三、Word2Vec的实现方法四、直接建模的问题——以Skip-gram为例五、负采样方法的引入——以Skip-gram为例六、小结附录:词向量长什么样子:
一、热点与背景
各位同学,欢迎来到今天的课程!我们将会探索一门有趣且富有挑战性的领域——自然语言处理。在本次课程中,我将先介绍一下当下人工智能领域的热点,以此引出什么是什么是自然语言处理,以及它的应用,以及自然语言基石的“词向量Word2Vec。
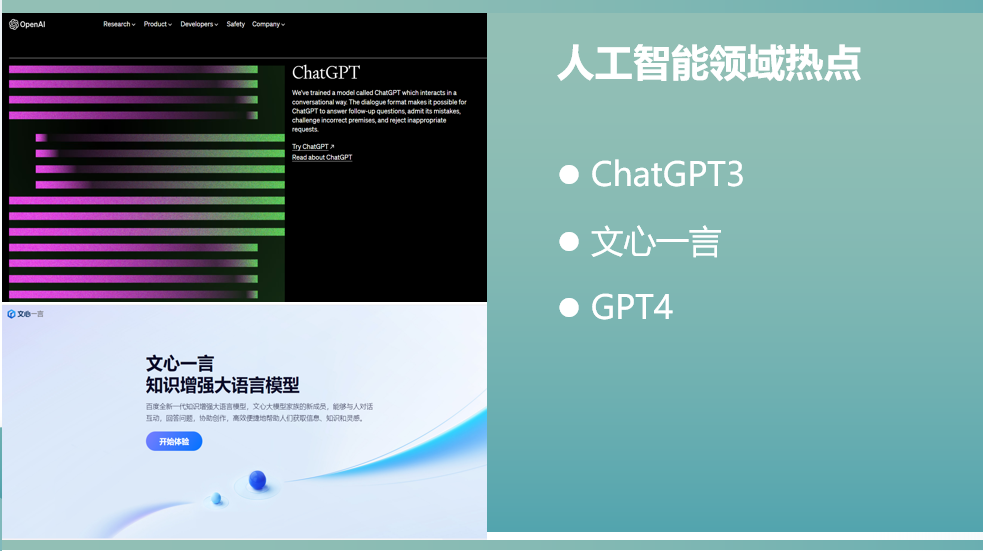
相信各位同学最近都听过ChatGPT,GPT-4,百度的文言一心甚至有些同学也已经玩上了这些工具,大家都知道这是人工智能的产物,但是ChatGPT有哪些功能,我们进行一个简单的介绍。
我们输入一句:
作为一名刚入门自然语言处理的同学,第一堂课的学习,你能给些建议吗?即使这个输入,可能含有错别字。
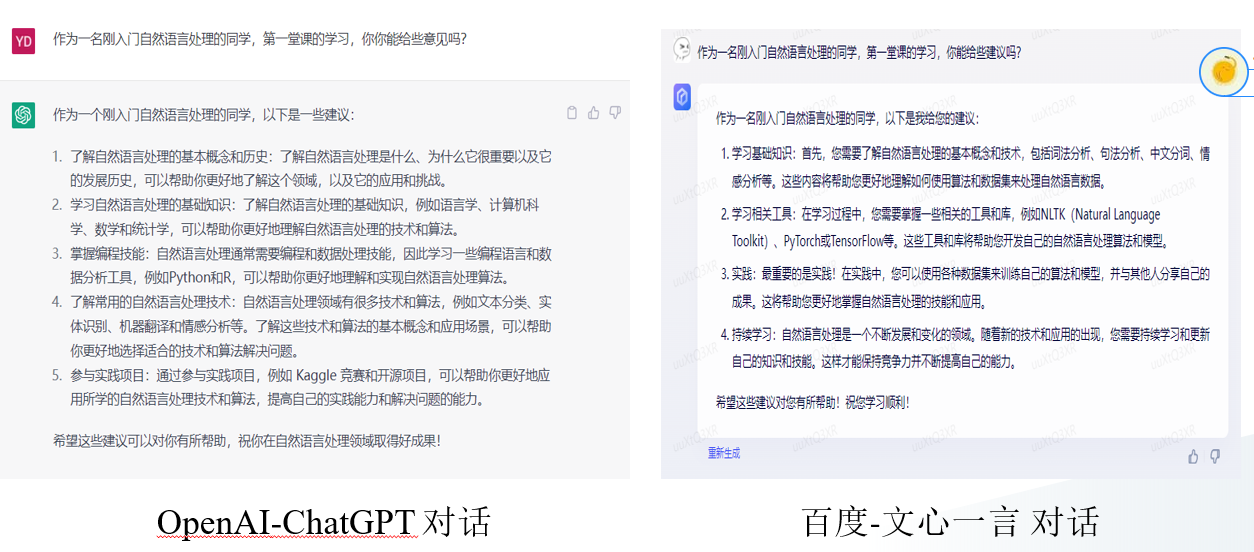
那这背后运用的是那些技术的呢?
是CV还是自然语言处理
二、什么是自然语言处理
上述设计到的模型所用的人工智能领域技术是自然语言处理,那么什么是自然语言处理呢?
我们来看一下维基百科上是如何进行定义的:
计算机科学与语言学领域交叉的一门学科,目的是让计算机能够理解、解释、生成人类语言。这么说可能会优点抽象,简单来说就是:
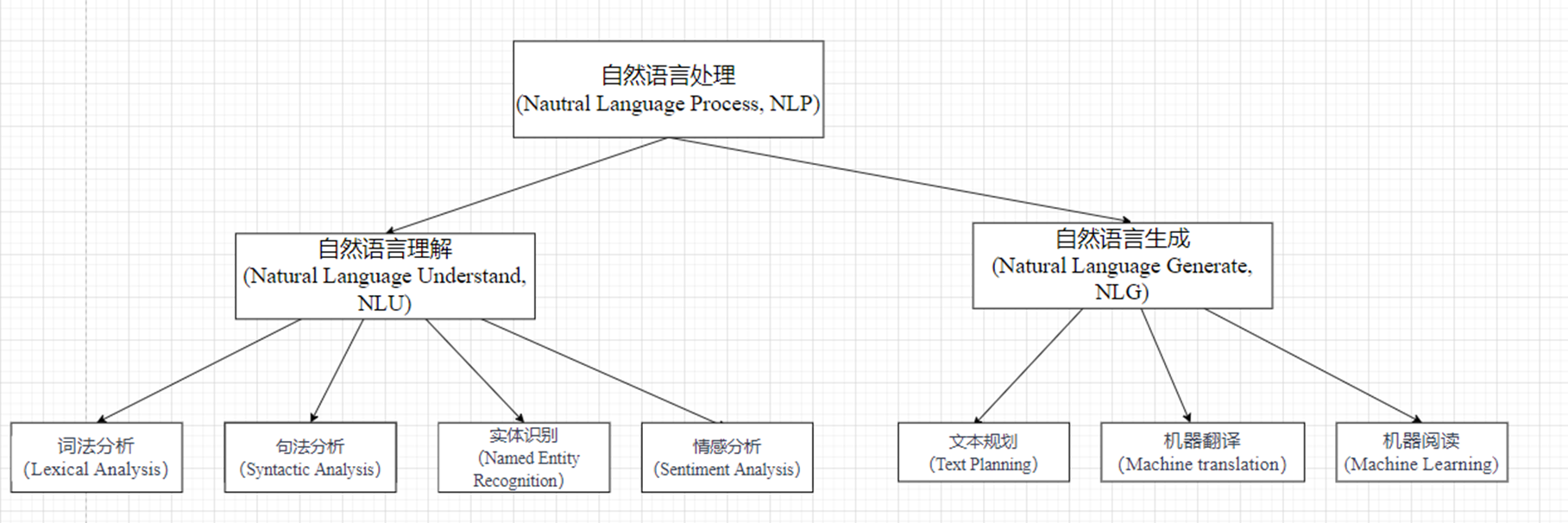
自然语言处理 (Nautral Language Process, NLP) =自然语言理解(Natural Language Understand, NLU) + 自然语言生成
(Natural Language Generate, NLG)。
可能这在你看来是很神奇的一件事情,但其实ChatGPT也就做了这两部分的内容。
总的来说:NLP = NLU + NLR。
ChatGPT可以说是自然语言处理综合应用的一个典型的模型了

自然语言处理技术可以看出是两个阶段。
我们以ChatGPT为例,他是如何做到这些功能的呢?
(通过一个图 人–>电脑 电脑—人)
以ChatGPT为例,我们每一次向他输入一段话的时候,会发生哪些事情呢?
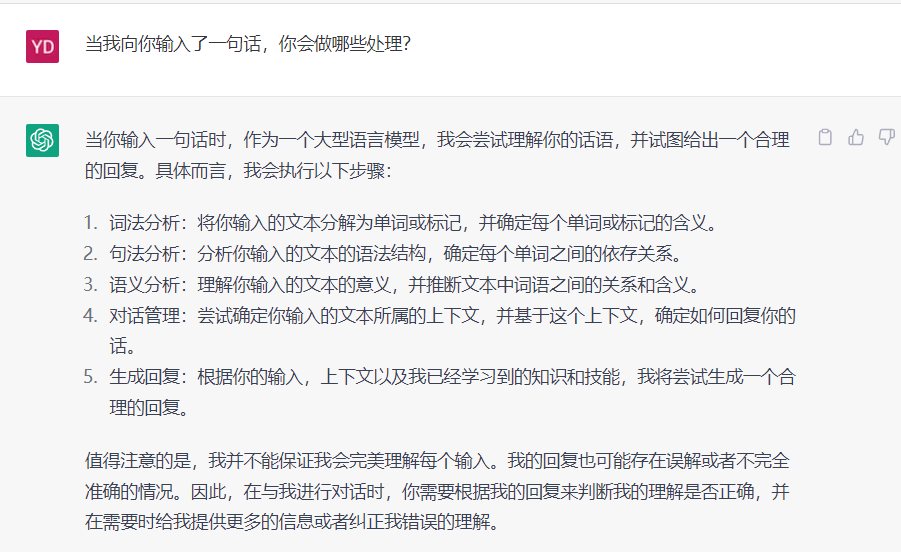
其中词法分析、句法分析、语义分析属于NLU任务,对话管理、生成回复属于NLG任务。
我门进行一个简单的小结。
三、目前自然语言处理有哪些挑战呢?
与图像处理相比,自然语言处理更为复杂。
图像:所见即所得
文本:所要的文字背后的语义。
简单来说自然语言处理,普遍遇到以下三个问题:

万丈高楼平地起,接下来我们讲解一下自然语言处理的基石Word2Vec
四、Word2Vec
自然语言处理以及语言模型的本质是词向量。
我们以问题为导向进行Word2Vec的学习。
4.1 为什么要学习Word2Vec
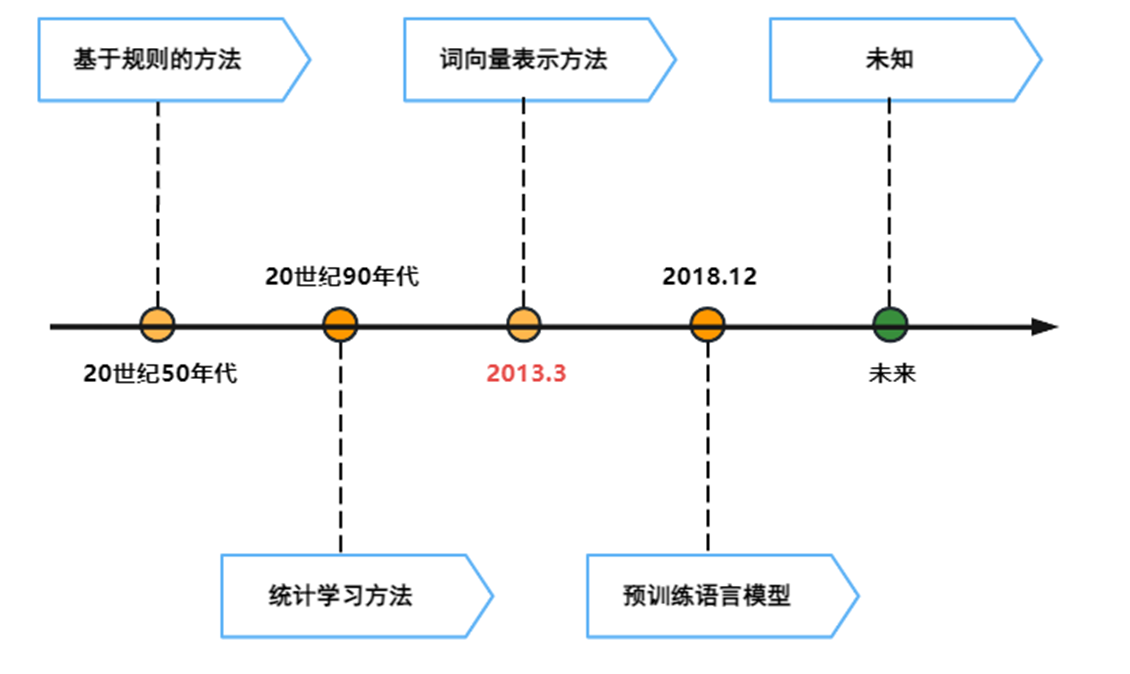
从自然语言的发展趋势来看:
从词向量表示方法出现后,短短5年时间,自然语言处理就得到了大幅度进展(预训练语言模型BERT、GPT).。
4.2 为什么需要词向量?
一句话或一个文章都是一个词一个词组成。
解决了基于规则和基于统计学习方法遗留的问题:
•输入词的语序问题。
•词之间相似性的问题。
1、词语序的问题
基于统计的方法:
只看一个词的出现和总体的关系。
但是这种统计词频,避免不了一个问题,就是比如一个词出现在不同的位置,所表达的语义是不同的。如下面的例句。
Input1:我|要|学习|自然|语言|处理。
Input2:我|要|语言|自然|地|学习。
2、词相似性带来的问题
比如:
“自然语言处理”=“NLP”
但与“吃饭”无关。
不同语义的文字相似度应该低,相同语义的相似度高。
具体表现在二维空间上是距离的疏远

相关性
越相近的表达离得越近 。
通过一些问题来解释。
这里有个前提大家先熟悉了神经网络,不过多强调神经网络而是把重点放到词向量模型中。
先考虑第一个问题:
4.3 Word2Vec有什么意义呢?
看起来比较抽象,可以先从人的角度来观察。
比如说,现在来了一个人,我们应该如何对其进行描述呢?

对一个人进行打分,一个指标相当于一个维度****。
身高、性格、能力等综合特征多个维度构成了一个独特的人的描述。
当我们有了这种多个指标构成的多种维度时,我们就可以进行向量的运算。
比如相似度计算:
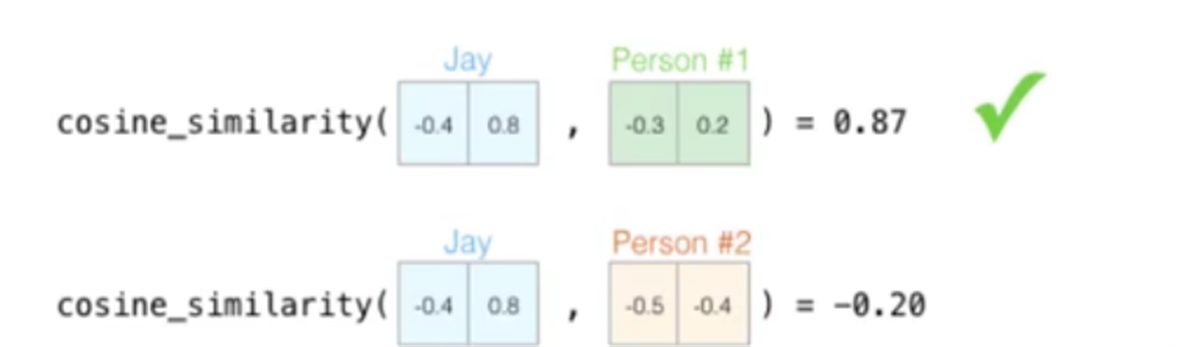
欧拉公式、余弦公式通过距离计算他们的相似度。
4.4 Word2Vec的维度意义
在实际的训练过程中,数据的维度越高,能提供的信息也就越多,从而计算结果的可靠性就更值得信赖。(通常为50-300维)

一、词向量模型训练

•输入:词的特征。
•黑盒:通过神经神经网络反向传播调整模型参数
•输出:下个单词的预测
二、词向量模型训练–黑盒
我们来看一下一个整体的结果:
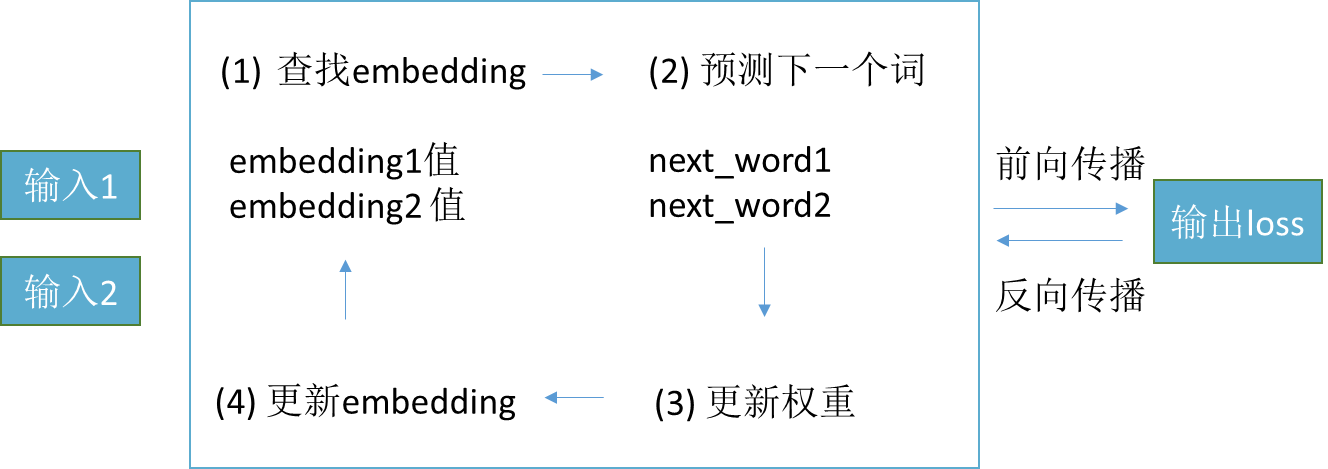
训练过程:
1.从embedding表中查找输入词的初始embedding值
2.通过神经网络来预测下一个值。
3.前向传播:求损失函数的值
4.反向传播:更新权重参数和输入的embedding值
三、Word2Vec的实现方法
输入:自然 语言 处理 包含 很多 任务
分为两个部分
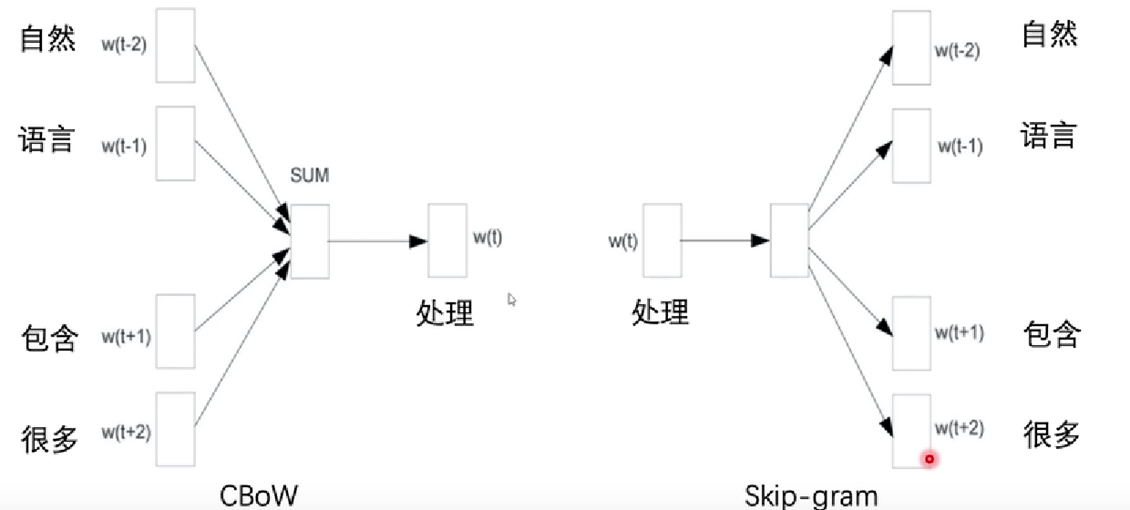
简单来说:
就是输入的不同,CBow,以上下文预测中渐次。Skip-gram 以一个中间词预测上下文。
四、直接建模的问题——以Skip-gram为例
输入:自然 语言 处理 包含 很多 任务
Window Size = 3
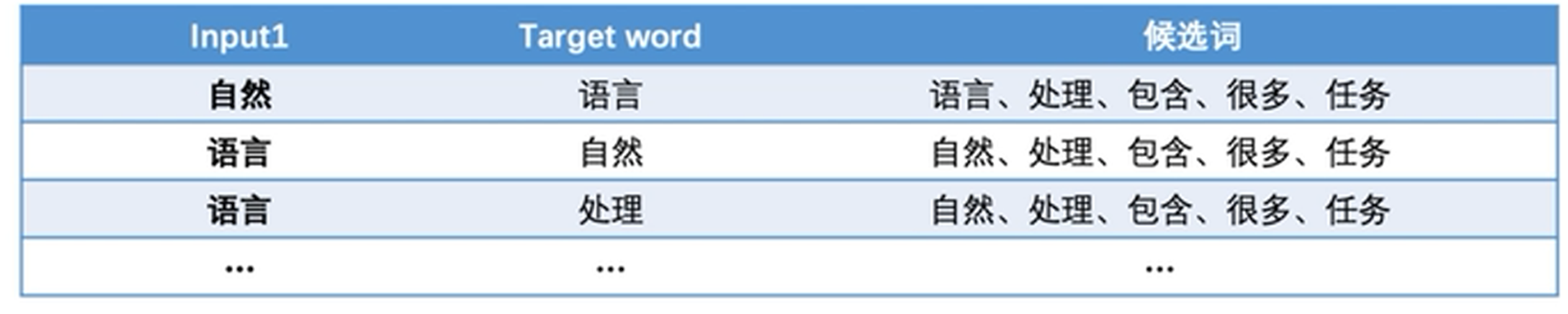
存在的问题:求解一个Length(corpus)的多分类问题。
解释:因为从预测结果来看,候选词为长度-1 个。
解决办法:将输入与输出同时作为输入,计算候选输出的概率。

解释:然而由于输入包含了输出的标签,预测目标全为1,因此模型进行乱猜导致无法训练。
五、负采样方法的引入——以Skip-gram为例
由于训练过程只有正样本,导致模型训练无法收敛,因此可以适当添加错误的样本。
负采样(Negative Sample)方法:在输入样本中加入负样本(错误的样本)
输入:自然 语言 处理 包含 很多 任务

根据大量实验的经验值:负样本个数3-5个比较合适
六、小结
Word2Vec的意义词向量模型的训练Word2Vec实现方法直接建模的问题负采样的引入
附录:词向量长什么样子:
输出Word2Vec下面是一个五十维的向量:

我们用热度图来判断他们之间的相似性

我们用热度图来判断他们之间的相似性,其中红色越深 关系越强。

假设我们已经训练好了词向量,
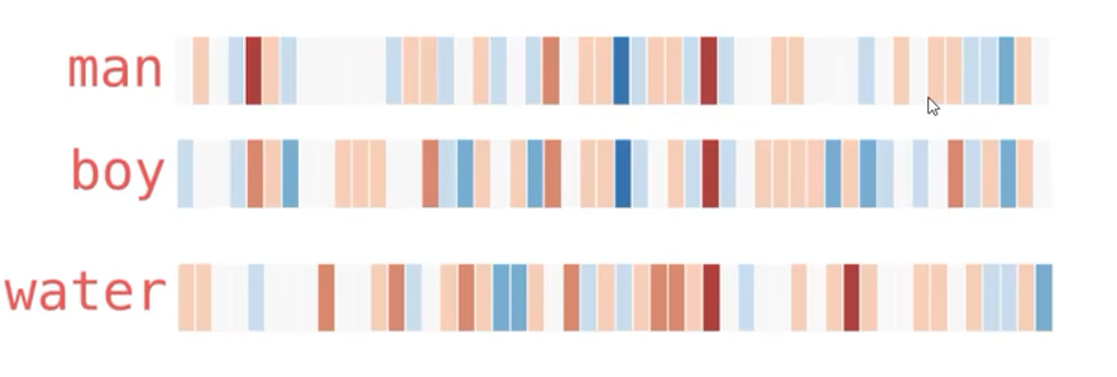
观察一下当前的词向量的相似性:
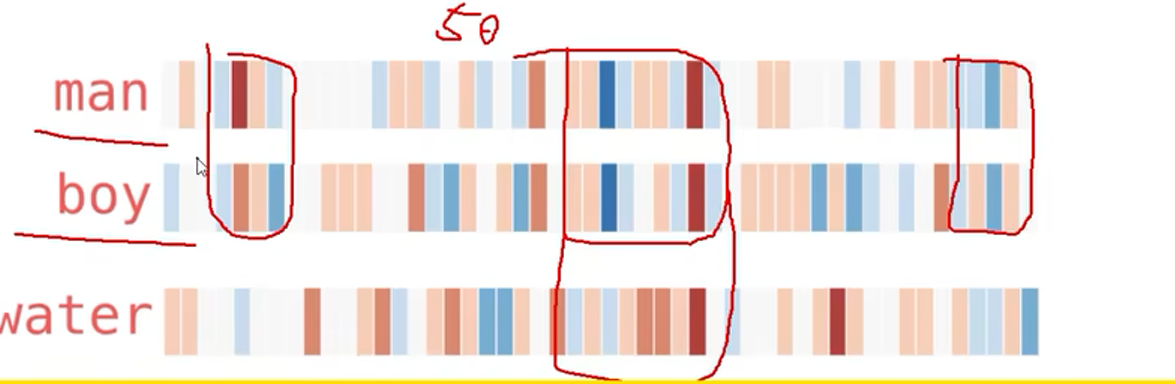
可以可视化的观察到,词向量的相关性。
最后,最后
如果觉得有用,麻烦三连?⭐️❤️支持一下呀,希望这篇文章可以帮到你,你的点赞是我持续更新的动力