一、前言
hadoop是大数据生态中的基础服务,也是其他大数据框架的基础运行环境,尤其是hdfs,是其他大数据框架的基础存储载体,因此系统学习和掌握hadoop对学习大数据很有必要;
而Hive则是Hadop生态系统中必不可少的一个数据分析工具,它可以将存储在HDES中的结构化数据映射为数据库中的一张表,并提供了一种SQL方言对其进行查询。这些SQL语句最终会翻译成MapReduce程序执行。Hive的本质就是为了简化用户编写MapReduce程序而生成的一种框架,它本身并不会存储和计算数据,完全依赖于HDFS和MapReduce,所以搭建hive的前提需要安装并启动hadoop服务;
本篇将基于阿里云服务器,搭建一个hive的环境,由于生产环境下,hive的运行需要依赖hadoop的环境,所以需要提前搭建好hadoop环境;
二、安装包版本说明
本文核心软件包主要包括下面几个,请提前根据需需要准备好,并上传值指定目录;
| 名称 | 版本号 | 备注 |
| jdk | 3.1.3 | hadoop基础依赖 |
| mysql | 5.7 | 存储hive元数据 |
| hive | 3.1.2 | 注意这里的版本要与hadoop的版本进行匹配(可以查询相关资料进行版本匹配的确认) |
| hadoop | 3.1.3 |
|
三、服务器环境
基于cents7.x版本,虚拟机或云服务器,推荐:4核8G(至少:2核4G)
接下来将按照表中的安装包顺序依次进行安装配置;
四、配置JDK环境
上传安装包到当前目录
![]()
文件解压
tar -zxvf jdk-8u181-linux-x64.tar.gzmv jdk-8u181-linux-x64 jdk8
配置环境变量
vi /etc/profile
将下面的内容配置进去
JAVA_HOME=/usr/local/soft/jdk8CLASSPATH=$JAVA_HOME/lib/PATH=$PATH:$JAVA_HOME/bin然后使用下面命令使环境变量生效
source /etc/profile
验证配置是否生效

五、安装mysql
这里为了方便,将使用docker快速搭建起mysql的环境,本篇使用的是mysql5.7的版本;
1、拉取mysql镜像
docker pull mysql:5.7
如果拉取镜像比较慢,也可以使用下面的这个采用网易加速地址
docker pull hub.c.163.com/library/mysql:5.7
过程展示
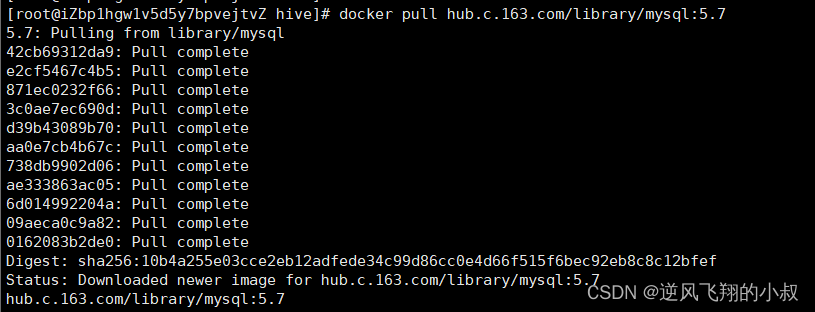
拉取完毕后,使用docker images查看下镜像

2、启动mysql容器
docker run -p 3306:3306 --name mysql5.7 \-e MYSQL_ROOT_PASSWORD=123456 \-d hub.c.163.com/library/mysql:5.7
使用这种方式启动容器之后,只是创建了mysql镜像容器并且以默认配置启动,当容器被删除则数据和新加的配置全部清空,为了数据安全起见,需要对数据持久化,以及配置持久化到宿主机上。需要采用docker容器数据卷实,目录的挂载来实现;
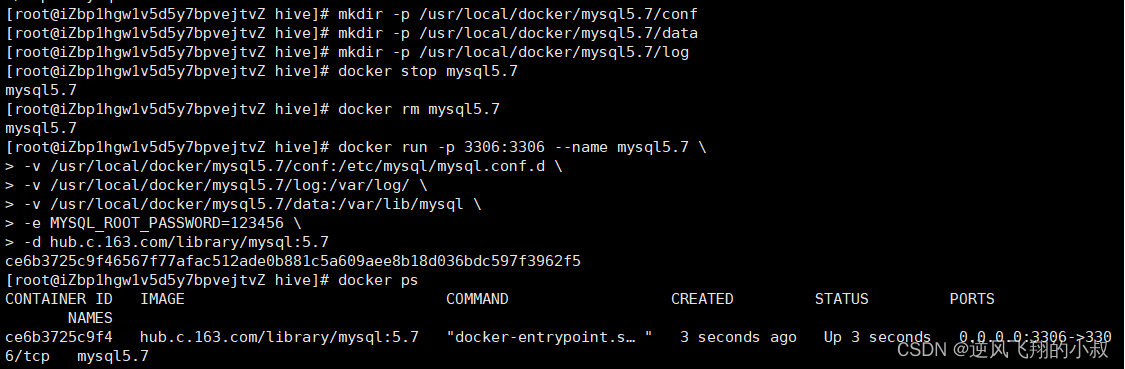
创建数据卷相关目录
mkdir -p /usr/local/docker/mysql5.7/conf
mkdir -p /usr/local/docker/mysql5.7/data
mkdir -p /usr/local/docker/mysql5.7/log
停止mysql5.7容器
docker stop mysql5.7
删除mysql5.7容器
docker rm mysql5.7
重启mysql容器
docker run -p 3306:3306 --name mysql5.7 \-v /usr/local/docker/mysql5.7/conf:/etc/mysql/mysql.conf.d \-v /usr/local/docker/mysql5.7/log:/var/log/ \-v /usr/local/docker/mysql5.7/data:/var/lib/mysql \-e MYSQL_ROOT_PASSWORD=123456 \-d hub.c.163.com/library/mysql:5.7过程展示
3、客户端工具连接测试
使用navicat连接root账户进行测试,注意提前在安全组中开放3306端口;

到这里就把mysql的环境搭建完成了;
六、安装与启动 hadoop
安装包可以在官网下载,或者通过一些镜像源,使用wget下载;
wget --no-check-certificate https://repo.huaweicloud.com/apache/hadoop/common/hadoop-3.1.3/hadoop-3.1.3.tar.gz下载地址1:hadoop 下载地址
1、上传安装包并解压
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/mv /opt/hadoop-3.1.3 /opt/hadoop
2、配置hadoop环境变量
依次执行下面的命令,将hadoop配置到环境变量中去;
echo 'export HADOOP_HOME=/opt/hadoop/' >> /etc/profileecho 'export PATH=$PATH:$HADOOP_HOME/bin' >> /etc/profileecho 'export PATH=$PATH:$HADOOP_HOME/sbin' >> /etc/profilesource /etc/profile
3、执行如下命令,修改配置文件
将JDK环境配置到:yarn-env.sh,hadoop-env.sh 脚本文件中【即在hadoop中配置JDK的依赖环境,hadoop服务启动之后以Java进程的方式运行】
echo "export JAVA_HOME=/usr/java8" >> /opt/hadoop/etc/hadoop/yarn-env.shecho "export JAVA_HOME=/usr/java8" >> /opt/hadoop/etc/hadoop/hadoop-env.sh
4、测试hadoop是否安装成功
使用下面的命令进行测试是否安装成功
hadoop version
看到下面的信息,表示hadoop安装成功

5、hadoop 相关配置文件的配置
hadoop最终是否能够正常跑起来,关键点在于几个核心配置文件是否配置正确,请依次安装下面的顺序对相关的文件进行配置;

修改配置文件 core-site.xml
进入到haddop目录,找到 core-site.xml文件
cd /opt/hadoop/etc/hadoop
编辑该文件
vim core-site.xml
在<configuration></configuration>节点内插入如下内容
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/hadoop/tmp</value>
<description>location to store temporary files</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
修改配置文件 hdfs-site.xml
编辑该配置文件
vim /opt/hadoop/etc/hadoop/hdfs-site.xml
在<configuration></configuration>节点内插入如下内容
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop/tmp/dfs/data</value>
</property>
补充说明
在完全分布式模式下,通常还要配置:mapred-site.xm 与yarn-site.xml 这两个文件,比如在里面添加zk的配置等,这里由于是单机的伪分布式环境,暂时不需要配置另外这两个文件;
6、配置SSH免密登录
在任意目录下,执行下面的命令,创建公钥和私钥
ssh-keygen -t rsa
将公钥添加到authorized_keys文件中
依次执行下面的命令
cd ~
cd .ssh
cat id_rsa.pub >> authorized_keys
在环境变量中添加hadoop相关的配置
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
然后使用:source /etc/profile 使得配置生效
七、hadoop启动与初始化
1、执行以下命令,初始化namenode
hadoop namenode -format
2、依次执行以下命令,启动Hadoop
start-dfs.sh
start-yarn.sh
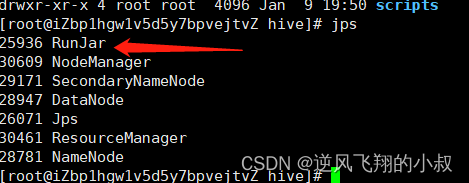
3、使用jps查看是否启动成功
如果能看到下面这些进程,说明hadoop启动完成;

4、测试hadoop是否可以正常使用
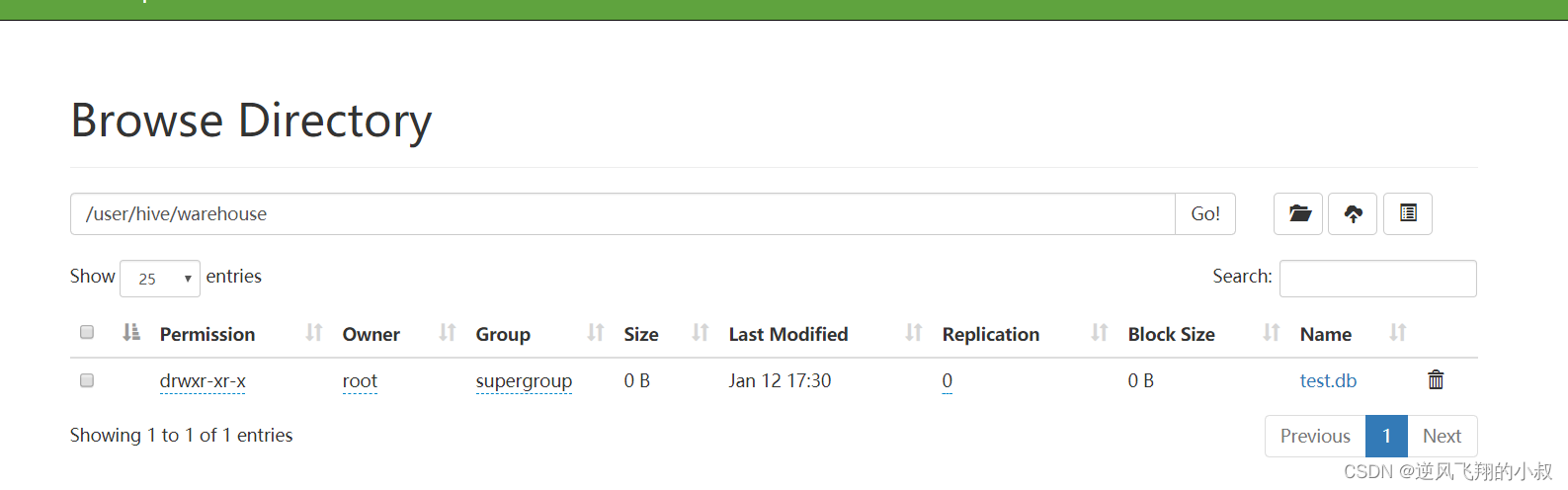
使用下面的hdfs命令创建一个文件目录,创建成功后,可以在WEB-UI界面上看到这个目录;
hdfs dfs -mkdir /sanguo
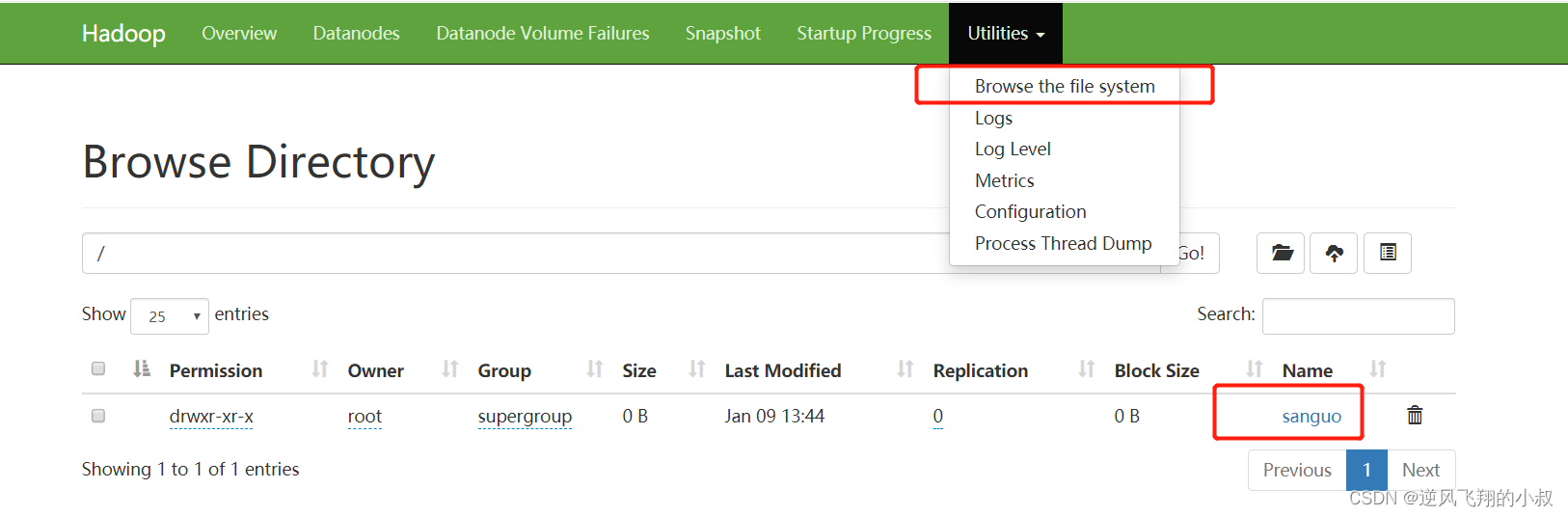
八、浏览器web-ui界面访问
默认情况下,hadoop为了更好的管理集群的任务以及hdfs的信息,有两个端口可以直接通过界面访问的,一个是关于集群的任务,另一个是hdfs的界面【注意提前在安全组将端口进行开放】;
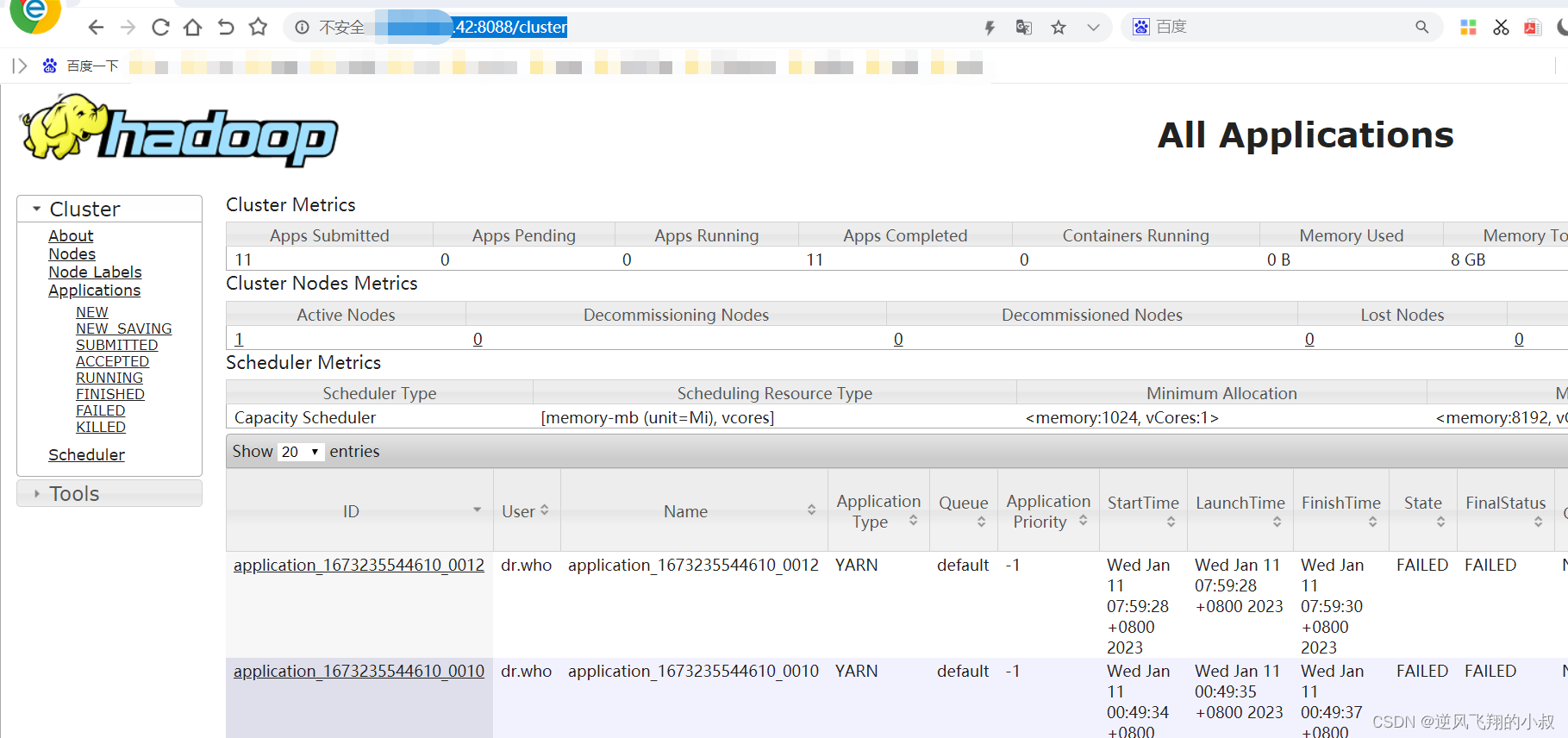
可以依次访问
All Applicationshttp://外网IP:8088/cluster
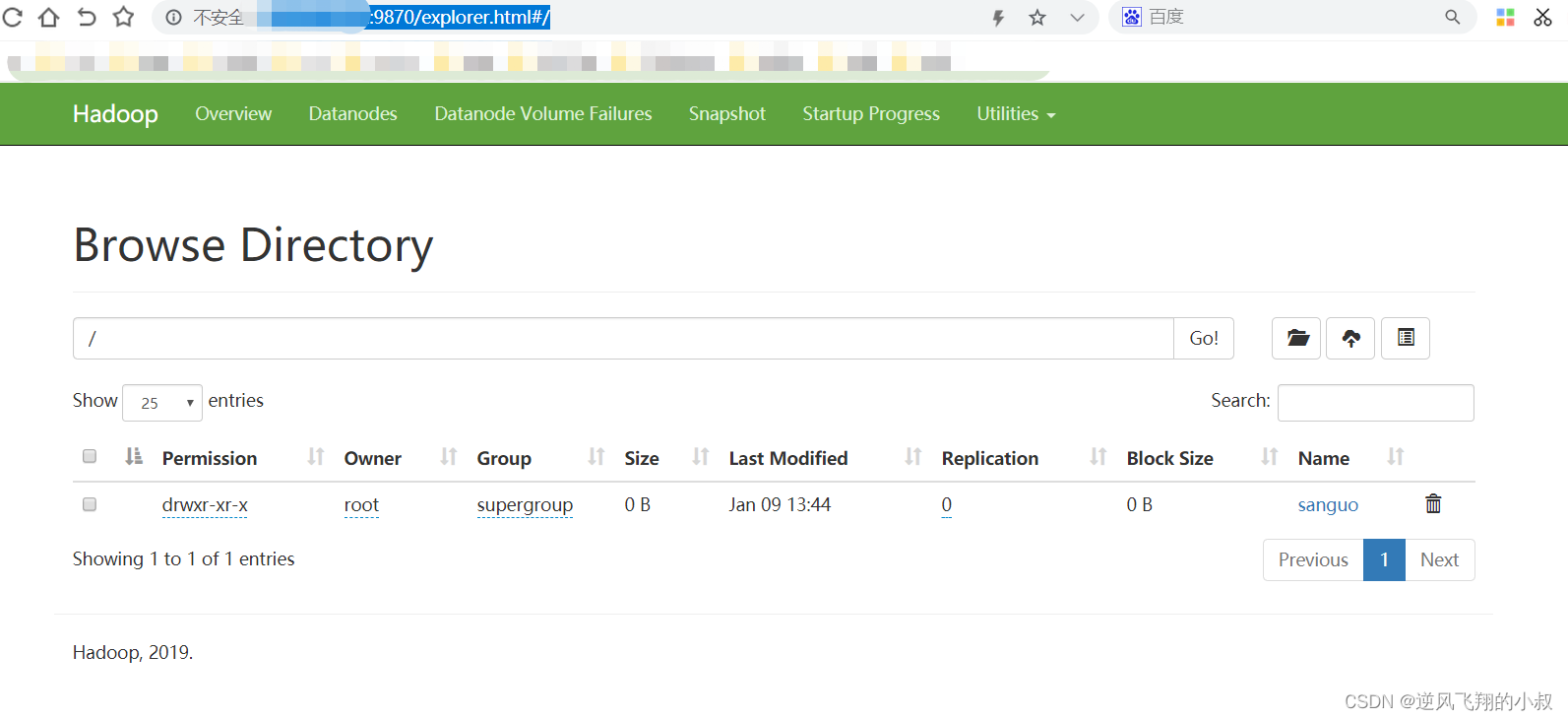
http://外网IP:9870/explorer.html#/All Applications
第一个界面如下
第二个界面如下
八、安装hive并启动服务【本地模式】
1、上传安装包并解压
tar -zxvf apache-hive-3.1.2-bin.tar.gz
mv apache-hive-3.1.2-bin hive
![]()
2、替换hive的相关jar
上传mysql驱动包到lib目录
由于后面使用hive时需要将信息存储到mysql,因此这里需要添加mysql的连接驱动,上传至lib目录下即可;
![]()
替换guawa包
做这个替换主要是为了解决hadoop与hive的依赖包版本上的差异,在3.1.2这个版本,hive的lib目录下的guawa包版本不匹配(会造成启动失败),因此需要替换为高版本的,可以从hadoop目录下拷贝替换到hive的lib目录;
cp /opt/hadoop/share/hadoop/common/lib/guava-27.0-jre.jar /usr/local/soft/hive/lib
3、配置环境变量
修改hive的环境变量,将hadoop_home配置进去,进入hive的conf目录,执行下面的命令
cp hive-env.sh.template hive-env.sh

使用vim命令,将hadoop的配置信息添加进去,以及hive自身的配置文件目录;
export HADOOP_HOME=/opt/hadoop/
export HIVE_CONF_DIR=/usr/local/soft/hive/conf
export HIVE_AUX_JARS_PATH=/usr/local/soft/hive/lib
4、配置hive-site文件
这里我们将使用本地模式进行hive的部署,这种模式下,不需要初始化hive的metastore信息,但是hive的元数据将存放在mysql中,所以需要在这个配置文件中配置与mysql的连接;
在conf目录下创建hive-site.xml文件

添加如下配置到该文件
<configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://你的mysql连接地址:3306/hive?createDatabaseIfNotExist=true</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>Driver class name for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> <description>username to use against metastore database</description> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>123456</value> <description>password to use against metastore database</description> </property> <property> <name>hive.metastore.schema.verification</name> <value>false</value> </property> <property> <name>hive.metastore.event.db.notification.api.auth</name> <value>false</value> </property></configuration>
5、初始化metadata信息
进入到hive的主目录,执行下面的命令进行metadata数据的初始化,其实就是将初始化的hive数据到mysql中;
执行下面的命令进行初始化
bin/schematool -initSchema -dbType mysql -verbos
过程展示
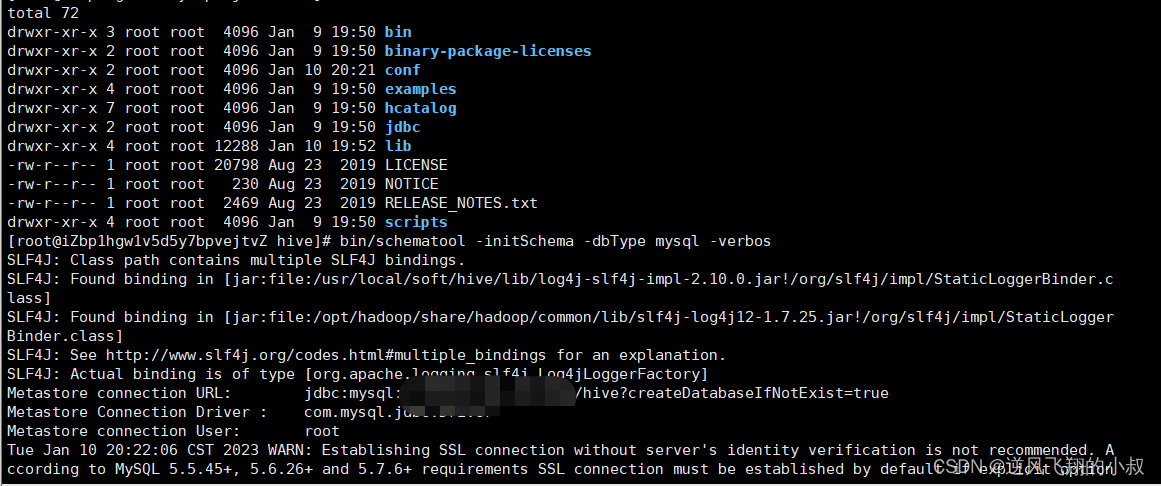
看到下面的信息,说明初始化完成;

此时再通过navicat客户端工具查看,多出了一个hive的数据库以及下面的数据表;
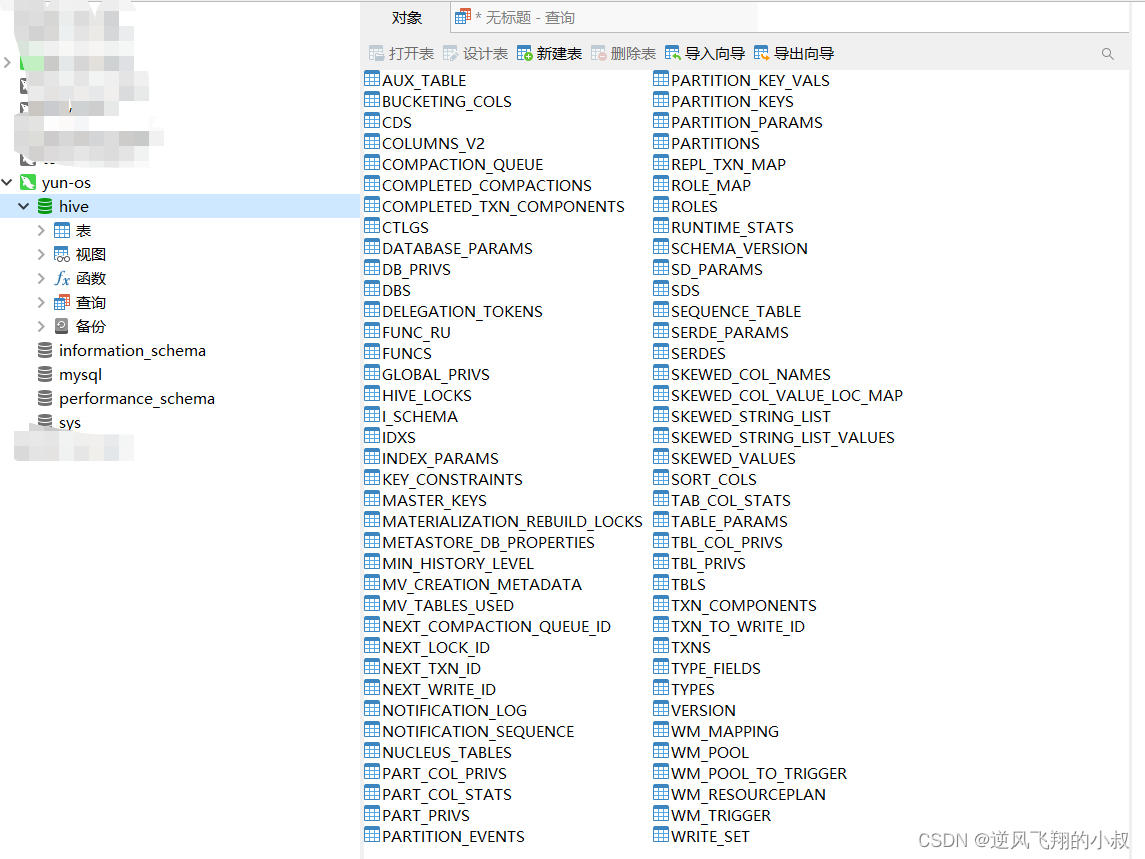
六、启动hive服务
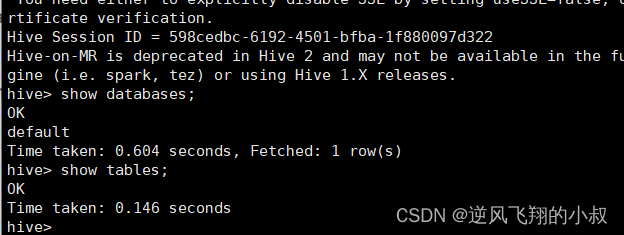
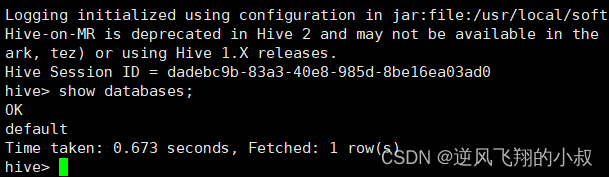
在当前目录下直接执行: bin/hive ,即可启动hive,如下,然后就可以像操作mysql的相关命令一样开始使用hive了;
九、安装hive并启动服务【远程模式】
以上的hive服务是可以正常运行起来了,但我们并没有启动metastore服务,这种部署模式也叫本地模式;
但是在生产环境下,建议是先启动metastore服务,再使用hive,这种模式也成为远程模式,远程模式与本地模式在hive-site.xml配置上稍有差别,其他的过程均不变;
1、配置hive-site.xml文件
在上面的hive-site.xml配置基础上补充下面的信息
<property> <name>hive.server2.thrift.bind.host</name> <value>IP</value> </property><property> <name>hive.metastore.uris</name> <value>thrift://IP:9083</value> </property>
2、初始化元数据
这个和上面的差不多
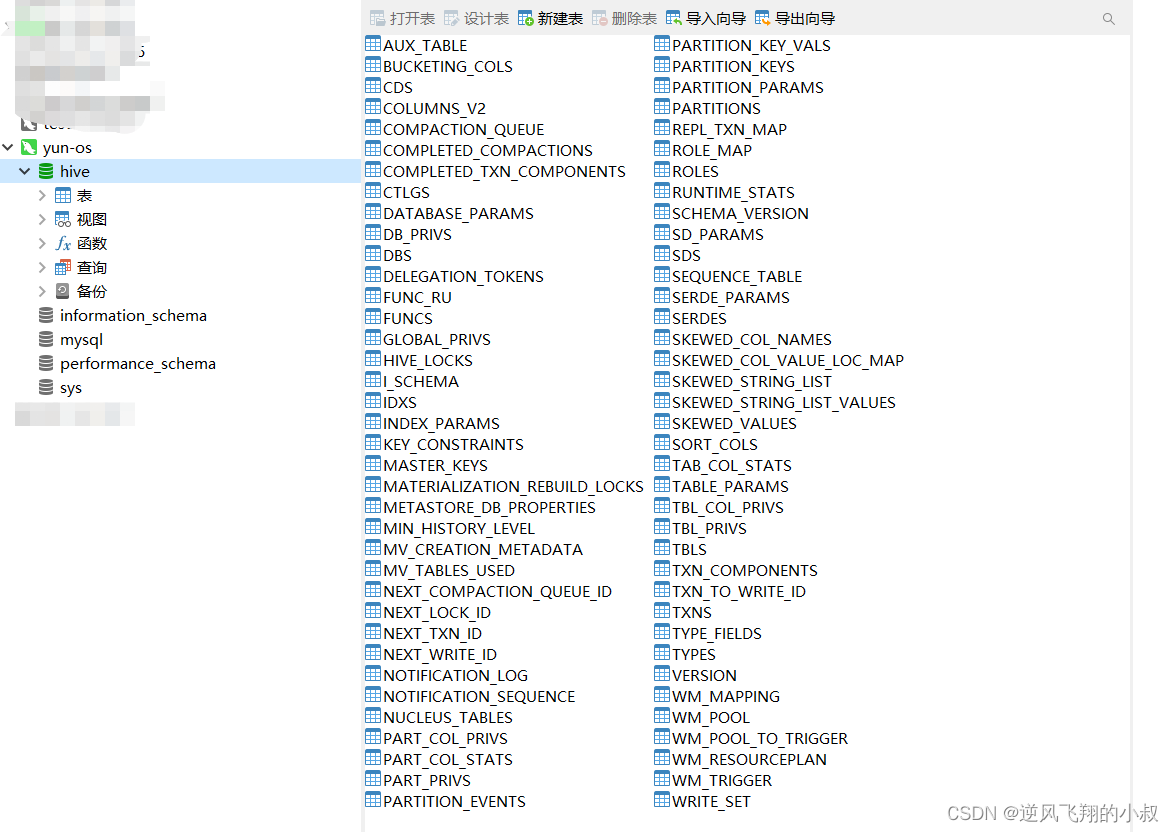
bin/schematool -initSchema -dbType mysql -verbos
初始化完成后将看到下面的hive库和相关的数据表
3、启动metastore服务
metastore的启动也可以通过前台启动和后台启动,自己测试可以使用前台启动,生产环境下建议使用后台启动;
前台启动命令
/bin/hive --service metastore
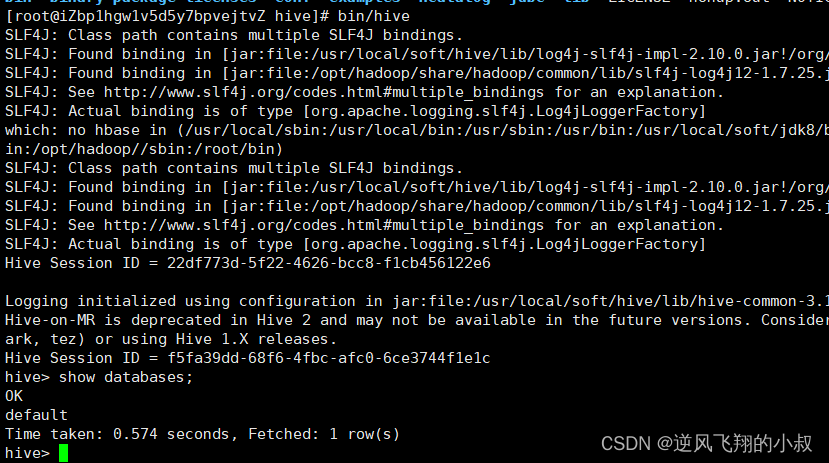
在这种模式下,启动之后,需要开启另一个窗口,否则进程就杀掉了,再开一个窗口,使用 : bin/hive开启客户端服务,效果是一样的;
后台启动命令
nohup /bin/hive --service metastore &
在这种模式下,后台将会运行一个进程;
这时候就可以使用 : bin/hive开启客户端服务,效果是一样的;
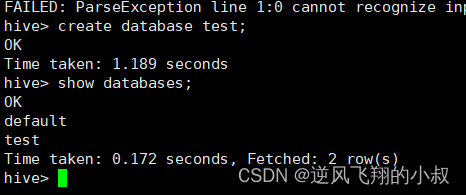
尝试创建一个test的数据库
创建完成之后,就可以在hdfs目录下看到数据库的相关的目录信息了