Pytorch实现动物识别(含动物数据集和训练代码)
目录
动物数据集+动物分类识别训练代码(Pytorch)
1. 前言
2. Animals-Dataset动物数据集说明
(1)Animals90动物数据集
(2)Animals10动物数据集
(3)自定义数据集
3. 动物分类识别模型训练
(1)项目安装
(2)准备Train和Test数据
(3)配置文件: config.yaml
(4)开始训练
(5)可视化训练过程
(6)一些优化建议
(7) 一些运行错误处理方法:
cannot import name 'load_state_dict_from_url'
4. 动物分类识别模型测试效果
5.项目源码下载
1. 前言
基于人工智能的动物AI识别,能够帮助我们快速认知动物品种,对动物科普等研究方面具有重大的意义。本项目将采用深度学习的方法,搭建一个动物分类识别的训练和测试系统。 基于该项目,你可以快速训练一个动物分类识别模型。
目前,基于ResNet18的动物分类识别,支持90种动物分类识别;在Animals90动物数据集上,训练集的Accuracy 99%左右,测试集的Accuracy在91%左右;在Animals10动物数据集上,训练集的Accuracy 99%左右,测试集的Accuracy在96%左右。骨干网络模型可支持googlenet, resnet[18,34,50], inception_v3,mobilenet_v2等常用的模型。

如果想进一步提高准确率,可以尝试:
增加样本数据: 可以采集更多的样本数据,提高模型泛化能力减少种类:Animals90动物数据集共有90种类,可以剔除部分不常见的动物数据清洗数据:动物数据集,部分数据是通过网上爬取的,存在部分错误的图片,尽管鄙人已经清洗一部分了,但还是建议你,训练前,再次清洗数据集,不然会影响模型的识别的准确率。使用不同backbone模型,比如resnet50或者更深的模型增加数据增强: 已经支持: 随机裁剪,随机翻转,随机旋转,颜色变换等数据增强方式,可以尝试诸如mixup,CutMix等更复杂的数据增强方式样本均衡: 建议进行样本均衡处理调超参: 比如学习率调整策略,优化器(SGD,Adam等)损失函数: 目前训练代码已经支持:交叉熵,LabelSmoothing,可以尝试FocalLoss等损失函数【源码下载】动物数据集+动物分类识别训练代码(Pytorch)
【尊重原创,转载请注明出处】https://panjinquan.blog.csdn.net/article/details/126640766
2. Animals-Dataset动物数据集说明
(1)Animals90动物数据集
Animals90动物数据集,包含 90 个不同类别动物,约有 5400 张动物图像,每种类含有60张图片。所有照片都已经按照其所属类别存放于各自的文件夹下。动物种类包括常见的类别,如羚羊,獾,蝙蝠,熊,蜜蜂,甲虫,野牛,公猪,蝴蝶,猫 毛虫,黑猩猩等。
为了方便训练,鄙人已将数据划分为训练集和测试集,其中训练集每类50张图片,共4500张图片;测试集每类10张图片,共900张图片
下面是Animals90动物数据集90类别名称:
antelopebadgerbatbearbeebeetlebisonboarbutterflycatcaterpillarchimpanzeecockroachcowcoyotecrabcrowdeerdogdolphindonkeydragonflyduckeagleelephantflamingoflyfoxgoatgoldfishgoosegorillagrasshopperhamsterharehedgehoghippopotamushornbillhorsehummingbirdhyenajellyfishkangarookoalaladybugsleopardlionlizardlobstermosquitomothmouseoctopusokapiorangutanotterowloxoysterpandaparrotpelecaniformespenguinpigpigeonporcupinepossumraccoonratreindeerrhinocerossandpiperseahorsesealsharksheepsnakesparrowsquidsquirrelstarfishswantigerturkeyturtlewhalewolfwombatwoodpeckerzebra(2)Animals10动物数据集
Animals10动物数据集,仅包含 10个不同类别动物,分别为:蝴蝶,猫,鸡,牛,狗,象,马,羊,蜘蛛和松鼠,总共约有26000+张动物图像。其中训练集共25000+张图片,平均每类含有2500张图片;测试集每类100张图片,共1000张图片。所有照片都已经按照其所属类别存放于各自的文件夹下。
 |  |
 |  |
下面是Animals10动物数据集10类别名称:
butterflycatchickencowdogelephanthorsesheepspidersquirrel(3)自定义数据集
如果需要新增类别数据,或者需要自定数据集进行训练,可以如下进行处理:
Train和Test数据集,要求相同类别的图片,放在同一个文件夹下;且子目录文件夹命名为类别名称,如
class_name.txt
(最后一行,请多回车一行)
ABCDtrain_data: # 可添加多个数据集 - 'data/dataset/train1' - 'data/dataset/train2'test_data: 'data/dataset/test'class_name: 'data/dataset/class_name.txt'......3. 动物分类识别模型训练
考虑到Animals90动物数据集种类比较齐全,因此本项目以Animals90动物数据集为训练样本,当然你也可以合并Animals90和Animals10这两个数据集进行训练。
(1)项目安装
整套工程基本框架结构如下:
.├── classifier # 训练模型相关工具├── configs # 训练配置文件├── data # 训练数据├── libs ├── demo.py # 模型推理demo├── README.md # 项目工程说明文档├── requirements.txt # 项目相关依赖包└── train.py # 训练文件项目依赖python包请参考requirements.txt,使用pip安装即可:
numpy==1.16.3matplotlib==3.1.0Pillow==6.0.0easydict==1.9opencv-contrib-python==4.5.2.52opencv-python==4.5.1.48pandas==1.1.5PyYAML==5.3.1scikit-image==0.17.2scikit-learn==0.24.0scipy==1.5.4seaborn==0.11.2tensorboard==2.5.0tensorboardX==2.1torch==1.7.1+cu110torchvision==0.8.2+cu110tqdm==4.55.1xmltodict==0.12.0basetrainerpybaseutils==0.6.5项目安装教程请参考(初学者入门,麻烦先看完下面教程,配置好开发环境):
项目开发使用教程和常见问题和解决方法视频教程:1 手把手教你安装CUDA和cuDNN(1)视频教程:2 手把手教你安装CUDA和cuDNN(2)视频教程:3 如何用Anaconda创建pycharm环境视频教程:4 如何在pycharm中使用Anaconda创建的python环境(2)准备Train和Test数据
下载动物分类数据集,Train和Test数据集,要求相同类别的图片,放在同一个文件夹下;且子目录文件夹命名为类别名称。
数据增强方式主要采用: 随机裁剪,随机翻转,随机旋转,颜色变换等处理方式
import numbersimport randomimport PIL.Image as Imageimport numpy as npfrom torchvision import transformsdef image_transform(input_size, rgb_mean=[0.5, 0.5, 0.5], rgb_std=[0.5, 0.5, 0.5], trans_type="train"): """ 不推荐使用:RandomResizedCrop(input_size), # bug:目标容易被crop掉 :param input_size: [w,h] :param rgb_mean: :param rgb_std: :param trans_type: :return:: """ if trans_type == "train": transform = transforms.Compose([ transforms.Resize([int(128 * input_size[1] / 112), int(128 * input_size[0] / 112)]), transforms.RandomHorizontalFlip(), # 随机左右翻转 # transforms.RandomVerticalFlip(), # 随机上下翻转 transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5, hue=0.1), transforms.RandomRotation(degrees=5), transforms.RandomCrop([input_size[1], input_size[0]]), transforms.ToTensor(), transforms.Normalize(mean=rgb_mean, std=rgb_std), ]) elif trans_type == "val" or trans_type == "test": transform = transforms.Compose([ transforms.Resize([input_size[1], input_size[0]]), # transforms.CenterCrop([input_size[1], input_size[0]]), # transforms.Resize(input_size), transforms.ToTensor(), transforms.Normalize(mean=rgb_mean, std=rgb_std), ]) else: raise Exception("transform_type ERROR:{}".format(trans_type)) return transform修改配置文件数据路径:config.yaml
注意数据路径分隔符使用【/】,不是【\】项目不要出现含有中文字符的目录文件或路径,否则会出现很多异常!# 训练数据集,可支持多个数据集train_data: - '/path/to/animal/animals90/train'# 测试数据集test_data: '/path/to/animal/animals90/test'# 类别文件class_name: '/path/to/animal/animals90/class_name.txt'(3)配置文件: config.yaml
目前支持的backbone有:googlenet,resnet[18,34,50],inception_v3,mobilenet_v2等, 其他backbone可以自定义添加训练参数可以通过(configs/config.yaml)配置文件进行设置配置文件config.yaml说明如下:
# 训练数据集,可支持多个数据集train_data: - '/path/to/animal/animals90/train'# 测试数据集test_data: '/path/to/animal/animals90/test'# 类别文件class_name: '/path/to/animal/animals90/class_name.txt'train_transform: "train" # 训练使用的数据增强方法test_transform: "val" # 测试使用的数据增强方法work_dir: "work_space/" # 保存输出模型的目录net_type: "resnet18" # 骨干网络,支持:resnet18/50,mobilenet_v2,googlenet,inception_v3width_mult: 1.0input_size: [ 224,224 ] # 模型输入大小rgb_mean: [ 0.5, 0.5, 0.5 ] # for normalize inputs to [-1, 1],Sequence of means for each channel.rgb_std: [ 0.5, 0.5, 0.5 ] # for normalize,Sequence of standard deviations for each channel.batch_size: 32lr: 0.01 # 初始学习率optim_type: "SGD" # 选择优化器,SGD,Adamloss_type: "CrossEntropyLoss" # 选择损失函数:支持CrossEntropyLoss,LabelSmoothingmomentum: 0.9 # SGD momentumnum_epochs: 100 # 训练循环次数num_warn_up: 3 # warn-up次数num_workers: 8 # 加载数据工作进程数weight_decay: 0.0005 # weight_decay,默认5e-4scheduler: "multi-step" # 学习率调整策略milestones: [ 20,50,80 ] # 下调学习率方式gpu_id: [ 0 ] # GPU IDlog_freq: 50 # LOG打印频率progress: True # 是否显示进度条pretrained: False # 是否使用pretrained模型finetune: False # 是否进行finetune
| 参数 | 类型 | 参考值 | 说明 |
|---|---|---|---|
| train_data | str, list | - | 训练数据文件,可支持多个文件 |
| test_data | str, list | - | 测试数据文件,可支持多个文件 |
| class_name | str | - | 类别文件 |
| work_dir | str | work_space | 训练输出工作空间 |
| net_type | str | resnet18 | backbone类型,{resnet18/50,mobilenet_v2,googlenet,inception_v3} |
| input_size | list | [128,128] | 模型输入大小[W,H] |
| batch_size | int | 32 | batch size |
| lr | float | 0.1 | 初始学习率大小 |
| optim_type | str | SGD | 优化器,{SGD,Adam} |
| loss_type | str | CELoss | 损失函数 |
| scheduler | str | multi-step | 学习率调整策略,{multi-step,cosine} |
| milestones | list | [30,80,100] | 降低学习率的节点,仅仅scheduler=multi-step有效 |
| momentum | float | 0.9 | SGD动量因子 |
| num_epochs | int | 120 | 循环训练的次数 |
| num_warn_up | int | 3 | warn_up的次数 |
| num_workers | int | 12 | DataLoader开启线程数 |
| weight_decay | float | 5e-4 | 权重衰减系数 |
| gpu_id | list | [ 0 ] | 指定训练的GPU卡号,可指定多个 |
| log_freq | in | 20 | 显示LOG信息的频率 |
| finetune | str | model.pth | finetune的模型 |
| progress | bool | True | 是否显示进度条 |
| distributed | bool | False | 是否使用分布式训练 |
(4)开始训练
整套训练代码非常简单操作,用户只需要将相同类别的数据放在同一个目录下,并填写好对应的数据路径,即可开始训练了。
终端输入:
python train.py -c configs/config.yaml (5)可视化训练过程
训练过程可视化工具是使用Tensorboard,使用方法,在终端输入:
# 基本方法tensorboard --logdir=path/to/log/# 例如tensorboard --logdir=work_space/mobilenet_v2_1.0_CrossEntropyLoss/log可视化效果
 | 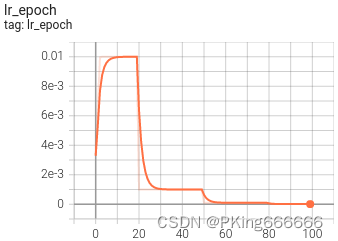 |
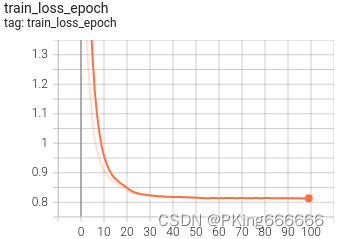 | 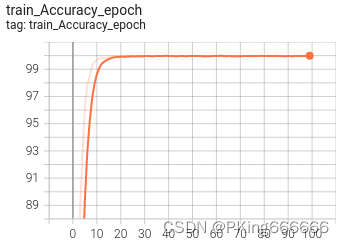 |
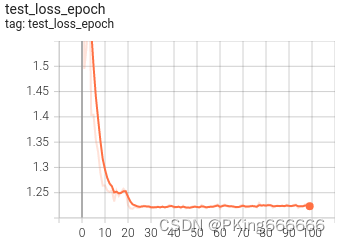 |  |
(6)一些优化建议
训练完成后,目前,基于ResNet18的动物分类识别,在Animals90动物数据集上,训练集的Accuracy 99%左右,测试集的Accuracy在91%左右;在Animals10动物数据集上,训练集的Accuracy 99%左右,测试集的Accuracy在96%左右。如果想进一步提高准确率,可以尝试:
增加样本数据: 可以采集更多的样本数据,提高模型泛化能力减少种类:Animals90动物数据集共有90种类,可以剔除部分不常见的动物数据清洗数据:动物数据集,部分数据是通过网上爬取的,存在部分错误的图片,尽管鄙人已经清洗一部分了,但还是建议你,训练前,再次清洗数据集,不然会影响模型的识别的准确率。使用不同backbone模型,比如resnet50或者更深的模型增加数据增强: 已经支持: 随机裁剪,随机翻转,随机旋转,颜色变换等数据增强方式,可以尝试诸如mixup,CutMix等更复杂的数据增强方式样本均衡: 建议进行样本均衡处理调超参: 比如学习率调整策略,优化器(SGD,Adam等)损失函数: 目前训练代码已经支持:交叉熵,LabelSmoothing,可以尝试FocalLoss等损失函数(7) 一些运行错误处理方法:
项目不要出现含有中文字符的目录文件或路径,否则会出现很多异常!!!!!!!!
cannot import name 'load_state_dict_from_url'
由于一些版本升级,会导致部分接口函数不能使用,请确保版本对应
torch==1.7.1
torchvision==0.8.2
或者将对应python文件将
from torchvision.models.resnet import model_urls, load_state_dict_from_url修改为:
from torch.hub import load_state_dict_from_urlmodel_urls = { 'mobilenet_v2': 'https://download.pytorch.org/models/mobilenet_v2-b0353104.pth', 'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth', 'resnet34': 'https://download.pytorch.org/models/resnet34-333f7ec4.pth', 'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth', 'resnet101': 'https://download.pytorch.org/models/resnet101-5d3b4d8f.pth', 'resnet152': 'https://download.pytorch.org/models/resnet152-b121ed2d.pth', 'resnext50_32x4d': 'https://download.pytorch.org/models/resnext50_32x4d-7cdf4587.pth', 'resnext101_32x8d': 'https://download.pytorch.org/models/resnext101_32x8d-8ba56ff5.pth', 'wide_resnet50_2': 'https://download.pytorch.org/models/wide_resnet50_2-95faca4d.pth', 'wide_resnet101_2': 'https://download.pytorch.org/models/wide_resnet101_2-32ee1156.pth',}
4. 动物分类识别模型测试效果
demo.py文件用于推理和测试模型的效果,填写好配置文件,模型文件以及测试图片即可运行测试了
def get_parser(): # 配置文件 config_file = "data/pretrained/resnet18_1.0_LabelSmoothing_20220830191723/config.yaml" # 模型文件 model_file = "data/pretrained/resnet18_1.0_LabelSmoothing_20220830191723/model/best_model_096_91.1111.pth" # 待测试图片目录 image_dir = "data/test_images/animals" parser = argparse.ArgumentParser(description="Inference Argument") parser.add_argument("-c", "--config_file", help="configs file", default=config_file, type=str) parser.add_argument("-m", "--model_file", help="model_file", default=model_file, type=str) parser.add_argument("--device", help="cuda device id", default="cuda:0", type=str) parser.add_argument("--image_dir", help="image file or directory", default=image_dir, type=str) return parser#!/usr/bin/env bash# Usage:# python demo.py -c "path/to/config.yaml" -m "path/to/model.pth" --image_dir "path/to/image_dir"# 配置文件config_file="data/pretrained/resnet18_1.0_LabelSmoothing_20220830191723/config.yaml"# 模型文件model_file="data/pretrained/resnet18_1.0_LabelSmoothing_20220830191723/model/best_model_096_91.1111.pth"# 待测试图片目录image_dir="data/test_images/animals"python demo.py -c $config_file -m $model_file --image_dir $image_dirWindows系统,请将$config_file, $model_file ,$image_dir等变量代替为对应的变量值即可,如
# 配置文件python demo.py -c "data/pretrained/resnet18_1.0_LabelSmoothing_20220830191723/config.yaml" -m "data/pretrained/resnet18_1.0_LabelSmoothing_20220830191723/model/best_model_096_91.1111.pth" --image_dir "data/test_images/animals"运行测试结果:

|
pred_index:['cat'],pred_score:[0.9299037]
|
pred_index:['cow'],pred_score:[0.8641183]
|
|
pred_index:['duck'],pred_score:[0.20411915]
|
pred_index:['duck'],pred_score:[0.8169622] |




5.项目源码下载
整套项目源码内容包含:
Animals90动物数据集,包含 90 个不同类别动物,总共约有5400 张动物图像,每种类含有60张图片,其中训练集每类50张图片,共4500张图片;测试集每类10张图片,共900张图片Animals10动物数据集,包含 10 个不同类别动物,总共约有26000+张动物图像,其中训练集共25000+张图片,平均每类含有2500张图片;测试集每类100张图片,共1000张图片支持自定义数据集训练整套动物分类训练代码和测试代码(Pytorch版本), 支持的backbone骨干网络模型有:googlenet,resnet[18,34,50],inception_v3,mobilenet_v2等, 其他backbone可以自定义添加【源码下载】动物数据集+动物分类识别训练代码(Pytorch)