Revisiting Skeleton-based Action Recognition解读
摘要1. 简介2. Related Work2.1 基于3D-CNN的rgb视频动作识别2.2 基于GCN的骨骼动作识别2.3 基于CNN的骨骼动作识别 3. Framework3.1 Pose Extraction3.2 From 2D Poses to 3D Heatmap Volumes3.3 基于骨骼的动作识别3D-CNN3.3.1 PoseConv3D:3.3.2 RGBPose-Conv3D 4. 实验4.1 数据集FineGYMNTURGB+DKinetics400, UCF101, and HMDB51Volleyball 4.2 PoseConv3D的性能Performance & EfficiencyRobustnessGeneralizationScalability 4.3 基于RGBPose-Conv3D的多模态融合4.4 Comparisons with the state-of-the-artSkeleton-based Action RecognitionMulti-modality Fusion 5. 其它补充内容5.1 Visualization5.2 Generating Pseudo Heatmap Volumes5.3 PoseConv3D的详细架构
论文链接:https://openaccess.thecvf.com/content/CVPR2022/papers/Duan_Revisiting_Skeleton-Based_Action_Recognition_CVPR_2022_paper.pdf
论文代码:https://github.com/kennymckormick/pyskl
论文出处:2022CVPR
摘要
人体骨骼作为人类活动的一种紧凑的表现形式,近年来受到越来越多的关注。许多基于骨骼的动作识别方法都采用GCNs来提取人体骨骼顶部的特征。尽管这些尝试显示了积极的结果,基于gcn的方法在健壮性(robustness)、互操作性(interoperability)和可伸缩性(scalability)方面受到限制。在这项工作中,我们提出了一种新的基于骨骼的动作识别方法PoseConv3D。PoseConv3D依赖3D heatmap volume,而不是graph sequence作为人体骨骼的基本表示。与基于gcn的方法相比,PoseConv3D在学习时空特征方面更有效,对姿态估计噪声的抗噪性更强,在跨数据集设置中泛化效果更好。此外,PoseConv3D可以处理多人场景而无需额外的计算成本。在早期的融合阶段,分层特征可以很容易地与其他模式集成,为提高性能提供了很大的设计空间。PoseConv3D在六个基于骨骼的动作识别基准测试中有五个达到了最先进的水平。一旦与其他模式融合,它在所有8个多模式动作识别基准上都达到了最先进的水平。1. 简介
动作识别是视频理解中的一个核心问题。现有的研究已经探索了特征表示的各种模式,如RGB帧、光流、声波和人体骨骼。在这些模式中,基于骨骼的动作识别由于其聚焦动作的特性和紧凑性,近年来受到越来越多的关注。在实践中,视频中的人体骨骼主要表示为关节坐标列表序列,其中坐标由位姿估计器提取。由于只包括姿势信息,骨架序列只捕捉动作信息,而不受情境干扰,如背景变化和照明变化。在所有基于骨骼的动作识别方法中,图卷积网络(GCN)是最受欢迎的方法之一。具体来说,GCNs将每个时间步上的每个人体关节视为一个节点。空间维度和时间维度上的相邻节点用边连接。然后将图卷积层应用于构建的图,以发现跨空间和时间的动作模式。由于基于骨骼的动作识别在标准基准上的良好性能,GCNs已成为处理骨骼序列的标准方法。基于GCN的方法在以下方面有局限性:(1)鲁棒性(Robustness)。GCN直接使用人体关机坐标,它的识别能力受到坐标分布偏移的显著影响,在使用不同的位姿估计器获取坐标时,经常会发生坐标分布偏移。坐标上的一个小扰动往往会导致完全不同的预测。
(2)互用性(Interoperability)。先前的研究表明,来自不同模式的表示,如RGB、光流和骨架,是互补的。因此,这些模式的有效组合往往能提高行动识别方面的绩效。然而,GCN是在不规则的骨架图上运行的,这使得它很难与通常以规则网格表示的其他模式融合,尤其是在早期阶段。
(3)可扩展性(Scalability)。此外,由于GCN将每个人的关节视为一个节点,因此GCN的复杂性随人数的增加呈线性扩展,限制了其在涉及多人的场景中的适用性,如群体活动识别。在本文中,我们提出了一个新颖的框架PoseConv3D,作为基于gcn的方法的一个有竞争力的替代方案。特别是,PoseConv3D将由图1所示的模型姿态估计器获得的二维姿态作为输入。
 二维姿势是由骨骼关节的热图堆栈来表示的,而不是在人体骨骼图上操作的坐标。不同时间步的热图将沿着时间维度堆叠,形成一个3D heatmap volume。然后,PoseConv3D在3D heatmap volume上采用三维卷积神经网络来识别动作。表1总结了PoseConv3D和基于gcn的方法之间的主要区别。
二维姿势是由骨骼关节的热图堆栈来表示的,而不是在人体骨骼图上操作的坐标。不同时间步的热图将沿着时间维度堆叠,形成一个3D heatmap volume。然后,PoseConv3D在3D heatmap volume上采用三维卷积神经网络来识别动作。表1总结了PoseConv3D和基于gcn的方法之间的主要区别。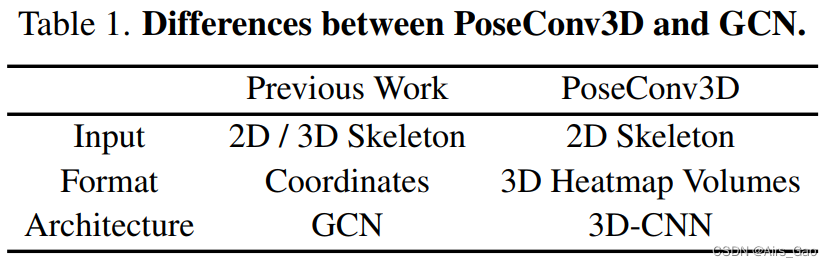 PoseConv3D可以解决上述基于gcn的方法的局限性。
PoseConv3D可以解决上述基于gcn的方法的局限性。(1)首先,使用3D heatmap volume对上游姿态估计更稳健: 根据经验,我们发现PoseConv3D可以很好地泛化通过不同方法获得的输入骨架。
(2)此外,PoseConv3D依赖于基础表示的热图,享受了卷积网络架构的最新进展,更容易与其他模式集成到多流卷积网络中。这一特性为进一步提高识别性能开辟了巨大的设计空间。
(3)最后,PoseConv3D可以处理不同数量的人,而不会增加计算开销,因为3D heatmap volume的复杂性与人数无关。
2. Related Work
2.1 基于3D-CNN的rgb视频动作识别
3D-CNN是2D-CNN对图像空间特征学习到视频时空特征学习的自然延伸。由于3D-CNN有大量的参数,因此需要大量的视频来学习良好的表示。3D-CNN自I3D以来已成为动作识别的主流方法。2.2 基于GCN的骨骼动作识别
图卷积网络被广泛应用于基于骨骼的动作识别中.它将人体骨骼序列建模为时空图。ST-GCN是基于gcn的方法的一个众所周知的基线,它结合了空间图卷积和交错时间卷积进行时空建模。尽管取得了巨大的成功,在基于骨骼的动作识别中,GCN在鲁棒性和可扩展性方面也有局限性。此外,对于基于gcn的方法,融合骨架和其他模式的特征可能需要仔细设计。2.3 基于CNN的骨骼动作识别
基于2d - cnn的方法首先将骨架序列建模为基于手动设计转换的伪图像。其中一行工作是沿着时间维度将热图聚集到带有颜色编码或学习模块的2D输入中。尽管经过精心设计,但在聚合过程中仍会出现信息丢失,导致识别性能较差。其他作品直接将骨架序列中的坐标转换为经过变换的伪图像,通常生成形状为K ×T的二维输入,其中K为关节数,T为时间长度。这样的输入不能利用卷积网络的局部性,这使得这些方法在流行的基准上不像GCN那样具有竞争力。此前只有少数研究采用3d - cnn进行基于骨骼的动作识别。为了构建3D输入,他们要么将距离矩阵的伪图像叠加,要么直接将3D骨架累加为长方体。这些方法还会严重丢失信息,性能远不如最先进的方法。我们的工作沿着时间维度堆叠热图,形成3D heatmap volumes,在这个过程中保存所有信息。此外,我们使用3D-CNN以其良好的时空特征学习能力取代2D-CNN。3. Framework
我们提出了一种基于3d - cnn的骨骼动作识别方法PoseConv3D,它可以成为基于GCN的方法的一种有竞争力的替代方案,在各种设置下,在提高鲁棒性、互操作性和可伸缩性的准确性方面优于GCN。图2描述了PoseConv3D的概述: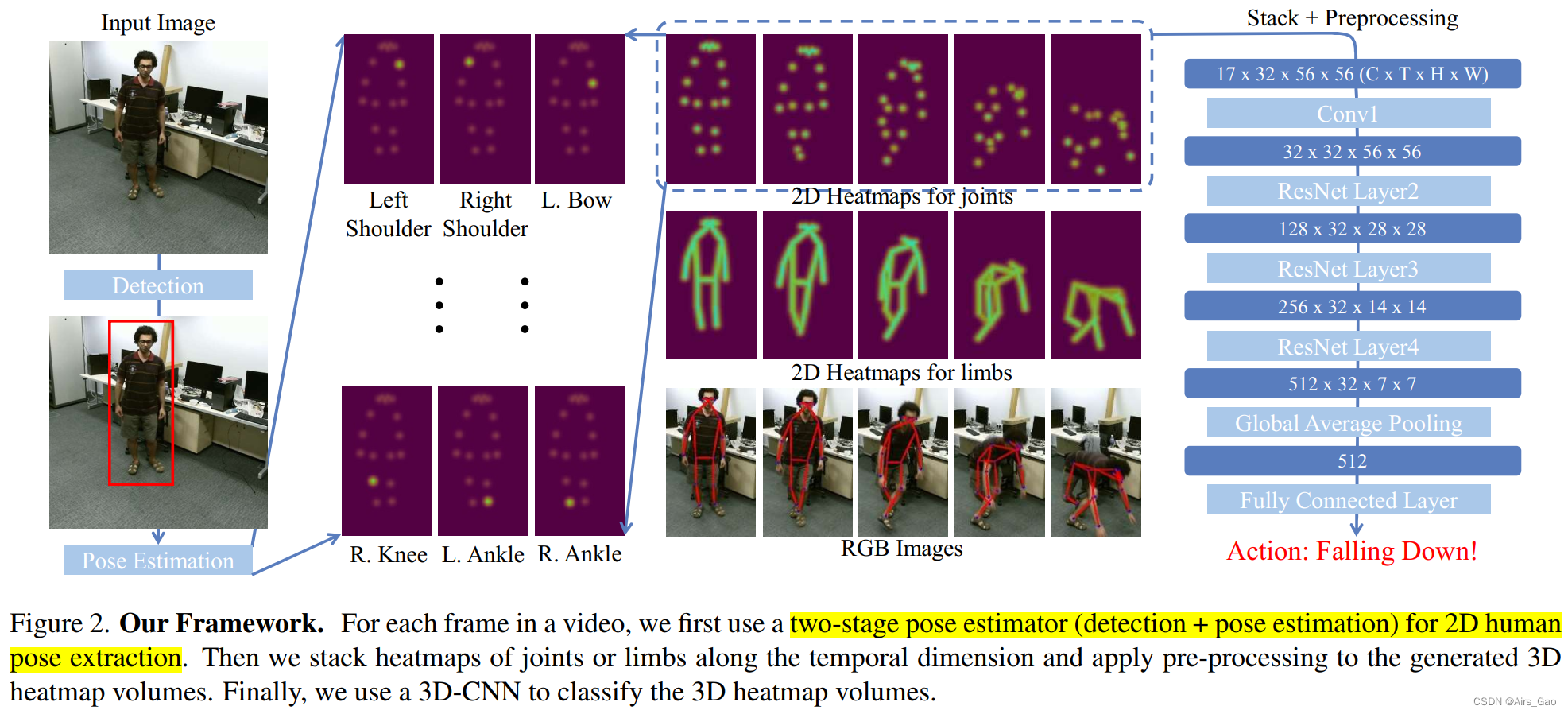 我们首先回顾了骨骼提取,这是基于骨骼的动作识别的基础,但在以往的文献中经常被忽视。我们指出了在选择骨架提取器时应该考虑的几个方面,并鼓励在PoseConv3D中使用2D骨架。随后,我们介绍了3D Heatmap Volume,这是在PoseConv3D中使用的2D骨架序列的表示,随后介绍了PoseConv3D的结构设计,包括一个侧重于人体骨骼形态的变体,以及一个结合人体骨骼形态和RGB帧的变体,以演示PoseConv3D的互操作性。
我们首先回顾了骨骼提取,这是基于骨骼的动作识别的基础,但在以往的文献中经常被忽视。我们指出了在选择骨架提取器时应该考虑的几个方面,并鼓励在PoseConv3D中使用2D骨架。随后,我们介绍了3D Heatmap Volume,这是在PoseConv3D中使用的2D骨架序列的表示,随后介绍了PoseConv3D的结构设计,包括一个侧重于人体骨骼形态的变体,以及一个结合人体骨骼形态和RGB帧的变体,以演示PoseConv3D的互操作性。 3.1 Pose Extraction
人体骨骼或姿态提取是基于骨骼的动作识别的重要预处理步骤,对最终的识别精度有很大影响。在这里,我们对姿态提取的关键方面进行了回顾,以找到一个好的实践。一般来说,2D姿势比3D姿势质量更好,如图1所示.我们采用二维自顶向下的位姿估计进行位姿提取。在估计热图的存储方面,它们通常被存储为 coordinate-triplets (x;y;C),其中C表示热图的最大得分,(x;y)是c的对应坐标。我们发现coordinate-triplets (x; y; C)以很少的性能下降为代价节省了大部分存储空间。3.2 From 2D Poses to 3D Heatmap Volumes
在从视频帧中提取2D姿势后,为了将其输入到PoseConv3D中,我们将它们重新制定为3D heatmap volume。形式上,我们将二维姿势表示为大小为K × H × W的热图,其中K为关节的数量,H和W是框架的高度和宽度。我们可以直接使用由自上而下的位姿估计器产生的热图作为目标热图,在给定相应的边界框的情况下,应该对目标热图进行零填充以匹配原始帧。如果我们只有coordinate-triplets (xk;yk;ck)时,可以得到由 K 个关节点处的高斯热图组成的关节热图(joint heatmap) J: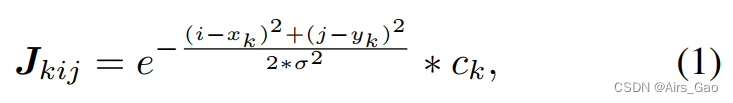
σ控制高斯映射的方差,(xk;Yk)和ck分别为第k个关节的位置和置信度分数。我们还可以创建肢体热图(limb heatmap)L:
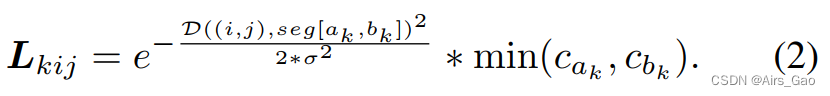
第k肢位于两个关节ak和bk之间。
函数D计算从点(i,j)到段[(x_ak, y_ak), (x_bk, y_bk)]的距离。
(1)SubjectsCentered Cropping
使热图与框架一样大是低效的,特别是当相关人员只在一个小区域活动时。
在这种情况下,我们首先找到最小的包围框,包围所有的2D姿势跨帧。
然后我们根据找到的框裁剪所有帧,并将它们调整为目标大小。
因此,三维热图的体积可以在空间上减小,而所有二维姿态和它们的运动被保留。
(2)Uniform Sampling
通过对帧的子集进行采样,还可以沿时间维减小3D热图的体积。
与以往基于rgb的动作识别工作不同的是,研究人员通常在短时间窗口中采样帧,例如在SlowFast中所述的64帧时间窗口中采样帧,我们建议对3D-CNNs 使用统一采样策略。
特别地,为了从一个视频中采样n帧,我们将视频分成n个长度相等的片段,并随机从每个片段选择一帧。
Uniform Sampling策略能更好地保持视频的全局动态。
3.3 基于骨骼的动作识别3D-CNN
在基于骨骼的动作识别中,GCN一直是主流的backbone。相比之下,在基于rgb的动作识别中常用的有效网络结构3D-CNN在这方面的研究较少。为了展示3D-CNN在捕捉骨骼序列时空动态方面的能力,我们设计了两个3D-CNN家族,即用于Pose 模态的PoseConv3D和用于RGB+Pose双模态的RGBPose-Conv3D。3.3.1 PoseConv3D:
PoseConv3D专注于人体骨骼的形态,它采用3D heatmap volumes作为输入,可以用各种3D-CNN的backbones实例化。
基于骨骼的动作识别,需要对3D-CNN进行两处改进:
(a)从3D- cnn中删除了早期阶段的下采样操作,因为3D heatmap volumes的空间分辨率不需要像RGB剪辑那么大(4× smaller in our setting)。
(b)一个更浅(更少的层)和更薄(更少的通道)的网络足以建模人类骨骼序列的时空动态,因为3D heatmap volumes已经是动作识别的中级特征。
基于这些原则,我们改编了三种流行的3d - cnn: C3D、SlowOnly和X3D,到基于骨骼的动作识别。
在NTURGB+D-XSub基准测试上对改编的3d - cnn的不同变体进行评估: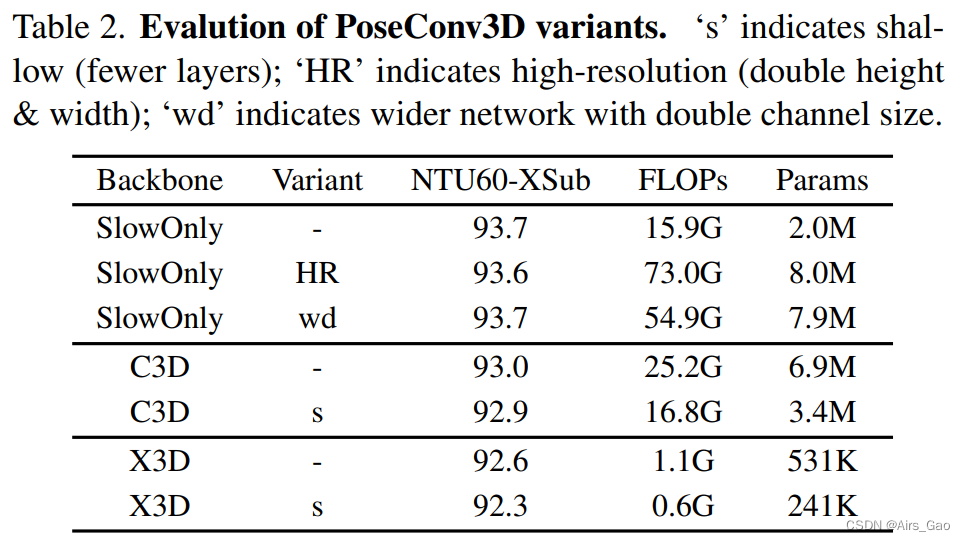
采用轻量级版本的3D- cnn可以显著降低计算复杂度,但识别性能略有下降(所有3D骨干≤0.3%)。
在实验中,我们使用SlowOnly作为默认的主干,考虑到它的简单性(直接从ResNet膨胀)和良好的识别性能。
PoseConv3D在准确性和效率方面都优于具有代表性的GCN / 2D-CNN。
更重要的是,PoseConv3D与基于rgb动作识别的流行网络之间的互操作性,使得在多模态融合中很容易涉及人体骨骼。
3.3.2 RGBPose-Conv3D
为了展示PoseConv3D的互操作性,我们提出RGBPose-Conv3D用于早期的人体骨骼和RGB帧的融合。
这是一个双流3D-CNN有两条路径分别处理RGB模态和Pose模态。
RGBPose-Conv3D的体系结构总体上遵循几个原则:
(1)由于两种模式的特点不同,这两条路径是不对称的。与RGB通道相比,姿态路径具有较小的通道宽度、较小的深度和较小的输入空间分辨率。
(2)受到SlowFast的启发,增加了两个通路之间的双向横向连接,促进两种模式之间的早期特征融合。
为了避免过拟合,RGBPose-Conv3D对每条路径分别使用两个单独的交叉熵损失进行训练。
在实验中,我们发现,通过横向连接实现的早期特征融合与仅在后期融合相比,会带来一致的改善。
4. 实验
4.1 数据集
我们在实验中使用了6个数据集:FineGYM,NTURGB+D, Kinetics400, UCF101,HMDB51和Volleyball。
我们使用自顶向下的方法进行姿势提取:
(1)检测器选择带有ResNet50 backbone的fast - rcnn。
(2)位姿估计器选择在coco关键点上预训练的HRNet。
对于除FineGYM外的所有数据集,通过直接对RGB输入应用TopDown位姿估计来获得2D位姿。
我们report了在数据集上的平均Top-1的准确度。
我们在实验中采用了在MMAction2[11]中实现的3D ConvNets。
FineGYM
FineGYM是一个细粒度动作识别数据集,包含99个细粒度体操动作类的29K视频。在姿态提取过程中,我们比较了三种不同的人物边界框:(1)检测器预测的人员边界框(Detection);
(2)GT为第一帧运动员设置的边界框,为剩余帧设置的跟踪框(Tracking).
(3)运动员在所有帧内的GT框(GT)
在实验中,我们使用第三种边界框提取的人体姿态.
NTURGB+D
NTURGB+D是在实验室收集的大规模人体动作识别数据集。它有两个版本,即NTU-60和NTU-120:NTU-60包含57K视频,包含60个人类动作,而NTU-120包含114K视频,包含120个人类动作。数据集以三种方式划分: Cross-subject(X-Sub),Cross-view(X-View,用于NTU-60),Cross-setup(X-Set,用于NTU-120),其动作对象、相机视图、相机设置在训练和验证中是不同的。传感器收集的3D骨架可用于该数据集。我们对NTU-60和NTU-120的X-sub划分方法进行了实验。Kinetics400, UCF101, and HMDB51
这三个数据集是从网上收集的一般动作识别数据集。Kinetics400是一个大型视频数据集,包含来自400个动作类的300K视频。UCF101和HMDB51较小,UCF101包含来自101个类别的13K视频,HMDB51包含来自51个类别的6.7K视频。我们使用Top-Down提取的2d姿势注释进行实验。Volleyball
Volleyball是一个包含8个群体活动课程的4830个视频的群体活动识别数据集。每帧包含大约12人,而只有中心帧有GT人框的注释。我们使用跟踪框进行姿态提取。4.2 PoseConv3D的性能
为了阐述3D CNN优于graph networks的良好特性,我们将PoseSlowOnly与MS-G3D进行了比较,MS-G3D是一种具有代表性的多维度基于gcn的方法。两个模型采用完全相同的输入(GCN的coordinate-triplets,PoseConv3D的coordinate-triplets生成的热图)。Performance & Efficiency
PoseConv3D的输入尺寸采用48×56×56。表3显示,在这样的配置下,PoseConv3D在参数数量和flop数量上都比GCN轻。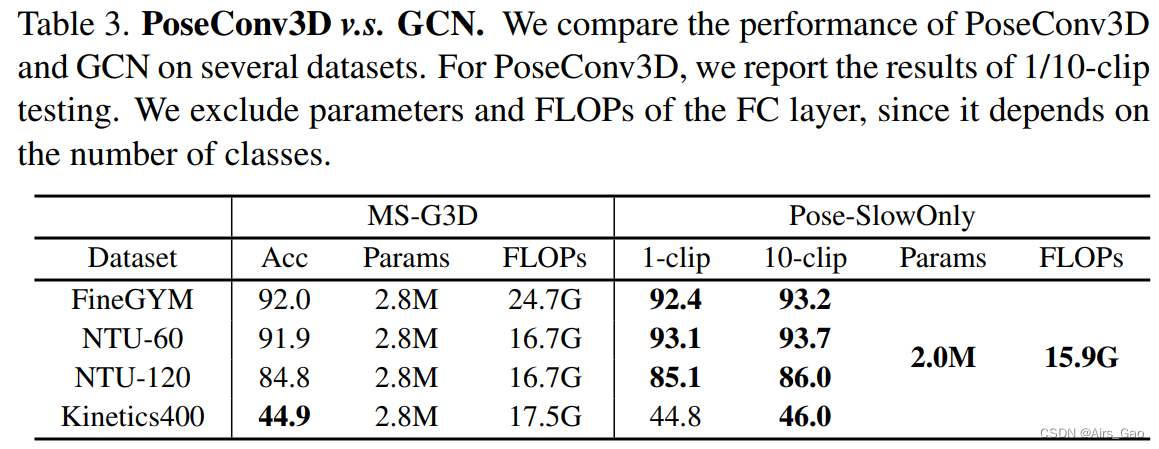 虽然是轻量级的,但PoseConv3D在不同的数据集上实现了具有竞争力的性能。此外,PoseConv3D对不同的数据集使用相同的体系结构和超参数,而GCN依赖于对不同数据集的体系结构和超参数进行大量调优。
虽然是轻量级的,但PoseConv3D在不同的数据集上实现了具有竞争力的性能。此外,PoseConv3D对不同的数据集使用相同的体系结构和超参数,而GCN依赖于对不同数据集的体系结构和超参数进行大量调优。 Robustness
为了测试这两个模型的鲁棒性,我们可以在输入中删除一定比例的关键点,看看这种扰动将如何影响最终的精度。由于肢体关键点对体操来说比躯干或面部关键点更关键,我们通过在每帧中随机丢弃一个肢体关键点来测试这两个模型,概率为p。在表4中,我们看到PoseConv3D对输入扰动具有高度的鲁棒性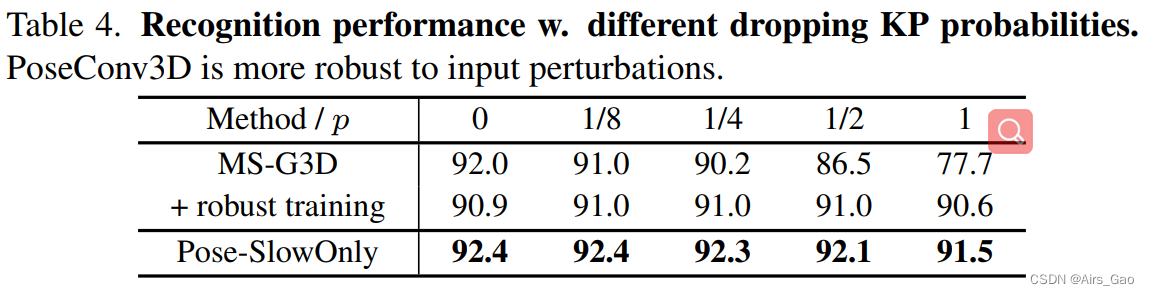 对于PoseConv3D,每帧减少一个分支关键点会导致Mean-Top1的适度下降小于1%,对于GCN, 下降14.3%。GCN在p = 1的情况下,GCN的Mean-Top1精度仍然下降了1.4%。此外,通过强大的训练,在p = 0的情况下,将额外下降1.1%。实验结果表明PoseConv3D在姿态识别的鲁棒性方面明显优于GCN。
对于PoseConv3D,每帧减少一个分支关键点会导致Mean-Top1的适度下降小于1%,对于GCN, 下降14.3%。GCN在p = 1的情况下,GCN的Mean-Top1精度仍然下降了1.4%。此外,通过强大的训练,在p = 0的情况下,将额外下降1.1%。实验结果表明PoseConv3D在姿态识别的鲁棒性方面明显优于GCN。 Generalization
为了比较GCN和3D-CNN的泛化性,我们在FineGYM上设计了一个跨模型检验。具体来说,我们使用了两个模型,即HRNet (HigherQuality,简称HQ)和MobileNet (Lower-Quality,LQ)进行位姿估计,并在其上分别训练两个PoseConv3D。在测试过程中,我们将LQ输入到HQ 训练的模型中,反之亦然。从表5a中,我们可以看到,与GCN相比,在使用较低质量的姿势进行训练和测试时,使用PoseConv3D的准确性下降更小。
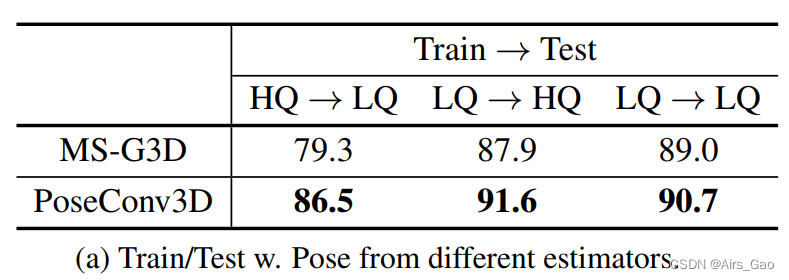 类似地,我们也可以改变人员框的来源,使用GT框(HQ)或跟踪结果(LQ)进行训练和测试。结果如表5b所示。
类似地,我们也可以改变人员框的来源,使用GT框(HQ)或跟踪结果(LQ)进行训练和测试。结果如表5b所示。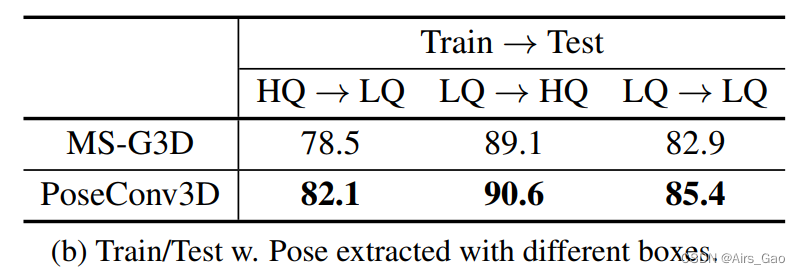 PoseConv3D的性能下降也比GCN小得多。
PoseConv3D的性能下降也比GCN小得多。 Scalability
GCN的计算量随着视频中人数的增加呈线性增长,对群体活动的识别效率较低。我们使用Volleyball数据集上的一个实验来证明这一点。数据集中的每个视频包含13个人和20帧。对于GCN,相应的输入形状为13×20×17×3,比一个人的输入大13倍。在此配置下,GCN的参数数和flop数分别为2.8M和7.2G (13×)。对于PoseConv3D,我们可以使用一个单一的热图体积(形状为17×12×56×56)来表示所有13个人。Pose-SlowOnly基本通道宽度设置为16,导致只有0.52M的参数和1.6 GFLOPs。尽管参数和flop要小得多,但PoseConv3D在排球验证上达到了91.3%的Top-1精度,比基于gcn的方法高2.1%。4.3 基于RGBPose-Conv3D的多模态融合
PoseConv3D的3D-CNN架构通过一些早期的融合策略使其更灵活地将姿态与其他模式融合。如,在RGBPose-Conv3D中,在早期阶段,利用rgb通路和姿态通路之间的横向连接进行跨模态特征融合。在实践中,我们首先分别训练RGB 和 Pose两个模型,并使用他们初始化RGBPose-Conv3D。为了训练横向连接,我们持续调整了几个阶段的网络。最后的预测是通过后期融合来自两个路径的预测分数来实现的。RGBPose-Conv3D融合早期+晚期融合(early+late fusion)效果较好。我们首先在表6中比较了单向横向连接和双向横向连接。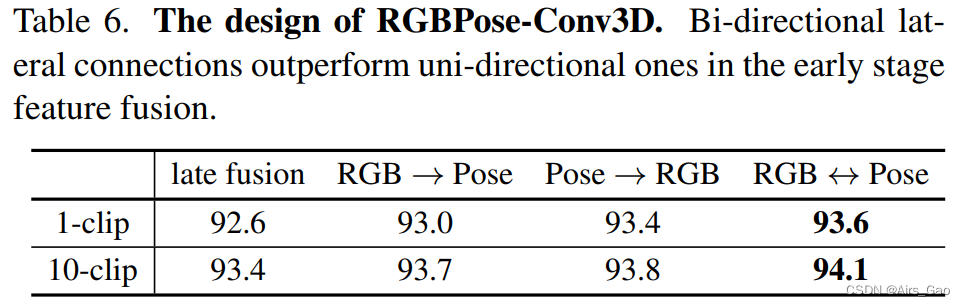 结果表明,对于RGB和Pose,双向特征融合优于单向特征融合。早期以双向特征融合为主,early+late fusion with 1-clip测试性能优于late fusion with 10-clip测试。此外,RGBPose-Conv3D也适用于两个模式的重要性不同的情况。姿态模态在FineGYM中更重要,在NTU-60中则相反。我们观察到,在表7中,通过早期+晚期融合两者的性能改善。
结果表明,对于RGB和Pose,双向特征融合优于单向特征融合。早期以双向特征融合为主,early+late fusion with 1-clip测试性能优于late fusion with 10-clip测试。此外,RGBPose-Conv3D也适用于两个模式的重要性不同的情况。姿态模态在FineGYM中更重要,在NTU-60中则相反。我们观察到,在表7中,通过早期+晚期融合两者的性能改善。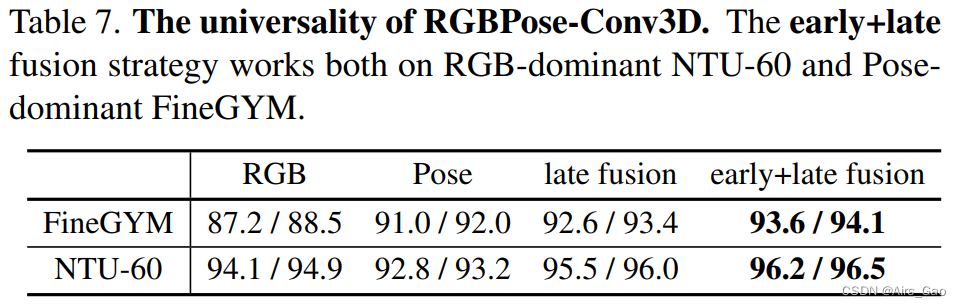
4.4 Comparisons with the state-of-the-art
Skeleton-based Action Recognition
在表8中,我们比较了基于骨骼动作识别的PoseConv3D与之前的工作。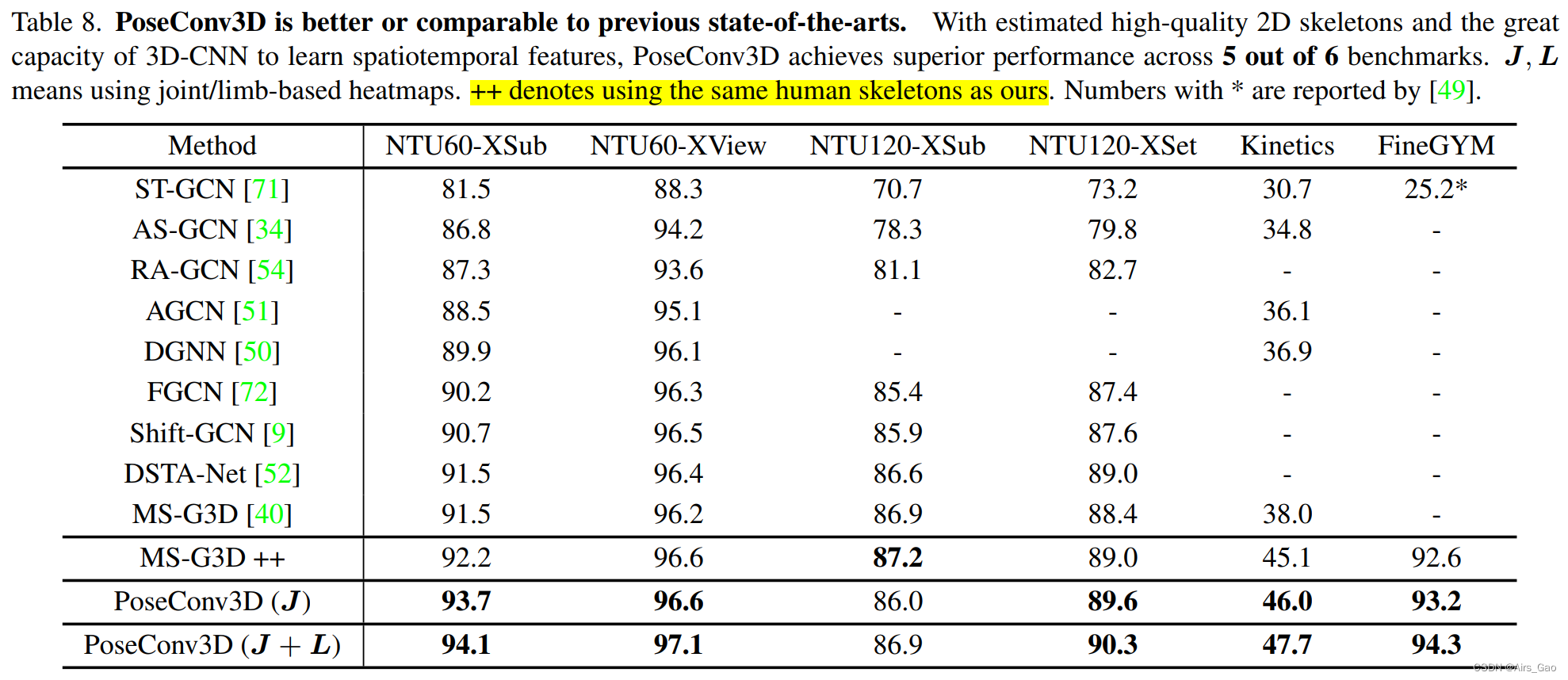 我们用SlowOnly主干实例化PoseConv3D,输入形状为48×56×56的3D热图卷,并报告通过10-clip 测试获得的准确性。使用高质量的2D人体骨骼,MS-G3D++和PoseConv3D都实现了比之前的先进技术水平更好的性能,证明了在基于骨骼的动作识别中提出的姿态提取实践的重要性。当两者都采用高质量的2D姿态作为输入时,PoseConv3D在6个基准测试中的5个测试中都优于最先进的MS-G3D,显示出其强大的时空特征学习能力。
我们用SlowOnly主干实例化PoseConv3D,输入形状为48×56×56的3D热图卷,并报告通过10-clip 测试获得的准确性。使用高质量的2D人体骨骼,MS-G3D++和PoseConv3D都实现了比之前的先进技术水平更好的性能,证明了在基于骨骼的动作识别中提出的姿态提取实践的重要性。当两者都采用高质量的2D姿态作为输入时,PoseConv3D在6个基准测试中的5个测试中都优于最先进的MS-G3D,显示出其强大的时空特征学习能力。 Multi-modality Fusion
作为一种强大的表现形式,骨骼也补充了其他模式,如RGB外观。基于多模融合(RGBPose-Conv3D或LateFusion),我们在8个不同的视频识别基准上实现了SOAT的结果。我们将提出的RGBPose-Conv3D应用于FineGYM和4个NTURGB+D基准,以R50为骨干;16,48作为RGB/pose通道的时间长度。表9a显示我们的早期+晚期融合在各种基准测试中取得了优异的性能。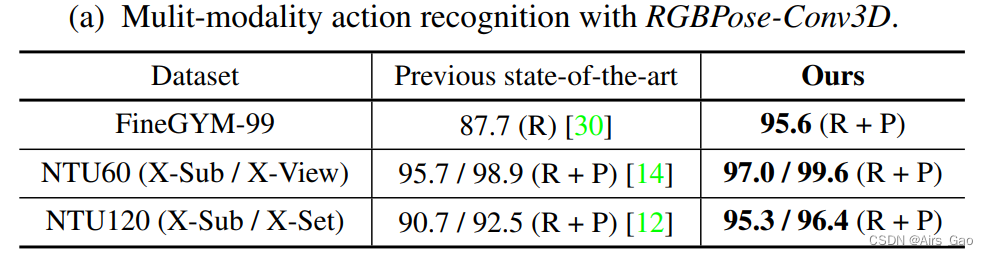 我们还尝试用LateFusion将PoseConv3D的预测直接与其他模式融合。表9b显示,与Pose模态的后期融合可以将识别精度提高到一个新的水平。
我们还尝试用LateFusion将PoseConv3D的预测直接与其他模式融合。表9b显示,与Pose模态的后期融合可以将识别精度提高到一个新的水平。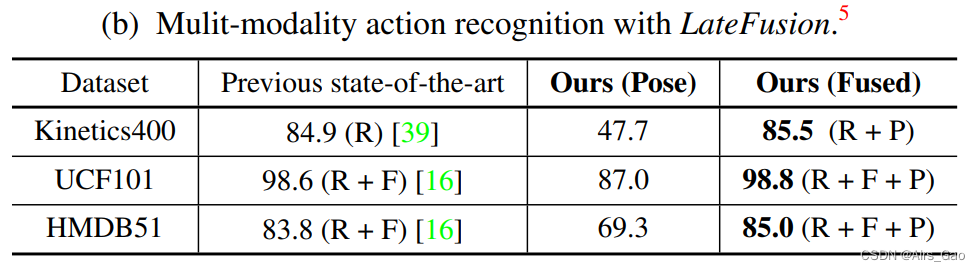 我们在三个动作识别基准上实现了SOAT的技术水平: Kinetics400,UCF101, HMDB51。在具有挑战性的Kinetics400基准上,与PoseConv3D预测融合后,识别精度比SOAT方法的水平提高了0.6%。
我们在三个动作识别基准上实现了SOAT的技术水平: Kinetics400,UCF101, HMDB51。在具有挑战性的Kinetics400基准上,与PoseConv3D预测融合后,识别精度比SOAT方法的水平提高了0.6%。 5. 其它补充内容
5.1 Visualization
我们提供了四个数据集:FineGYM, NTURGB+D, Kinetics400,Volleyball的姿态提取方法进行了定性论证。



5.2 Generating Pseudo Heatmap Volumes
在本节中,我们将演示如何生成pseudo heatmap volumes(PoseConv3D的输入)。我们还提供一个jupyter notebook命名GenPseudoHeatmaps.ipynb,它可以从RGB视频中提取骨架关键点(可选),并根据骨架关键点生成伪热图。图9演示了姿态提取的流程(RGB video > coordinate-triplets)和生成生成伪热图块 (coordinate-triplets > 3D heatmap volumes)的流程。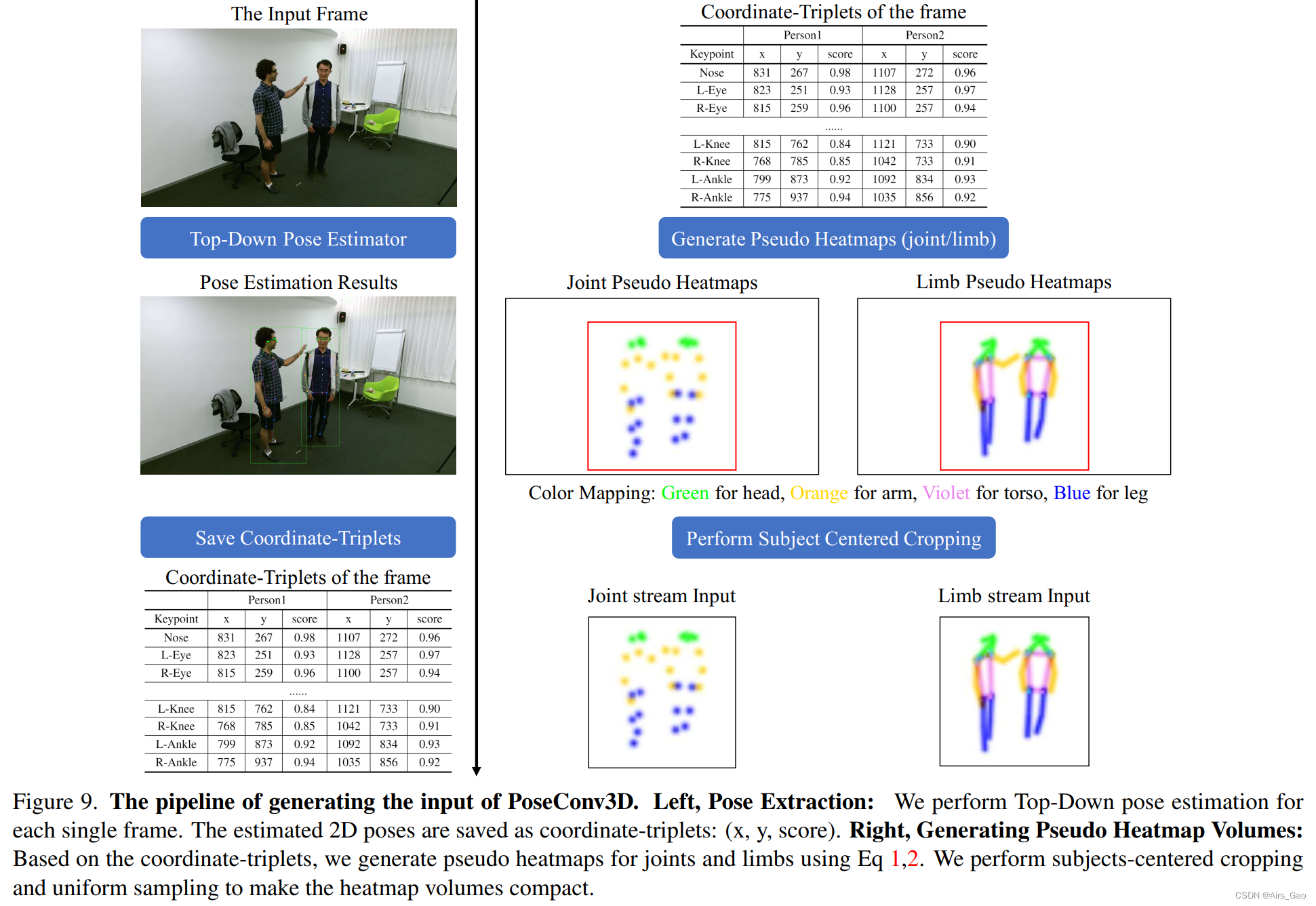 尽管热图有K个通道(对于COCOkeypoints K = 17),我们将其可视化为一个带有彩色编码的2D图像。对于姿势提取,我们使用一个由HRNet实例化的自顶向下姿势估计器来提取每一帧中每个人的2D姿势,并保存coordinate-triplets:(x, y, score)。为了生成伪热图,我们首先进行统一采样,从视频中统一采样T帧,丢弃剩余帧。然后我们找到一个全局裁剪框(图9中的红色框,对于所有T帧都是一样的),它包含视频中的所有人,并用该框裁剪所有T帧以减少空间大小。
尽管热图有K个通道(对于COCOkeypoints K = 17),我们将其可视化为一个带有彩色编码的2D图像。对于姿势提取,我们使用一个由HRNet实例化的自顶向下姿势估计器来提取每一帧中每个人的2D姿势,并保存coordinate-triplets:(x, y, score)。为了生成伪热图,我们首先进行统一采样,从视频中统一采样T帧,丢弃剩余帧。然后我们找到一个全局裁剪框(图9中的红色框,对于所有T帧都是一样的),它包含视频中的所有人,并用该框裁剪所有T帧以减少空间大小。 5.3 PoseConv3D的详细架构
(1)PoseConv3D的不同变体
在表11中,我们展示了从基于rgb的动作识别中改编的三个主干的体系结构及其变体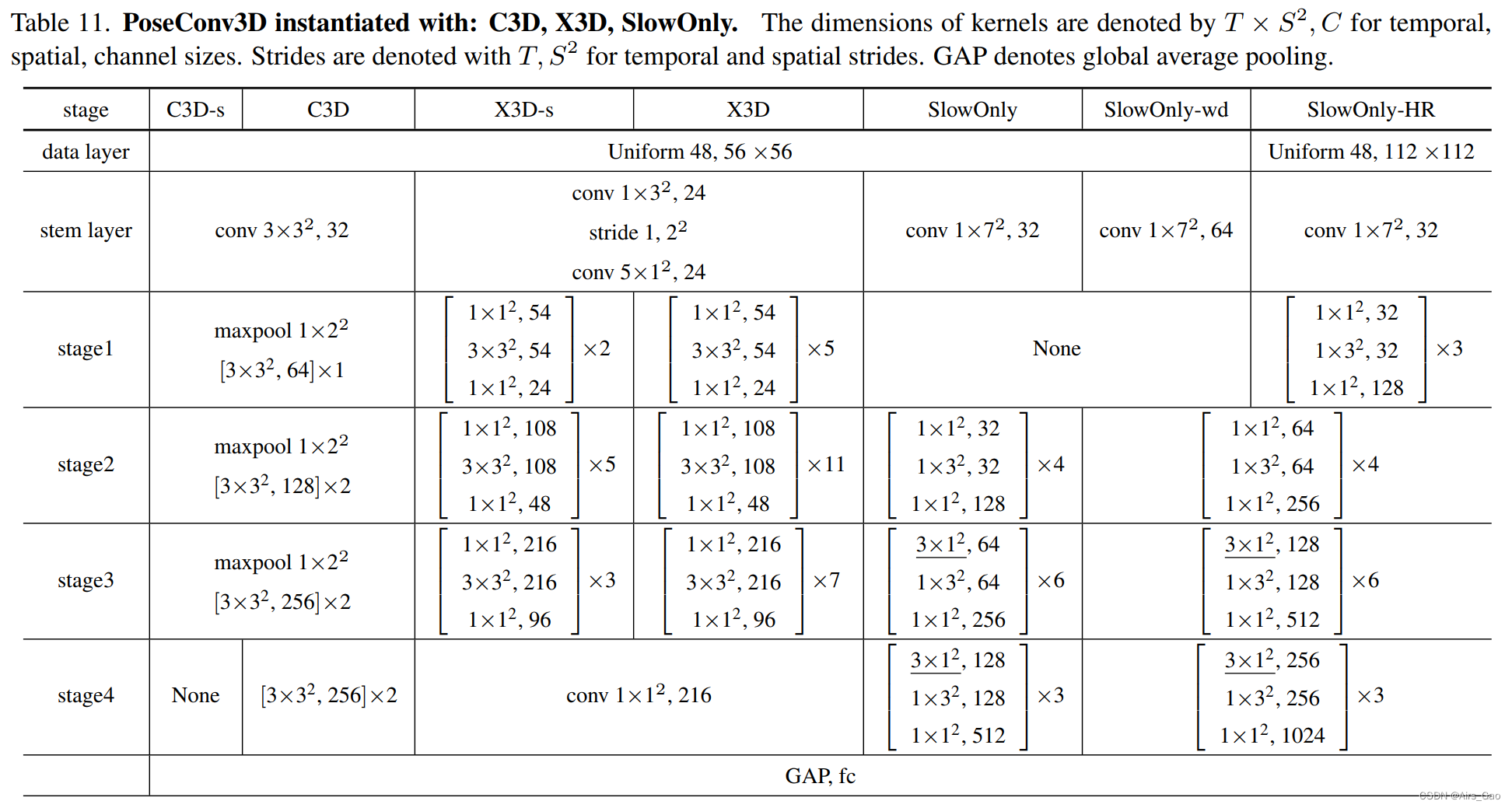
C3D
C3D是最早为基于rgb的动作识别开发的3D-CNN之一(像用于图像识别的AlexNet ),它包括8个3D卷积层。为了使C3D适应基于骨骼的动作识别,我们将其通道宽度减少到一半(64 > 32)提高效率。此外,对于Pose-C3D-s,我们删除了最后两个卷积层。X3D
X3D是最近SOAT的用于动作识别的3D-CNN。用深度卷积代替普通卷积,X3D通过少量的参数和FLOPs实现了具有竞争力的识别性能。与最初的X3D-S相比,改进后的Pose-X3D的架构几乎没有变化,除了我们删除了最初的第一级。对于Pose-X3D-s,我们通过将超参数γd从2.2更改为1来均匀地从每一级去除卷积层。SlowOnly
SlowOnly是一个流行的3D-CNN,用于基于rgb的动作识别。它是通过在最后两个阶段将ResNet层从2D膨胀到3D而获得的。为了使SlowOnly适应基于骨骼的动作识别,我们将其通道宽度减少到一半(64 > 32)以及去掉原有的第一级网络。我们还对Pose-SlowOnly-wd(信道宽度64)和Pose-SlowOnly-HR(2倍大的输入和更深的网络)进行了实验。尽管有更重的主干,但性能没有提高。(2)RGBPose-Conv3D用SlowOnly实例化
RGBPose- conv3d是RGBPose双模态动作识别的通用框架,可以用各种3D-CNN主干实例化。在这项工作中,我们用SlowOnly网络实例化了这两条路径。如表12所示,RGB通道具有更小的帧速率和更大的通道宽度,因为RGB帧是底层特性。相反,姿态通道具有较大的帧速率和较小的通道宽度。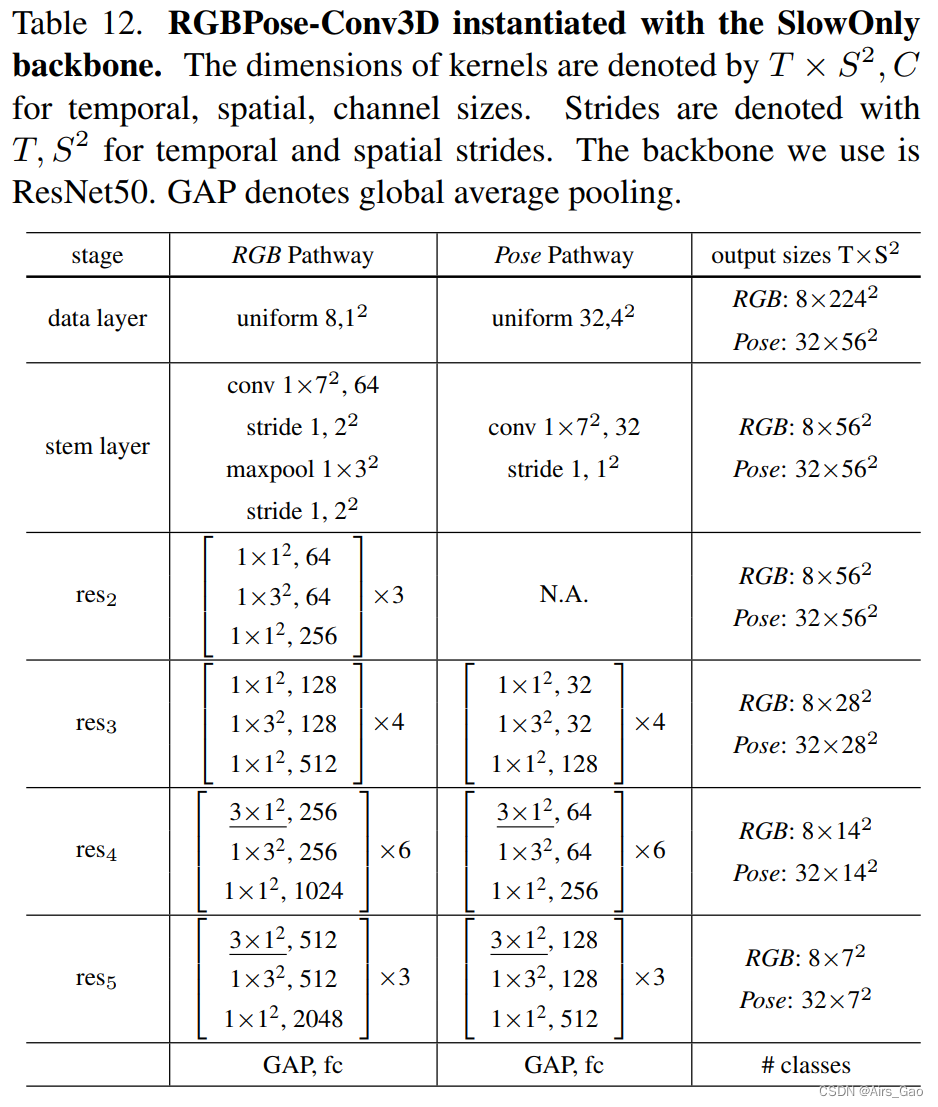 时间跨步卷积作为两个通路(res3和res4之后)之间的双向横向连接,使不同模态的语义能够充分相互作用。除了横向连接外,我们还将两条通路的预测进行了后期融合,这使得我们的实证研究得到了进一步的完善。RGBPoseConv3D在每个通路中分别使用两个单独的损失进行训练,因为一个损失联合从两种模式中学习,会导致严重的过拟合。
时间跨步卷积作为两个通路(res3和res4之后)之间的双向横向连接,使不同模态的语义能够充分相互作用。除了横向连接外,我们还将两条通路的预测进行了后期融合,这使得我们的实证研究得到了进一步的完善。RGBPoseConv3D在每个通路中分别使用两个单独的损失进行训练,因为一个损失联合从两种模式中学习,会导致严重的过拟合。