
大家好!我是码银?
欢迎关注?:
CSDN:码银
公众号:码银学编程

正文
正则表达式
粗略的定义:正则表达式是一个特殊的字符序列,帮助用户非常便捷的检查一个字符串是否符合某种模式。例如:平时我们的登陆密码,必须是字母和数字的组合,就可以使用正则表达式。
正则表达式的特点:灵活性、逻辑性和功能性非常强,可以迅速地用极简单的方式达到字符串的复杂控制。然而,对于刚接触的人来说,可能会觉得比较晦涩难懂。
Python有关正则表达式的方法是在re模块内,所以使用正则表达式需要导入re模块。
import re本篇文章先介绍一下re模块中的几个函数:
| 函数 | 功能 |
| re.match() | 用于从字符串的开始位置进行匹配,如果起始位置匹配 成功,结果为Match对象,否则结果为None。 |
| re.search() | 用于在整个字符串中搜索第一个匹配的值,如果匹配成 功,结果为Match对象,否则结果为None。 |
| re.findall() | 用于在整个字符串搜索所有符合正则表达式的值,结果 是一个列表类型。 |
| re.sub () | 用于实现对字符串中指定子串的替换 |
| re.split() | 字符串中aplit(方法功能相同,都是分隔字符串 |
re.match()
这个方法和re.search()方法类似,但是也有点小差别的:
re.match从字符串的开头开始匹配(也就是说待匹配字符在中间是匹配不到的),如果找到匹配项,则返回一个匹配对象;如果没有找到匹配项,则返回None。re.search在整个字符串中搜索匹配项,如果找到匹配项,则返回一个匹配对象;如果没有找到匹配项,则返回None。import re # 定义一个字符串变量msg,包含一段描述 msg = 'During my two years living in London, I found that the British people really enjoy eating and drinking outdoors.' # 定义一个字符串变量pattern,包含我们要在msg中搜索的文本模式 pattern = 'During' # 使用re.match函数搜索msg中与pattern匹配的文本。如果找到匹配项,则返回一个匹配对象;否则返回None txt = re.match(pattern,msg) # 检查是否找到了匹配项 if txt!=None : # 如果找到了匹配项,则打印匹配的文本 print("测试1输出: ", txt.group()) else: # 如果没有找到匹配项,则打印“测试1搜寻失败” print("测试1搜寻失败") # 定义另一个字符串变量pattern2,包含我们要在msg中搜索的另一个文本模式 pattern2='my' txt = re .match(pattern2, msg) if txt!=None: print("测试2输出:",txt.group()) else: print("测试2搜寻失败")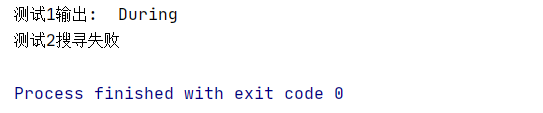
re.search()
由于re.search()方发是全文搜索,所以文章中只要出现对应字符串(开头、中间位置都无所谓,这是与re.match最大的区别),就会返回正确结果。
import re msg = 'During my two years living in London, I found that the British people really enjoy eating and drinking outdoors.' pattern = 'During'txt = re.search(pattern, msg) if txt != None: print("测试1输出: ", txt.group())else: print("测试1搜寻失败") pattern2 = 'my'txt = re.search(pattern2, msg)if txt != None: print("测试2输出:", txt.group())else: print("测试2搜寻失败")输出结果:测试1输出: During测试2输出: myre.findall()
re.findall(pattern, string, flags=0),用于在整个字符串搜索所有符合正则表达式的值,结果
是一个列表类型
pattern:正则表达式模式,用于匹配字符串。string:要搜索的字符串。flags:可选参数,指定正则表达式的匹配选项,如多行匹配、忽略大小写等。 import re# 定义一个正则表达式模式,匹配所有的数字pattern = r'\d+'# 要搜索的字符串string = 'abc123 def456 ghi789'# 使用 re.findall() 查找所有匹配项matches = re.findall(pattern, string)print(matches) 其中\d是“元字符”,具有特殊意义的专用字符,在另外一章文章中在做解释吧。
在上面的示例中,我们定义了一个正则表达式模式 \d+,用于匹配一个或多个数字。然后,我们使用 re.findall() 函数在字符串 abc123 def456 ghi789 中查找所有匹配项。最后,我们将结果打印出来,可以看到成功匹配到了所有的数字。
re.sub ()
re.sub(pattern, repl, string, count=0, flags=0),用于在字符串中使用正则表达式进行查找和替换
pattern:正则表达式模式,用于匹配字符串。repl:替换模式,表示找到匹配项后要替换成的字符串。string:要搜索的字符串。count:可选参数,指定替换操作的次数,默认为 0 表示替换所有匹配项。flags:可选参数,指定正则表达式的匹配选项,如多行匹配、忽略大小写等。 import remsg = 'During my two years living in London'pattern1 = 'years'#欲搜寻字符串newstr = 'days'#新字符串txt = re.sub(pattern1 ,newstr ,msg)#如果找到则取代if txt != msg: print("取代成功:", txt)else: print("取代失败:",txt)pattern2 = 'Eli Thomson'#欲搜寻字符串txt = re.sub(pattern2,newstr,msg)#如果找到则取代if txt!= msg: print("取代成功:",txt)else: print("取代失败: " ,txt)D:\anaconda2019\python.exe D:/pyprogect/正则表达式/test1.py取代成功: During my two days living in London取代失败: During my two years living in Londonre.split()
re.split(pattern, string, maxsplit=0, flags=0),用于根据正则表达式模式将字符串分割成多个子字符串,并返回一个包含所有子字符串的列表。
pattern:正则表达式模式,用于指定分割规则。string:要分割的字符串。maxsplit:可选参数,指定最大分割次数,默认为 0 表示不限制分割次数。sflags:可选参数,指定正则表达式的匹配选项,如多行匹配、忽略大小写等。 import res='https://www.baidu.com/s?wd=CSDN&ie=utf-8&tn=54093922_14_hao_pg'pattern='[?|&]'txt=re.split(pattern,s)print(txt)pattern = ','string = 'apple,banana,orange'split_strings = re.split(pattern, string)print(split_strings) # 输出: ['apple', 'banana', 'orange']输出结果:
D:\anaconda2019\python.exe D:/pyprogect/正则表达式/test2.py['https://www.baidu.com/s', 'wd=CSDN', 'ie=utf-8', 'tn=54093922_14_hao_pg']['apple', 'banana', 'orange']Process finished with exit code 0