文章目录
引言pd.to_numeric函数简介参数详解实战案例进阶应用:处理缺失值与异常值1. 处理缺失值2. 处理异常值 高效利用downcast参数优化内存占用优化性能:使用apply函数批量处理数据实战案例:处理时间序列数据处理多列数据:结合apply函数总结
引言
在数据处理和分析的过程中,经常会遇到需要将数据类型进行转换的情况。Pandas提供了丰富的函数来满足这个需求,其中pd.to_numeric是一种强大而灵活的数据类型转换函数。本篇博客将深入解析pd.to_numeric函数的各种参数,并通过实战案例演示其用法。
pd.to_numeric函数简介
pd.to_numeric函数主要用于将一个或一组值转换为数值类型。其基本语法如下:
pandas.to_numeric(arg, errors='raise', downcast=None)参数详解
arg:可以是各种类型的输入数据,包括单个数值、列表、Series等。例如:import pandas as pd# 单个数值result = pd.to_numeric('123')print(result) # 输出: 123# 列表result = pd.to_numeric(['1', '2', '3'])print(result) # 输出: [1, 2, 3]# Seriesdata = pd.Series(['1', '2', '3'])result = pd.to_numeric(data)print(result)import pandas as pddata = ['1', '2', 'a', '4']# 默认情况,抛出异常result = pd.to_numeric(data)# 输出: ValueError: Unable to parse string "a" at position 2# 使用'coerce',将非数值转为NaNresult = pd.to_numeric(data, errors='coerce')print(result)# 输出: [ 1. 2. nan 4.]# 使用'ignore',保持原值不变result = pd.to_numeric(data, errors='ignore')print(result)# 输出: ['1' '2' 'a' '4']import pandas as pddata = ['1.1', '2.2', '3.3']# 不指定downcast,保持原浮点数类型result = pd.to_numeric(data)print(result)# 输出: [1.1 2.2 3.3]# 指定downcast='integer',将浮点数转为整数result = pd.to_numeric(data, downcast='integer')print(result)# 输出: [1 2 3]实战案例
现在,我们通过一个实战案例来演示pd.to_numeric的用法。假设我们有一个包含混合数据类型的DataFrame,需要将其中的某一列转换为数值类型。
import pandas as pd# 创建包含混合数据类型的DataFramedata = {'ID': [1, 2, 3, 4], 'Value': ['10', '20', '30', 'abc']}df = pd.DataFrame(data)# 查看原始DataFrameprint("原始DataFrame:")print(df)# 使用pd.to_numeric将'Value'列转换为数值类型df['Value'] = pd.to_numeric(df['Value'], errors='coerce')# 查看转换后的DataFrameprint("\n转换后的DataFrame:")print(df)在这个案例中,我们使用pd.to_numeric将DataFrame中的’Value’列转换为数值类型,并通过设置errors='coerce'将非数值转为NaN。这样,我们可以确保在数据分析过程中不会受到非数值的影响。
进阶应用:处理缺失值与异常值
除了基本的数据类型转换外,pd.to_numeric在处理缺失值和异常值时也具备强大的功能。通过设置不同的errors参数,我们可以灵活地控制非数值数据的处理方式,进而处理缺失值和异常值。
1. 处理缺失值
在实际数据中,经常会遇到一些缺失值,这可能是由于数据采集过程中的问题或其他原因导致的。pd.to_numeric中的errors='coerce'参数可以将非数值的数据转换为NaN,帮助我们轻松处理缺失值。
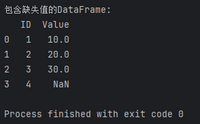
import pandas as pd# 创建包含缺失值的DataFramedata = {'ID': [1, 2, 3, 4], 'Value': ['10', '20', '30', 'abc']}df = pd.DataFrame(data)# 将'Value'列转换为数值类型,将非数值转为NaNdf['Value'] = pd.to_numeric(df['Value'], errors='coerce')# 查看包含缺失值的DataFrameprint("包含缺失值的DataFrame:")print(df)通过上述代码,我们将’Value’列的非数值数据转换为NaN,从而处理了缺失值。这种方式通常比直接删除包含缺失值的行更为灵活,能够在保留其他有效信息的同时进行数据清洗。
2. 处理异常值
在数据中,有时会出现一些异常值,例如特殊字符或者数据录入错误。pd.to_numeric中的errors='raise'参数可以帮助我们及时发现和处理这些异常值。
import pandas as pd# 创建包含异常值的DataFramedata = {'ID': [1, 2, 3, 4], 'Value': ['10', '20', '30', 'abc']}df = pd.DataFrame(data)try: # 尝试将'Value'列转换为数值类型,遇到异常值时抛出异常 df['Value'] = pd.to_numeric(df['Value'], errors='raise')except ValueError as e: print(f"发现异常值: {e}")# 查看异常值未被转换的DataFrameprint("\n异常值未被转换的DataFrame:")print(df)通过将errors='raise',我们在遇到异常值时抛出异常,进而及时发现问题。这种方式在对数据质量要求较高的场景中非常有用,可以帮助我们快速定位并解决异常数据的问题。
高效利用downcast参数优化内存占用
除了处理数据类型和异常值外,pd.to_numeric还提供了downcast参数,允许我们将数据转换为更紧凑的数值类型,从而优化内存占用。在处理大规模数据时,这一功能尤为重要。
import pandas as pd# 创建包含大量数据的DataFramedata = {'ID': range(1, 1000001), 'Value': [str(i) for i in range(1, 1000001)]}df = pd.DataFrame(data)# 查看原始DataFrame的内存占用print("原始DataFrame内存占用:")print(df.memory_usage(deep=True).sum() / (1024 ** 2), "MB")# 将'Value'列转换为整数类型并指定downcast='integer'df['Value'] = pd.to_numeric(df['Value'], downcast='integer')# 查看转换后DataFrame的内存占用print("\n转换后DataFrame内存占用:")print(df.memory_usage(deep=True).sum() / (1024 ** 2), "MB")通过设置downcast='integer',我们将’Value’列的数据转换为整数类型,从而大幅减少了内存占用。这在处理大规模数据时能够显著提高程序的运行效率。
优化性能:使用apply函数批量处理数据
在实际数据处理中,我们经常需要对整个列进行数据类型转换。使用pd.to_numeric结合apply函数可以实现高效的批量处理。
import pandas as pd# 创建包含混合数据类型的DataFramedata = {'ID': range(1, 1000001), 'Value': [str(i) for i in range(1, 1000001)]}df = pd.DataFrame(data)# 使用apply批量处理'Value'列df['Value'] = df['Value'].apply(pd.to_numeric, errors='coerce', downcast='integer')上述代码中,apply函数将pd.to_numeric应用于’Value’列的每个元素,实现了对整列的批量处理。这种方式尤其适用于需要同时处理多列数据的情况,可以提高代码的复用性和整体性能。
实战案例:处理时间序列数据
在实际数据分析中,经常会遇到时间序列数据。pd.to_numeric函数也可以用于处理时间序列中的数值数据,例如将字符串表示的时间转换为数值。让我们通过一个实际案例来演示这个过程。
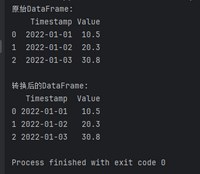
import pandas as pd# 创建包含时间序列的DataFramedata = {'Timestamp': ['2022-01-01', '2022-01-02', '2022-01-03'], 'Value': ['10.5', '20.3', '30.8']}df = pd.DataFrame(data)# 查看原始DataFrameprint("原始DataFrame:")print(df)# 将'Timestamp'列转换为datetime类型df['Timestamp'] = pd.to_datetime(df['Timestamp'])# 将'Value'列转换为数值类型df['Value'] = pd.to_numeric(df['Value'])# 查看转换后的DataFrameprint("\n转换后的DataFrame:")print(df)在上述案例中,我们首先使用pd.to_datetime将’Timestamp’列转换为Pandas的datetime类型,然后使用pd.to_numeric将’Value’列转换为数值类型。这样,我们就成功地将时间序列数据中的字符串转换为可用于分析的数值型数据。
处理多列数据:结合apply函数
当我们需要处理多列数据时,可以使用apply函数结合pd.to_numeric进行批量处理。这在处理大型数据集时尤为有用。
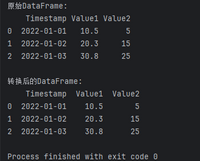
import pandas as pd# 创建包含多列数据的DataFramedata = {'Timestamp': ['2022-01-01', '2022-01-02', '2022-01-03'], 'Value1': ['10.5', '20.3', '30.8'], 'Value2': ['5', '15', '25']}df = pd.DataFrame(data)# 查看原始DataFrameprint("原始DataFrame:")print(df)# 使用apply批量处理数值型数据列numeric_columns = ['Value1', 'Value2']df[numeric_columns] = df[numeric_columns].apply(pd.to_numeric)# 查看转换后的DataFrameprint("\n转换后的DataFrame:")print(df)在上述案例中,我们使用apply函数对列名为’Value1’和’Value2’的列进行了批量处理,将它们转换为数值类型。这种方式既简洁又高效,适用于需要处理多列数值型数据的情况。
总结
通过深入探讨Pandas中的pd.to_numeric函数及其实战案例,我们全面了解了该函数在数据处理中的多方面应用。以下是本篇文章的主要亮点:
基本用法: 我们详细介绍了pd.to_numeric函数的基本语法和参数,包括arg、errors和downcast,使读者对函数有了清晰的认识。
参数详解: 通过实例展示了pd.to_numeric函数中arg、errors和downcast参数的不同设置对数据处理的影响。这有助于读者根据实际需求灵活选择参数,提高数据处理的准确性。
处理缺失值与异常值: 我们演示了如何利用pd.to_numeric函数处理缺失值和异常值,通过errors参数的设置,使函数在面对非数值数据时更加灵活,有力地处理了数据质量问题。
优化内存占用: 通过downcast参数,我们展示了如何在大规模数据处理中优化内存占用,提高程序性能。这对于处理大数据集时尤为重要,能够有效减少内存占用。
高效批量处理: 通过结合pd.to_numeric和apply函数,我们演示了如何高效批量处理数据。这一技巧在处理多列数据时尤为有用,提高了代码的复用性和整体性能。
时间序列数据处理: 通过实际案例,我们展示了如何在处理时间序列数据时利用pd.to_numeric函数将字符串表示的时间转换为数值,为时间序列分析提供了实用的方法。
多列数据处理: 最后,我们通过apply函数结合pd.to_numeric演示了如何批量处理多列数据,简化了代码结构,提高了整体代码的可维护性。
通过这篇文章的学习,读者应该对pd.to_numeric函数有了深入的理解,并能够在实际工作中灵活运用这一功能,提高数据处理的效率和准确性。希望本文为读者在Pandas数据处理中的学习与实践提供了有益的指导。