引言
一天不学编程手就痒,今天是除夕,学C艹vector的话就没时间出去玩了,所以就写写博客。今天要讲的内容是关于,list(列表),tuple(元组),字典(dict),以及文件操作相关的内容,那么我们现在就开始吧!
列表和元组
这两个类型都可以用一个变量来表示很多个数据~类似于C语言中的数组
列表和元组大部分功能都差不多,只是
列表是可变的:可以随时改
元组是不可变的:只能读,不能改(一旦初始化好里面的内容就固定了)
列表
创建列表
1.可以使用字面值来创建
[ ]表示一个空的列表
a = []print(type(a))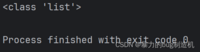
2.使用list()来创建
b = list()print(type(b))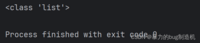
3.在创建列表时,在[ ] 中指定列表初始值并用 ,分隔
a = [1, 2, 3, 4, 5]print(a)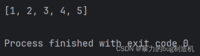
这里介绍一下python列表和元组的逆天属性
在C/C++和JAVA中要求数组只能 存相同类型的变量
但是在python中无此限制
a = [1, 1.5, 'hello', True, [4, 5, 6]]print(a)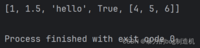
访问和修改下标
通过下标访问的方式来获取列表中的元素~
[ ] 下标访问运算符
把 [ ] 放列表后同时 [ ] 内写一个整数,此时就是下标访问运算符
python中下标从0开始计数
不但可以通过下标访问,同时也可以通过下标修改元素
a = [1, 2, 3, 4]print(a[2])a[2] = 100print(a[2])print(a)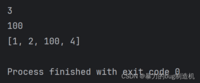
由于下标从0开始计算,对于列表来说,下标有效范围 从 0->长度-1
当越界时,会抛出异常
可以使用内联函数len获取元素个数
a = [1, 2, 3, 4]print(len(a)) 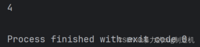
这里的内联函数len可以传的数据类型有很多,包括字符串,列表,元组,字典,自定义的类等等
python中的下标,其实还可以写成负数
写成-1,相当于len(a)-1
a = [1, 2, 3, 4]print(a[len(a)-1])print(a[-1])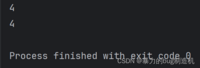
切片操作
使用[ : ]的方式进行切片操作
1.切片的基本使用
a = [1, 2, 3, 4]# 切片支持赋值b = a[1:3]# [1:3)->数学区间print(a[1:3])print(b)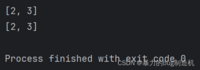
2.切片操作可以省略前后两个边界
a = [1, 2, 3, 4]# 省略后边界print(a[1:])# 省略前边界print(a[:2])# 此处切片同时还可以写成负数print(a[:-1])# 切片还可以都不写print(a[:])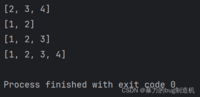
切片操作比较高效,是取出列表中的一部分并无“数据的拷贝”
3.带有步长的切片操作
切片操作还可指定步长
a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]# 下面的1就是步长,一般情况下,不写步长的时候步长默认为1print(a[::1])# 下面步长为2print(a[::2])print(a[1:-1:2])
4.步长的数值可以为负,为负时从后往前取数
a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]print(a[::-1])print(a[::-2])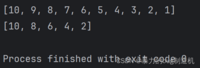
5.当我们切片范围超出有效下标,不会出现异常,而是尽可能把元素获取到
a = [1, 2, 3, 4, 5]print(a[1:100])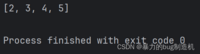
列表的遍历
关于列表的遍历需要搭配循环
1.for循环遍历
a = [1, 2, 3, 4, 5]for elem in a: print(elem) elem = 0print(a)这里的elem与列表中的元素不是同一个,elem只是对列表中元素的拷贝,所以对elem的修改不会影响元素
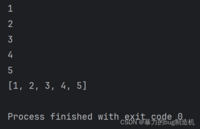
2.使用for循环->下标方式
a = [1, 2, 3, 4, 5]for i in range(0, len(a)): print(a[i])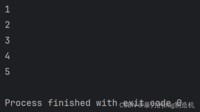
新增元素
1.使用append往列表末尾新增元素
a = [1, 2, 3, 4]a.append(5)a.append('hello')print(a)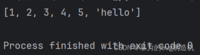
像a.append()这种搭配对象来使用的函数,也叫做方法(method)
python中,对象,就可以视为是“变量”
2.还可以使用insert方法,往列表任意位置新增元素~
a = [1, 2, 3, 4]a.insert(1, 'hello')print(a)# 如果处插入超出列表下标范围则直接插到列表末尾a.insert(100, 'wold')print(a)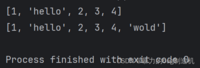
查找元素
1.使用(in/not in)来判定某个元素是否在列表中存在
a = [1, 2, 3, 4]print(1 in a)print(10 in a)print(1 not in a)print(10 not in a)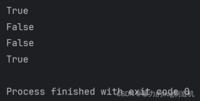
2.使用index方法来判定当前元素在列表中的位置,得到一个下标
a = [1, 2, 3, 4]print(a.index(2))print(a.index(3))# 像下面这种寻找列表中不存在的元素,程序会直接抛异常# print(a.index(10))
删除元素
1.使用pop删除列表末尾元素
a = [1, 2, 3, 4]a.pop()print(a)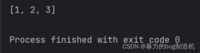
2.使用pop删除任意位置的元素,pop的参数可以传一个下标过去
a = [1, 2, 3, 4]a.pop(1)print(a)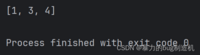
如果pop的下标超出范围,程序会抛异常
3.使用remove方法,可以按照值来进行删除
a = ['aa', 'bb', 'cc', 'dd']a.remove('cc')print(a) 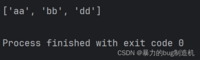
当删除的值不存在时,程序抛出异常
连接列表
1.使用+对两个列表进行拼接
a = [1, 3, 4]b = [2, 5, 6]c = a + bprint(c)print(a + b)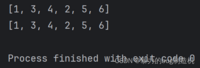
此处拼接链表的操作不会对原有的a和b造成影响
2.使用entend来进行拼接
这个拼接是把后一个列表内容直接拼接到前一个列表里
a = [1, 3, 4]b = [2, 5, 6]a.extend(b)print(a)print(b)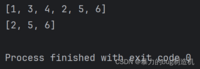
这里extend方法是没有返回值的
a = [1, 3, 4]b = [2, 5, 6]c = a.extend(b)print(c)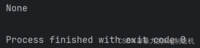
这里打印的None,是一个特殊的变量的值,表示“啥都没有”
3.使用+=来进行拼接
a = [1, 3, 4]b = [2, 5, 6]a += bprint(a)print(b) 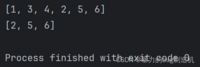
这里的+=和extend方法的作用一样,但是+=相对extend低效,a += b包含了拼接和拷贝两个操作(a和b先拼接成一个临时的大列表,再将大列表拷贝给a),而extend只包含拼接这一步
所以,在进行列表拼接操作的过程中,尽量使用extend方法拼接
元组
元组这里和列表的性质和操作方式有很多是相同的,所以就集中一口气讲完了
1.和列表一样,两种方式初始创建元组
a = ()b = tuple()print(type(a))print(type(b)) 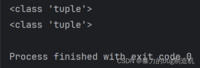
2.在创建元组时,指定初始值,和列表创建的方式极其相似,不过用的是()
a = (1, 2, 3, 4)print(a)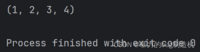
3.元组的元素也可以是任意类型的
a = (1, 'hello', True, 1.5, [1, 2, 3])print(a)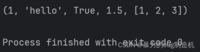
4.通过下标访问元组中的元素,从0~len-1结束
a = (1, 2, 3, 4)print(a[1])print(a[-1])# 像下面这种超出范围的范围同样导致程序抛异常# print(a[100])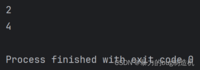
5.通过切片来获取元组中的一个部分
a = (1, 2, 3, 4)print(a[1:3])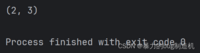
6.同样可以使用for循环遍历元素
a = (1, 2, 3, 4)for elem in a: print(elem)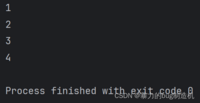
7.可以使用(in/not in)判定元素是否存在,使用index查找元素下标
a = (1, 2, 3, 4)print(3 in a)print(a.index(3))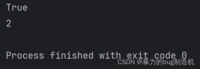
8.使用+来拼接两个元组
a = (1, 2, 3)b = (4, 5, 6)c = a + bprint(c)print(a + b)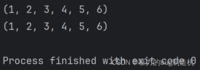
9.元组只支持“读”操作,不能支持“修改”操作
a = (1, 2, 3, 4)# 以下改的操作都是元组所不支持的# a[1] = 100# a.append(5)# a.pop()# a.extend()10.当进行多元素赋值时,本质上是按照元组的方式来进行工作的
def getPoint(): x = 10 y = 20 return x, yx, y = getPoint()print(type(getPoint()))列表式返回返回的其实是一个元组
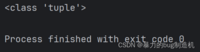
元组不可修改,所以是不可变对象,而不可变对象又是可哈希的!(后续再继续介绍此性质)
字典
字典包含,键(key)和值(value)两部分
字典的键和值是一种映射关系:根据字典的key可以快速找到value
在python的字典中,可以同时包含很多键值对,同时要求这些键,不能重复!
创建字典
a = {}b = dict()print(type(a))print(type(b))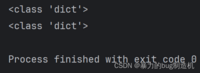
创建字典同时设置初始值
a = {'id': 1, 'name': 'zhangsan'}print(a)上述字典a中,包含了两个键值对
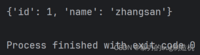
key和value的类型不必都一样
字典中,对于key的类型有约束,对于value的类型无约束,这个后面再具体介绍
查找key
1.使用(in/not in)来判定某个key是否在字典中存在
a = {'id': 1, 'name': 'zhangsan'}print('id' in a)print('name' in a)print('classname' in a)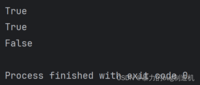
虽然可以查找key,但是没有提供查找value的方式,像'zhangsan' in a,这句命令是无法在字典中找到对应的内容的
2.使用[ ]根据key获取value
a = { 'id': 1, 'name': 'zhangsan', # key的数据类型也可以是整数 100: 'lisi'}print(a['id'])print(a['name'])print(a[100])# 像下面这样写,key不存在时抛异常# print(a['classID']) 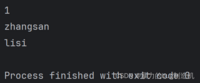
对于字典,用in或[ ]来获取value,都是很高效的操作(字典底层使用了哈希表~)
对于列表,使用in较低效(需要把整个列表遍历一遍),而使用[ ]是比较高效的(类似数组下标)
新增,修改和删除元素
1.在字典中新增元素用[ ]来进行
a = { 'id': 1, 'name': 'zhangsan'}print(a)# 下面一行的操作就是往列表中插入新键值对a['score'] = 90print(a)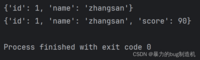
2.在字典中,根据key修改value,用[]
a = { 'id': 1, 'name': 'zhangsan', 'score': 90}print(a)a['score'] = 100print(a)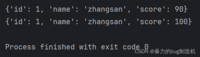
将新增和修改元素总结成两句话:
key存在,根据key改valuekey不存在,相当于新增键值对3.使用pop方法,根据key删除键值对
a = { 'id': 1, 'name': 'zhangsan', 'score': 90}print(a)a.pop('name')print(a)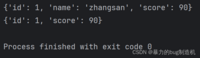
字典中的各种操作都是针对key来进行的增,删,获取value,改value……
字典的遍历
字典被设计出来的初衷,不是为了遍历,而是为了增删改查。
字典是哈希表,进行增删改查操作时,效率都是非常高的,哈希结构很巧妙,能够以”常数级“的时间复杂度来完成增删改查~
但是字典的遍历效率因其结构特性相对会差一些
直接使用for循环来遍历字典
a = { 'id': 1, 'name': 'zhangsan', 'score': 90}for key in a: print(key, a[key]) 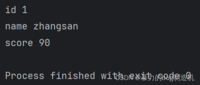
C++和JAVA中,哈希表里面的键值对存储是无序的!
但python中做了特殊处理,能够保证遍历出来的顺序就是和插入顺序一致的。
所以,python中的字典->不是单纯的哈希表
字典键值对获取方法
python字典中还提供了关于键,值和字典的获取方法
keys -> 获取字典中的所有keyvalues -> 获取字典中的所有valueitems -> 获取字典中的所有键值对使用方法具体来看看代码案例吧!
a = { 'id': 1, 'name': 'zhangsan', 'score': 90}print(a.keys())print(a.values())print(a.items())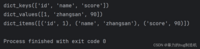
在dict_items中,首先是一个列表一样的结构,里面每个元素又是一个元组,元组里包含了键和值
在之前的学习中,我们学到过列表式返回本质上返回的是元组,所以我们其实可以这样玩
a = { 'id': 1, 'name': 'zhangsan', 'score': 90}for key, value in a.items(): print(key, value)合法的key类型
在python中专门提供了一个hash(哈希)函数
使用hash函数能够计算出一个变量的哈希值
print(hash(0))print(hash(3.14))print(hash('hello'))print(hash(True))print(hash((1, 2, 3)))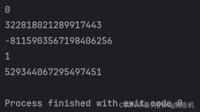
当然也存在类型不能计算hash(哈希)值,如:列表(list),和字典(dict)
所以能否做字典key值类型的标准就随之而出了,就是看此类型能否哈希,如果不可哈希,则不可以做字典的key
不可变的对象,一般可哈希
可变的对象,一般就是不可哈希的
类型小结
字典,列表,元组都是python中非常常用的内置类型
相比于int,str,float……
它们内部都可以再包含其他元素~
故也被称为 容器 / 集合类
python的文件操作
像图片(.jpg),电影(mp4),歌曲(mp3),文本(.txt),表格(.xlsx)之类的文件都是保存在硬盘上的。在程序运行过程中,变量之类的数据都存储在内存中。
内存和硬盘的区别:
内存空间小,硬盘空间大内存访问慢,硬盘访问更慢内存成本高,硬盘成本较低内存数据易失,硬盘的数据可以持久化存储(硬盘上存储的数据是以文件的形式来组织的)像此电脑的C盘,D盘都是硬盘上的内容
文件夹(目录)也是一种特殊的文件
而今天的文件操作,主要是针对文本文件的写和读
文件路径
此处把一层一层目录构成的字符串称为文件路径,下面这是一个绝对路径
eg. D:/code/first_python
知道路径就可以知道文件在硬盘上的详细位置,文件路径也可以视为是文件在硬盘上的身份标识
目录之间用\来分割(只有Windows这样支持),使用/也可以(所以系统都支持)
代码中表示文件路径,用/更多一些,毕竟\是在字符串里有特定含义的转义字符
文件操作
文件操作包括打开文件,读文件,写文件和关闭文件四个操作
打开文件
使用open打开一个文件
f = open('hello.txt', 'r')print(f)print(type(f))open第一个参数是文件路径(代码案例中展示的是相对路径,关于绝对路径和相对路径,大家可以参考一下别的博客对这方面内容的讲解),第二个参数是文件打开的方式,决定以何种方式操作文件),r是只读
r(read):按照只读的方式打开文件w(write):按照写的方式打开a(append):也是按照写的方式打开其实关于文件打开方式还有很多,如果想了解更多可以去看看python的官方文档,目前我们知道这三种就足够了
f 在此处的意思是一个文件对象
print(f)是打印文件对象信息
如果打开(以只读的方式)的文件不存在,打开文件时会抛异常
open的返回值是一个文件对象~
文件的内容,是在硬盘上的,此处的文件对象,则是内存上的一个变量~后续读写文件的操作,都是拿着这个文件对象来进行操作的(像一个“遥控器”)
在计算机领域中这种“遥控器”被称为“句柄”(handler)

你可能看不太懂这打印的是什么,不过不要紧,目前你只需要知道第一个是关于文件的信息,另一个是文件对象类型就行
关闭文件
使用f.close()关闭文件
f = open('hello.txt', 'r')f.close()文件在打开,使用完之后,就一定要关闭
打开文件其实是在申请一定的系统资源~这种资源是有限的
不再使用时,资源就应该及时释放(防止文件资源泄露)
关于打开文件个数的上限,大概几千个吧
flist = []count = 0while True: f = open('hello.txt', 'r') flist.append(f) count += 1 print(f'打开文件个数:{count}')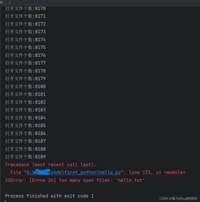
每个程序在启动时,都会默认打开三个文件:
标准输入~键盘标准输出~显示器标准错误~显示器在8189加上这打开的三个文件后,变成了8192,有没有发现,是2的13次方,计算机有很多数字都是2的次方数,例如2的10次方,1024,就是程序员的幸运数字。
在python中,有一个重要的机制->垃圾回收机制(GC),会自动关闭和释放不使用的变量,但是这个机制有时间周期,所以文件不用了一定记得要手动释放掉哦!!!
写文件
使用write来实现写文件操作
f = open('hello.txt', 'w')f.write('hello')f.close()
写文件时,注意用w的方式打开,如用r方式,则会抛异常
写方式,如是w,写方式打开,会将文件原有内容清空,写新内容;如用a,追加方式打开,则在原文件基础上将文件内容追加在后面
如果已经关闭文件,强行去写会抛异常
读文件
1.使用read读取文件内容,()内指定读几个字符
f = open('hello.txt', 'r')# read方法括号中指定指定读几个字符result = f.read(2)print(result)f.close()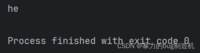
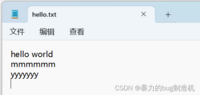
如果读的是中文有可能会报错,原因可能是汉字编码方式不同,目前汉字主流版本GBK,UTF8
所以实际开发时要保证文件内容的编码方式和代码中操作文件的编码方式匹配!!
下面来确认文件汉字编码是否匹配
f = open('hello.txt', 'r')print(f)f.close()
观察一下它打印的信息,可以得知此处编码(encoding)方式为'cp936'
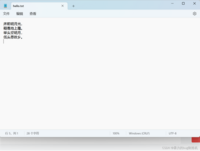
看右下角,可以得知文本文件中的编码方式为'UTF-8'
现在有两种方案:
我们可以选择改文本文件编码
还可以改代码读的方式
这里我们选择第二种方式,我们只需要给open函数多传一个参数就可以做到了
f = open('hello.txt', 'r', encoding='utf8')result = f.read(3)print(result)f.close()现在就可以成功读取用utf8方式编码的文本文件了
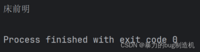
2.更常见的,是按行读取
直接for循环
f = open('hello.txt', 'r', encoding='utf8')for line in f: print(f'line = {line}')f.close()这里的f应该也是个可迭代类型
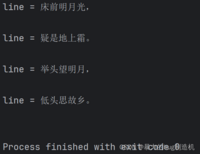
这首诗就被很好的打印出来了,但是你可能会注意到多打了一个空行,是因为文件中的\n被读取,这时给print多设置个参数,修改print的自动添加换行的行为
f = open('hello.txt', 'r', encoding='utf8')for line in f: print(f'line = {line}', end='')f.close()print的第二个参数表示每次打印后在末尾加什么,默认为'\n'
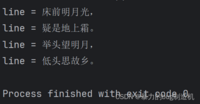
3.使用readlines方法直接把整个文件全都读出来,按照行组织到一个列表里
f = open('hello.txt', 'r', encoding='utf8')lines = f.readlines()print(lines)f.close()
方法3比方法2一次一次读的效率更高,但是需要考虑下文本文件内容是否会过大
上下文件管理器
使用上下文件管理器,防止忘记close
def fun(): with open('hello.txt', 'r', encoding='utf8') as f: # 代码。。。 pass 这里with的语句就是上下文件管理器,使f处于始终被监控的状态当中,一旦出了with的代码块,自动会将'hello.txt'文件关闭,就不用担心忘记关闭浪费资源的问题了。
结语
到了这里,关于python基础语法速成的内容就先告一段落了。记录一下,学到这个程度是我假期7天在学习C++的同时速通出来的,而本篇和上篇博客是我除夕夜和除夕夜前一天肝掉的,有很多人想了解python这方面的内容,我就连夜赶出来力。现在是2024年的凌晨1点,祝大家新年快乐,如果想了解更多有意思的内容,记得给我点点关注啊---比心♥
最后的最后,博主写博客有点急,如果有错别字,或者表达讲解有误欢迎在评论区里指出,谢谢大家的支持!!!