检索增强生成(Retrieval-augmented generation,RAG)代表了生成式人工智能领域的重大进展,将高效的数据检索与大型语言模型的强大功能相结合。
在其核心,RAG通过利用矢量搜索来挖掘相关且已存在的数据,将这些检索到的信息与用户的查询相结合,然后通过诸如ChatGPT之类的大型语言模型进行处理。
这种RAG方法确保生成的响应不仅精确而且反映了当前信息,大大减少了输出中的不准确性或“幻觉”。
然而,随着AI应用领域的不断扩展,对RAG的需求变得更加复杂和多样化。基本的RAG框架虽然强大,但可能不再足以满足不同行业和不断发展的用例的微妙需求。这就是先进的RAG技术发挥作用的地方。这些增强的方法专为应对特定挑战而设计,提供更精准、适应性和高效的信息处理。
文章目录
通俗易懂讲解大模型系列技术交流&资料理解RAG技术基本 RAG 的本质技术1:自查询检索技术2:高级RAG中的父子关系(自动合并)技术3:交互式RAG — 问答技术四:高级RAG中的上下文压缩 总结
通俗易懂讲解大模型系列
做大模型也有1年多了,聊聊这段时间的感悟!
用通俗易懂的方式讲解:大模型算法工程师最全面试题汇总
用通俗易懂的方式讲解:我的大模型岗位面试总结:共24家,9个offer
用通俗易懂的方式讲解:大模型 RAG 在 LangChain 中的应用实战
用通俗易懂的方式讲解:一文讲清大模型 RAG 技术全流程
用通俗易懂的方式讲解:如何提升大模型 Agent 的能力?
用通俗易懂的方式讲解:ChatGPT 开放的多模态的DALL-E 3功能,好玩到停不下来!
用通俗易懂的方式讲解:基于扩散模型(Diffusion),文生图 AnyText 的效果太棒了
用通俗易懂的方式讲解:在 CPU 服务器上部署 ChatGLM3-6B 模型
用通俗易懂的方式讲解:使用 LangChain 和大模型生成海报文案
用通俗易懂的方式讲解:ChatGLM3-6B 部署指南
用通俗易懂的方式讲解:使用 LangChain 封装自定义的 LLM,太棒了
用通俗易懂的方式讲解:基于 Langchain 和 ChatChat 部署本地知识库问答系统
用通俗易懂的方式讲解:在 Ubuntu 22 上安装 CUDA、Nvidia 显卡驱动、PyTorch等大模型基础环境
用通俗易懂的方式讲解:Llama2 部署讲解及试用方式
用通俗易懂的方式讲解:基于 LangChain 和 ChatGLM2 打造自有知识库问答系统
用通俗易懂的方式讲解:一份保姆级的 Stable Diffusion 部署教程,开启你的炼丹之路
用通俗易懂的方式讲解:对 embedding 模型进行微调,我的大模型召回效果提升了太多了
用通俗易懂的方式讲解:LlamaIndex 官方发布高清大图,纵览高级 RAG技术
用通俗易懂的方式讲解:使用 LlamaIndex 和 Eleasticsearch 进行大模型 RAG 检索增强生成
用通俗易懂的方式讲解:基于 Langchain 框架,利用 MongoDB 矢量搜索实现大模型 RAG 高级检索方法
用通俗易懂的方式讲解:使用Llama-2、PgVector和LlamaIndex,构建大模型 RAG 全流程
技术交流&资料
技术要学会分享、交流,不建议闭门造车。一个人可以走的很快、一堆人可以走的更远。
成立了大模型技术交流群,本文完整代码、相关资料、技术交流&答疑,均可加我们的交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、微信搜索公众号:机器学习社区,后台回复:加群
方式②、添加微信号:mlc2060,备注:来自CSDN + 技术交流
理解RAG技术
基本 RAG 的本质
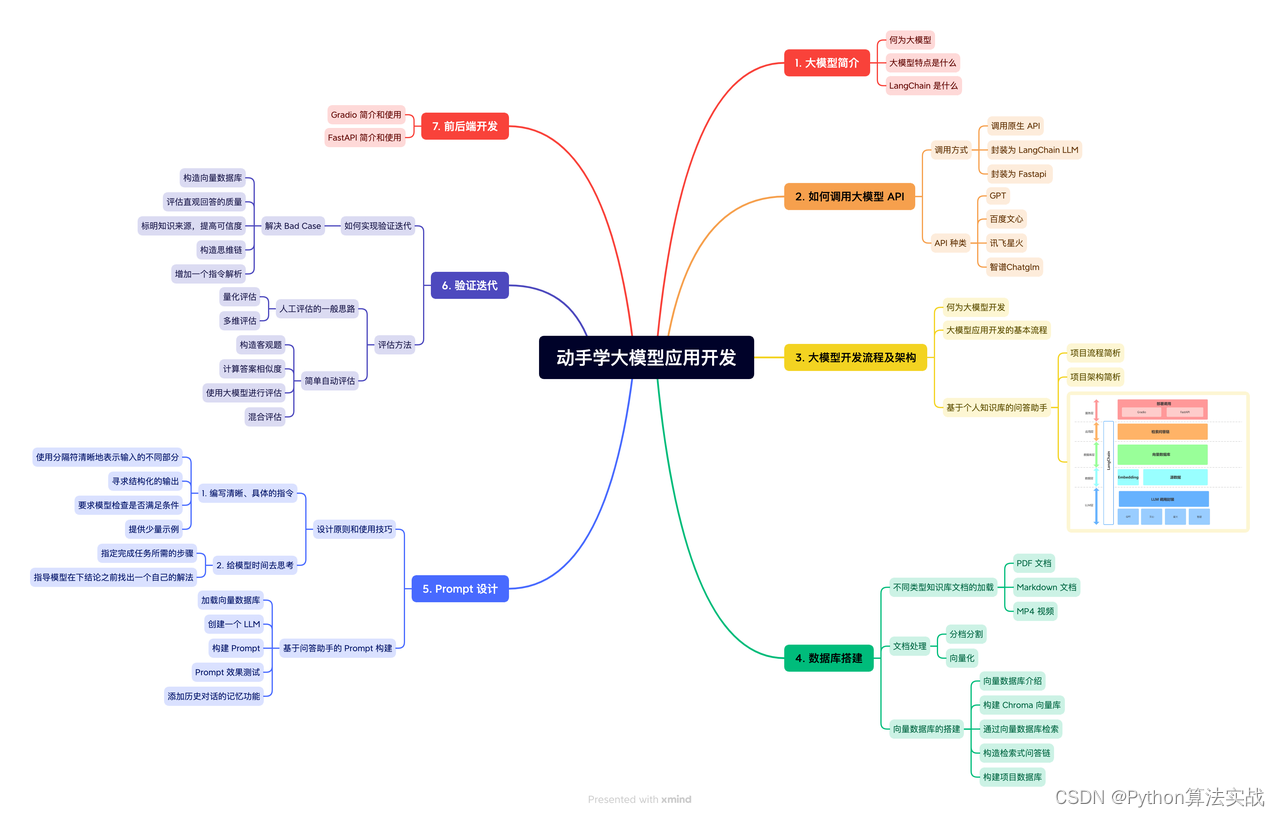
检索增强生成(RAG)将数据管理与智能查询相结合,以提高AI响应的准确性。
数据准备:用户上传数据,然后对其进行“分块”并存储带嵌入的数据,为检索奠定基础。
检索:一旦提出问题,系统利用矢量搜索技术浏览存储的数据,准确定位相关信息。
LLM查询:然后,使用检索到的信息为语言模型(LLM)提供上下文,LLM通过将上下文与问题融合来准备最终提示。结果是基于提供的丰富上下文化数据生成的答案,展示了RAG在产生可靠、知情响应方面的能力。
这一过程在这个图表中得到了概括,强调了RAG对可靠数据处理和具有上下文意识的答案生成的重视,这对于先进的AI应用至关重要。
随着人工智能技术的进步,RAG的能力也得到了提升。先进的RAG技术已经出现,推动着这些模型能够实现的边界。这些进展不仅仅是关于更好的检索或更流畅的生成。它们涵盖了一系列改进,包括对上下文的更深入理解、对微妙查询的更复杂处理,以及能够无缝集成多样化数据源的能力。
技术1:自查询检索
自查询检索是人工智能驱动的数据库系统中的尖端技术,通过自然语言理解增强数据查询。例如,在您有一个产品目录数据集的情况下,您希望搜索“一条黑色皮制迷你裙价格低于20美元”。您不仅希望对产品描述进行语义搜索,还可以利用对产品的子类别和价格的筛选器。


通过从自然语言构建结构化查询,自查询检索确保在数据获取方面既高效又精确,因为它可以同时考虑语义元素和元数据。
import openaiimport pymongofrom bson.json_util import dumps# OpenAI API key setupopenai.api_key = 'your-api-key'# Connect to MongoDBclient = pymongo.MongoClient('mongodb://localhost:27017/')db = client['your_database']collection = db['your_collection']# Function to use GPT-3.5 for interpreting natural language query and outputting a structured querydef interpret_query_with_gpt(query): response = openai.Completion.create( model="gpt-3.5-turbo", prompt=f"Translate the following natural language query into a MongoDB vector search query:\n\n'{query}'", max_tokens=300 ) return response.choices[0].message.content# Function to execute MongoDB vector search querydef execute_query(query): structured_query = eval(query) # Caution: Use eval carefully results = collection.aggregate([structured_query]) return dumps(list(results), indent=4)# Example usagenatural_language_query = "Find documents related to AI advancements"structured_query = interpret_query_with_gpt(natural_language_query)results = execute_query(structured_query)print(results)技术2:高级RAG中的父子关系(自动合并)
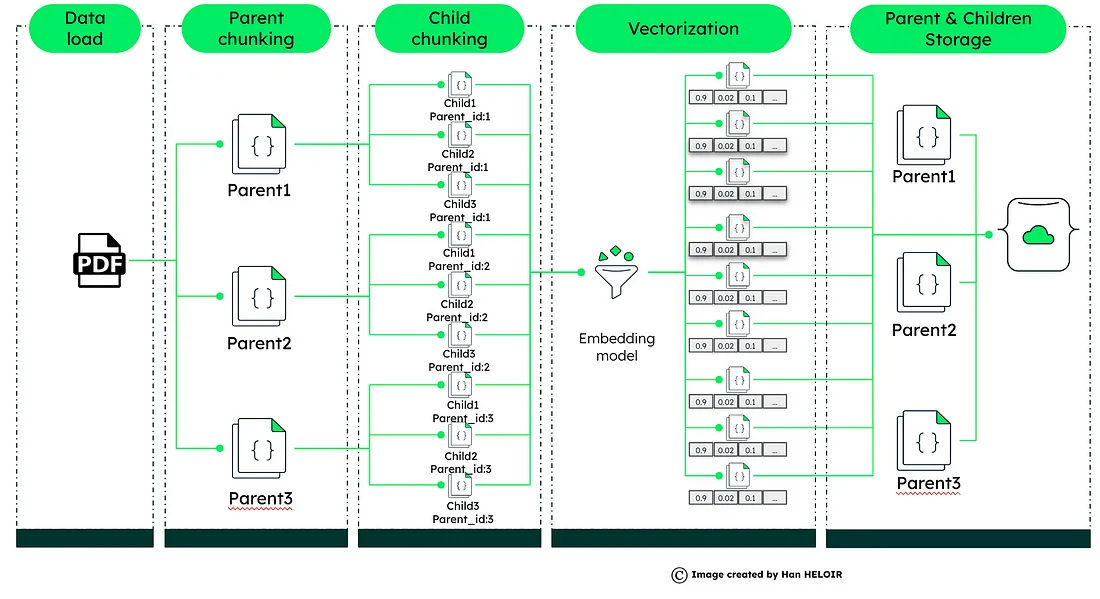
在高级RAG系统中,父子关系的概念将数据检索提升到一个新的水平。这种方法涉及将大型文档分割成较小、可管理的部分 —— 父文档和它们各自的子文档。
父子文档动态:将大型文档分解为父文档和它们各自的子文档。父文档提供更广泛的背景,而子文档提供具体的细节。精度的矢量化:对每个子文档进行矢量化,创建一个独特的数字化配置文件,有助于精确的数据检索。查询处理和上下文响应:当收到查询时,它与这些矢量化的子文档进行匹配。系统不仅检索最相关的子文档,还引入父文档以获取额外的上下文。这种方法确保响应不仅精确而且富有上下文信息。增强的LLM集成:然后将来自子文档和父文档的详细信息输入到大型语言模型(LLM)中,如ChatGPT,以生成既准确又具有上下文意识的响应。在MongoDB中的实施:利用MongoDB的矢量搜索,这种技术为浏览大型数据集提供了一种精细的方法,确保快速和具有上下文丰富的响应。该技术通过提供一种更细致和具有上下文丰富的数据检索方法,解决了基本RAG的局限性,对于理解更广泛背景至关重要的复杂查询至关重要。
from langchain.document_loaders import PyPDFLoaderfrom langchain.text_splitter import RecursiveCharacterTextSplitter# Initialize the text splitters for parent and child documentsparent_splitter = RecursiveCharacterTextSplitter(chunk_size=2000)child_splitter = RecursiveCharacterTextSplitter(chunk_size=200)# Function to process PDF document and split it into chunksdef process_pdf(file): loader = PyPDFLoader(file.name) docs = loader.load() parent_docs = parent_splitter.split_documents(docs) # Process parent documents for parent_doc in parent_docs: parent_doc_content = parent_doc.page_content.replace('\n', ' ') parent_id = collection.insert_one({ 'document_type': 'parent', 'content': parent_doc_content }).inserted_id # Process child documents child_docs = child_splitter.split_documents([parent_doc]) for child_doc in child_docs: child_doc_content = child_doc.page_content.replace('\n', ' ') child_embedding = embeddings.embed_documents([child_doc_content])[0] collection.insert_one({ 'document_type': 'child', 'content': child_doc_content, 'embedding': child_embedding, 'parent_ref': parent_id }) return "PDF processing complete"# Function to embed a query and perform a vector searchdef query_and_display(query): query_embedding = embeddings.embed_documents([query])[0] # Retrieve relevant child documents based on query child_docs = collection.aggregate([{ "$vectorSearch": { "index": "vector_index", "path": "embedding", "queryVector": query_embedding, "numCandidates": 10 } }]) # Fetch corresponding parent documents for additional context parent_docs = [collection.find_one({"_id": doc['parent_ref']}) for doc in child_docs] return parent_docs, child_docsfrom langchain.llms import OpenAI# Initialize the OpenAI clientopenai_client = OpenAI(api_key=OPENAI_API_KEY)# Function to generate a response from the LLMdef generate_response(query, parent_docs, child_docs): response_content = " ".join([doc['content'] for doc in parent_docs if doc]) chat_completion = openai_client.chat.completions.create( messages=[{"role": "user", "content": query}], model="gpt-3.5-turbo" ) return chat_completion.choices[0].message.content详情可以看之前文章[3]:基于 Langchain 框架,利用 MongoDB 矢量搜索实现大模型 RAG 高级检索方法
技术3:交互式RAG — 问答
交互式RAG代表了AI驱动的搜索能力的前沿。该技术通过允许用户实时主动影响检索过程,增强了传统RAG,使信息发现更加个性化和精确。
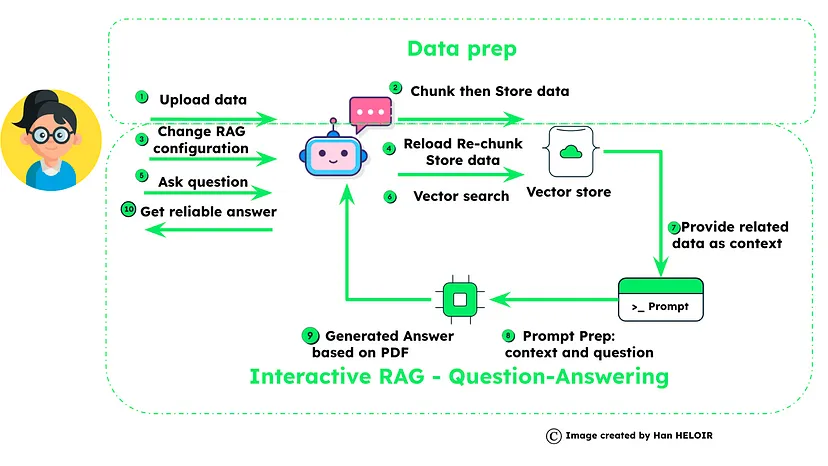
这第三种技术展示了先进的RAG方法对未来AI应用的重要性,为信息检索和处理提供了一种动态、自适应和用户中心的方法[1]。
技术四:高级RAG中的上下文压缩
上下文压缩解决了从充满无关文本的文档中检索相关信息的挑战。它通过根据查询上下文压缩文档来适应查询的不可预测性,确保只有与用户请求最相关的信息通过语言模型,从而提高响应质量并降低成本。
上下文压缩机制:该方法通过根据查询的上下文压缩检索到的文档,从而优化检索过程,这意味着它只返回与用户请求最相关的信息。
高效数据处理:通过上下文压缩文档,系统减轻了语言模型的负担,从而实现更快速和更具成本效益的操作。
使用文档压缩器进行实现:使用基本检索器和文档压缩器,如Longchain的LLMChainExtractor,系统通过初始文档进行过滤,根据其与查询的相关性缩短内容或完全省略文档。
增强的查询相关性:其结果是一组压缩的文档,其中包含高度相关的信息,语言模型可以使用这些信息生成精确的答案,而无需筛选杂散的内容。
这种方法在Brian Leonard的工作中得到了展示,展示了Langchain python代码在创建高效和专注的AI检索系统方面的实用性[2]。
总结
在总结中,我们探讨了先进RAG方法的领域,探索了它们在人工智能革命中的关键作用。自我查询检索、父子关系、交互RAG和上下文压缩等技术向我们展示了当我们将人类般的理解力与机器精度融合时可能产生的奇迹。在人工智能思想领袖的指导和他们开创的实际应用的启发下,我们站在一个未来的风口上,在那里人工智能不仅仅是回答我们的问题,而是理解它们,包括上下文等。这就是未来先进RAG引导我们迈向更直观、响应更灵活和准确的人工智能的未来。
参考链接
[1]https://www.mongodb.com/developer/products/atlas/interactive-rag-mongodb-atlas-function-calling-api/
[2]https://www.mongodb.com/developer/languages/python/semantic-search-made-easy-langchain-mongodb/
[3]https://ai.gopubby.com/byebye-basic-rag-embracing-advanced-retrieval-with-mongodb-vector-search-47b550be2c59