
?日报&周刊合集 | ?生产力工具与行业应用大全 | ? 点赞关注评论拜托啦!

? Runway AIFF 2024 | 第二届AI电影节,作品提交进入50天倒计时

https://aiff.runwayml.com
补充一份背景:AIFF 全程是 AI Film Festival (AI电影节),由 Runway 举办,旨在庆祝艺术家们拥抱新兴AI科技并用于电影制作;AIFF 2023是第一届,今年的 AIFF 2024 将这项「科技+电影」的盛会带入第二届~
当最先进的AI技术被用于影视制作,会有怎样炫酷的呈现呢?!AIFF 2024 可能会给到你一些答案!? 截图展示了本次赛程时间分布,2月底截至提交后,评委团进入评选环节,最终获奖团队将共享超过 60,000 美元的总奖金池。感兴趣的话点击链接可以查看全部信息~
官方给出的提交标准非常简明,满足以下三条即可:
1) 时长1-10分钟
2) 在创作过程中包含AI驱动的工具,这包括但不限于生成式AI
3) 使用 Runway 链接提交
https://aiff.runwayml.com/2023
官方页面还可以看到 ? 上一届获奖作品、制作人及其所获奖项名称,还有对应奖项的获奖金额等信息。点击左侧按钮,还可以播放这些视频。
? 第14届北京国际电影节 | AIGC电影短片单元,启动全球征片

第十四届「北京国际电影节」率先开启AIGC短片展映及评选,探索人工智能如何挑战和重塑传统的电影叙事。
主办方不仅提供专业的AI技术支持和创作指导,还给获奖作品提供电影节的展映机会,创作者也可以与全球著名导演、制片人及行业专家进行交流。
征集时间
2024年1月15日 至 2024年3月31日征集要求
短片时长:1 - 10分钟
技术要求:短片创作中,在叙事手法、影像美学、视觉特效、声音创作等等方面巧妙融合人工智能技术,并在提交作品时进行简短的书面描述
主题自由:鼓励自由探索科技与艺术的交汇,创作具有深度和意义的作品
参与资格:鼓励具有创新思维和实验精神的全球青年影人:学生、独立电影人、AI技术爱好者等 ⋙ 了解更多
? 中国美术学院 X 腾讯互娱 | 「时空博物馆」AIGC 数字艺术创作大赛,全球作品征集

http://museum.caacosmos.com/
「时空博物馆」是由中国美术学院和腾讯互娱主办、多家博物馆联合主办、众多权威机构承办的一项活动,目的是与广大在校学生、艺术家与设计师们共同搭建一座数字艺术的博物馆,带领着人类文明的魅力一起穿越时空。
参赛作品需要是基于 AIGC 生成的动态影像、图像、音乐、文本等,进入主赛道、历史印记、传世匠心、书画韵味、传说之下、合作赛道等参与评审。主办方为优秀作品提供了丰厚的奖金。
征集时间
2023年12月10日 至 2024年1月25日作品提交要求
视频要求:时长不超过3分钟,格式为 MP4,画面比例自定,文件大小不超过100mb,可配字幕,但不得以任何形式出现个人信息
图片要求:10张以内,JPG格式,画面比例自定,解析度300ppi,RGB色彩模式,单张图片大小不超过 10MB ⋙ 了解更多

? 六类提示工程最佳实践,有效提高大语言模型的输出质量

https://mphr.notion.site/Prompt-Engineering-Best-Practices-0839585d4bce4c6abb0b551b2107a92a
补充一份背景:提示词 (Prompt) 是指与大语言模型交互时,用来指导模型产生特定输出的简短描述或指令;
提示工程 (Prompt Engineering) 是一种利用提示词来优化大语言模型输出的技术,提示工程师们通过精心设计和优化提示词,从而达到期望的输出效果
这是一篇提示工程 (Prompt Engineering) 的实践经验总结文章。作者可是把干货都掏出来了呀,还给了不少例子!原文篇幅不长但知识点慢慢,果断加入收藏清单呀!
清晰且具体的指令 (Clear and Specific Instructions)提供详细背景:为问题提供详细的上下文,减少歧义,从而降低无关或错误输出的可能性
使用分隔符:通过使用如章节标题、三重引号、三重反引号、三重破折号、尖括号等分隔符来清晰地指示输入的不同部分
指定输出格式或长度:例如,让模型扮演特定角色,或指定输出的长度
给模型思考的时间 (Give the Model Time to Think) 链式推理:通过要求模型逐步思考,可以减少推理错误 (例如可以添加「Think step by step」的提示) 多次提示模型 (Prompt Multiple Times) 调整参数:通过改变温度 (Temperature) 、示例数量 (Shots) 和提示的直接性 (Prompt) 来生成多个响应,并确定最佳答案 引导模型 (Guide the Model)处理长文档:如果文档过长,引导模型逐步处理并递归构建完整摘要
自我纠正:如果模型开始时回答错误,引导模型自我纠正 (例如通过提问「Are you sure about your answer?」)
避免引导性问题:确保问题开放性,不要引导模型给出特定答案
分解任务或提示 (Break Down the Task or Prompt)将复杂任务分解为简单任务:通过分解任务,语言模型可以一次专注于一个方面,减少复杂任务中常发生的误差,还可以解决成本
例如,如果用户需要巴黎旅行的建议,可以将任务分解为单独的意图 (如打包建议、餐饮推荐和公共交通指导),然后 LLM 可以针对每个意图分别提供定制的建议
使用外部工具 (Use External Tools)可以借助外部工具,将 LLM 的自然语言处理能力与外部工具的专业功能结合起来,从而提高整体的工作效率和准确性
Calculator (计算器) :LLM 在数学计算方面可能不够精确,使用计算器可以显著提高模型在数学问题上的表现
RAG (信息检索) : 通过连接LLM到一个智能的信息检索系统,可以更有效地检索信息
Code Execution (代码执行) :使用代码执行功能或调用外部 API,来执行和测试由 LLM 创建的代码
External Functions (外部函数) :为 LLM 定义外部函数,如send_email()、get_current_weather()或get_customers(),这些函数可以在用户的端执行,并将结果返回给模型

? 万字长文!手把手教你构建**基于RAG的LLM应用,并部署到生产环境
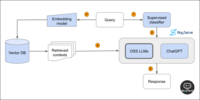
https://github.com/ray-project/llm-applications
https://www.anyscale.com/blog/a-comprehensive-guide-for-building-rag-based-llm-applications-part-1
这是一份超级详细的开发指南,一步一步地介绍如何基于RAG (检索增强生成)构建 LLM 应用并将其部署到生产环境中。
文章不仅有大量的结构示意图,还附上了实践代码,并且强调了开发过程中可能遇到的挑战以及解决方式,包括如何通过增加上下文来提高答案质量、如何通过调整块大小/使用不同的嵌入模型来优化性能、如何通过持续迭代和数据飞轮来改进应用程序等。宝藏好文!收藏 +1
文章要点简述
? 开发:一个从头开始的基于检索增强生成 (RAG) 的 LLM 应用程序
? 扩展:主要工作负载 (加载、分块、嵌入、索引、服务等) 到具有不同计算资源的多个工作者
✅ 评估:应用程序的不同配置,以优化每个组件 (例如 retrieval_score) 和整体性能 (quality_score)
? 实施:在开源与闭源LLM之间的混合代理路由方法,创建性能最佳且成本效益最高的应用程序
? 服务:以高度可扩展和可用的方式提供应用程序
? 学习:如何通过微调、提示工程、词汇搜索、重新排名、数据飞轮等方法影响应用程序的性能
RAG 应用开发的全流程概述
概述 (Overview)
介绍了RAG应用程序的开发,旨在通过结合外部数据源来扩展 LLM 的能力,特别是针对 Ray 框架的文档向量数据库创建 (Vector DB creation)
加载数据:使用 wget 命令从 Ray 文档网站下载 HTML 文件到本地目录
分节:开发函数提取 HTML 页面中的各个部分,并将其保存为字典列表,映射文本到特定 URL 和部分锚点 ID
分块数据:将每个部分的文本分割成较小的块,以减少噪声并提高检索效率
嵌入数据:使用预训练模型 (如OpenAIEmbeddings) 将数据块嵌入到向量空间中,以便快速检索
索引数据:将嵌入的数据块存储在 Postgres 数据库中,使用 pgvector 进行高效检索
查询检索 (Query Retrieval)
使用嵌入模型对查询进行嵌入,然后从数据库中检索最相关的数据块响应生成 (Response Generation)
代理:结合上下文检索和LLM生成响应,创建了一个方便的查询代理评估 (Evaluation)
评估器:定义一个评估器来评分和评估响应质量,使用GPT-4作为评估器
冷启动:在没有准备好的问题和答案数据集的情况下,使用LLM生成问题
LLM实验 (LLM Experiments)
工具:定义了一些实用函数来帮助实验流程,包括生成响应和评估响应
上下文:测试额外上下文对答案质量的影响
分块大小:探索不同分块大小对检索和质量的影响
分块数量:测试使用不同数量的分块对性能的影响
嵌入模型:比较不同嵌入模型的性能
开源与闭源LLM:评估开源和闭源 LLM 的性能
MoEs无上下文:测试没有上下文的 MoEs 性能
微调 (Fine-tuning)
合成数据集:创建一个用于微调嵌入模型的合成数据集,通过生成问题和答案
训练数据:将数据集分为训练和验证集
验证:使用信息检索评估器进行验证
嵌入模型:初始化嵌入模型进行微调,包括全参数和仅嵌入层的微调
调整tokenizer:调整 tokenizer 以包含新词汇,能更好地表示数据
提示工程 (Prompt engineering)
探索了不同的提示工程方法,以提高LLM的性能词汇搜索 (Lexical search)
BM25:使用 BM25 算法进行词汇搜索,以补充基于嵌入的检索
语义:比较词汇搜索与基于嵌入的检索
词汇实验:将词汇搜索结果纳入检索工作流程,以提高检索的准确性
重新排名 (Reranking)
数据集:创建了一个数据集,用于训练一个模型来预测文档部分的相关性
预处理:对数据进行预处理,以改善其表示
训练:训练一个简单的逻辑回归模型进行重新排名
测试:评估重新排名模型的性能
重新排名实验:在检索后应用重新排名模型,以优化检索结果的顺序
成本分析 (Cost analysis)
分析了不同配置的成本效益,包括提示和采样定价,以及如何根据成本和性能进行权衡路由 (Routing)
描述了如何根据查询的复杂性或主题将查询路由到适当的 LLM,以实现性能和成本的最佳平衡服务 (Serving)
使用 Ray Serve 和 FastAPI 部署 RAG 应用程序,以实现可扩展和高效的服务数据飞轮 (Data flywheel)
描述了如何通过用户反馈和数据迭代来持续改进应用程序,包括自动重新索引和评估影响 (Impact)
讨论了 RAG 应用程序对产品和生产力的积极影响,以及如何作为基础代理支持其他 LLM 应用程序的开发了解更多 (Learn more)
使用 Ray 和 Anyscale 来扩展和生产化 LLM 应用程序的资源和联系方式,以及参与 Ray 和 Anyscale 社区的方式? 人类如何应对「AI+编程」的冲击:三类程序员策略各异

https://stackoverflow.blog/2023/12/11/three-types-of-ai-assisted-programmers
AI工具的代码能力在逐渐成熟,「AI+编程」成为越来越高频出现的话题。我们都要掌握编程技能么?使用AI工具编程可以一劳永逸么?程序员会因此全部失业么?
这篇文章把用户分为没有编程经验、新手程序员、资深程序员三类,分别讨论了AI工具对他们的帮助,以及可用场景和使用建议等,很中肯也很专业。看看你在哪一类呀~
没有编程经验
AI编程工具如 ChatGPT 能够快速生成代码片段,对于没有编程经验的人来说相当有吸引力,给人一种破解行业壁垒的感觉;但是这些AI工具生成的代码质量不一,虽然能够运行但可能不够可靠、可维护、安全或无bug
对于没有编程经验的人来说,AI工具可能不适合构建复杂的应用程序,但可以用于生成一次性的SQL查询、VBA宏等,或者帮助快速实现&验证一些想法
新手程序员
对新手程序员来说,AI工具可以减轻大量工作压力,但需要警惕的是过度依赖AI可能导致浅尝辄止并因此影响个人能力成长
更安全的做法是用它来学习和理解代码,例如生成代码示例或将生成内容与自己写的进行比较,而不是完全依赖它来生成代码
资深工程师
资深工程师可以使用AI工具提高开发速度,并将节省的时间用来提升代码质量和软件架构可持续性
AI生成的代码,需要资深工程师进行审查和重构,以确保质量合格;以及遇到不熟悉的编程语言或制作快速原型时,AI工具的提效作用将更加明显

? 头豹研究院 X 沙利文 | 2023中国大模型「行研」能力评测报告

ShowMeAI知识星球资源编码:R217
补充一份背景:行研,也就是行业研究,指的是通过分析特定行业的定义、竞争格局、市场规模等关键方面,产出深刻洞察和观点;弗若斯特沙利文 (Frost & Sullivan) 是一家权威调研机构
这份报告很有意思,是「行业研究」这个细分领域里的国产大模型能力评估。原报告对12个国产大模型进行了多维度的平度,并且给出了非常详细的评估标准、过程和结果。

? 这两张图是核心结论图,可以看出在「行业研究」场景下国产大模型能力排名,以及在报告撰写能力、行研基础能力、行业理解能力这三个细分方向上的评估结果。? 以下是更细致的报告页面,感兴趣可以下载报告原文。



? 多伦多大学2024冬季最新课程 | CSC2547: AI Alignment
https://alignment-w2024.notion.site/CSC2547-AI-Alignment-b44359978f3a4a8f95c90adb0a6e7d53
补充一份背景:AI Alignment (人工智能对齐) ,指的是人工智能系统的目标和行为与人类的价值观、意图和长远利益相一致
注意!课程时间安排、视频、资料、讲座、作业等等都还没有!因为是新课,还没公布这些信息~ 感兴趣可以关注下课程页面,跟着一起打卡学习啦~
随着人工智能技术的发展,尤其是通用人工智能 (AGI) 的出现,使得AI系统可能会在没有人类直接监督的情况下自主追求目标,甚至忽视人类的安全和福祉。所以 AI Alignment 的研究非常必要。
不过,AI Alignment 是一个新兴的研究领域,新的研究成果和理论不断涌现但都还没形成体系。所以,超级期待 Roger Grosse 教授这门课程,可以跟着课程进行系统学习啦!!
根据课程页面介绍,课程前半部分关注强大的AI系统的理性模型 (包括最优规划者和通用归纳),课程后半部分关注大语言模型的实践安全性和对齐技术 (包括从人类反馈中学习的强化学习、机制解释性、健壮无害性、可扩展的监督等)。
感谢贡献一手资讯、资料与使用体验的 ShowMeAI 社区同学们!

◉ 点击 ?日报&周刊合集,订阅话题 #ShowMeAI日报,一览AI领域发展前沿,抓住最新发展机会!
◉ 点击 ?生产力工具与行业应用大全,一起在信息浪潮里扑腾起来吧!