传奇开心果短博文系列
系列短博文目录Python文本和语音相互转换库技术点案例示例系列 短博文目录前言一、雏形示例代码二、扩展思路介绍三、数据准备示例代码四、特征提取示例代码五、声学模型训练示例代码六、语言模型训练示例代码七、解码示例代码八、评估和调优示例代码九、扩展功能示例代码十、深入研究Kaldi的相关文档、论文和示例,以了解更多细节和技术细节十一、与Kaldi的社区和其他用户进行交流和讨论,也可以获得更多的帮助和指导
系列短博文目录
Python文本和语音相互转换库技术点案例示例系列
短博文目录
前言


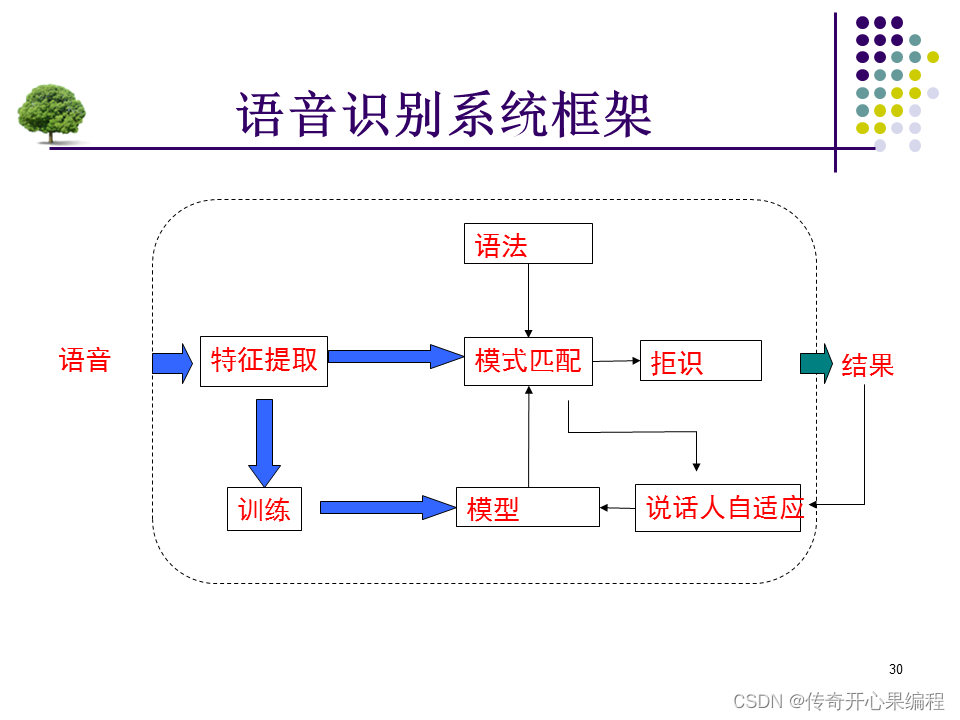
 Kaldi是一个开源的语音识别工具包,用于构建自定义的语音识别系统。它提供了一系列的工具和库,用于语音数据的前端处理、特征提取、声学模型训练和解码等任务。Kaldi的设计目标是提供高度可定制的语音识别框架,使用户能够根据自己的需求构建定制化的语音搜索引擎。
Kaldi是一个开源的语音识别工具包,用于构建自定义的语音识别系统。它提供了一系列的工具和库,用于语音数据的前端处理、特征提取、声学模型训练和解码等任务。Kaldi的设计目标是提供高度可定制的语音识别框架,使用户能够根据自己的需求构建定制化的语音搜索引擎。
Kaldi是一个功能强大的工具,适用于构建定制化的语音搜索引擎。通过使用Kaldi,您可以根据自己的需求和数据来定制和优化语音识别系统,以实现更准确和高效的语音搜索。
一、雏形示例代码
 定制语音搜索引擎涉及多个步骤和组件,这里给出一个简化的示例代码,展示了如何使用Kaldi构建自定义的语音搜索引擎:
定制语音搜索引擎涉及多个步骤和组件,这里给出一个简化的示例代码,展示了如何使用Kaldi构建自定义的语音搜索引擎:
# 假设您已经安装了Kaldi并设置了环境变量# 步骤1:数据准备# 创建数据目录和相应的文件mkdir data/traintouch data/train/wav.scptouch data/train/texttouch data/train/utt2spktouch data/train/spk2utt# 将音频文件和对应的文本信息添加到相应的文件中echo "audio1 /path/to/audio1.wav" >> data/train/wav.scpecho "audio2 /path/to/audio2.wav" >> data/train/wav.scpecho "audio1 transcriptions" >> data/train/textecho "audio2 transcriptions" >> data/train/textecho "audio1 speaker1" >> data/train/utt2spkecho "audio2 speaker2" >> data/train/utt2spkecho "speaker1 audio1" >> data/train/spk2uttecho "speaker2 audio2" >> data/train/spk2utt# 步骤2:特征提取# 使用Kaldi提供的特征提取工具,例如mfcc.shsteps/make_mfcc.sh --nj 1 data/train# 步骤3:语音模型训练# 使用Kaldi提供的训练脚本,例如train_tri2b.shsteps/train_tri2b.sh --nj 1 --cmd run.pl data/train# 步骤4:语言模型训练# 使用Kaldi提供的语言模型训练工具,例如ngram-countngram-count -order 3 -text data/train/text -lm data/train/lm.arpa# 步骤5:解码# 使用Kaldi提供的解码工具,例如decode.shsteps/decode.sh --nj 1 --cmd run.pl --acwt 0.1 exp/tri2b/graph data/train exp/tri2b/decode# 步骤6:评估和调优# 根据需要进行评估和调优,例如计算识别准确率等指标上述示例代码中,我们使用了一种更复杂的声学模型(tri2b)和语言模型(n-gram)。您可以根据需要选择不同的声学模型和语言模型,并相应地调整配置和参数。此外,您还可以使用更高级的技术,如深度神经网络(DNN)或循环神经网络(RNN),来改进语音识别性能。
请注意,这只是一个简化的示例,实际构建定制语音搜索引擎需要更多的配置和步骤。您可以参考Kaldi的官方文档和示例来了解更多细节和用法,并根据自己的需求进行相应的调整和扩展。
二、扩展思路介绍
 当您想要扩展和定制Kaldi语音搜索引擎时,以下是一些可能的思路和步骤:
当您想要扩展和定制Kaldi语音搜索引擎时,以下是一些可能的思路和步骤:
数据准备:根据您的应用场景和目标,收集和准备适合的训练数据。确保数据包含多样化的语音样本和对应的文本标注。
特征提取:Kaldi提供了多种特征提取工具,如MFCC、PLP、FBANK等。您可以根据需要选择适合的特征,并根据数据进行相应的配置和参数调整。
声学模型训练:Kaldi支持多种声学模型,如GMM-HMM、DNN、RNN等。您可以选择合适的声学模型,并使用训练脚本进行模型训练。根据需要,您可以尝试不同的模型结构、训练算法和超参数设置。
语言模型训练:语言模型对语音识别的准确性和流畅性有重要影响。您可以使用Kaldi提供的工具,如ngram-count或SRILM,根据训练数据训练语言模型。您可以尝试不同的n-gram大小、平滑算法和训练数据的预处理方法。
解码:使用训练好的声学模型和语言模型,对新的语音进行解码。Kaldi提供了解码工具,您可以使用相应的脚本进行解码,并获取识别结果。
评估和调优:对识别结果进行评估,计算准确率、召回率等指标。根据评估结果,您可以调整和优化声学模型、语言模型以及其他相关参数,以提高识别性能。
扩展功能:根据您的需求,您可以进一步扩展和定制语音搜索引擎的功能。例如,添加关键词检测、说话人识别、语音分割等功能。Kaldi提供了相应的工具和示例,您可以参考官方文档和社区资源来实现这些功能。
请注意,以上步骤和思路只是一个大致的指导,具体的扩展和定制取决于您的需求和应用场景。在实际操作中,您可能需要深入研究Kaldi的相关文档、论文和示例,以了解更多细节和技术细节。同时,与Kaldi的社区和其他用户进行交流和讨论,也可以获得更多的帮助和指导。
三、数据准备示例代码
 数据准备是构建定制语音搜索引擎的关键步骤之一。以下是一个简化的示例代码,展示了如何准备训练数据并生成相应的文件:
数据准备是构建定制语音搜索引擎的关键步骤之一。以下是一个简化的示例代码,展示了如何准备训练数据并生成相应的文件:
# 假设您已经收集了一些音频文件和对应的文本标注# 步骤1:创建数据目录和相应的文件mkdir data/traintouch data/train/wav.scptouch data/train/texttouch data/train/utt2spktouch data/train/spk2utt# 步骤2:将音频文件和对应的文本信息添加到相应的文件中# 假设您有两个音频文件audio1.wav和audio2.wav,对应的文本标注分别是"transcription1"和"transcription2"echo "audio1 /path/to/audio1.wav" >> data/train/wav.scpecho "audio2 /path/to/audio2.wav" >> data/train/wav.scpecho "audio1 transcription1" >> data/train/textecho "audio2 transcription2" >> data/train/text# 步骤3:生成utt2spk和spk2utt文件# 假设两个音频文件都属于同一个说话人,我们将它们都标记为"speaker1"echo "audio1 speaker1" >> data/train/utt2spkecho "audio2 speaker1" >> data/train/utt2spkecho "speaker1 audio1 audio2" >> data/train/spk2utt在上述示例中,我们创建了一个名为"data/train"的数据目录,并生成了四个文件:wav.scp、text、utt2spk和spk2utt。其中,wav.scp文件包含音频文件的路径信息,text文件包含音频文件的文本标注,utt2spk文件定义了音频文件和说话人的对应关系,spk2utt文件定义了说话人和音频文件的对应关系。
请注意,这只是一个简化的示例,实际的数据准备过程可能更加复杂,具体取决于您的数据集和需求。您可能需要进行数据清洗、标注处理、说话人划分等操作。此外,如果您的数据集很大,您可能需要将数据分成多个子集,并为每个子集创建相应的数据目录和文件。
根据您的应用场景和目标,确保您的训练数据包含多样化的语音样本和对应的文本标注是非常重要的。这样可以提高模型的泛化能力和识别准确性。
四、特征提取示例代码
 在Kaldi中进行特征提取可以使用特征提取工具和相应的配置文件。以下是一个示例代码,展示了如何使用Kaldi提取MFCC特征:
在Kaldi中进行特征提取可以使用特征提取工具和相应的配置文件。以下是一个示例代码,展示了如何使用Kaldi提取MFCC特征:
# 假设您已经准备好了数据目录和文件,如上一个示例中的"data/train"# 步骤1:创建特征目录和相应的文件mkdir data/train_mfcctouch data/train_mfcc/feats.scptouch data/train_mfcc/cmvn.scp# 步骤2:使用Kaldi的特征提取工具进行MFCC特征提取compute-mfcc-feats --config conf/mfcc.conf scp:data/train/wav.scp ark:- | \ apply-cmvn --norm-vars=true scp:data/train/cmvn.scp ark:- ark:- | \ add-deltas ark:- ark:- | \ copy-feats --compress=true ark:- ark,scp:data/train_mfcc/feats.ark,data/train_mfcc/feats.scp# 步骤3:计算特征的均值和方差并保存到cmvn.scp文件中compute-cmvn-stats --spk2utt=ark:data/train/spk2utt scp:data/train_mfcc/feats.scp ark,scp:data/train_mfcc/cmvn.ark,data/train_mfcc/cmvn.scp在上述示例中,我们首先创建了一个名为"data/train_mfcc"的特征目录,并生成了两个文件:feats.scp和cmvn.scp。feats.scp文件包含了MFCC特征的路径信息,cmvn.scp文件包含了特征的均值和方差信息。
接下来,我们使用Kaldi提供的特征提取工具进行MFCC特征提取。具体来说,我们使用compute-mfcc-feats命令计算MFCC特征,然后使用apply-cmvn命令进行归一化,再使用add-deltas命令添加差分特征。最后,我们使用copy-feats命令将特征保存到feats.scp文件中。
在步骤3中,我们使用compute-cmvn-stats命令计算特征的均值和方差,并将结果保存到cmvn.scp文件中。这些均值和方差信息将在训练和解码过程中用于特征归一化。
请注意,上述示例中的配置文件"conf/mfcc.conf"用于指定MFCC特征提取的参数,您可以根据需要进行相应的配置和参数调整。此外,您可能还需要根据实际情况调整特征提取的流程和参数,例如添加VAD(Voice Activity Detection)处理、调整特征维度等。
这只是一个示例,Kaldi提供了丰富的特征提取工具和配置选项,您可以根据自己的需求选择适合的特征,并根据数据进行相应的配置和参数调整。您可以参考Kaldi的官方文档和示例来了解更多关于特征提取的细节和用法。
五、声学模型训练示例代码

 在Kaldi中进行声学模型训练可以使用相应的训练脚本和配置文件。以下是一个示例代码,展示了如何使用Kaldi进行GMM-HMM声学模型训练:
在Kaldi中进行声学模型训练可以使用相应的训练脚本和配置文件。以下是一个示例代码,展示了如何使用Kaldi进行GMM-HMM声学模型训练:
# 假设您已经准备好了数据目录和特征文件,如上述示例中的"data/train_mfcc"# 步骤1:创建声学模型目录和相应的文件mkdir exp/tri1touch exp/tri1/treetouch exp/tri1/final.mdl# 步骤2:使用Kaldi的训练脚本进行GMM-HMM声学模型训练steps/train_mono.sh --boost-silence 1.25 --nj 4 data/train_mfcc data/lang exp/mono# 步骤3:对齐数据steps/align_si.sh --boost-silence 1.25 --nj 4 data/train_mfcc data/lang exp/mono exp/mono_ali# 步骤4:训练三角形式的声学模型steps/train_deltas.sh --boost-silence 1.25 --cmd run.pl 2000 10000 data/train_mfcc data/lang exp/mono_ali exp/tri1# 步骤5:编译解码图utils/mkgraph.sh data/lang_test exp/tri1 exp/tri1/graph# 步骤6:解码steps/decode.sh --nj 4 exp/tri1/graph data/test_mfcc exp/tri1/decode在上述示例中,我们首先创建了一个名为"exp/tri1"的声学模型目录,并生成了两个文件:tree和final.mdl。tree文件定义了声学模型的拓扑结构,final.mdl文件保存了训练得到的最终模型。
接下来,我们使用Kaldi提供的训练脚本进行声学模型训练。具体来说,我们使用train_mono.sh脚本进行单音素模型训练,然后使用align_si.sh脚本对数据进行对齐,最后使用train_deltas.sh脚本训练三角形式的声学模型。
在步骤5中,我们使用mkgraph.sh脚本编译解码图,该图将在解码过程中用于生成最终的识别结果。
在步骤6中,我们使用decode.sh脚本进行解码,将训练得到的声学模型应用于测试数据,并生成解码结果。
请注意,上述示例中的命令和参数仅供参考,您可能需要根据实际情况进行相应的调整和扩展。例如,您可以尝试不同的声学模型结构、训练算法和超参数设置,以获得更好的识别性能。此外,您还可以根据需要进行数据处理、特征选择、模型调优等操作。
这只是一个示例,Kaldi提供了丰富的训练脚本和工具,支持多种声学模型的训练。您可以参考Kaldi的官方文档和示例来了解更多关于声学模型训练的细节和用法。
六、语言模型训练示例代码

 在Kaldi中进行语言模型训练可以使用不同的工具和库,如ngram-count和SRILM。以下是一个示例代码,展示了如何使用SRILM进行语言模型训练:
在Kaldi中进行语言模型训练可以使用不同的工具和库,如ngram-count和SRILM。以下是一个示例代码,展示了如何使用SRILM进行语言模型训练:
# 假设您已经准备好了训练数据文件,如"data/train/text"# 步骤1:创建语言模型目录和相应的文件mkdir data/langtouch data/lang/words.txttouch data/lang/G.fst# 步骤2:使用Kaldi的脚本生成词汇表utils/prepare_lang.sh --position-dependent-phones false data/local/dict "<UNK>" data/local/lang data/lang# 步骤3:将训练数据转换为ARPA格式text2wfreq < data/train/text | wfreq2vocab -top 50000 > data/lang/vocab.txttext2idngram -vocab data/lang/vocab.txt -idngram data/lang/train.idngram < data/train/text# 步骤4:使用SRILM训练语言模型ngram-count -order 3 -text data/lang/train.idngram -lm data/lang/train.lm# 步骤5:将训练得到的语言模型转换为Kaldi的二进制格式arpa2fst --disambig-symbol=#0 --read-symbol-table=data/lang/words.txt data/lang/train.lm data/lang/G.fst在上述示例中,我们首先创建了一个名为"data/lang"的语言模型目录,并生成了两个文件:words.txt和G.fst。words.txt文件包含了词汇表信息,G.fst文件保存了训练得到的语言模型。
接下来,我们使用Kaldi提供的脚本生成词汇表。具体来说,我们使用prepare_lang.sh脚本根据字典文件和未知词标记""生成词汇表。
在步骤3中,我们将训练数据转换为ARPA格式,并使用ngram-count命令基于训练数据训练语言模型。在此示例中,我们将n-gram的大小设置为3,您可以根据需要进行相应的调整。
在步骤5中,我们使用arpa2fst命令将训练得到的语言模型转换为Kaldi的二进制格式,以便在识别过程中使用。
请注意,上述示例中的命令和参数仅供参考,您可能需要根据实际情况进行相应的调整和扩展。例如,您可以尝试不同的n-gram大小、平滑算法和训练数据的预处理方法,以获得更好的语言模型性能。
这只是一个示例,Kaldi提供了多种工具和脚本用于语言模型训练,您可以根据自己的需求选择适合的工具和方法。您可以参考Kaldi的官方文档和示例来了解更多关于语言模型训练的细节和用法。
七、解码示例代码
 在Kaldi中使用训练好的声学模型和语言模型进行解码可以使用相应的解码工具和脚本。以下是一个示例代码,展示了如何使用Kaldi进行解码:
在Kaldi中使用训练好的声学模型和语言模型进行解码可以使用相应的解码工具和脚本。以下是一个示例代码,展示了如何使用Kaldi进行解码:
# 假设您已经准备好了声学模型目录和语言模型目录,如"exp/tri1"和"data/lang"# 步骤1:准备解码数据mkdir data/test# 将待解码的语音数据放入"data/test"目录,并生成相应的特征文件,如"data/test/feats.scp"# 步骤2:使用Kaldi的脚本进行解码steps/decode.sh --nj 4 --cmd run.pl exp/tri1/graph data/test exp/tri1/decode# 步骤3:获取解码结果cat exp/tri1/decode/scoring/10.tra | utils/int2sym.pl -f 2- data/lang/words.txt > exp/tri1/decode/result.txt在上述示例中,我们首先创建了一个名为"data/test"的目录,并将待解码的语音数据放入该目录。然后,我们使用Kaldi提供的decode.sh脚本进行解码。具体来说,我们指定了解码所需的声学模型目录、语言模型目录和解码数据目录,并通过--nj参数指定了解码所使用的并行任务数。
在步骤3中,我们使用cat命令读取解码结果的整数标签文件"10.tra",并使用int2sym.pl脚本将整数标签转换为对应的词汇,生成最终的解码结果文件"result.txt"。
请注意,上述示例中的命令和参数仅供参考,您可能需要根据实际情况进行相应的调整和扩展。例如,您可以尝试不同的解码参数和配置,以获得更好的解码性能。此外,您还可以根据需要对解码结果进行后处理和评估。
这只是一个示例,Kaldi提供了多种解码工具和脚本,支持不同的解码算法和模型组合。您可以参考Kaldi的官方文档和示例来了解更多关于解码的细节和用法。
八、评估和调优示例代码

 在Kaldi中,您可以使用相应的工具和脚本对识别结果进行评估,并计算准确率、召回率等指标。以下是一个示例代码,展示了如何使用Kaldi进行识别结果评估:
在Kaldi中,您可以使用相应的工具和脚本对识别结果进行评估,并计算准确率、召回率等指标。以下是一个示例代码,展示了如何使用Kaldi进行识别结果评估:
# 假设您已经准备好了识别结果文件和相应的参考文本文件,如"exp/tri1/decode/result.txt"和"data/test/text"# 步骤1:使用Kaldi的脚本生成评估所需的文件cat data/test/text | awk '{print $1}' > data/test/utt.listutils/int2sym.pl -f 2- data/lang/words.txt < exp/tri1/decode/scoring/10.tra > exp/tri1/decode/scoring/decoded.txt# 步骤2:使用Kaldi的脚本进行评估compute-wer --text --mode=present ark:data/test/text ark:exp/tri1/decode/scoring/decoded.txt > exp/tri1/decode/scoring/wer.txt# 步骤3:查看评估结果cat exp/tri1/decode/scoring/wer.txt在上述示例中,我们首先使用awk命令从参考文本文件中提取出音频文件的ID,并将其保存到"utt.list"文件中。然后,我们使用int2sym.pl脚本将解码结果的整数标签转换为对应的词汇,并将其保存到"decoded.txt"文件中。
接下来,我们使用compute-wer命令计算识别结果的词错误率(Word Error Rate,WER)。通过指定--text参数,我们告诉Kaldi使用文本格式进行评估。评估结果会保存到"wer.txt"文件中。
最后,我们使用cat命令查看评估结果。
请注意,上述示例中的命令和参数仅供参考,您可能需要根据实际情况进行相应的调整和扩展。例如,您可以使用不同的评估指标和模式,或根据需要对评估结果进行进一步处理和分析。
通过评估结果,您可以了解识别性能的准确率、召回率等指标,并根据需要进行声学模型、语言模型和其他相关参数的调整和优化,以提高识别性能。
这只是一个示例,Kaldi提供了多种工具和脚本用于识别结果评估和调优。您可以参考Kaldi的官方文档和示例来了解更多关于评估和调优的细节和用法。
九、扩展功能示例代码

 当使用Kaldi构建语音搜索引擎时,您可以根据需求进一步扩展和定制其功能。以下是一些示例代码,展示了如何使用Kaldi实现一些扩展功能:
当使用Kaldi构建语音搜索引擎时,您可以根据需求进一步扩展和定制其功能。以下是一些示例代码,展示了如何使用Kaldi实现一些扩展功能:
# 假设您已经准备好了声学模型目录和关键词列表文件,如"exp/mono"和"data/keywords.txt"# 步骤1:准备关键词检测数据mkdir data/kws# 将待检测的语音数据放入"data/kws"目录,并生成相应的特征文件,如"data/kws/feats.scp"# 步骤2:使用Kaldi的脚本进行关键词检测steps/kws_search.sh --cmd run.pl data/keywords.txt data/kws exp/mono/decode_kws# 步骤3:获取关键词检测结果cat exp/mono/decode_kws/keywords.int | utils/int2sym.pl -f 2- data/keywords.txt > exp/mono/decode_kws/result.txt在上述示例中,我们首先创建了一个名为"data/kws"的目录,并将待检测的语音数据放入其中。然后,我们使用Kaldi提供的kws_search.sh脚本进行关键词检测。我们指定了关键词列表文件和声学模型目录,并通过--cmd参数指定了运行命令的配置。
在步骤3中,我们使用cat命令读取关键词检测结果的整数标签文件"keywords.int",并使用int2sym.pl脚本将整数标签转换为对应的关键词,生成最终的关键词检测结果文件"result.txt"。
Kaldi提供了一些说话人识别的工具和示例,您可以参考官方文档和社区资源来了解更多关于说话人识别的细节和用法。
语音分割(Speech Segmentation):Kaldi中的语音分割可以使用工具和脚本实现,例如LIUM SpkDiarization工具包。您可以参考官方文档和社区资源来了解如何使用Kaldi进行语音分割。
请注意,上述示例中的代码仅供参考,您可能需要根据实际情况进行相应的调整和扩展。Kaldi提供了丰富的工具、示例和文档,以支持各种语音处理任务的定制和扩展。建议您查阅Kaldi的官方文档、示例和社区资源,以获取更详细的指导和更多的示例代码。
十、深入研究Kaldi的相关文档、论文和示例,以了解更多细节和技术细节

 当深入研究Kaldi时,以下文档和示例代码资源,可帮助您了解更多细节和技术细节:
当深入研究Kaldi时,以下文档和示例代码资源,可帮助您了解更多细节和技术细节:
官方文档:Kaldi的官方文档是学习和了解Kaldi的重要资源。您可以访问Kaldi的官方网站(https://kaldi-asr.org)并浏览文档页面,其中包含了详细的说明、教程、工具和脚本的用法,以及各种任务的示例代码。
论文和出版物:Kaldi的发展和技术细节在多个论文和出版物中有所介绍。一些经典的论文包括:
“The Kaldi Speech Recognition Toolkit”(Daniel Povey等)“The Kaldi Speech Recognition Toolkit and the Open-Source Community”(Daniel Povey等)“Sequence-discriminative training of deep neural networks”(Geoffrey Hinton等)这些论文提供了关于Kaldi的详细描述、算法和方法的信息,对于深入研究Kaldi的内部工作原理和技术细节非常有帮助。
示例代码:Kaldi的源代码中包含了丰富的示例代码,涵盖了各种语音处理任务的实现。您可以浏览Kaldi源代码的"egs"目录,其中包含了多个示例项目,如"egs/wsj"、"egs/tedlium"等。这些示例项目包括了数据准备、特征提取、声学模型训练、解码和评估等步骤的示例代码,可以帮助您了解Kaldi的用法和工作流程。此外,Kaldi的社区资源也是学习和深入研究的宝贵资料。您可以参与Kaldi的邮件列表、论坛和GitHub存储库,与其他用户和开发者交流和分享经验。
需要注意的是,Kaldi是一个庞大而复杂的工具包,深入研究和理解它可能需要一定的时间和学习成本。建议您根据自己的需求和兴趣选择合适的资源和示例代码,并结合实际的实验和实践来加深对Kaldi的理解和应用。
十一、与Kaldi的社区和其他用户进行交流和讨论,也可以获得更多的帮助和指导

 与Kaldi的社区和其他用户进行交流和讨论是获取更多帮助和指导的好方法。以下是一些示例途径和平台,您可以在这些地方与Kaldi的社区和其他用户进行交流:
与Kaldi的社区和其他用户进行交流和讨论是获取更多帮助和指导的好方法。以下是一些示例途径和平台,您可以在这些地方与Kaldi的社区和其他用户进行交流:
Kaldi论坛:Kaldi论坛是一个在线社区,您可以在其中发布问题、参与讨论和与其他用户交流。您可以访问Kaldi论坛网站(https://groups.google.com/g/kaldi-help)并加入该论坛。在论坛上,您可以提出问题、回答其他人的问题、分享经验和资源,并与Kaldi社区的其他成员进行交流。
GitHub Issues:Kaldi的GitHub存储库(https://github.com/kaldi-asr/kaldi)上有一个Issues部分,您可以在其中提交问题、报告错误和提出改进建议。其他用户和开发者可以在这里回答您的问题、提供解决方案,并与您讨论相关主题。
Stack Overflow:Stack Overflow是一个广泛使用的问答平台,您可以在其中提问关于Kaldi的问题,并获得其他用户的回答和解决方案。在Stack Overflow上,使用"kaldi"标签来标记您的问题,以便与Kaldi相关的用户能够找到并回答您的问题。
语音处理论坛和社区:除了Kaldi专用的平台,您还可以参与其他语音处理论坛和社区,如Speech and Language Processing (SLP)论坛(https://groups.google.com/g/speech-language-processing)和声学模型论坛(https://groups.google.com/g/acoustic-modeling)。在这些论坛上,您可以与其他语音处理领域的专业人士和研究者交流和讨论。
邮件列表:Kaldi维护了几个邮件列表,您可以通过电子邮件与其他用户和开发者进行交流和讨论。以下是一些常用的Kaldi邮件列表:
kaldi-help:一般性的问题和帮助请求。kaldi-asr:与语音识别相关的问题和讨论。kaldi-recipes:与Kaldi的示例和配方相关的问题和讨论。您可以订阅这些邮件列表并通过电子邮件与其他用户进行交流。有关详细信息和订阅指南,请访问Kaldi的官方网站。 开发者社区:Kaldi的开发者社区也是一个宝贵的资源,您可以在GitHub上找到Kaldi的源代码存储库,并参与开发者社区的讨论和贡献。您可以查看和提交问题、提出改进建议,并与其他开发者进行交流。

 无论您选择哪个平台,重要的是明确您的问题、提供相关的上下文和代码,并尊重其他用户的时间和努力。与社区和其他用户进行积极的交流和讨论,有助于您获得更多的帮助、指导和见解,推动和加速您在Kaldi中的学习和应用。
无论您选择哪个平台,重要的是明确您的问题、提供相关的上下文和代码,并尊重其他用户的时间和努力。与社区和其他用户进行积极的交流和讨论,有助于您获得更多的帮助、指导和见解,推动和加速您在Kaldi中的学习和应用。