
图片来源:伊利亚·卢基切夫/盖蒂图片社
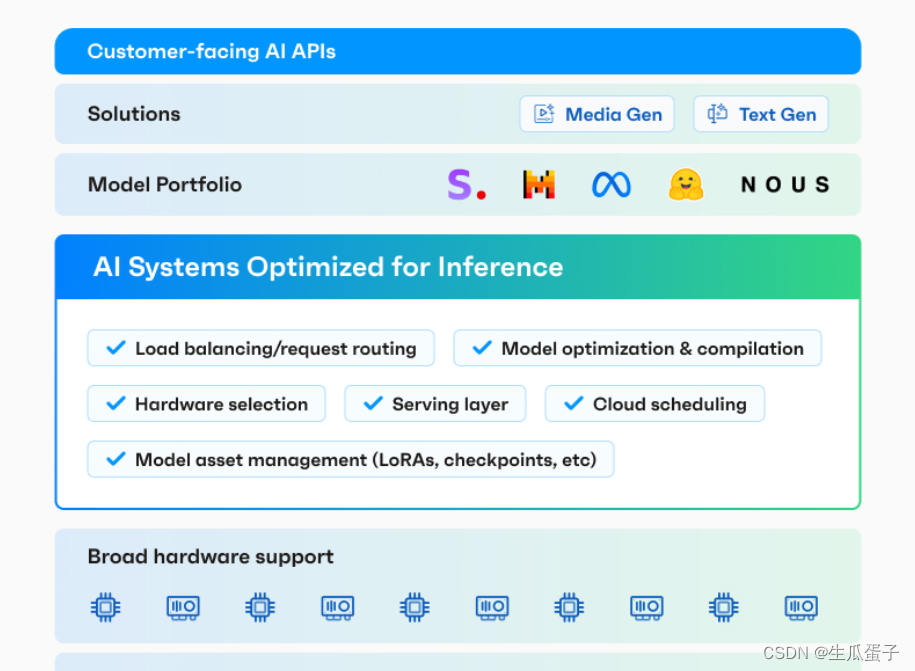
OctoAI(以前称为OctoML)宣布推出 OctoStack,这是其新的端到端解决方案,用于在公司的私有云中部署生成式 AI 模型,无论是在本地还是在主要供应商之一的虚拟私有云中,包括 AWS、Google、Microsoft 和 Azure,以及 CoreWeave、Lambda Labs、Snowflake 等。
在早期,OctoAI 几乎完全专注于优化模型以更有效地运行。基于Apache TVM机器学习编译器框架,该公司随后推出了 TVM 即服务平台,并随着时间的推移,将其扩展为成熟的模型服务产品,将其优化功能与 DevOps 平台相结合。随着生成式人工智能的兴起,该团队随后推出了完全托管的 OctoAI 平台,以帮助用户服务和微调现有模型。 OctoStack 的核心是 OctoAI 平台,但用于私有部署。
图片来源: OctoAI
OctoAI 首席执行官兼联合创始人Luis Ceze告诉我,该公司在该平台上拥有超过 25,000 名开发人员,以及数百名在生产中使用该平台的付费客户。 Ceze 表示,其中很多公司都是 GenAI 本土公司。不过,想要采用生成式人工智能的传统企业的市场要大得多,因此,OctoAI 现在也通过 OctoStack 来追赶他们,这也许并不奇怪。
“有一点很明显,随着企业市场从去年的实验转向部署,所有人都在四处寻找,因为他们对通过 API 发送数据感到紧张,”Ceze 说。 “第二:他们中的很多人也承诺了自己的计算,那么当我已经拥有自己的计算时,为什么还要购买 API?第三,无论你获得什么认证,无论你有多大的名气,他们都会觉得他们的人工智能像他们的数据一样珍贵,他们不想将其发送出去。因此,企业非常明确地需要将部署置于您的控制之下。”
Ceze 指出,该团队构建架构以提供 SaaS 和托管平台已经有一段时间了。虽然 SaaS 平台针对 Nvidia 硬件进行了优化,但 OctoStack 可以支持更广泛的硬件,包括 AMD GPU 和AWS 的 Inferentia加速器,这反过来又使优化挑战变得更加困难(同时也发挥了 OctoAI 的优势)。
对于大多数企业来说,部署 OctoStack 应该很简单,因为 OctoAI 为该平台提供了可读取的容器及其用于部署的相关 Helm 图表。对于开发人员来说,无论他们的目标是 SaaS 产品还是私有云中的 OctoAI,API 都保持不变。
规范的企业用例仍然使用文本摘要和 RAG 来允许用户与其内部文档聊天,但一些公司也在其内部代码库上微调这些模型以运行自己的代码生成模型(类似于 GitHub 现在提供的模型)致Copilot Enterprise 用户)。
对于许多企业来说,能够在严格控制的安全环境中做到这一点,现在使他们能够将这些技术投入生产,供员工和客户使用。
Apate AI创始人兼首席执行官 Dali Kaafar 表示:“对于我们对性能和安全敏感的用例,处理调用数据的模型必须在提供灵活性、规模和安全性的环境中运行。” “OctoStack 让我们能够在我们选择的环境中轻松高效地运行我们需要的定制模型,并提供客户所需的规模。”