Recommender AI Agent: Integrating Large Language Models for InteractiveRecommendations 论文阅读 精读
目录
1.摘要
2.现有问题
3.方法与框架
3.1 整体框架
3.2 记忆工具部分
3.3 Plan-first Execution with Dynamic Demonstrations细节
3.4 Reflection
4 实验部分
4.1 评估策略
4.2实验细节
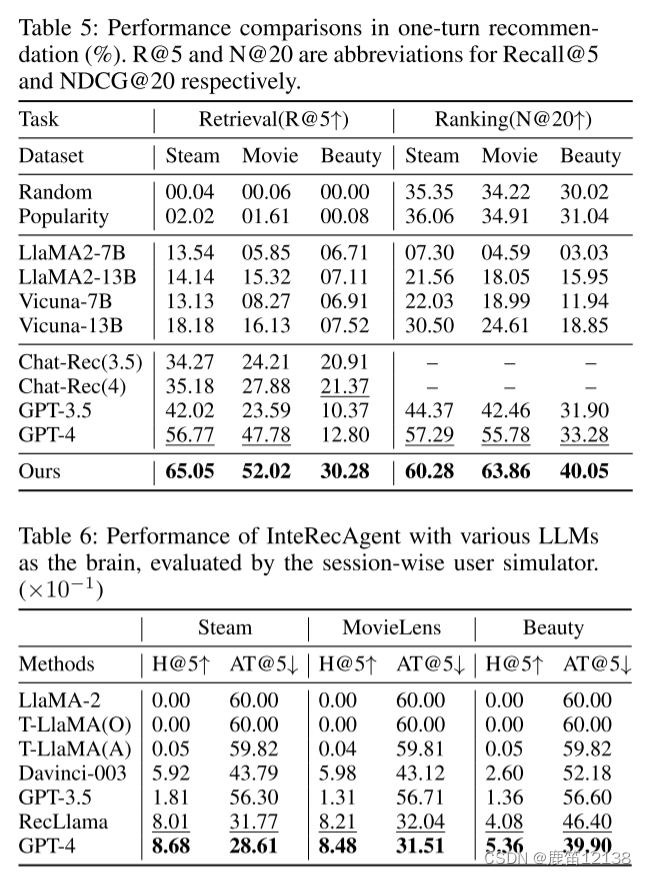
4.3实验数据
1.摘要
推荐模型和大型语言模型(LLM)之间的优势和不足,并提出了一个名为InterRecAgent的框架,旨在结合两者的优势,创建一个通用的和交互式的推荐系统。InterRecAgent利用LLM作为大脑和推荐模型作为工具,通过一系列基本工具将LLM转换为交互式推荐系统。该系统结合了关键组件,如内存组件、动态演示增强的任务规划和反射,使得传统的推荐系统可以通过自然语言界面与用户进行交互。实验结果表明,InterRecAgent作为一个会话式推荐系统在多个公共数据集上表现出令人满意的性能,优于通用LLM。
源码地址GitHub - microsoft/RecAIContribute to microsoft/RecAI development by creating an account on GitHub. https://aka.ms/recagent
https://aka.ms/recagent
2.现有问题
LLMs可能无法捕捉领域特定的细粒度行为模式,特别是在具有大规模训练数据的领域;LLMs可能难以理解一个数据私密、互联网上难以找到的领域;LLMs在预训练数据收集后发布的新物品方面缺乏知识,而使用最新数据进行微调可能成本过高。为了克服这些限制,常见的范式是将LLMs与特定领域内模型结合,填补空白,产生更强大的智能。作者提到的一些例子包括AutoGPT、HuggingGPT和Visual ChatGPT。作者也是使用了类似的LLM+工具范式作用于推荐系统当中。
3.方法与框架
3.1 整体框架
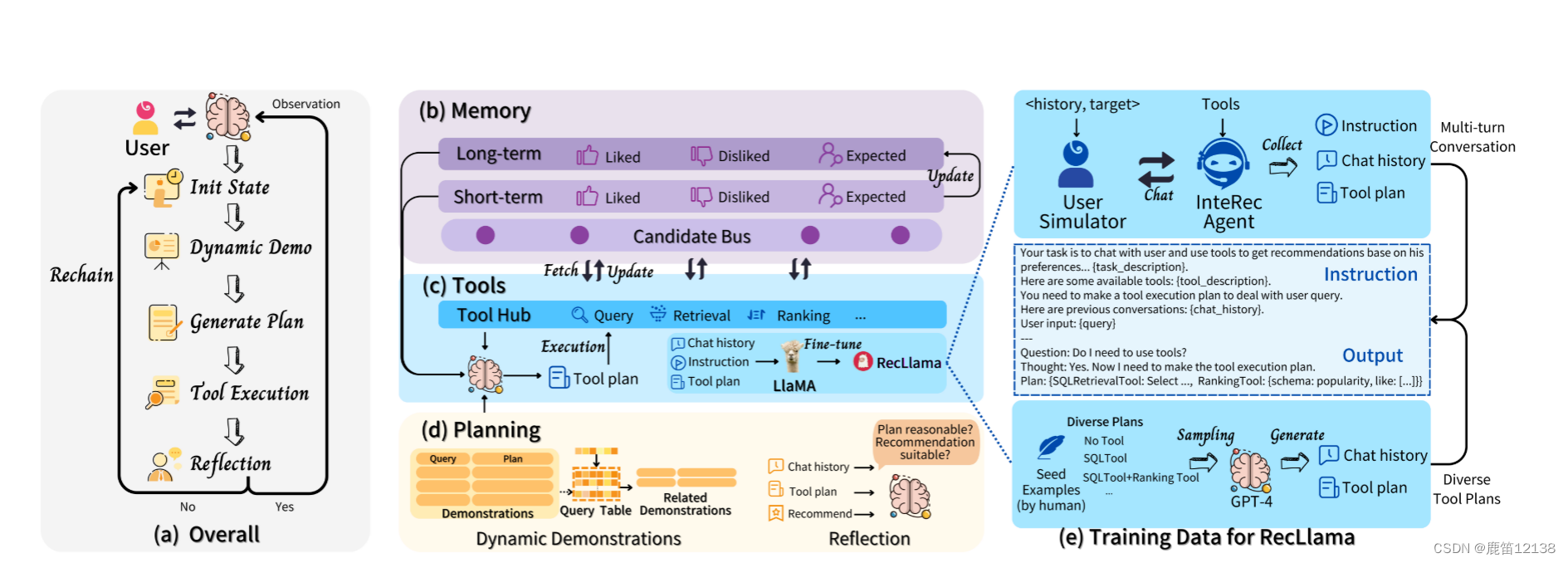
最基本的工具需要包含以下三类
信息查询(Information Query): 例如,在游戏平台上,用户可能会问类似于“这个游戏的发布日期是什么时候?价格是多少?”的问题。为了处理这些查询,LLMs被配置了一个Item Information Query模块,可以通过结构化查询语言(SQL)表达式高效地从后端物品信息数据库中检索详细的物品信息。项目检索(Item Retrieval): 用于提出在当前对话中满足用户意图的项目候选列表。工具分为两种类型:硬条件和软条件。硬条件是对项目的明确要求,比如“我想要一些受欢迎的体育游戏”或“推荐我一些价格低于100美元的RPG游戏”。软条件涉及无法用离散属性明确表达的需求,需要使用语义匹配模型,比如“我想要一些类似于《使命召唤》和《堡垒之夜》的游戏”。为了满足这两种条件,InteRecAgent使用SQL工具处理硬条件,从项目数据库中找到候选项目;对于软条件,采用项目到项目工具,基于潜在嵌入匹配相似项目。项目排序(Item Ranking):排名工具通过利用用户画像对所选候选人执行更复杂的用户偏好预测。与传统推荐系统中的排名器类似,这些工具通常采用单塔架构。候选项的选择可以从项目检索工具的输出中产生,也可以由用户直接提供,如“项目A和项目B哪个更适合我?"排名工具保证推荐的项目不仅与用户的直接意图相关,而且与他们更广泛的偏好一致。从工具来看,作者本质上不过是把粗排的部分,变成一个可接受指令的范围查询。
工具运行流程的例子:
例如,用户可能会问,“我以前玩过Fortnite和Call of Duty。现在,我想玩一些益智游戏,发布日期在Fortnite之后。你有什么建议吗?”在这种情况下,工具执行顺序将是“SQL查询工具→ SQL检索工具→排名工具”。首先,查询Fortnite的发布日期,然后将发布日期和谜题类型解释为SQL检索的硬条件。最后,Fortnite和Call of Duty被认为是排名模型的用户画像。
3.2 记忆工具部分
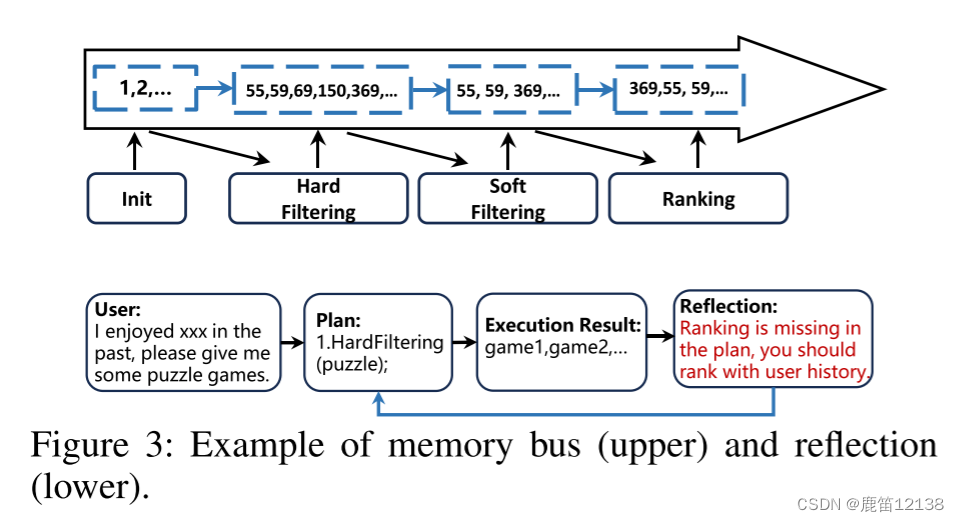
Candidate Memory Bus: 作者引入了一个候选项内存总线,为当前项候选集分配一个独立的内存,消除了将它们附加到提示输入的需求。这样,所有工具都可以访问和修改候选内存,实现了候选项在工具之间的流动。
Plan-first Execution with Dynamic Demonstrations: 作者放弃了最初的“step-by-step”方法,采用了两阶段方法。在第一阶段,LLMs被迫在一次尝试中制定全面的工具执行计划,基于对话中派生的用户意图。在第二阶段,LLMs严格遵循计划,按顺序调用工具,允许它们通过Candidate Memory Bus进行通信。为了提高LLMs的规划能力,作者引入了动态演示策略,将多种可能的用户意图和相应的执行计划嵌入到提示中,以进行上下文学习。这一方法有效解决了“step-by-step”执行方式中存在的问题。

对比下来,主要是将ReAct的多次调用反馈,变为一次计划集中调用,好处体现在API的调用次数减少,时间开销降低(API call下降明显),但是同时,这也导致了推理的准确性有一定程度的降低。
3.3 Plan-first Execution with Dynamic Demonstrations细节
Plan阶段,将用户输入,上下文内容、工具描述、演示样例四类数据作为输入
Execution阶段,按照计算执行,将每一个工具调用的反馈最为一个小的输出结果,最后一个工具的输出结果作为LLM的观察来生成当前阶段的一个响应response。其余信息就存在candidate memory bus 中了
输入plan中演示样例,通过手写20+,再用LLM根据随机生成的计划p,反推对话意图x,再用x生成p~,如果p与p~保持高度一致,则定义为生成成功
3.4 Reflection
假设在第t轮中,对话上下文是Ct−1,并且当前用户输入是Xt。参与者是一名LLM,配备了工具,灵感来自于动态演示-增强计划(Plan-first Execution with Dynamic Demonstrations)优先执行机制。对于用户输入,参与者将制定计划pt,获取工具的输出ot并生成响应yt。评论家评价演员的行为决定。反射机制的执行步骤如下:
1.评论者评估演员在当前对话上下文下的输出pt、ot和yt,并获得判断
γ=Reflect(xt,ct−1,pt,ot,yt) // (用户输入、上下文内容、一系列计划、输出结果、响应)
2.判断γ是否为正,正的话就是ok,反之,rechain重新进如链跑一遍
4 实验部分
4.1 评估策略
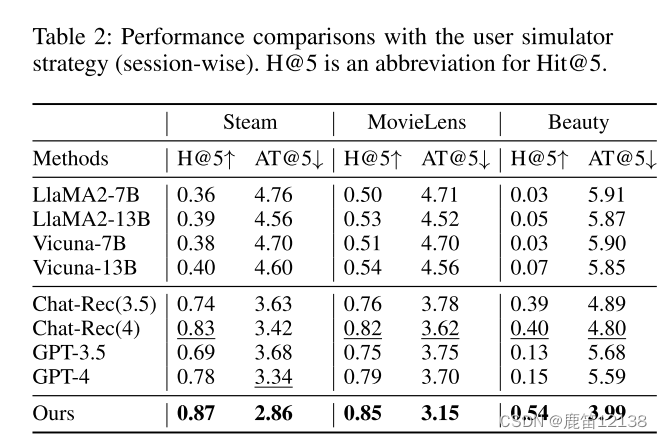
1.用户模拟器,将用户A的交互历史,遮住最后一项,注入到LLM中,模拟用户A与模型对话后,评估模型是否有找到被遮住的最后一项。两中会话策略,一种是多轮,一种是单轮
重点在于,此时InteRecAgent中的长期储存模块是停用的

4.2实验细节
实施细节。我们使用GPT-4作为InteRecAgent的大脑,用于用户意图解析和工具规划。在工具方面,我们使用SQL作为信息查询工具,SQL和ItemCF(Linden,Smith,and York 2003)分别作为硬条件和软条件项检索工具,SASRec(Kang和McAuley 2018)作为排名工具。SQL用集成在PandaSQL中的SQLite实现,检索和排序模型用PyTorch实现。InteRecAgent的框架是用Python语言和LangChain实现的。对于动态演示选择,使用语句转换器将演示编码为向量,并使用ChromaDB存储它们,这有助于在运行时进行ANN搜索。在超参数设置方面,我们将动态演示次数设置为3个,硬条件检索的最大候选数为1000个,软条件检索的阈值削减到前5%
4.3实验数据
用户模拟下的短期数据比较数据
用户模拟下的长期数据比较,LT是启动了长期记忆模块状态下的数据
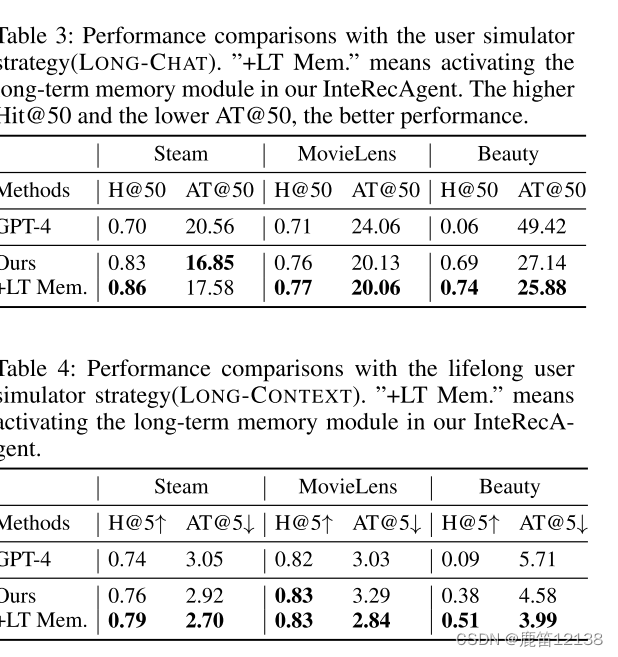
一轮推荐条件下的数据
其他文章相关解读:
InteRecAgent: 结合大语言模型与传统推荐技术,提升推荐系统性能 - 知乎 (zhihu.com)
登录后可发表评论
点击登录