手把手教你基于pytorch实现VGG16(长文)
前言
最近在看经典的卷积网络架构,打算自己尝试复现一下,在此系列文章中,会参考很多文章,有些已经忘记了出处,所以就不贴链接了,希望大家理解。
完整的代码在最后。
本系列必须的基础
python基础知识、CNN原理知识、pytorch基础知识
本系列的目的
一是帮助自己巩固知识点;
二是自己实现一次,可以发现很多之前的不足;
三是希望可以给大家一个参考。
目录结构
文章目录
手把手教你基于pytorch实现VGG16(长文)1. 前言与参考资料:2. 数据集介绍与下载:3. VGG16构建与完善:4. DataSet类构建:5. 训练代码:6. 尝试训练:7. 测试代码:8. 探索1—有无参数初始化的区别:9. 探索2—学习率自动调整:10. 探索3—多尺度:11. 探索4—加载官方预训练的VGG16模型:12. 总结:
1. 前言与参考资料:
在之前的文章中,已经分享过如何实现使用pytorch构建VGG16,不过仅仅停留在构建,并没有使用它去训练测试。
另外,在前面的文章已经详细实现过AlexNet、LeNet了,而在图像分类领域,基本上流程都差不多(创建模型,创建数据加载器、训练、测试),所以注定了有很多重复的地方,有些不重要,我就略过,有需要可以看前面AlexNet、LeNet的实现流程(在我个人主页中查看)。
这篇文章主要目的有两个,一是再次复习实现流程,二是探索新的东西。
数据参考资料
B站的一个up主的GitHub仓库,链接为:
https://github.com/WZMIAOMIAO/deep-learning-for-image-processing 这个up不仅提供了数据集,也提供了相关代码和讲解视频,大家可以自己去学习,但是建议大家自己先实现一次,体验下难点在哪里。
2. 数据集介绍与下载:
数据集下载
**方法一:**从GitHub中下载,然后还需要自己处理一下。
**方法二:**从下面的百度云下载:
链接:https://pan.baidu.com/s/18xFTO8Ps_jPRi3SGWmuVlQ 提取码:6666 数据集介绍
这个数据集也是来自于网上公开的数据集的子集,是一个花分类的数据集,总共有5个类别,分别为daisy(雏菊)、dandelion(蒲公英)、rose(玫瑰)、sunflower(向日葵)、tulip(郁金香)。
从百度网盘获取的数据集,分为两个文件夹,一个为train、一个为test,train中每个类别都有200张图片,共1000张图片;test中每个类别100张图片,共500张图片。
3. VGG16构建与完善:
在之前的文章中已经构建过VGG16了,可以查看之前的文章,链接为:
https://blog.csdn.net/weixin_46676835/article/details/128730174 完整代码为:
# VGG16class My_VGG16(nn.Module): def __init__(self): super(My_VGG16, self).__init__() # 特征提取层 self.features = nn.Sequential( nn.Conv2d(in_channels=3,out_channels=64,kernel_size=3,stride=1,padding=1), nn.Conv2d(in_channels=64,out_channels=64,kernel_size=3,stride=1,padding=1), nn.MaxPool2d(kernel_size=2,stride=2), nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1), nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1), nn.MaxPool2d(kernel_size=2, stride=2), nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1), nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1), nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1), nn.MaxPool2d(kernel_size=2,stride=2), nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, stride=1, padding=1), nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1), nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1), nn.MaxPool2d(kernel_size=2, stride=2), nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1), nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1), nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1), nn.MaxPool2d(kernel_size=2, stride=2), ) # 分类层 self.classifier = nn.Sequential( nn.Linear(in_features=7*7*512,out_features=4096), nn.ReLU(), nn.Dropout(0.5), nn.Linear(in_features=4096,out_features=4096), nn.ReLU(), nn.Dropout(0.5), nn.Linear(in_features=4096,out_features=5) ) def forward(self,x): x = self.features(x) x = torch.flatten(x,1) result = self.classifier(x) return result 不过,这段代码还不完美,因为没有实现参数初始化的部分,并且,最好把最后输出的类个数(5)改为一个可控制的变量。
后者容易修改(只显示改动的部分):
def __init__(self,num_classes=5): # 添加一个变量num_classes,默认值为5,是因为我们的数据集只有5类......nn.Linear(in_features=4096,out_features=num_classes) # 改为变量num_classes...... 下一步,添加参数初始化部分,这一部分也很简单,可以直接使用同一种初始化方法,也可以对不同的部分使用不同初始化方法,这里我参照pytorch官方的实现方法实现初始化部分:
def __init__(self,num_classes=5,init_weight=True): # 设置一个控制是否参数初始化的变量......# 参数初始化 if init_weight: # 如果进行参数初始化 for m in self.modules(): # 对于模型的每一层 if isinstance(m, nn.Conv2d): # 如果是卷积层 # 使用kaiming初始化 nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu") # 如果bias不为空,固定为0 if m.bias is not None: nn.init.constant_(m.bias, 0) elif isinstance(m, nn.Linear):# 如果是线性层 # 正态初始化 nn.init.normal_(m.weight, 0, 0.01) # bias则固定为0 nn.init.constant_(m.bias, 0)......完整代码
# VGG16class My_VGG16(nn.Module): def __init__(self,num_classes=5,init_weight=True): super(My_VGG16, self).__init__() # 特征提取层 self.features = nn.Sequential( nn.Conv2d(in_channels=3,out_channels=64,kernel_size=3,stride=1,padding=1), nn.Conv2d(in_channels=64,out_channels=64,kernel_size=3,stride=1,padding=1), nn.MaxPool2d(kernel_size=2,stride=2), nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1), nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1), nn.MaxPool2d(kernel_size=2, stride=2), nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1), nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1), nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1), nn.MaxPool2d(kernel_size=2,stride=2), nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, stride=1, padding=1), nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1), nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1), nn.MaxPool2d(kernel_size=2, stride=2), nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1), nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1), nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1), nn.MaxPool2d(kernel_size=2, stride=2), ) # 分类层 self.classifier = nn.Sequential( nn.Linear(in_features=7*7*512,out_features=4096), nn.ReLU(), nn.Dropout(0.5), nn.Linear(in_features=4096,out_features=4096), nn.ReLU(), nn.Dropout(0.5), nn.Linear(in_features=4096,out_features=num_classes) ) # 参数初始化 if init_weight: # 如果进行参数初始化 for m in self.modules(): # 对于模型的每一层 if isinstance(m, nn.Conv2d): # 如果是卷积层 # 使用kaiming初始化 nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu") # 如果bias不为空,固定为0 if m.bias is not None: nn.init.constant_(m.bias, 0) elif isinstance(m, nn.Linear):# 如果是线性层 # 正态初始化 nn.init.normal_(m.weight, 0, 0.01) # bias则固定为0 nn.init.constant_(m.bias, 0) def forward(self,x): x = self.features(x) x = torch.flatten(x,1) result = self.classifier(x) return result4. DataSet类构建:
这里,我们需要自己实现Dataset类(用来获取数据和标签,配合Dataloader使用)。
目录结构
在介绍如何写代码前,先说明一下我的目录结构:
data # 文件夹net_train_images # 下载后解压的数据文件夹net_test_images# 下载后解压的数据文件夹图像分类# 文件夹VGG16.py # 代码文件基本框架
首先,根据pytorch基础知识,写出Dataset类的基本框架:
class My_Dataset(Dataset): def __init__(self): pass def __len__(self): pass def __getitem__(self,idx): pass_init_()填写
我们需要定义两个基本的参数filename,transform:
def __init__(self,filename,transform=None): self.filename = filename# 文件路径 self.transform = transform # 是否对图片进行变化 而在init方法中,我们需要获取到我们的**图像路径和相应标签,**因此我们定义一个函数来实现该想法:
def __init__(self,filename,transform=None): self.filename = filename# 文件路径 self.transform = transform # 是否对图片进行变化# 变化之处 self.image_name,self.label_image = self.operate_file()operate_file方法实现
由于我们的图片存在于多个文件夹中,因此**决定了我们的filename参数应该是一个文件夹路径,**在我的目录结构中应该为:
'../data/net_train_images' 因此,可以这么写代码(看注释)
def operate_file(self): # 获取所有的文件夹路径 '../data/net_train_images'下的文件夹 dir_list = os.listdir(self.filename) # 拼凑出图片完整路径 '../data/net_train_images' + '/' + 'xxx.jpg' full_path = [self.filename+'/'+name for name in dir_list] # 获取里面的图片名字 name_list = [] for i,v in enumerate(full_path): temp = os.listdir(v) temp_list = [v+'/'+j for j in temp] name_list.extend(temp_list)# 由于一个文件夹的所有标签都是同一个值,而字符值必须转为数字值,因此我们使用数字0-4代替标签值 # 将标签每个复制200个 label_list = [] temp_list = np.array([0,1,2,3,4],dtype=np.int64) # 用数字代表不同类别 for j in range(5): for i in range(200): label_list.append(temp_list[j]) return name_list,label_list 这里,我必须解释一下:**为什么np那里需要声明为int64类型?**因为你训练的时候,使用损失函数计算loss(pred,ture_label)那里,必须要求int类型为int64。
__len__方法填写
这个简单,直接按照固定套路写即可:
def __len__(self): return len(self.image_name)__getitem__方法填写
实现的思路:打开图片、对图片下采样为224*224、获取标签、是否需要处理、转为tensor对象、返回值。
具体代码为:(看注释)
def __getitem__(self,idx): # 由路径打开图片 image = Image.open(self.image_name[idx]) # 下采样: 因为图片大小不同,需要下采样为224*224 trans = transforms.RandomResizedCrop(224) image = trans(image) # 获取标签值 label = self.label_image[idx] # 是否需要处理 if self.transform: image = self.transform(image) # 转为tensor对象 label = torch.from_numpy(np.array(label)) return image,label完整代码
class My_Dataset(Dataset): def __init__(self,filename,transform=None): self.filename = filename # 文件路径 self.transform = transform # 是否对图片进行变化 self.image_name,self.label_image = self.operate_file() def __len__(self): return len(self.image_name) def __getitem__(self,idx): # 由路径打开图片 image = Image.open(self.image_name[idx]) # 下采样: 因为图片大小不同,需要下采样为224*224 trans = transforms.RandomResizedCrop(224) image = trans(image) # 获取标签值 label = self.label_image[idx] # 是否需要处理 if self.transform: image = self.transform(image) # 转为tensor对象 label = torch.from_numpy(np.array(label)) return image,label def operate_file(self): # 获取所有的文件夹路径 '../data/net_train_images'的文件夹 dir_list = os.listdir(self.filename) # 拼凑出图片完整路径 '../data/net_train_images' + '/' + 'xxx.jpg' full_path = [self.filename+'/'+name for name in dir_list] # 获取里面的图片名字 name_list = [] for i,v in enumerate(full_path): temp = os.listdir(v) temp_list = [v+'/'+j for j in temp] name_list.extend(temp_list) # 由于一个文件夹的所有标签都是同一个值,而字符值必须转为数字值,因此我们使用数字0-4代替标签值 label_list = [] temp_list = np.array([0,1,2,3,4],dtype=np.int64) # 用数字代表不同类别 # 将标签每个复制200个 for j in range(5): for i in range(200): label_list.append(temp_list[j]) return name_list,label_list5. 训练代码:
在完成了模型创建、Dataset类构建,就可以开始着手实现训练过程了。
这里,我将训练过程放入了一个名为train的函数中进行。
def train():pass前期准备
首先,创建我们的模型,并将模型放入GPU中:
def train(): model = My_VGG16() # 创建模型 # 将模型放入GPU中 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") model.to(device) 声明,为了简便,后面不会写重复的部分,只会写新多出来的部分。
接着,我们定义损失函数,这里采取分类任务常用的交叉熵损失函数:
# 定义损失函数loss_func = nn.CrossEntropyLoss() 然后,定义优化器,这里采取Adam优化器:
# 定义优化器optimizer = optim.Adam(params=model.parameters(),lr=0.0002) 下一步,定义每批训练的数据个数并加载数据:
batch_size = 32 # 批量训练大小# 加载数据train_set = My_Dataset('../data/net_train_images',transform=transforms.ToTensor())train_loader = DataLoader(train_set, batch_size, shuffle=True)训练中
假设训练20次,并定义一个临时变量loss_temp来存储损失值:
# 训练20次for i in range(20): loss_temp = 0 # 临时变量 接着,批量批次接收数据:
for i in range(20):loss_temp = 0 # 临时变量for j,(batch_data,batch_label) in enumerate(train_loader): # 之后的代码都在这个循环中 首先,把数据放入GPU中:
# 数据放入GPU中batch_data,batch_label = batch_data.cuda(),batch_label.cuda() 接着,便是丝滑小连招:
# 梯度清零optimizer.zero_grad()# 模型训练prediction = model(batch_data)# 损失值loss = loss_func(prediction,batch_label)loss_temp += loss.item()# 反向传播loss.backward()# 梯度更新optimizer.step() 当内层结束循环时,打印一下这次的平均损失值:
# 这里新增的print('[%d] loss: %.3f' % (i+1,loss_temp/len(train_loader)))完整代码
# 训练过程def train(): batch_size = 32 # 批量训练大小 model = My_VGG16() # 创建模型 # 将模型放入GPU中 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") model.to(device) # 定义损失函数 loss_func = nn.CrossEntropyLoss() # 定义优化器 optimizer = optim.Adam(params=model.parameters(),lr=0.0002) # 加载数据 train_set = My_Dataset('../data/net_train_images',transform=transforms.ToTensor()) train_loader = DataLoader(train_set, batch_size, shuffle=True) # 训练20次 for i in range(20): loss_temp = 0 # 临时变量 for j,(batch_data,batch_label) in enumerate(train_loader): # 数据放入GPU中 batch_data,batch_label = batch_data.cuda(),batch_label.cuda() # 梯度清零 optimizer.zero_grad() # 模型训练 prediction = model(batch_data) # 损失值 loss = loss_func(prediction,batch_label) loss_temp += loss.item() # 反向传播 loss.backward() # 梯度更新 optimizer.step() # 打印一次损失值 print('[%d] loss: %.3f' % (i+1,loss_temp/len(train_loader)))6. 尝试训练:
我完成上面的代码后,尝试去训练VGG16,但是遇到一个问题:GPU不够用,直接报错了,报错代码如下:
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 50.00 MiB (GPU 0; 4.00 GiB total capacity; 2.56 GiB already allocated; 0 bytes free; 2.56 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF 如果没记错,AlexNet参数量在6千万左右,而VGG16在1.3亿左右,想来报错也应该(不过,主要原因是我对这块不是很懂)。
想来想去,只好减少batch_size大小了,不过即使我减小的再小也无法成功运行。
于是,我尝试修改了优化器,改为了SGD优化器并且降低了batch_size大小(由原来的32改为了10):
# batch_sizebatch_size = 10# 定义优化器optimizer = optim.SGD(params=model.parameters(),lr=0.0002) 终于可以成功运行了,运行结果如下:
[1] loss: 1.871[2] loss: 1.540[3] loss: 1.416[4] loss: 1.396[5] loss: 1.330[6] loss: 1.324[7] loss: 1.320[8] loss: 1.279[9] loss: 1.276[10] loss: 1.299[11] loss: 1.298[12] loss: 1.252[13] loss: 1.255[14] loss: 1.233[15] loss: 1.264[16] loss: 1.211[17] loss: 1.218[18] loss: 1.221[19] loss: 1.209[20] loss: 1.207 不过受限于算力,没有过多的训练,并且优化器也没有怎么调整,所以结果勉强接受,大家如果有更好的设备,可以多探索探索。
7. 测试代码:
测试部分的代码,需要写两个部分,一是测试集数据的加载,二是测试过程代码。
数据集加载的代码,可以仿照训练集加载来写 ,我直接把代码放在这里,大家可以自行参考:
# 继承自训练数据加载器,只修改一点点的地方class My_Dataset_test(My_Dataset): def operate_file(self): # 获取所有的文件夹路径 dir_list = os.listdir(self.filename) full_path = [self.filename+'/'+name for name in dir_list] # 获取里面的图片名字 name_list = [] for i,v in enumerate(full_path): temp = os.listdir(v) temp_list = [v+'/'+j for j in temp] name_list.extend(temp_list) # 将标签每个复制一百个 label_list = [] temp_list = np.array([0,1,2,3,4],dtype=np.int64) # 用数字代表不同类别 for j in range(5): for i in range(100): # 只修改了这里 label_list.append(temp_list[j]) return name_list,label_list 另外,就是测试过程的代码,也很简单,可以看注释:
def test(model): # 批量数目 batch_size = 10 # 预测正确个数 correct = 0 # 加载数据 test_set = My_Dataset_test('../data/net_test_images', transform=transforms.ToTensor()) test_loader = DataLoader(test_set, batch_size, shuffle=False) # 开始 for batch_data,batch_label in test_loader: # 放入GPU中 batch_data, batch_label = batch_data.cuda(), batch_label.cuda() # 预测 prediction = model(batch_data) # 将预测值中最大的索引取出,其对应了不同类别值 predicted = torch.max(prediction.data, 1)[1] # 获取准确个数 correct += (predicted == batch_label).sum() print('准确率: %.2f %%' % (100 * correct / 500)) # 因为总共500个测试数据 需要注意的是,这里需要在训练代码中加入一句:
def train():....test() 这样才可以调用测试部分代码。
8. 探索1—有无参数初始化的区别:
为了探索参数初始化的作用,我们肯定是其它参数都一致,只是改变有无初始化即可,结果如下:
无参数初始化,运行结果:[1] loss: 1.609[2] loss: 1.609[3] loss: 1.610[4] loss: 1.609[5] loss: 1.609[6] loss: 1.610[7] loss: 1.609[8] loss: 1.610[9] loss: 1.609[10] loss: 1.610[11] loss: 1.609[12] loss: 1.609[13] loss: 1.609 我没有训练完,因为基本上都在1.609这个值跳动了,说明收敛很快,不过这也说明了没有训练好,参数等需要调整。
再看看有参数初始化的情况:[1] loss: 1.870[2] loss: 1.515[3] loss: 1.418[4] loss: 1.397[5] loss: 1.359[6] loss: 1.345[7] loss: 1.307[8] loss: 1.310[9] loss: 1.280[10] loss: 1.305[11] loss: 1.290[12] loss: 1.245[13] loss: 1.280[14] loss: 1.261[15] loss: 1.261[16] loss: 1.214[17] loss: 1.226[18] loss: 1.197[19] loss: 1.191[20] loss: 1.211准确率: 47.00 % 可见参数初始化很重要,可以提高准确率和训练效率。
另外,老实说这个结果很差劲,之前在AlexNet中可以取得准确率: 64.20 %,不过这个差劲的结果很大的原因是因为算力限制,我直觉告诉我,提高了batch_size、优化优化器参数、提高训练次数是可以提高准确率的。
另外,需要说明一下,AlexNet论文中Top-1错误率为37%左右,即准确率在63%左右,所以60%多的top-1准确率也还不错了(相对而言_)(这个是对AlexNet那篇博客的补充)。
9. 探索2—学习率自动调整:
在论文中,明确提及了学习率自动调整,即前期使用大学习率,当误差收敛或在某值跳动时,降低学习率。
这个的实现思路很简单,就是添加一个函数,输入参数为损失值,记录当前的损失值变化情况如何,当变化波动很小时,便通过函数改变学习率的大小即可。
我简单的按照自己的想法尝试实现了一下:
# 调整学习率loss_save = []flag = 0lr = 0.002def adjust_lr(loss): global flag,lr loss_save.append(loss) if len(loss_save) >= 2: # 如果已经训练了2次,可以判断是否收敛或波动 if abs(loss_save[-1] - loss_save[-2]) <= 0.0005: # 如果变化范围小于0.0005,说明可能收敛了 flag += 1 if loss_save[-1] - loss_save[-2] >= 0: # 如果损失值增加,也记一次 flag += 1 if flag >= 3: # 如果出现3次这样的情况,需要调整学习率 lr /= 10 print('学习率已改变,变为了%s' % (lr)) # 并将flag清为0 flag = 0 我这里实现的思路是一边训练,一边调整。但是其实这有一个坏处:**怎样的评价标准来判断是否改变学习率?**用人话很好解决,如果收敛或者波动就改变学习率,但是放在代码中如何体现?我这里设置一个敏感度,当出现3次损失变化范围小于0.0005或者损失值增加,就将学习率/10。
不过,我觉得更好的实现方法是,当发现损失值收敛或波动时,停止训练,保存模型参数。接着,调整学习率,继承参数,继续训练。
10. 探索3—多尺度:
在VGG原始论文中,说他们的测试代码并没有像常规操作一样进行,而是探索了多尺度的好处。即输入图像的分辨率大小不一样,想要实现这个,需要知道什么东西限制了输入大小。答案就是全连接层,因为全连接层的输入和输出固定,所以必须限制模型的输入大小。
为此,作者改变了VGG的架构,将最后的全连接层替换成了卷积层。一定很好奇怎么替换的,比如VGG16中全连接层的输入为7*7*512,输出为4096,那么替换的卷积层为7*7*4096,后面的全连接层替换为1*1*4096和1*1*1000。
这里仅做讨论,不实现(想要实现,就是先训练,保存参数,然后改变模型,继承对应部分的参数,然后进行测试。)
11. 探索4—加载官方预训练的VGG16模型:
pytorch官方其实提供了预训练的vgg16模型,我们可以直接拿来用,这样不仅方便而且效率很高。
**所谓预训练模型,你可以简单理解为别人在大数据上跑好的模型,别人把这些参数保存并发表在网上供我们使用。**预训练模型的下载链接为:
链接:https://pan.baidu.com/s/196kMlq8UE3ufPbbRZUpKwA 提取码:gmui 我这里下载后保存的路径为:F:/官方_预训练模型/vgg16-397923af.pth。
于是,我定义一个函数,加载预训练模型:
def load_pretrained(): path = 'F:/官方_预训练模型/vgg16-397923af.pth' model = vgg16() # 来自 from torchvision.models import vgg16 model.load_state_dict(torch.load(path)) return model 接着,我改变了我们的训练次数,由原来的20次,改为了50次来训练我自己定义的模型,结果为:
[1] loss: 1.9250[2] loss: 1.4973[3] loss: 1.4317[4] loss: 1.3899[5] loss: 1.3463[6] loss: 1.3157[7] loss: 1.2699[8] loss: 1.2105[9] loss: 1.2180[10] loss: 1.2270[11] loss: 1.1846[12] loss: 1.1652[13] loss: 1.1506[14] loss: 1.1771[15] loss: 1.1465[16] loss: 1.1707[17] loss: 1.1332[18] loss: 1.1041[19] loss: 1.0885[20] loss: 1.1173[21] loss: 1.1143[22] loss: 1.0801[23] loss: 1.0724[24] loss: 1.0278[25] loss: 1.0714[26] loss: 1.0464[27] loss: 1.0350[28] loss: 1.0153[29] loss: 1.0077[30] loss: 1.0233[31] loss: 1.0305[32] loss: 0.9998[33] loss: 0.9752[34] loss: 0.9988[35] loss: 0.9896[36] loss: 0.9851[37] loss: 0.9496[38] loss: 0.9576[39] loss: 0.9551[40] loss: 0.9136[41] loss: 0.9640[42] loss: 0.9368[43] loss: 0.9130[44] loss: 0.8888[45] loss: 0.8946[46] loss: 0.8754[47] loss: 0.9135[48] loss: 0.8933[49] loss: 0.8460[50] loss: 0.8345准确率: 58.20 % 这里表明:提高训练次数,的确可以提高准确率。
接着,我用预训练模型,仅仅训练20次,所得结果为:
[1] loss: 1.6929[2] loss: 0.8252[3] loss: 0.6762[4] loss: 0.5808[5] loss: 0.4888[6] loss: 0.4424[7] loss: 0.3816[8] loss: 0.3353[9] loss: 0.2834[10] loss: 0.2950[11] loss: 0.2784[12] loss: 0.2790[13] loss: 0.2311[14] loss: 0.2086[15] loss: 0.1971[16] loss: 0.1815[17] loss: 0.2106[18] loss: 0.1975[19] loss: 0.1857[20] loss: 0.1610准确率: 85.80 % 可见,预训练模型的作用真的很大,可以提高效率和准确率。
12. 总结:
经过这次实现,我明白了几个道理:
算力很重要,真的很重要。我的笔记本根本算不动T_T。学习模型参数初始化方法、模型学习率调整函数实现思路如何使用卷积代替全连接当算力不够的时候,如何去调整模型,以达到可以训练的目的学习率调整思路预训练模型如何加载和使用模型保存很重要,特别时你的训练时间很久的时候,建议大家训练的时候一定要保存模型完整代码
# author: baiCaiimport osfrom PIL import Imageimport numpy as npimport torchfrom torch import nnfrom torch.nn.functional import interpolatefrom torch.utils.data import DataLoader,Datasetfrom torch import optimfrom torchvision import transformsfrom torchvision.models import vgg16# VGG16:自己的模型class My_VGG16(nn.Module): def __init__(self,num_classes=5,init_weight=True): super(My_VGG16, self).__init__() # 特征提取层 self.features = nn.Sequential( nn.Conv2d(in_channels=3,out_channels=64,kernel_size=3,stride=1,padding=1), nn.Conv2d(in_channels=64,out_channels=64,kernel_size=3,stride=1,padding=1), nn.MaxPool2d(kernel_size=2,stride=2), nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1), nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1), nn.MaxPool2d(kernel_size=2, stride=2), nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1), nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1), nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1), nn.MaxPool2d(kernel_size=2,stride=2), nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, stride=1, padding=1), nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1), nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1), nn.MaxPool2d(kernel_size=2, stride=2), nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1), nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1), nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1), nn.MaxPool2d(kernel_size=2, stride=2), ) # 分类层 self.classifier = nn.Sequential( nn.Linear(in_features=7*7*512,out_features=4096), nn.ReLU(), nn.Dropout(0.5), nn.Linear(in_features=4096,out_features=4096), nn.ReLU(), nn.Dropout(0.5), nn.Linear(in_features=4096,out_features=num_classes) ) # 参数初始化 if init_weight: # 如果进行参数初始化 for m in self.modules(): # 对于模型的每一层 if isinstance(m, nn.Conv2d): # 如果是卷积层 # 使用kaiming初始化 nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu") # 如果bias不为空,固定为0 if m.bias is not None: nn.init.constant_(m.bias, 0) elif isinstance(m, nn.Linear):# 如果是线性层 # 正态初始化 nn.init.normal_(m.weight, 0, 0.01) # bias则固定为0 nn.init.constant_(m.bias, 0) def forward(self,x): x = self.features(x) x = torch.flatten(x,1) result = self.classifier(x) return result# 模型输入:224*224*3# 训练集数据加载class My_Dataset(Dataset): def __init__(self,filename,transform=None): self.filename = filename # 文件路径 self.transform = transform # 是否对图片进行变化 self.image_name,self.label_image = self.operate_file() def __len__(self): return len(self.image_name) def __getitem__(self,idx): # 由路径打开图片 image = Image.open(self.image_name[idx]) # 下采样: 因为图片大小不同,需要下采样为224*224 trans = transforms.RandomResizedCrop(224) image = trans(image) # 获取标签值 label = self.label_image[idx] # 是否需要处理 if self.transform: image = self.transform(image) # image = image.reshape(1,image.size(0),image.size(1),image.size(2)) # print('变换前',image.size()) # image = interpolate(image, size=(227, 227)) # image = image.reshape(image.size(1),image.size(2),image.size(3)) # print('变换后', image.size()) # 转为tensor对象 label = torch.from_numpy(np.array(label)) return image,label def operate_file(self): # 获取所有的文件夹路径 '../data/net_train_images'的文件夹 dir_list = os.listdir(self.filename) # 拼凑出图片完整路径 '../data/net_train_images' + '/' + 'xxx.jpg' full_path = [self.filename+'/'+name for name in dir_list] # 获取里面的图片名字 name_list = [] for i,v in enumerate(full_path): temp = os.listdir(v) temp_list = [v+'/'+j for j in temp] name_list.extend(temp_list) # 由于一个文件夹的所有标签都是同一个值,而字符值必须转为数字值,因此我们使用数字0-4代替标签值 label_list = [] temp_list = np.array([0,1,2,3,4],dtype=np.int64) # 用数字代表不同类别 # 将标签每个复制200个 for j in range(5): for i in range(200): label_list.append(temp_list[j]) return name_list,label_list# 测试集数据加载器class My_Dataset_test(My_Dataset): def operate_file(self): # 获取所有的文件夹路径 dir_list = os.listdir(self.filename) full_path = [self.filename+'/'+name for name in dir_list] # 获取里面的图片名字 name_list = [] for i,v in enumerate(full_path): temp = os.listdir(v) temp_list = [v+'/'+j for j in temp] name_list.extend(temp_list) # 将标签每个复制一百个 label_list = [] temp_list = np.array([0,1,2,3,4],dtype=np.int64) # 用数字代表不同类别 for j in range(5): for i in range(100): # 只修改了这里 label_list.append(temp_list[j]) return name_list,label_list# 调整学习率loss_save = []flag = 0lr = 0.0002def adjust_lr(loss): global flag,lr loss_save.append(loss) if len(loss_save) >= 2: # 如果已经训练了2次,可以判断是否收敛或波动 if abs(loss_save[-1] - loss_save[-2]) <= 0.0005: # 如果变化范围小于0.0005,说明可能收敛了 flag += 1 if loss_save[-1] - loss_save[-2] >= 0: # 如果损失值增加,也记一次 flag += 1 if flag >= 3: # 如果出现3次这样的情况,需要调整学习率 lr /= 10 print('学习率已改变,变为了%s' % (lr)) # 并将flag清为0 flag = 0# 加载预训练模型def load_pretrained(): path = 'F:/官方_预训练模型/vgg16-397923af.pth' # 需要改为自己的路径 model = vgg16() model.load_state_dict(torch.load(path)) return model# 训练过程def train(): batch_size = 10 # 批量训练大小 model = My_VGG16() # 创建模型 # 加载预训练vgg # model = load_pretrained() # 定义优化器 optimizer = optim.SGD(params=model.parameters(), lr=lr) # 将模型放入GPU中 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") model.to(device) # 定义损失函数 loss_func = nn.CrossEntropyLoss() # 加载数据 train_set = My_Dataset('../data/net_train_images',transform=transforms.ToTensor()) train_loader = DataLoader(train_set, batch_size, shuffle=True) # 训练20次 for i in range(20): loss_temp = 0 # 临时变量 for j,(batch_data,batch_label) in enumerate(train_loader): # 数据放入GPU中 batch_data,batch_label = batch_data.cuda(),batch_label.cuda() # 梯度清零 optimizer.zero_grad() # 模型训练 prediction = model(batch_data) # 损失值 loss = loss_func(prediction,batch_label) loss_temp += loss.item() # 反向传播 loss.backward() # 梯度更新 optimizer.step() # 每25个批次打印一次损失值 print('[%d] loss: %.4f' % (i+1,loss_temp/len(train_loader))) # 是否调整学习率,如果调整的话,需要把优化器也移动到循环内部 # adjust_lr(loss_temp/len(train_loader)) # torch.save(model,'VGG16.pkl') test(model)def test(model): # 批量数目 batch_size = 10 # 预测正确个数 correct = 0 # 加载数据 test_set = My_Dataset_test('../data/net_test_images', transform=transforms.ToTensor()) test_loader = DataLoader(test_set, batch_size, shuffle=False) # 开始 for batch_data,batch_label in test_loader: # 放入GPU中 batch_data, batch_label = batch_data.cuda(), batch_label.cuda() # 预测 prediction = model(batch_data) # 将预测值中最大的索引取出,其对应了不同类别值 predicted = torch.max(prediction.data, 1)[1] # 获取准确个数 correct += (predicted == batch_label).sum() print('准确率: %.2f %%' % (100 * correct / 500)) # 因为总共500个测试数据if __name__ == '__main__': train()补充:如何进行可视化?
留言区有位朋友问如何实现结果的可视化。按照我的理解,应该是现在的结果只显示了一个简单的测试准确率,而他想要实现图像—预测标签这样的可视化结果。
稍微修改一下测试函数代码: 我们的测试函数有一个结果变量叫做predicted,打印一下看看值为什么:
tensor([4, 3, 3, 0, 0, 3, 0, 0, 0, 0], device='cuda:0')# 一个变量十个值,是因为batch_size=10 可以发现为一个tensor变量,其中的0、1、2、3、4其实代表了不同的类别,分别为{daisy,dandelion,rose,sunflower,tulip}五个类别。
那么,我们可以修改测试函数代码,把predicted变量值保存起来,然后把该值(预测标签值)、真实标签值和图片的名字传给一个可视化函数:(只写出修改的代码)
def test(model):... # 定义一个存储预测类别值的变量 predicted_labels = [] # 定义一个存储真实标签的变量 truth_labels = [] # 定义一个存储图片名字的变量 image_names = [] # 加载图片名字:从上面的加载数据集代码中直接拷贝过来的 # 作用就是把文件夹里面的图片名字弄进一个列表中 dir_list = os.listdir('../data/net_test_images') full_path = ['../data/net_test_images' + '/' + name for name in dir_list] for path in full_path: temp = os.listdir(path) temp_list = [path + '/' + j for j in temp] image_names.extend(temp_list) ... for batch_data,batch_label in test_loader: ... # 添加值 # predicted = tensor([4, 3, 3, 0, 0, 3, 0, 0, 0, 0], device='cuda:0') for i in predicted: # i = tensor(4, device='cuda:0') predicted_labels.append(i.item())# 添加真实值 for j in batch_label: truth_labels.append(j.item())...... # 传给可视化函数 visualize(predicted_labels,truth_labels,image_names) 打印一下定义的变量predicted_labels和truth_labels的值如下(部分):
预测的类别值:[4, 3, 3, 3, 0, 3, 0, 1, 1, 0, 0, 1, 1, 0, 0....]真实的类别值:[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,...] 首先,需要把这些数字转为对应的真实标签:
def visualize(predicted_labels,truth_labels,image_names): # 真实标签,用字典存储 labels = {0:'daisy',1:'dandelion',2:'rose',3:'sunflower',4:'tulip'} # 转换 predicted_labels = [labels[i] for i in predicted_labels] truth_labels = [labels[i] for i in truth_labels] 打印看看结果(部分):
['rose', 'sunflower', 'daisy', 'sunflower', 'daisy', 'sunflower', 'daisy', 'dandelion', 'daisy', 'sunflower', 'daisy', 'sunflower', .....] 结果正常,继续。**我简单想了想,首先,第一种简单的实现方法,就是打印出图像文件名字---预测标签---真实标签这样的结果。**实现方法如下:
# 第一种实现方法:for pred,truth,name in zip(predicted_labels,truth_labels,image_names):print('图片路径:%s\t\t预测标签值:%s\t\t真实标签值:%s' % (name,pred,truth)) 打印结果如下: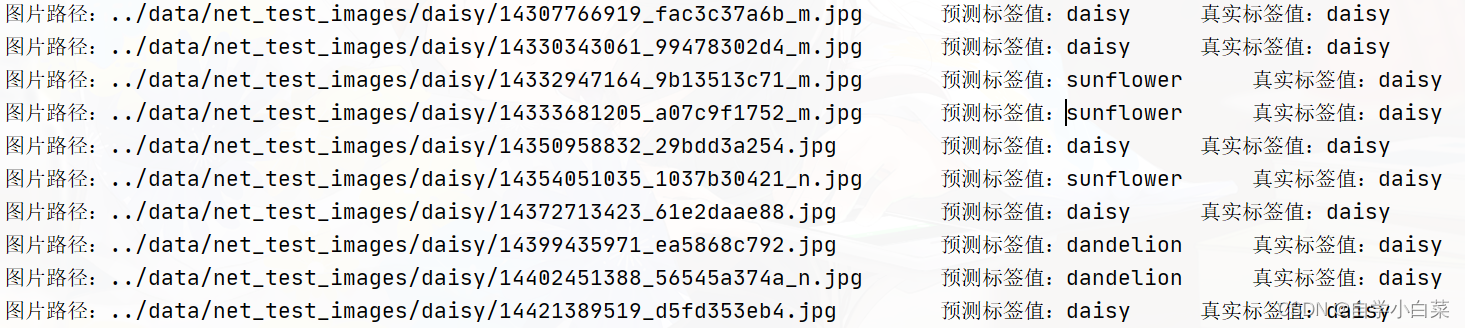
第二种稍微复杂点,就是打开图片,然后把预测标签和真实标签写进入:
# 第二种实现方法 for pred, truth, name in zip(predicted_labels, truth_labels, image_names): # 打开图片 image = Image.open(name) # 显示图片 plt.figure() plt.imshow(image) plt.text(0,50,'predicted:'+pred,color='red',fontsize=20) # 前两个值制定显示的位置,第三个值显示的内容,后面的为颜色和字体大小参数 plt.text(0,100,'truth:'+truth,color='blue',fontsize=20) plt.show() 我们可以设置两个断点,然后来查看结果如下: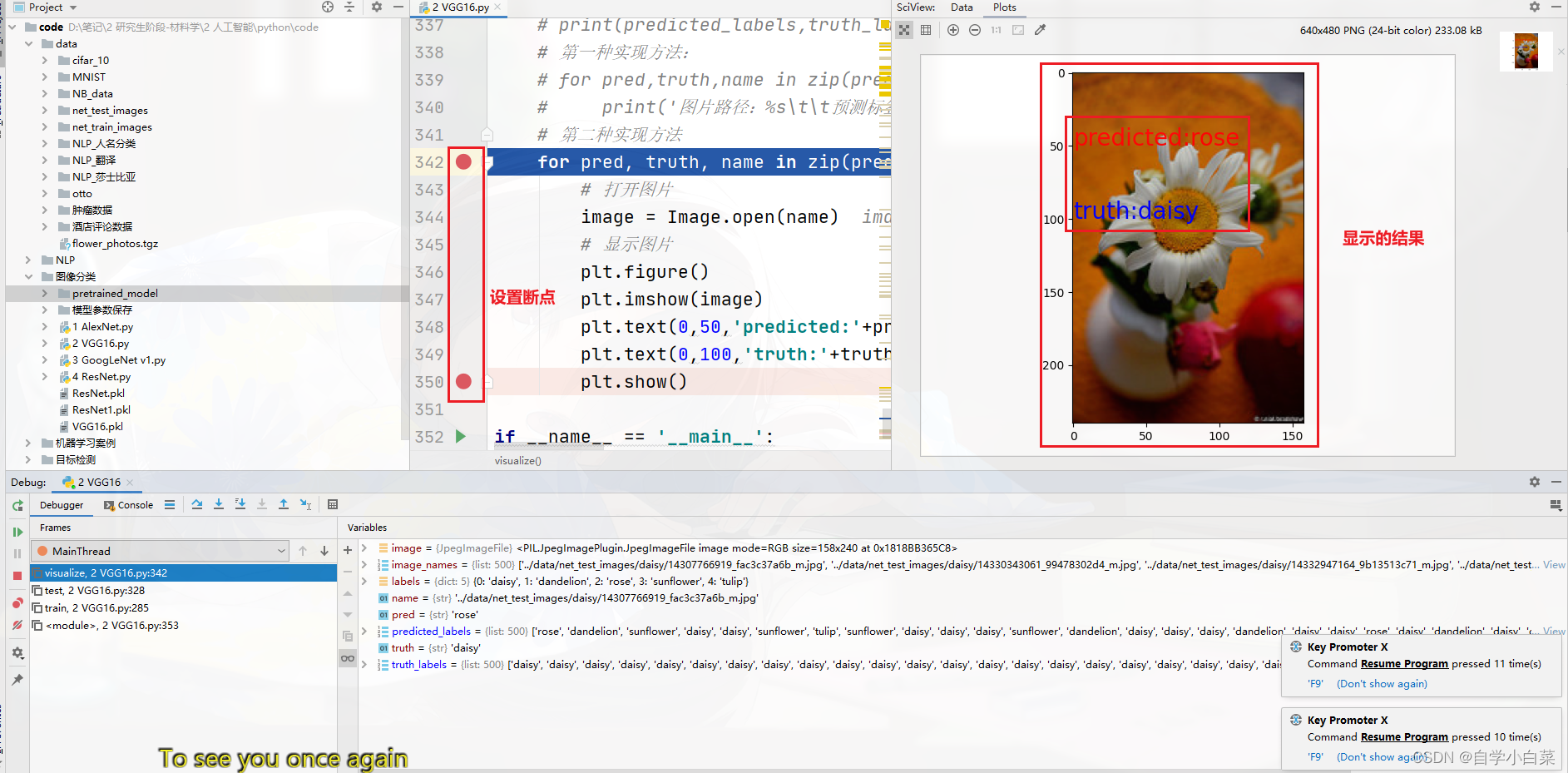
可视化完整代码如下:
def visualize(predicted_labels,truth_labels,image_names): # 真实标签,用字典存储 labels = {0:'daisy',1:'dandelion',2:'rose',3:'sunflower',4:'tulip'} # 转换 predicted_labels = [labels[i] for i in predicted_labels] truth_labels = [labels[i] for i in truth_labels] # 打印看看结果 # print(predicted_labels,truth_labels) # 第一种实现方法: # for pred,truth,name in zip(predicted_labels,truth_labels,image_names): # print('图片路径:%s\t\t预测标签值:%s\t\t真实标签值:%s' % (name,pred,truth)) # 第二种实现方法 for pred, truth, name in zip(predicted_labels, truth_labels, image_names): # 打开图片 image = Image.open(name) # 显示图片 plt.figure() plt.imshow(image) plt.text(0,50,'predicted:'+pred,color='red',fontsize=20) # 前两个值制定显示的位置,第三个值显示的内容,后面的为颜色和字体大小参数 plt.text(0,100,'truth:'+truth,color='blue',fontsize=20) plt.show() **说明:**上面的可视化其实比较粗糙,主要还是向那位朋友传达一下实现思路,更细、更好的方式可以自己再去探索探索,thanks。