内容导读
人脸识别也遇到坑了,识别得了三次元,却对二次元无效。迪士尼的技术团队,正在开发这一算法,以帮助动画制作者进行后期搜索。团队利用 PyTorch,效率得到很大的提高。
本文由公众号 PyTorch 开发者社区 编译整理发布
说到动画,不得不提起自 1923 年就成立的商业帝国迪士尼,以动画起家的迪士尼,至今引领着全球动画电影的发展。
每一部动画电影的背后,都凝结了数百人的心血与汗水。自第一部电脑3D动画《玩具总动员》的上映,迪士尼就开启了数字化动画创作的征程。随着 CGI、AI 技术的发展,迪士尼动画电影的制作、存档等方式也发生了极大的变化。
火遍全球的《疯狂动物城》历时五年制作完成
目前,迪士尼也吸收了一大批计算机科学家,他们正在用最前沿的技术,改变内容创作的方式,减轻电影幕后制作者的负担。
百年电影巨头,如何进行数字化内容管理
据了解,在华特迪士尼动画工作室中,大约有来自 25 个不同国家的 800 多名员工,包括艺术家、导演、编剧、制片人以及技术团队。
制作一部电影,需要经历从灵感产生,到故事大纲撰写,再到剧本拟定,美术设计,人物设计,配音,动画效果,特效制作,剪辑,后期等诸多复杂流程。
截至 2021 年 3 月,仅专业制作动画电影的华特迪士尼动画工作室已制作并上映了 59 部长篇动画,这些电影中的动画形象加起来就有成百上千个。

历史动画角色的相关素材数据,会在续集、彩蛋、参考设计时被高频使用
动画师在进行续集制作、或想参考某一角色时,需要在海量的内容档案库中,寻找特定角色、场景或物体。为此,他们往往需要花费数小时来观看视频,纯靠肉眼从中筛选自己需要的片段。
为了解决这个问题,迪士尼从 2016 年起,就开始了一项叫做**「Content Genome」**的 AI 项目,旨在创建迪士尼数字内容档案,帮助动画制作者快速、准确地识别动画中的面部(无论是人物或是什么物体)。
训练动画专用人脸识别算法
数字化内容库的第一步,是将过往作品中的内容进行检测与标记,方便制作者以及用户搜索。
人脸识别技术已经比较成熟,但是,同一套方法,能否用于动画中的面部识别呢?
Content Genome 技术团队进行试验之后,发现只在某些情况下可行。
他们选取《阿瓦勒公主埃琳娜》和《小狮王守护队》两部动画电影作品,手动注释了一些样本,用正方形标出数百帧影片中的面孔。通过该手动注释数据集,团队验证了基于 HOG + SVM pipeline 的人脸识别技术,在动画面孔(尤其是类人脸和动物面孔)中的表现不佳。

手动标注出动画形象的面部
团队分析后确认,像 HOG + SVM 这样的方法对于颜色,亮度或纹理变化具有鲁棒性,但所使用的模型只能匹配具有人类比例的动画角色(即两只眼睛,一只鼻子和一张嘴)。
此外,由于动画内容的背景通常具有平坦的区域和很少的细节,所以,Faster-RCNN 模型会错误地把简单背景下脱颖而出的所有事物,都认作是动画面孔。
 《汽车总动员》中,两位「赛车」主角较为抽象的面部,就无法用传统的人脸识别技术进行检测与识别
《汽车总动员》中,两位「赛车」主角较为抽象的面部,就无法用传统的人脸识别技术进行检测与识别
因此,团队认为他们需要一种能够学习更抽象的人脸概念的技术。
团队选择用 PyTorch 训练模型。团队介绍道,通过 PyTorch,他们可以访问最先进的预训练模型,满足其训练需求,并使归档过程更高效。
训练过程中,团队发现,他们的数据集中,正样本是足够的,却没有充足的负样本来训练模型。他们决定使用不包含动画面孔、但具有动画特征的其他图像,来增加初始数据集。
在技术上为了做到这一点, 他们扩展了 Torchvision 的 Faster-RCNN 实现,以允许在训练过程中加载负样本而无需注释。
这也是团队在 Torchvision 核心开发人员的引导下,为 Torchvision 0.6 做出的一项新功能。在数据集中添加负样本示例,可以在推理时大大减少误报,从而得到出色的结果。
用 PyTorch 处理视频,效率提升 10 倍
实现动画形象的面部识别之后,团队的下一个目标是加快视频分析流程,而应用 PyTorch 能够有效并行化并加速其他任务。
团队介绍道,读取和解码视频也很耗时,因此团队使用自定义的 PyTorch IterableDataset,与 PyTorch 的 DataLoader 结合使用,允许使用并行 CPU 读取视频的不同部分。
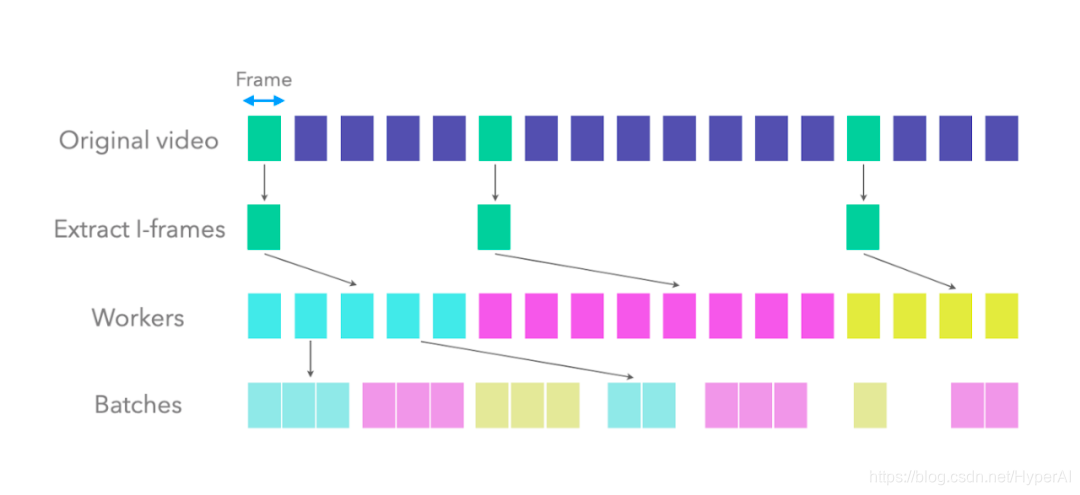 视频被提取的 I-frames,被分割成不同的块(chunks),每个 CPU worker 读取不同的块
视频被提取的 I-frames,被分割成不同的块(chunks),每个 CPU worker 读取不同的块
这样的读取视频方式已经非常快了,不过团队还尝试只通过一次读取就完成所有计算。于是,他们在 PyTorch 中执行了大部分 pipeline,并考虑了 GPU 的执行。每一帧只发送给 GPU 一次,然后将所有算法应用到每一个 batch 上,将 CPU 和 GPU 之间的通信减少到最小。
团队还使用 PyTorch 来实现更传统的算法,如镜头检测器,它不使用神经网络,主要执行颜色空间变化、直方图和奇异值分解(SVD)等操作。PyTorch 使得团队能以最小的成本将计算转移到 GPU,并轻松回收多个算法之间共享的中间结果。
通过使用 PyTorch,团队将 CPU 部分转移到 GPU 上,并使用 DataLoader 加速视频阅读,充分利用硬件,最终将处理时间缩短了 10 倍。
团队的开发者总结道,PyTorch 的核心组件,如 IterableDataset,DataLoader 和 Torchvision,都让团队得以在生产环境中提高数据加载和算法效率,从推理到模型训练资源到完整的 pipeline 优化工具集,团队都越来越多地选择使用 PyTorch。