本文是对文章《Unsupervised Learning of Depth and Ego-Motion from Video》的解读。

Figure 1. 深度图和Ground-Truth [1]
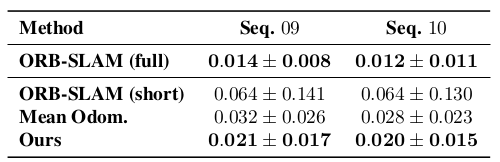
Figure 2. Absolute Trajectory Error(ATE) on KITTI dataset [1]
1. 概述
1.1为什么要讲这篇文章?
在无人驾驶、3D重建和AR三个领域中,对于周围环境物体的深度(Depth)和对自身位置的估计(State Estimation)一直是一个非常棘手而复杂的问题。
过去常用的方法,传统的SLAM,通常用非常繁琐的数学公式和基于特征点/直接法的方法来进行轨迹估算,而深度通常用单目视觉(多态几何),双目视觉,激光雷达来进行估计。
但传统方法通常只能进行稀疏的特征点(Features),进行深度估计和自身姿态估计,而不能利用所有pixel,而这对于自动驾驶领域中重建高精地图和AR领域中的室内环境感知来说就会导致信息的缺失。
1.2 这篇文章提出了什么新方法?
这篇文章主要提出了一种基于无监督深度学习的单目视觉的深度和自身运动轨迹估计的深度神经模型。
它的新颖之处在于:
-
提出了一种堪称经典的:depth network和ego-motion network共同训练的架构模式。(因此这篇文章可以说是最2年基于深度学习的depth estimation的祖师爷,Google和Toyota的最新论文都借鉴了它的训练模式)
-
无监督学习:只需任意单目相机的视频就可以学习其深度和轨迹信息。
-
同时追踪所有像素点,不丢失任何场景信息。
-
深度估计比肩传统SLAM,自身轨迹估计优于传统SLAM。
它在工程之中的应用价值:
-
高境地图重建(自动驾驶车,移动机器人)
-
3D视觉效果重建
-
AR/VR定位
2. 文章核心
简单来说,这篇文章的核心就是下图中的两个深度卷积网络CNN,Depth CNN和Pose CNN绑定在一起通过View Synthesis进行训练。
具体来说,通过把Target Image (It )中每一个pixel都按下图的公式给warp到Source Image ( I t − 1 或 I t + 1 )中,计算Pixel-Wise的intensity error:
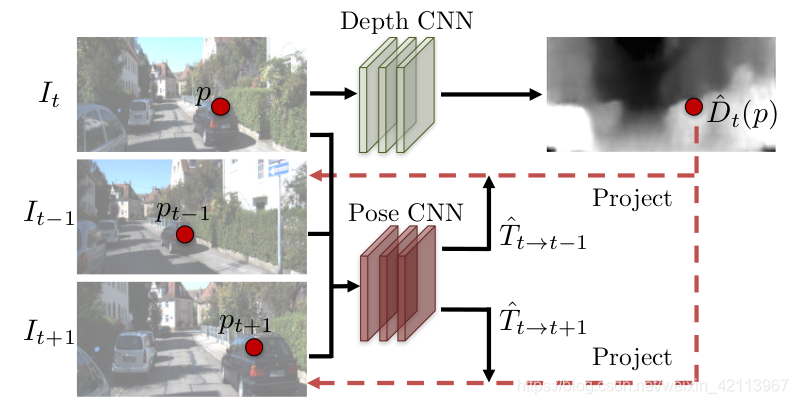
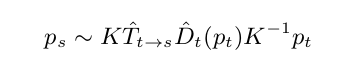
Figure 3. Depth/Pose nNtwork共同训练的模式 [1]
-
大师兄:看到这里,俺老孙就想到了当年GAN生成对抗网络,也是两个Network捆绑在一起进行训练。
-
师傅:是的徒儿,这篇文章就是把Depth和Pose的Output合并在一起计算Loss。具体细节请听为师娓娓道来~
2.1 View Synthesis与误差函数的构建
众所周知,深度学习模型的关键就是Loss function,它类似于传统SLAM中的最小二乘法问题,都是要寻找到一个全局最小残差,从而使得模型最能够接近于最优解。
本文的Loss function用到了一个很强的假设:
-
假设:已有 t t t时刻图像target image和每个像素对应的深度, 以及target image相对上一 ( t − 1 ) (t-1) (t−1)时刻图像source帧相机位置的T。(transfomration matrix)
-
结论:若D, T均是正确完美的数值,则必定可以准确地将targe image每一个像素点 p t对应warp到上一帧source image中的 p s 位置。
这么说可能有些抽象,打个比方: “ t t t时刻图像有一个艾菲尔铁塔的尖尖,经过Depth和T的warp变换后,我们可以得到上一 ( t − 1 ) (t-1) (t−1)时刻在另一个角度拍摄的艾菲尔铁塔的尖尖的pixel位置,那么它们两个点图像的亮度 (intensity) 应该是一样的”。
有了这个假设以后,我们的Loss就可以设为pixel intensity ( I I I)的差值之和:
![]()
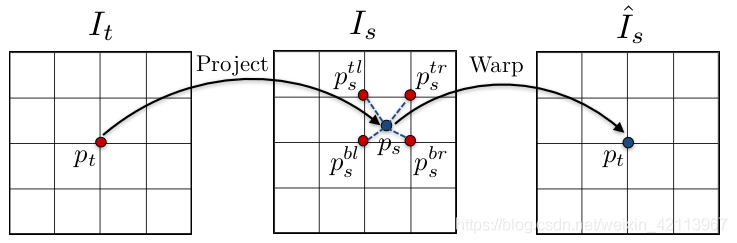
Figure 4. Warping [1]
2.2 Warping的数学模型
在上一节中使用的warping公式,具体含义如下:
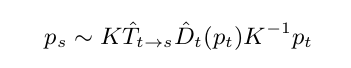
p s : pixel in source image
p t : pixel in target image
K : camera intrinsics matrix
D ^ t : Depth of a point, at time t t t
T ^ t − > s : Transformation matrix from target image to source image
除此以外,为了让该公式能够被神经网络训练,求出D和T,我们必须让它可求导 (differentiable)。
本文的做法是采用Spatial Transformer Networks [2]文章中的双线性插值法 (biliner interpoltion),具体原理如下:

Figure 5. bilinear interpoltion [2]
2.3 Explainability Mask & Regularization
2.1节中的监督模型有一个很强的假设,但现实世界;总是不尽如人意的,有以下三种特殊情况会打破之前的假设:
-
场景中有移动物体
-
前后两帧之家出现不连续性,如有物体被遮挡
-
Surface不符合Lambertian规律(不是理想散射)
因此,本文引入了一个Explainability Mask Network ( E ^ s (⋅))来“马赛克”移动物体,遮挡物体和不符合理想散射的平面。
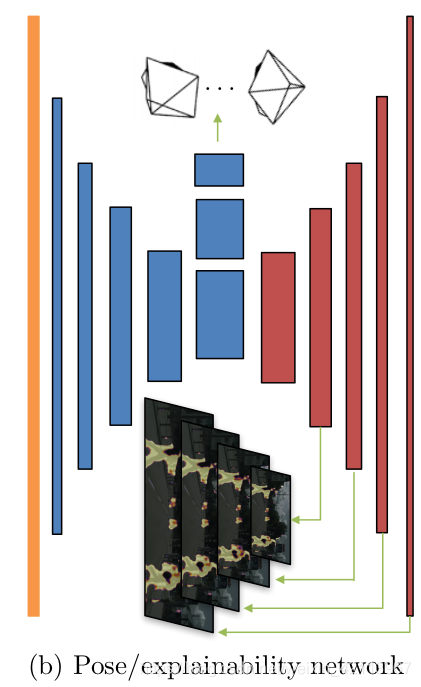
Figure 6. Explainability Mask Network [1]
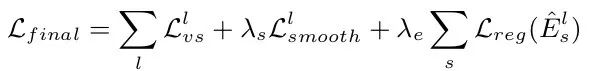
除此以外,由于low-texture region和far from current estimation的缘故,我们在训练模型时容易进入gradient locality (梯度局部性),简单来说就是“训练不动了”。加入regularization因子可以有效地解决这点,最终我们可以得到一个loss function:
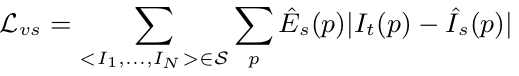
2.4 Network Architecture
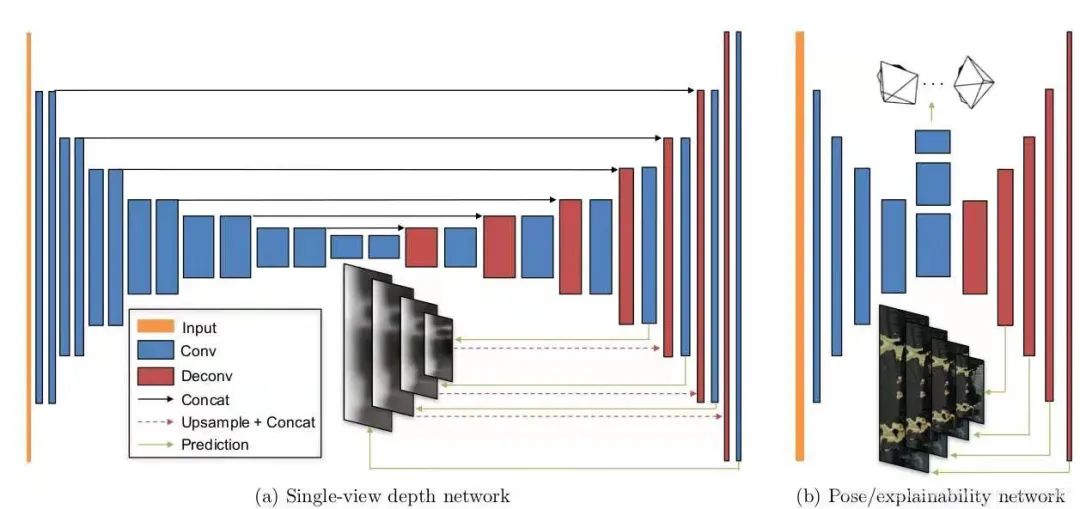
Figure 7. Network Architecture [1]
注:本文采用了multi-scale side predictions,在四个layer的位置,生成了四张不同清晰度的predictions,具体效果估计是让Loss更robust,对不同大小和清晰度的图像都能兼容吧(个人观点~)
3. Conclusion
总的来说,本文使用Unsupervised Learning获得的Depth和Trajectory的效果均获得了不逊色于传统SLAM和基于Supervised-Learning的Depth Estimation的结果。并且,本文对于Trajectory估计的效果还要更胜一筹。
在实际工程中,基于深度学习得到的Depth和Ego-Motion可直接用于vSLAM或者3D reconstruction,并且可以实现全像素的追踪,这一点和基于几十几百个稀疏的feature pixels的传统SLAM是一个巨大的优势。
因为它可以获得更加稳定的Depth/Motion Estimation,并且可以拓展到鱼眼摄像头、全景摄像头等不规则相机的SLAM。
(因为目前自动驾驶通常会使用鱼眼相机来保证360度的周围环境感知和深度测量,能够通过文章[3] [4]来拓展本文的pin-hole方法,到Fisheye)
3.1 基于本文的拓展: Google AI 2019论文
在本文所介绍的[1]中,训练集是一个非常头疼的问题。海量的数据就是模型准确度提升的关键,但是网上存在的很多Wild Videos连相机模型都不一定有,更不用说内参了。
Google 2019年的这篇论文[4]名为"Depth from videos in the wild",顾名思义,它基于[1]所作出的改进就是在不需要已知Camera Instrinsics的情况下,可以同时估计Depth和Intrinsics。
3.2 基于本文的拓展: Toyota 2020论文
在本文所介绍的[1]中,只有针孔相机模型的intrinsics matrix是可以估计的,而其他Fisheye或者catadioptric相机由于intrinsics matrix的模型都不一样。
(有各种radial distortion模型,所需的参数数量都不一样)。
Toyota 2020的这篇论文[2]就在上两篇论文的基础上,记入了对所有相机类型的支持。
它不使用任何analytical (解析)模型,而是用network直接自己学习2D pixel 到 3D point的projection公式,因而不需要一个预设的,要估计的内参模型。

Figure 8. Toyota的最新论文基于本文的方法拓展到了所有异型相机的Depth Estimation [3]
4. Appendix
4.1 Experiment on Cityscapes and KITTI

Figure 9. Depth Prediction Results [1]
4.2 Experiment on NYU depth and KITTI

Figure 10. Depth Prediction Results [1]
4.3 Experiment on KITTI for Trajectory
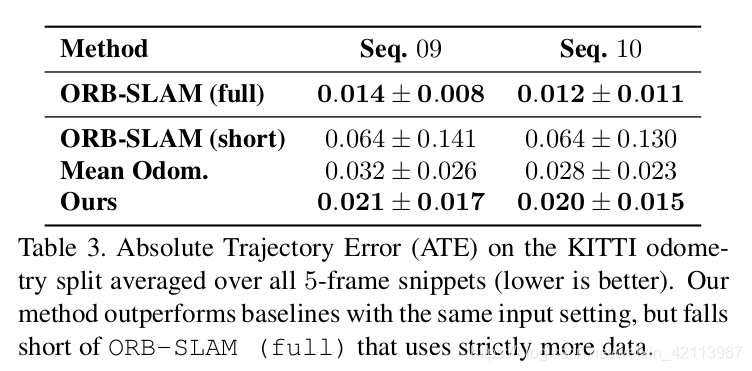
Figure 11. Ego-Motion Prediction Results [1]
Reference:
[1] T. Zhou, M. Brown, N. Snavely and D. G. Lowe, “Unsupervised Learning of Depth and Ego-Motion from Video,” 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 2017, pp. 6612-6619, doi: 10.1109/CVPR.2017.700.
[2] M. Jaderberg, K. Simonyan, A. Zisserman, et al. Spatial transformer networks. In Advances in Neural Information Processing Systems, pages 2017–2025, 2015.
[3] Vasiljevic, Igor & Guizilini, Vitor & Ambrus, Rares & Pillai, Sudeep & Burgard, Wolfram & Shakhnarovich, Greg & Gaidon, Adrien. (2020). Neural Ray Surfaces for Self-Supervised Learning of Depth and Ego-motion. 1-11. 10.1109/3DV50981.2020.00010.
[4] A. Gordon, H. Li, R. Jonschkowski and A. Angelova, “Depth From Videos in the Wild: Unsupervised Monocular Depth Learning From Unknown Cameras,” 2019 IEEE/CVF International Conference on Computer Vision (ICCV), 2019, pp. 8976-8985, doi: 10.1109/ICCV.2019.00907.
作者介绍:夏唯桁,柏林工业大学硕士研究生,主要研究方向为自动驾驶和移动机器人的SLAM及运动规划。目前在法国雷诺集团担任自动驾驶SLAM算法实习生。