Stable Diffusion是2022年发布的深度学习文本到图像生成模型。它主要用于根据文本的描述生成详细图像,它也可以应用于其他任务,如内补绘制、外补绘制,以及在提示词(英语)指导下产生图生图的翻译。详细介绍看维基百科词条Stable Diffusion。
去年刚出的时候搭建门槛很高,对Mac用户极度劝退。后来有大佬开源了stable-diffusion-webui,把搭建难度从地狱模式降到了新手模式,让更多Mac用户也能玩AI绘图了。
我用的32G内存M1 Max玩了几天,总结一下经验。搭建Stable Diffusion对机器配置要求还是挺高的,主要是内存和显卡,这两个决定了生成图片的数量、尺寸、效果。16G内存可以简单玩玩,生成图片稍大一点内存就会飙到20多G,交换内存(swap)用到10G左右,玩这个的时候基本上别的都干不了。m1的8核显存生成最基础的512x512图片,出图速度大约2-3分钟一张;512x768稍复杂一点的图片就奔着10分钟去了。网友分享的64核显卡的M1 Ultra生成最基础的512*512图片出图速度约10秒一张。图片尺寸越大生成时间越长。
所以我建议机器配置内存16G起步,8G也能玩但体验很坐牢。M1/M2最基础的显卡就能玩。因为要下载很多模型,硬盘剩余空间建议20G起步,可以安装到移动硬盘里。
下面将介绍如何在M1 Mac上部署Stable Diffusion WebUI,以及部署ControlNet实现骨骼绑定、临摹、填色等玩法。
项目地址:
Installation on Apple Silicon:stable-diffusion-webui
sd-webui-controlnet:sd-webui-controlnet
安装 stable-diffusion-webui
安装Homebrew
打开终端,输入:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)" 安装Python
装完Homebrew后,重新打开终端,输入:
brew install cmake protobuf rust python@3.10 git wget 下载项目
终端进入你想存放的目录,输入:
# 我放在硬动硬盘里 cd /Volumes/MobileDisk # 下载 git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui 下载完成后去你目录里可以看到stable-diffusion-webui。
下载模型
首先了解一下模型存放路径。
基本模型比较大,每个都是几个G,放在 stable-diffusion-webui/models/Stable-diffusion
官方1.4和1.5模型,点击一个模型,然后点击 Files and versions 。寻找以.ckpt 或.safetensors为扩展名的文件,然后点击文件大小右边的向下箭头下载它们:
Stable DIffusion 1.4 (sd-v1-4.ckpt)
Stable Diffusion 1.5 (v1-5-pruned-emaonly.ckpt)
Stable Diffusion 1.5 Inpainting (sd-v1-5-inpainting.ckpt)
Stable Diffusion 2.0和2.1需要一个模型和一个配置文件,在生成图像时,图像宽度和高度需要设置为768或更高。
Stable Diffusion 2.0 (768-v-ema.ckpt)
Stable Diffusion 2.1 (v2-1_768-ema-pruned.ckpt)
lora模型通常只有一百兆左右,放在 stable-diffusion-webui/models/Lora
civitai.com有大量精美的模型和lora可以下载。现在还处于早期没有法律监管,新增的不少,删除的也不少,喜欢的就下载别犹豫。
Civitai.com有大量18+内容。请自行甄别
运行项目
# 进到stable-diffusion-webui目录 cd /Volumes/MobileDisk/stable-diffusion-webui # 运行 ./webui.sh 当看到 Running on local URL: http://127.0.0.1:7860 时就可以打开http://127.0.0.1:7860 愉快的玩耍了。
关闭按两次 Control + C 或关掉终端窗口。
用法
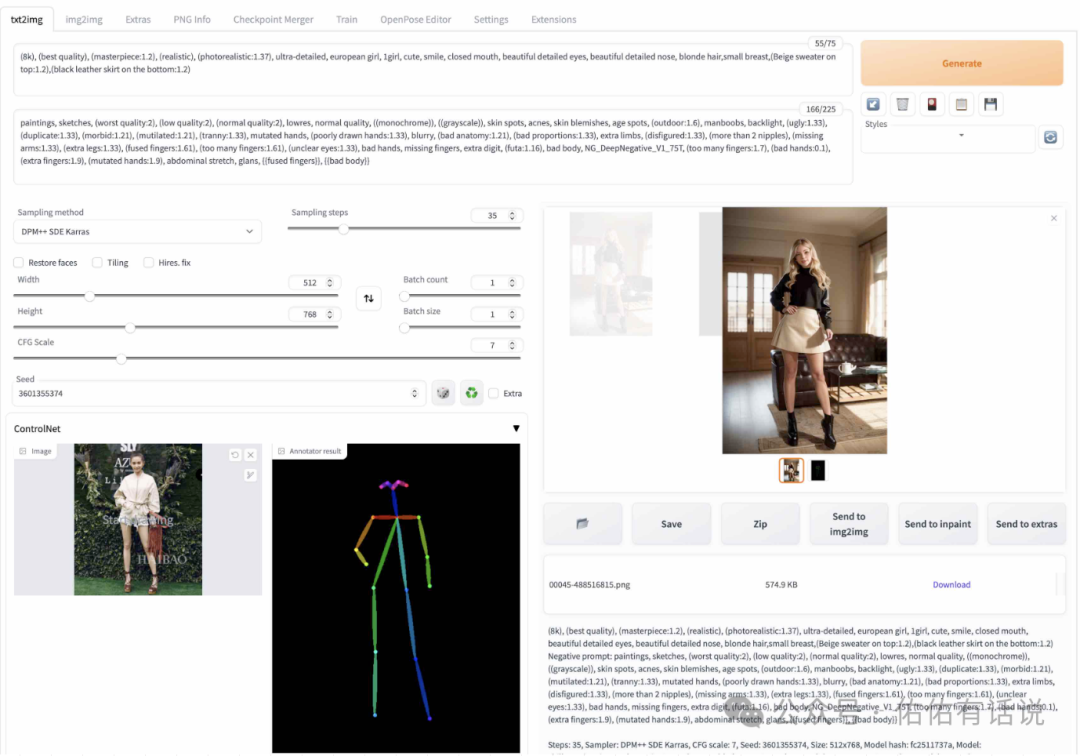
把下图标注的地方填上调好,点Generate生成图片。
最简单的方式是去civitai.com点开一张别人的图片,复制右边的参数自己生成一遍试试效果,注意图片是基于哪个模型。先模仿别人的写法,再修改一些地方看看效果,然后试着生成自己构思的图片。
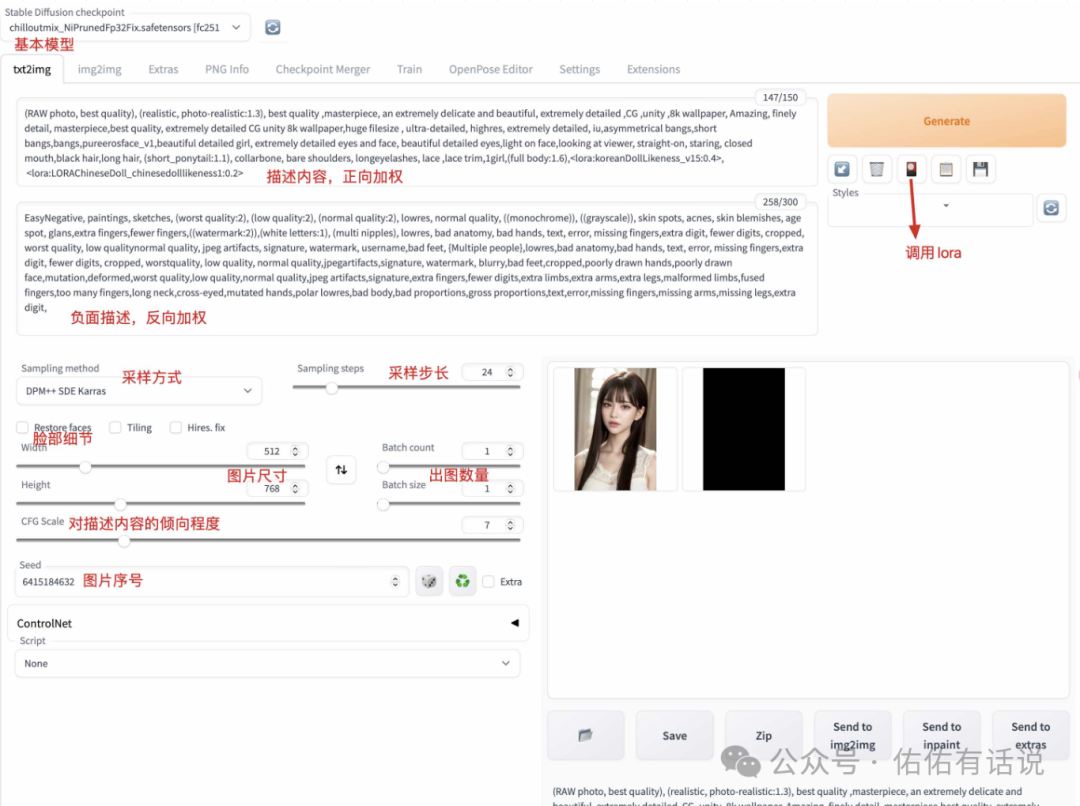
参数解释
Stable Diffusion checkpoint:基本模型,同一套参数用不同模型生成的效果差距非常大。切换的时候会加载,注意等加载完成。
Prompt:描述内容,即你想要的效果,用 , 分隔,不能用中文。(full body:1.6)表示full body占更高的权重。<lora:koreanDollLikeness_v15:0.4> 表示调用了lora模型,权重0.4。点图中位置再点 Lora 页签即可选择lora模型。
Negative prompt:负面描述,你不想要的效果。用来排除模型或生成结果中包含的元素。
Sampler:采样方式。
Steps:越大内容越丰富,也越吃机器配置。通常在20-40之间。
CFG scale:可以简单理解为AI对描述参数的倾向程度。
Seed:可以理解为图片编号。-1表示随机数,和别人用同一个数生成相似的图片的概率更大。
Restore faces:优化面部的,原理是调用一个神经网络模型对面部进行修复,影响面部。除非脸部细节有问题一般不开,吃配置。
Tiling:是一种老牌优化技术,即CUDA的矩阵乘法优化,影响出图速度和降低显存消耗,不过实际选上之后可能连正常的图都不出来了。一般不开。
Highres.fix:这个也是和上面的一样,都是一种优化技术,其原理是先在内部出低分辩率的图,再放大添加细节之后再输出出来,影响出图的结果,可以在低采样步长的情况下达到高采样步长的效果,但是如果采样步长过低(例如小于12)或者过高(例如高于100)以及长宽太小(例如小于128)效果则不尽人意,这个也有一个Denoising strength,只不过这个Denoising strength影响的只是内部的那个低分辨图,如果只是初次生成一张图这个可以不管,不过如果预设种子和参数一致的话这个就会对生成的图造成影响,也就是图会发生变化而不是原图更为精细。吃配置,一般不开。
部署 sd-webui-controlnet
不想玩骨骼绑定、临摹、填色的可以跳过这部分。
安装 controlnet
sd-webui-controlnet 是基于 stable-diffusion-webui 的一个扩展。
先运行stable-diffusion-webui,在页面里点Extensions选项,在标签中打开Install from URL标签,在URL for extension's git repository中输入该仓库的URL,点Install按钮。重新加载/重启WebUI。
网络不好的也可以在github下载后放到stable-diffusion-webui/extensions下面。
安装成功后stable-diffusion-webui页面下方会多出一个可展开的 ControlNet 。
下载模型
打开huggingface.co,点击 Files and versions 。寻找以.pth为扩展名的文件,然后点击文件大小右边的向下箭头下载它们。模型下好后放在stable-diffusion-webui/extensions/sd-webui-controlnet/models下面。
模型作用
openpose用于提取人物骨骼;normal提取模型效果;其它都差不多一个效果略有不同,都是从图片提取线稿生成中间图,然后再给中间图上色生成图片。
control_any3_canny.pth:这个模型可能是使用Canny边缘检测算法进行训练的,可以用于检测图像的边缘。先生成线稿中间图,再按中间图上色生成图片。适合转化人物。
control_any3_depth.pth:这个模型可能是使用深度学习技术进行训练的,可以用于提取图像的深度信息。具有景深效果,和canny类似用法,建筑人物皆可使用。
control_any3_hed.pth:这个模型可能是使用HED(Holistically-Nested Edge Detection)边缘检测算法进行训练的,可以用于检测图像的边缘。和canny类似,比较适合人物。
control-any3_mlsd.pth:这个模型可能是使用MLS(Moving Least Squares)Deformation方法进行训练的,可以用于对图像进行形变或扭曲操作。和canny类似,适合转化建筑图片。
control-any3_normal.pth:这个模型可能是使用深度学习技术进行训练的,可以用于提取图像的法线信息。根据给的底图,生成一个类似建模效果(法线贴图)的中间图,再生成图片。非常适合使用人物建模,生成人物和建筑皆可,但显然是更适合人物的。
control_any3_openpose.pth:这个模型可能是使用OpenPose姿态估计算法进行训练的,可以用于对人体姿态进行调整。提取骨骼用真人图片最好。
control_-any3_scribble.pth:这个模型可能是使用半监督学习中的”scribble”技术进行训练的,可以用于对图像进行语义分割。和canny类似用法
control_any3_seg.pth:这个模型可能是使用深度学习技术进行训练的,可以用于对图像进行语义分割。
用法
先运行stable-diffusion-webui,按下图指示顺序来。小内存机器可以勾上 Low VRAM 。
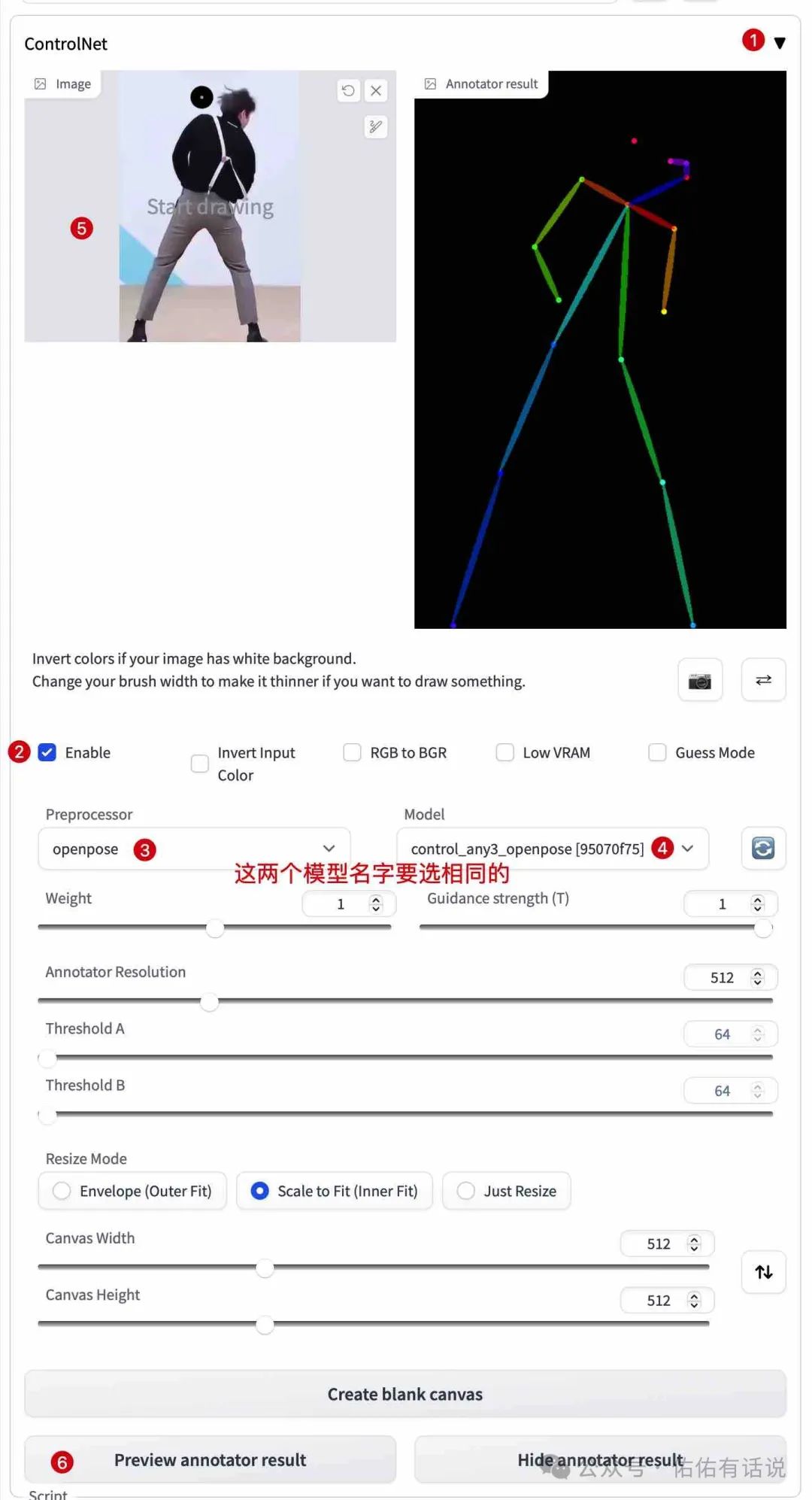
然后就可以生成图片了。上面用图片提取的是个背影且姿势太夸张,骨骼头部已经乱掉了,会生成一张失败的图片。
另一种方式是用 OpenPose Editor 插件编辑骨骼发送到txt2img。Openpose Editor 也是一个插件,安装方式和安装 ControlNet 一样。
「注意」:使用 Openpose Editor 时注意不要给 ConrtolNet 的 “Preprocessor” 选项指定任何值,请保持在none状态。
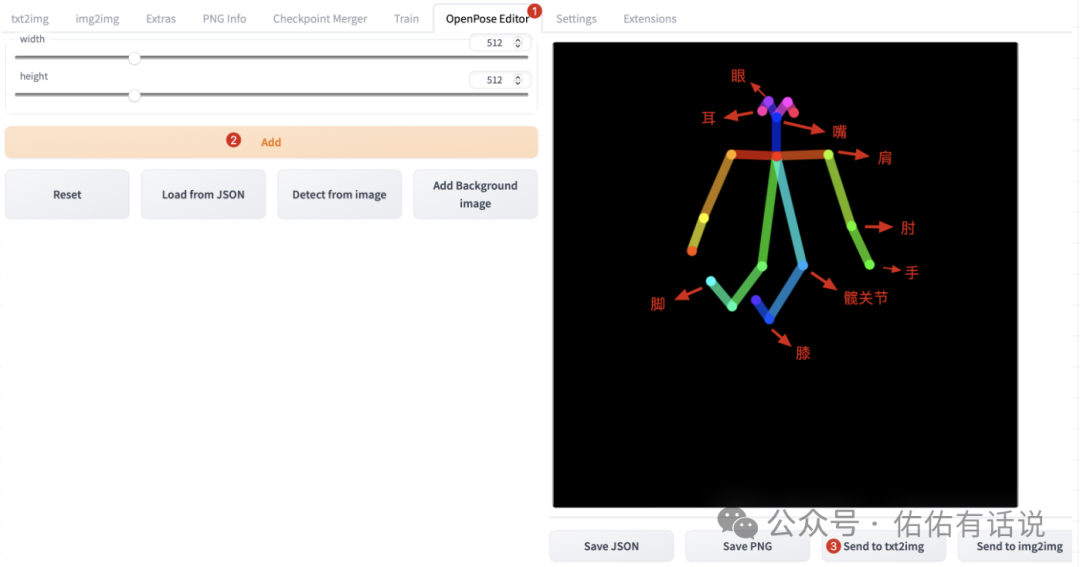
实际上生成精细人物图片对骨骼位置要求很高,尤其是头部,很容易生成畸形人物图片。最好使用真人图片提取骨骼,动漫的人物比例相较于真人比较夸张。注意你的Prompt、图片尺寸跟controlnet骨骼是否有冲突,以免生成失败的图片。
下图是用control_any3_depth.pth提取动漫人物轮廓生成的图片。
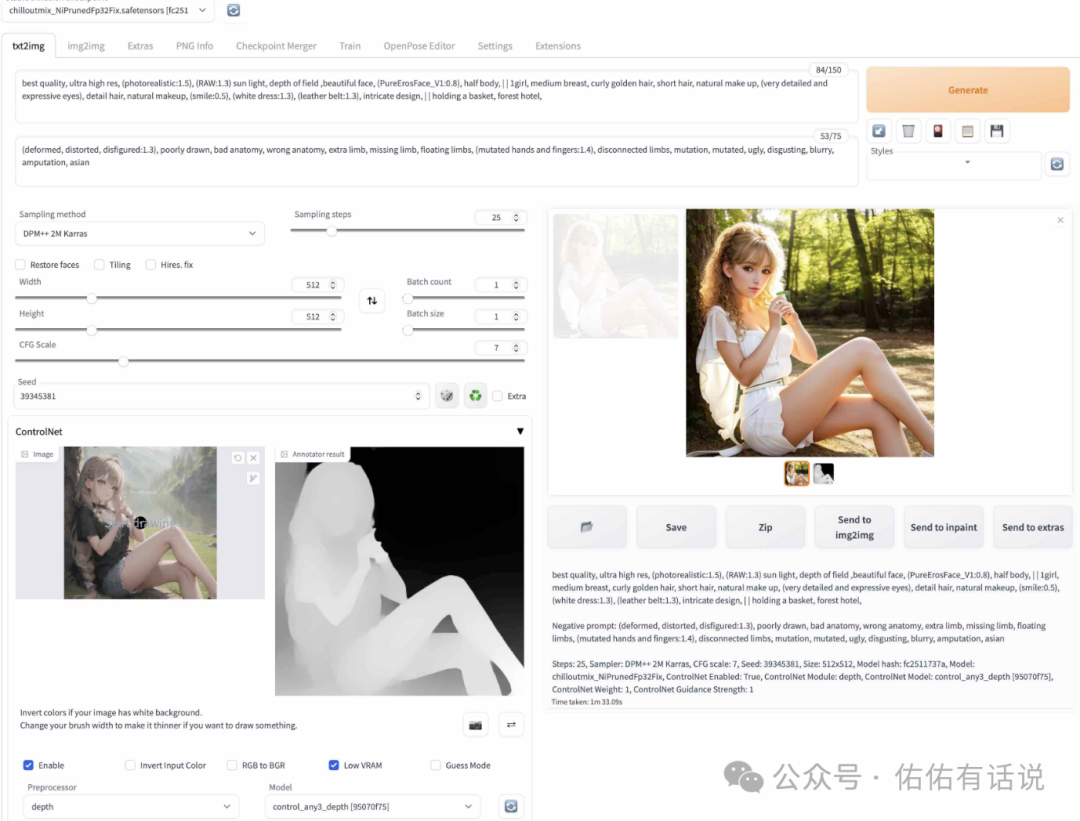
下图是用control_any3_openpose.pth提取人物骨骼生成的图片。
control-any3_normal.pth我机器报错用不了,提示显卡不支持。
AI不会画手,只靠Prompt很难画好。有人用Blender建了手部模型来解决这个问题。
还可以通过建模来渲染图片。
还有更高级的用法,将真人视频转换成动漫视频。原理是将每一帧生成一张图片,再组合成一段视频。例如你想生成一段1分钟每秒60帧的视频,那么需要生成3600张图片。非常吃机器配置且非常耗时。
写在最后
感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。

AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。
一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。
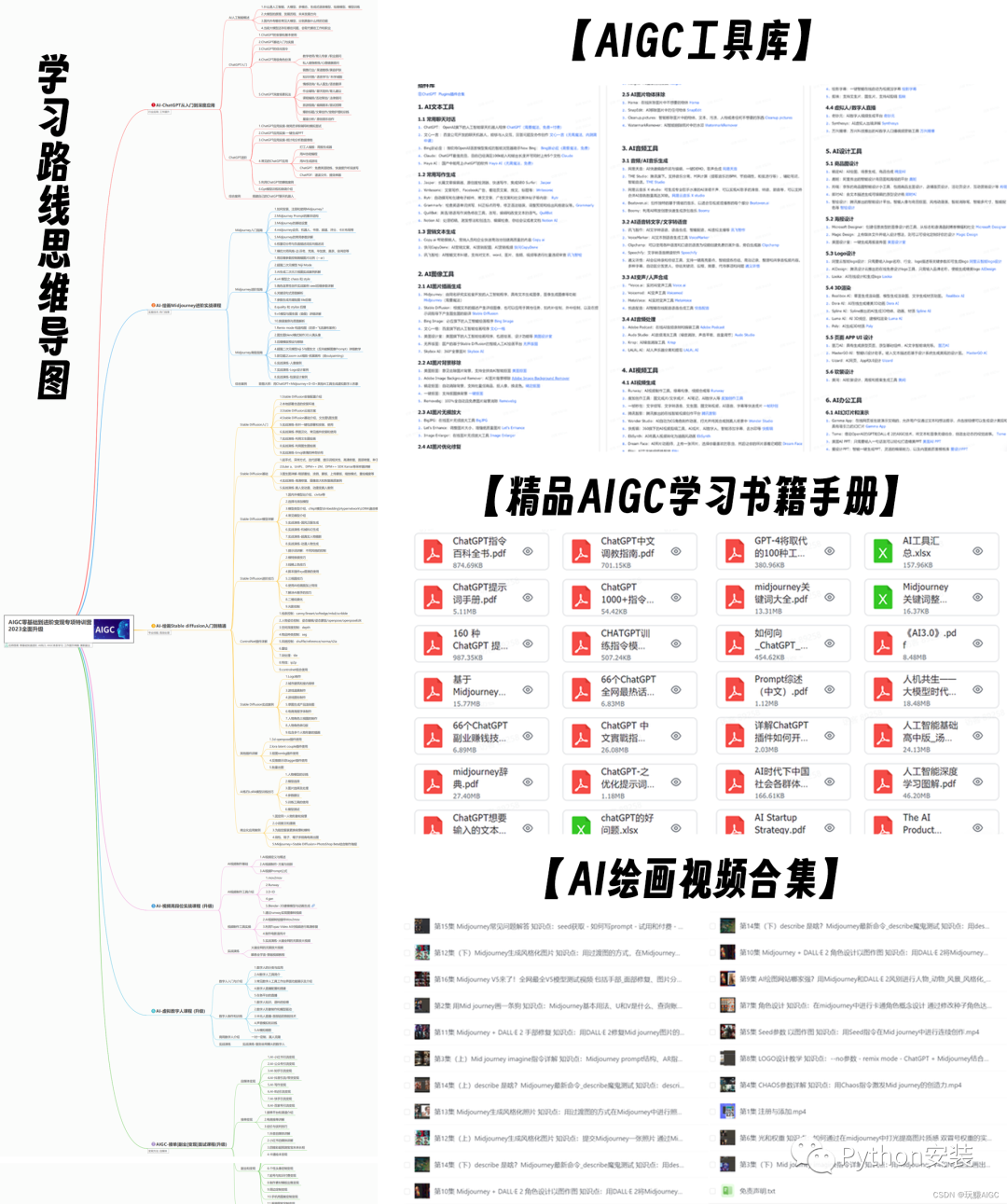
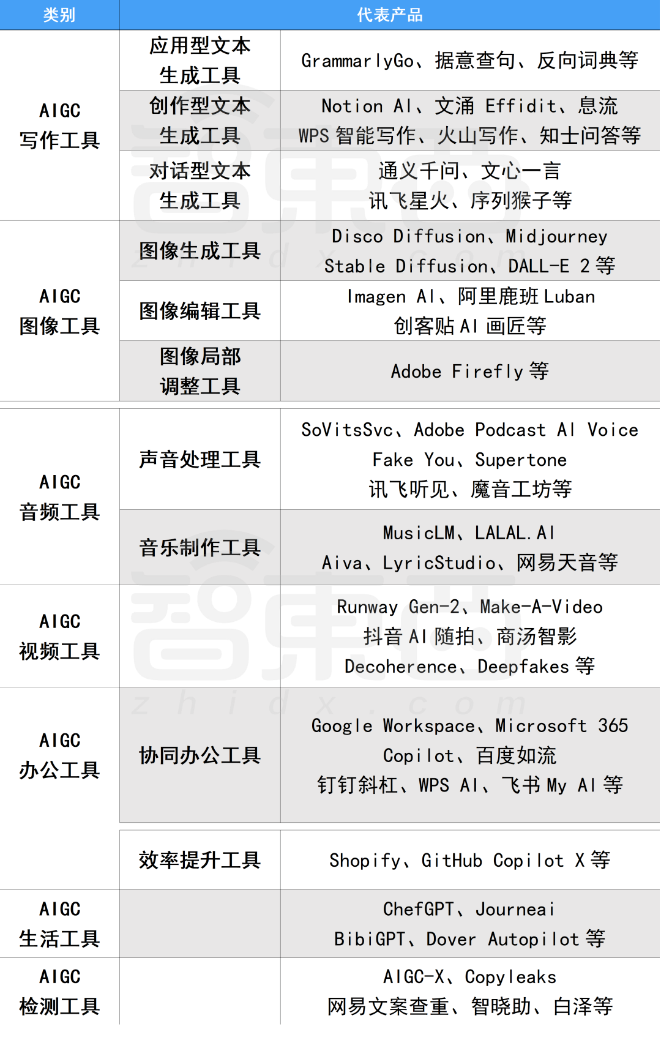
二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!
三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

若有侵权,请联系删除