经过 Seal 研发团队几个月来持续的开发和测试,我们满怀期待及热情地发布新的产品 GPUStack,GPUStack 是一个用于运行LLM(大型语言模型)的开源GPU集群管理器。尽管如今大语言模型作为公共的云上服务已经被广泛推广并在公有云上变得更加易于使用,但对企业来说,部署托管自己私有的 LLM 供企业和组织在私有环境使用仍然非常复杂。
首先,企业需要安装和管理复杂的集群软件,如 Kubernetes,然后还需要研究清楚如何在上层安装和管理 AI 相关的工具栈。而目前流行的能在本地环境运行 LLM 的方法,如 LMStudio 和 LocalAI,却大都只支持在单台机器上运行,而没有提供多节点复杂集群环境的支持能力。
GPUStack 支持基于任何品牌的异构 GPU 构建统一管理的算力集群,无论目标 GPU 运行在 Apple Mac、Windows PC 还是 Linux 服务器上, GPUStack 都能统一纳管并形成统一算力集群。GPUStack 管理员可以从诸如 Hugging Face 等流行的大语言模型仓库中轻松部署任意 LLM。进而,开发人员则可以像访问 OpenAI 或 Microsoft Azure 等供应商提供的公有 LLM 服务的 API 一样,非常简便地调用 OpenAI 兼容的 API 访问部署就绪的私有 LLM。
有关 GPUStack 的更多详细信息,可以访问:
GitHub 仓库地址: https://github.com/gpustack/gpustack
GPUStack 用户文档: https://docs.gpustack.ai
发布背景
当前,企业如果想要在 GPU 集群上托管大模型,必须要做大量的工作来集成复杂的技术栈。通过使用 GPUStack,企业不再需要担心如何管理 GPU 集群、推理引擎和推理加速、租户和配额管理、使用和计量、性能度量、统一认证授权和访问控制,以及仪表板。
如下图所示,GPUStack 是一个构建企业私有的大模型即服务(LLMaaS)的完整平台,拥有构建大模型即服务所需的各项功能。管理员可以将模型从 Hugging Face 等模型仓库部署到 GPUStack 中,然后开发人员可以连接到 GPUStack 提供的私有大模型 API,在他们的应用中集成和使用私有大模型服务。
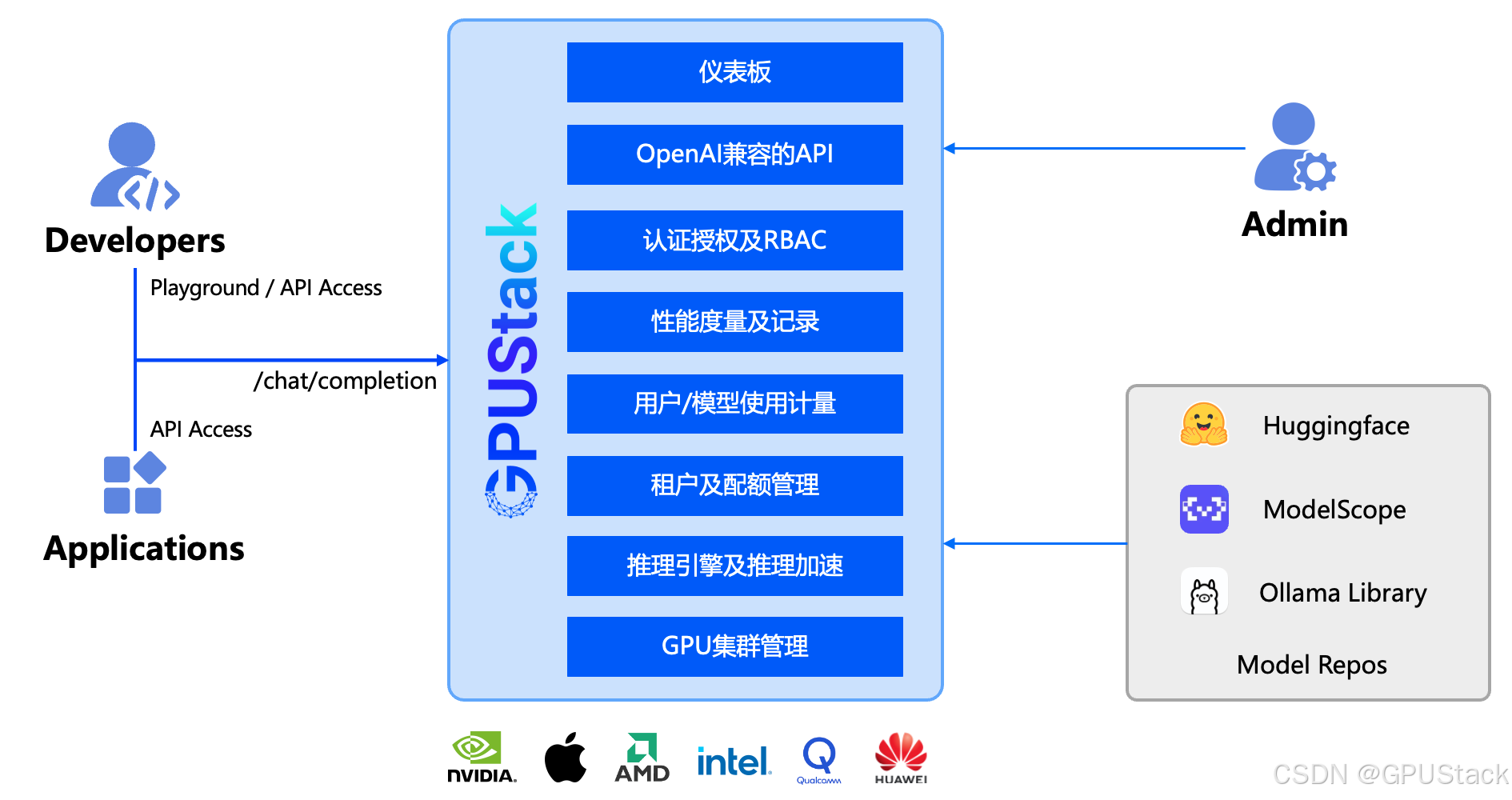
“随着大语言模型能力的逐渐提高,企业和组织一方面对快速进入 AI 时代充满了信心并满怀期待,希望大语言模型能尽快为自己的企业和组织带来生产效能的提高,而另一方面,对于能否有效地把如火如荼的大语言模型技术进一步与实际业务进行有机结合,是否能因此产生相应的效益,企业及团队又同时充满了疑问。我们希望通过简单易用的 GPUStack 平台,部署和运行各种开源大语言模型,提供 OpenAI 兼容的 API 接口,使得开发人员简单方便地访问任何的 LLM。” Seal 联合创始人及 CEO 秦小康介绍道,“最重要的是,我们支持 Nvidia,Intel,AMD 及众多品牌的 GPU,在支持异构 GPU 集群的同时能为企业节省更多成本。帮助企业简单快速地开启 LLM 创新是 GPUStack 团队的初心和使命。”
GPUStack 核心功能
组建 GPU 集群整合资源
GPUStack 可以聚合集群内的所有 GPU 资源。它旨在支持所有的 GPU 厂商,包括英伟达,苹果,AMD,英特尔,高通,华为等。GPUStack 兼容运行 MacOS、Windows 和 Linux 操作系统的笔记本电脑、台式机、工作站和服务器。
在 GPUStack 的首个版本中,支持苹果 Mac 电脑和带有 Nvidia 显卡的 Windows PC 和 Linux 服务器。
模型部署和推理
GPUStack 为在不同 GPU 上运行不同大模型选择最佳的推理引擎。GPUStack 支持的首个推理引擎是 LLaMA.cpp,允许 GPUStack 部署来自 Hugging Face 的 GGUF 类型的模型和 Ollama Library (ollama.com/library)中列出的所有模型。
管理员可以在 GPUStack 上运行任何模型,需要先将其转换为 GGUF 格式,并上传 Hugging Face 或 Ollama Library。
对其他推理引擎(如vLLM)的支持也在我们的路线图中,将在未来版本中提供。
注意:GPUStack 会自动将你部署的模型调度到具有适当资源的机器上运行,减少手动干预。如果你想了解如何评估所部署模型的资源消耗,可以使用我们的 GGUF Parser 项目: https://github.com/gpustack/gguf-parser-go。我们将在未来提供更详细的教程。
在资源充足的情况下,GPUStack 默认将模型全部卸载到 GPU,以实现最佳性能的推理加速。如果 GPU 资源相对不足,GPUStack 会同时使用 GPU 和 CPU 进行混合推理,以最大限度地利用资源。而在没有 GPU 资源的场景下,GPUStack 也支持纯 CPU 推理。这样的设计使 GPUStack 能够更广泛地适配各种边缘或资源有限的环境。
快速与现有应用集成
GPUStack 提供了与 OpenAI 兼容的 API,并提供了大模型试验场。试验场可以让 AI 开发人员能够调试大模型,并将其快速集成到自己的应用中。
此外,开发人员还可以使用 GPUStack 提供的观测指标来了解应用对各种大模型的使用情况。这也有助于管理员有效地管理 GPU 资源利用。
GPU 和 LLM 的观测指标
GPUStack 提供全面的性能、利用率和状态监控指标。
对于 GPU,管理员可以使用 GPUStack 实时监控资源利用率和系统状态。基于这些指标:
管理员可以进行扩容、优化等管理操作。
GPUStack 可以根据资源监控指标,调整其模型调度算法。
对于 LLM,开发人员可以使用 GPUStack 来查看 Token 吞吐量、Token 使用量、 API 请求吞吐量等指标。这些指标可以帮助开发人员评估模型的性能并优化应用。GPUStack 还计划在未来的版本中,基于这些推理性能指标进行自动扩容。
认证和访问控制
GPUStack 也为企业提供身份验证和 RBAC(Role-based Access Control)功能。平台上的用户可以拥有管理员或普通用户角色。这保证了只有授权的管理员可以部署和管理大模型,只有授权的开发人员可以使用大模型。应用也可以通过统一的 API 认证授权访问各种大模型。
GPUStack 应用场景
GPUStack 尝试解锁在任何 GPU 厂商上运行大模型的可能性。以下是一些你可以用 GPUStack 实现的应用场景:
整合现有的 Mac、Windows PC 和其他 GPU 资源,为开发团队提供低成本的 LLMaaS。
在资源有限的环境下,聚合多个边缘节点,提供基于 CPU 资源的 LLMaaS。
在你的数据中心构建自己的企业级 LLMaaS,用于无法在云中托管的高度敏感的工作负载。
开始使用 GPUStack
安装并创建 GPU 集群
Linux 或 MacOS 系统
要在 Linux 或 MacOS 系统上安装,GPUStack 提供了一个安装脚本,可以将其作为系统服务安装在 systemd 或 launchd 的系统上。
要使用这种方法安装 GPUStack,执行以下命令:
curl -sfL https://get.gpustack.ai | sh -现在你已经成功部署并启动了 GPUStack,且将当前节点作为第一个 Worker 节点。
你可以通过 http://myserver (替换为你所安装的主机 IP 或域名)在浏览器访问 GPUStack,以 admin 用户名和默认密码登录。
默认密码可以在 GPUStack Server 节点上通过以下命令获得:
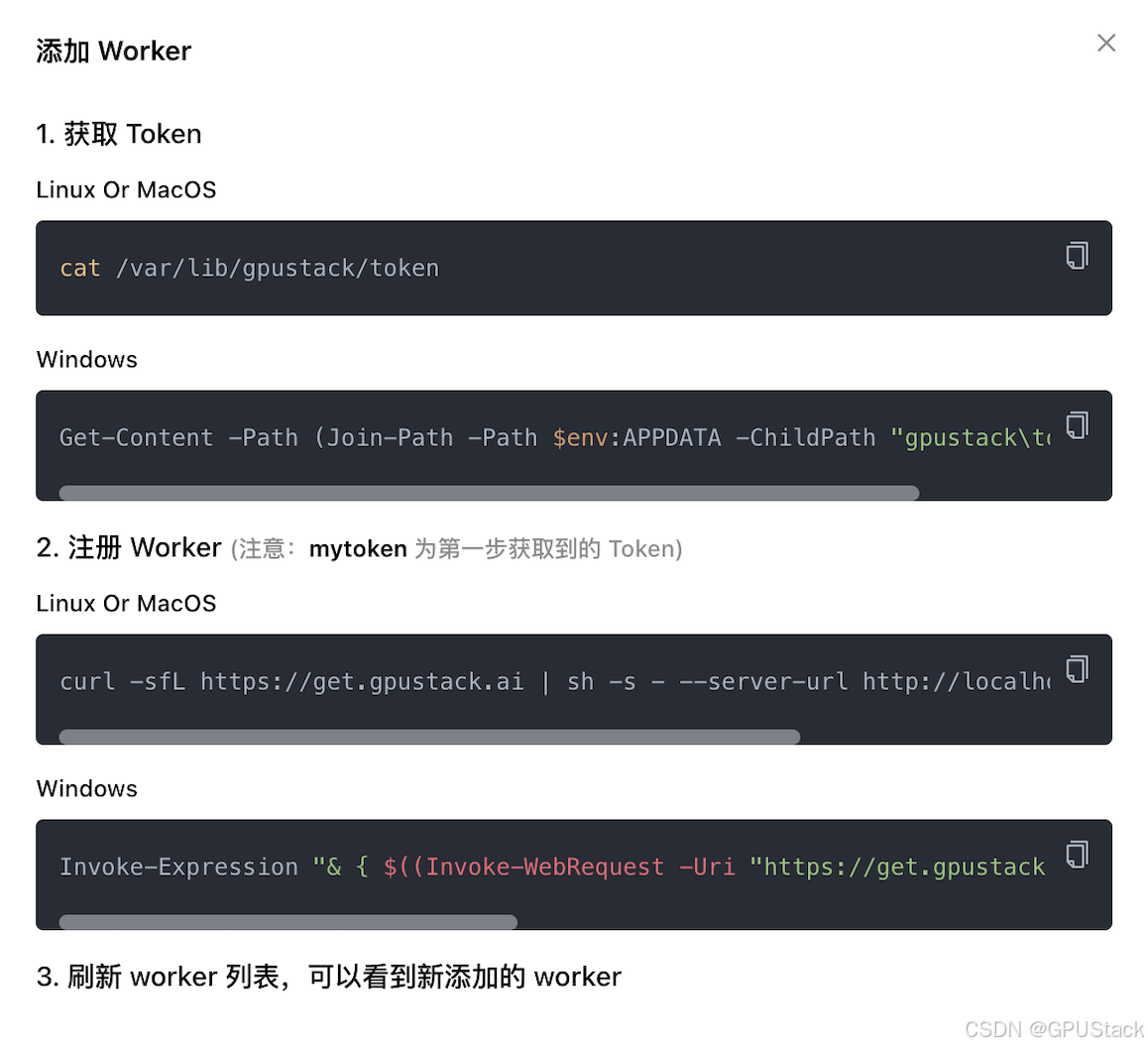
cat /var/lib/gpustack/initial_admin_password(可选)要添加更多的 Worker 节点组建 GPU 集群,请在其他要加入集群的 Worker 节点执行以下命令:
curl -sfL https://get.gpustack.ai | sh - --server-url http://myserver --token mytoken将其中的 http://myserver 替换为你的 GPUStack 访问地址,并将 mytoken 替换为用于添加 Worker 的认证 token。
你可以在 Server 节点执行以下命令获取 token:
cat /var/lib/gpustack/token也可以直接按照 GPUStack 上的指引添加 Worker:
Windows 系统
要在 Windows 系统上安装,以管理员权限运行 PowerShell,执行如下命令安装 GPUStack:
Invoke-Expression (Invoke-WebRequest -Uri "https://get.gpustack.ai" -UseBasicParsing).Content完成后,通过 http://myserver (替换为你所安装的主机 IP 或域名)在浏览器访问 GPUStack,以 admin 用户名和默认密码登录。
默认密码可以在 Server 节点上通过以下命令获得:
Get-Content -Path (Join-Path -Path $env:APPDATA -ChildPath "gpustack\initial_admin_password") -Raw(可选)你也可以在其他 Windows 节点上运行以下命令,添加额外的 Worker 以组建 GPU 集群(注意替换 http://myserver 和 mytoken):
Invoke-Expression "& { $((Invoke-WebRequest -Uri "https://get.gpustack.ai" -UseBasicParsing).Content) } -ServerURL http://myserver -Token mytoken"默认情况下,你可以在 Server 节点上运行以下命令来获取用于添加 Worker 的 token:
Get-Content -Path (Join-Path -Path $env:APPDATA -ChildPath "gpustack\token") -RawGPUStack 支持混合集群(即将 Linux,MacOS 和 Windows 节点组建成混合的 GPU 集群),安装命令同理。
对于其他安装场景,请参考我们的安装文档:https://docs.gpustack.ai/quickstart/
部署大模型服务
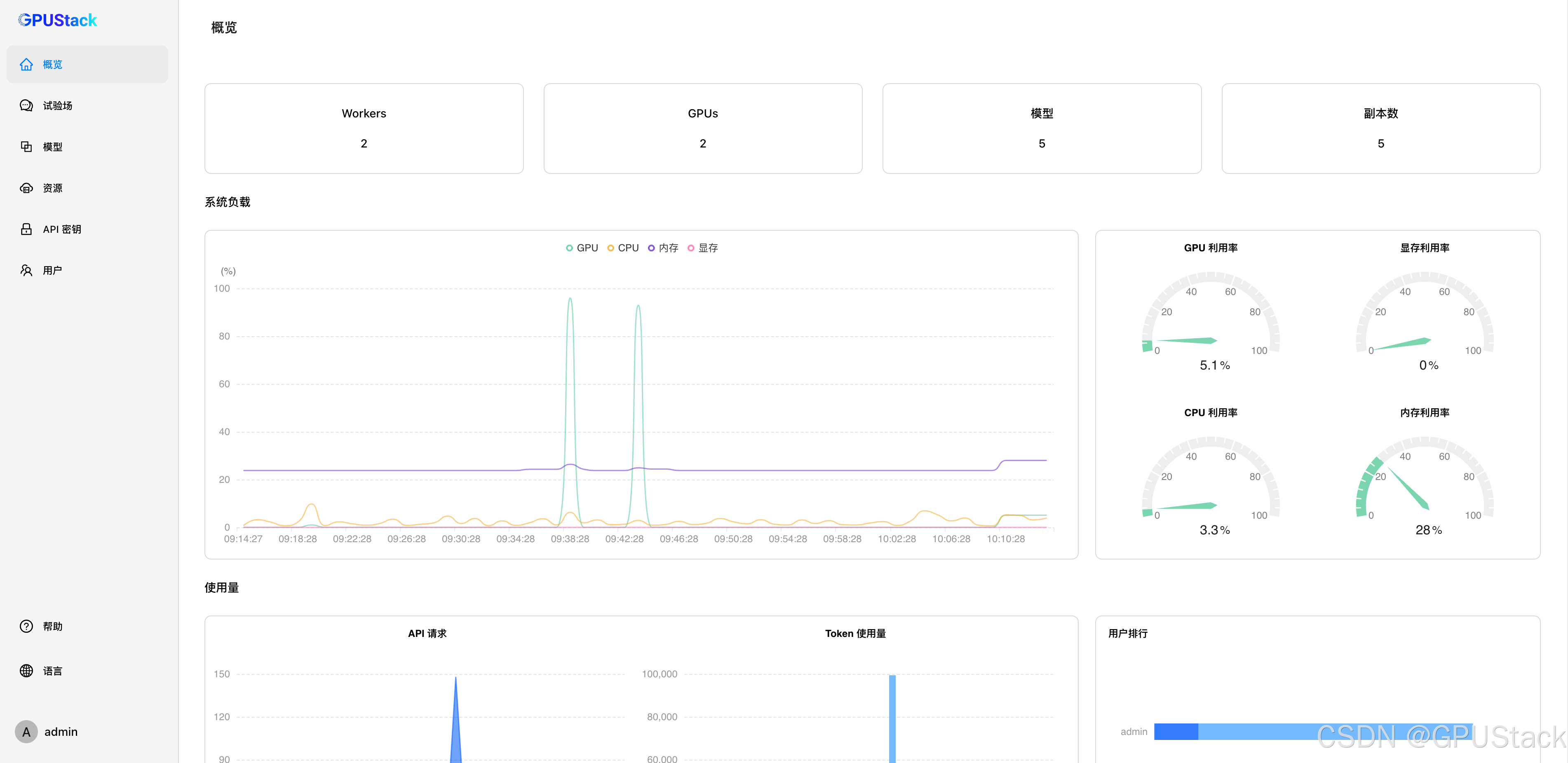
作为平台管理员,你可以以管理员的角色登录到 GPUStack 并导航到菜单中的资源,在这里查看你当前的 GPU 资源状态和容量。
然后你可以导航到模型,将任何开源的大模型到你的 GPU 集群中。这使得平台管理员可以快速在任意 GPU 之上运行大模型并向普通用户提供大模型服务,以便集成到他们的应用程序中。
这种方法可以帮助你有效地利用现有的资源,为各种需求和场景提供私有的大模型服务。
访问 GPUStack,在模型中部署你需要的大模型,选择从 Hugging Face (注意当前仅支持 GGUF 格式的模型文件)或 Ollama Library 下载模型文件到本地并运行大模型: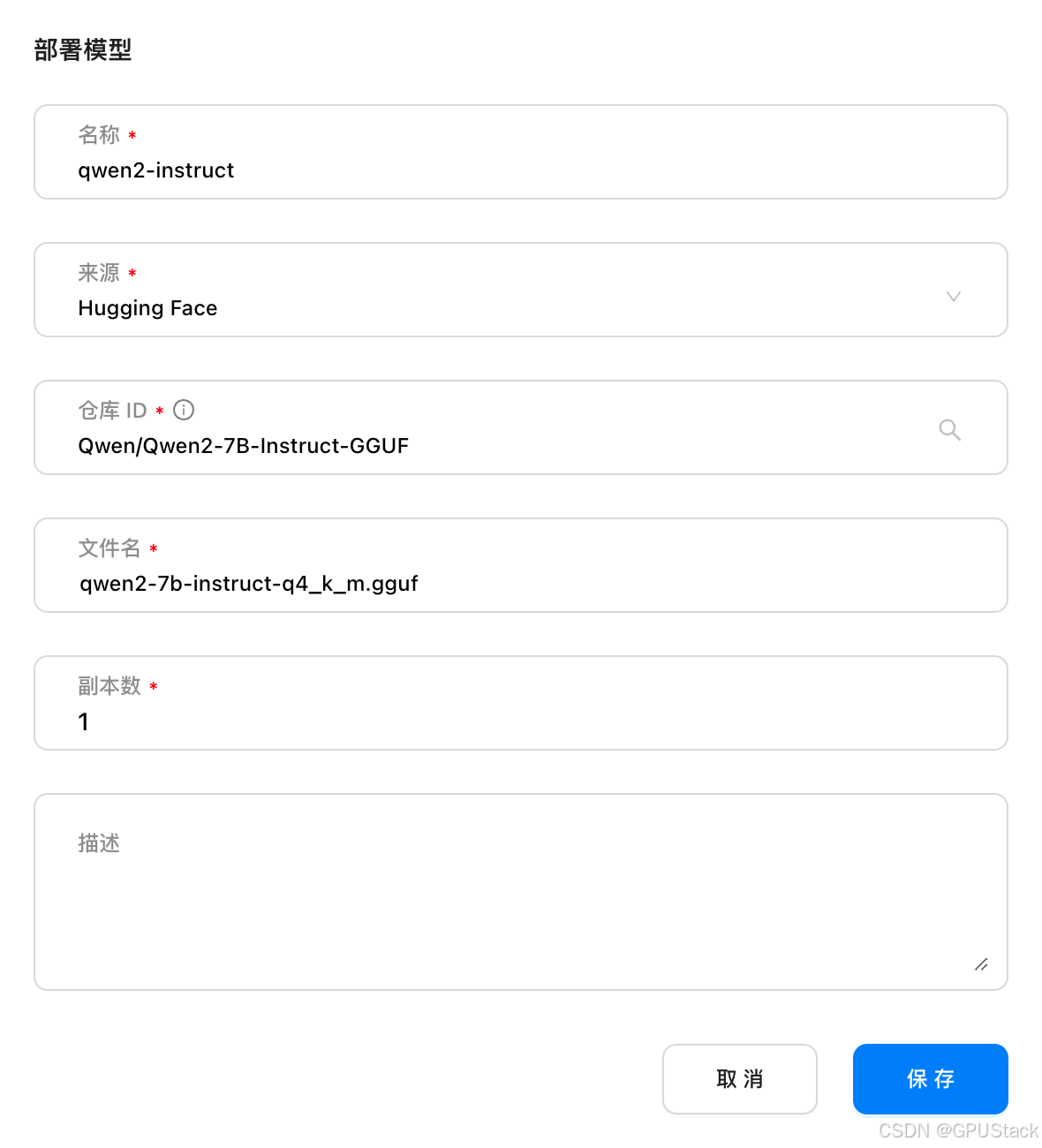
集成到你的应用中
作为一个 AI 应用开发人员,你可以以普通用户的角色登录到 GPUStack 并导航到菜单中的试验场,你可以在这里通过 UI 跟大模型进行交互。
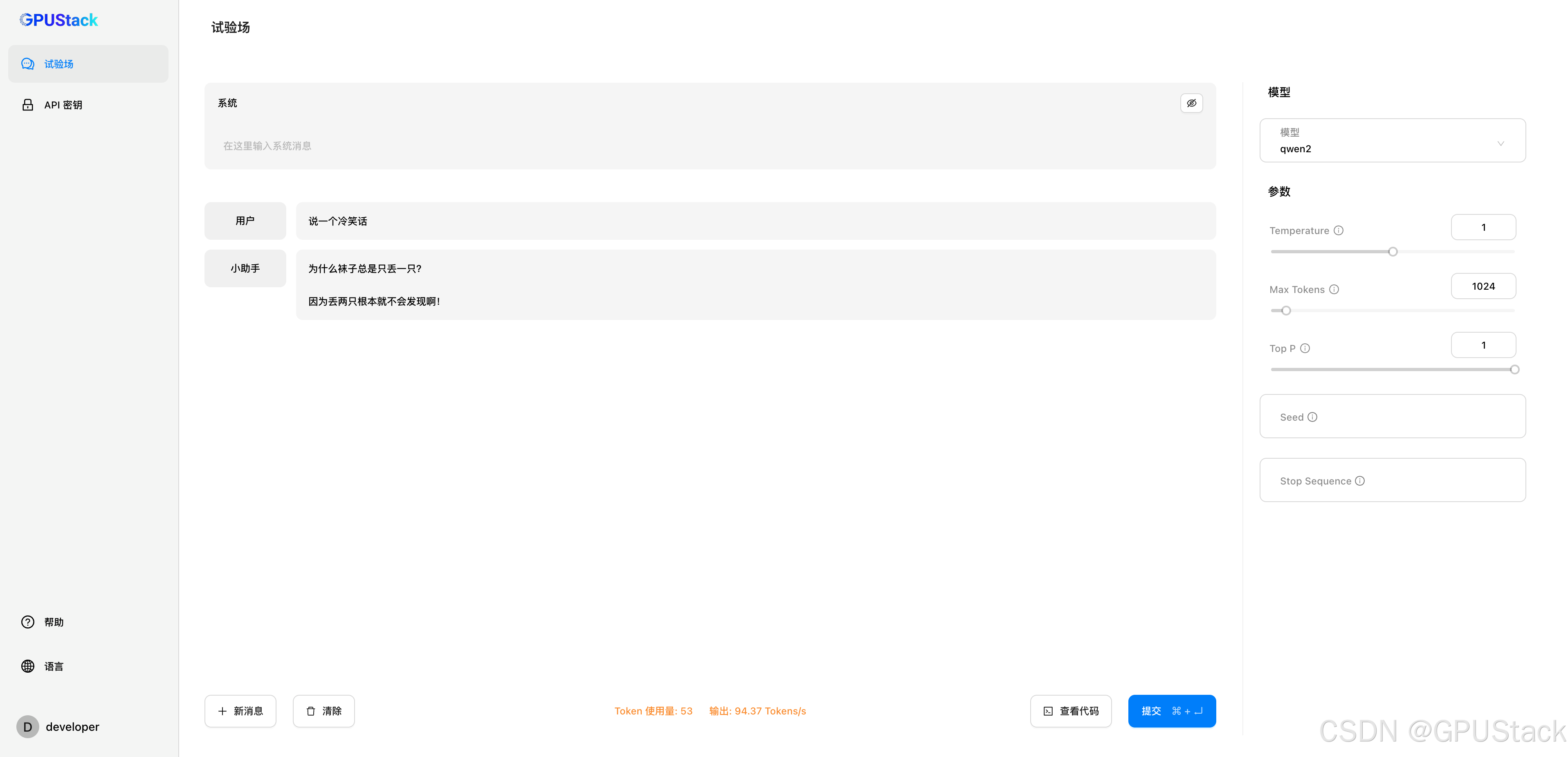
下一步,你可以访问到 API 秘钥生成并保存你的 API 秘钥。然后回到试验场,在这里自定义你的大模型,例如调整系统 prompt,添加小样本学习样例,或调整 prompt 参数。
当你完成了自定义设置,点击查看代码选择你期望的调用代码格式(curl, Python, Node.js),并加入之前的 API 秘钥,然后在你的应用中使用这段调用代码来让应用与你的私有大模型通信。
现在你已经可以访问 OpenAI 兼容的大模型 API。例如,通过 curl 访问的示例如下:
export GPUSTACK_API_KEY=myapikeycurl http://myserver/v1-openai/chat/completions \ -H "Content-Type: application/json" \ -H "Authorization: Bearer $GPUSTACK_API_KEY" \ -d '{ "model": "llama3", "messages": [ { "role": "system", "content": "You are a helpful assistant." }, { "role": "user", "content": "Hello!" } ], "stream": true }'加入社区
想要知道更多关于 GPUStack 的信息,可以访问:https://gpustack.ai。
如果你在使用过程中遇到任何问题,或者对 GPUStack 有任何建议,欢迎随时加入我们的 Discord 社区 Community ,也可以添加 GPUStack 微信小助手(微信号:GPUStack)加入 GPUStack 微信交流群,获得 GPUStack 团队的技术支持,并与社区爱好者友好交流。