???本专栏所有程序均经过测试,均可成功执行???
专栏地址:YOLOv8从入门改进到发论文——点击即可跳转 订阅专栏不迷路
在深度学习的目标检测领域,YOLOv8是现在较受欢迎的一个算法。但很多同学没有老师手把手教,对YOLOv8了解甚少。为了让大家少走弯路,我为大家整理了详细的步骤,越是小白,越是适合看我写的内容。如果有写的不明白的地方,大家可以在评论区问我,我将知无不言言无不尽。
目录
1. 环境配置
安装Anaconda
具体步骤(一)
具体步骤(二)
2. YOLOv8代码下载
3. 数据准备
数据集地址(一)
数据集地址(二)
数据集地址(三)
4. 开始训练
1. 环境配置
想要成功的运行实验,一个合适稳定的环境是不可或缺的。
安装Anaconda
Anaconda包括Conda、Python以及一大堆安装好的工具包,比如:numpy等常用的包
因此安装Anaconda的好处主要为以下几点:
1)包含conda:conda是一个环境管理器,其功能依靠conda包来实现,该环境管理器与pip类似,那有同学会问了:我能通过pip装conda包达到conda环境管理器一样的功能吗?答案是不能,conda包的实现离不开conda环境管理器。
2)安装大量工具包:Anaconda会自动安装一个基本的python,该python的版本Anaconda的版本有关。该python下已经装好了一大堆工具包,这对于科学分析计算是一大便利,你愿意费时耗力使用pip一个个包去装吗?
3)可以创建使用和管理多个不同的Python版本:比如想要新建一个新框架或者使用不同于Anoconda装的基本Python版本,Anoconda就可以实现同时多个python版本的管理
具体步骤(一)
Anaconda的安装
你可以根据你的操作系统是32位还是64位选择对应的版本到官网下载,但是官网下载很慢,建议到清华大学镜像站下载。
Anaconda3-5.3.0-Windows-x86_64.exe——点击即可跳转
下载好后进行安装
安装Anaconda3-5.3.0-Windows-x86_64.exe
2. 主要选择,基本默认安装
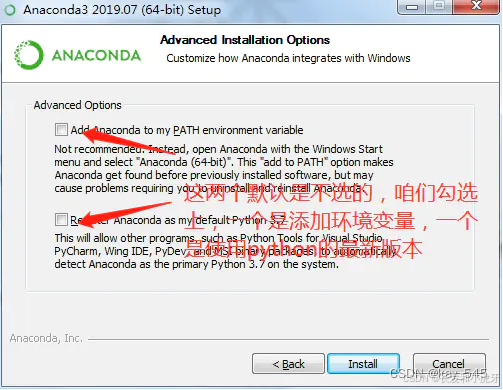
3. 两个勾选项的选择,选择第一个
4. 进度条完成后点Next
去掉默认的两个选项,点击Finish完成安装
验证是否安装成功
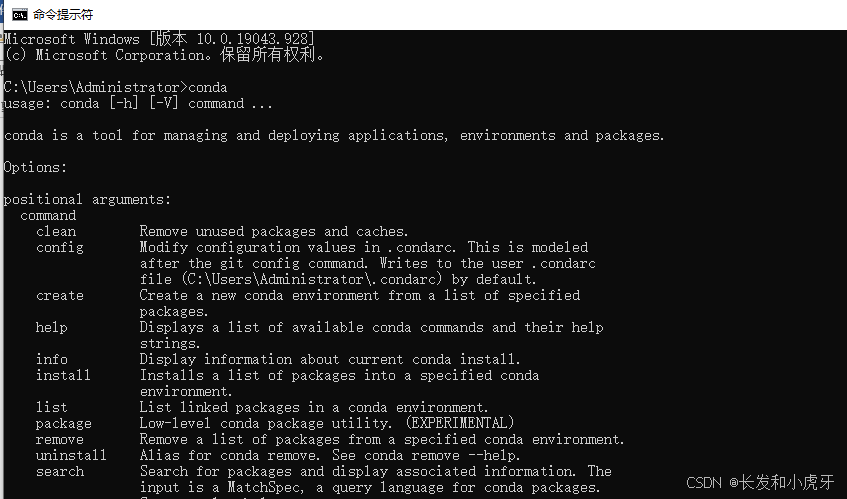
输入cmd打开dos
在打开的dos中输入conda命令,出现如下图提示就代表我们已经安装完成了
具体步骤(二)
安装好以后打开anaconda powershell prompt

然后输入命令
conda create -n name python==3.8 # 创建环境, name是可以替换的,随便起名,这个名字是你的环境名称, python==3.8意思是python的版本是3.8创建环境, name是可以替换的,随便起名,这个名字是你的环境名称, python==3.8意思是python的版本是3.8 ,如果你想要3.9版本的,则python==3.9
回车后出现
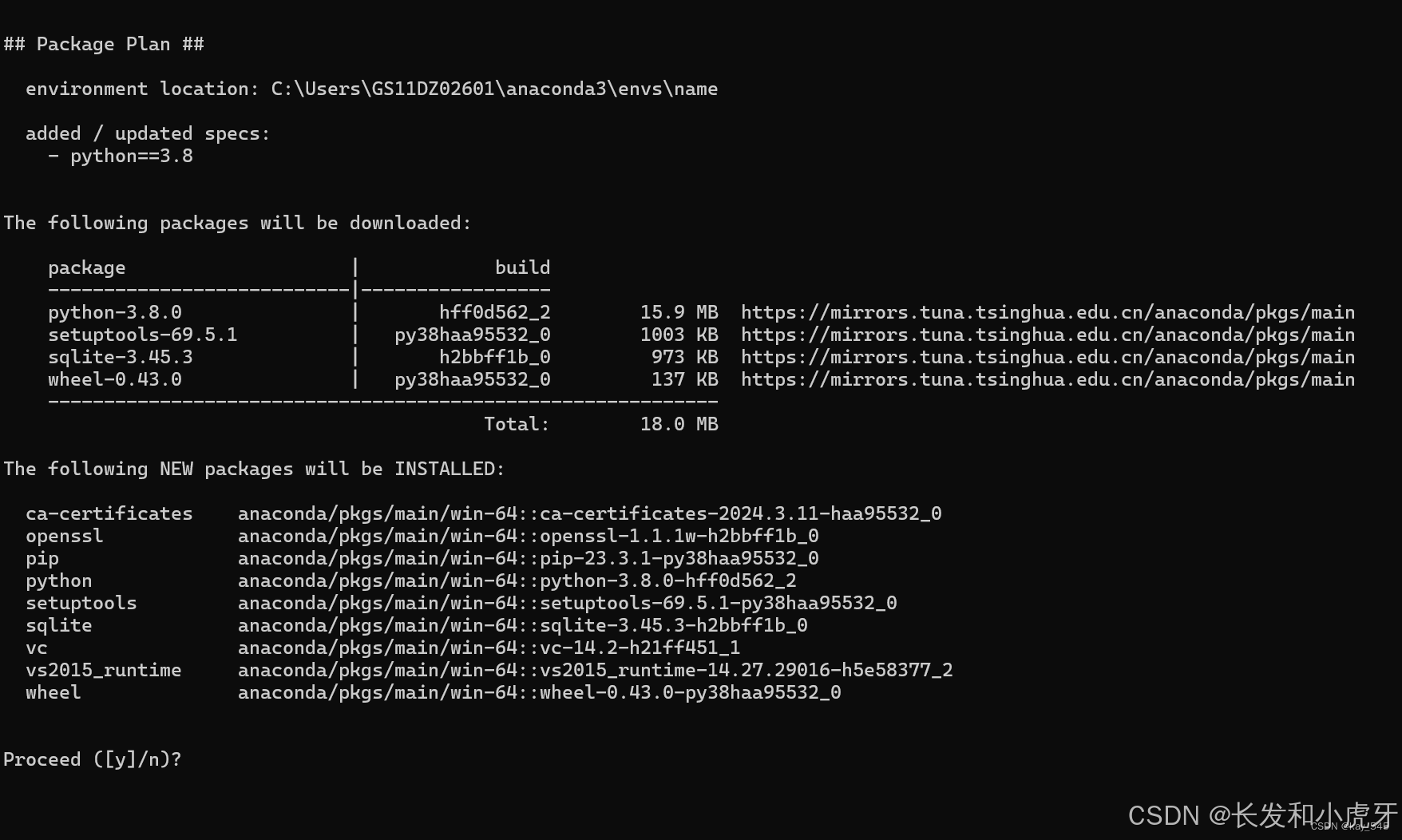
输入 Y后回车,开始下载python和一些基础的包

下载完成后 激活环境
conda activate name # 其中name是你上面创建环境的名称
? 激活成功。现在基本的环境已经安装好了,我们可以下载代码了?
但是能运行YOLOv8的环境还没有完全安装好
2. YOLOv8代码下载
可能有些同学不知道在哪下载YOLOv8的官方代码,YOLOv8的官方代码在github上下载。
YOLOv8官方代码仓库——点击即可跳转
进入网站后,可以这样下载,这样下载的是一个压缩包
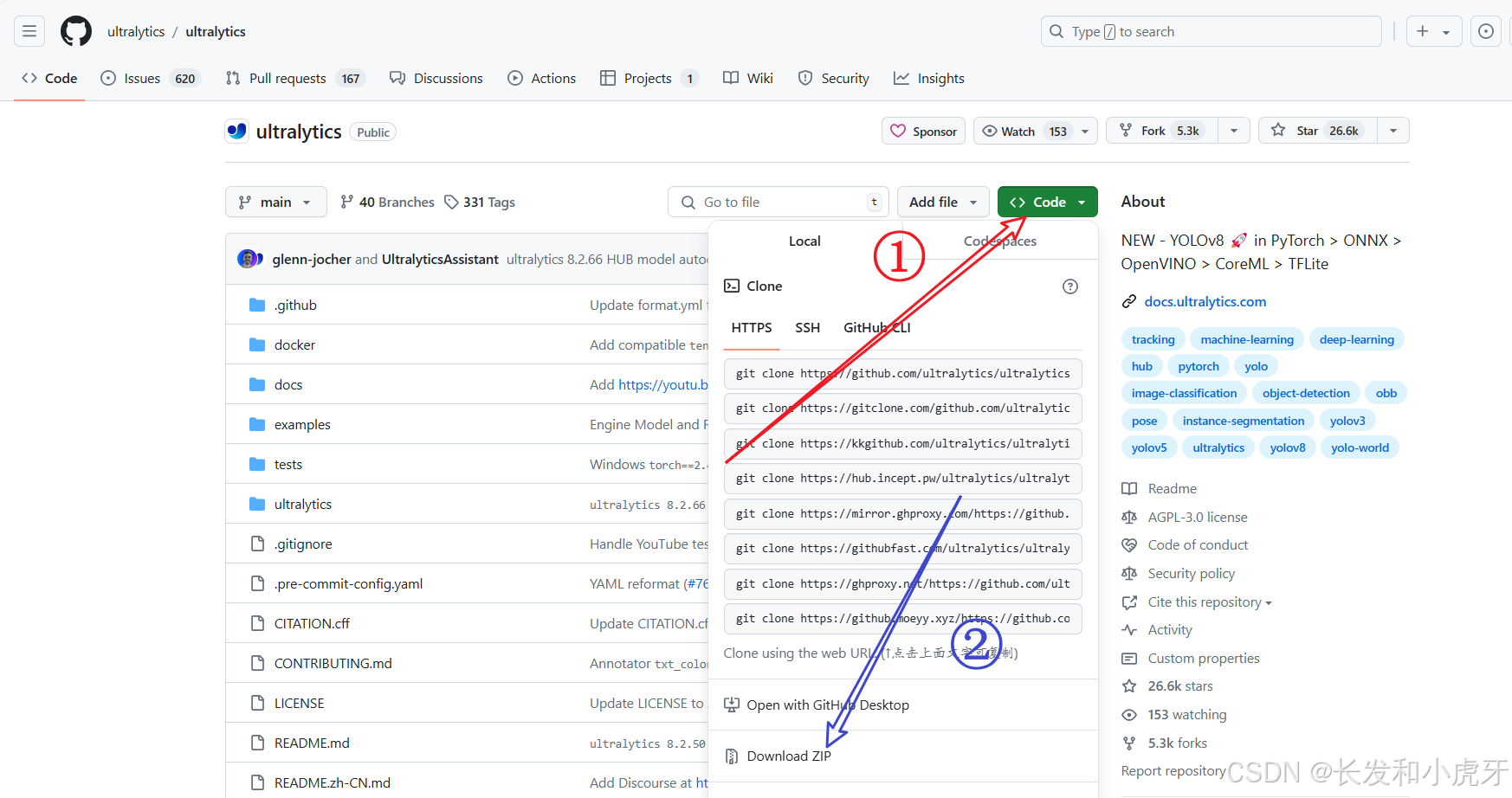
也可以这样下载,即用命令下载
git clone https://github.com/ultralytics/ultralytics.git
两种方法选择一种下载即可。
然后现在可以打开刚刚激活环境的窗口,切换到你下载好YOLOv8的目录下面
cd /root/ultralytics/输入命令
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple/ -r requirements.txt为了下载速度快,我这里用了清华源,当然,也可以换成阿里源
https://mirrors.aliyun.com/pypi/simple 出现这个画面即说明环境安装成功
到这一步,整个YOLOv8的环境才算是真正的配置完成。
3. 数据准备
如果你想用自己的数据作实验的话,需要自己编写对应的ymal文件
在\root\ultralytics\ultralytics\ultralytics\cfg\datasets文件夹下,我们可以找到有关数据的yaml文件,我们参考coco128.yaml的内容编写我们自己的数据路径。
# Ultralytics YOLO ?, AGPL-3.0 license# COCO128 dataset https://www.kaggle.com/ultralytics/coco128 (first 128 images from COCO train2017) by Ultralytics# Documentation: https://docs.ultralytics.com/datasets/detect/coco/# Example usage: yolo train data=coco128.yaml# parent# ├── ultralytics# └── datasets# └── coco128 ← downloads here (7 MB)# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]path: ../datasets/coco128 # dataset root dirtrain: images/train2017 # train images (relative to 'path') 128 imagesval: images/train2017 # val images (relative to 'path') 128 imagestest: # test images (optional)# Classesnames: 0: person 1: bicycle 2: car 3: motorcycle 4: airplane 5: bus在coco128.yaml上面可以看到在写一行
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list:
这说明给数据集的方式有三种,接下来我们一一介绍。
数据集地址(一)
其中path是根目录,train是训练集的相对目录,是相对path的相对目录,这里我个人认为比较麻烦,所以我一般是将path注释掉,直接在train写绝对路径。同理,val和test也是一样的。
下面得names是你要训练的类别和它对应的索引,如果在你的数据集中,person被标注为0,那person的索引就是0,以此类推。
数据集的放置要和coco128的类似,coco128是这样放置的,需要注意的像images,labels,train,val不可以用其他的单词替换,但是coco128可以换成其他的文件夹名称
coco128├─images│ ├─train│ └─val└─labels ├─train └─val数据集地址(二)
第二种是给一个file,即txt文件,txt文件的内容是每张img的绝对路径或者相对路径,和上面一样,我还是喜欢写绝对路径,因为写相对路径容易出错,绝对路径无脑放就行了。txt具体的内容如下:

只写图片的地址即可,但是文件夹的放置应该是这样的
dataset├─images # 里面是训练验证和测试的全部图片│ │ └─labels # 里面是训练验证和测试的对应的标签但是有同学可能在生成txt文件的时候觉得困难,不能轻松的拿到全部图片的绝对路径,下面我提供一个脚本,一键生成三个txt文件。
import osimport randomdef get_image_paths(folder): """Returns a list of absolute paths of images in the given folder and subfolders.""" image_extensions = {'.png', '.jpg', '.jpeg', '.bmp', '.gif', '.tiff'} image_paths = [] for root, _, files in os.walk(folder): for file in files: if any(file.lower().endswith(ext) for ext in image_extensions): image_paths.append(os.path.join(root, file)) return image_pathsdef split_data(paths, train_ratio=0.7, val_ratio=0.2, test_ratio=0.1): """Splits the paths into train, val, and test sets based on the given ratios.""" random.shuffle(paths) total = len(paths) train_end = int(total * train_ratio) val_end = train_end + int(total * val_ratio) train_paths = paths[:train_end] val_paths = paths[train_end:val_end] test_paths = paths[val_end:] return train_paths, val_paths, test_pathsdef save_paths(file_path, paths): """Saves the list of paths to the given file.""" with open(file_path, 'w') as f: for path in paths: f.write(path + '\n')def main(folder, train_file='train.txt', val_file='val.txt', test_file='test.txt'): image_paths = get_image_paths(folder) train_paths, val_paths, test_paths = split_data(image_paths) save_paths(train_file, train_paths) save_paths(val_file, val_paths) save_paths(test_file, test_paths)if __name__ == '__main__': folder = '/datasets/images' # 替换为你自己数据集的地址 main(folder)同样,images和labels的是不可以用其他的单词的,yaml文件的具体内容供参考
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]# path: ../datasets/coco8 # dataset root dirtrain: root\datasets\train.txt # train images (relative to 'path') 4 imagesval: root\datasets\val.txt # val images (relative to 'path') 4 imagestest: # test images (optional)# Classesnames: 0: person 1: bicycle 2: car 3: motorcycle 4: airplane 5: bus数据集地址(三)
第三种方式放置列表,因为数据一般都比较多,我基本不用这种方式,但在这里我也简单的给出例子
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]# path: ../datasets/coco8 # dataset root dirtrain: [/home/inspur/datasets/trian/images/000000044802.jpg, /home/inspur/datasets/trian/images/000000044813.jpg, /home/inspur/datasets/trian/images/000000044815.jpg, /home/inspur/datasets/trian/images/000000044820.jpg, /home/inspur/datasets/trian/images/000000044823.jpg, /home/inspur/datasets/trian/images/000000044825.jpg, /home/inspur/datasets/trian/images/000000044827.jpg] # train images (relative to 'path') 4 imagesval: [/home/inspur/datasets/trian/images/000000044802.jpg, /home/inspur/datasets/trian/images/000000044813.jpg, /home/inspur/datasets/trian/images/000000044815.jpg, /home/inspur/datasets/trian/images/000000044820.jpg, /home/inspur/datasets/trian/images/000000044823.jpg, /home/inspur/datasets/trian/images/000000044825.jpg, /home/inspur/datasets/trian/images/000000044827.jpg] # val images (relative to 'path') 4 imagestest: # test images (optional)# Classesnames: 0: person 1: bicycle 2: car 3: motorcycle 4: airplane 5: bus4. 开始训练
在准备好数据以后就可以开始训练了,
我们在\root\ultralytics\下面新建train.py 粘贴下面的内容
import warningswarnings.filterwarnings('ignore')from ultralytics import YOLOif __name__ == '__main__': model = YOLO(r'root\ultralytics\ultralytics\ultralytics\cfg\models\v8\yolov8.yaml') # model.load('yolov8n.pt') # 是否加载预训练权重,可以加载也可以不加载 model.train(data=r'ultralytics\ultralytics\ultralytics\cfg\datasets/data.yaml', cache=False, # 是否生成告诉缓存文件,生成以后训练的速度是会提高的 imgsz=640, # 图片输入模型的尺寸 epochs=150, # 训练的轮数 single_cls=False, # 是否是单类别检测 batch=4, # batch_size 的大小 close_mosaic=10, # 最后10个epoch关闭马赛克增强 workers=0, # 线程数 device='0', # 选择哪个卡进行训练, 没有GPU卡的话可以修改成 device="cpu" optimizer='SGD', # 使用 SGD 优化器 resume='runs/train/exp/weights/last.pt', # 如过想继续训就设置last.pt的地址 amp=True, # 开启自动混合精度训练 project='runs/train', name='exp', #这个name建议大家修改,我一般修改为数据集的名称+时间戳,这样你保存的实验结果可知道是什么适合做的哪个实验 )然后执行即可开始实验,出现下面的内容就是成功的开始训练

接下来我们将讲解关于YOLOv8实验结果分析的内容