?大家好,我是Yui_,目标成为全栈工程师~?
?如果文章知识点有错误的地方,请指正!和大家一起学习,一起进步?
?如有不懂,可以随时向我提问,我会全力讲解~
?如果感觉博主的文章还不错的话,希望大家关注、点赞、收藏三连支持一下博主哦~!
?你们的支持是我创作的动力!
?我相信现在的努力的艰辛,都是为以后的美好最好的见证!
?人的心态决定姿态!
?欢迎讨论:如有疑问或见解,欢迎在评论区留言互动。
?点赞、收藏与分享:如觉得这篇文章对您有帮助,请点赞、收藏并分享!
?分享给更多人:欢迎分享给更多对编程感兴趣的朋友,一起学习!
文章目录
1.案例引入2.正则表达式2.1 核心概念 3.正则表达式的语法3.1 正则:`.`3.2 正则: `\d`3.3 正则:`\D`3.4 正则:`\w`3.5 正则:`\W`3.6 正则:`\s`3.7 正则:`\S`3.8 正则:`^`3.9 正则:`$`3.10 正则:`*`3.11 正则:`+`3.12 正则:`?`3.13 正则:`{n}`3.14 正则:`{n,}`3.15 正则:`{n,m}`3.16 正则:`[]`3.17 正则`()`3.18 正则`(?:...`3.18 正则`(?P<name>...`3.19 正则:`|`3.20 正则:`(?=...)` 4. `re`库4.1 常见的`re`函数4.1.1 `re.match()`4.1.2 `re.findall()`4.1.3 `re.search()`4.1.4 `re.sub()`4.1.5 `re.split()` 5. 再讲案例6. 总结
1.案例引入
本文将会先介绍什么是正则表达式,然后在介绍正则表达式在python中的应用。
下方图片及案例思路来自:正则表达式
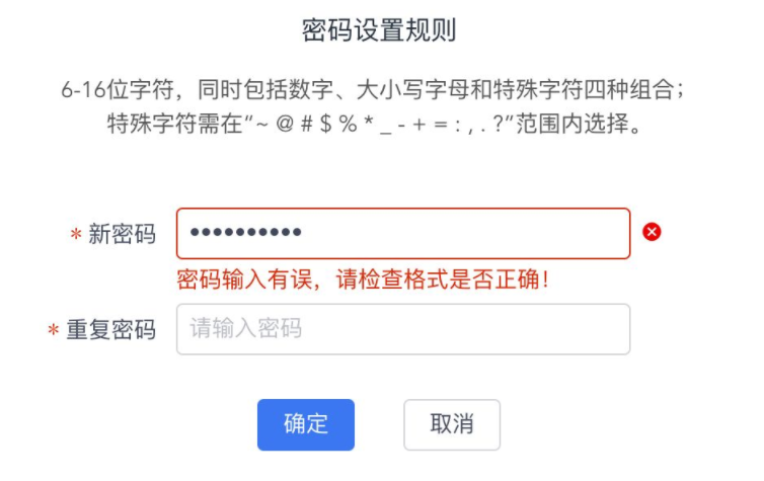
在没有学习正则表达式前,当你被要求实现上图的功能,你会怎么实现呢?肯定就是将上面的要求一个个拆分出来逐个击破。
密码设置的规则:
def checkPassword(password): if(password == None): return False if(len(password)>16 or len(password)<6): return False hasNumber = False hasSmallLetter = False hasBigLetter = False hasSpecialChar = False arr = '~@#$%*_-+=:.?' for c in password: if '0'<=c<='9': hasNumber = True elif 'a'<=c<='z': hasSmallLetter = True elif 'A'<=c<='Z': hasBigLetter = True elif c in arr: hasSpecialChar = True else: return False return hasNumber and hasSmallLetter and hasBigLetter and hasSpecialChar下面是验证:
#测试用例分别为:长度不够,完全符合,含有无效字符,长度过长,不含数字,不含小写字母,不含大写字母,不含特殊字符passwords = ['aA1#a','AAA123__a','adasd1AS$$\\','asd232ASD&&asdqwasfa2','asdadASD$%','123ASD$$$$','123asd$','123qweASD']for s in passwords: print(checkPassword(s))#打印结果:#False#True#False#False#False#False#False#False这是我们的没有学习过正则表达式的做法,代码量还是比较多的,但是如果运用正则表达式,可以将代码量压缩到一行。
import reimport numpy as npdef checkPassword(password): return bool(re.fullmatch(r'^(?=.*[0-9])(?=.*[a-z])(?=.*[A-Z])(?=.*[~@#\$%*_\-+=:.?])[A-Za-z0-9~@#\$%*_\-+=:.?]{6,16}$', password)) # 返回布尔值表示是否符合美化一下验证代码:
# 测试用例passwords = [ 'aA1#a', # 长度不够 'AAA123__a', # 完全符合 'adasd1AS$$\\', # 含有无效字符 'asd232ASD&&asdqwasfa2', # 长度过长 'asdadASD$%', # 不含数字 '123ASD$$$$', # 不含小写字母 '123asd$', # 不含大写字母 '123qweASD' # 不含特殊字符]for s in passwords: print(f"{s}: {checkPassword(s)}")打印结果:
aA1#a: FalseAAA123__a: Trueadasd1AS$$\: Falseasd232ASD&&asdqwasfa2: FalseasdadASD$%: False123ASD$$$$: False123asd&&$: False123qweASD: False这样是不是就非常简单了,现在你可能看不懂正则表达式,但相信你在看完这篇博客就会有所了解了。
2.正则表达式
正则表达式(英语:regular expression,常简写为regex、regexp或RE),又称规律表达式、正则表示式、正则表示法、规则表达式、常规表示法,是计算机科学概念,用简单字符串来描述、匹配文中全部匹配指定格式的字符串,现在很多文本编辑器都支持用正则表达式搜索、取代匹配指定格式的字符串。
许多程序设计语言都支持用正则表达式操作字符串,如Perl就内置功能强大的正则表达式引擎。正则表达式这概念最初由Unix的工具软件(例如sed和grep)普及开。
2.1 核心概念
1. 模式(Pattern)
正则表达式通过模式来描述字符的规则,比如“匹配所有数字”或“匹配以字母开头的字符串”。模式由普通字符(如字母、数字)和特殊字符(元字符)组成。2. 匹配正则表达式根据定义的模式,尝试在目标字符串中找到匹配部分。
3.正则表达式的语法
本文会详细讲述以下表格中的正则表达式的语法,当然正则表达式还存在其他的语法,但不在本文的讨论范围内。
| 元字符 | 功能 |
|---|---|
. | 匹配除换行符的任意字符 |
\d | 匹配数字,等价于[0-9] |
\D | 匹配非数字,等价于[^0-9] |
\w | 匹配字母、数字或下划线,等价于[a-zA-Z0-9_] |
\W | 匹配非字母,数字或下划线 |
\s | 匹配空白字符(空格、制表符等) |
\S | 匹配非空白字符 |
^ | 匹配字符串的开头 |
$ | 匹配字符串的结尾 |
* | 匹配前面的字符0次或多次 |
+ | 匹配前面的字符1次或多次 |
? | 匹配前面的字符0次或1次 |
{n} | 精确匹配n次 |
{n,} | 至少匹配n次 |
{n,m} | 匹配n到m次 |
[] | 匹配字符集中的任意一个字符 |
() | 分组,捕获子模式 |
(?:... | 非捕获分组 |
?P<name>... | 命名分组 |
3.1 正则:.
匹配除换行符的任意字符
举例:
a.c可以匹配abc、acc等等
...可以匹配123,124但是不能匹配1234
3.2 正则: \d
匹配任意一位数字
举例:
asd\d可以匹配asd1、asd2等等
aaabb\dccc就表示aaabb和ccc中间有一个数字。
aaa\d\d\d就表示aaa后面有3个数字。
3.3 正则:\D
匹配非数字
举例:
\D\D\D可以匹配3个非数字字符
如abc,qwe,zxc
3.4 正则:\w
匹配字母、数字或下划线
举例:
12\w212可以匹配123212,12a212,12_212…
3.5 正则:\W
匹配非字母,数字或下划线
举例:
12\W212可以匹配12+212,12-212…
3.6 正则:\s
匹配空白字符(空格、制表符等)(制表符为\t也就是Tab键)
举例:
12\s12可以匹配12 12
3.7 正则:\S
匹配非空白字符
举例:
12\S12可以匹配12112,12a12…
3.8 正则:^
匹配字符串的开头
举例:
^abc可以匹配以abc开头的字符串
比如^abc可以匹配abc123但是不能匹配123abc
3.9 正则:$
匹配字符串的结尾
举例:
$abc可以匹配123abc但是不能匹配abc123
3.10 正则:*
匹配前面的字符0次或多次,也就是任意次
举例:a*匹配任意次a
abc*abc可以匹配ababc,abcabc,abccabc,`abcccccccccabc
3.11 正则:+
匹配前面的字符1次或多次
举例:
abc+de可以匹配abcde,abccde,abccccde
3.12 正则:?
匹配前面的字符0次或1次
举例:
abc?bc可以匹配abcbc,abbc
3.13 正则:{n}
精确前面的字符匹配n次
举例:
ab{3}ab可以匹配abbbab
3.14 正则:{n,}
前面的字符至少匹配n次
举例:
ab{3,}ab可以匹配abbbab,abbbbbbbbab
3.15 正则:{n,m}
前面的字符匹配n到m次
举例:
ab{3,4}ab可以匹配abbbab,abbbbab
3.16 正则:[]
匹配字符集中的任意一个字符
举例:
ab[abc]de可以匹配abade,abbde,abcde
配合前面的语法,我们可以组合出[^]表示不与括号中的任意字符匹配。
举例:
a[^abc]c表示a和c的中间除了a、b、c这3个字符外,其他字符都满足要求。
3.17 正则()
分组,捕获子模式,把()中的内容看成一个整体。
举例:
(abc)+可以匹配abc,abcabc
3.18 正则(?:...
它的作用类似于普通的分组 (),但有一个关键区别:它只对正则表达式的逻辑分组,而不会将匹配的内容捕获为一个组。
这个举例必须用代码解释了
import repattern1 = r'(abc)+'pattern2 = r'(?:abc)+'text = 'abcabc'match1 = re.match(pattern1,text)match2 = re.match(pattern2,text)if match1: print(match1.groups())if match2: print(match2.groups())因为它们的功能是一样的,所以match1和match2的if判断都为真,但是(?:匹配后不会将内容捕获为一个组,所以第二个print打印不出内容的。
打印结果:('abc',)()3.18 正则(?P<name>...
与普通的捕获组 () 不同,命名捕获组为每个捕获的子表达式指定一个可读的名称,而不仅仅使用数字索引来引用它。这使得代码更加易读,特别是在多个捕获组时,能够明确标明每个捕获组的意义。
这里还是用代码来解释
import re# 使用命名捕获组pattern = r'(?P<year>\d{4})-(?P<month>\d{2})-(?P<day>\d{2})'text = "2023-12-14"# 执行匹配match = re.match(pattern, text)if match: # 通过组名来获取匹配的内容 print(f"Year: {match.group('year')}") # 输出:Year: 2023 print(f"Month: {match.group('month')}") # 输出:Month: 12 print(f"Day: {match.group('day')}") # 输出:Day: 143.19 正则:|
补充一个语法
功能:| (竖线) 则表示或的关系,表示检测的字符串须满足其中一个时,才符合条件
举例:
aa|bb|cc可以匹配aa,bb,cc
3.20 正则:(?=...)
再补充一个语法,这是前面案例中用到的语法。
(?=...) 是正则表达式中的正向前瞻(Positive Lookahead),用于在某个位置检查后面是否跟着某个特定的模式,但不会消耗这些字符,即匹配时并不会把 (?=...) 中的内容包括在最终结果中。
举例:
X(?=Y)
X后面必须匹配到Y,但是Y不会成为匹配结果的一部分。用代码举例:
import repattern = r'[a-zA-Z](?=\d)' # 匹配一个字母,后面必须是数字text = "a1b2c3"matches = re.findall(pattern, text)print(matches) # 输出:['a', 'b', 'c']那么正则表达式的基础语法就都讲完了,下面就是python中的re库的介绍
4. re库
re 是 Python 的正则表达式(regular expression)模块,提供了一套强大而灵活的工具,用于字符串的模式匹配、查找和替换操作。正则表达式是一种用来匹配字符串的规则,这种规则通常用于数据验证、字符串解析或复杂的文本处理。
re库是python中内置的库,不需要进行额外的安装在代码的开头添加import re即可。
4.1 常见的re函数
第一个不得不提的函数就是re.match().
4.1.1 re.match()
功能:用于从字符串的起始位置开始匹配开始匹配一个正则表达式。如果正则表达式匹配成功,则返回一个匹配对象,如果匹配失败,返回None.
语法:
re.match(pattern,string,[flags])参数:
pattern:表示模式字符串,由要匹配的正则表达式转化而来。string:表示要匹配的字符串。flags:可选参数,表示标志位,用于控制匹配模式,比如是否区分大小写。返回值:
失败返回
None,成功返回一个匹配对象match object这里的
match object就是该函数的重点。该返回值包含了详细的匹配信息,可以通过对该返回值的提取获得更多的内容,如匹配的字符串、位置等信息。
match object的常见方法和属性: group():返回匹配到的子串。 group(0):返回整个匹配到的字符串。group(n):返回第n个捕获组(如果存在的话)。 import repattern1 = r'\d*' #无捕获组pattern2 = r'(\d*)' #有捕获组text = '12345678'match1 = re.match(pattern1,text)match2 = re.match(pattern2,text)print(match1.group()) print(match1.group(0))#print(match1.group(1)) #报错print(match2.group())print(match2.group(0))print(match2.group(1))#打印结果'''1234567812345678123456781234567812345678'''在这个例子上你发现会对于不存在捕获组的pattern1它的match1.group(1)是无法打印的,通过这个例子似乎并不能完全理解,看着打印结果。你可能会认为它们的功能相同,实际上只有group()和group(0)的功能是一样的。
那么我们来看第二个例子:
import repattern = r"(\d+)-(\w+)"text = "123-abc"match = re.match(pattern, text)if match: print(match.group(0)) # 输出:123-abc(完整匹配) print(match.group(1)) # 输出:123(第一个捕获组) print(match.group(2)) # 输出:abc(第二个捕获组)这个例子可以清楚的理解到返回第n个捕获组的意思了吧。
2. groups():返回所有捕获组的内容,形式是一个元组。
通过代码更好理解
import repattern = r"(\d+)-(\w+)"text = "123-abc"match = re.match(pattern, text)if match: print(match.group(0)) # 输出:123-abc(完整匹配) print(match.group(1)) # 输出:123(第一个捕获组) print(match.group(2)) # 输出:abc(第二个捕获组) print(match.groups()) # 输出:('123', 'abc')(所有捕获组)这个函数和group()非常之像,不要记反了。
match object还有其它的一些方法,如:start(),end(),span,lastgroup(),lastindex(),这里就不具体介绍了,读者可以根据提供的方法名,自行了解。
4.1.2 re.findall()
返回字符串中所有与正则表达式匹配的非重复子串,结果以列表的形式返回。如果没有匹配项返回空列表。
语法:
re.fillall(pattern,string,[flags])直接看代码可能会更好理解:
import repattern = r'\d+'text = '123456x12x123'arr = re.findall(pattern,text)print(arr) #输出['123456', '12', '123']4.1.3 re.search()
功能:从整个字符串中查找第一个匹配的子串,如果找到匹配项,那么返回一个匹配对象;否则,返回None
语法:
re,search(pattern,string,[flags])返回值:match object
注意:search()方法不仅是在字符串的起始位置进行匹配,其他位置上有符合的匹配也可以进行搜索,但是最终不论待匹配字符串有多少个符合的结果,也只会返回一个。
import repattern = r"abc" # 查找 'abc'text = "123abc456"search = re.search(pattern, text)if search: print(f"匹配到:{search.group()}") # 输出:匹配到:abcelse: print("没有匹配到")4.1.4 re.sub()
功能:用于替换字符串所有匹配正则表达式的部分。接受正则表达式,替换内容和目标字符串作为参数。
语法:
re.sub(pattern,repl,string,[count],[flags])参数:
repl:表示要替换后的字符串。count:可选参数,表示模式匹配后替换的最大次数,默认值为0,表示替换所有的匹配。下面看代码吧。
import repattern = r"\d+" # 匹配数字text = "123abc456def789"result = re.sub(pattern, "X", text)print(result) # 输出:XabcXdefX4.1.5 re.split()
功能:按正则表达式分割字符串,返回分割后的字符串列表。
语法:
re.split(pattern,string,[maxsplit],[flags])参数:
maxsplit:可选参数,表达最大的拆分次数。这个也是看代码更清晰易懂:
import repattern = r"\d+" # 按数字分割text = "abc123def456ghi789"result = re.split(pattern, text)print(result) # 输出:['abc', 'def', 'ghi', '']5. 再讲案例
还记得我们在最前面引入的那个密码问题吗?
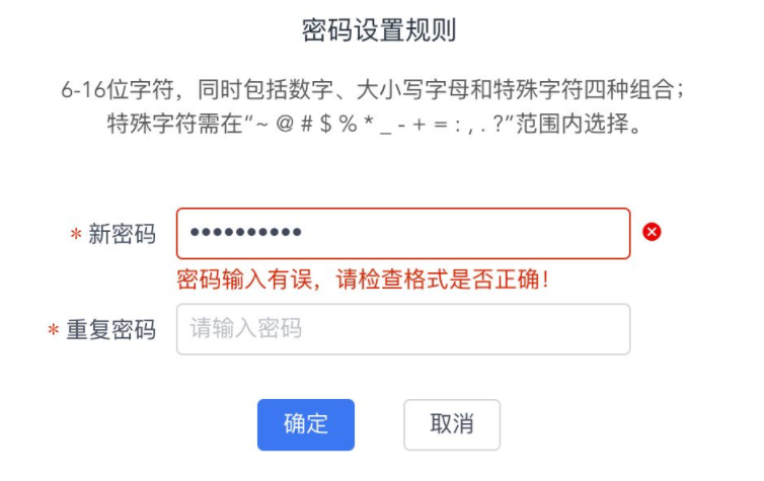
前面我给出了它们的普通写法,以及正则表达式写法。现在学完正则表达式的你,能不能写出它的正则表达式呢?
首先就是至少包含一个数字,可能读者会想到[0-9]来匹配,但是这其实是不行的,这是因为它的作用范围仅限匹配当前字符,不能与其他复杂规则组合使用。
对比:
[0-9]: 只能直接匹配数字,无法检查整个字符串。举例:[0-9]匹配123abc的第一个数字1. 正向前瞻(?=.*[0-9]): 检查整个字符串中是否包含一个数字。举例:(?=.*[0-9])检查abc123是否包含数字,不消耗字符,后续规则继续匹配。r'^(?=.*[0-9])(?=.*[a-z])(?=.*[A-Z])(?=.*[~@#\$%*_\-+=:.?])[A-Za-z0-9~@#\$%*_\-+=:.?]{6,16}$' 了解完这个案例,后续的大小写字母、特殊字符也是这样规则。
那么案例的后续规则还有,输入字符必须是指定范围内的字符。为此我们还需要限定一下可选的字符。
这时候想到的语法就是匹配字符集中的任意一个字符,用到[]
把范围内的字符全加进去[A-Za-z0-9~@#\$%*_\-+=:.?]
最后一个要求就是字符串长度要求6~16,这就要用到{6~16}匹配前面的字符6~16次
最后的最后,在加上^和$,分别表示匹配字符串的开头和结尾,确保字符串完全匹配,不允许多余字符。
6. 总结
正则表达式是处理文本数据的强大工具,它以灵活的模式匹配能力广泛应用于数据清洗、验证、提取和替换等任务中。而 Python 的 re 库则提供了一套高效且易用的接口,让开发者可以轻松地使用正则表达式来解决复杂的字符串处理问题。从简单的匹配到多条件组合的验证,再到高级功能如前瞻、后瞻和命名捕获组,re 模块都能满足你的需求。无论你是编程新手,还是需要快速完成数据处理任务的开发者,掌握正则表达式与 re 库将帮助你在文本操作中如虎添翼。
往期文章python
文章代码都在gitee
