diff 算法实现的几种方法和前端中的应用
diff 算法原理和几种实现方法
diff 是什么
diff 算法就是比较两个数据的差异,例如字符串的差异,对象的差异。
常用于版本管理(git)例如下面的实际案例。
github 上某个 commit,旧代码和新代码之间的不同 diff 展示如下。绿色部分表示添加,红色部分表示删除。这里表示整行的删除和增加。
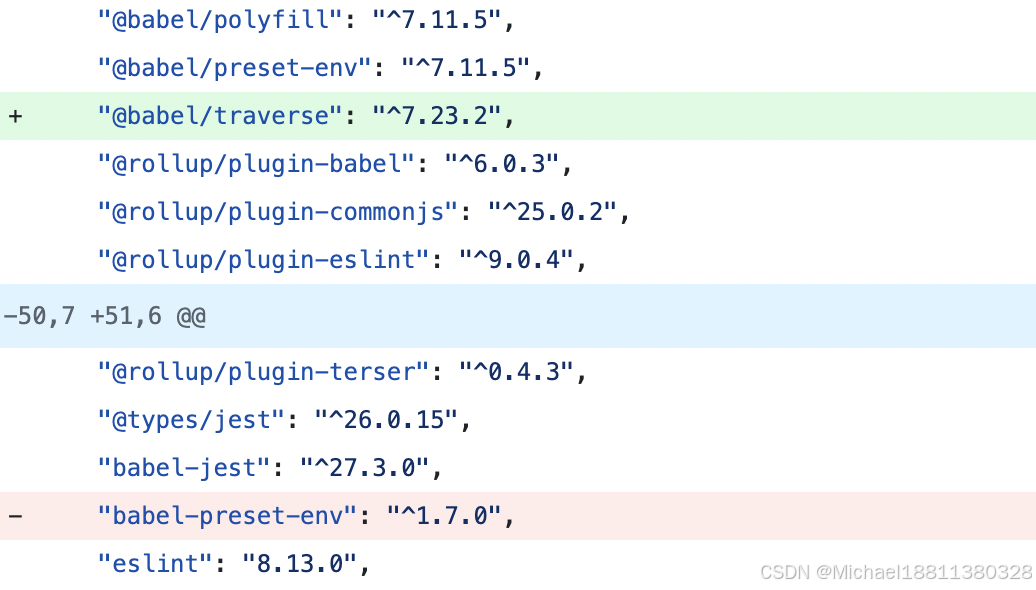
这里就表示删除了两个空行。

上面的案例都是整行更新。还有一些行内的变化,例如某一行中(一个字符串)的某一些字符做了删除和增加。这就需要用到 diff 算法求两个字符串的差异。

字符串的 diff 可以有很多算法实现,其中最常用的就是 LCS 最长公共子序列算法。
最长公共子序列 LCS 算法
diff 可以使用最长公共子序列 LCS 算法进行处理,时间复杂度为O(n²),本质上是 DP 动态规划算法的扩展。
什么是最长公共子序列呢?
最长公共子串(Longest Common Substring)指的是两个字符串中的最长公共子串,要求子串一定连续。
最长公共子序列(Longest Common Subsequence)指的是两个字符串中的最长公共子序列,不要求子序列连续。
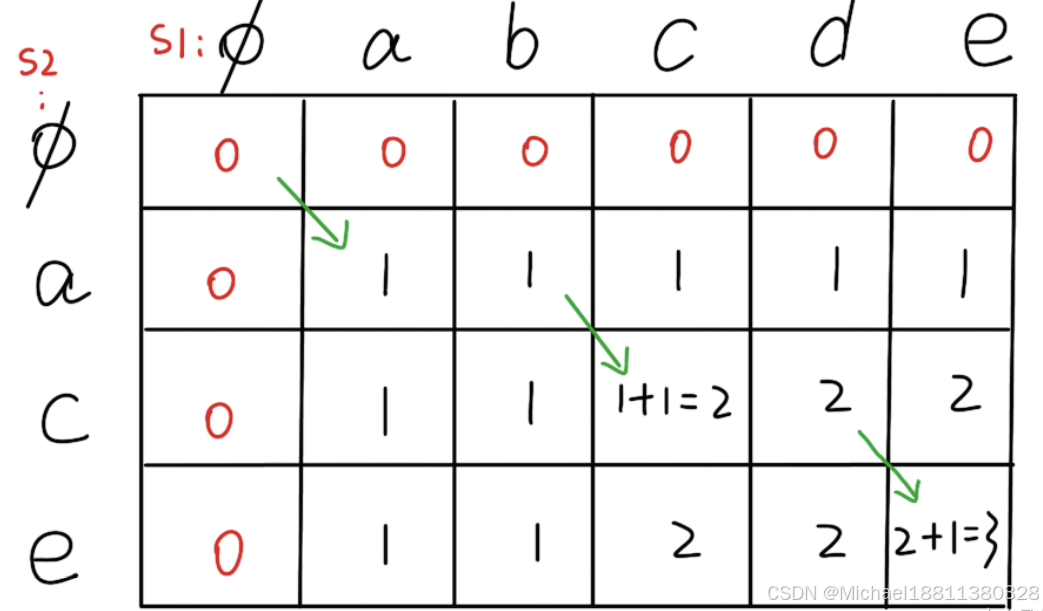
例如,两个字符串 abcde 和 ace 求最长公共子序列,那么实际上就是下面的图示(对应代码在后面)。
其核心的递推式如下:
二维矩阵中,某一个格点的值可以递推得到:
令两个字符串是 str1 str2
1、如果 str1[i - 1] 等于 str2[j - 1],就是相同的字符,那么当前值就是左上角值 + 1,即 D[i][j] = D[i - 1][j - 1] + 1。对应图中绿色的箭头
2、如果 str1[i - 1] 不等于 str2[j - 1],就是不同的字符,那么当前的值就是上方和左方的值的最大值,即 D[i][j] = Max(D[i - 1][j], D[i][j - 1])。

通过分析可知,长度是 N 的字符串,计算矩阵的权重,算法需要 O(n ^ 2)的时间复杂度,这个性能不太好。
有些库使用了更精确的查分算法实现。
查分算法
基于“差分算法及其变体”(Myers,1986)中提出的算法。
这个算法比较复杂
按照我的理解,核心思想如下
感兴趣的朋友可以查找原文阅读 http://www.xmailserver.org/diff2.pdf
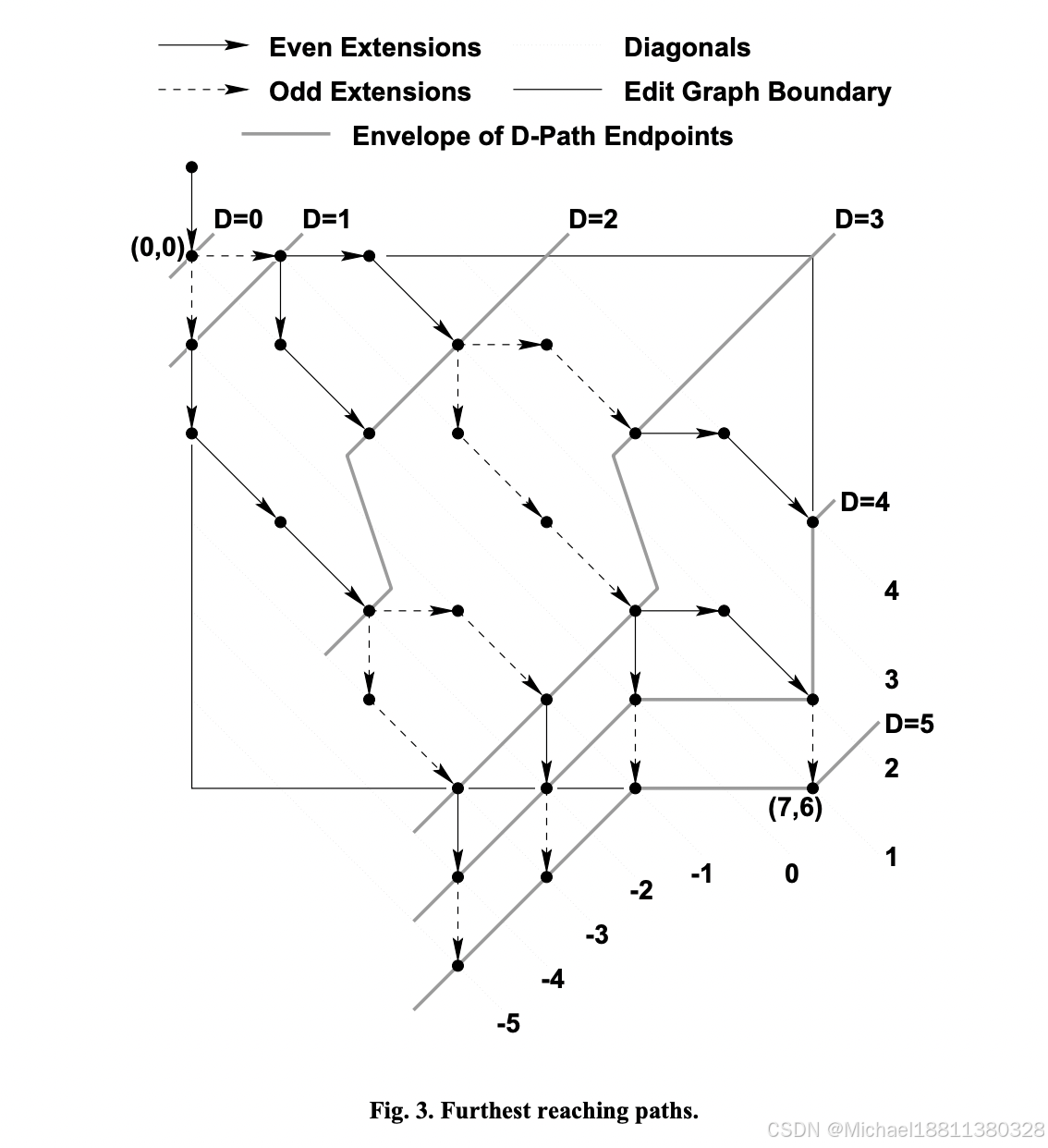
Broadly, jsdiff’s diff functions all take an old text and a new text and perform three steps:
Split both texts into arrays of “tokens”. What constitutes a token varies; in diffChars, each character is a token, while in diffLines, each line is a token.
Find the smallest set of single-token insertions and deletions needed to transform the first array of tokens into the second.
This step depends upon having some notion of a token from the old array being “equal” to one from the new array, and this notion of equality affects the results. Usually two tokens are equal if === considers them equal, but some of the diff functions use an alternative notion of equality or have options to configure it. For instance, by default diffChars(“Foo”, “FOOD”) will require two deletions (o, o) and three insertions (O, O, D), but diffChars(“Foo”, “FOOD”, {ignoreCase: true}) will require just one insertion (of a D), since ignoreCase causes o and O to be considered equal.
Return an array representing the transformation computed in the previous step as a series of change objects. The array is ordered from the start of the input to the end, and each change object represents inserting one or more tokens, deleting one or more tokens, or keeping one or more tokens.
diff 函数都接受一个旧字符串和一个新字符串,并执行三个步骤:
1、将两个文本拆分为“标记”数组,标记的构成各不相同;在diffChar中,每个字符都是一个标记,而在diffLines中,每一行都是标记。
2、找到将第一个 token 数组转换为第二个 token 数组所需的最小单 token 插入和删除集合。
这一步取决于让旧数组中的令牌与新数组中的标记“相等”,而这种相等的概念会影响结果。
通常,如果===认为两个标记相等,则这两个标记是相等的,但一些diff函数使用了另一种相等概念或有配置它的选项。例如,默认情况下,diffChar(“Foo”,“FOOD”)将需要两次删除(o,o)和三次插入(o,o,D),但diffChar(”Foo“,”FOOD“,{ignoreCase:true})将只需要一次插入(D),因为ignoreCase会导致 o 和 O 被视为相等。
3、返回一个数组,将上一步中计算的变换表示为一系列变化对象。数组从输入的开始到结束排序,每个更改对象表示插入一个或多个token、删除一个或更多个token或保留一个或更多个token。
其他改进的 diff 算法
查阅资料,基于上述基本的 diff 算法,很多学者提出了“最长公共子数组”算法,或者优化了虚拟 DOM 的 diff 算法。他们的思想也值得学习,限于篇幅不进行展开。感兴趣的朋友可以查找原始论文阅读。
说了很多理论知识,那么具体怎么在项目中使用呢?
下面就是若干具体使用的案例。
js 第三方库实现 diff
jsdiff 这个第三方库集成了 diff 算法,使用人数很多,项目中可以放心使用。
可以在 nodejs 实现,也可以在浏览器中实现
在 nodejs 中的案例如下
// jsdiff demo, reference: https://github.com/kpdecker/jsdiff// nodejs// "colors": "^1.4.0",// "diff": "^7.0.0"require('colors');const Diff = require('diff');// 核心:比较两个字符串的差异 Diff.diffChars(s1, s2)const diffList = Diff.diffChars('Hello Michael Blog', 'Hello Tom Blog');// 返回值是一个列表,然后循环用不同颜色展示diffList.forEach((part) => { let text = part.value; // green for additions if (part.added) { text = part.value.bgGreen; } // red for deletions if (part.removed) { text = part.value.bgRed; } process.stderr.write(text);});react 第三方库实现 diff-viewer
diff-viewer 是 diff 库在 react 框架中进一步的应用
// react-diff-viewer demo, reference: https://github.com/praneshr/react-diff-viewerimport React, { PureComponent } from 'react';import ReactDiffViewer from 'react-diff-viewer';// 两端代码(字符串)const oldCode = `const a = 10const b = 10const c = () => console.log('foo')if(a > 10) { console.log('bar')}console.log('done')`;const newCode = `const a = 10const boo = 10if(a === 10) { console.log('bar')}`;// 直接把代码传入组件中,即可展示。其他的属性和配置详见官方网站。class Diff extends PureComponent { render = () => { return ( <ReactDiffViewer oldValue={oldCode} newValue={newCode} splitView={true} /> ); };}export default Diff;python 库实现 diff
python 内置函数也实现了这个效果
import difflib# https://blog.csdn.net/molangmolang/article/details/138093020text1 = '一次性执行\nJS\nPY\nTS\n的单元测试'text2 = '一次性执行\njavascript\npython\ntypescript\n的单元测试'# 创建Differ对象differ = difflib.Differ()# 使用Differ对象生成差异报告# diff = differ.compare(text1.splitlines(' '), text2.splitlines(' '))diff = differ.compare(text1.splitlines(keepends=True), text2.splitlines(keepends=True))# 打印差异报告print(''.join(diff))手写 diff 算法实现
很多场景我们不能使用第三方库(管理层觉得第三方库太大,不用;或者管理层觉得维护很慢反,不用;或者自己写作为成果),所以可以自己简单实现一下这部分算法
diff-text.js 实现字符串的 diff
import ObjectUtils from './object-utils';// 字符串的 diff 关键是分词——按照空格回车换行符等,对字符串进行分词// 这里不同的算法给出的分词可能不一样,看实际需求是单词还是汉字等const extendedWordChars = 'a-zA-Z\\u{C0}-\\u{FF}\\u{D8}-\\u{F6}\\u{F8}-\\u{2C6}\\u{2C8}-\\u{2D7}\\u{2DE}-\\u{2FF}\\u{1E00}-\\u{1EFF}\\u{4e00}-\\u{9fa5}';const tokenText = new RegExp(`[${extendedWordChars}]+|\\s+|[^${extendedWordChars}]`, 'ug');const buildValues = (diff, components, newString, oldString, valueType, useLongestToken) => { let componentPos = 0; let componentLen = components.length; let newPos = 0; let oldPos = 0; for (; componentPos < componentLen; componentPos++) { let component = components[componentPos]; if (!component.removed) { if (!component.added && useLongestToken) { let value = newString.slice(newPos, newPos + component.count); // eslint-disable-next-line no-loop-func value = value.map((value, i) => { let oldValue = oldString[oldPos + i]; return oldValue.length > value.length ? oldValue : value; }); component.value = diff.join(value, valueType); } else { component.value = diff.join(newString.slice(newPos, newPos + component.count), valueType); } newPos += component.count; // Common case if (!component.added) { oldPos += component.count; } } else { component.value = diff.join(oldString.slice(oldPos, oldPos + component.count), valueType); oldPos += component.count; // Reverse add and remove so removes are output first to match common convention // The diffing algorithm is tied to add then remove output and this is the simplest // route to get the desired output with minimal overhead. if (componentPos && components[componentPos - 1].added) { let tmp = components[componentPos - 1]; components[componentPos - 1] = components[componentPos]; components[componentPos] = tmp; } } } // Special case handle for when one terminal is ignored (i.e. whitespace). // For this case we merge the terminal into the prior string and drop the change. // This is only available for string mode. let lastComponent = components[componentLen - 1]; if (componentLen > 1 && typeof lastComponent.value === 'string' && (lastComponent.added || lastComponent.removed) && diff.equals('', lastComponent.value)) { components[componentLen - 2].value += lastComponent.value; components.pop(); } return components;};const clonePath = (path) => { return { newPos: path.newPos, components: path.components.slice(0) };};class DiffText { constructor(oldValue, newValue, options = {}) { this.oldValue = oldValue; this.newValue = newValue; const oldValueType = ObjectUtils.getDataType(oldValue); const newValueType = ObjectUtils.getDataType(newValue); this.canCompare = true; if (oldValueType !== newValueType) { this.canCompare = false; return; } this.valueType = newValueType; this.callback = options.callback; const optionsType = ObjectUtils.getDataType(options); if (optionsType === 'function') { this.callback = options; this.options = {}; } else { this.options = {}; } this.comparePath = 1; this.oldValue = this.removeEmpty(this.tokenize(oldValue, oldValueType), oldValueType); this.oldLen = this.oldValue.length; this.newValue = this.removeEmpty(this.tokenize(newValue, newValueType), newValueType); this.newLen = this.newValue.length; this.maxEditLength = this.newLen + this.oldLen; if (this.options.maxEditLength) { this.maxEditLength = Math.min(this.maxEditLength, this.options.maxEditLength); } } done = (value) => { if (this.callback) { setTimeout(function () { this.callback(undefined, value); }, 0); return true; } return value; } // Main worker method. checks all permutations of a given edit length for acceptance. execCompareLength = (bestPath) => { for (let diagonalPath = -1 * this.comparePath; diagonalPath <= this.comparePath; diagonalPath += 2) { let basePath; let addPath = bestPath[diagonalPath - 1]; let removePath = bestPath[diagonalPath + 1]; let oldPos = (removePath ? removePath.newPos : 0) - diagonalPath; if (addPath) { // No one else is going to attempt to use this value, clear it bestPath[diagonalPath - 1] = undefined; } let canAdd = addPath && addPath.newPos + 1 < this.newLen; let canRemove = removePath && 0 <= oldPos && oldPos < this.oldLen; if (!canAdd && !canRemove) { // If this path is a terminal then prune bestPath[diagonalPath] = undefined; continue; } // Select the diagonal that we want to branch from. We select the prior // path whose position in the new string is the farthest from the origin // and does not pass the bounds of the diff graph if (!canAdd || (canRemove && addPath.newPos < removePath.newPos)) { basePath = clonePath(removePath); this.pushComponent(basePath.components, undefined, true); } else { basePath = addPath; // No need to clone, we've pulled it from the list basePath.newPos++; this.pushComponent(basePath.components, true, undefined); } oldPos = this.extractCommon(basePath, this.newValue, this.oldValue, diagonalPath); // If we have hit the end of both strings, then we are done if (basePath.newPos + 1 >= this.newLen && oldPos + 1 >= this.oldLen) { return this.done(buildValues(this, basePath.components, this.newValue, this.oldValue, this.valueType, this.useLongestToken)); } else { // Otherwise track this path as a potential candidate and continue. bestPath[diagonalPath] = basePath; } } this.comparePath++; } exec = (bestPath) => { setTimeout(function () { if (this.comparePath > this.maxEditLength) { return this.callback(); } if (!this.execCompareLength(bestPath)) { this.exec(bestPath); } }, 0); } pushComponent = (components, added, removed) => { let last = components[components.length - 1]; if (last && last.added === added && last.removed === removed) { // We need to clone here as the component clone operation is just // as shallow array clone components[components.length - 1] = { count: last.count + 1, added: added, removed: removed }; } else { components.push({ count: 1, added: added, removed: removed }); } } extractCommon = (basePath, newString, oldString, diagonalPath) => { let newLen = newString.length; let oldLen = oldString.length; let newPos = basePath.newPos; let oldPos = newPos - diagonalPath; let commonCount = 0; while (newPos + 1 < newLen && oldPos + 1 < oldLen && this.equals(newString[newPos + 1], oldString[oldPos + 1])) { newPos++; oldPos++; commonCount++; } if (commonCount) { basePath.components.push({ count: commonCount }); } basePath.newPos = newPos; return oldPos; } equals = (left, right) => { if (this.options.ignoreCase) { left = left.toLowerCase(); right = right.toLowerCase(); } return left.trim() === right.trim(); } removeEmpty = (array, type) => { if (type === 'Array') return array; let ret = []; for (let i = 0; i < array.length; i++) { if (array[i]) { ret.push(array[i]); } } return ret; } tokenize = (value, valueType) => { if (valueType === 'Array') { return value.slice(); } let parts = value.match(tokenText) || []; const tokens = []; let prevPart = null; parts.forEach(part => { if ((/\s/).test(part)) { if (prevPart == null) { tokens.push(part); } else { tokens.push(tokens.pop() + part); } } else if ((/\s/).test(prevPart)) { if (tokens[tokens.length - 1] === prevPart) { tokens.push(tokens.pop() + part); } else { tokens.push(prevPart + part); } } else { tokens.push(part); } prevPart = part; }); return tokens; } join = (value, valueType) => { if (valueType === 'Array') return value; // Tokens being joined here will always have appeared consecutively in the // same text, so we can simply strip off the leading whitespace from all the // tokens except the first (and except any whitespace-only tokens - but such // a token will always be the first and only token anyway) and then join them // and the whitespace around words and punctuation will end up correct. return value.map((token, i) => { if (i === 0) { return token; } else { return token.replace((/^\s+/), ''); } }).join(''); } getDiffs = () => { if (!this.canCompare) { return [ { value: this.oldValue, removed: true }, { value: this.newValue, added: true } ]; } let bestPath = [{ newPos: -1, components: [] }]; // Seed editLength = 0, i.e. the content starts with the same values let oldPos = this.extractCommon(bestPath[0], this.newValue, this.oldValue, 0); if (bestPath[0].newPos + 1 >= this.newLen && oldPos + 1 >= this.oldLen) { // Identity per the equality and tokenizer return this.done([{ value: this.join(this.newValue, this.valueType), count: this.oldValue.length }]); } // Performs the length of edit iteration. Is a bit fugly as this has to support the // sync and async mode which is never fun. Loops over execCompareLength until a value // is produced, or until the edit length exceeds options.maxEditLength (if given), // in which case it will return undefined. if (this.callback) { this.exec(bestPath); } else { while (this.comparePath <= this.maxEditLength) { let ret = this.execCompareLength(bestPath); if (ret) { return ret; } } } }}diff-string.js
// LCS 算法,用于找出两端字符串中最长子串,基本思路为 动态规划算法 DP,算法复杂度 O(n^2)function LcsFn(str1, str2) { const n1 = str1.length; const n2 = str2.length; // 建立空的二维数组,填充0,行列分别是两个字符串的长度 const lcsArr = new Array(n1 + 1).fill(null).map((_, index) => new Array(n2 + 1).fill(0)); // 使用动态规划存储子串长度 // 遍历矩阵 for (let i = 1; i < n1 + 1; i++) { for (let j = 1; j < n2 + 1; j++) { // 如果字符串的两个值相等,那么当前的值等于左上角的值 + 1 if (str1[i - 1] === str2[j - 1]) { lcsArr[i][j] = lcsArr[i - 1][j - 1] + 1; } // 如果字符串的两个值不等,那么当前值等于上面的值和左边的值的最大值。 else { lcsArr[i][j] = Math.max(lcsArr[i][j - 1], lcsArr[i - 1][j]); } } } const sameStr = getStr(str1, str2, lcsArr); return { str1, str2, lcsArr, sameStr }}// 根据二维数组,输出子串具体字符function getStr(str1, str2, lcsArr) { const result = [] let i = str1.length; let j = str2.length; // 使用双指针获取矩阵的索引 while (i > 0 && j > 0) { // 如果索引对应的字符串一样,那么把相同的字符,放到结束数组中(就是公共字符) // 如果索引对应的字符串不一样,比较矩阵的值,那么一个指针减少1 if (str1[i - 1] === str2[j - 1]) { result.unshift(str1[i - 1]) i-- j-- } else if (lcsArr[i][j - 1] > lcsArr[i - 1][j]) { j-- } else { i-- } } return result;}let str1 = 'hello-Mike-Hi'; // 最长相同子串为:'e,l,o,b,g' -- 长度9let str2 = 'hello-Tom-Hi'; // -- 长度14console.log(LcsFn(str1, str2));diff-tree.js
// 获取当前内容和旧内容之间的差异const getElementDiffValue = (currentContent, oldContent) => { // 初始化一个空 diff 对象,用于存储差异 let diff = { value: [], changes: [] }; // 生成id映射和id数组 const { map: currentContentMap, ids: currentIds } = generateIdMapAndIds(currentContent); const { map: oldContentMap, ids: oldIds } = generateIdMapAndIds(oldContent); // 获取当前ids和旧ids之间的id差异 const diffs = getIdDiffs(oldIds, currentIds); // 遍历全部不同的元素 diffs.forEach(diffItem => { // 1、被删除的元素 if (diffItem.removed) { diffItem.value.forEach(elementId => { diff.changes.push(elementId); // 获取被删除的元素 const element = oldContentMap[elementId]; // 生成被删除的元素的差异元素 const diffElement = generatorDiffElement(element, TEXT_STYLE_MAP.DELETE, DELETED_STYLE); // 将被删除的元素的差异元素添加到value数组中 diff.value.push(diffElement); }); // 2、被添加的元素 } else if (diffItem.added) { diffItem.value.forEach(elementId => { diff.changes.push(elementId); // 获取被添加的元素 const element = currentContentMap[elementId]; // 生成被添加的元素的差异元素 const diffElement = generatorDiffElement(element, TEXT_STYLE_MAP.ADD, ADDED_STYLE); // 将被添加的元素的差异元素添加到value数组中 diff.value.push(diffElement); }); // 3、被修改的元素 } else { diffItem.value.forEach(elementId => { const element = currentContentMap[elementId]; // 更新差异 updateDiffValue(diff, element, oldContentMap[element.id]); }); } }); // 返回差异 return diff;};// 获取新旧id之间的差异:创建一个DiffText对象,用于比较新旧idexport const getIdDiffs = (oldIds, newIds) => { const diff = new DiffText(oldIds, newIds); return diff.getDiffs();};// 获取两个值之间的差异 return { value: [], change: [] }export const getDiff = (currentValue = { children: [] }, oldValue = { children: [] }) => { // 如果两个值都为空,则返回空对象 if (!currentValue && !oldValue) { return { value: [], changes: [] }; } // 如果当前值为空,则返回旧值 if (!currentValue && oldValue) { return { value: normalizeChildren(oldValue.children), changes: [] }; } // 如果旧值为空,则返回当前值 if (currentValue && !oldValue) { return { value: normalizeChildren(currentValue.children), changes: [] }; } // 将当前值和旧值都转换为对象,并调用 normalizeChildren 函数,对 children 属性进行规范化 const { version: currentVersion, children: currentContent } = { ...currentValue, children: normalizeChildren(currentValue.children) }; const { version: oldVersion, children: oldContent } = { ...oldValue, children: normalizeChildren(oldValue.children) }; // 如果两个值的版本号相同,则返回当前值 if (currentVersion === oldVersion) { return { value: currentContent, changes: [] }; } else { // 如果两个值的版本号不同,调用getElementDiffValue函数获取两个值之间的差异 return getElementDiffValue(currentContent, oldContent); }};参考链接
jsdiff: https://github.com/kpdecker/jsdiff
An O(ND) Difference Algorithm and Its Variations: http://www.xmailserver.org/diff2.pdf
https://xueshu.baidu.com/usercenter/paper/show?paperid=1b0039833a74422f1de7e4286d40f30f
https://download.csdn.net/blog/column/8019278/88798916
https://www.cnblogs.com/wp-leonard/p/17888780.html
https://blog.csdn.net/m0_74931837/article/details/142443789
登录后可发表评论
点击登录