目录
一、文件准备二、Yolov8训练自己的数据集1.准备数据集2.处理数据3.环境配置4.下载权重文件5.开始训练 三、.PT 转换为 .ONNX四、.ONNX转换为 .RKNN1.虚拟机配置2.rknn转换环境配置安装转换环境RKNN转换 五、板端部署1.烧录系统2.环境配置3.进行识别 六、踩坑笔记ImportError: DLL load failed while importing onnx_cpp2py_export :动态链接库(DLL)初始化历程失败 七、致谢
一、文件准备
在开始部署之前,需要大家把教程所使用到的文件全部下载完成。(普通下载可能较慢,合理使用工具;如果有需要我可以把百度网盘链接放在评论区内,共大家下载!)
使用rknn修改后的ultralytics_yolov8项目到本地:ultralytics_yolov8
ONNX转换为RKNN模型需要使用官方rknn_model_zoo工具:rknn_model_zoo-2.2.0
该处环境部署代码使用到官方rknn-toolkit2工具:rknn-toolkit2
(这里使用的都是最新版本的2.2.0版本的,如果有使用其他版本的也可以。一定要注意版本对应,要不会出很多问题!很多人都是这个位置不注意导致出现各种不匹配的问题)
板端代码使用优化修改后的开源代码:rknn3588-yolov8
二、Yolov8训练自己的数据集
1.准备数据集
使用Labelimg或者Labelme对所识别的数据打标签。环境配置可以搜索CSDN上相关的文章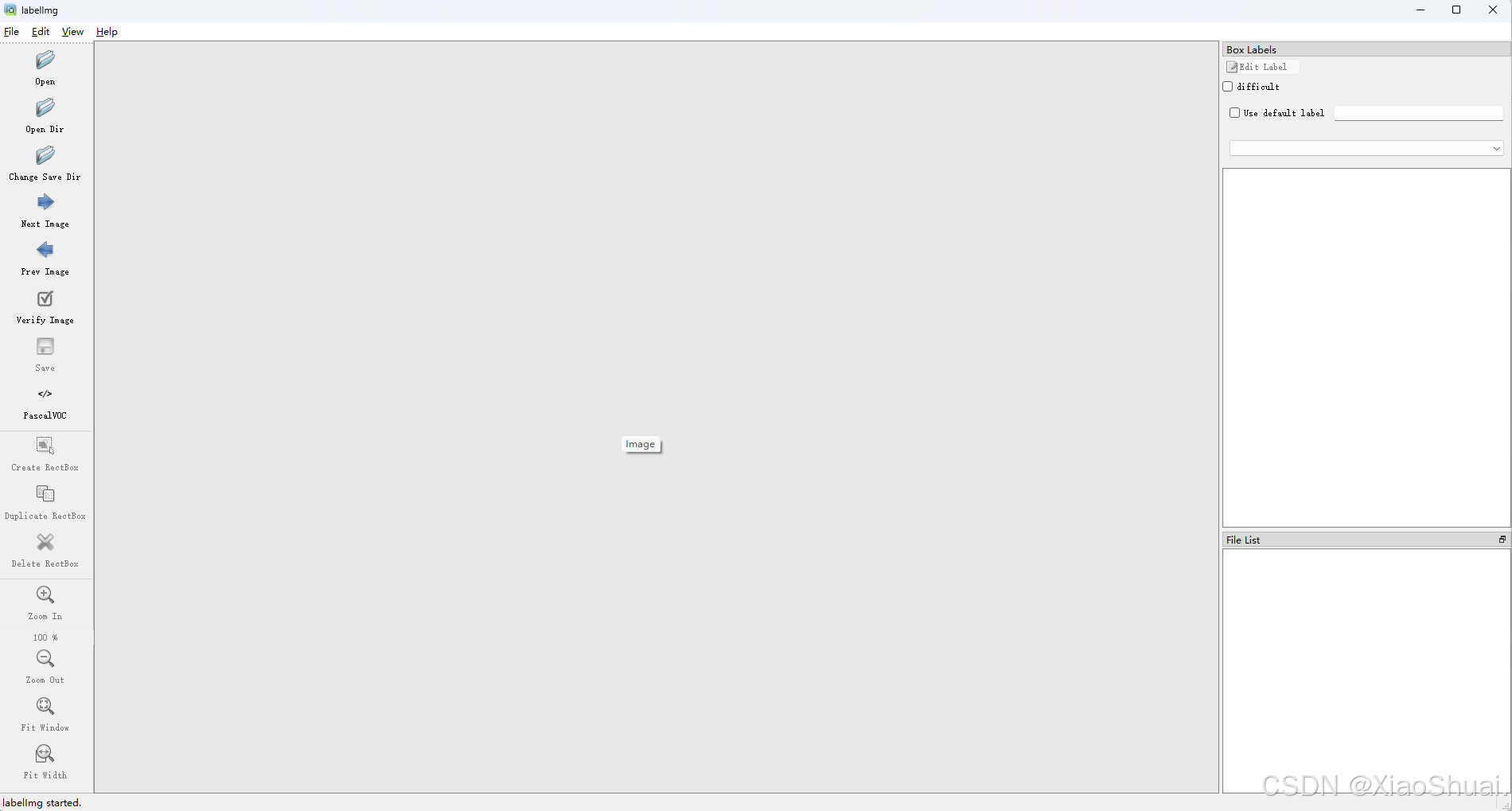 常规操作:(将原始图片存放在)
常规操作:(将原始图片存放在)
1.左侧栏 Open Dir 导入需要做标签的数据的文件夹;
2.Change Save Dir 选择保存标签文件(.xml)的文件夹;
3.按键A D分别代表上一张和下一张图片;
4.Ctrl+s 打完标签要及时保存;
5.Varify Image修改标签的数据格式。
(笔者这里保存的是 .xml的数据格式,包括后面对数据进行处理的代码也是适配的该格式的数据;其它的也可以使用,适合自己的才是最好的)
2.处理数据
dataset├─data_split - > split_train_val.py
├─images
├─labels
├─xml
└─data_label.py
将原始数据保存在images文件夹下;标签数据保存在xml文件夹下。
先运行下面的代码,把数据名称拆分出来;可以自行修改训练集和测试集的比例。
split_train_val.pyimport osimport randomtrainval_percent = 0.1train_percent = 0.9xmlfilepath = './dataset/xml'txtsavepath = './dataset/data_split'total_xml = os.listdir(xmlfilepath)num = len(total_xml)list = range(num)tv = int(num * trainval_percent)tr = int(tv * train_percent)trainval = random.sample(list, tv)train = random.sample(trainval, tr)ftrainval = open(txtsavepath + '/trainval.txt', 'w')ftest = open(txtsavepath + '/test.txt', 'w')ftrain = open(txtsavepath + '/train.txt', 'w')fval = open(txtsavepath + '/val.txt', 'w')for i in list: name = total_xml[i][:-4] + '\n' if i in trainval: ftrainval.write(name) if i in train: ftest.write(name) else: fval.write(name) else: ftrain.write(name)ftrainval.close()ftrain.close()fval.close()再运行data_label.py文件,生成转换后的 ./labels/.txt 文件,里面存放着类别、坐标信息。*
data_label.pyimport xml.etree.ElementTree as ETimport pickleimport osfrom os import listdir, getcwdfrom os.path import joinsets = ['train', 'test','val']classes = ['1', '2', '3']def convert(size, box): dw = 1. / size[0] dh = 1. / size[1] x = (box[0] + box[1]) / 2.0 y = (box[2] + box[3]) / 2.0 w = box[1] - box[0] h = box[3] - box[2] x = x * dw w = w * dw y = y * dh h = h * dh return (x, y, w, h)def convert_annotation(image_id): in_file = open('./dataset/xml/%s.xml' % (image_id)) out_file = open('./dataset/labels/%s.txt' % (image_id), 'w') tree = ET.parse(in_file) root = tree.getroot() size = root.find('size') w = int(size.find('width').text) h = int(size.find('height').text) for obj in root.iter('object'): difficult = obj.find('difficult').text cls = obj.find('name').text if cls not in classes or int(difficult) == 1: continue cls_id = classes.index(cls) xmlbox = obj.find('bndbox') b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text)) bb = convert((w, h), b) out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')wd = getcwd()print(wd)for image_set in sets: if not os.path.exists('./dataset/labels/'): os.makedirs('./dataset/labels/') image_ids = open('./dataset/data_split/%s.txt' % (image_set)).read().strip().split() list_file = open('./dataset/%s.txt' % (image_set), 'w') for image_id in image_ids: list_file.write('./dataset/images/%s.jpg\n' % (image_id)) convert_annotation(image_id) list_file.close()3.环境配置
打开下载好的ultralytics_yolov8文件。首先先配置环境(笔者这里使用的是Anaconda),下面是官方的requirement.txt文件;打开终端,运行以下命令即安装。
如果没有安装Anaconda,这里给大家附上一篇安装Anaconda的博客作为参考https://blog.csdn.net/weixin_43412762/article/details/129599741
pip install -r requirement.txt
requirement.txt
# Ultralytics requirements# Usage: pip install -r requirements.txt# Base ----------------------------------------matplotlib>=3.2.2numpy>=1.18.5opencv-python>=4.6.0Pillow>=7.1.2PyYAML>=5.3.1requests>=2.23.0scipy>=1.4.1torch>=1.7.0torchvision>=0.8.1tqdm>=4.64.0# Logging -------------------------------------tensorboard>=2.4.1# clearml# comet# Plotting ------------------------------------pandas>=1.1.4seaborn>=0.11.0# Export --------------------------------------# coremltools>=6.0 # CoreML export# onnx>=1.12.0 # ONNX export# onnx-simplifier>=0.4.1 # ONNX simplifier# nvidia-pyindex # TensorRT export# nvidia-tensorrt # TensorRT export# scikit-learn==0.19.2 # CoreML quantization# tensorflow>=2.4.1 # TF exports (-cpu, -aarch64, -macos)# tensorflowjs>=3.9.0 # TF.js export# openvino-dev>=2022.3 # OpenVINO export# Extras --------------------------------------ipython # interactive notebookpsutil # system utilizationthop>=0.1.1 # FLOPs computation# albumentations>=1.0.3# pycocotools>=2.0.6 # COCO mAP# roboflow如果网速太慢,可以配置清华源进行下载,分别运行以下命令进行操作即可完成配置。(设置默认)
python -m pip install -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple --upgrade pip
pip config set global.index-url https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
4.下载权重文件
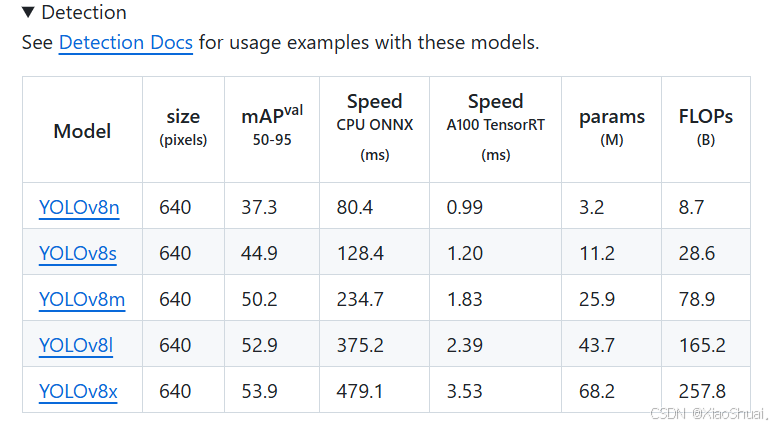
在Yolov8官方下下载所需要的权重文件,yolov8n、yolov8s等。这里给大家附上链接,如果有需要的我可以将下载好的发给大家。
https://github.com/Pertical/YOLOv8/tree/main
5.开始训练
在ultralytics_yolov8文件夹下首先要将训练集和测试集的路径以及类别数和名称写好。根据自己的类别数量以及名称进行修改
config.yaml
train: dataset/train.txtval: dataset/val.txttest: dataset/test.txt# number of classesnc: 3# class names names: [ '1', '2', '3']同时要在 ./ultralytics/cfg/models/v8 下的yolov8.yaml,修改类别数nc(和上面对应)。
train.py
from ultralytics import YOLO# 加载模型model = YOLO('weights/yolov8n.pt')# 训练模型results = model.train(data='config.yaml', epochs=300, imgsz=640, batch=16)# 在ultralytics/nn/modules/conv.py and block.py 中激活函数修改 nn.SiLU() 或 nn.ReLU()至此Yolov8有关自己数据集的模型训练完毕!
三、.PT 转换为 .ONNX
在当前目录下编写一个转换的Python脚本,内容如下。
Convert_onnx.py
from ultralytics import YOLOmodel = YOLO('mass.pt')results = model.export(format='rknn')运行该脚本即可完成转换(参数format为’rknn’,不是’onnx’)
注:如果报错 format里面没有’rknn’,就是文件下载错了。rknn对yolov8里面部分代码进行了修改,所以要下载rknn修改后的ultralytics_yolov8代码。链接都在文章开头处。
四、.ONNX转换为 .RKNN
1.虚拟机配置
首先需要准备一个安装有ubuntu22.04的虚拟机,具体流程:下载VMware,加载ubuntu-22.04.3-desktop-amd64.iso的镜像,一步一步进行操作。这一步网上有很多教程,可以网上搜索进行操作。
2.rknn转换环境配置
安装转换环境
在虚拟中首先要安装Miniconda,我是下载的Miniconda3-latest-Linux-x86_64.sh,下载好了放在根目录下,使用以下命令进行安装。
bash Miniconda3-latest-Linux-x86_64.sh
一路点空格,然后yes,回车完成安装。
打开终端,输入以下命令安装Python版本为3.8的环境。(这里如果觉得安装太慢,可以配置清华源,上面有说!)
conda create -n rknn python=3.8
将准备好的rknn-toolkit2-master文件,放在目录下。并进入到rknn-toolkit2-master/rknn-toolkit2/packages文件夹下。
首先先安装所用到的依赖包,在终端输入
pip install -r requirements_cp38-2.2.0.txt
接着安装rknn-toolkit2
pip install rknn_toolkit2-2.2.0-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl
至此rknn转换环境配置完成
RKNN转换
打开准备好的rknn_model_zoo-2.2.0文件夹,进入到examples/yolov8/python文件夹下。
先修改yolov8.py中的内容:
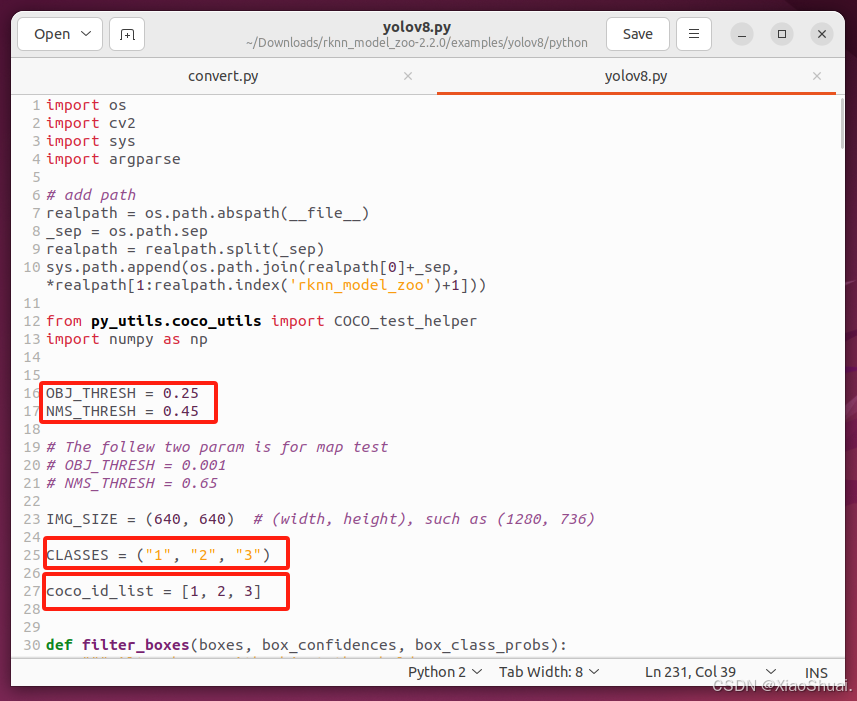 OBJ_THRESH,置信度阈值。提高OBJ_THRESH会减少检测到的框的数量,会增加检测的准确性;降低OBJ_THRESH会增加检测到的框的数量,可能会包含更多的误检。
OBJ_THRESH,置信度阈值。提高OBJ_THRESH会减少检测到的框的数量,会增加检测的准确性;降低OBJ_THRESH会增加检测到的框的数量,可能会包含更多的误检。
NMS_THRESH,非极大值抑制。较高的NMS_THRESH值允许更多重叠的框存在,而较低的值则会导致更多重叠框被抑制。
还需要修改 platform_target,根据所使用的设备进行填写。我这里使用的是rk3588的板子。现支持[rk3562,rk3566,rk3568,rk3576,rk3588,rk1808,rk1109,rk1126]
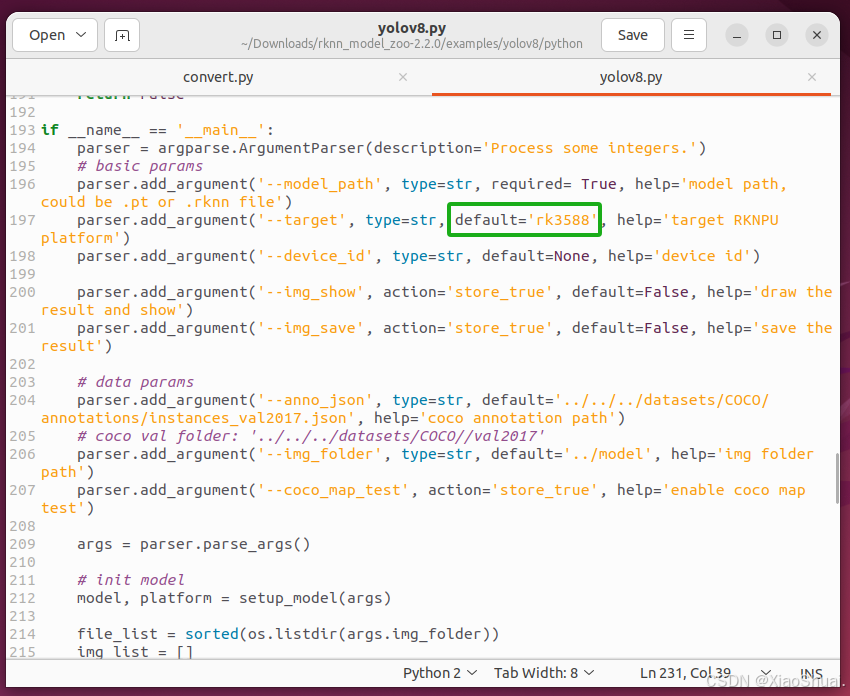
修改convert.py中的内容:
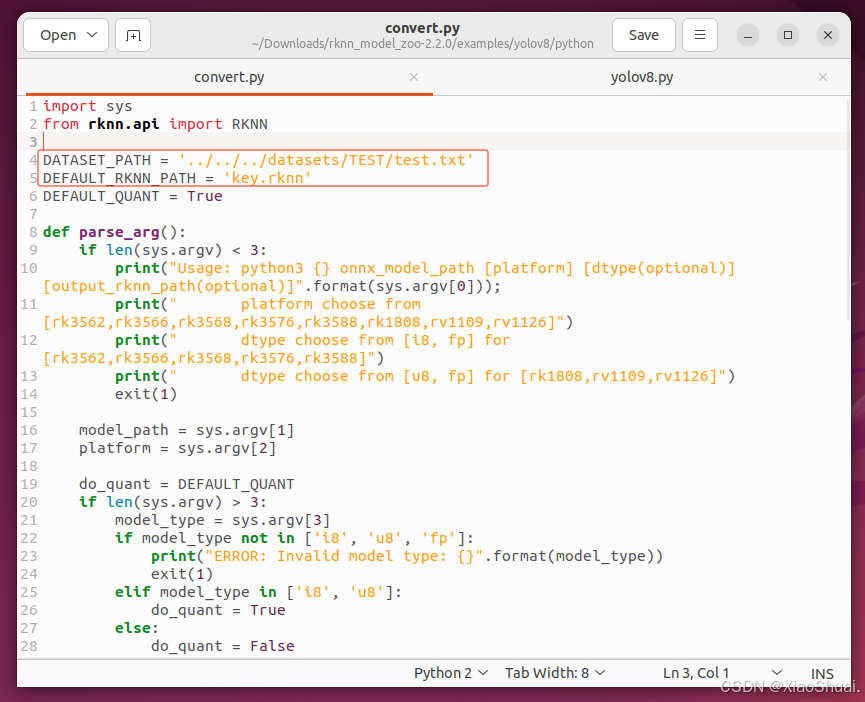
我这里是创建了一个测试文件夹,大家可以选择自己的目录。(注意修改路径)
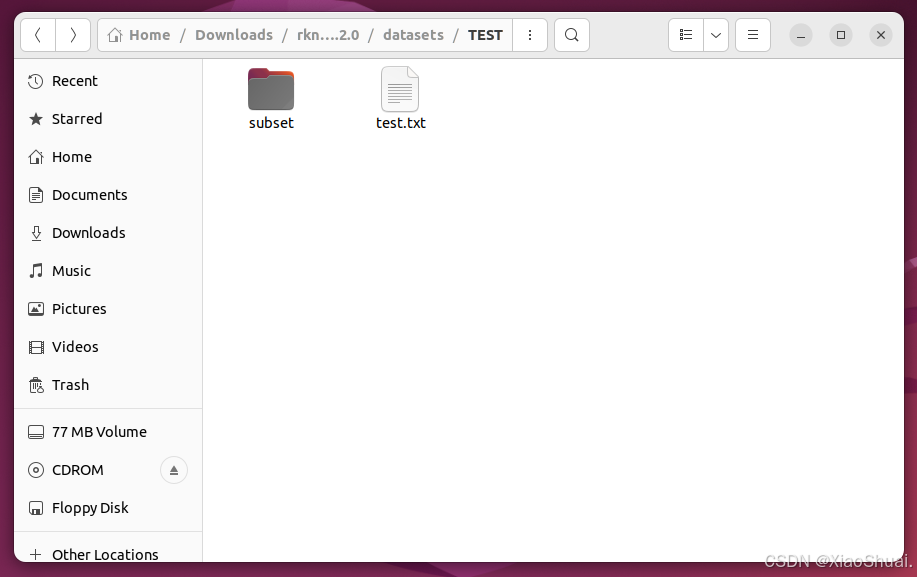
subset文件夹中存放大家测试的图片,图片中内容越丰富越好,将每张测试的图片保存下来,查看准确度,进行调参。知道转换出一个好的量化模型。
终端运行convert.py即可完成转换。
python convert.py key.onnx rk3588
至此模型量化完毕,得到 .RKNN。
五、板端部署
1.烧录系统
(1)下载好官方提供的镜像:镜像地址
(2)准备一个32G及以上的SD卡,使用balenaEtcher软件烧录镜像。
(3)SSH登录
为了方便操作,这里使用MobaXterm SSH远程登录设备。初次登录可以先将设备连接一个显示器,连接网络,在终端使用以下命令查看设备的ip地址。
ifconfig
2.环境配置
事先准备:将下载好的rknn-toolkit2-master文件下的rknpu2和rknn-toolkit-lite2拖到设备中的目录下。
(1)NPU驱动升级
使用以下命令来升级 RKNPU2 Runtime 库
cp ~/rknpu2/runtime/Linux/librknn_api/aarch64/librknnrt.so /usr/lib/librknnrt.so
因为rknn-toolkit2-2.0版本没有librknn_api.so,所以需要使用以下命令创建一个软连接到librknnrt.so。首先要在 /usr/lib下删除旧版本的librknn_api.so(如果有这个的话)。
sudo ln -s /usr/lib/librknnrt.so /usr/lib/librknn_api.so
(2)配置python运行环境
创建一个python=3.10的环境。
conda create -n rknn python=3.10
在rknn-toolkit-lite2/packages文件下安装rknn_toolkit_lite2-2.2.0包。
pip install rknn_toolkit_lite2-2.2.0-cp310-cp310-linux_aarch64.whl
创建其他python版本的环境也可,但需要安装对应版本的rknn_toolkit_lite2-2.2.0包。
接着安装opencv。(配置清华源)
pip install opencv_contrib_python
至此运行环境配置完毕
3.进行识别
将下载好的rknn3588-yolov8代码拖入设备中。
修改func.py中的内容:

这里的OBJ_THRESH,NMS_THRESH,IMG_SIZE,CLASSES要和转化成.RKNN中的参数保持一致
在main.py中修改modelPath到自己的模型,在终端运行main.py即开始识别。增加线程数TEPs
如果高帧率的识别,首先需要查看自己的摄像头的配置,查看摄像头最高支持多少FPS,以及对应的(CAP_PROP_FRAME_WIDTH,CAP_PROP_FRAME_HEIGHT)。在终端输入以下命令即可查看摄像头支持的格式、分辨率、帧率等信息。
v4l2-ctl --list-formats-ext
接着在main.py中设置摄像头的信息。(我这里的摄像头是最高支持60FPS)
cap = cv2.VideoCapture(0)cap.set(cv2.CAP_PROP_FOURCC, cv2.VideoWriter_fourcc('M', 'J', 'P', 'G'))cap.set(cv2.CAP_PROP_FRAME_WIDTH, 1280)cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 720)cap.set(cv2.CAP_PROP_FPS, 60)还有一个关键的一步,就是对NPU、CPU进行定频操作。这一步可以放到最前面执行。终端执行:
sudo bash performance.sh
使用下面明天可以查看当前温度与NPU占用
sudo bash rkcat.sh
六、踩坑笔记
ImportError: DLL load failed while importing onnx_cpp2py_export :动态链接库(DLL)初始化历程失败
解决方法如下:
卸载旧版本onnx,安装低版本的onnx
pip uninstall onnx
pip install onnx==1.16.1
七、致谢
笔者在部署时也频繁碰壁,大家遇到错误也不要着急,仔细查看报错原因,寻找解决方案。本文部分参考:
https://blog.csdn.net/A_l_b_ert/article/details/141610417