前言
在上一篇文章中【JVM入门食用指南-03】JVM垃圾回收器以及性能调优[1],对垃圾回收器以及JVM性能调优进行了叙述,并对JVM中CMS垃圾回收器进行了重点阐述。通过之前在JVM中的铺垫,本文我们回到Android中,本文我们主要对 Android虚拟机和类加载机制进行叙述,加深对 Android 的理解。
即将学会
- ART 和 Dalvik
- Android 类加载流程
- 热修复实现原理
ART 与 Dalvik
JVM 与 DVM
JVM 是我们的 Java 虚拟机,而我们的Android应用运行在 Dalvik/ART 虚拟机上的。每一个应用对应一个 Dalvik 虚拟机,虽然 Dalvik 虚拟机也算 Java 虚拟机,不过执行的不是.class文件,而是dex文件。

这里对上述名词进行一些叙述
虚拟机分类
基于栈的虚拟机 每一个运行的线程,都有一个独立的栈,栈中记录了方法调用的历史,每一个方法的调用,都对应一个栈帧,并且将栈帧压入栈中,最顶部的栈帧为当前栈帧,既 当前执行的方法,基于栈帧 与 操作数栈进行所有操作。
寄存器 CPU的组成部分,寄存器是有限存储容量的高速存储容器(计算机中各级存储速度 寄存器-> 一级缓存->二级缓存 -> 内存 -> 硬盘),可以用来管理指令、数据的地址。
基于寄存器的虚拟机 (模拟寄存器的操作流程)
基于寄存器的虚拟机中没有操作数栈,不过有很多虚拟寄存器,类似操作数栈,这些寄存器也存放在运行时栈中,本质上就是一个数组,与JVM相似,在Dalvik 虚拟机中每个线程都有自己的PC 和 调用栈,方法调用的活动记录以帧为单位保存在调用栈上。
不同虚拟机流程
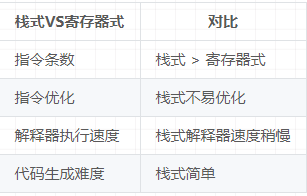
我们对比一下 基于栈的流程 和 基于寄存器的流程

JVM流程分析参考之前文章分析,通常需要经过以下操作
- 如将栈顶某类型值存入局部变量某处
- 将局部变量中某处某类型常量压入操作数栈
- 执行相关指令

DVM 中,直接依据指令,将某类型值存入虚拟寄存器中,相关的操作也依据指令在虚拟寄存器中通过CPU处理,将处理结果返回虚拟寄存器(省掉了基于栈的流程中局部变量与操作数栈中数据的流动)
ART 与 Dalvik 区别

ART 和 Dalvik 都是基于寄存器的虚拟机
Dalvik 执行 dex字节码,解释执行,在Android2.2 开始,支持即时编译,既选择程序中经常执行的代码(又称热点代码),进行编译和优化 减少了JVM中解释的流程。
ART虚拟机 (Android4.4) 直接跑机器码,不进行字节码解释。Android的运行时从Dalvik 无影响过渡ART,因为并不用开发者将应用直接编译成目标机器码,APk依旧是一个包含dex字节码的文件。
为什么APK依旧是包含dex字节码的文件,而ART和 Dalvik的执行方式不一样?
这里ART直接跑字节码,而Dalvik进行解释执行,并在2.2引入JIT,但是都是dex文件。
因为APK文件需要在Android系统中运行,需要进行安装,这个时候,经过虚拟机,会对dex进行优化,Dalvik中,会将dex字节码进行优化生成odex文件,而ART 会将 dex字节码翻译为本地机器码(引入了预先编译机制 Ahead of Time),安装时,ART使用设备自带的dex2oat工具对应用进行编译。dex中的字节码被编译成本地机器码,这也是为什么我们安装的时候比较慢。
不过后面从Android O 开始,安装速度变快了,因为这个时候采用混合编译了,JIT、AOT、和字节码解释。 当应用首次安装时,不进行AOT编译,运行过程中采用解释执行,并将程序中经常要执行的代码进行即时编译(JIT),并将JIT编译后的方法记录到Profile配置文件,当设备闲置时,利用编译守护进程,依据Profile文件对常用文件进行AOT编译(生成.art文件),以便下次运行时直接使用。如果下次程序运行,将检测该文件并解析出机器码中文件中的类信息,加载到ClassLoader中。
ClassLoader 及 类加载流程
ClassLoader
每一个Java程序都是有一个或多个class文件组成,在程序运行时,需要将class文件加载到JVM中才可以使用,而加载class文件的是Java的类加载机制,ClassLoader加载class文件提供程序运行时使用,每个Class对象内部都有一个classLoader字段来标识由何种classLoader加载。
ClassLoader 类 以及 类结构
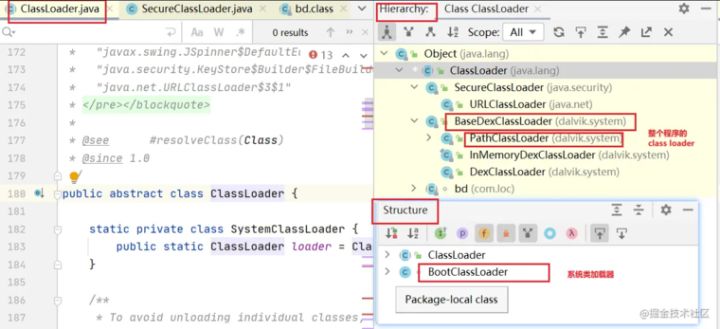

- ClassLoader
- BootClassLoader 用于加载Android Framework 层 Class文件(像String.Class)
- PathClassLoader 继承自ClassLoader 用于Android应用程序加载类
类加载流程
PathClassLoader
下面我们分析一下PathClassLoader类来分析类加载流程
/**
* Loads the class with the specified <a href="#name">binary name</a>. The
* default implementation of this method searches for classes in the
*/
// Android-removed: Remove references to getClassLoadingLock
// Remove perf counters.
//
// <p> Unless overridden, this method synchronizes on the result of
// {@link #getClassLoadingLock <tt>getClassLoadingLock</tt>} method
// during the entire class loading process.
//
protected Class<?> loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
//找缓存,已经加载过的就不会被加载了
//class文件需要转换为class对象 耗时操作
// First, check if the class has already been loaded
Class<?> c = findLoadedClass(name);
//没有缓存进if
if (c == null) {
try {
//如果该类下的parent对象实例不为空,利用该parent对象加载相关类
//该对象指向 BootClassLoader 如下图所示
if (parent != null) {
c = parent.loadClass(name, false);
} else {
//parent 为空,返回空
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// ClassNotFoundException thrown if class not found
// from the non-null parent class loader
}
if (c == null) {
// If still not found, then invoke findClass in order
// to find the class.
//如果 parent(BootstrapClass)中加载不到该类
//则 调用自身findClass去加载类(PathClassLoader)
c = findClass(name);
}
}
//有缓存直接返回
return c;
}
/**
* Returns a class loaded by the bootstrap class loader;
* or return null if not found.
*/
private Class<?> findBootstrapClassOrNull(String name)
{
return null;
}我们可以通过上述代码分析 和 PathClassLoader类结构图得到该类的loadClass流程
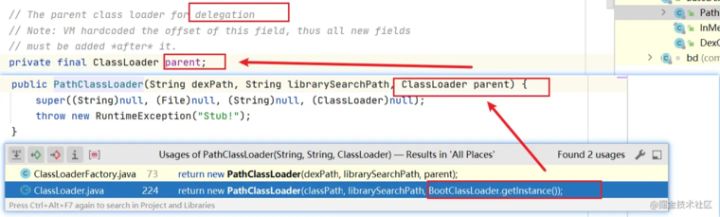
那么为什么我们ClassLoader中要进行这样的设计呢 ?
首先,这个parent的目的在于实现类加载的双亲委托,首先加载任务委托给父类加载器,依次递归,如果父类加载器可以完成类加载任务,则成功返回,只有父类加载器无法完成此加载任务时,才自己去完成加载。 而实现这种机制,可以达到以下效果
- 避免重复加载,当parent对应的加载器已经加载了该类的时候,就没有必有当前classloader再加载一次,直接在parent中的缓存找。
- 安全考虑,防止核心API被篡改,像自己定义一个String.java 这个时候classloader会先加载framework中的String.java(加载只要全限定名一样,可以伪造构建和系统类一样的全限定名)
上面我们分析了它的设计思想,回归加载过程中,这里用到了findClass(name) 方法
findClass(name) 又做了什么?
我们可以通过查看其自身和父类寻找findClass方法,通过查看
@Override
protected Class<?> findClass(String name) throws ClassNotFoundException {
List<Throwable> suppressedExceptions = new ArrayList<Throwable>();
//通过pathList 去找 相关 类,而pathList 是 DexPathList 是 final 的
Class c = pathList.findClass(name, suppressedExceptions);
//知道了 返回 Class相关实例对象,没找到抛异常 关键在上一行代码
if (c == null) {
ClassNotFoundException cnfe = new ClassNotFoundException(
"Didn't find class \"" + name + "\" on path: " + pathList);
for (Throwable t : suppressedExceptions) {
cnfe.addSuppressed(t);
}
throw cnfe;
}
return c;
}
//上述pathList 声明 是不可变的 我们去查看其赋值
private final DexPathList pathList;
//pathList 又是由什么赋值 可以看到相关使用在构造方法中
// 通过查看其构造方法,可知我们需要传入 dexPath 去 实例化 DexPathList
// 因此PathClassLoader才可以加载到程序的所有类
/**
* @hide
*/
public BaseDexClassLoader(String dexPath, File optimizedDirectory,
String librarySearchPath, ClassLoader parent, boolean isTrusted) {
super(parent);
//我们跳去 DexPathList 看看
this.pathList = new DexPathList(this, dexPath, librarySearchPath, null, isTrusted);
if (reporter != null) {
reportClassLoaderChain();
}
}
// 我们看一下DexPathList
DexPathList(ClassLoader definingContext, String dexPath,
String librarySearchPath, File optimizedDirectory, boolean isTrusted) {
//常规 参数判空
if (definingContext == null) {
throw new NullPointerException("definingContext == null");
}
if (dexPath == null) {
throw new NullPointerException("dexPath == null");
}
if (optimizedDirectory != null) {
if (!optimizedDirectory.exists()) {
throw new IllegalArgumentException(
"optimizedDirectory doesn't exist: "
+ optimizedDirectory);
}
if (!(optimizedDirectory.canRead()
&& optimizedDirectory.canWrite())) {
throw new IllegalArgumentException(
"optimizedDirectory not readable/writable: "
+ optimizedDirectory);
}
}
this.definingContext = definingContext;
ArrayList<IOException> suppressedExceptions = new ArrayList<IOException>();
// save dexPath for BaseDexClassLoader
// 这里使用到了 dexpath
// splitDexPath 将dexpath的多地址分离 , PathClassLoader 可以处理多个dex
// makeDexElements 依据dexpath生成多个dexElement
// 下面我们去看一下splitDexPath 和 makeDexElements
this.dexElements = makeDexElements(splitDexPath(dexPath), optimizedDirectory,
suppressedExceptions, definingContext, isTrusted);
this.nativeLibraryDirectories = splitPaths(librarySearchPath, false);
this.systemNativeLibraryDirectories =
splitPaths(System.getProperty("java.library.path"), true);
List<File> allNativeLibraryDirectories = new ArrayList<>(nativeLibraryDirectories);
allNativeLibraryDirectories.addAll(systemNativeLibraryDirectories);
this.nativeLibraryPathElements = makePathElements(allNativeLibraryDirectories);
if (suppressedExceptions.size() > 0) {
this.dexElementsSuppressedExceptions =
suppressedExceptions.toArray(new IOException[suppressedExceptions.size()]);
} else {
dexElementsSuppressedExceptions = null;
}
}
//splitDexPath 方法
private static List<File> splitDexPath(String path) {
return splitPaths(path, false);
}
/**
* Splits the given path strings into file elements using the path
* separator, combining the results and filtering out elements
* that don't exist, aren't readable, or aren't either a regular
* file or a directory (as specified). Either string may be empty
* or {@code null}, in which case it is ignored. If both strings
* are empty or {@code null}, or all elements get pruned out, then
* this returns a zero-element list.
*/
private static List<File> splitPaths(String searchPath, boolean directoriesOnly) {
List<File> result = new ArrayList<>();
if (searchPath != null) {
for (String path : searchPath.split(File.pathSeparator)) {
if (directoriesOnly) {
try {
StructStat sb = Libcore.os.stat(path);
if (!S_ISDIR(sb.st_mode)) {
continue;
}
} catch (ErrnoException ignored) {
continue;
}
}
result.add(new File(path));
}
}
return result;
}
//makePathElements 方法
private static final String zipSeparator = "!/";
private static NativeLibraryElement[] makePathElements(List<File> files) {
// 一个dex 生成一个 elements 对象
NativeLibraryElement[] elements = new NativeLibraryElement[files.size()];
int elementsPos = 0;
for (File file : files) {
String path = file.getPath();
if (path.contains(zipSeparator)) {
String split[] = path.split(zipSeparator, 2);
File zip = new File(split[0]);
String dir = split[1];
elements[elementsPos++] = new NativeLibraryElement(zip, dir);
} else if (file.isDirectory()) {
// We support directories for looking up native libraries.
elements[elementsPos++] = new NativeLibraryElement(file);
}
}
if (elementsPos != elements.length) {
elements = Arrays.copyOf(elements, elementsPos);
}
return elements;
}
这里,我们了解到了pathList这个对象为了findClass做了什么准备,现在,我们回到BaseClassLoader 中的 findClass 方法中,继续看pathList这一行代码,pathList这个实例我们已经知晓了,现在看它调用的findClass方法(和BaseClassLoader中不一样)
//在这里,我们可以看到 该方法使用到了刚才 pathList 中 dexElements数组
// 通过遍历 每一个 Element 遍历所有的dex
// DexFile dex = element.dexFile; 拿到对应的 DexFile
// dex.loadClassBinaryName(name, definingContext, suppressed);
// 再通过每个dex 的 loadClassBinaryName 去将类找出
/**
* Finds the named class in one of the dex files pointed at by
* this instance. This will find the one in the earliest listed
* path element. If the class is found but has not yet been
* defined, then this method will define it in the defining
* context that this instance was constructed with.
*
* @param name of class to find
* @param suppressed exceptions encountered whilst finding the class
* @return the named class or {@code null} if the class is not
* found in any of the dex files
*/
public Class findClass(String name, List<Throwable> suppressed) {
for (Element element : dexElements) {
DexFile dex = element.dexFile;
if (dex != null) {
Class clazz = dex.loadClassBinaryName(name, definingContext, suppressed);
if (clazz != null) {
return clazz;
}
}
}
if (dexElementsSuppressedExceptions != null) {
suppressed.addAll(Arrays.asList(dexElementsSuppressedExceptions));
}
return null;
}
大致的类加载流程就如上所示
热修复原理
那么,通过类加载流程,我们这个时候可以在这之上进行一下热修复

当我们程序有Bug时,我们对相关类进行修改,并将修改后的类打包成补丁dex,当客户端下载时,只要让补丁包加载在类加载之前,就可以提前加载到虚拟机中,而有错误的类,因为类加载机制问题,不会重复加载,从而不会加载到错误类,进而实现修复。
热修复原理大致代码流程
//相关正常修复类打补丁包
dx --dex --output=output.dex xxx.jar
dx --dex --output=output.dex 类全限定名
在Application类中 重写 attachBaseContext 并在super后 调用 热修复
并传入Application,补丁dex文件至热修复类
//热修复类中
//1、获得classloader(PathClassLoader)
ClassLoader classLoader = application.getClassLoader();
//2\. 不同的Android 版本 ,热修复有所差异,需要对其适配 (以6.0为例)
//3\. 遍历该类及超类
Class<?> clazz = classLoader.getClass(); clazz != null; clazz = clazz.getSuperclass()
//4.通过反射 获取 pathList 属性成员
Field field = clazz.getDeclaredField("pathList");
//5.获取到pathList对象
Object dexPathList = pathListField.get(classLoader);
///将自己的补丁包转换为Element数组 参考PathClassLoader
// 得到补丁包的Element数组
// 反射拿到 makePathElements 方法
Class<?> clazz = dexPathList.getClass(); clazz != null; clazz = clazz.getSuperclass()
Method method = clazz.getDeclaredMethod("makePathElements", parameterTypes);
//反射执行方法 返回 补丁包对应的 Element数组
Object[] patchElements = (Object[]) method.invoke(dexPathList, files, optimizedDirectory,
suppressedExceptions)
//将原本的 dexElements 与 makePathElements生成的数组合并,并利用反射塞回 dexElements
//拿到 classloader中的dexelements 数组
Class<?> clazz = dexPathList.getClass(); clazz != null; clazz = clazz.getSuperclass()
Field dexElementsField = clazz.getDeclaredField("dexElements");
//old Element[]
Object[] dexElements = (Object[]) dexElementsField.get(dexPathList);
//合并后的数组
Object[] newElements = (Object[]) Array.newInstance(dexElements.getClass().getComponentType(),
dexElements.length + patchElements.length);
// 先拷贝新数组
System.arraycopy(patchElements, 0, newElements, 0, patchElements.length);
System.arraycopy(dexElements, 0, newElements, patchElements.length, dexElements.length);
//修改 classLoader中 pathList的 dexelements
dexElementsField.set(dexPathList, newElements);
上述只是依据类加载原理进而对热修复原理进行阐述的大致流程,实现热修复还需要考虑到一下兼容问题、混淆等内容。