前言
Bert/Transformer结构及其变体,已成为自然语言处理 (NLP)、语音识别 (ASR)等领域的主流序列建模结构。并且,相比于卷积操作的局部特征提取能力、以及平移不变性,Self-attention的全局Context信息编码能力,能够使视觉模型具备更强的特征表达能力、与领域适应性。因此在计算机视觉领域,Vision Transformer结构也日益流行、方兴未艾。然而,Transformer模型的高计算复杂度与参数量,限制了模型的推理部署(包括服务端与移动端应用),其计算、存储与运行时内存等资源开销都成为限制因素。例如,从标准Transformer layer的Tensor处理结构来看,计算量与序列长度、特征维度的平方成正比:
- Standard Self-Attention:
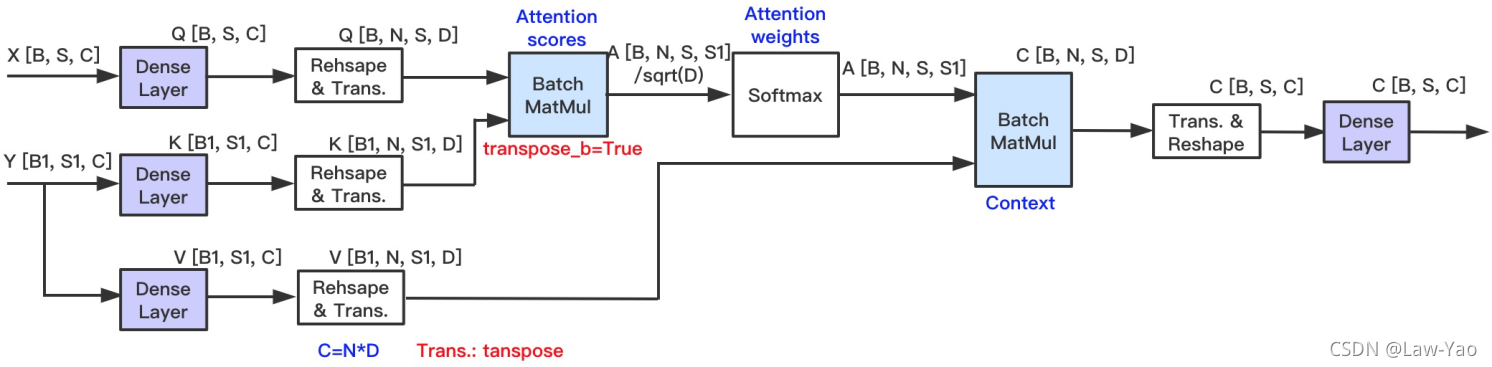
- Standard FFN:

本文从以下几个维度举例说明,解析Bert/Transformer模型的加速方法:
- 模型结构精简化与知识蒸馏;
- 模型量化 (Quantization);
- 网络结构搜索 (NAS: Network Architecture Search);
- 计算图优化;
- 推理优化引擎 (Faster Transformer);
模型结构精简化与知识蒸馏
Lite-Transformer
参考文献: https://arxiv.org/abs/2004.11886
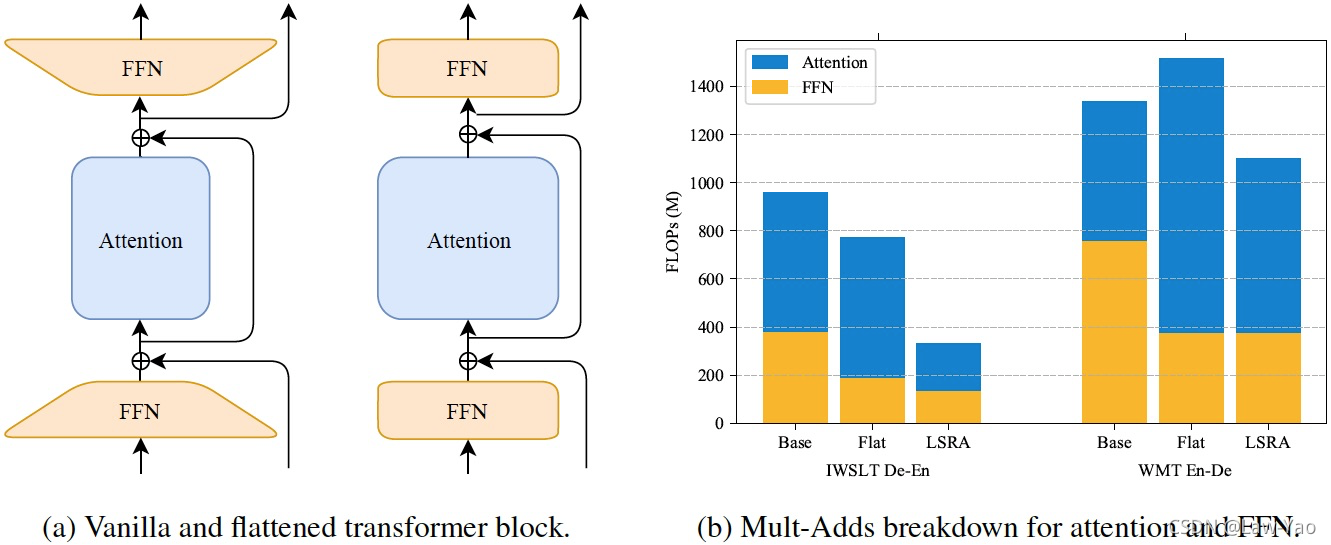
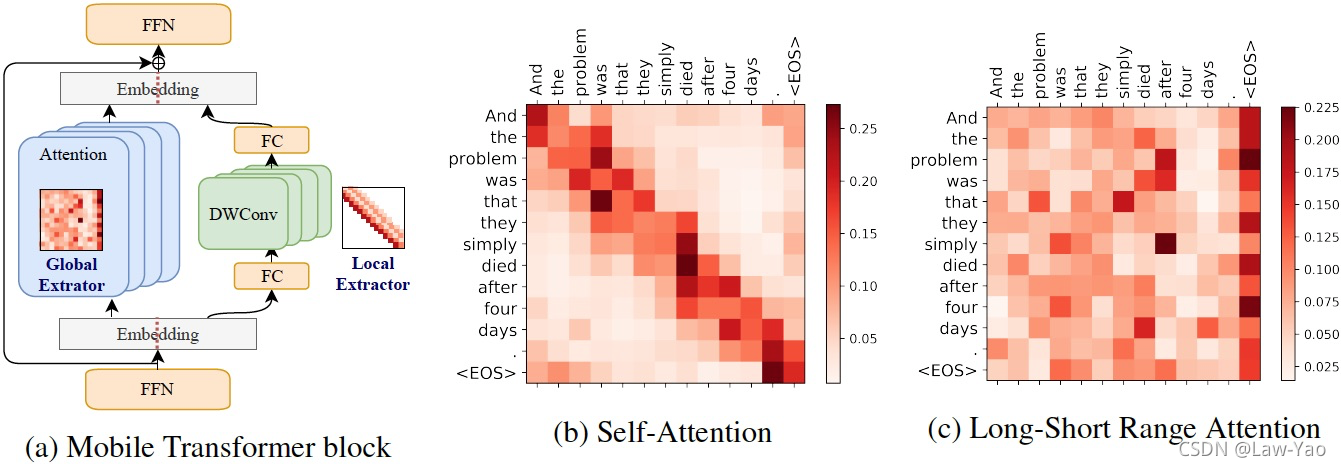
Lite Transformer是一种融合卷积与Self-attention操作的、高效精简的Transformer结构,可应用于NMT、ASR等序列生成任务。其核心是长短距离注意力结构 (LSRA:Long-Short Range Attention)。LSRA将输入Embedding沿Feature维度split成两部分,其中一部分通过GLU (Gate Linear Unit)、一维卷积,用以提取局部Context信息;而另一部分依靠Self-attention,完成全局相关性信息编码。Lite Transformer核心结构如下:
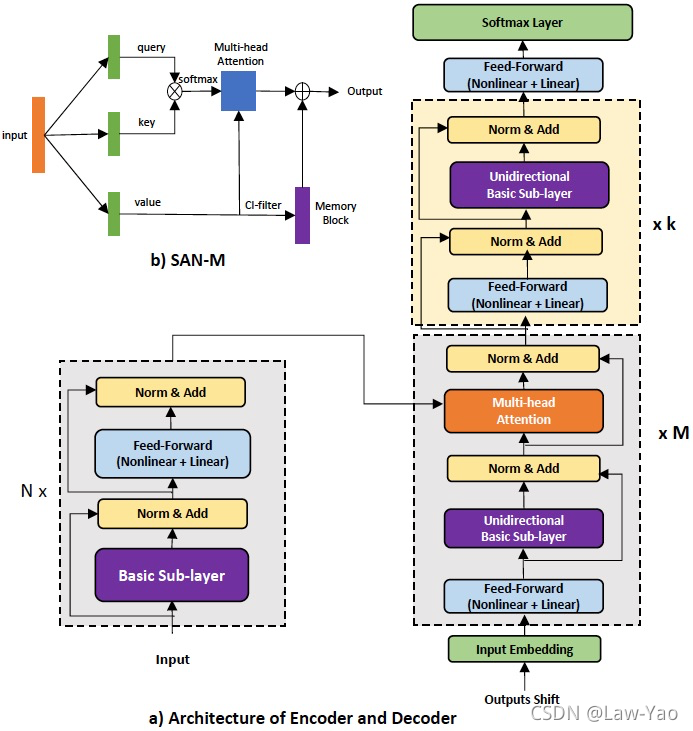
SAN-M
参考文献: https://arxiv.org/abs/2006.01713
SAN-M表示Self-attention与DFSMN记忆单元的融合,是一种Transformer ASR模型。DFSMN适合捕获局部信息,Self-attention模块具备较强的长时依赖捕获能力,因此二者存在互补性。SAN-M通过将两个模块的特性融合在一起,实现了优势互补。Biasic Sub-layer表示包含了SAN-M的Self-attention layer,DFSMN添加在values后面,其输出与Multi-head Attention (MHA)相加:
![]()
MiniLM (知识蒸馏)
参考文献: https://arxiv.org/abs/2002.10957
针对NLP任务,深度自注意力知识蒸馏 (Deep Self-Attention Distillation),通过迁移Teacher model最后一层Self-attention layer的Attention score信息与Value relation信息,可有效实现Student model的诱导训练。只迁移最后一层的知识,显得简单有效、训练速度更快,而且不需要手动设计Teacher-student之间的层对应关系。Attention score信息与Value relation信息的知识迁移如下:
- Attention score transfer:
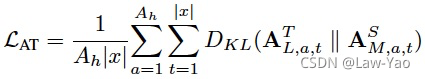
- Value relation transfer:
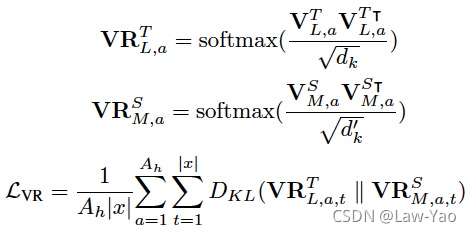
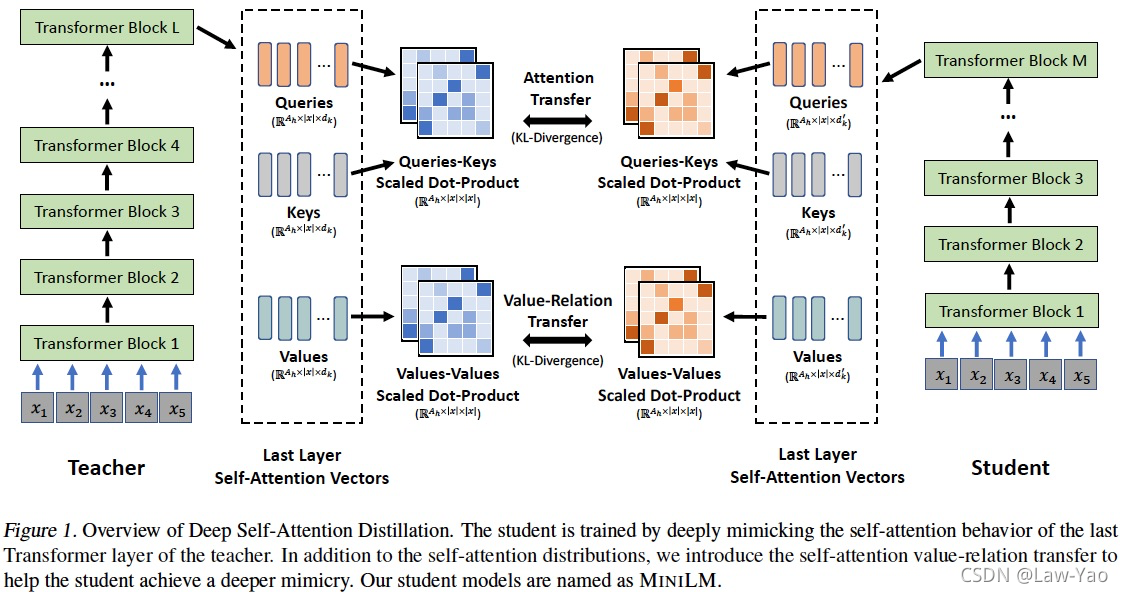
- 若选择的Self-attention layer为LSRA,除了在multi-head self-attention分支迁移attention score与value relation;在CNN分支需要迁移feature map的信息,这里主要计算AT loss:
式中Fs,j表示学生网络里第j个网络层的特征输出,Ft,j表示teacher network里第j个group的特征输出。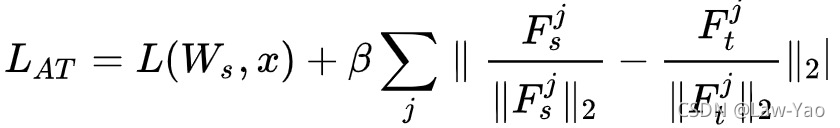
模型量化 (Quantization)
Transformer ASR模型压缩
参考文献: https://arxiv.org/abs/2104.05784
针对Transformer ASR,文章提出了联合随机稀疏与PTQ量化 (KL量化、ADMM与混合精度设置)的压缩策略,整体实现了10倍压缩,且绝对精度损失约0.5%。总体流程如下:
- 模型稀疏化,更新Weight重要性:
![]()
- KL量化,计算Activation量化参数:
![]()
- ADMM,优化Weight量化参数:
![]()
![]()
- 混合精度量化设置,减少量化误差:
![]()
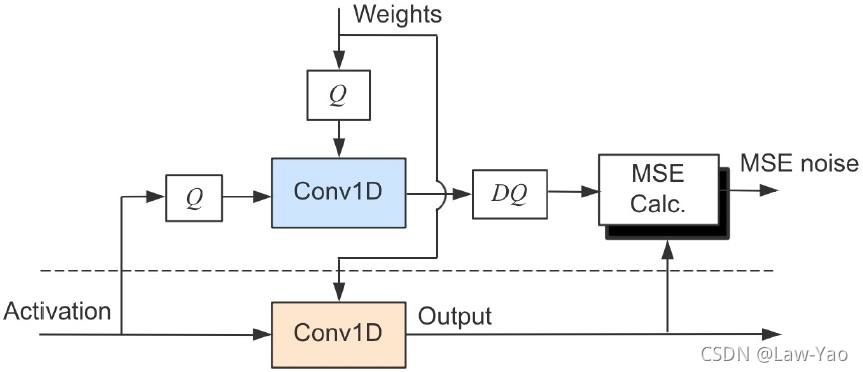
此外,针对Transformer模型的量化,需要讨论全网络INT8量化与计算的意义:
- 全网络INT8量化:
- 同时减少计算密集算子与访存密集算子的开销;
- 实现模型压缩,INT8模型是FP32模型的1/4;
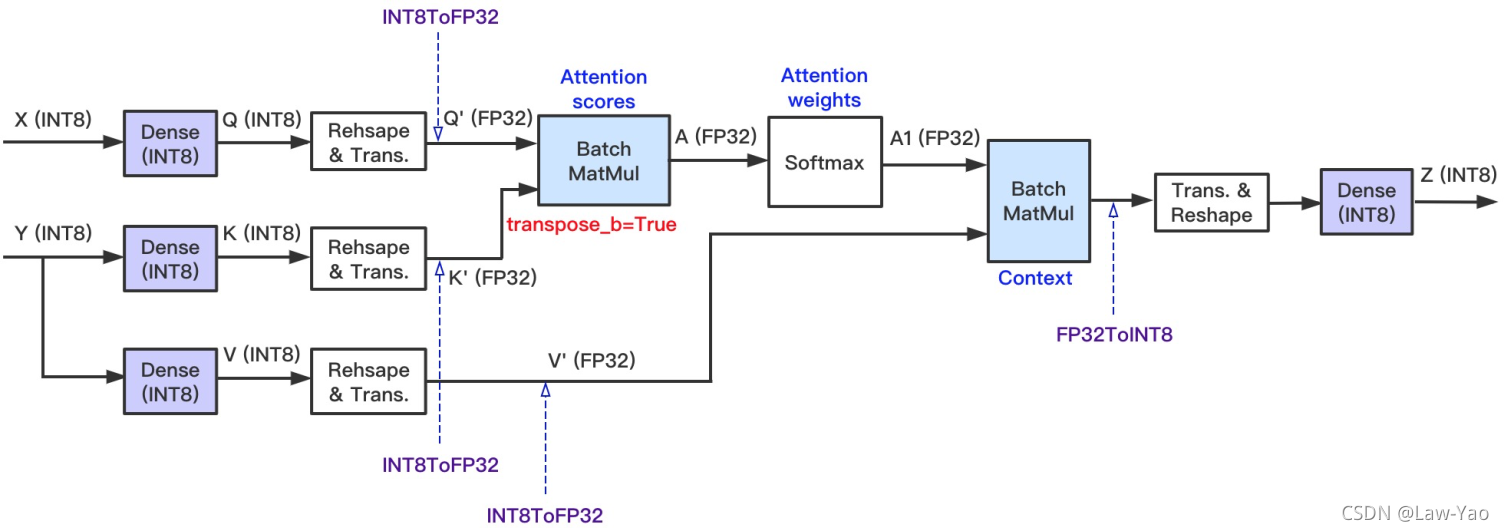
- Fully INT8 Attention Path:
- 基本的全INT8通路:
- Dense layer的输入与输出均为INT8 Tensor;
- Reshape与Transpose的操作对象为INT8 Tensor,节省内存开销:
- Dense+Reshape+Transpose、与Transpose+Reshape+Dense可以实现Op fusion;
- BatchMatMul、Softmax的操作对象保留为FP32 Tensor,确保模型预测精度;
- 基本的全INT8通路:
- Encoder的Self-attention:
- X=Y;
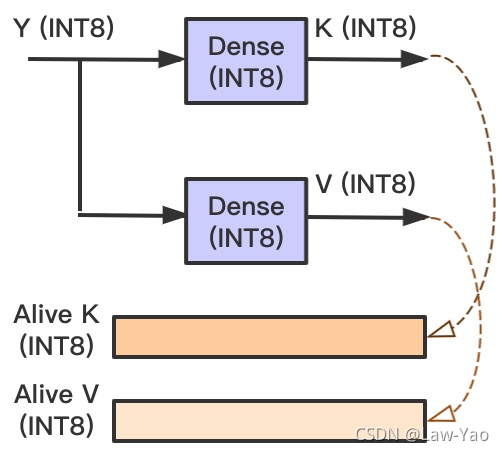
- Decoder的Self-attention:
- X=Y,Batch_size=Batch_size * Beam_size,Seq_len=1;
- k_dense与v_dense的输出会添加到Cache,按照INT8类型搬运数据,可节省访存开销:
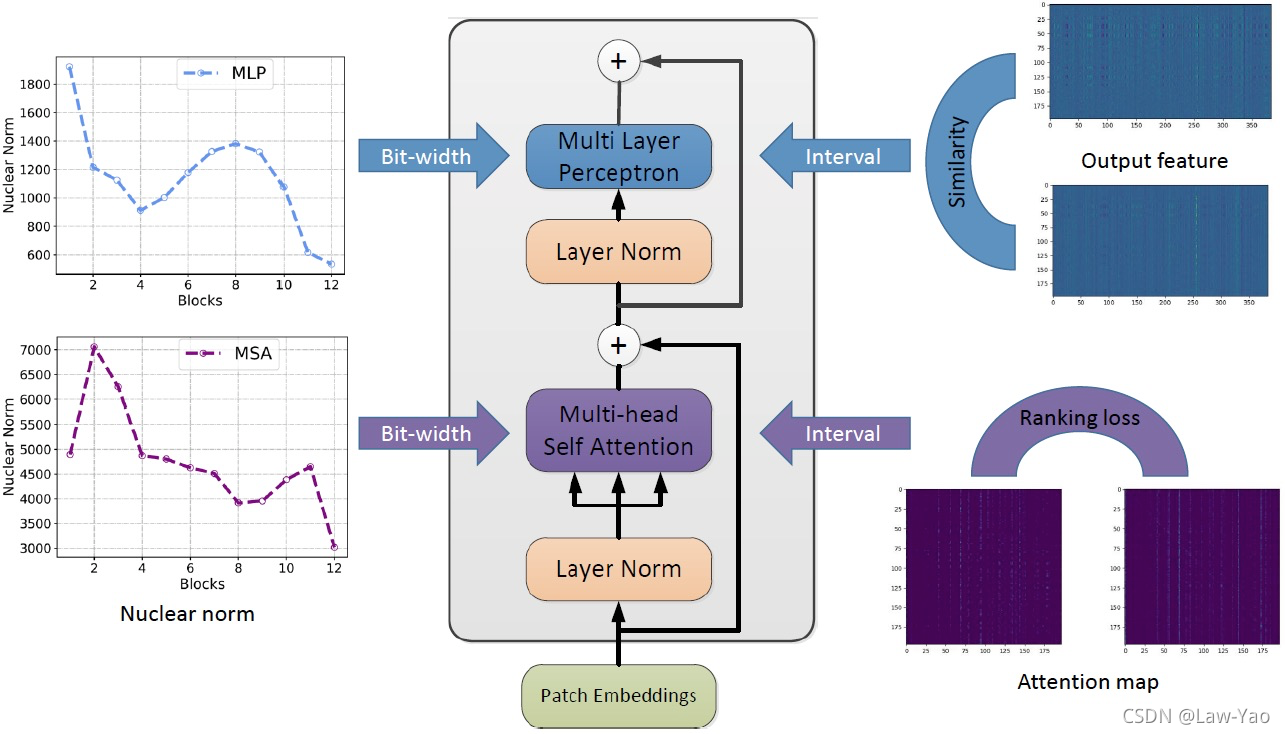
PTQ for Vision Transformer
参考文献: https://arxiv.org/abs/2106.14156
针对Vision Transformer的PTQ量化,分别针对FFN与Self-Attention,提出了Similarity-aware Quantization与Ranking-aware Quantization:
- Similarity-aware Quantization: 基于优化方式确定Weight与Activation量化的最优量化参数,并以Pearson相似度作为Loss;
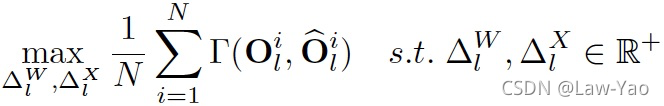
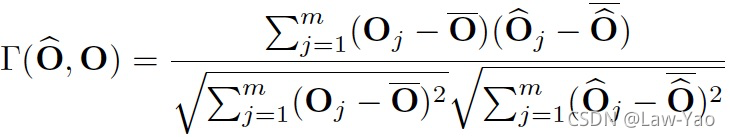
- Ranking-aware Quantization: 在相似度Loss基础之上,叠加Attention map的Ranking loss作为约束,以准确感知不同Attention map的重要性,确保Self-attention量化的有效性;
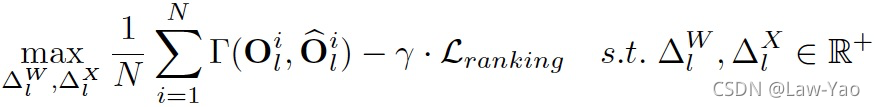
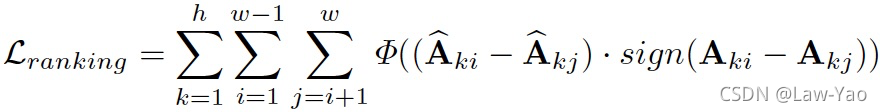
网络结构搜索 (NAS)
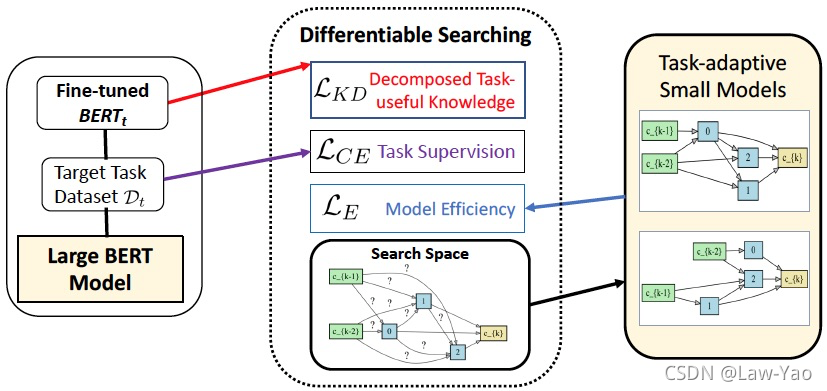
AdaBert
参考文献: https://arxiv.org/abs/2001.04246
针对NLP任务,AdaBert通过可微分搜索、与知识蒸馏,实现卷积类型的NLP模型搜索:
- 搜索空间:类似于DARTS的Cell设计,以构造搜索空间;
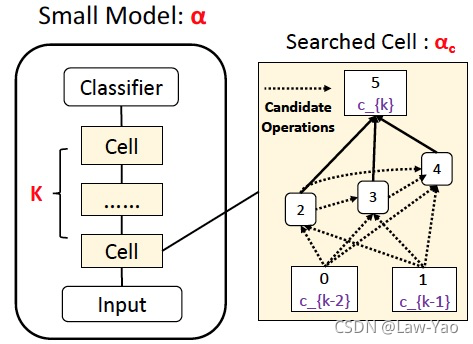
- 搜索策略:基于Gumbel Softmax实现网络结构的随机采样(类似于FBNet)、与可微分搜索;并基于FLOPS与Model size构造了Efficiency-aware Loss,作为搜索训练的资源约束;
- 知识蒸馏:多层次、任务相关的知识迁移;
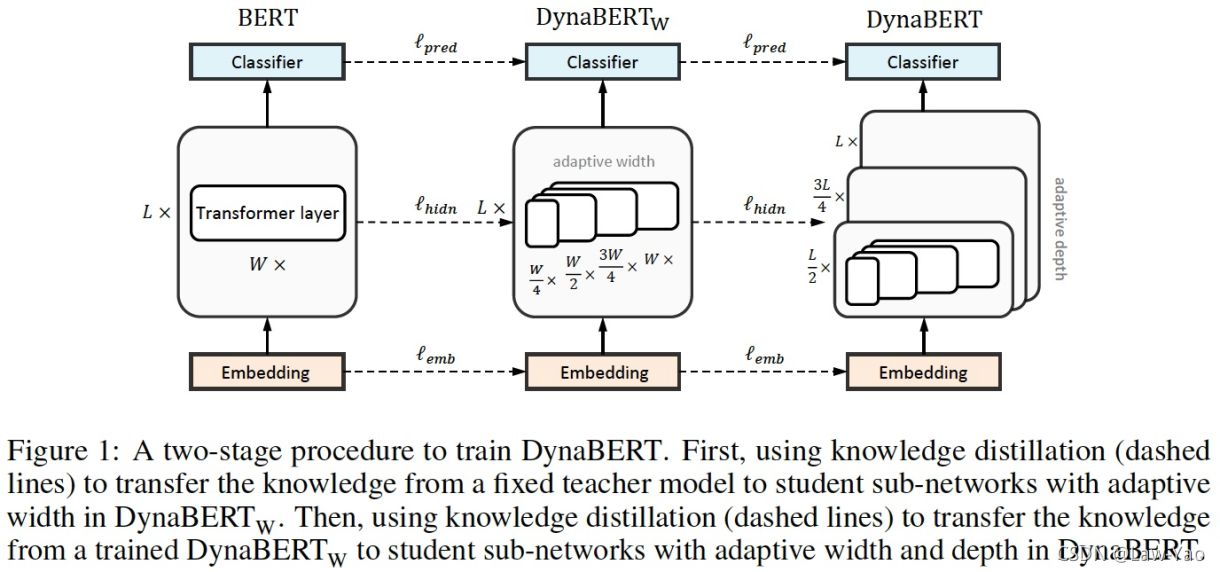
DynaBert
参考文献: https://arxiv.org/abs/2004.04037
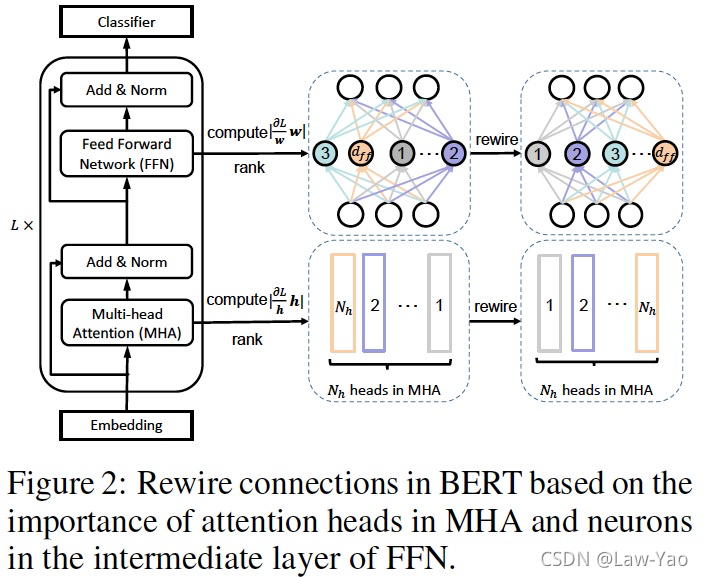
针对NLP任务,DynaBert模型压缩策略可实现多个维度的压缩搜索(主要是Width与Depth维度)。通过动态可伸缩性质的One-shot NAS:首先基于预训练Bert模型(或其变体),进行多维度正则化训练;正则化训练之后,按照不同的资源约束需求,能够进行网络参数的裁剪、以获得子网络,并进行子网络的微调训练;从正则训练、到子网络微调,可协同知识蒸馏训练。主要步骤描述如下:
- 第一步:基于Neuron与Attention head的重要性,执行参数重排(Weight Re-wiring):
- 第二步:多阶段微调训练,实现宽度、与深度方向的自适应正则化:
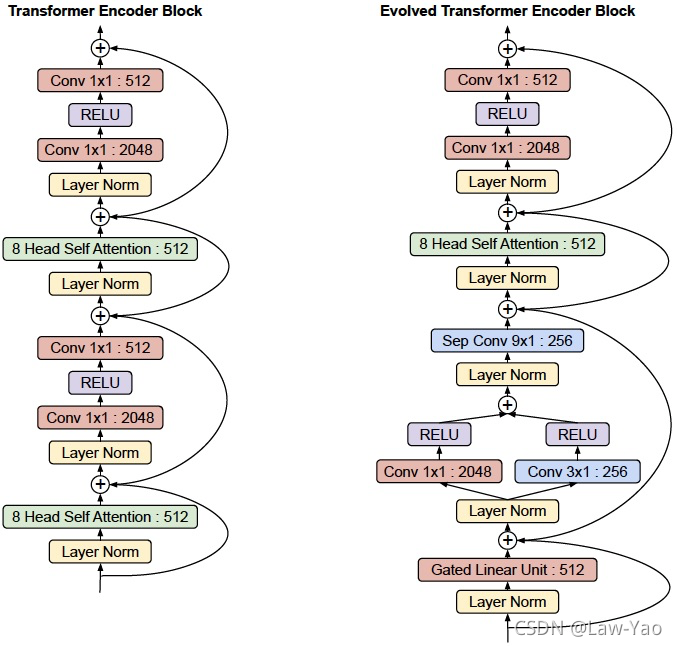
Evolved Transformer
参考文献: https://arxiv.org/abs/2004.11886
针对序列生成任务,基于NAS搜索获得的Transformer结构:
- 搜索空间:包括两个Stackable cell,分别包含在Transformer encoder与Transformer decoder。每个Cell由NAS-style block组成, 可通过左右两个Block转换输入Embedding、再聚合获得新的Embedding,进一步输入到Self-attention layer。
- 搜索策略:基于EA (Evolutional Aligorithm)的搜索策略;
网络结构如下,融合了一维卷积与Attention的特点:
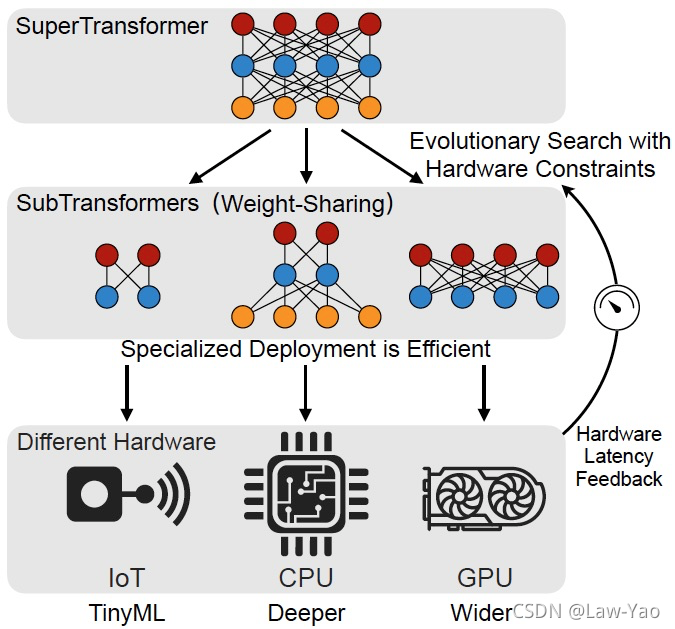
HAT: Hardware-aware Transformer
参考文献: https://arxiv.org/abs/2005.14187
对Transformer模型进行网络结构搜索时,通常会面临两个关键问题:
- FLOPS不能完全代表Transformer模型的计算速度/实际执行效率,即只能间接反映硬件平台特性;
- 不同硬件设备上,与计算硬件或计算库相适配的最优Transformer结构不尽相同;
针对序列生成任务,HAT (Hardware-aware Transformer)从搜索空间、搜索策略与搜索预测三方面加以分析:
- 搜索空间:Encoder-decoder Attention的任意连接方式,以及Transformer layer内部结构(Attention head数目、Width等);
- 搜索策略:训练了SuperTransformer作为超网络,并在超网络预训练之后,结合资源约束,通过进化搜索算法(EA: Evolutional Algorithm)寻找最优子网络;不同于权重共享型NAS (如FBNet、SPOS等),HAT是一种动态可伸缩类型的One-shot NAS;
- 搜索预测:训练了MLP模型作为Cost model或Predicter,用于预测不同子网络结构、在指定硬件平台上的执行速度 (Latency);通过搜索预测,可直接、有效获取硬件平台特性,作为超网络预训练的资源约束;
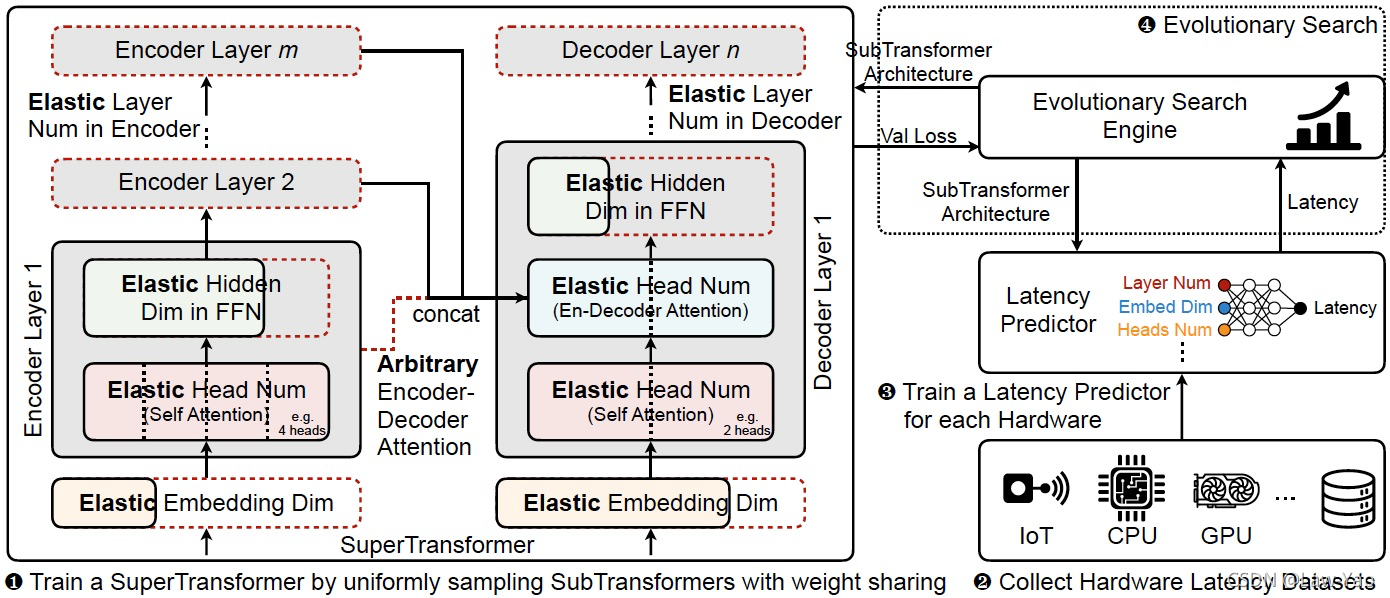
AutoFormer
参考文献: https://arxiv.org/abs/2107.00651
针对Vision Transformer的结构搜索,AutoFormer提出的Weight entanglement,在不额外增加Block choice的前提下,通过通道宽度、网络深度、Attention head数目等多个维度的调整,实现了Vision Transformer模型的动态可伸缩预训练与结构搜索。Weight entanglement的做法,类似于BigNAS、FBNet-v2的通道搜索,都不会额外增加通道维度的权重参数量。相比于手工设计的CNN模型(ResNet、ResNext、DenseNet)与Vision Transformer模型(ViT、Deit),AutoFormer模型在相同资源开销条件下、能够获得最好的识别精度。
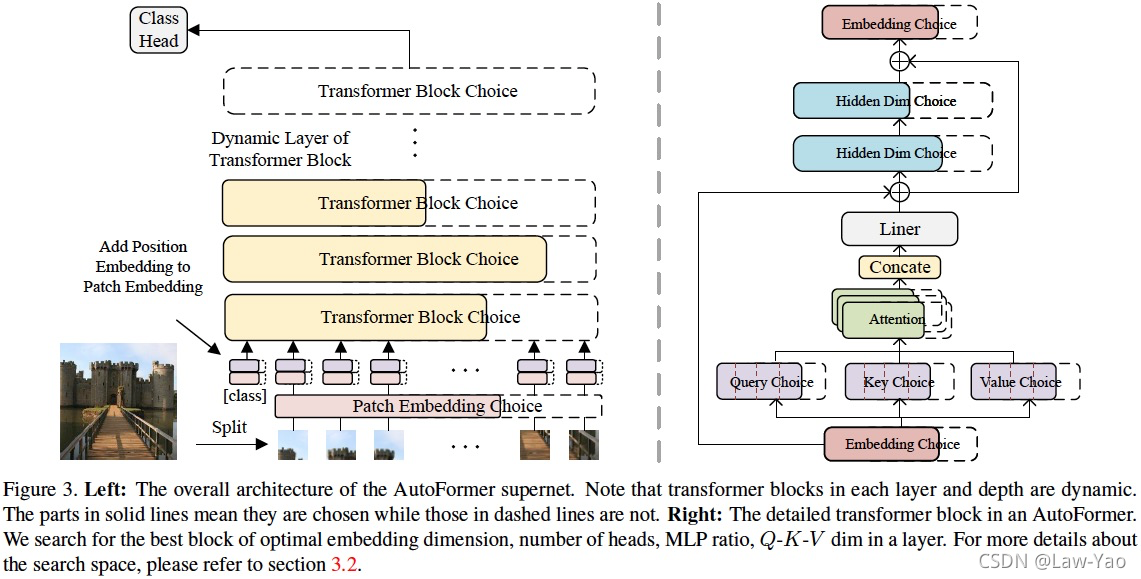
AutoFormer总体思路如上图所示,是一种基于Weight entanglement的动态可伸缩搜索方法,其搜索维度包括Attention heads、通道宽度与网络深度。下面从搜索空间、搜索策略与搜索效率这些维度加以分析:
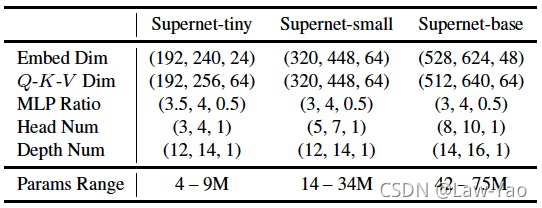
- 搜索空间:Embedding dimension、O-K-V dimension、Attention heads、MLP ratio与Network depth;根据不同的资源约束,分别设置Supernet-tiny、Supernet-small与Supernet-base三个基本的Template model;
- 搜索策略:基于Weight entanglement的One-shot NAS,完成超网络预训练之后,通过进化算法执行子网络搜索。包含l个网络层的子网络结构可按下式表示,表示第i层的Block结构,表示相应的权重参数:
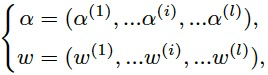
而每个Block结构,都是按照Weight entanglement原则从超网络采样获得,下式表示n个动态选择范围:
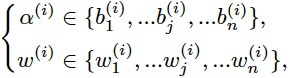
![]()
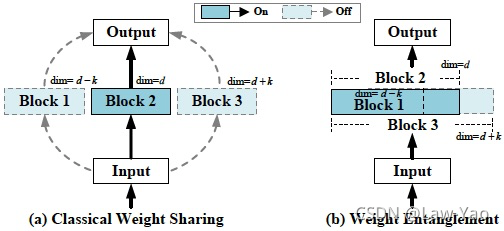
- 搜索效率:按照权重共享形式、完成超网络预训练,训练效率高、且收敛速度快;另外,由于没有引入额外的Block choice,因此训练时的Memory cost较低;
计算图优化
LINM
LINM (Loop-invariant Node Motion)是一种计算图等价变换技术,通过将Transformer模型涉及的自回归解码 (Auto-regressive Decoding)的重复计算逻辑 (Encoder-decoder Attention的k/v计算)移至while-loop之外,在确保计算功能不变的情况下,实现计算效率的提升:
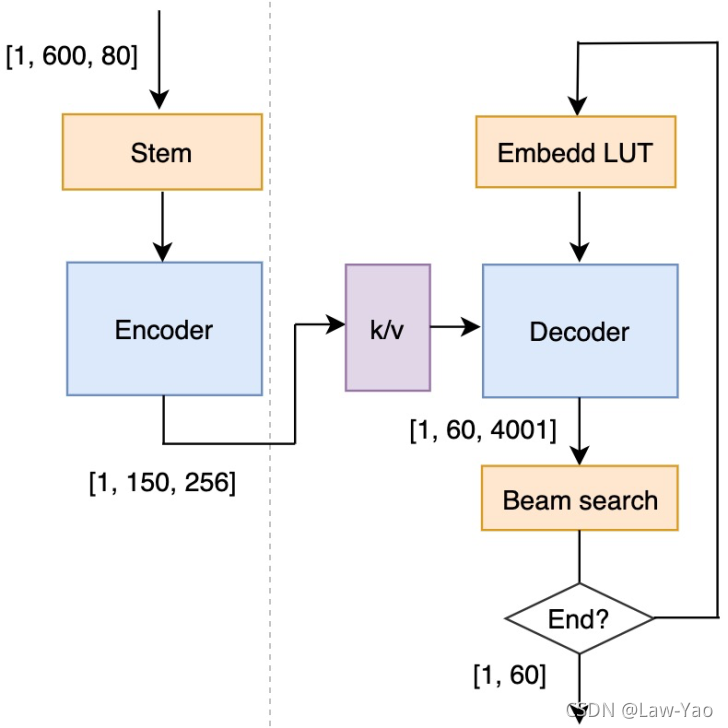
推理优化引擎
Faster Transformer
GitHub链接:https://github.com/NVIDIA/FasterTransformer
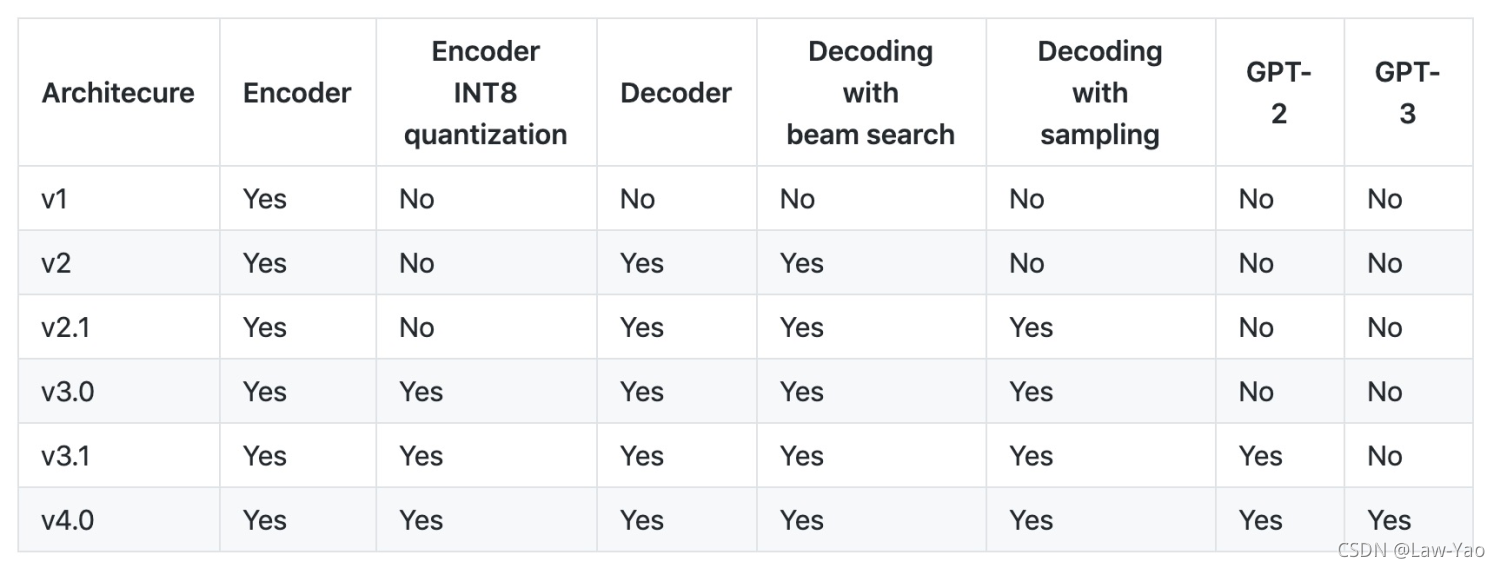
Faster Transformer是NVIDIA针对标准BERT/Transformer做的推理优化库,其发布时间线:
- 1.0版本:
- 2019年7月,开源了FasterTransformer 1.0,针对 BERT中的Transformer Encoder进行优化和加速;
- 面向BERT分类、自然语言理解场景;
- 底层由CUDA和cuBLAS实现,支持FP16和FP32计算,FP16可充分利用Volta和Turing架构的Tensor Core计算单元;
- 提供C++ API、TF Op与TensorRT Plugin三种接口;
- 参考资料;
- 2.0版本:
- 2020年2月,新增对Transformer decoder的优化和加速,包括decoder与decoding两种加速模式;
- 面向生成式场景,如NMT、文本内容生成与ASR等;
- 底层由CUDA和cuBLAS实现,支持FP16和FP32计算模,FP16可充分利用Volta和Turing架构的 Tensor Core计算单元;
- 提供C++ API、TF Op与TensorRT Plugin三种接口;
- 参考资料;
- 2.1版本:
- 2020年6月,引入Effective Transformer优化;通过remove_padding的支持,提高计算与访存效率;
- 并新增PyTorch Op接口;
- 参考资料;
- 3.0版本:
- 2020年9月,新增BERT encoder的INT8量化加速支持;
- 仅支持Turing架构GPU;
- 同时支持PTQ与QAT方法,提供了TF量化工具;
- 相比于FP16计算,约20~30%加速,但存在精度损失风险;
- 3.1版本:
- 2020年12月,新增对PyTorch使用INT8推理的支援;
- 在Turing以后的GPU上,FP16的性能比3.0提升了 10% ~ 20%;
- INT8的性能比3.0最多提升了70%;
- 4.0版本:
- 2021年4月,新增对GPT-3等百亿/千亿级参数规模模型的多机多卡推理加速能力;
- 新增FP16 fused MHA算子,同时支持Volta与Turing架构的GPU;
- 以及对解码端Kernel的优化,可以省略已完成语句的计算,节省计算资源;
- 参考资料;
- 支持矩阵:
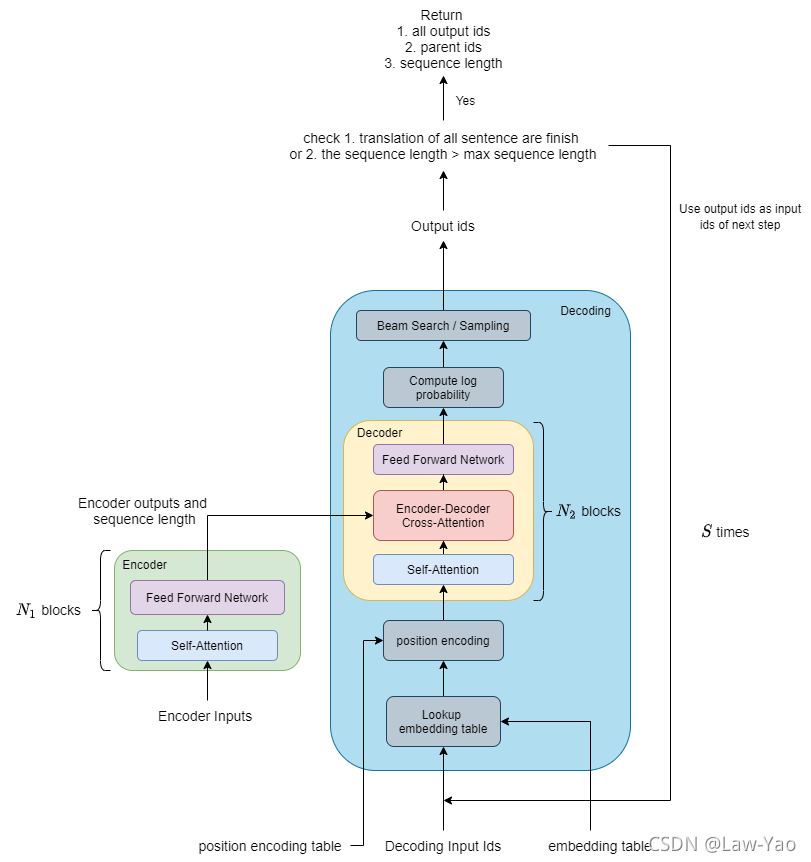
Transformer计算图表示,主要包含三个部分的表示:
- Encoder layer;
- Decoder layer;
- Decoding logic;