目录
1、rnn是什么
2、原理说明
2.1 rnn 和全连接神经网略的区别
2.2 RNN 简单图解释
2.3 RNN展开图解释
2.4 RNN的一些点
3、rnn的伪代码表示
4、来个小例子
5、rnn存在的问题
6、总结
最近写了一些基础的东西,总是理解性的,没有看到实例,今天就讲一个基础的网络结构RNN,然后写个实例,体验下深度神经网络的牛逼,这次学习下rnn神经网络,虽然看起来好高深,不过不用慌,没有理论,全是大白话,大家都可以懂的。
注:阅读的时候希望先看下目录,知道我在说什么,也可以快速的阅读到自己想get的点,这样阅读能更快的理解。
1、rnn是什么
RNN 是循环神经网络的简称,他的英语是 Rerrent Neural Network = RNN,从命名中可以看到核心点是循环的神经网络,所以我们要理解循环的是什么?为什么要循环。这个会慢慢解释。不用着急。
RNN对具有序列特性的数据非常有效,它能挖掘数据中的时序信息以及语义信息,用人话解释就是RNN具有语境信息,可以理解上下文,在你进行分析的时候可以对全局进行考虑,可以用来挖掘数据之间的关系。
举个例子:我不喜欢美女,对文字进行拆分,我,不,喜欢,美女,在普通的全连接的神经网络中会每个词是鼓励的,没有关系的,通过大量的函数去拟合数据,这个时候机器可能理解的就是喜欢美女,没有考虑到前面的“不”带来的语境信息。
RNN 可以解决这个问题,RNN 会记录整个句子出现的信息,然后进行综合评判,最后才得出结论。
总结下:RNN神经网络善于发现数据之间的关系。
2、原理说明
2.1 rnn 和全连接神经网略的区别
普通的全连接的神经网络像下面这样,每个属性是独立的,然后通过大量的函数参数进行拟合,然后进行处理,得出自己的结论,就像上篇入门的时候对函数的拟合,可以看出每个数据之间并没有什么关联
![]()
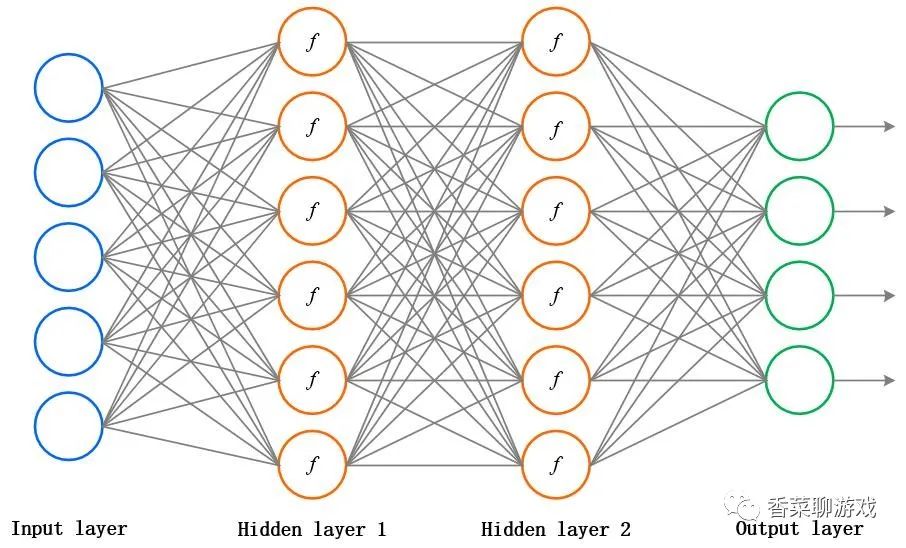
再看看我们今天说的RNN,循环的神经网络,注:这张图来自百度,我为什么要展示这张图呐?虽然我想用最直白的话给描述RNN,但是以后你可能会查阅资料,会频繁的看到这张图,所以我贴进来,以免下次遇到的时候没办法理解,因为这个图理解起来还是不那么好理解,当然如果你理解了RNN可能会明白。但是对于入门的我们来说还是有点费劲的。
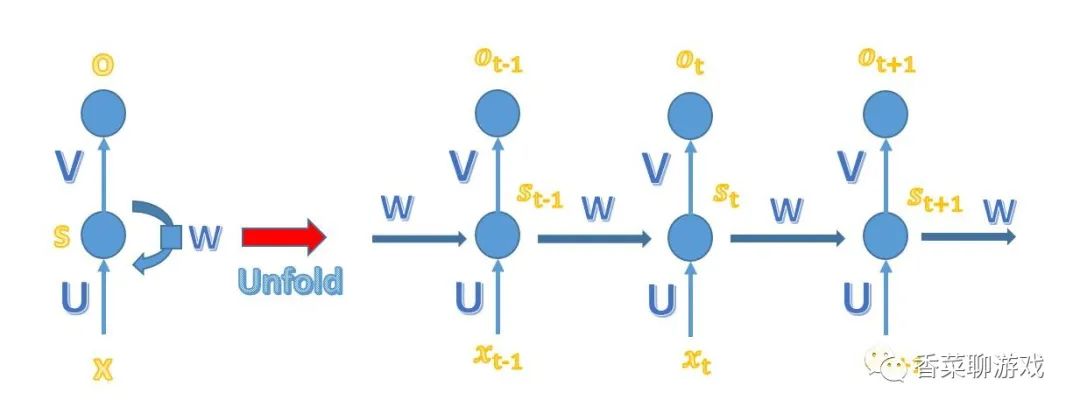
2.2 RNN 简单图解释
左边的部分是没展开的RNN的见图,到这里可以看到循环神经网络的循环在哪里了
x是一个向量,它表示输入层的值
U是输入层到隐藏层的权重矩阵
s是一个向量,它表示隐藏层的值
V是隐藏层到输出层的权重矩阵。
o也是一个向量,它表示输出层的值
用函数表示 :

用代码简单的理解下
def getHidenS(x,w,prevS):
return x * u + prevS*w
def getOutput(s):
return s * v2.3 RNN展开图解释
右边的图看起来很简单,但是下面的 x 增加了时间序列,这里的x 表示时间上的输入单词,举个例子:
比如:我爱中国,这个词序列,t-1 就是我 这个词的向量表示,爱 就是 t 这个词的向量表示,t+1 就是中国这个词的向量表示
o就是在输入每个单词时神经网络的输出,也就是说每次输入一个词向量的时候都会有一个输出,最后得出结论可以使用其中一个,或者综合考虑都可以,根据自己的需求
2.4 RNN的一些点
公用参数:RNN的时间序列公用参数,也就是说整个RNN公用一组参数,不同的时间点的输入的时候,神经网络的权重参数都是一组。也就是说只有一组W参数。
具有记忆功能:记忆功能的实现是基于隐藏层的输出值实现的。因为隐藏层会将上一次的信息进行保存
3、rnn的伪代码表示
对”我爱中国“进行编码,我= 1 爱 = 2 中国=3
输入 x = [1,2,3]
w = 1 # 权重矩阵
u = 1 # 输入层到隐藏层的矩阵
v = 2 # 隐藏层到输出层的矩阵
prevS = 1 # 隐藏层的输出值
def getHidenS(x, w, prevS):
return x * u + prevS * w
def getOutput(s,v):
return s * v
sentance = [1,2,3]
for x in sentance:
prevS = getHidenS(x,u,prevS)
o = getOutput(prevS,v)
print('隐藏层的值:'+ str(prevS))
print('输出层的值 :'+str(o))
print('----------------------')prevS 保存了之前的记忆,每一次的输出都可以用来判断

4、来个小例子
import torch
from torch import nn
import numpy as np
import matplotlib.pyplot as plt
# https://www.cnblogs.com/lokvahkoor/p/12263953.html
# torch.manual_seed(1) # reproducible
# 超参数定义
TIME_STEP = 10 # rnn time step
INPUT_SIZE = 1 # rnn input size
LR = 0.02 # 学习率
HIDDEN_SIZE = 32# 隐藏层神经元个数
EPOCH = 100
# 横向坐标,产出100个float点
steps = np.linspace(0, np.pi * 2, 100, dtype=np.float32) # float32 for converting torch FloatTensor
x_np = np.sin(steps)
y_np = np.cos(steps)
# 输入的参数是sin的序列,输出是余弦序列
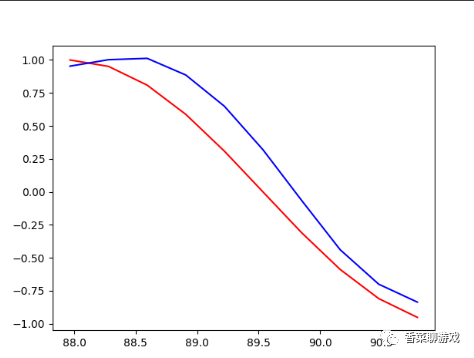
plt.plot(steps, y_np, 'r-', label='target (cos)')
plt.plot(steps, x_np, 'b-', label='input (sin)')
plt.legend(loc='best')
plt.show()
input("请回车:")
class RNN(nn.Module):
def __init__(self):
super(RNN, self).__init__()
self.rnn = nn.RNN(
input_size=INPUT_SIZE,
hidden_size=HIDDEN_SIZE, # 隐藏神经元的数量
num_layers=1, # 一层rnn
batch_first=True, # input & output will has batch size as 1s dimension. e.g. (batch, time_step, input_size)
)
self.out = nn.Linear(HIDDEN_SIZE, 1)
def forward(self, x, h_state):
# x = (batch, time_step, input_size)
# h_state = (n_layers, batch, hidden_size)
# r_out = (batch, time_step, hidden_size)
out, h_state = self.rnn(x, h_state)
out = out.view(-1, HIDDEN_SIZE) #(10,32)
out = self.out(out) #(10,1)
out = out.unsqueeze(dim=0) # (1,10,1) -> (n_layers, batch, hidden_size)
return out, h_state
rnn = RNN()
print(rnn)
optimizer = torch.optim.Adam(rnn.parameters(), lr=LR) # 优化器
loss_func = nn.MSELoss() # 损失函数
h_state = None # 隐藏层的输出值
plt.figure(1, figsize=(12, 5))
plt.ion() # continuously plot
for step in range(EPOCH):
# 每次生成新的数据,整体的趋势是拟合成cos函数曲线
start, end = step * np.pi, (step + 1) * np.pi # time range
# use sin predicts cos
steps = np.linspace(start, end, TIME_STEP, dtype=np.float32,
endpoint=False) # float32 for converting torch FloatTensor
x_np = np.sin(steps)
y_np = np.cos(steps)
# np.newaxis的功能:插入新维度,(1,10,1)
# shape (batch, time_step, input_size)
# 表示每一批送进去一个
x = torch.from_numpy(x_np[np.newaxis, :, np.newaxis])
y = torch.from_numpy(y_np[np.newaxis, :, np.newaxis])
prediction, h_state = rnn(x, h_state) # 计算输出
# 将上一步的隐藏层的结果进行保存,在下次输入
h_state = h_state.data # repack the hidden state, break the connection from last iteration
loss = loss_func(prediction, y) # 计算误差
optimizer.zero_grad() # 清除之前的梯度
loss.backward() # 反向传播
optimizer.step() # 优化参数
# 开始画图
plt.plot(steps, y_np.flatten(), 'r-')
plt.plot(steps, prediction.data.numpy().flatten(), 'b-')
plt.draw()
plt.pause(0.05)
plt.ioff()
plt.show()看一下最后的拟合结果:
![]()
5、rnn存在的问题
对于梯度消失: 由于它们都有特殊的方式存储”记忆”,那么以前梯度比较大的”记忆”不会像简单的RNN一样马上被抹除,因此可以一定程度上克服梯度消失问题。
对于梯度爆炸:用来克服梯度爆炸的问题就是gradient clipping,也就是当你计算的梯度超过阈值c或者小于阈值-c的时候,便把此时的梯度设置成c或-c。
6、总结
RNN的关键点是记忆功能,也就是保存了语境信息,但是也存在一些问题,后面我们会分析怎么解决这个问题。
原创不容易,求点赞支持,为爱发电。
推荐阅读 点击标题可跳转
1、再不入坑就晚了,从零学pytorch,一步一步环境搭建
2、再不入坑就晚了,深度神经网络概念大整理,最简单的神经网络是什么样子?
3、深度学习基础之三分钟轻松搞明白tensor到底是个啥

书分为 11章,涵盖的主要内容有神经网络概述,神经网络基础知识,计算机程序的特点,神经网络优化算法,搭 建Python环境,Python基础知识,深度学习框架PyTorch基础知识,NumPy简介与使用,OpenCV简介与使用,OS遍历文件夹,Python中Matplotlib可视化绘图,Lenet-5、AlexNet、VGG16网络模型,回归问题和分类问题,猫狗识别程序开发,验证码识别程序开发,过拟合问题与解决方法,梯度消失与爆炸,加速神经网络训练的方法,人工智能的未来发展趋势等。
京东自营购买链接:
《Python神经网络入门与实战》(王凯)【摘要 书评 试读】- 京东图书
当当自营购买链接:
《Python神经网络入门与实战》(王凯)【简介_书评_在线阅读】 - 当当图书
大家点赞关注,三天后在留言的同学中抽取送一本书
注:如果中奖了没关注则放弃