目录
- 第 21 天 - 类和对象
- 21.1创建一个类
- 21.2创建对象
- 21.3类构造函数
- 21.4对象方法
- 21.5对象默认方法
- 21.6修改类默认值的方法
- 21.7继承
- 21.8Overriding parent method
- 第 22 天 - 网页抓取
- 22.1什么是网页抓取
- 第 23 天 - 虚拟环境
- 23.1设置虚拟环境
- 第 24 天 - 统计
- 24.1统计数据
- 24.2什么是数据?
- 24.3统计模块
- 24.4NumPy
- 24.5导入 NumPy
- 24.6使用创建 numpy 数组
- 24.7创建 float numpy 数组
- 24.8创建布尔 numpy 数组
- 24.9使用numpy创建多维数组
- 24.10将 numpy 数组转换为列表
- 24.11从元组创建numpy数组
- 24.12numpy 数组的形状
- 24.13numpy数组的数据类型
- 24.14numpy 数组的大小
- 24.15使用numpy进行数学运算
- 24.16添加
- 24.17减法
- 24.18乘法
- 24.19分配
- 24.20模数;找到余数
- 24.21楼层划分
- 24.22指数
- 24.23检查数据类型
- 24.24转换类型
- 24.25多维数组
- 24.26从 numpy 数组中获取项目
- 24.27切片 Numpy 数组
- 24.28如何反转行和整个数组?
- 24.29反转行列位置
- 24.30如何表示缺失值?
- 24.31生成随机数
- 24.32生成随机数
- 24.33Numpy 和统计
- 24.34numpy中的矩阵
- 24.35numpy numpy.arange()
- 24.36使用 linspace 创建数字序列
- 24.37NumPy 统计函数与示例
- 24.38如何创建重复序列?
- 24.39如何生成随机数?
- 24.40线性代数
- 24.41NumPy 矩阵乘法与 np.matmul()
- 第 25 天 - Pandas
- 25.1安装pandas
- 导入pandas
- 25.2使用默认索引创建 Pandas 系列
- 25.3使用自定义索引创建 Pandas 系列
- 25.4从字典创建 Pandas 系列
- 25.5创建一个常量 Pandas 系列
- 25.6使用 Linspace 创建 Pandas 系列
- 25.7数据帧
- 从列表列表创建数据帧
- 25.8使用字典创建 DataFrame
- 25.9从字典列表创建数据帧
- 25.10使用 Pandas 读取 CSV 文件
- 25.11数据探索
- 25.12修改数据帧
- 25.13创建数据帧
- 25.14添加新列
- 25.15修改列值
- 25.16格式化 DataFrame 列
- 25.17检查列值的数据类型
- 25.18布尔索引

你们的三连(点赞,收藏,评论)是我持续输出的动力,感谢。
在兴趣中学习,效益超乎想象,有趣的源码与学习经验,工具安装包,欢迎加我的微信:bobin1124,一起交流学习与分享。
第 21 天 - 类和对象
Python 是一种面向对象的编程语言。Python 中的一切都是一个对象,有它的属性和方法。程序中使用的数字、字符串、列表、字典、元组、集合等是相应内置类的对象。我们创建类来创建一个对象。一个类就像一个对象构造函数,或者是创建对象的“蓝图”。我们实例化一个类来创建一个对象。类定义了对象的属性和行为,而另一方面,对象代表了类。
从这个挑战一开始,我们就在不知不觉中处理类和对象。Python 程序中的每个元素都是一个类的对象。让我们检查一下python中的所有东西是否都是一个类:
asabeneh @ Asabeneh:~ $ python
Python 3.9。6(默认,2021 年6月 28 日 ,15:26:21)
[锵 11.0 0.0(铛- 1100.0。33.8)在 达尔文
式 的“帮助”,“版权”,“信用” 或 “许可” 的 更多 信息。
>> > num = 10
>> > type ( num )
< class 'int' >
>> > string = 'string'
>> > 类 'STR' >
>> > 布尔 = 真
>> > 类型(布尔)
<类 '布尔' >
>> > LST = []
>> > 型(LST)
<类 '列表' >
>> > TPL =( )
>> > 类型( tpl )
< class 'tuple' >
>> > SET1 = 集()
>> > 类型(set1)
< class 'set' >
>> > dct = {}
>> > 类型(dct)
< class 'dict' >
21.1创建一个类
要创建一个类,我们需要关键字类,后跟名称和冒号。类名应该是CamelCase。
#语法
类类名:
代码在这里
例子:
类 人:
通过
打印(人)
< __main__.Person 对象在 0x10804e 510>
21.2创建对象
我们可以通过调用类来创建一个对象。
p = 人()
打印( p )
21.3类构造函数
在上面的例子中,我们从 Person 类创建了一个对象。然而,没有构造函数的类在实际应用中并没有真正的用处。让我们使用构造函数使我们的类更有用。与Java或JavaScript中的构造函数一样,Python也有内置的init ()构造函数。的初始化构造函数有自参数这对类的当前实例的引用
实施例:
class Person :
def __init__ ( self , name ):
# self 允许将参数附加到类
self。姓名 =姓名
p = Person ( 'Asabeneh' )
打印( p . name )
打印( p )
#输出
阿萨贝内
< __main__.Person 对象在 0x2abf46907e 80>
让我们向构造函数添加更多参数。
class Person :
def __init__ ( self , firstname , lastname , age , country , city ):
self。名字 = 名字
自我。姓氏 = 姓氏
自我。年龄 = 年龄
自我。国家 = 国家
自我。城市 = 城市
p = Person ( 'Asabeneh' , 'Yetayeh' , 250 , 'Finland' , 'Helsinki' )
print ( p . firstname )
print ( p . lastname )
print ( p . age )
print ( p . country )
print ( p .城市)
#输出
阿萨贝内
耶塔耶
250
芬兰
赫尔辛基
21.4对象方法
对象可以有方法。方法是属于对象的函数。
例子:
class Person :
def __init__ ( self , firstname , lastname , age , country , city ):
self。名字 = 名字
自我。姓氏 = 姓氏
自我。年龄 = 年龄
自我。国家 = 国家
自我。city = city
def person_info ( self ):
返回 f' {自我。名字} {自我。姓氏}是{ self。年龄}岁。他住在{自我。城市},{自我。国家} '
p = 人('Asabeneh' ,'Yetayeh' ,250,'芬兰','赫尔辛基')
打印(p。person_info())
#输出
Asabeneh Yetayeh 已经 250 岁了。他住在芬兰赫尔辛基
21.5对象默认方法
有时,您可能希望为对象方法设置默认值。如果我们在构造函数中给参数赋予默认值,就可以避免在不带参数的情况下调用或实例化我们的类时出错。让我们看看它的外观:
例子:
class Person :
def __init__ ( self , firstname = 'Asabeneh' , lastname = 'Yetayeh' , age = 250 , country = 'Finland' , city = 'Helsinki' ):
self。名字 = 名字
自我。姓氏 = 姓氏
自我。年龄 = 年龄
自我。国家 = 国家
自我. 城市 = 城市
def person_info ( self ):
返回 f' { self . 名字} {自我。姓氏}是{ self。年龄}岁。他住在{自我。城市},{自我。国家} .'
P1 = 人()
打印(P1。person_info())
P2 = 人('约翰','李四',30,'Nomanland' , “诺曼城市)
打印(P2。person_info())
#输出
Asabeneh Yetayeh 已经 250 岁了。他住在芬兰赫尔辛基。
约翰·多伊今年 30 岁。他住在诺曼兰的诺曼城。
21.6修改类默认值的方法
在下面的例子中,person 类,所有的构造函数参数都有默认值。除此之外,我们还有技能参数,我们可以使用方法访问它。让我们创建 add_skill 方法来将技能添加到技能列表中。
class Person :
def __init__ ( self , firstname = 'Asabeneh' , lastname = 'Yetayeh' , age = 250 , country = 'Finland' , city = 'Helsinki' ):
self。名字 = 名字
自我。姓氏 = 姓氏
自我。年龄 = 年龄
自我。国家 = 国家
自我. 城市 = 城市
自我。技能 = []
def person_info ( self ):
返回 f' { self . 名字} {自我。姓氏}是{ self。年龄}岁。他住在{自我。城市},{自我。国家} .'
def add_skill(自我,技能):
自我。技能。追加(技能)
p1 = Person ()
打印( p1 . person_info ())
p1 . add_skill ( 'HTML' )
p1。add_skill ( 'CSS' )
p1。add_skill('的JavaScript' )
P2 = 人('约翰','李四',30,'Nomanland' , “诺曼城市)
打印(P2。person_info())
印刷(P1. 技能)
打印(p2。技能)
#输出
Asabeneh Yetayeh 已经 250 岁了。他住在芬兰赫尔辛基。
约翰·多伊今年 30 岁。他住在诺曼兰的诺曼城。
[ ' HTML '、' CSS '、' JavaScript ' ]
[]
21.7继承
使用继承,我们可以重用父类代码。继承允许我们定义一个继承父类的所有方法和属性的类。父类或超类或基类是提供所有方法和属性的类。子类是从另一个类或父类继承的类。让我们通过继承person类来创建一个student类。
班级 学生(人):
通过
S1 = 学生('Eyob' ,'Yetayeh' ,30,'芬兰','赫尔辛基')
S2 = 学生('了Lidiya' ,'Teklemariam' ,28,'芬兰','埃斯波')
印刷(S1。person_info( ))
s1。add_skill ( 'JavaScript' )
s1。add_skill ( '反应' )
s1。'Python' )
打印( s1 .技能)
打印(S2。person_info())
S2。add_skill ( '组织' )
s2。add_skill ( '营销' )
s2。add_skill ( '数字营销' )
打印( s2 . Skill )
输出
Eyob Yetayeh 30 岁。他住在芬兰赫尔辛基。
[ ' JavaScript '、' React '、' Python ' ]
Lidiya Teklemariam 28 岁。他住在芬兰的埃斯波。
[ “组织”、“营销”、“数字营销” ]
我们没有在子类中调用init ()构造函数。如果我们没有调用它,那么我们仍然可以从父级访问所有属性。但是如果我们确实调用了构造函数,我们就可以通过调用super来访问父属性。
我们可以向子类添加新方法,也可以通过在子类中创建相同的方法名称来覆盖父类方法。当我们添加init ()函数时,子类将不再继承父类的init ()函数。
21.8Overriding parent method
类 学生(人):
高清 __init__(自我,名字= 'Asabeneh' ,姓氏= 'Yetayeh' ,年龄= 250,全国= '芬兰,城市= '赫尔辛基',性别= '男'):
自我。性别 = 性别
超()。__init__(名字,姓氏,年龄,country , city )
def person_info ( self ):
性别 = 'He' if self。性别 == '男' 否则 '她'
返回 f' { self . 名字} {自我。姓氏}是{ self。年龄}岁。{性别}生活在{自我。城市} , {自己. 国家} .'
s1 = Student ( 'Eyob' , 'Yetayeh' , 30 , 'Finland' , 'Helsinki' , 'male' )
s2 = Student ( 'Lidiya' , 'Teklemariam' , 28 , 'Finland' , 'Espoo' , 'female' ' )
打印( s1 . person_info ())
s1 . add_skill ( 'JavaScript' )
s1。s1。add_skill('Python的)
印刷(S1,技能)
打印(S2。person_info())
S2。add_skill ( '组织' )
s2。add_skill ( '营销' )
s2。add_skill ( '数字营销' )
打印( s2 . Skill )
Eyob Yetayeh 30 岁。他住在芬兰赫尔辛基。
[ ' JavaScript '、' React '、' Python ' ]
Lidiya Teklemariam 28 岁。她住在芬兰的埃斯波。
[ “组织”、“营销”、“数字营销” ]
我们可以使用 super() 内置函数或父名 Person 来自动继承其父级的方法和属性。在上面的例子中,我们Overriding parent method的方法。child 方法有一个不同的特点,它可以识别性别是男性还是女性并指定适当的代词(他/她)
第 22 天 - 网页抓取
22.1什么是网页抓取
互联网充满了可用于不同目的的大量数据。为了收集这些数据,我们需要知道如何从网站上抓取数据。
网页抓取是从网站中提取和收集数据并将其存储在本地机器或数据库中的过程。
在本节中,我们将使用 beautifulsoup 和 requests 包来抓取数据。我们使用的包版本是beautifulsoup 4。
要开始抓取网站,您需要请求、beautifoulSoup4和网站。
pip 安装请求
pip 安装 beautifulsoup4
要从网站抓取数据,需要对 HTML 标签和 CSS 选择器有基本的了解。我们使用 HTML 标签、类或/和 ID 定位来自网站的内容。让我们导入 requests 和 BeautifulSoup 模块
进口 请求
从 BS4 进口 BeautifulSoup
让我们为要抓取的网站声明 url 变量。
来自bs4 的导入请求
import BeautifulSoup url = 'https://archive.ics.uci.edu/ml/datasets.php'
# 让我们使用 requests 的 get 方法从 url 中获取数据
响应 = 请求。get ( url )
# 让我们检查状态
status = response。status_code
print ( status ) # 200 表示获取成功
200
使用beautifulSoup解析页面内容
来自bs4 的导入请求
import BeautifulSoup url = 'https://archive.ics.uci.edu/ml/datasets.php'
响应 = 请求。获取(网址)
内容 = 响应。content # 我们从网站上获取所有内容
soup = BeautifulSoup ( content , 'html.parser' ) # beautiful
Soup将有机会解析print ( soup . title ) # <title>UCI Machine Learning Repository: Data Sets</标题>
打印(汤。标题。get_text())#UCI机器学习库:数据集
打印(汤。体)#给网站上的整个页面
打印(响应。STATUS_CODE)
桌子 = 汤。find_all ( 'table' , { 'cellpadding' : '3' })
# 我们的目标是 cellpadding 属性值为 3 的表格
# 我们可以选择使用 id、class 或 HTML 标签,更多信息请查看beautifulsoup doc
table = 表[ 0 ] #,结果是一个列表,我们是从它取出数据
为 TD 在 表。找到('tr')。find_all ( 'td' ):
打印( td . text)
如果你运行这段代码,你可以看到提取已经完成了一半。
🌕你很特别,每天都在进步。您距离通往伟大的道路只剩下八天了。
🎉 恭喜! 🎉
第 23 天 - 虚拟环境
23.1设置虚拟环境
从项目开始,最好有一个虚拟环境。虚拟环境可以帮助我们创建一个孤立或分离的环境。这将帮助我们避免跨项目的依赖冲突。如果您在终端上编写 pip freeze ,您将在计算机上看到所有已安装的软件包。如果我们使用 virtualenv,我们将只访问特定于该项目的包。打开终端并安装 virtualenv
asabeneh@Asabeneh: ~ $ pip install virtualenv
在 30DaysOfPython 文件夹中创建一个 flask_project 文件夹。
安装 virtualenv 包后,转到您的项目文件夹并通过编写以下内容创建一个虚拟环境:
对于 Mac/Linux:
asabeneh@Asabeneh: ~ /Desktop/30DaysOfPython/flask_project \$ virtualenv venv
对于 Windows:
C:\Ú SERS \Ú SER \ d ocuments \ 3 0DaysOfPython \˚F lask_project >蟒-m VENV VENV
我更喜欢将新项目称为 venv,但可以随意使用不同的名称。让我们检查 venv 是否是通过使用 ls(或 dir 用于 Windows 命令提示符)命令创建的。
asabeneh@Asabeneh:~ /Desktop/30DaysOfPython/flask_project$ ls
静脉/
让我们通过在我们的项目文件夹中编写以下命令来激活虚拟环境。
对于 Mac/Linux:
asabeneh@Asabeneh: ~ /Desktop/30DaysOfPython/flask_project$ source venv/bin/activate
在 Windows 中激活虚拟环境可能非常依赖于 Windows Power shell 和 git bash。
对于 Windows 电源外壳:
C:\Ú SERS \Ú SER \ d ocuments \ 3 0DaysOfPython \˚F lask_project > VENV \ S cripts \一个ctivate
对于 Windows Git bash:
C:\Ú SERS \Ú SER \ d ocuments \ 3 0DaysOfPython \˚F lask_project > VENV \ S cripts \。启用
编写激活命令后,您的项目目录将以 venv 开头。请参阅下面的示例。
(venv) asabeneh@Asabeneh: ~ /Desktop/30DaysOfPython/flask_project$
现在,让我们通过编写 pip freeze 来检查这个项目中的可用包。您将看不到任何包。
我们将要做一个Flask小项目,所以让我们将Flask包安装到这个项目中。
(venv) asabeneh@Asabeneh: ~ /Desktop/30DaysOfPython/flask_project$ pip install Flask
现在,让我们编写 pip freeze 来查看项目中已安装包的列表:
(venv) asabeneh@Asabeneh: ~ /Desktop/30DaysOfPython/flask_project$ pip freeze
点击==7.0
Flask==1.1.1
它的危险==1.1.0
Jinja2==2.10.3
标记安全==1.1.1
Werkzeug==0.16.0
完成后,您应该使用deactivate 停用活动项目。
(venv) asabeneh@Asabeneh: ~ /Desktop/30DaysOfPython$ 停用
安装了使用Flask的必要模块。现在,您的项目目录已准备好用于Flask项目。
🎉 恭喜! 🎉
第 24 天 - 统计
24.1统计数据
统计学是研究数据的收集、组织、显示、分析、解释和呈现的学科。统计学是数学的一个分支,建议作为数据科学和机器学习的先决条件。统计学是一个非常广泛的领域,但我们将在本节中只关注最相关的部分。完成此挑战后,您可以进入 Web 开发、数据分析、机器学习和数据科学路径。无论您走哪条路,在您职业生涯的某个阶段,您都会获得可以处理的数据。拥有一些统计知识将帮助您根据数据做出决策,数据如他们所说。
24.2什么是数据?
数据是为某种目的(通常是分析)收集和翻译的任何字符集。它可以是任何字符,包括文本和数字、图片、声音或视频。如果数据没有放在上下文中,它对人或计算机没有任何意义。为了让数据有意义,我们需要使用不同的工具处理数据。
数据分析、数据科学或机器学习的工作流程始于数据。可以从某个数据源提供数据,也可以创建数据。有结构化和非结构化数据。
可以以小格式或大格式找到数据。我们将获得的大多数数据类型已在文件处理部分中介绍。
24.3统计模块
Python统计模块提供了计算数值数据的数理统计的函数。该模块无意成为第三方库(如 NumPy、SciPy)或面向专业统计学家(如 Minitab、SAS 和 Matlab)的专有全功能统计软件包的竞争对手。它针对图形和科学计算器的级别。
24.4NumPy
在第一部分中,我们将 Python 本身定义为一种出色的通用编程语言,但在其他流行库(numpy、scipy、matplotlib、pandas 等)的帮助下,它成为了一个强大的科学计算环境。
NumPy 是 Python 科学计算的核心库。它提供了一个高性能的多维数组对象,以及用于处理数组的工具。
到目前为止,我们一直在使用 vscode,但从现在开始我会推荐使用 Jupyter Notebook。要访问 jupyter notebook,让我们安装anaconda。如果您使用的是 anaconda,则大多数常用软件包都已包含在内,如果您安装了 anaconda,则您没有安装软件包。
asabeneh@Asabeneh: ~ /Desktop/30DaysOfPython$ pip install numpy
24.5导入 NumPy
如果您支持 jupyter notebook,则可以使用Jupyter notebook
# 如何导入 numpy
import numpy as np
# 如何检查 numpy 包的版本
print ( 'numpy:' , np . __version__ )
# 检查可用方法
print ( dir ( np ))
24.6使用创建 numpy 数组
创建 int numpy 数组
# 创建 python 列表
python_list = [ 1 , 2 , 3 , 4 , 5 ]
# 检查数据类型
print ( 'Type:' , type ( python_list )) # <class 'list'>
#
print ( python_list ) # [1, 2, 3, 4, 5]
二维列表 = [[ 0 , 1 , 2 ], [ 3 , 4 , 5 ], [ 6 , 7 , 8 ]]
打印(二维列表) # [[0, 1, 2], [3, 4, 5], [6, 7, 8]]
# 从 python 列表创建 Numpy(Numerical Python) 数组
numpy_array_from_list = np。array ( python_list )
print ( type ( numpy_array_from_list )) # <class 'numpy.ndarray'>
print ( numpy_array_from_list ) # array([1, 2, 3, 4, 5])
24.7创建 float numpy 数组
使用浮点数据类型参数从列表创建浮点 numpy 数组
# Python 列表
python_list = [ 1 , 2 , 3 , 4 , 5 ]
numy_array_from_list2 = np。阵列(python_list,D型细胞=浮动)
打印(numy_array_from_list2)#阵列([1,2,3,4,5])
24.8创建布尔 numpy 数组
从列表创建一个布尔值 numpy 数组
numpy_bool_array = np。数组([ 0 , 1 , - 1 , 0 , 0 ], dtype = bool )
打印( numpy_bool_array ) # 数组([假, 真, 真, 假, 假])
24.9使用numpy创建多维数组
一个 numpy 数组可能有一个或多个行和列
two_Dimension_list = [[ 0 , 1 , 2 ], [ 3 , 4 , 5 ], [ 6 , 7 , 8 ]]
numpy_two_dimensional_list = np。数组(二维列表)
打印(类型(numpy_two_dimensional_list))
打印(numpy_two_dimensional_list)
<类’ numpy.ndarray ’ >
[[0 1 2]
[3 4 5]
[6 7 8]]
24.10将 numpy 数组转换为列表
# 我们总是可以使用 tolist() 将数组转换回 Python 列表。
np_to_list = numpy_array_from_list。tolist()
打印(类型(np_to_list))
打印('一个维阵列:',np_to_list)
打印('二维阵列:',numpy_two_dimensional_list。tolist())
<类'列表' >
一维数组:[1, 2, 3, 4, 5]
二维数组:[[0, 1, 2], [3, 4, 5], [6, 7, 8]]
24.11从元组创建numpy数组
# Numpy array from tuple
# 在 Python 中创建元组
python_tuple = ( 1 , 2 , 3 , 4 , 5 )
print ( type ( python_tuple )) # <class 'tuple'>
print ( 'python_tuple: ' , python_tuple ) # python_tuple: ( 1, 2, 3, 4, 5)
numpy_array_from_tuple = np。array ( python_tuple )
print ( type ( numpy_array_from_tuple )) # <class 'numpy.ndarray'>
print ( 'numpy_array_from_tuple: ' , numpy_array_from_tuple ) # numpy_array_from_tuple: [1 2 3 4 5]
24.12numpy 数组的形状
shape 方法以元组的形式提供数组的形状。第一个是行,第二个是列。如果数组只是一维,则返回数组的大小。
数字 = np。阵列([ 1,2,3,4,5 ])
打印(NUMS)
打印('NUMS的形状:',NUMS。形状)
打印(numpy_two_dimensional_list)
打印('numpy_two_dimensional_list的形状:',numpy_two_dimensional_list。形状)
three_by_four_array = NP。数组([[ 0, 1 , 2 , 3 ],
[ 4 , 5 , 6 , 7 ],
[ 8,9,10,11 ]])
打印(three_by_four_array。形状)
[1 2 3 4 5]
数字的形状:(5,)
[[0 1 2]
[3 4 5]
[6 7 8]]
numpy_two_dimensional_list 的形状:(3, 3)
(3, 4)
24.13numpy数组的数据类型
数据类型类型:str、int、float、complex、bool、list、None
int_lists = [ - 3 , - 2 , - 1 , 0 , 1 , 2 , 3 ]
int_array = np . 数组(int_lists)
float_array = np。阵列(int_lists,D型细胞=浮动)
打印(INT_ARRAY)
打印(INT_ARRAY。D型细胞)
打印(float_array)
打印(float_array。D型)
[-3 -2 -1 0 1 2 3]
int64
[-3。-2. -1. 0. 1. 2. 3.]
浮动64
24.14numpy 数组的大小
在 numpy 中要知道 numpy 数组列表中的项目数,我们使用 size
numpy_array_from_list = np。数组([ 1 , 2 , 3 , 4 , 5 ])
two_dimensional_list = np。数组([[ 0 , 1 , 2 ],
[ 3 , 4 , 5 ],
[ 6 , 7 , 8 ]])
print ( 'The size:' , numpy_array_from_list . size ) # 5
print ( 'The size:' , two_dimensional_list . size ) # 3
尺寸:5
尺寸:9
24.15使用numpy进行数学运算
NumPy 数组并不完全像 python 列表。要在 Python 列表中进行数学运算,我们必须遍历项目,但 numpy 可以允许在不循环的情况下进行任何数学运算。数学运算:
- 加法 (+)
- 减法 (-)
- 乘法 (*)
- 分配 (/)
- 模块 (%)
- 楼层划分(//)
- 指数(**)
24.16添加
# 数学运算
# 加法
numpy_array_from_list = np . 数组([ 1 , 2 , 3 , 4 , 5 ])
打印( '原始数组: ' , numpy_array_from_list )
ten_plus_original = numpy_array_from_list + 10
打印( ten_plus_original )
原始数组:[1 2 3 4 5]
[11 12 13 14 15]
24.17减法
# 减法
numpy_array_from_list = np . 数组([ 1 , 2 , 3 , 4 , 5 ])
打印( '原始数组: ' , numpy_array_from_list )
ten_minus_original = numpy_array_from_list - 10
打印( ten_minus_original )
原始数组:[1 2 3 4 5]
[-9 -8 -7 -6 -5]
24.18乘法
numpy_array_from_list = np . 数组([ 1 , 2 , 3 , 4 , 5 ])
打印( '原始数组: ' , numpy_array_from_list )
ten_times_original = numpy_array_from_list * 10
打印( ten_times_original )
原始数组:[1 2 3 4 5]
[10 20 30 40 50]
24.19分配
# 除法
numpy_array_from_list = np . 数组([ 1 , 2 , 3 , 4 , 5 ])
打印( '原始数组: ' , numpy_array_from_list )
ten_times_original = numpy_array_from_list / 10
打印( ten_times_original )
原始数组:[1 2 3 4 5]
[0.1 0.2 0.3 0.4 0.5]
24.20模数;找到余数
numpy_array_from_list = np。数组([ 1 , 2 , 3 , 4 , 5 ])
打印( '原始数组: ' , numpy_array_from_list )
ten_times_original = numpy_array_from_list % 3
打印( ten_times_original )
原始数组:[1 2 3 4 5]
[1 2 0 1 2]
24.21楼层划分
# 楼层除法:没有余数的除法结果
numpy_array_from_list = np . 数组([ 1 , 2 , 3 , 4 , 5 ])
打印( '原始数组: ' , numpy_array_from_list )
ten_times_original = numpy_array_from_list // 10
打印( ten_times_original )
24.22指数
# Exponential 是找到某个数字的另一个幂:
numpy_array_from_list = np。数组([ 1 , 2 , 3 , 4 , 5 ])
打印( '原始数组: ' , numpy_array_from_list )
ten_times_original = numpy_array_from_list ** 2
打印( ten_times_original )
原始数组:[1 2 3 4 5]
[ 1 4 9 16 25]
24.23检查数据类型
#Int, 浮点数
numpy_int_arr = np . 数组([ 1 , 2 , 3 , 4 ])
numpy_float_arr = np。数组([ 1.1 , 2.0 , 3.2 ])
numpy_bool_arr = np。数组([ - 3 , - 2 , 0 , 1 , 2 , 3 ], dtype = 'bool' )
打印(numpy_int_arr。D型细胞)
打印(numpy_float_arr。D型细胞)
打印(numpy_bool_arr。D型)
int64
浮动64
布尔值
24.24转换类型
我们可以转换numpy数组的数据类型
1.整数到浮动
numpy_int_arr = np。数组([ 1 , 2 , 3 , 4 ], dtype = 'float' )
numpy_int_arr
array([1., 2., 3., 4.])
2.浮动到整数
numpy_int_arr = np。数组([ 1. , 2. , 3. , 4. ], dtype = 'int' )
numpy_int_arr
数组([1, 2, 3, 4])
3.整数或布尔值
NP。数组([ - 3 , - 2 , 0 , 1 , 2 , 3 ], dtype = 'bool' )
数组([真,真,假,真,真,真])
4.整数到 str
numpy_float_list。astype ( 'int' )。astype('str')
数组([ ’ 1 ’ , ’ 2 ’ , ’ 3 ’ ], dtype= ’ <U21 ’ )
24.25多维数组
# 2 维数组
two_dimension_array = np . array ([( 1 , 2 , 3 ),( 4 , 5 , 6 ), ( 7 , 8 , 9 )])
print ( type ( two_dimension_array ))
print ( two_dimension_array )
print ( 'Shape: ' , two_dimension_array . shape )
打印( '大小:',two_dimension_array。尺寸)
的打印('数据类型:',two_dimension_array。D型)
<类’ numpy.ndarray ’ >
[[1 2 3]
[4 5 6]
[7 8 9]]
形状:(3, 3)
尺寸:9
数据类型:int64
24.26从 numpy 数组中获取项目
# 2 维数组
two_dimension_array = np . 阵列([[ 1,2,3 ],[ 4,5,6 ],[ 7,8,9 ]])
FIRST_ROW = two_dimension_array [ 0 ]
second_row = two_dimension_array [ 1 ]
third_row = two_dimension_array [ 2 ]
打印(“第一行:' , first_row )
打印('第二行:',second_row)
打印('第三行:',third_row)
第一行:[1 2 3]
第二行:[4 5 6]
第三行:[7 8 9]
first_column = two_dimension_array [:, 0 ]
second_column = two_dimension_array [:, 1 ]
third_column = two_dimension_array [:, 2 ]
print ( 'First column:' , first_column )
print ( 'Second column:' , second_column )
print ( '第三列: ' , third_column )
打印( two_dimension_array )
第一列:[1 4 7]
第二列:[2 5 8]
第三列:[3 6 9]
[[1 2 3]
[4 5 6]
[7 8 9]]
24.27切片 Numpy 数组
在 numpy 中切片类似于在 python list 中切片
two_dimension_array = np。数组([[ 1 , 2 , 3 ],[ 4 , 5 , 6 ], [ 7 , 8 , 9 ]])
first_two_rows_and_columns = two_dimension_array [ 0 : 2 , 0 : 2 ]
打印( first_two_rows_and_columns )
[[1 2]
[4 5]]
24.28如何反转行和整个数组?
二维数组[::]
数组([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
24.29反转行列位置
two_dimension_array = np。数组([[ 1 , 2 , 3 ],[ 4 , 5 , 6 ], [ 7 , 8 , 9 ]])
two_dimension_array [:: - 1 ,:: - 1 ]
数组([[9, 8, 7],
[6, 5, 4],
[3, 2, 1]])
24.30如何表示缺失值?
打印( two_dimension_array )
two_dimension_array [ 1 , 1 ] = 55
two_dimension_array [ 1 , 2 ] = 44
打印( two_dimension_array )
[[1 2 3]
[4 5 6]
[7 8 9]]
[[ 1 2 3]
[ 4 55 44]
[ 7 8 9]]
# Numpy
Zeroes # numpy.zeros(shape, dtype=float, order='C')
numpy_zeroes = np . 零(( 3 , 3 ), dtype = int , order = 'C' )
numpy_zeroes
数组([[0, 0, 0],
[0, 0, 0],
[0, 0, 0]])
# Numpy
归零 numpy_ones = np . 个(( 3 , 3 ), dtype = int , order = 'C' )
打印( numpy_ones )
[[1 1 1]
[1 1 1]
[1 1 1]]
两个 = numpy_ones * 2
# 重塑
# numpy.reshape(), numpy.flatten()
first_shape = np . 阵列([(1,2,3),(4,5,6)])
打印(first_shape)
重构 = first_shape。重塑(3,2)
打印(重塑)
[[1 2 3]
[4 5 6]]
[[1 2]
[3 4]
[5 6]]
扁平 = 重塑。flatten ()
扁平化
数组([1, 2, 3, 4, 5, 6])
## 水平堆栈
np_list_one = np . 数组([ 1 , 2 , 3 ])
np_list_two = np . 数组([ 4 , 5 , 6 ])
打印(np_list_one + np_list_two)
打印('水平附加:',NP。hstack((np_list_one,np_list_two)))
[5 7 9]
水平追加:[1 2 3 4 5 6]
##垂直叠
打印(‘垂直附加:’,NP。vstack((np_list_one,np_list_two)))
垂直附加:[[1 2 3]
[4 5 6]]
24.31生成随机数
# 生成一个随机浮点数
random_float = np . 随机的。随机()
random_float
0.018929887384753874
# 生成一个随机浮点数
random_floats = np . 随机的。随机( 5 )
random_floats
数组([0.26392192, 0.35842215, 0.87908478, 0.41902195, 0.78926418])
# 生成 0 到 10 之间的随机整数
random_int = np。随机的。randint ( 0 , 11 )
random_int
4
# 生成一个 2 到 11 之间的随机整数,并创建一个
单行 数组random_int = np . 随机的。randint ( 2 , 10 , size = 4 )
random_int
数组([8, 8, 8, 2])
# 生成 0 到 10 之间的随机整数
random_int = np . 随机的。randint ( 2 , 10 , size = ( 3 , 3 ))
random_int
数组([[3, 5, 3],
[7, 3, 6],
[2, 3, 3]])
24.32生成随机数
# np.random.normal(mu, sigma, size)
normal_array = np . 随机的。正常( 79 , 15 , 80 )
normal_array
数组([ 89.49990595, 82.06056961, 107.21445842, 38.69307086,
47.85259157、93.07381061、76.40724259、78.55675184、
72.17358173、47.9888899、65.10370622、76.29696568、
95.58234254、68.14897213、38.75862686、122.5587927、
67.0762565、95.73990864、81.97454563、92.54264805、
59.37035153、77.76828101、52.30752166、64.43109931、
62.63695351、90.04616138、75.70009094、49.87586877、
80.22002414、68.56708848、76.27791052、67.24343975、
81.86363935、78.22703433、102.85737041、65.15700341、
84.87033426、76.7569997、64.61321853、67.37244562、
74.4068773、58.65119655、71.66488727、53.42458179、
70.26872028、60.96588544、83.56129414、72.14255326、
81.00787609、71.81264853、72.64168853、86.56608717、
94.94667321、82.32676973、70.5165446、85.43061003、
72.45526212、87.34681775、87.69911217、103.02831489、
75.28598596、67.17806893、92.41274447、101.06662611、
87.70013935、70.73980645、46.40368207、50.17947092、
61.75618542、90.26191397、78.63968639、70.84550744、
88.91826581、103.91474733、66.3064638、79.49726264、
70.81087439, 83.90130623, 87.58555972, 59.95462521])
24.33Numpy 和统计
导入 matplotlib。pyplot as plt
将 seaborn 作为 sns
sns导入。设置()
plt。hist ( normal_array , color = "grey" , bins = 50 )
(数组([2., 0., 0., 0., 1., 2., 2., 0., 2., 0., 0., 1., 2., 2., 1., 4 ., 3.,
4., 2., 7., 2., 2., 5., 4., 2., 4., 3., 2., 1., 5., 3., 0., 3., 2. ,
1., 0., 0., 1., 3., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 1.]),
数组([ 38.69307086, 40.37038529, 42.04769973, 43.72501417,
45.4023286、47.07964304、48.75695748、50.43427191、
52.11158635、53.78890079、55.46621523、57.14352966、
58.8208441、60.49815854、62.17547297、63.85278741、
65.53010185、67.20741628、68.88473072、70.56204516、
72.23935959、73.91667403、75.59398847、77.27130291、
78.94861734、80.62593178、82.30324622、83.98056065、
85.65787509、87.33518953、89.01250396、90.6898184、
92.36713284、94.04444727、95.72176171、97.39907615、
99.07639058、100.75370502、102.43101946、104.1083339、
105.78564833、107.46296277、109.14027721、110.81759164、
112.49490608、114.17222052、115.84953495、117.52684939、
119.20416383, 120.88147826, 122.5587927 ]),
< 50 个 Patch 对象的列表> )
24.34numpy中的矩阵
Four_by_four_matrix = np . 矩阵(NP。者((4,4),D型细胞=浮动))
Four_by_four_matrix
矩阵([[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]])
NP。asarray(four_by_four_matrix)[ 2 ] = 2个
four_by_four_matrix
矩阵([[1., 1., 1., 1.],
[1., 1., 1., 1.],
[2., 2., 2., 2.],
[1., 1., 1., 1.]])
24.35numpy numpy.arange()
有时,您希望创建在定义的间隔内均匀分布的值。例如,您想创建从 1 到 10 的值;你可以使用 numpy.arange() 函数
# 使用 range(starting, stop, step) 创建列表
lst = range ( 0 , 11 , 2 )
lst
范围( 0 , 11 , 2 )
for l in lst :
打印( l )
2
4
6
8
10
# 类似于范围 arange numpy.arange(start, stop, step)
whole_numbers = np . 范围( 0 , 20 , 1 )
整数
数组([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19])
natural_numbers = np。arange ( 1 , 20 , 1 )
natural_numbers
奇数 = np。arange ( 1 , 20 , 2 )
奇数
数组([ 1, 3, 5, 7, 9, 11, 13, 15, 17, 19])
even_numbers = np。arange ( 2 , 20 , 2 )
even_numbers
数组([ 2, 4, 6, 8, 10, 12, 14, 16, 18])
24.36使用 linspace 创建数字序列
# numpy.linspace()
# numpy.logspace() in Python with Example
# 例如,它可以用来创建从 1 到 5 的 10 个均匀间隔的值。
NP。linspace ( 1.0 , 5.0 , num = 10 )
数组([1., 1.44444444, 1.88888889, 2.33333333, 2.77777778,
3.22222222, 3.66666667, 4.11111111, 4.55555556, 5.])
# 不包括区间
np 中的最后一个值。linspace ( 1.0 , 5.0 , num = 5 ,端点= False )
array([1. , 1.8, 2.6, 3.4, 4.2])
# LogSpace
# LogSpace 返回对数刻度上的偶数间隔数。Logspace 具有与 np.linspace 相同的参数。
# 句法:
# numpy.logspace(开始,停止,数量,端点)
NP。日志空间( 2 , 4.0 , num = 4 )
数组([ 100. , 464.15888336, 2154.43469003, 10000. ])
# 检查数组的大小
x = np . 阵列([ 1,2,3 ],D型细胞= NP。complex128)
X
数组([1.+0.j, 2.+0.j, 3.+0.j])
×。项目大小
16
# 在 Python 中索引和切片 NumPy 数组
np_list = np . 数组([( 1 , 2 , 3 ), ( 4 , 5 , 6 )])
np_list
数组([[1, 2, 3],
[4, 5, 6]])
打印('第一行:',np_list [ 0 ])
打印('第二行:',np_list [ 1 ])
第一行:[1 2 3]
第二行:[4 5 6]
打印('第一列:',np_list[ :,0 ])
打印('第二列:',np_list[ :,1 ])
打印('第三列:',np_list[ :,2 ])
第一列:[1 4]
第二列:[2 5]
第三列:[3 6]
24.37NumPy 统计函数与示例
NumPy 具有非常有用的统计函数,用于从数组中的给定元素中查找最小值、最大值、平均值、中位数、百分位数、标准偏差和方差等。函数解释如下 - 统计函数 Numpy 配备了如下所列的稳健统计函数
- Numpy 函数
- 最小 np.min()
- 最大 np.max()
- 平均 np.mean()
- 中位数 np.median()
- 差异
- 百分位
- 标准差 np.std()
np_normal_dis = np。随机的。正常(5,0.5,100)
np_normal_dis
##最小值,最大值,平均值,中位数,SD
打印('分钟:',two_dimension_array。分钟())
的打印('最大:',two_dimension_array。最大())
的打印(“平均: ' two_dimension_array。意思是())
#打印('中位数”,two_dimension_array.median())
打印('SD:', two_dimension_array。标准())
min: 1
max: 55
mean: 14.777777777777779
sd: 18.913709183069525
最小值: 1
最大值: 55
平均值: 14.777777777777779 标准
差: 18.913709183069525
打印(two_dimension_array)
打印('列具有最小:',NP。阿明(two_dimension_array,轴= 0))
的打印('列具有最大:',NP。AMAX(two_dimension_array,轴= 0))
的打印(“===行==”)
打印('行用最小的:',NP。阿明(two_dimension_array,轴= 1))
的打印('行用最大:',NP。AMAX(two_dimension_array,轴= 1))
[[ 1 2 3]
[ 4 55 44]
[ 7 8 9]]
Column with minimum: [1 2 3]
Column with maximum: [ 7 55 44]
=== Row ==
Row with minimum: [1 4 7]
Row with maximum: [ 3 55 9]
24.38如何创建重复序列?
a = [ 1 , 2 , 3 ]
#整个重复的'A'两次
打印('平铺:',NP。瓷砖(一,2))
#重复的'A'两次各元件
打印('重复:',NP。重复(一,2))
Tile: [1 2 3 1 2 3]
Repeat: [1 1 2 2 3 3]
24.39如何生成随机数?
# [0,1)
one_random_num = np之间的一个随机数。随机的。随机()
one_random_in = np。随机
打印(one_random_num)
0.6149403282678213
0.4763968133790438
0.4763968133790438
# 形状为 2,3 的 [0,1) 之间的随机数
r = np . 随机的。随机( size = [ 2 , 3 ])
打印( r )
[[0.13031737 0.4429537 0.1129527 ]
[0.76811539 0.88256594 0.6754075 ]]
打印( np . random . choice ([ 'a' , 'e' , 'i' , 'o' , 'u' ], size = 10 ))
['u' 'o' 'o' 'i' 'e' 'e' 'u' 'o' 'u' 'a']
[ 'i' 'u' 'e' 'o' 'a' 'i' 'e' 'u' 'o' 'i' ]
['iueoaieuoi']
## 形状 2, 2 的 [0, 1] 之间的随机数
rand = np . 随机的。兰特( 2 , 2 )
兰特
array([[0.97992598, 0.79642484],
[0.65263629, 0.55763145]])
rand2 = np。随机的。randn ( 2 , 2 )
rand2
array([[ 1.65593322, -0.52326621],
[ 0.39071179, -2.03649407]])
# 形状为 2,5 的 [0, 10) 之间的随机整数
rand_int = np . 随机的。randint ( 0 , 10 , size = [ 5 , 3 ])
rand_int
array([[0, 7, 5],
[4, 1, 4],
[3, 5, 3],
[4, 3, 8],
[4, 6, 7]])
从 scipy 导入 统计
np_normal_dis = np。随机的。正常(5,0.5,1000)#平均值,标准偏差,样本数
np_normal_dis
##最小值,最大值,平均值,中位数,SD
打印('分钟:',NP。分钟(np_normal_dis))
打印('最大:',np . max ( np_normal_dis ))
print ( 'mean: ' , np .均值(np_normal_dis))
打印('中位数:',NP。中值(np_normal_dis))
打印('模式:',统计信息。模式(np_normal_dis))
打印('SD:',NP。STD(np_normal_dis))
分钟:3.557811005458804
最大:6.876317743643499
平均值:5.035832048106663
中位数:5.020161980441937
模式:模式结果(模式=数组([3.55781101]),计数=数组([1]))
标准差:0.489682424165213
PLT。hist ( np_normal_dis , color = "grey" , bins = 21 )
plt。显示()

# numpy.dot(): Python 中使用 Numpy 的
Dot Product
# Dot Product # Numpy 是强大的矩阵计算库。例如,您可以使用 np.dot 计算点积
# 句法
# numpy.dot(x, y, out=None)
24.40线性代数
点积
## 线性代数
### 点积:两个数组的乘积
f = np。数组([ 1 , 2 , 3 ])
g = np。数组([ 4 , 5 , 3 ])
### 1*4+2*5 + 3*6
np . 点( f , g ) # 23
24.41NumPy 矩阵乘法与 np.matmul()
### Matmul:两个数组的矩阵乘积
h = [[ 1 , 2 ],[ 3 , 4 ]]
i = [[ 5 , 6 ],[ 7 , 8 ]]
### 1*5+2*7 = 19
纳米。matmul ( h , i )
数组([[19, 22],
[43, 50]])
##行列式2*2矩阵
###5*8-7*6np.linalg.det(i)
NP。linalg。检测( i )
-1.999999999999999
Z = np。零(( 8 , 8 ))
Z [ 1 :: 2 ,:: 2 ] = 1
Z [:: 2 , 1 :: 2 ] = 1
Z
array([[0., 1., 0., 1., 0., 1., 0., 1.],
[1., 0., 1., 0., 1., 0., 1., 0.],
[0., 1., 0., 1., 0., 1., 0., 1.],
[1., 0., 1., 0., 1., 0., 1., 0.],
[0., 1., 0., 1., 0., 1., 0., 1.],
[1., 0., 1., 0., 1., 0., 1., 0.],
[0., 1., 0., 1., 0., 1., 0., 1.],
[1., 0., 1., 0., 1., 0., 1., 0.]])
new_list = [ x + 2 for x in range ( 0 , 11 )]
新列表
[2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]
[ 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 , 11 , 12 ]
[2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]
np_arr = np。数组(范围( 0 , 11 ))
np_arr + 2
数组([ 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12])
对于具有线性关系的量,我们使用线性方程。让我们看看下面的例子:
温度 = np。数组([ 1 , 2 , 3 , 4 , 5 ])
pressure = temp * 2 + 5
pressure
数组([ 7, 9, 11, 13, 15])
PLT。绘图(温度,压力)
plt。xlabel('摄氏温度')
plt。ylabel('atm 中的压力')
plt。标题('温度与压力')
plt。xticks(NP。人气指数(0,6,步骤= 0.5))
PLT。显示()

使用 numpy 绘制高斯正态分布。如下所示,numpy 可以生成随机数。要创建随机样本,我们需要均值(mu)、sigma(标准差)、数据点数。
mu = 28
西格玛 = 15 个
样本 = 100000
x = np。随机的。正常(mu , sigma ,样本)
ax = sns。分布图( x );
斧头。设置( xlabel = "x" , ylabel = 'y' )
plt。显示()
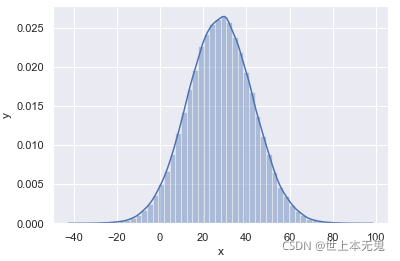
总而言之,与 python 列表的主要区别是:
- 数组支持向量化操作,而列表不支持。
- 一旦创建了数组,就不能更改其大小。您将不得不创建一个新阵列或覆盖现有阵列。
- 每个数组都有一个且只有一个 dtype。其中的所有项目都应该是那个 dtype。
- 等效的 numpy 数组比 Python 列表占用的空间少得多。
- numpy 数组支持布尔索引。
第 25 天 - Pandas
Pandas 是一种开源、高性能、易于使用的 Python 编程语言的数据结构和数据分析工具。Pandas 添加了数据结构和工具,旨在处理类似表格的数据,即Series和Data Frames。Pandas 提供了用于数据操作的工具:
- 重塑
- 合并
- 排序
- 切片
- 聚合
- 插补。如果您使用的是 anaconda,则无需安装 pandas。
25.1安装pandas
对于 Mac:
pip 安装 conda
conda 安装 pandas
对于 Windows:
pip 安装 conda
pip 安装 熊猫
Pandas 数据结构基于Series和DataFrames。
一个系列是一列和一个数据帧是一个多维表的集合组成系列。为了创建一个pandas系列,我们应该使用numpy来创建一个一维数组或一个python列表。让我们看一个系列的例子:
命名pandas系列
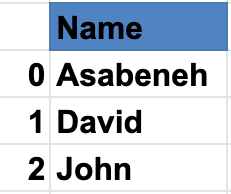
国家系列

城市系列

如您所见,pandas 系列只是一列数据。如果我们想要多列,我们使用数据框。下面的示例显示了 Pandas DataFrames。
让我们看看一个 Pandas 数据框的例子:
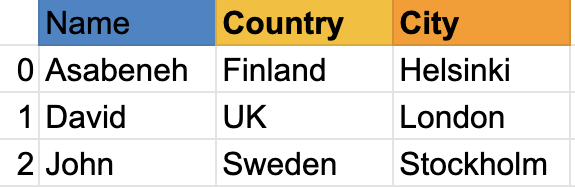
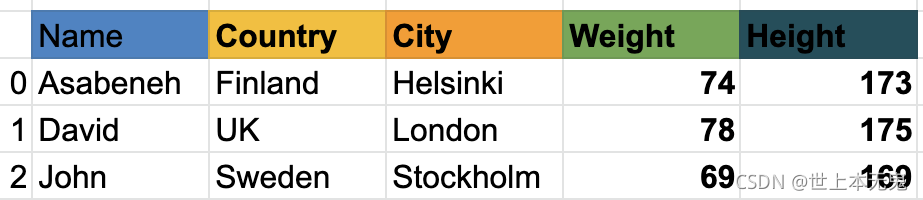
数据框是行和列的集合。看下表;它比上面的例子有更多的列:
接下来,我们将看到如何导入pandas以及如何使用pandas创建Series和DataFrames
导入pandas
import pandas as pd # 将pandas 导入为pd
import numpy as np # 将numpy 导入为np
25.2使用默认索引创建 Pandas 系列
nums = [ 1 , 2 , 3 , 4 , 5 ]
s = pd。系列( nums )
打印( s )
0 1
1 2
2 3
3 4
4 5
数据类型:int64
25.3使用自定义索引创建 Pandas 系列
nums = [ 1 , 2 , 3 , 4 , 5 ]
s = pd。系列( nums , index = [ 1 , 2 , 3 , 4 , 5 ])
打印( s )
1 1
2 2
3 3
4 4
5 5
数据类型:int64
水果 = [ 'Orange' , 'Banana' , 'Mango' ]
水果 = pd . 系列(水果,指数= [ 1,2,3 ])
打印(水果)
1 橙色
2 香蕉
3 芒果
数据类型:对象
25.4从字典创建 Pandas 系列
dct = { 'name' : 'Asabeneh' , 'country' : '芬兰' , 'city' : '赫尔辛基' }
s = pd。系列( dct )
打印( s )
姓名 Asabeneh
国家芬兰
赫尔辛基市
数据类型:对象
25.5创建一个常量 Pandas 系列
s = pd。系列( 10 , index = [ 1 , 2 , 3 ])
打印( s )
1 10
2 10
3 10
数据类型:int64
25.6使用 Linspace 创建 Pandas 系列
s = pd。系列( np . linspace ( 5 , 20 , 10 )) # linspace(starting, end, items)
打印( s )
0 5.000000
1 6.666667
2 8.333333
3 10.000000
4 11.666667
5 13.333333
6 15.000000
7 16.666667
8 18.333333
9 20.000000
数据类型:float64
25.7数据帧
Pandas 数据框可以用不同的方式创建。
从列表列表创建数据帧
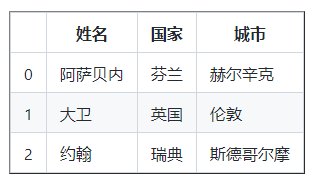
数据 = [
[ “阿萨本尼”、“芬兰”、“赫尔辛克” ]、
[ '大卫','英国','伦敦' ],
[ “约翰”、“瑞典”、“斯德哥尔摩” ]
]
df = pd。DataFrame ( data , columns = [ 'Names' , 'Country' , 'City' ])
打印( df )
25.8使用字典创建 DataFrame
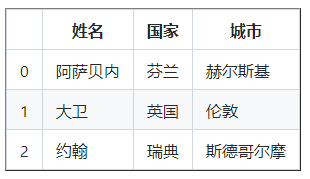
data = { 'Name' : [ 'Asabeneh' , 'David' , 'John' ], '国家' :[
'芬兰' , '英国' , '瑞典' ], '城市' : [ '赫尔斯基' , '伦敦' , '斯德哥尔摩' ]}
df = pd . DataFrame(数据)
打印(df)
25.9从字典列表创建数据帧
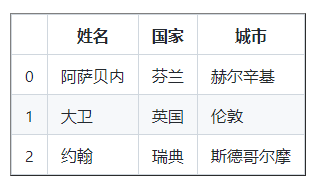
数据 = [
{ '姓名' : 'Asabeneh' , '国家' : '芬兰' , '城市' : '赫尔辛基' },
{ '姓名':'大卫','国家':'英国','城市':'伦敦' },
{ '姓名':'约翰','国家':'瑞典','城市':'斯德哥尔摩' }]
df = pd . DataFrame(数据)
打印(df)
25.10使用 Pandas 读取 CSV 文件
要下载 CSV 文件,本例中需要什么,控制台/命令行就足够了:
curl -O https://raw.githubusercontent.com/Asabeneh/30-Days-Of-Python/master/data/weight-height.csv
将下载的文件放在您的工作目录中。
将 Pandas 导入为 pd
df = pd。read_csv ( 'weight-height.csv' )
打印( df )
25.11数据探索
让我们使用 head() 仅读取前 5 行
print ( df . head ()) # 给五行我们可以通过将参数传递给 head() 方法来增加行数

让我们还使用 tail() 方法探索数据帧的最后记录。
打印(DF。尾()) #尾巴给最后的五排,我们可以通过传递参数尾法提高行
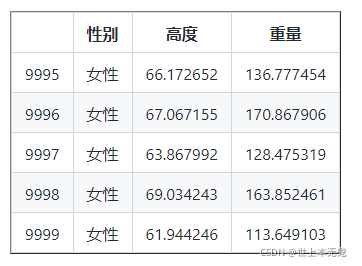
如您所见,csv 文件有三行:性别、身高和体重。如果 DataFrame 有很长的行,就很难知道所有的列。因此,我们应该使用一种方法来知道列。我们不知道行数。让我们使用形状肉类。
print ( df . shape ) # 如你所见 10000 行和三列
(10000, 3)
让我们使用列获取所有列。
打印(df。列)
Index(['Gender', 'Height', 'Weight'], dtype='object')
现在,让我们使用列键获取特定列
heights = df [ 'Height' ] # 这是一个系列
打印(高度)
0 73.847017
1 68.781904
2 74.110105
3 71.730978
4 69.881796
...
9995 66.172652
9996 67.067155
9997 63.867992
9998 69.034243
9999 61.944246
名称:高度,长度:10000,数据类型:float64
weights = df [ 'Weight' ] # 这是一个系列
打印(重量)
0 241.893563
1 162.310473
2 212.740856
3 220.042470
4 206.349801
...
9995 136.777454
9996 170.867906
9997 128.475319
9998 163.852461
9999 113.649103
名称:重量,长度:10000,dtype:float64
打印(len(高度)== len(权重))
True
describe() 方法提供数据集的描述性统计值。
print ( heights . describe ()) # 给出高度数据的统计信息
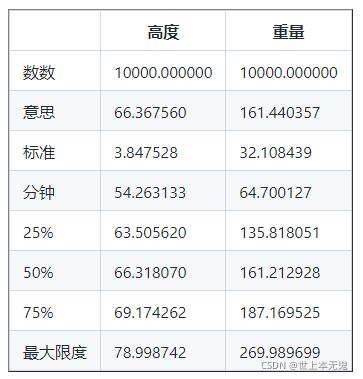
数 10000.000000
平均 66.367560
标准 3.847528
分钟 54.263133
25% 63.505620
50% 66.318070
75% 69.174262
最大 78.998742
名称:高度,数据类型:float64
打印(权重。描述())
数 10000.000000
平均 161.440357
标准 32.108439
最低 64.700127
25% 135.818051
50% 161.212928
75% 187.169525
最大 269.989699
名称:重量,数据类型:float64
print ( df . describe ()) # describe 还可以给出来自数据帧的统计信息
与 describe() 类似,info() 方法也提供有关数据集的信息。
25.12修改数据帧
修改DataFrame: * 我们可以创建一个新的DataFrame * 我们可以创建一个新列并将其添加到DataFrame, * 我们可以从DataFrame 中删除现有列, * 我们可以修改DataFrame 中的现有列, * 我们可以更改 DataFrame 中列值的数据类型
25.13创建数据帧
与往常一样,首先我们导入必要的包。现在,让我们导入 pandas 和 numpy,这两个最好的朋友。
将Pandas 导入为 pd
将 numpy 导入为 np
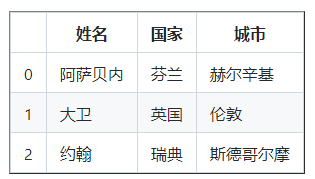
数据 = [
{ “姓名”:“阿萨本尼”,“国家”:“芬兰”,“城市”:“赫尔辛基” },
{ “姓名”:“大卫”,“国家”:“英国”,“城市”:“伦敦” },
{ “姓名”:“约翰”,“国家”:“瑞典”,“城市”:“斯德哥尔摩” }]
df = pd . DataFrame(数据)
打印(df)
向 DataFrame 添加列就像向字典添加键。
首先让我们使用前面的示例来创建一个 DataFrame。创建 DataFrame 后,我们将开始修改列和列值。
25.14添加新列
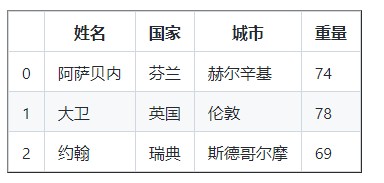
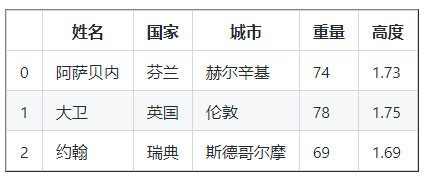
让我们在 DataFrame 中添加一个权重列
权重 = [ 74 , 78 , 69 ]
df [ 'Weight' ] = 权重
df
让我们在 DataFrame 中添加一个高度列
高度 = [ 173 , 175 , 169 ]
df [ '高度' ] = 高度
打印( df )
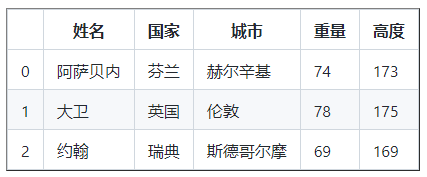
正如您在上面的 DataFrame 中看到的,我们确实添加了新的列,重量和高度。让我们通过使用他们的体重和身高计算他们的 BMI 来添加一个额外的列,称为 BMI(身体质量指数)。BMI 是质量除以身高的平方(以米为单位)- 体重/身高 * 身高。
如您所见,高度以厘米为单位,因此我们应该将其更改为米。让我们修改高度行。
25.15修改列值
df [ '高度' ] = df [ '高度' ] * 0.01
df
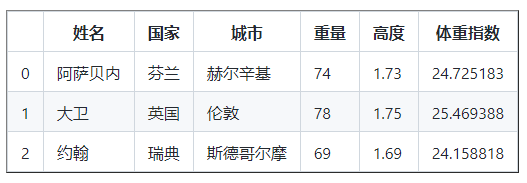
# 使用函数使我们的代码更简洁,但是你可以不用一个来计算 bmi
def calculate_bmi ():
weights = df [ 'Weight' ]
heights = df [ 'Height' ]
bmi = []
for w , h in zip ( weights ,高度):
b = w / ( h * h )
bmi。追加( b )
返回 体重指数
bmi = calculate_bmi ()
df [ 'BMI' ] = bmi
df
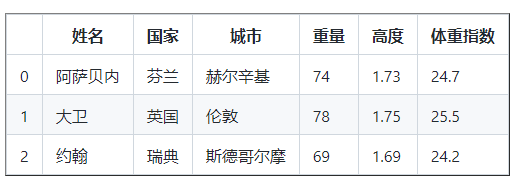
25.16格式化 DataFrame 列
DataFrame 的 BMI 列值是浮点数,小数点后有许多有效数字。让我们将其更改为一位有效数字。
df [ 'BMI' ] = round ( df [ 'BMI' ], 1 )
打印( df )
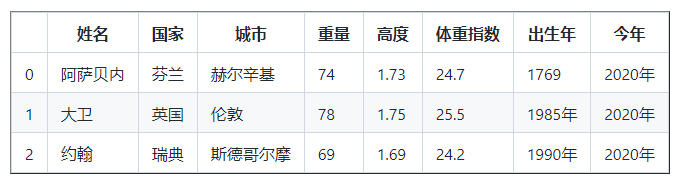
DataFrame 中的信息似乎还没有完成,让我们添加出生年份和当前年份列。
birth_year = [ '1769' , '1985' , '1990' ]
current_year = pd。系列( 2020 , index = [ 0 , 1 , 2 ])
df [ 'Birth Year' ] = birth_year
df [ 'Current Year' ] = current_year
df
25.17检查列值的数据类型
打印(DF,重量,D型)
数据类型(' int64 ')
df [ '出生年份' ]。dtype # 它给出字符串对象,我们应该将其更改为数字
df [ '出生年份' ] = df [ '出生年份' ]。astype ( 'int' )
print ( df [ 'Birth Year' ]. dtype ) # 现在检查数据类型
数据类型(' int32 ')
现在与当年相同:
df [ '当年' ] = df [ '当年' ]。astype ( 'int' )
df [ '本年' ]。数据类型
数据类型(' int32 ')
现在,出生年份和当前年份的列值为整数。我们可以计算年龄。
年龄 = df [ '本年' ] - df [ '出生年份' ]
年龄
0 251
1 35
2 30
dtype: int32
df [ '年龄' ] = 年龄
打印(df)
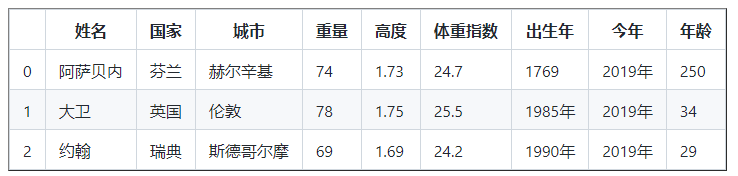
第一排的人迄今活了251岁。一个人不可能活这么久。要么是打字错误,要么是数据被煮熟了。因此,让我们用列的平均值填充该数据,而不包括异常值。
平均值 = (35 + 30)/ 2
mean = ( 35 + 30 ) / 2
print ( 'Mean: ' , mean ) #在输出中添加一些描述很好,所以我们知道什么是什么
平均值:32.5
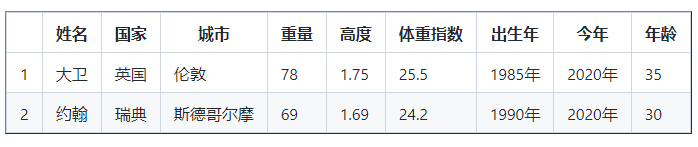
25.18布尔索引
打印( df [ df [ '年龄' ] > 120 ])

打印( df [ df [ '年龄' ] < 120 ])
初学者挑战学习Python编程30天还有最后一节续集就要结束了,感兴趣了解下面的学习内容,记得关注我。