一:硬件环境:
深度学习模块训练运算量较大,依赖GPU进行加速,硬件需独立显卡支撑,目前训练只支持英伟达核心显卡。显卡硬件配置越高,训练及预测耗时越短。
1,模型训练:
本地训练
a) 6G及以上显存 DL单字符识别训练实现显存自适应,能根据硬件配置自动分配训练显存,从耗时等综合因素考虑推荐采用6G及以上显存显卡训练,如GTX1660Super,RTX
2080,RTX 3070等
b) 需去英伟达显卡驱动官网(https://www.nvidia.cn/geforce/drivers/),根据电脑显卡型号下载451.22版本以上驱动
c) VisionTrain1.4(VM4.0)版本已支持30系列显卡训练(预测),以前版本不支持
支持萤石云服务器训练
支持本地云服务器训练
2,模型检测:
支持GPU版本检测 (需2G及以上显存。单DL模块2G显存可以满足,多DL流程或单流程多DL模块需更大的显存)
支持CPU版本检测 (效果与GPU版本一致,检测耗时会比GPU版本长)
操作系统要求为Windows7或Windows10 (系统需要安装完整版)若显卡配置符合条件,发现无法进行训练或预测,则需检查显卡驱动,要求安装451.22版本以上显卡驱动(显卡驱动的要求和显卡本身以及VM的版本有关)
二:适用场景:
DL图像检索就是利用图像的语义信息,如颜色、纹理、布局等进行分析和检索的技术。从功能上来说与图像分类类似,把整张图像归为若干类别中的某一类,在物体识别与分拣上有广泛的应用。从算法
本质上来说存在较大的区别:
图像分类:
分类模型从图像中提取到图像特征,直接通过内嵌分类器输出图像类别。适用于类间差异较大的图像场景,且分类器输出类别数与模型绑定,模型生成后,类别数无法进行扩增。
图像检索:
检索模型从图像中提取到图像特征,并无内置分类器,不进行直接分类,而是通过与数据库
(Gallery)中所有图像的特征进行相似性搜索,将库中的图像按照相似度大小进行排列,
输出指定的TopN结果。适用于类内差异较小的图像场景,且可以通过向数据库中注册新的
类别进行类别扩增。
总结:
1、图像检索更适合用于同类内差异较小,图像分类适合同类内差异较大的情况。如:区分香蕉和苹
果两类。其中苹果类中包含不同品种的苹果(红富士苹果、青苹果等),不同品种的苹果差异较大,
更适合用图像分类。

2、若后续增加新的类别,图像检索只需进行注册(将新类别加入数据库),无需重新训练模型,快速
方便。图像分类则无法直接进行扩增,只能将新类型加入训练集重新训练。
三:DL图像检索训练和测试
一)深度学习图像检索-模型训练:
1)双击VisionTrain1.4.0软件,打开DL训练工具
注:VM3.4之前版本训练工具都集成在VM软件内,可在VM软件内直接打开。VM3.4之后版本训练工具独立成为一个软件VisionTrain(需单独安装)与VM分开。
2)选择VM训练平台,选择图像检索模块,点击下一步。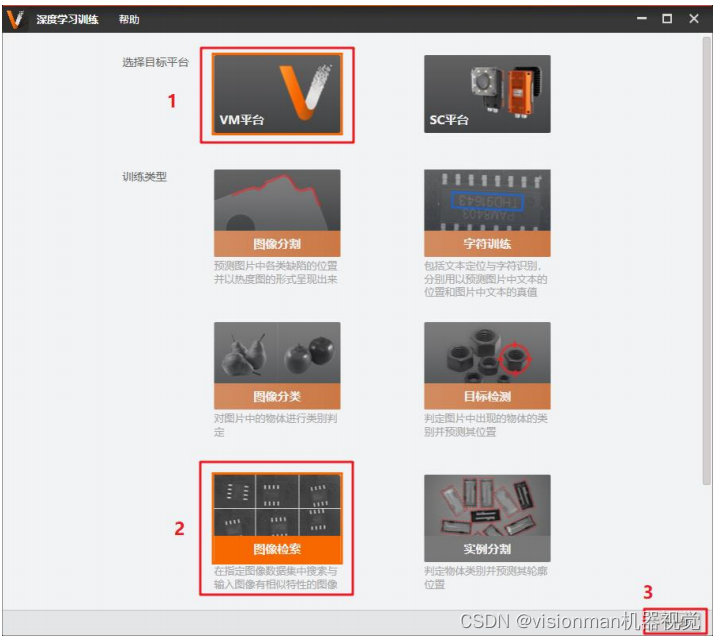
3)点击新建训练集,选择训练图片所在的文件夹,点击确定加载图片(训练图片不得少于11张)。
注:DL图像检索训练集内必须包括2类及以上的类型,否则在开始训练时会提示“标签类别数错误”。
为了保证效果,尽量保证不同类别的图像数目有相同的量级,不能相差太悬殊。
4)传统标定:对图片进行标定,每类图片分别输入对应的类别名称。
(注:当图片数量较多时,此类标注方式较为繁琐,可用快速标定方式,见下)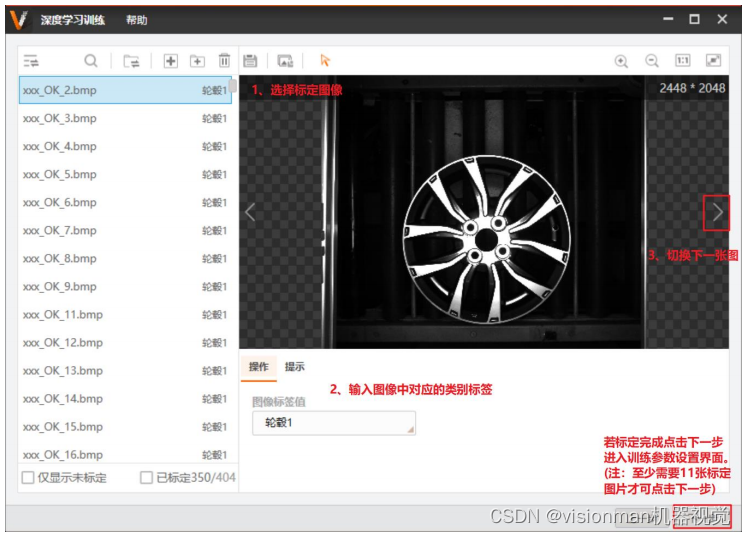
快速标定:新建一个空文件夹为训练集,将不同类图片分别放置不同的文件夹,文件夹名称为其
快速标定:新建一个空文件夹为训练集,将不同类图片分别放置不同的文件夹,文件夹名称为其
内图片的类别名称。步骤如下:
4.1 点击新建训练集打开空训练集文件夹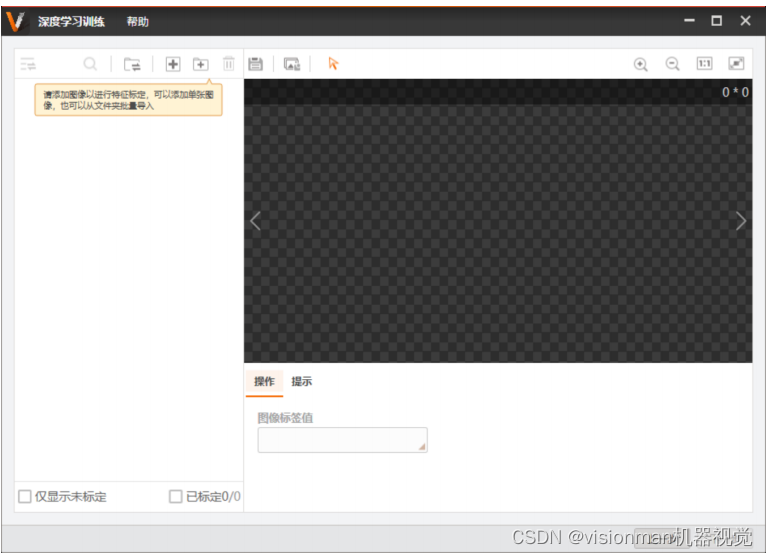
4.2 点击添加文件夹按钮,选择已经分类好的图片文件夹,点击确定。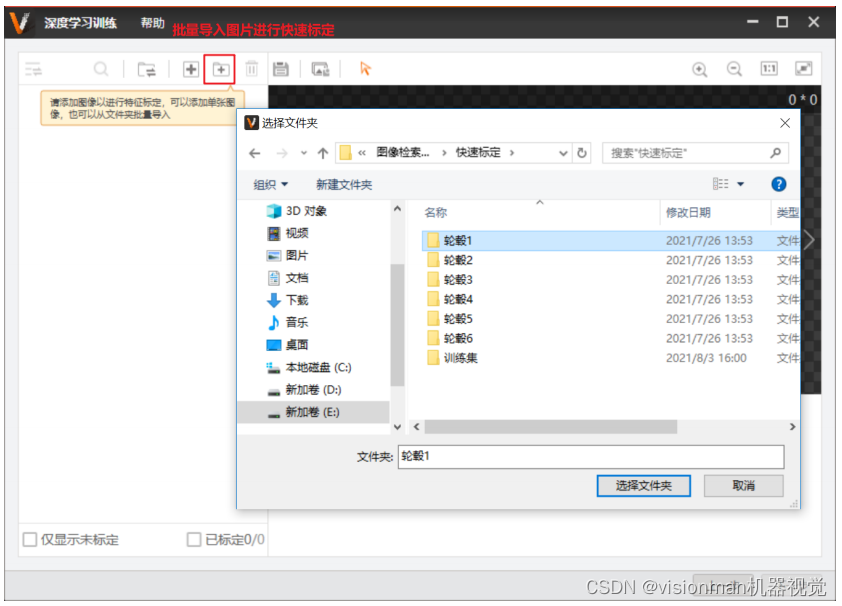
4.3 点击“是”,进行文件夹内图片批量标定。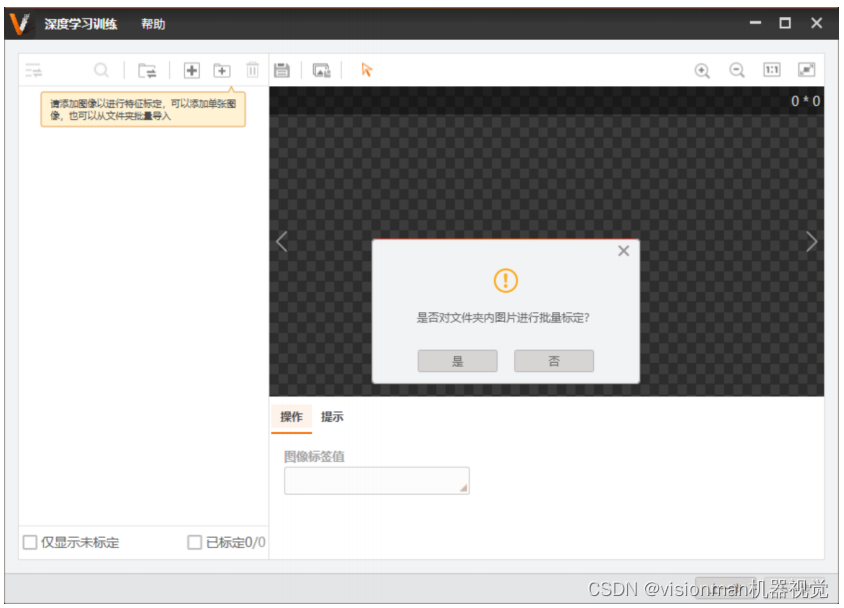
4.4 输入此类图片的类别名称(默认为文件夹名称),点击“保存”。软件将会自动将此文件夹内图片复制到空训练集文件夹,并批量进行标注。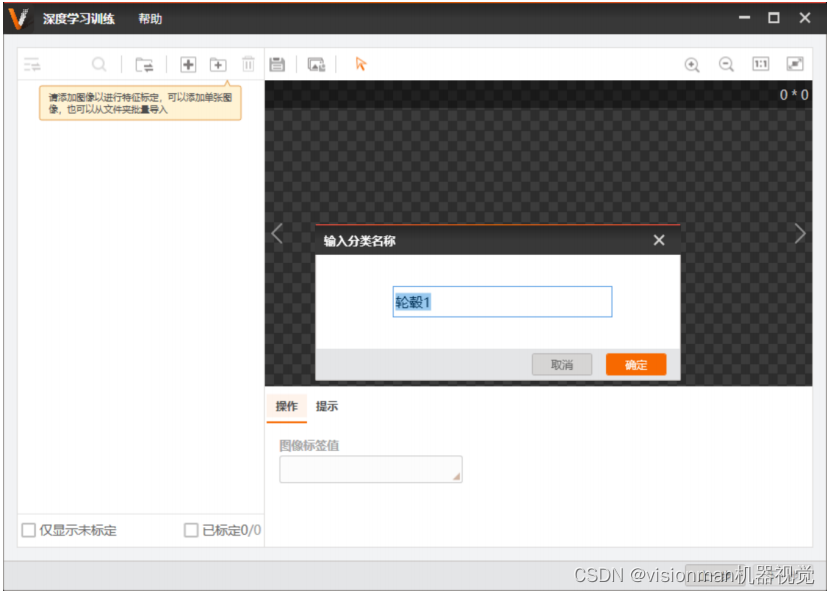
4.5 继续点击添加文件夹按钮,依次添加其它类别图片。
4.6 预标定功能
4.6.1 预标定通常是模型已经生成,在加入新样本的时,通过先前的模型预测新加入样本标签,提升打标的速度。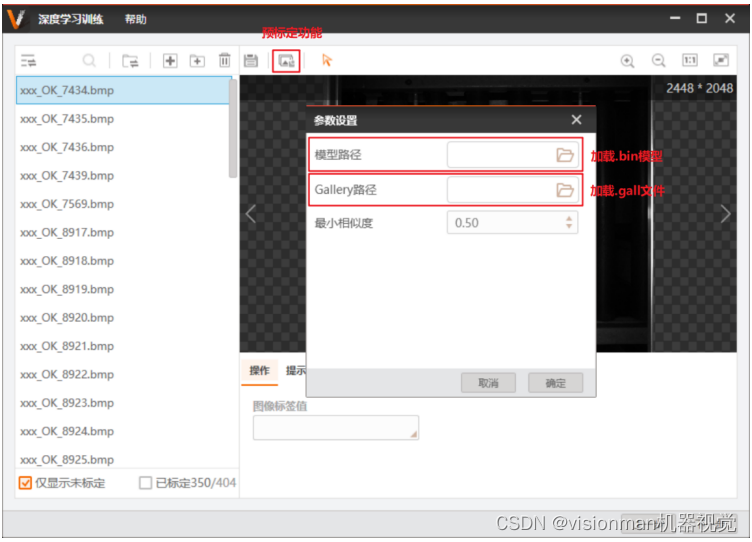
4.6.2 使用用预标定功能需要具备2G以上的英伟达显卡,安装较新的显卡驱动,且需要
加密狗。预标定的效果是根据加载模型决定的,一般需要对标签值进行微调,检查预测类别是否错误。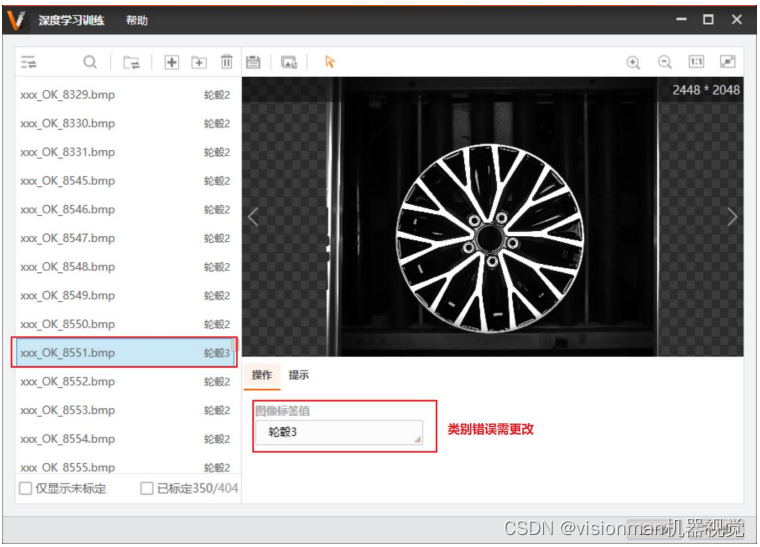
5)配置训练参数和训练。
5.1 配置训练参数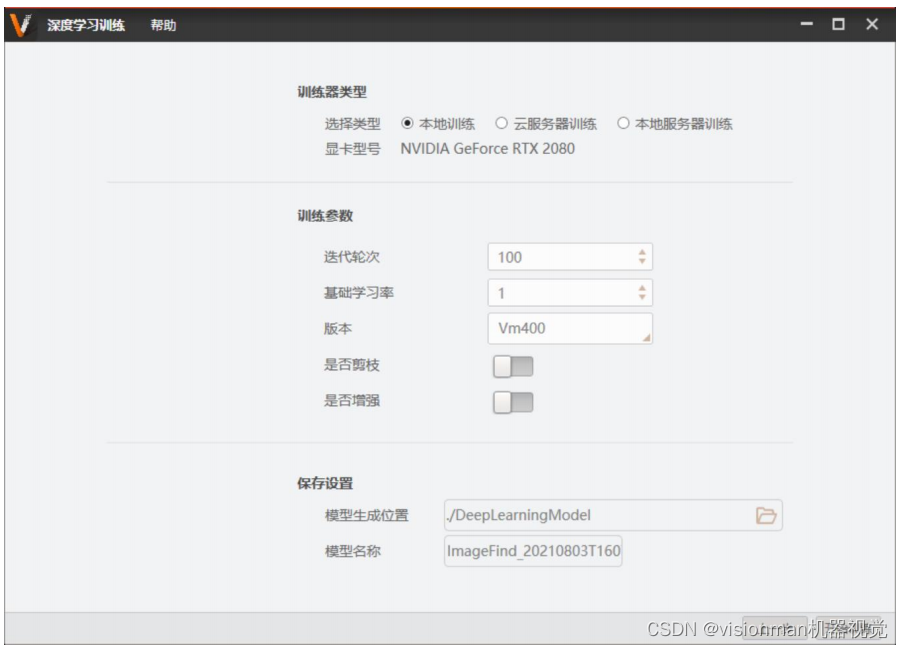
训练器类型:
(1) 本地训练:依托于本地电脑显卡进行训练。
(2) 云服务器训练:训练参数设置与本地训练完全一致,版本目前只能选择VM340,暂不支持VM400版本模型云服务器训练。参数设置完成后点击开始训练,会显示“训练集上传中”,并会在目录下生成一个压缩包。在提示时间内完成训练后会在对应的位置生成模型。
(3) 本地服务器训练:将本地带显卡的训练机配置成本地服务器,与此服务器联网的电脑均可选选择本地服务器进行训练,自动上传图片和下载模型。(如需配置本地服务器请先联系海康技术支持)
迭代轮次:算法内部称为Epoch,一轮就是将所有训练样本训练一次的过程。增大迭代伦次可以增加训练的迭代次数。参数根据图片数量设置。30张设置700轮。100张设置500轮。500张设置200轮。1000张设置150轮。5000张设置100轮。10000张设置60轮。100000张设置50轮。若训练过程中曲线任有明显的下降趋势,可以暂停训练增大迭代伦次。
基础学习率:更新参数时前进的步长。一般按默认值1设置,不需改动。
版本:目前提供VM340、VM400两个版本模型训练。VM340版本模型能在VM3.4及更高的VM版本如VM4.0上使用,VM400版本模型只能在VM4.0及更高的VM版本使用。
是否剪纸枝:开启剪枝使能后,能设置剪枝比例。根据设置的比例减小模型大小,缩短检测耗时,同时也会损失一定的检测精度与增加训练耗时。若节拍满足不建议开启。
是否增强:开启增强使能后,可设置数据增强参数。可进行HSV空间变换、镜像、画布扩大、裁剪、仿射变换、噪声这六类数据增强的操作。具体设置见“数据增强白皮书”。
5.2 训练过程。
随着迭代次数增加,训练误差逐渐下降,到训练结束时训练误差会平稳在一个较低的值(DL图像检索训练一般收敛在0.5~0.6之间)。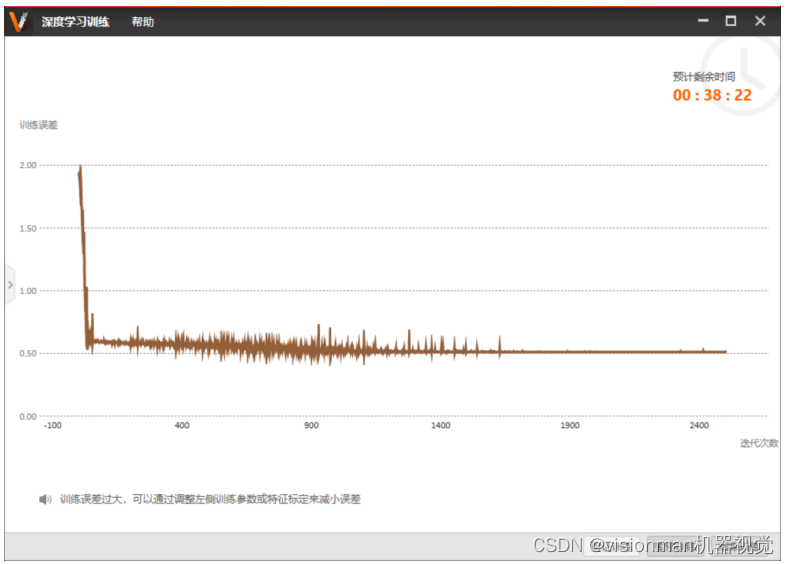
(注:若在训练过程中发现曲线到训练快结束时还有明显的下降趋势,可以点击暂停训练增大迭代次
数。当训练到一定的迭代次数后,可以点击验证训练,查看在次迭代次数下模型的验证效果)
训练结束后,会在指定的路径生成一个“xxx.bin”的模型文件和“xxx.gall”的数据库(gallery)
文件,将两者加载到DL图像检索模块中,测试模型效果。若训练结束后无自动生成gallery文件,需在VM软件的DL图像检索模块中手动注册,注册方法见下方预测流程。
注:如果训练集图片中存在无法读取的图像,自动生成gallery文件将会失败。
二)深度学习图像检索-测试模型:
1)拉出一个图像源模块,点击右下角的 或 将需要测试图片放入模块中。
2)拉出一个DL图像检索G模块,与图像源模块连接。(使用GPU版本还是CPU版本根据实际需求决定)
3)双击模块设置参数,选择运行参数。模型文件(.bin)路径和Gallery(.gall)路径选择训练好的两个文件位置;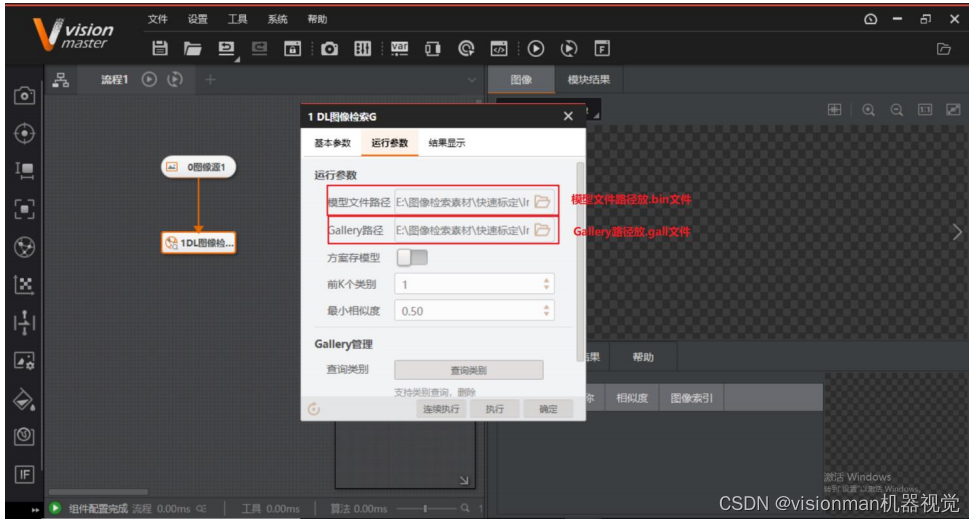
方案存模型使能:若打开使能,模型将会保存到方案中,方案拷贝或移动时不用重新加载模型路径。(同时方案会变大)
前K个类别:默认为1,最大为10。如下:轮毂一共有7类,前K个类别设置大于或等于7,将会根据相似度从大到小依次显示出其对应的类别名称与相似度。若只需要获得最相似结果,设为1。
最小相似度:预测图片与输出类别的相似度,低于最小相似度分数的类别将会被过滤。
注:在预测时若发现有图片没有输出类别名称,可降低最小相似度查看是否能够识别。
Gallery管理:若在训练模型过程中无自动生成gallery文件,则需手动注册。
3.1 点击注册图像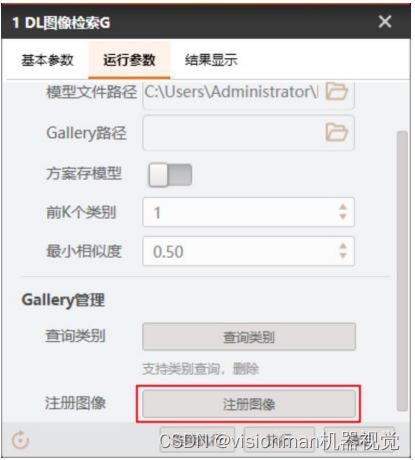
3.3 加载gallery,并向其添加其它类别的图片。步骤如3.2,可点“保存”直接覆盖原gallery,或“另存为”重新生成新gallery。
注:当后续有新产品,需要增加新的比对类别时,操作与此步骤一致。
当新增类别数量大于训练类别数量的70~80%时,需将新增类别加入训练集重新训练模型以保证识别效果。如训练集有100类,后续注册的新产品到达70类时,需将这70类也加入到训练集训练。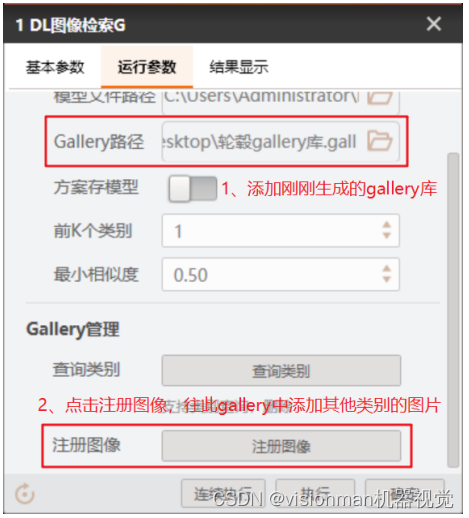
若删除了此类的注册图像可点击保存按钮,直接覆盖原gallery。或另存为一个新gallery。
点击右上角的 按钮,可以将此gallery里的注册信息导出成txt,如下。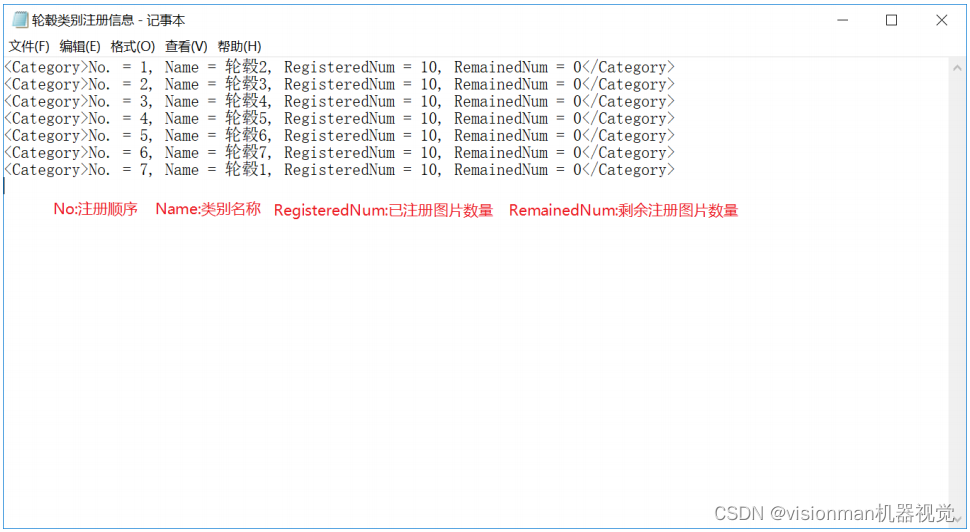
4)点击
运行按钮,观察测试结果是否与想要的一致;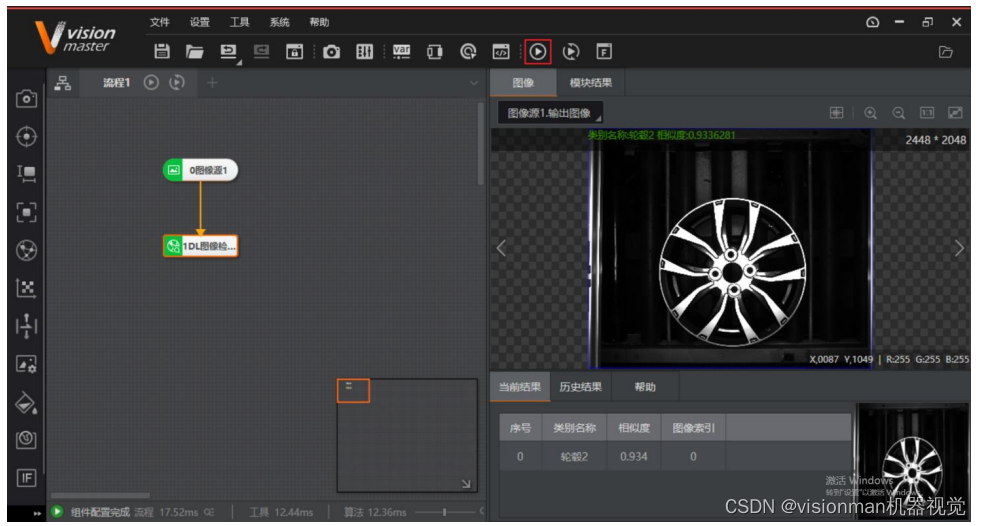
四:系统运行过程中继续添加样本的方法
在系统运行过程或实际现场应用中,通常训练的模型不能一次到位,适用于所有的场景,需要在运行
过程中不断添加样本,增强模型的鲁棒性。方法是:
1,之前标定的样本图片及标定文件RetrievalTrainData.txt不能删除,新采集或识别错误的样
本需要放到之前的训练样本文件夹中去(或者直接在训练工具中添加)。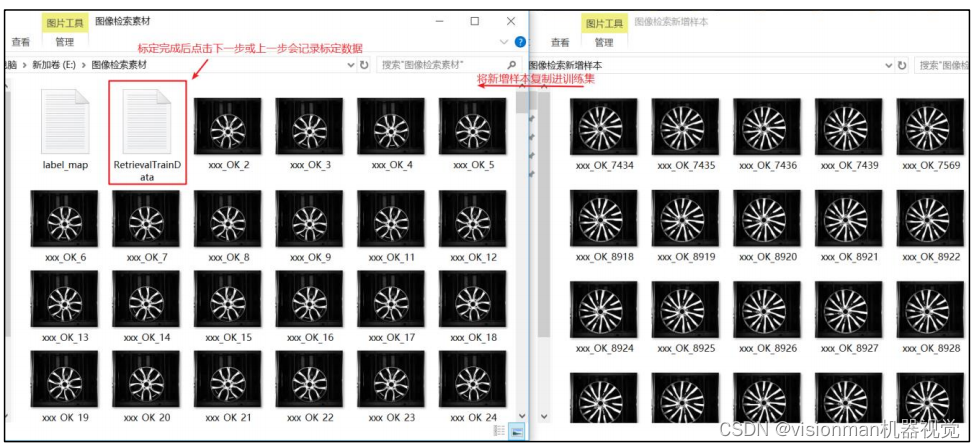
2,重新打开“深度学习训练工具”,像之前的训练标定一样,将新增的样本标定。之前标定的数据还保存在样本的文件夹中,只需要把新采集的样本标定好,重新训练。训练的过程如上。