生成你的漫画形象! 漫画风格迁移神器 AnimeGANv2
文章目录
生成你的漫画形象! 漫画风格迁移神器 AnimeGANv2快速在线生成你的漫画形象AnimeGAN 简要介绍与其他动漫风格迁移模型的效果对比AnimeGANv2 的优点AnimeGANv2 风格多样化AnimeGANv2 网络结构快速生成你的漫画形象导入人脸检测模型可视化landmarks预处理图片漫画风格图片生成利用本地图片生成 利用在线图片生成趁着有空的时间,给大家介绍一些有趣的项目吧,比如这个漫画风格迁移神器 AnimeGANv2,可以快速生成自己的漫画形象

快速在线生成你的漫画形象
首先告诉大家怎么用,可能这是大家最感兴趣的啦
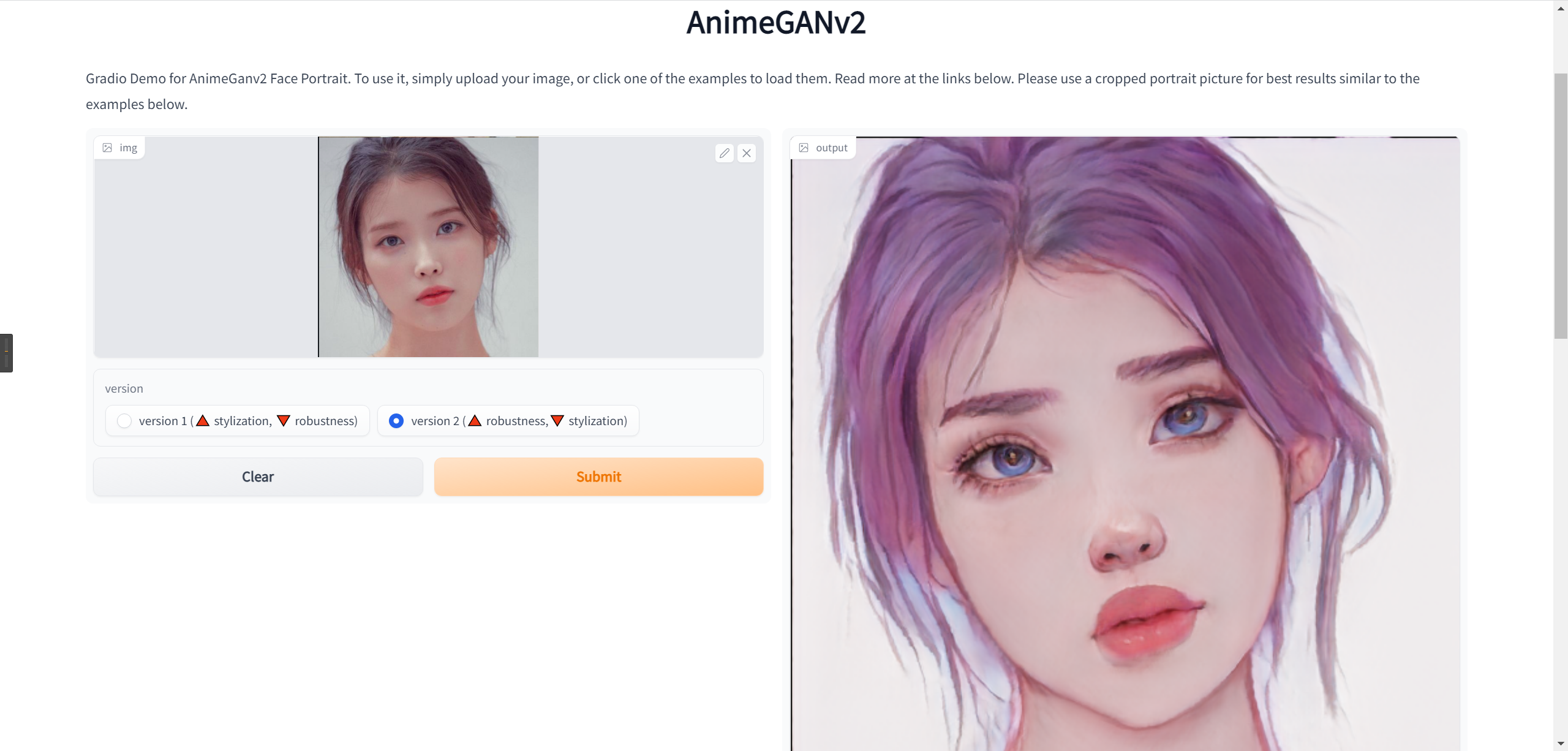
如果希望能够在线生成自己的漫画形象的话,首先可以简单使用hungging face https://huggingface.co/spaces/akhaliq/AnimeGANv2,这里面可以快速生成自己的漫画形象,也可以选择一些明星来生成。
以下就是简单的在线生成自己的漫画形象,并且可以选择v1还是v2来生成自己的漫画形象
AnimeGAN 简要介绍
动漫是我们日常生活中常见的艺术形式,被广泛应用于广告、电影和儿童教育等多个领域。目前,动漫的制作主要是依靠手工实现。然而,手工制作动漫非常费力,需要非常专业的艺术技巧。对于动漫艺术家来说,创作高质量的动漫作品需要仔细考虑线条、纹理、颜色和阴影,这意味着创作动漫既困难又耗时。因此,能够将真实世界的照片自动转换为高质量动漫风格图像的自动技术是非常有价值的。它不仅能让艺术家们更多专注于创造性的工作,也能让普通人更容易创建自己的动漫作品。
AnimeGAN是来自武汉大学和湖北工业大学的一项研究,采用的是神经风格迁移 + 生成对抗网络(GAN)的组合。该项目可以实现将真实图像动漫化,由Jie Chen等人在论文AnimeGAN: A Novel Lightweight GAN for Photo Animation中提出。生成器为对称编解码结构,主要由标准卷积、深度可分离卷积、反向残差块(IRB)、上采样和下采样模块组成。判别器由标准卷积组成。
在初始版本发布时的论文《AnimeGAN: a novel lightweight GAN for photo animation》中还提出了三个全新的损失函数,用于提升风格化的动漫视觉效果。
这三个损失函数分别是:灰度风格损失,灰度对抗损失、颜色重建损失,下图也可以看到对比

与其他动漫风格迁移模型的效果对比
去年九月发布的 AnimeGANv2 优化了模型效果,解决了 AnimeGAN 初始版本中的一些问题。


以马斯克为例,AnimeGAN 初代的效果已经很令人惊艳,只是太过于白嫩病娇,仿佛韩国男团成员。相比之下,v2 更加自然,也更贴合真实气质。
AnimeGANv2 的优点
AnimeGANv2 的更新重点:
解决了生成的图像中的高频伪影问题。它易于训练,并能直接达到论文所述的效果。进一步减少生成器网络的参数数量。(现在生成器大小 8.17Mb)尽可能多地使用来自BD电影的新的高质量的风格数据。AnimeGANv2 风格多样化
在 v2 中新增了新海诚、宫崎骏、今敏三位漫画家漫画风格的训练数据集。
数据集包含6656张真实的风景图片,3种动漫风格:Hayao,Shinkai,Paprika,每一种动漫风格都是从对应的电影中通过对视频帧的随机裁剪生成的,除此之外数据集中也包含用于测试的各种尺寸大小的图像。数据集信息如下图所示:

AnimeGANv2 网络结构
AnimeGANv2中生成器的网络结构如图所示,K代表卷积核大小,S代表步长,C代表卷积核个数,IRB代表倒残差块,resize代表插值up-采样方法,SUM表示逐元素相加。AnimeGANv2 的生成器参数大小为 8.6MB,AnimeGAN 的生成器参数大小为 15.8MB。AnimeGANv2 使用与 AnimeGAN 相同的判别器,区别在于判别器使用Layer Normalization而不是Instance Normalization(IN)。
快速生成你的漫画形象
前面讲了一下如何在线生成,现在介绍一下,使用的代码,其实也是几个步骤,下面我给大家简要介绍一下吧
## AnimeGANv2源码解析import osimport dlibimport collectionsfrom typing import Union, Listimport numpy as npfrom PIL import Imageimport matplotlib.pyplot as pltimport warningswarnings.filterwarnings('ignore')导入人脸检测模型
这一部分是导入dlib库里面的face_detector也就是针对我们的人脸进行检测,所以需要导入我们的模型
def get_dlib_face_detector(predictor_path: str = "shape_predictor_68_face_landmarks.dat"): if not os.path.isfile(predictor_path): model_file = "shape_predictor_68_face_landmarks.dat.bz2" os.system(f"wget http://dlib.net/files/{model_file}") os.system(f"bzip2 -dk {model_file}") detector = dlib.get_frontal_face_detector() shape_predictor = dlib.shape_predictor(predictor_path) def detect_face_landmarks(img: Union[Image.Image, np.ndarray]): if isinstance(img, Image.Image): img = np.array(img) faces = [] dets = detector(img) for d in dets: shape = shape_predictor(img, d) faces.append(np.array([[v.x, v.y] for v in shape.parts()])) return faces return detect_face_landmarks可视化landmarks
接下来定义了可视化脸部的landmarks关键点的代码,这样可以使我们更清晰的认识。
def display_facial_landmarks( img: Image, landmarks: List[np.ndarray], fig_size=[15, 15]): plot_style = dict( marker='o', markersize=4, linestyle='-', lw=2 ) pred_type = collections.namedtuple('prediction_type', ['slice', 'color']) pred_types = { 'face': pred_type(slice(0, 17), (0.682, 0.780, 0.909, 0.5)), 'eyebrow1': pred_type(slice(17, 22), (1.0, 0.498, 0.055, 0.4)), 'eyebrow2': pred_type(slice(22, 27), (1.0, 0.498, 0.055, 0.4)), 'nose': pred_type(slice(27, 31), (0.345, 0.239, 0.443, 0.4)), 'nostril': pred_type(slice(31, 36), (0.345, 0.239, 0.443, 0.4)), 'eye1': pred_type(slice(36, 42), (0.596, 0.875, 0.541, 0.3)), 'eye2': pred_type(slice(42, 48), (0.596, 0.875, 0.541, 0.3)), 'lips': pred_type(slice(48, 60), (0.596, 0.875, 0.541, 0.3)), 'teeth': pred_type(slice(60, 68), (0.596, 0.875, 0.541, 0.4)) } fig = plt.figure(figsize=fig_size) ax = fig.add_subplot(1, 1, 1) ax.imshow(img) ax.axis('off') for face in landmarks: for pred_type in pred_types.values(): ax.plot( face[pred_type.slice, 0], face[pred_type.slice, 1], color=pred_type.color, **plot_style ) plt.show()预处理图片
这一部分就是提取我们的数据,也就是对图片进行预处理得到预处理后的的图片,后续输入网络中
# https://github.com/NVlabs/ffhq-dataset/blob/master/download_ffhq.pyimport PIL.Imageimport PIL.ImageFileimport numpy as npimport scipy.ndimagedef align_and_crop_face( img: Image.Image, landmarks: np.ndarray, expand: float = 1.0, output_size: int = 1024, transform_size: int = 4096, enable_padding: bool = True,): # 将五官数据转为数组 # pylint: disable=unused-variable lm = landmarks lm_chin = lm[0 : 17] # left-right lm_eyebrow_left = lm[17 : 22] # left-right lm_eyebrow_right = lm[22 : 27] # left-right lm_nose = lm[27 : 31] # top-down lm_nostrils = lm[31 : 36] # top-down lm_eye_left = lm[36 : 42] # left-clockwise lm_eye_right = lm[42 : 48] # left-clockwise lm_mouth_outer = lm[48 : 60] # left-clockwise lm_mouth_inner = lm[60 : 68] # left-clockwise # 计算辅助向量 eye_left = np.mean(lm_eye_left, axis=0) eye_right = np.mean(lm_eye_right, axis=0) eye_avg = (eye_left + eye_right) * 0.5 eye_to_eye = eye_right - eye_left mouth_left = lm_mouth_outer[0] mouth_right = lm_mouth_outer[6] mouth_avg = (mouth_left + mouth_right) * 0.5 eye_to_mouth = mouth_avg - eye_avg # 提取矩形框 x = eye_to_eye - np.flipud(eye_to_mouth) * [-1, 1] # flipud函数实现矩阵的上下翻转;数组乘法,每行对应位置相乘 x /= np.hypot(*x) x *= max(np.hypot(*eye_to_eye) * 2.0, np.hypot(*eye_to_mouth) * 1.8) x *= expand y = np.flipud(x) * [-1, 1] c = eye_avg + eye_to_mouth * 0.1 quad = np.stack([c - x - y, c - x + y, c + x + y, c + x - y]) qsize = np.hypot(*x) * 2 # 缩放 shrink = int(np.floor(qsize / output_size * 0.5)) if shrink > 1: rsize = (int(np.rint(float(img.size[0]) / shrink)), int(np.rint(float(img.size[1]) / shrink))) img = img.resize(rsize, PIL.Image.ANTIALIAS) quad /= shrink qsize /= shrink # 裁剪 border = max(int(np.rint(qsize * 0.1)), 3) crop = (int(np.floor(min(quad[:,0]))), int(np.floor(min(quad[:,1]))), int(np.ceil(max(quad[:,0]))), int(np.ceil(max(quad[:,1])))) crop = (max(crop[0] - border, 0), max(crop[1] - border, 0), min(crop[2] + border, img.size[0]), min(crop[3] + border, img.size[1])) if crop[2] - crop[0] < img.size[0] or crop[3] - crop[1] < img.size[1]: img = img.crop(crop) quad -= crop[0:2] # 填充数据 pad = (int(np.floor(min(quad[:,0]))), int(np.floor(min(quad[:,1]))), int(np.ceil(max(quad[:,0]))), int(np.ceil(max(quad[:,1])))) pad = (max(-pad[0] + border, 0), max(-pad[1] + border, 0), max(pad[2] - img.size[0] + border, 0), max(pad[3] - img.size[1] + border, 0)) if enable_padding and max(pad) > border - 4: pad = np.maximum(pad, int(np.rint(qsize * 0.3))) img = np.pad(np.float32(img), ((pad[1], pad[3]), (pad[0], pad[2]), (0, 0)), 'reflect') h, w, _ = img.shape y, x, _ = np.ogrid[:h, :w, :1] mask = np.maximum(1.0 - np.minimum(np.float32(x) / pad[0], np.float32(w-1-x) / pad[2]), 1.0 - np.minimum(np.float32(y) / pad[1], np.float32(h-1-y) / pad[3])) blur = qsize * 0.02 img += (scipy.ndimage.gaussian_filter(img, [blur, blur, 0]) - img) * np.clip(mask * 3.0 + 1.0, 0.0, 1.0) img += (np.median(img, axis=(0,1)) - img) * np.clip(mask, 0.0, 1.0) img = PIL.Image.fromarray(np.uint8(np.clip(np.rint(img), 0, 255)), 'RGB') quad += pad[:2] # 转化图片 img = img.transform((transform_size, transform_size), PIL.Image.QUAD, (quad + 0.5).flatten(), PIL.Image.BILINEAR) if output_size < transform_size: img = img.resize((output_size, output_size), PIL.Image.ANTIALIAS) return img漫画风格图片生成
接下来我们就需要导入我们的生成模型,我们可以导入我们的模型,可以选择v2版本,下载到本地后,进入导入我们的模型的权重,模型非常小,只有8M多,是很轻量的,这样我们就导入我们的检测模型和生成模型
其次,还定义了一个face2paint的函数,也就是将输入的人脸转化为漫画,利用生成模型来生成
#@title AnimeGAN model from https://github.com/bryandlee/animegan2-pytorch# !git clone https://github.com/bryandlee/animegan2-pytorchmodel_fname = "face_paint_512_v2_0.pt"# model_urls = {# "face_paint_512_v0.pt": "https://drive.google.com/uc?id=1WK5Mdt6mwlcsqCZMHkCUSDJxN1UyFi0-",# "face_paint_512_v2_0.pt": "https://drive.google.com/uc?id=18H3iK09_d54qEDoWIc82SyWB2xun4gjU",# }import syssys.path.append("animegan2-pytorch")import torchtorch.set_grad_enabled(False)from model import Generatordevice = "cpu"model = Generator().eval().to(device)model.load_state_dict(torch.load(model_fname))from PIL import Imagefrom torchvision.transforms.functional import to_tensor, to_pil_imagedef face2paint( img: Image.Image, size: int, side_by_side: bool = True,) -> Image.Image: w, h = img.size s = min(w, h) img = img.crop(((w - s) // 2, (h - s) // 2, (w + s) // 2, (h + s) // 2)) img = img.resize((size, size), Image.LANCZOS) input = to_tensor(img).unsqueeze(0) * 2 - 1 output = model(input.to(device)).cpu()[0] if side_by_side: output = torch.cat([input[0], output], dim=2) output = (output * 0.5 + 0.5).clip(0, 1) return to_pil_image(output)利用本地图片生成
我们可以读入我们的图片生成我们的结果,并且可以可视化我们的landmarks
def inference_from_file(filepath): img = Image.open(filepath).convert("RGB") face_detector = get_dlib_face_detector() landmarks = face_detector(img) display_facial_landmarks(img, landmarks, fig_size=[5, 5]) for landmark in landmarks: face = align_and_crop_face(img, landmark, expand=1.3) display(face2paint(face, 512))inference_from_file('tony-stack.png')

inference_from_file('girl.png')

利用在线图片生成
输入图片的url网址,我们也可以读入进行生成
import requestsdef inference_from_url(url): img = Image.open(requests.get(url, stream=True).raw).convert("RGB") face_detector = get_dlib_face_detector() landmarks = face_detector(img) display_facial_landmarks(img, landmarks, fig_size=[5, 5]) for landmark in landmarks: face = align_and_crop_face(img, landmark, expand=1.3) display(face2paint(face, 512))inference_from_url("https://upload.wikimedia.org/wikipedia/commons/8/85/Elon_Musk_Royal_Society_%28crop1%29.jpg")
