目录
1 问题背景2 问题探索3 问题解决
1 问题背景
环境:
Ubuntu20.04CUDA 11.4显卡:Nividia GeForce MX130现象:在一台旧机器上通过Makefile编译Darknet时报错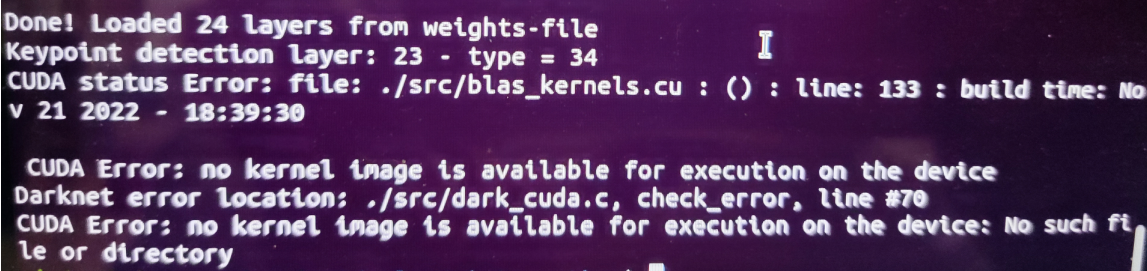
2 问题探索
查看Makefile中与显卡相关的配置
显卡型号及其架构指令
# Tesla V100# ARCH= -gencode arch=compute_70,code=[sm_70,compute_70]# GeForce RTX 2080 Ti, RTX 2080, RTX 2070, Quadro RTX 8000, Quadro RTX 6000, Quadro RTX 5000, Tesla T4, XNOR Tensor Cores# ARCH= -gencode arch=compute_75,code=[sm_75,compute_75]# Jetson XAVIER# ARCH= -gencode arch=compute_72,code=[sm_72,compute_72]# GTX 1080, GTX 1070, GTX 1060, GTX 1050, GTX 1030, Titan Xp, Tesla P40, Tesla P4ARCH= -gencode arch=compute_61,code=sm_61 -gencode arch=compute_61,code=compute_61# GP100/Tesla P100 - DGX-1# ARCH= -gencode arch=compute_60,code=sm_60# For Jetson TX1, Tegra X1, DRIVE CX, DRIVE PX - uncomment:# ARCH= -gencode arch=compute_53,code=[sm_53,compute_53]# For Jetson Tx2 or Drive-PX2 uncomment:# ARCH= -gencode arch=compute_62,code=[sm_62,compute_62]CUDA链接路径
ifeq ($(GPU), 1)COMMON+= -DGPU -I/usr/local/cuda-11.4/include/CFLAGS+= -DGPUifeq ($(OS),Darwin) #MACLDFLAGS+= -L/usr/local/cuda-11.4/lib -lcuda -lcudart -lcublas -lcurandelseLDFLAGS+= -L/usr/local/cuda-11.4/lib64 -lcuda -lcudart -lcublas -lcurandendifendififeq ($(CUDNN), 1)COMMON+= -DCUDNNifeq ($(OS),Darwin) #MACCFLAGS+= -DCUDNN -I/usr/local/cuda-11.4/includeLDFLAGS+= -L/usr/local/cuda-11.4/lib -lcudnnelseCFLAGS+= -DCUDNN -I/usr/local/cudnn/includeLDFLAGS+= -L/usr/local/cudnn/lib64 -lcudnnendifendif首先需要确定cudnn相关文件都已经补充到CUDA中,这部分请参考最新Windows/Ubuntu双系统CUDA与Pytorch保姆级图文安装教程(速查字典版),并验证当前使用的CUDA版本和这里的路径匹配
nvcc -Vnvcc: NVIDIA (R) Cuda compiler driverCopyright (c) 2005-2021 NVIDIA CorporationBuilt on Wed_Jun__2_19:15:15_PDT_2021Cuda compilation tools, release 11.4, V11.4.48Build cuda_11.4.r11.4/compiler.30033411_0接着检查显卡和架构是否匹配,先给出以下说明
gencode:生成码,允许生成更多的PTX文件,并且对不同的架构可以重复许多次ptx:并行线程执行(Parallel Thread eXecution, PTX)代码是编译后的GPU代码的一种中间形式,它可以再次编译为原生的GPU微码arch:架构标志位,前端编译目标,指明了CUDA文件编译产生的结果所依赖的NVIDIA GPU架构名称compute_XX:指PTX版本sm_XX:指cubin版本code:指定后端编译目标,可以是cubin或PTX或两者均可 上面xx中填的数字,例如compute_61中的61是这种显卡架构的算力,可以在官网查询https://developer.nvidia.com/cuda-gpus,如下所示,这里有绝大多数的算力表。
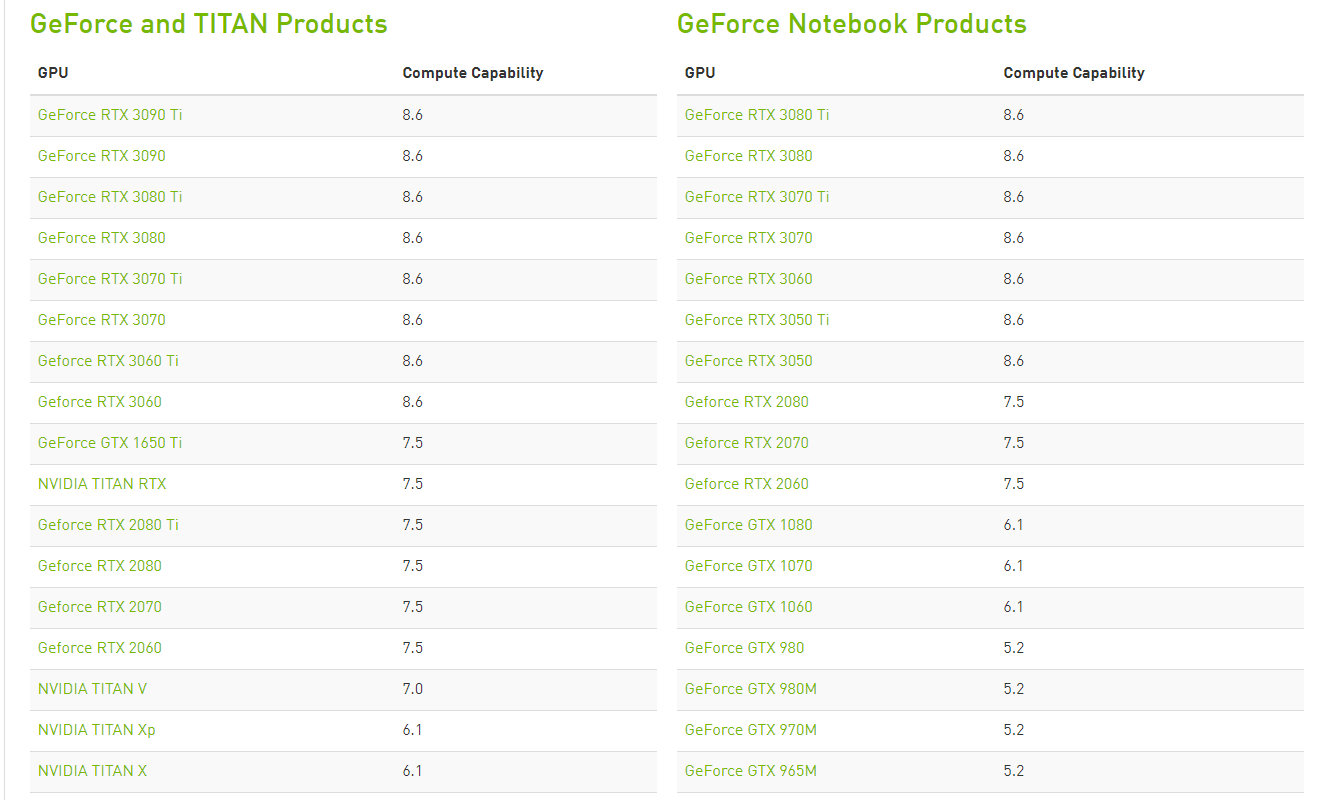
由于我这台机器MX130是旧显卡,不在官方的手册中,因此需要采用下面的脚本查询,这种方法也是对所有机器通用的
from numba import cudacuda.detect()I get:Found 1 CUDA devicesid 0 b'GeForce MX130' [SUPPORTED] compute capability: 5.0 pci device id: 0 pci bus id: 1Summary: 1/1 devices are supported可以看出,这里的算力和原Makefile中设置的算力不同,因此本质上导致这个问题的原因是CUDA编译时的架构指令和显卡算力不匹配。
3 问题解决
在Makefile中注释掉错误的架构设置,添加一行符合显卡的配置
# MX130ARCH= -gencode arch=compute_50,code=[sm_50,compute_50]随后即可编译通过。
? 更多精彩专栏:
《ROS从入门到精通》《机器人原理与技术》《机器学习强基计划》《计算机视觉教程》…?源码获取 · 技术交流 · 抱团学习 · 咨询分享 请联系?