最近乘着ChatGpt的东风,关于NLP的研究又一次被推上了风口浪尖。在现阶段的NLP的里程碑中,无论如何无法绕过Transformer。《Attention is all you need》成了每个NLP入门者的必读论文。惭愧的是,我虽然使用过很多基于Transformer的模型,例如BERT,但是对于他们,我也仅仅是会调用而已,对于他们的结构并不熟悉,更不要提修改他们了。
对于Transformer,则更不了解Transformer的细节,直到最近才下定决心复现一遍Transformer。完整的项目链接,我放在GitHub这里了。
工具
我使用的国产的框架,PaddlePaddle。为什么不使用Pytorch呢?因为我的英文并不十分灵光,对于Pytorch的一些API不能准确的理解,有时候理解错一个字就会带来十分巨大的偏差,所以Paddle的中文文档帮了我很大的忙。同时Paddle与Pytorch十分近似的API,也可以帮助我理解Pytorch。
我需要掌握的是Transformer的思想,至于工具的选择,在这个项目上,Paddle与Pytorch并没有什么不同。
模型结构
这里就要祭出这个十分经典的图了。
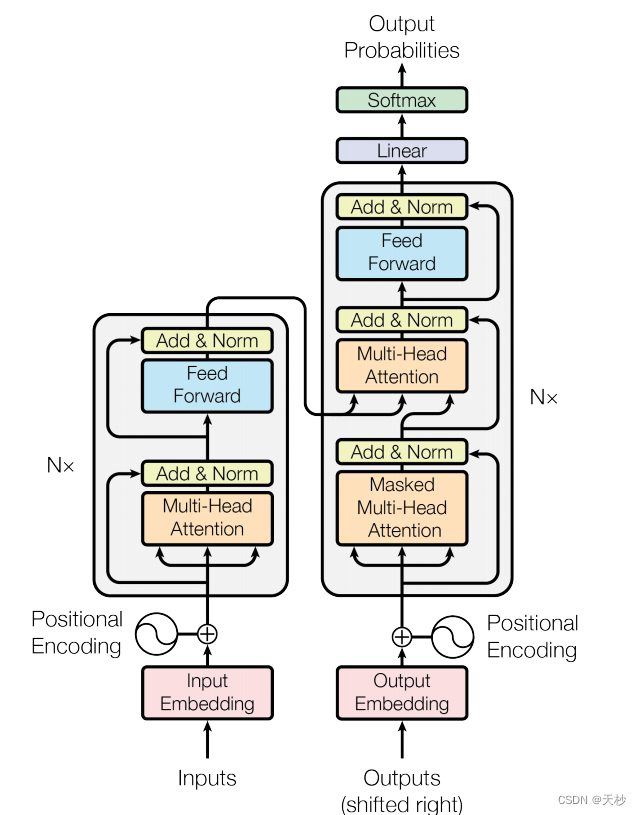
对于这幅图的理解,网上也有很多的介绍,我要做的是复现它。在复现的过程中,我也参考哈佛NLP的Annotated Transformer。那是一篇写的很风骚的代码,但是我认为它并不适合我。
我们就先从输入部分开始说吧:
Embedding
import mathimport paddleimport paddle.nn as nnfrom paddle import Tensorclass TransformerEmbedding(nn.Layer): def __init__(self, vocab_size, d_model=512): super(TransformerEmbedding, self).__init__() self.d_model = d_model self.embedding = nn.Embedding(vocab_size, d_model) self.positional_embedding = PositionalEncoding() def forward(self, x: Tensor): """ :param x: tensor对象,疑问,这是什么时候转成Tensor的呢?原版的Transformer是使用Tensor生成的数字,所以他不用考虑这个问题。 又因为Tensor是无法输入字符串的,所以只能输入字符串对应的数字。或许这就是BERT词表存在的意义。 :return: """ return self.embedding(x) + math.sqrt(self.d_model)class PositionalEncoding(nn.Layer): def __init__(self, d_model: int = 512, max_seq_length: int = 1000): """ PE(pos,2i) = sin(pos/100002i/dmodel) 通过公式可以知道,位置编码与原来的字信息毫无关系,独立门户的一套操作 对于在一句话中的一个字对应的512个维度中,位于偶数位置的使用sin函数,位于基数位置的使用cos函数 """ super(PositionalEncoding, self).__init__() self.pe = paddle.tensor.zeros([max_seq_length, d_model]) position = paddle.tensor.arange(0, max_seq_length).unsqueeze(1) two_i = paddle.tensor.arange(0, d_model, 2) temp = paddle.exp(-1 * two_i * math.log(10000.0) / d_model) aab = position * temp # position 对应的是词的长度 self.pe[:, 0::2] = paddle.sin(aab.cast('float32')) self.pe[:, 1::2] = paddle.cos(aab.cast('float32')) # pe[max_seq_length, d_model] self.pe = self.pe.unsqueeze(0) # pe[1,max_seq_length, d_model] def forward(self, x: Tensor): """ 词向量+位置编码 :param x: x应该是一个[bactch,seq_length,d_model]的数据 """ self.pe.stop_gradient = True return x + self.pe[:, x.shape[1]]在这里的位置编码中,我使用了与哈佛nlp相同的处理,关于这个的理解可以参考The Annotated Transformer的中文注释版(1) - 知乎 (zhihu.com)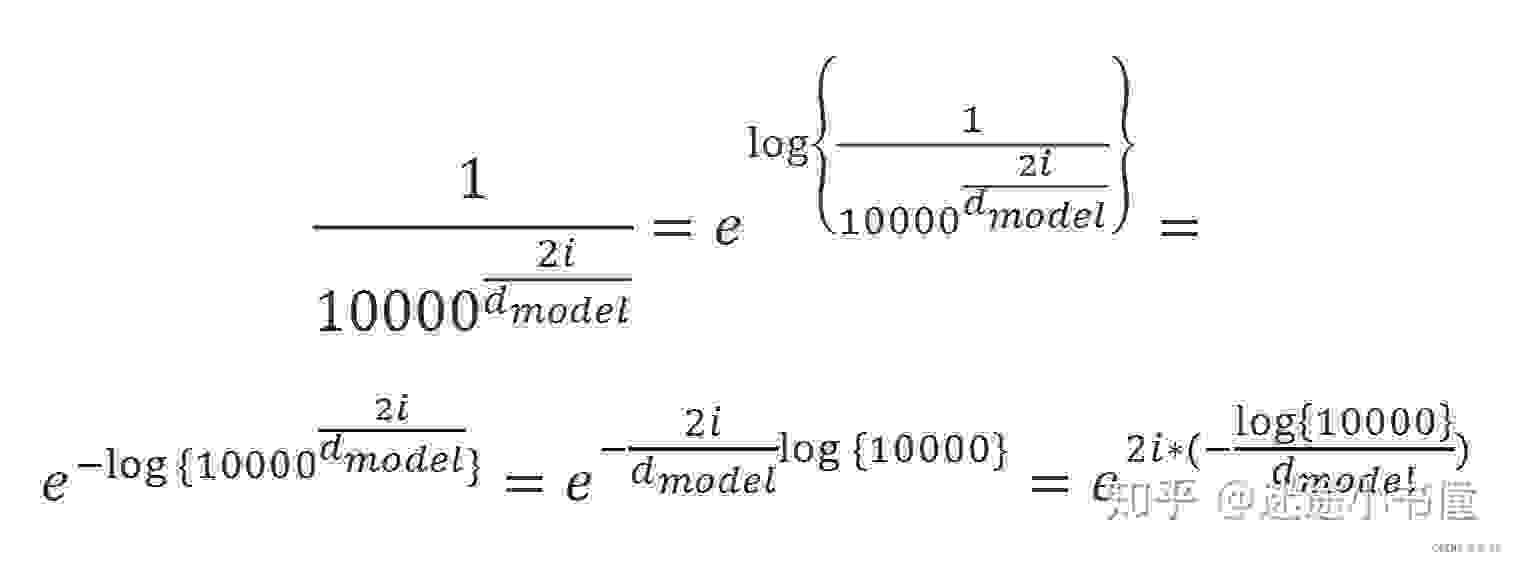
是数学的力量产生了如此优美的代码。
因为Transformer有很多复用的层,这些复用的层拼接出来了EncoderLayer和DecoderLayer;EncoderLayer堆叠出来了Encoder,DecoderLayer堆叠出来了Decoder。
这些复用的层,我将一一展示:
FeedForward
这是一个很简单的层,就是将输入的结果512维扩展到2048维,然后使用Relu函数后,又降低到原来的512维。
import paddleimport paddle.nn as nnclass FeedForward(nn.Layer): def __init__(self, d_model: int = 512, d_ff=2048): super().__init__() self.lin_to_big = nn.Linear(d_model, d_ff) self.lin_to_small = nn.Linear(d_ff, d_model) def forward(self, x): return self.lin_to_small(paddle.nn.functional.relu(self.lin_to_big(x)))LayerNorm
这里的代码我是完全copy哈佛nlp的,LayerNorm的思想不是Transformer论文提出的,各大框架也都有自己的实现。我觉得LayerNorm的与Relu这些函数一样,属于基础件,直接调用框架的代码也可以。
import paddle.nn as nnimport paddleclass LayerNorm(nn.Layer): def __init__(self, d_model: int = 512, eps=1e-6): super(LayerNorm, self).__init__() self.a_2 = self.create_parameter(shape=[d_model], dtype='float32', default_initializer=nn.initializer.Constant(1.0)) self.b_2 = self.create_parameter(shape=[d_model], dtype='float32', default_initializer=nn.initializer.Constant(0.0)) self.eps = eps def forward(self, x): # 就是在统计每个样本所有维度的值,求均值和方差,所以就是在hidden dim上操作 # 相当于变成[bsz*max_len, hidden_dim], 然后再转回来, 保持是三维 mean = x.mean(-1, keepdim=True) # mean: [bsz, max_len, 1] std = x.std(-1, keepdim=True) # std: [bsz, max_len, 1] # 注意这里也在最后一个维度发生了广播 return self.a_2 * (x - mean) / (std + self.eps) + self.b_2MultiHeadAttention
这是最重要的部分,也是Transformer的精华,讲Transformer其实就是在讲多头注意力机制,我曾经在毕业论文上见过利用注意力机制水论文,但是当时我被唬住了,直到亲手实现过一遍后,我更加确定他们就是在水论文。
相关的解释,我全部加在代码中了。
import copyimport mathfrom typing import Optionalimport paddleimport paddle.nn as nnfrom paddle import Tensorclass MultiHeadAttention(nn.Layer): def __init__(self, d_model: int = 512, head: int = 8): super().__init__() self.head = head """ MultiHeadAttention在论文中一共出现在了3个地方。在EncoderLayer中一处,在DecoderLay中两处。 论文中设置了头的数量为8。其实是分别使用网络为q,k,v进行了8次变换。 这个网络映射过程就是论文中提到的权重变换。 哈佛论文提出的方法很巧妙,与论文有些出入,所以我并不能理解。 于是完全按照论文的思路来实现。 为q,k,v分别进行8次变换,那就是需要有24个网络。 """ self.linear_list = [copy.deepcopy(nn.Linear(d_model, d_model)) for _ in range(head * 3)] # 这是经过多头注意力的拼接后,将他们恢复到512维。 self.linear_output = nn.Linear(d_model * head, d_model) def forward(self, query, encoder_output: Optional[Tensor] = None, mask=False, src_mask: Optional[Tensor] = None, tgt_mask: Optional[Tensor] = None): """ :param query: query :param encoder_output: encoder的输出 :param mask: 是否是论文中的MASK-multiheadAttention :param src_mask: 来自encoder编码层的掩码,或者是encoder输出的掩码。具体如何判读就是tgt_mask是不是None :param tgt_mask: 来自decoder的掩码 :return: """ attention_list = [] # 在论文中,self.linear_list的数量是24。 for index, linear in enumerate(self.linear_list): if index % 3 == 0: # query永远来自于自家 query = linear(query) elif index % 3 == 1: # 对于key来说,编码器没什么好说的;解码器中间的多头注意力,key和value都来自编码器的输出 # 在编码器中,都是使用query进行权重变换的。 z = query if encoder_output is None else encoder_output key = linear(z) else: z = query if encoder_output is None else encoder_output value = linear(z) attention_list.append(attention(query, key, value, self.head, src_mask, tgt_mask, mask=mask)) query = paddle.concat(attention_list, axis=-1) return self.linear_output(query)def attention(query: Tensor, key: Tensor, value: Tensor, head: int, src_mask=None, tgt_mask=None, mask=False) -> Tensor: """ 计算 Attention 的函数。在函数中,计算出来的scale是矩阵乘法的结果,我们为了“不让解码器看到未来的结果”计算出scale后 将相关的部位置设置为一个极小的数字,这样经过softmax后就几乎为0了,达成了“不让解码器看到未来的结果”的效果。这个是用一个 下三角矩阵做到的。 除此之外,其他的矩阵都是遮掩padding的矩阵,不需要“不让解码器看到未来的结果” :param src_mask: :param tgt_mask: :return: :param query: shape [batch,seq_length,d_model] :param key:同上 :param value:同上 :param mask:是否开启掩码矩阵。我们要防止模型看到未来的信息,那么未来的信息来自哪里,当然是解码器的输入啦。所以掩码矩阵的shape为[seq_length,seq_length] :param head:头数 """ assert query.shape[-1] % head == 0 dk = query.shape[-1] // head # paddle的转置操作真奇葩,好像tf也是这样子 scale = paddle.matmul(query, paddle.transpose(key, [0, 2, 1])) scale = scale / math.sqrt(dk) if src_mask is not None and tgt_mask is not None: # 这说明是在 DecoderLayer 的第二个多头注意力中。 q_sen_length = scale.shape[-2] k_sen_length = scale.shape[-1] batch_size = scale.shape[0] result = [] # 这个需要根据src_mask和tgt_mask生成掩码矩阵 # src_mask是一个[batch,input_seq_length,input_seq_length]的矩阵,tgt_mask同理,不够这两个矩阵的长度可能会不一样。 #比如我爱中国,4个字翻译成英语 i love china 就是3个字。 for index in range(batch_size): s = paddle.count_nonzero(src_mask[index]) lie = int(math.sqrt(s.item())) p = paddle.count_nonzero(tgt_mask[index]) row = int(math.sqrt(p.item())) temp = paddle.zeros([q_sen_length, k_sen_length]) temp[:row, :lie] = 1 result.append(temp) result_mask = paddle.to_tensor(result) scale = masked_fill(scale, result_mask, -1e9) elif src_mask is not None: # Encoderlayer中的mask,也就是为了遮掩住padding的部分 scale = masked_fill(scale, src_mask, -1e9) elif tgt_mask is not None: # decoderlayer中的mask,也就是为了遮掩住padding的部分 scale = masked_fill(scale, tgt_mask, -1e9) if mask: # 这里有一个下三角,只有decoderlayerr才会进入,但是我们这里的scale是一个[batch,tgt_length,tgt_length] seq_length = query.shape[-2] down_metric = (paddle.triu(paddle.ones([seq_length, seq_length]), diagonal=1) == 0) scale = masked_fill(scale, down_metric, -1e9) if tgt_mask is not None: assert tgt_mask.shape == scale.shape # tgt_mask也是一个[batch,tgt_length,tgt_length]的矩阵 scale = masked_fill(scale, tgt_mask, -1e9) return paddle.matmul(nn.functional.softmax(scale), value)def masked_fill(x, mask, value): """ 从paddle官方抄的代码,哈哈 :param x: :param mask: :param value: :return: """ mask = paddle.cast(mask, 'bool') y = paddle.full(x.shape, value, x.dtype) return paddle.where(mask, x, y)接下来就开始拼接了
EncoderLayer
import paddle.nn as nnfrom FeedForward import FeedForwardfrom LayerNorm import LayerNormfrom MultiHeadAttention import MultiHeadAttentionclass EncoderLayer(nn.Layer): def __init__(self): """ 编码器的组成部分,一个多头注意力机制+残差+Norm,一个前馈神经网路+残差+Norm, """ super(EncoderLayer, self).__init__() self.multi_head = MultiHeadAttention() self.feed_forward = FeedForward() self.norm = LayerNorm() def forward(self, x, src_mask=None): """ :param x: shape [batch,max_length,d_model] :return: """ y = self.multi_head(x, src_mask=src_mask) y = x + self.norm(y) z = self.feed_forward(y) z = y + self.norm(z) return zDecoderLayer
import paddle.nn as nnfrom paddle import Tensorfrom FeedForward import FeedForwardfrom LayerNorm import LayerNormfrom MultiHeadAttention import MultiHeadAttentionclass DecoderLayer(nn.Layer): def __init__(self): """ 解码器部分, 一个带掩码的多头注意力+norm+残差 一个不带掩码的多头注意力+norm+残差 一个前馈神经网络+norm+残差 """ super(DecoderLayer, self).__init__() self.mask_multi_head_attention = MultiHeadAttention() self.multi_head_attention = MultiHeadAttention() self.feed_forward = FeedForward() self.norm = LayerNorm() def forward(self, x, encoder_output: Tensor, src_mask: None, tgt_mask: None): """ :param x: decoder 的输入,他的初始输入应该只有一个标记,但是shape依然是[batch,seq_length,d_model] :param encoder_output:编码器的输出 """ y = self.mask_multi_head_attention(x, mask=True, tgt_mask=tgt_mask) query = x + self.norm(y) z = self.multi_head_attention(query, encoder_output, src_mask=src_mask, tgt_mask=tgt_mask) z = query + self.norm(z) p = self.feed_forward(z) output = self.norm(p) + z return outputEndoder
import copyimport paddle.nn as nnfrom EncoderLayer import EncoderLayerclass Encoder(nn.Layer): def __init__(self, num_layers: int): super(Encoder, self).__init__() self.layers = nn.LayerList([copy.deepcopy(EncoderLayer()) for _ in range(num_layers)]) def forward(self, x,src_mask:None): for encoder_layer in self.layers: x = encoder_layer(x,src_mask) return x.norm(p) + z return outputDecoder
import copyimport paddle.nn as nnfrom DecoderLayer import DecoderLayerclass Decoder(nn.Layer): def __init__(self, num_layers: int = 6): super(Decoder, self).__init__() self.decoder_layers = nn.LayerList([copy.deepcopy(DecoderLayer()) for _ in range(num_layers)]) def forward(self, x, encoder_output, src_mask, tgt_mask): """ :param x: shape [batch,seq_legth,d_model] """ for layer in self.decoder_layers: x = layer(x, encoder_output, src_mask, tgt_mask) return x最后集成为Transformer,它就是一个编码器,解码器工程。
EncoderDecoder
from typing import Optionalimport paddleimport paddle.nn as nnfrom paddle import Tensorfrom Decoder import Decoderfrom Embedding import TransformerEmbedding, PositionalEncodingfrom Encoder import Encoderclass EncoderDecoder(nn.Layer): def __init__(self, vocab_size: int, d_model: int = 512): super(EncoderDecoder, self).__init__() self.layers_nums = 3 self.embedding = nn.Sequential( TransformerEmbedding(vocab_size), PositionalEncoding() ) self.encoder = Encoder(self.layers_nums) self.decoder = Decoder(self.layers_nums) self.linear = nn.Linear(d_model, vocab_size) self.soft_max = nn.Softmax() self.loss_fct = nn.CrossEntropyLoss() def forward(self, x, label, true_label: Optional[Tensor] = None, src_mask=None, tgt_mask=None): input_embedding = self.embedding(x) label_embedding = self.embedding(label) encoder_output = self.encoder(input_embedding, src_mask) decoder_output = self.decoder(label_embedding, encoder_output, src_mask, tgt_mask) logits = self.linear(decoder_output) res_dict = {} if true_label is not None: loss = self.loss_fct(logits.reshape((-1, logits.shape[-1])), true_label.reshape((-1,))) res_dict['loss'] = loss result = self.soft_max(logits) max_index = paddle.argmax(result, axis=-1) res_dict['logits'] = result res_dict['index'] = max_index return res_dict然后是一个工具类,用于生成词表以及将输入转化为向量。
from typing import Listimport paddlefrom paddle import Tensordef convert(): chinese = ['你好吗', "我爱你", "中国是一个伟大的国家"] english = ['how are you', 'i love you', 'china is a great country'] cc = [] for item in chinese: for word in item: # 中文一个字一个字的加入list cc.append(word) for item in english: cc.extend(item.split()) word_list = list(set(cc)) word_list.sort(key=cc.index) word_list.insert(0, 0) word_list.append(-1) word2id = {item: index for index, item in enumerate(word_list)} id2word = {index: item for index, item in enumerate(word_list)} return word2id, id2worddef convert_list_to_tensor(str_list: List[str], endlish=True) -> (Tensor, Tensor): """ :param str_list: :return: 原始的id矩阵;处理好了的掩码矩阵 """ batch = len(str_list) max_length = 0 if endlish: for item in str_list: ll = item.split(' ') max_length = len(ll) if len(ll) > max_length else max_length else: max_length = len(max(str_list, key=len)) max_length += 2 word2id, id2word, = convert() result = [] padding_metric = [] pad = -1 mask_seq_seq = [] for sentence in str_list: ids = [0, ] # 开始的标志 padding_mask = [] if endlish: word_list = sentence.split(' ') for word in word_list: ids.append(word2id[word]) else: for word in sentence: ids.append(word2id[word]) padding_mask.extend([1] * len(ids)) ids.append(0) # 结束的标志 pad_nums = max_length - len(ids) ids.extend([word2id[pad]] * pad_nums) padding_mask.extend([0] * (len(ids) - len(padding_mask) - 1)) result.append(ids) count = padding_mask.count(1) metric_mask = paddle.zeros([len(padding_mask), len(padding_mask)]) metric_mask[:count, :count] = 1 mask_seq_seq.append(metric_mask) padding_metric.append(padding_mask) return paddle.to_tensor(result).reshape([batch, -1]), \ paddle.to_tensor(padding_metric).reshape([batch, -1]), \ paddle.to_tensor(mask_seq_seq).reshape([batch, len(padding_mask), -1]),接下来这里简单说一下,用到了 Teaching Force 思想。
我们的数据是这样的格式 < begin>内容< end> ,在这个程序中,begin和end都是0。这样的数据,喂给输入端时候去掉最开始的< begin>,在训练时去掉末尾的< /end>喂给 Decoder 。这样做的目的是训练 Decoder 根据自己已经有的信息预测下一个字符的能力。这样做的目的,是因为在测试阶段我们只会给 Decoder 一个< begin> 字符,让 Decoder 根据这个 < begin> 字符和 Encoder 的输出来输出内容。
import paddleimport paddle.nn as nn# 不知道这个有没有用。。nn.initializer.set_global_initializer(nn.initializer.Uniform(), nn.initializer.Constant())from EncoderDecoder import EncoderDecoderfrom utils import convert_list_to_tensordef train(): english = ['i love you', 'china is a great country', 'i love china', 'china is a country'] chinese = ['我爱你', '中国是一个伟大的国家', '我爱中国', '中国是一个国家'] input_ids, _, input_metric = convert_list_to_tensor(english) encod_ids, _, encod_metric = convert_list_to_tensor(chinese, endlish=False) input_ids = input_ids[:, 1:] true_labels = encod_ids[:, 1:] encod_ids = encod_ids[:, :-1] transformer = EncoderDecoder(vocab_size=26, d_model=512) adamw = paddle.optimizer.AdamW(learning_rate=0.001, parameters=transformer.parameters()) for epoch in range(700): output_dict = transformer(input_ids, encod_ids, true_labels, src_mask=input_metric, tgt_mask=encod_metric) loss = output_dict['loss'] print(f"第{epoch + 1}次训练,loss是{loss.item()},logits是{paddle.tolist(output_dict['index'])}") adamw.clear_gradients() loss.backward() adamw.step() evaluate(transformer)@paddle.no_grad()def evaluate(model: EncoderDecoder, MAX_LENGTH=6): model.eval() str_list = ['china'] enput_ids, _, enput_mask = convert_list_to_tensor(str_list) enput_ids = enput_ids[:, 1:] de_ids = [[0]] de_ids = paddle.to_tensor(de_ids) for i in range(MAX_LENGTH): tgt_mask = paddle.ones([i + 1, i + 1]).unsqueeze(0) output_dict = model(enput_ids, de_ids, src_mask=enput_mask, tgt_mask=tgt_mask) result = output_dict['index'] # temp = result[:, -1].item() # if temp == 0: # print("结束了") # return g = result[:, -1].unsqueeze(0) de_ids = paddle.concat((de_ids, g), axis=1) print(paddle.tolist(de_ids))if __name__ == '__main__': train() # vocab_size = 11 # original = [0, 1, 2, 3, 4, 5, 6, 8, 0] # encode_input = original[1:] # decode_input = original[0:-1] # encode_input = paddle.to_tensor(encode_input).unsqueeze(0) # decode_input = paddle.to_tensor(decode_input).unsqueeze(0) # # transformer = EncoderDecoder(vocab_size=vocab_size, d_model=512) # adamw = paddle.optimizer.AdamW(learning_rate=0.001, parameters=transformer.parameters()) # for epoch in range(400): # output_dict = transformer(encode_input, label=decode_input, true_label=encode_input) # loss = output_dict['loss'] # print(f"第{epoch + 1}次训练,logits是{paddle.tolist(output_dict['index'])},loss是{loss.item()}") # adamw.clear_gradients() # loss.backward() # adamw.step() # evaluate(transformer)总结
在这个过程中,我深刻的理解了这里的Decoder是串行的,刚开始不知道如何实现,看了TensorFlow的官方实现后才领悟到。
实际上的效果并不是很好,我也不知道是哪里的问题。再使用哈佛nlp的Transformer中,他们的重复数字的例子效果也不好,有可能是数据量太少的原因?
我觉得在亲自动手实现架构的过程,学到的东西要比纸上谈兵多的多。在复现的过程中,也遇到了一些细节问题,有些是框架的,有些是模型的,文章可能也有遗漏错误。欢迎大家提出,我们一起讨论学习。