目录
0 引言1 数学知识1.1 梯度(gradient) 概念1.2 梯度函数1.3 Hessian 矩阵 2 最速下降法2.1 概念[^6]2.2 算法步骤[^6]2.3 原理详解[^7]2.4 缺点[^6] 3 示例说明4 代码实现4.1 ∇ f ( x ) \nabla f(x) ∇f(x) 的函数模块代码实现4.2 Hessian 矩阵 H ( x ) H(x) H(x) 的模块代码实现4.3 最速下降法函数模块代码实现*4.4 最速下降法画图函数模块代码实现4.5 主函数4.6 上面图1的代码4.7 完整代码文件 5 总结6 引用参考
0 引言
最近太忙了,更新的有点慢了。本篇就更新一个通常用的较多的算法——最速下降法,其实数值分析中会讲到这个方法。此篇先回顾梯度概念,再讲述最速下降法,最后通过例子理解算法以及实现代码编写。
希望大家看完这篇文章之后能有所收获!!!!
下一篇文章:Matlab 自编雅可比矩阵 (jacobi) 函数与官方的Jacobian matrix(雅可比矩阵)函数对比及创新
这次需要提前必备一些 matlab 函数的使用
matlab 版本:2020a ,2022a (2022.6.5本人Matlab版本更新到了2022a)
matlab2022b版本中suptitle不能使用直接把suptitle改为sgtitle
f=@(变量名) 函数表达式matlabFunction 的使用2范数函数 norm绘制三维:mesh,等高线:contour,网格生成:meshgrid获取每一帧图像:getframe,更新:drawnow,暂停延迟:pause (这些可以作为了解) 1 数学知识
了解这个最速下降法,需要一些数学知识的,所以先来回顾一些数学知识。
必看:如果数学知识没有掌握好的同学,我建议还是老老实实的看完这第一节内所有内容,否则后面有些关于公式推导会看的云里雾里飘。
1.1 梯度(gradient) 概念
这个概念参考中3 有详细的解释说明,这里讲述一下其中 梯度 的概念
梯度:是一个向量,表示某一函数在该点处的方向导数沿着该方向取得最大值。(1)有大小:变化率最大(为该梯度的模);(2)有方向:函数在该点处沿着该方向(此梯度的方向)变化最快4。
定义: 设 z = f ( x , y ) z = f(x,y) z=f(x,y) 在点 P 0 ( x 0 , y 0 ) P_0(x_0,y_0) P0(x0,y0) 处存在偏导数 f x ′ ( x 0 , y 0 ) f'_x(x_0,y_0) fx′(x0,y0) 和 f y ′ ( x 0 , y 0 ) f'_y(x_0,y_0) fy′(x0,y0), 则称向量 { f x ′ ( x 0 , y 0 ) , f y ′ ( x 0 , y 0 ) } \{f'_x(x_0,y_0) ,f'_y(x_0,y_0)\} {fx′(x0,y0),fy′(x0,y0)} 为 f ( x , y ) f(x,y) f(x,y) 在 P 0 ( x 0 , y 0 ) P_0(x_0,y_0) P0(x0,y0) 的梯度,记作 ∇ f ∣ P 0 , ∇ z ∣ P 0 , gradf ∣ P 0 或 gradz ∣ P 0 \left.\nabla f\right|_{P_{0}},\left.\nabla z\right|_{P_{0}},\left.\operatorname{gradf}\right|_{P_{0}} \text { 或 }\left.\operatorname{gradz}\right|_{P_{0}} ∇f∣P0,∇z∣P0,gradf∣P0 或 gradz∣P0
∴ ∇ f ∣ P 0 = gradf ∣ P 0 = { f x ′ ( x 0 , y 0 ) , f y ′ ( x 0 , y 0 ) } \therefore \left.\nabla f\right|_{P_{0}}=\left.\operatorname{gradf}\right|_{P_{0}}=\{f'_x(x_0,y_0) ,f'_y(x_0,y_0)\} ∴∇f∣P0=gradf∣P0={fx′(x0,y0),fy′(x0,y0)}
其中 ∇ \nabla ∇ (Nabla)算子: ∇ = ∂ ∂ x i + ∂ ∂ y j \nabla = \frac{\partial}{\partial x}i + \frac{\partial}{\partial y}j ∇=∂x∂i+∂y∂j
1.2 梯度函数
定义: 若 f ( x , y ) f(x,y) f(x,y) 在 D D D 内处处存在偏导数,则称 ∇ f = { f x ′ ( x , y ) , f y ′ ( x , y ) } \nabla f= \{f'_x(x,y) ,f'_y(x,y)\} ∇f={fx′(x,y),fy′(x,y)} 为 f ( x , y ) f(x,y) f(x,y) 在D内的梯度函数
(1)梯度的大小: ∣ ∇ f ∣ = [ f x ′ ( x , y ) ] 2 + [ f y ′ ( x , y ) ] 2 |\nabla f|=\sqrt{\left[f_{x}^{\prime}(x, y)\right]^{2}+\left[f_{y}^{\prime}(x, y)\right]^{2}} ∣∇f∣=[fx′(x,y)]2+[fy′(x,y)]2
(2)梯度的方向:
设 v = { v 1 , v 2 } ( ∣ v ∣ = 1 ) v=\{v_1,v_2\} (|v|=1) v={v1,v2}(∣v∣=1) 是任一给定方向,则对 ∇ f \nabla f ∇f 与 v v v 的夹角 θ \theta θ 有: ∂ f ∂ v ∣ P 0 = f x ′ ( x 0 , y 0 ) v 1 + f y ′ ( x 0 , y 0 ) v 2 = { f x ′ ( x 0 , y 0 ) , f y ′ ( x 0 , y 0 ) } ∙ { v 1 , v 2 } = ∇ f ∣ P 0 ∙ v = ∣ ∇ f ∣ P 0 ∣ ⋅ ∣ v ∣ cos θ \begin{aligned} \left.\frac{\partial f}{\partial v}\right|_{P_{0}} &=f_{x}^{\prime}\left(x_{0}, y_{0}\right) v_{1}+f_{y}^{\prime}\left(x_{0}, y_{0}\right) v_{2} \\ &=\left\{f_{x}^{\prime}\left(x_{0}, y_{0}\right), f_{y}^{\prime}\left(x_{0}, y_{0}\right)\right\} \bullet\left\{v_{1}, v_{2}\right\} \\ &=\left.\nabla f\right|_{P_{0}} \bullet v=|\nabla f|_{P_{0}}|\cdot |v| \cos \theta \end{aligned} ∂v∂f P0=fx′(x0,y0)v1+fy′(x0,y0)v2={fx′(x0,y0),fy′(x0,y0)}∙{v1,v2}=∇f∣P0∙v=∣∇f∣P0∣⋅∣v∣cosθ
由于 ∣ v ∣ = 1 |v|=1 ∣v∣=1 那么上式为: ∂ f ∂ v ∣ P 0 = ∣ ∇ f ∣ P 0 ∣ cos θ \frac{\partial f}{\partial v}|_{P_{0}} =|\nabla f|_{P_{0}}|\cos \theta ∂v∂f∣P0=∣∇f∣P0∣cosθ
补充知识(高中内容):已知两个向量 v 1 → = ( a , b ) , v 2 → = ( c , d ) \overrightarrow{v_1} =(a,b),\overrightarrow{v_2} =(c,d) v1 =(a,b),v2 =(c,d),那么两个向量内积 : v 1 v 2 = a c + b d = ∣ v 1 → ∣ ∣ v 2 → ∣ cos θ v_1v_2=ac+bd=|\overrightarrow{v_1}||\overrightarrow{v_2}|\cos\theta v1v2=ac+bd=∣v1 ∣∣v2 ∣cosθ,其中: cos θ = a c + b d ∣ v 1 → ∣ ∣ v 2 → ∣ \cos\theta=\frac{ac+bd}{|\overrightarrow{v_1}||\overrightarrow{v_2}|} cosθ=∣v1 ∣∣v2 ∣ac+bd
∴ \therefore ∴ 当该点 P 0 P_0 P0 的方向 v v v 与梯度方向 ∇ f ∣ P 0 \nabla f|_{P_{0}} ∇f∣P0 夹角为 0 0 0 时取得最大,这就证明了沿着梯度方向函数值变化的最快,这公式也证明了5 ,梯度的方向是函数在指定点上升最快的方向,那么梯度的反方向自然是下降最快的方向了6:
如果点 P 0 P_0 P0 继续沿着梯度方向走,函数值增大当 θ = 180 ° \theta = 180° θ=180° 即沿着梯度反方向走,函数值减小垂直于梯度方向,函数值不变,即为:等高线以上三个总结之后会用到,接下来开启最速下降法的算法讲解。
1.3 Hessian 矩阵
梯度的作用就是给了表示它变化的向量场。所以我觉得梯度跟导数更像一家人。继续来看二次近似: Q ( x ) = f ( x 0 ) + f ′ ( x 0 ) ( x − x 0 ) + 1 2 f ′ ′ ( x 0 ) ( x − x 0 ) 2 Q(x)=f\left(x_{0}\right)+f^{\prime}\left(x_{0}\right)\left(x-x_{0}\right)+\frac{1}{2} f^{\prime \prime}\left(x_{0}\right)\left(x-x_{0}\right)^{2} Q(x)=f(x0)+f′(x0)(x−x0)+21f′′(x0)(x−x0)2如果我们想把它推广到多元函数,那么我们会想应该也是类似的状况,除了前面的这一部分 L ( x , y ) = a + b ( x 0 , y 0 ) + c ( x 0 , y 0 ) L(x,y)=a+b(x_0,y_0)+c(x_0,y_0) L(x,y)=a+b(x0,y0)+c(x0,y0), 我们会想要再加上二次的部分: d ( x − x 0 ) 2 + e ( x − x 0 ) ( y − y 0 ) + f ( y − y 0 ) 2 d(x-x_0)^2+e(x-x_0)(y-y_0)+f(y-y_0)^2 d(x−x0)2+e(x−x0)(y−y0)+f(y−y0)2
Q ( x , y ) = f ( x 0 , y 0 ) + f x ( x 0 , y 0 ) ( x − x 0 ) + f y ( x 0 , y 0 ) ( y − y 0 ) + 1 2 f x x ( x 0 , y 0 ) ( x − x 0 ) 2 + f x y ( x − x 0 ) ( y − y 0 ) + 1 2 f y y ( x 0 , y 0 ) ( y − y 0 ) 2 \begin{array}{c} Q(x, y)=f\left(x_{0}, y_{0}\right)+f_{x}\left(x_{0}, y_{0}\right)\left(x-x_{0}\right)+f_{y}\left(x_{0}, y_{0}\right)\left(y-y_{0}\right) \\ +\frac{1}{2} f_{x x}\left(x_{0}, y_{0}\right)\left(x-x_{0}\right)^{2}+f_{x y}\left(x-x_{0}\right)\left(y-y_{0}\right)+\frac{1}{2} f_{y y}\left(x_{0}, y_{0}\right)\left(y-y_{0}\right)^{2} \end{array} Q(x,y)=f(x0,y0)+fx(x0,y0)(x−x0)+fy(x0,y0)(y−y0)+21fxx(x0,y0)(x−x0)2+fxy(x−x0)(y−y0)+21fyy(x0,y0)(y−y0)2
通过类比或者计算,我们都可以得到以上的二次近似的结果。然后我们可以继续引出二次近似的向量形式: Q ( x ) = f ( x 0 ) + ∇ f ( x 0 ) ⋅ ( x − x 0 ) + 1 2 ( x − x 0 ) T H ( x 0 ) ( x − x 0 ) Q(\mathbf{x})=f\left(\mathbf{x}_{0}\right)+\nabla f\left(\mathbf{x}_{\mathbf{0}}\right) \cdot\left(\mathbf{x}-\mathbf{x}_{\mathbf{0}}\right)+\frac{1}{2}\left(\mathbf{x}-\mathbf{x}_{0}\right)^{T} H\left(\mathbf{x}_{0}\right)\left(\mathbf{x}-\mathbf{x}_{0}\right) Q(x)=f(x0)+∇f(x0)⋅(x−x0)+21(x−x0)TH(x0)(x−x0)
其中 H H H 是 Hessian 矩阵: ∇ ( ∇ f ) = H = [ ∂ f ∂ x 2 ∂ f ∂ x ∂ y ∂ f ∂ y ∂ x ∂ f ∂ y 2 ] \nabla (\nabla f)=H=\left[\begin{array}{cc} \frac{\partial f}{\partial x^{2}} & \frac{\partial f}{\partial x \partial y} \\ \frac{\partial f}{\partial y \partial x} & \frac{\partial f}{\partial y^{2}} \end{array}\right] ∇(∇f)=H=[∂x2∂f∂y∂x∂f∂x∂y∂f∂y2∂f]
当然我们也可以推广到更高的维度: H = [ ∂ 2 f ∂ x 1 2 ∂ 2 f ∂ x 1 ∂ x 2 ⋯ ∂ 2 f ∂ x 1 ∂ x n ∂ 2 f ∂ x 2 ∂ x 1 ∂ 2 f ∂ x 2 2 ⋯ ∂ 2 f ∂ x 2 ∂ x n ⋮ ⋮ ⋱ ⋮ ∂ 2 f ∂ x n ∂ x 1 ∂ 2 f ∂ x n ∂ x 2 ⋯ ∂ 2 f ∂ x n 2 ] \mathbf{H}=\left[\begin{array}{cccc} \frac{\partial^{2} f}{\partial x_{1}^{2}} & \frac{\partial^{2} f}{\partial x_{1} \partial x_{2}} & \cdots & \frac{\partial^{2} f}{\partial x_{1} \partial x_{n}} \\ \frac{\partial^{2} f}{\partial x_{2} \partial x_{1}} & \frac{\partial^{2} f}{\partial x_{2}^{2}} & \cdots & \frac{\partial^{2} f}{\partial x_{2} \partial x_{n}} \\ \vdots & \vdots & \ddots & \vdots \\ \frac{\partial^{2} f}{\partial x_{n} \partial x_{1}} & \frac{\partial^{2} f}{\partial x_{n} \partial x_{2}} & \cdots & \frac{\partial^{2} f}{\partial x_{n}^{2}} \end{array}\right] H= ∂x12∂2f∂x2∂x1∂2f⋮∂xn∂x1∂2f∂x1∂x2∂2f∂x22∂2f⋮∂xn∂x2∂2f⋯⋯⋱⋯∂x1∂xn∂2f∂x2∂xn∂2f⋮∂xn2∂2f Hessian 矩阵必定是一个对称矩阵
2 最速下降法
通过上面梯度知识的回顾,再来看这个算法就不会觉的很茫然。最速梯度下降法:解决的问题是 无约束优化 问题,而所谓的无约束优化问题就是对目标函数的求解,没有任何的约束限制的优化问题,比如求下方最小值: m i n f ( x ) min f(x) minf(x)
其中的函数 f : R n → R f:R^n \to R f:Rn→R.
求解这类的问题可以分为两大类:最优条件法和迭代法
2.1 概念7
最速下降法(Steepest descent)是梯度下降法的一种更具体实现形式,其理念为在每次迭代中选择合适的步长 α k \alpha_k αk ,使得目标函数值能够得到最大程度的减少。
每一次迭代,沿梯度的反方向,我们总可以找到一个 x ( k + 1 ) = x k − α k ⋅ ∇ f ( x ( k ) ) x^{(k+1)} = x^k - \alpha_k \cdot \nabla f(x^{(k)}) x(k+1)=xk−αk⋅∇f(x(k)) ,使得在这个方向 f ( x ( k + 1 ) ) f(x^{(k+1)}) f(x(k+1)) 取最小值,即 α ( k ) = argmin f ( x k − α ⋅ ∇ f ( x ( k ) ) ) \alpha_{(k)}=\operatorname{argmin}f\left(x^{k}-\alpha \cdot \nabla f\left(x^{(k)}\right)\right) α(k)=argminf(xk−α⋅∇f(x(k)))
可以发下一个很有趣的事情就是:最速下降法每次更新的轨迹都和上一次垂直(证明过程在2.3中会讲解)
2.2 算法步骤7
下面先给出最速下降法的计算步骤:
第1步:选取初始点 x 0 x^0 x0 ,给定终止误差 ε > 0 \varepsilon >0 ε>0 ,令 k = 0 k=0 k=0 ;
第2步:计算 ∇ f ( x k ) \nabla f(x^k) ∇f(xk) ,若 ∣ ∣ ∇ f ( x k ) ∣ ∣ ≤ ε ||\nabla f(x^k)|| \le \varepsilon ∣∣∇f(xk)∣∣≤ε ,停止迭代,输出 x k x^k xk 。否则进行第三步;
第3步:取 p k = − ∇ f ( x k ) p^k = -\nabla f(x^k) pk=−∇f(xk) ;
第4步:进行一维搜索,求 λ k \lambda_k λk ,使得 f ( x k + λ k p k ) = min λ ≥ 0 f ( x k + λ p k ) f\left(x^{k}+\lambda_{k} p^{k}\right)=\min _{\lambda \geq 0} f\left(x^{k}+\lambda p^{k}\right) f(xk+λkpk)=λ≥0minf(xk+λpk)令 x k + 1 = x k + λ k p k , k = k + 1 ,转第 2 步 x^{k+1} = x^k + \lambda_k p^k,k=k+1,\text{转第 2 步} xk+1=xk+λkpk,k=k+1,转第 2 步
2.3 原理详解8
设 x = x ( k ) + λ p ( k ) x=x^{(k)}+\lambda p^{(k)} x=x(k)+λp(k) 在 x ( k ) x^{(k)} x(k) 点处作一阶泰勒展开 f ( x ) = f ( x ( k ) + λ p ( k ) ) = f ( x ( k ) ) + λ ∇ f ( x ( k ) ) T p ( k ) + O ( ∣ ∣ λ p ( k ) ∣ ∣ ) f(x)=f(x^{(k)}+\lambda p^{(k)}) = f(x^{(k)})+\lambda \nabla f(x^{(k)})^{T} p^{(k)}+O(||\lambda p^{(k)}||) f(x)=f(x(k)+λp(k))=f(x(k))+λ∇f(x(k))Tp(k)+O(∣∣λp(k)∣∣) 其中 O ( ∣ ∣ λ p ( k ) ∣ ∣ ) = O ( ∣ ∣ λ ∣ ∣ ) O(||\lambda p^{(k)}||)=O(||\lambda||) O(∣∣λp(k)∣∣)=O(∣∣λ∣∣) 是比 λ \lambda λ 高阶的无穷小量,而 ∣ ∣ p ( k ) ∣ ∣ = 1 ||p^{(k)}||=1 ∣∣p(k)∣∣=1.
因此 f ( x ( k + 1 ) ) − f ( x ( k ) ) ≈ λ ∇ f ( x ( k ) ) T p ( k ) f(x^{(k+1)})-f(x^{(k)}) \approx \lambda \nabla f(x^{(k)})^{T} p^{(k)} f(x(k+1))−f(x(k))≈λ∇f(x(k))Tp(k)
∇ f ( x ( k ) ) T p ( k ) = ∣ ∣ ∇ f ( x ( k ) ) ∣ ∣ ⋅ ∣ ∣ p ( k ) ∣ ∣ cos θ = ∣ ∣ ∇ f ( x ( k ) ) ∣ ∣ ⋅ cos θ \nabla f(x^{(k)})^{T} p^{(k)}=||\nabla f(x^{(k)})||\cdot||p^{(k)}|| \cos \theta=||\nabla f(x^{(k)})||\cdot\cos \theta ∇f(x(k))Tp(k)=∣∣∇f(x(k))∣∣⋅∣∣p(k)∣∣cosθ=∣∣∇f(x(k))∣∣⋅cosθ
搜索方向 p ( k ) p^{(k)} p(k):在第1小节中讲述了取 θ = 180 ° \theta = 180° θ=180° 梯度负方向原因。 ∴ \therefore ∴ p ( k ) = − ∇ f ( x ( k ) ) p^{(k)}=-\nabla f(x^{(k)}) p(k)=−∇f(x(k))
求梯度向量模的值: ∣ ∣ ∇ f ( x ( k ) ) T ∣ ∣ ||\nabla f(x^{(k)})^{T}|| ∣∣∇f(x(k))T∣∣.
若 ∣ ∣ ∇ f ( x ( k ) ) T ∣ ∣ < ε ||\nabla f(x^{(k)})^{T}|| < \varepsilon ∣∣∇f(x(k))T∣∣<ε,停止计算,输出 x ( k ) x^{(k)} x(k) 作为极小点近似值。若 ∣ ∣ ∇ f ( x ( k ) ) T ∣ ∣ > ε ||\nabla f(x^{(k)})^{T}|| > \varepsilon ∣∣∇f(x(k))T∣∣>ε,转下一步很多讲解都没有对这一个地方进行详细的说明,其实一开始本人也是不太理解为什么只需要证明了梯度向量的模长 ∣ ∣ ∇ f ( x ( k ) ) T ∣ ∣ < ε ||\nabla f(x^{(k)})^{T}|| < \varepsilon ∣∣∇f(x(k))T∣∣<ε 就可以了。
证明:
其实可以结合公式( ∣ ∣ p ( k ) ∣ ∣ = 1 ||p^{(k)}||=1 ∣∣p(k)∣∣=1): f ( x ( k + 1 ) ) − f ( x ( k ) ) ≈ λ ∇ f ( x ( k ) ) T p ( k ) = ∣ ∣ ∇ f ( x ( k ) ) ∣ ∣ ⋅ cos θ f(x^{(k+1)})-f(x^{(k)}) \approx \lambda \nabla f(x^{(k)})^{T} p^{(k)}=||\nabla f(x^{(k)})||\cdot\cos \theta f(x(k+1))−f(x(k))≈λ∇f(x(k))Tp(k)=∣∣∇f(x(k))∣∣⋅cosθ,其中的 f ( x ( k + 1 ) ) f(x^{(k+1)}) f(x(k+1))表示的是下一个寻优值, f ( x ( k ) ) f(x^{(k)}) f(x(k)) 表示当前的迭代值:左边式子的含义:就是当前值与未来值之差越来越小,那就说明变化的速度越来越慢了,速度慢下来了,那不就意味着离这个最优的极小点越来越近了。右边式子含义:左边两个式子差值最终等于一个梯度的大小 ∣ ∣ ∇ f ( x ( k ) ) ∣ ∣ ||\nabla f(x^{(k)})|| ∣∣∇f(x(k))∣∣ × cos θ \cos \theta cosθ,大家都知道 cos θ ∈ [ 0 , 1 ] \cos \theta \in [0,1] cosθ∈[0,1], ∴ \therefore ∴ 当 ∣ ∣ ∇ f ( x ( k ) ) T ∣ ∣ < ε ||\nabla f(x^{(k)})^{T}|| < \varepsilon ∣∣∇f(x(k))T∣∣<ε 时是不是说明找的这个值是不是可以近似看作一个极小值,且 x ( k ) x^{(k)} x(k) 为极小点。
最优步长 λ k \lambda_k λk:
设 f ( x ) f(x) f(x) 具有二阶连续偏导数,将它在 x ( k ) x^{(k)} x(k) 点作二阶泰勒展开: f ( x ( k ) − λ ∇ f ( x ( k ) ) ) = f ( x ( k ) ) + ∇ f ( x ( k ) ) T ( − λ ∇ f ( x ( k ) ) ) + 1 2 ( − λ ∇ f ( x ( k ) ) ) T H ( x ( k ) ) ( − λ ∇ f ( x ( k ) ) ) + O ( ∥ λ ∇ f ( x ( k ) ∥ 2 ) \begin{aligned} f\left(x^{(k)}-\lambda \nabla f\left(x^{(k)}\right)\right) &=f\left(x^{(k)}\right)+\nabla f\left(x^{(k)}\right)^{T}\left(-\lambda \nabla f\left(x^{(k)}\right)\right) \\ &+\frac{1}{2}\left(-\lambda \nabla f\left(x^{(k)}\right)\right)^{T} H\left(x^{(k)}\right)\left(-\lambda \nabla f\left(x^{(k)}\right)\right) \\ &+O\left(\| \lambda \nabla f\left(x^{(k)} \|^{2}\right)\right. \end{aligned} f(x(k)−λ∇f(x(k)))=f(x(k))+∇f(x(k))T(−λ∇f(x(k)))+21(−λ∇f(x(k)))TH(x(k))(−λ∇f(x(k)))+O(∥λ∇f(x(k)∥2)
将上式主要部分记作 H ( λ ) H(\lambda) H(λ) H ( λ ) = f ( x ( k ) ) + ∇ f ( x ( k ) ) T ( − λ ∇ f ( x ( k ) ) ) + 1 2 ( − λ ∇ f ( x ( k ) ) ) T H ( x ( k ) ) ( − λ ∇ f ( x ( k ) ) ) H(\lambda)= f\left(x^{(k)}\right)+\nabla f\left(x^{(k)}\right)^{T}\left(-\lambda \nabla f\left(x^{(k)}\right)\right)+\frac{1}{2}\left(-\lambda \nabla f\left(x^{(k)}\right)\right)^{T} H\left(x^{(k)}\right)\left(-\lambda \nabla f\left(x^{(k)}\right)\right) H(λ)=f(x(k))+∇f(x(k))T(−λ∇f(x(k)))+21(−λ∇f(x(k)))TH(x(k))(−λ∇f(x(k)))
函数 H ( λ ) H(\lambda) H(λ)的唯一的极值点(令 H ′ ( λ ) = 0 H'(\lambda)=0 H′(λ)=0,即可求出 λ \lambda λ)为: λ k = ∇ f ( x ( k ) ) T ∇ f ( x ( k ) ) ∇ f ( x ( k ) ) T H ( x ( k ) ) ∇ f ( x ( k ) ) \lambda_{k}=\frac{\nabla f\left(x^{(k)}\right)^{T} \nabla f\left(x^{(k)}\right)}{\nabla f\left(x^{(k)}\right)^{T} H\left(x^{(k)}\right) \nabla f\left(x^{(k)}\right)} λk=∇f(x(k))TH(x(k))∇f(x(k))∇f(x(k))T∇f(x(k))
其中 H ( x ( k ) ) H(x^{(k)}) H(x(k)) 在第1节说过是 Hessian 矩阵
这里证明前面说的垂直关系,证明如下:
将点 x ( k + 1 ) = x ( k ) + λ p k x^{(k+1)}=x^{(k)}+\lambda p^{k} x(k+1)=x(k)+λpk 代入函数 f ( x ) f(x) f(x) 中,再令 f ′ ( x ) = 0 f'(x)=0 f′(x)=0 可以得到: f ′ ( x ( k + 1 ) ) = f ′ ( x ( k ) + λ p k ) = ∇ f ( x ( k ) + λ p k ) T p ( k ) = 0 f'(x^{(k+1)})=f'(x^{(k)}+\lambda p^{k})=\nabla f(x^{(k)}+\lambda p^{k})^{T}p^{(k)}=0 f′(x(k+1))=f′(x(k)+λpk)=∇f(x(k)+λpk)Tp(k)=0
将 p ( k ) = − ∇ f ( x ( k ) ) p^{(k)}=-\nabla f(x^{(k)}) p(k)=−∇f(x(k)) 代入上式: − ∇ f ( x ( k ) + λ p k ) T ∇ f ( x ( k ) ) = − ∇ f ( x ( k + 1 ) ) T ∇ f ( x ( k ) ) = 0 -\nabla f(x^{(k)}+\lambda p^{k})^{T}\nabla f(x^{(k)})=-\nabla f(x^{(k+1)})^{T}\nabla f(x^{(k)})=0 −∇f(x(k)+λpk)T∇f(x(k))=−∇f(x(k+1))T∇f(x(k))=0
这不就证明出来了,前一个点与后一个点的梯度是垂直关系
下面讲下这个步长 λ \lambda λ 取大取小的影响,以一元二次函数为例,如图 1 所示(这个图本人用matlab画出来的,代码会放大最后):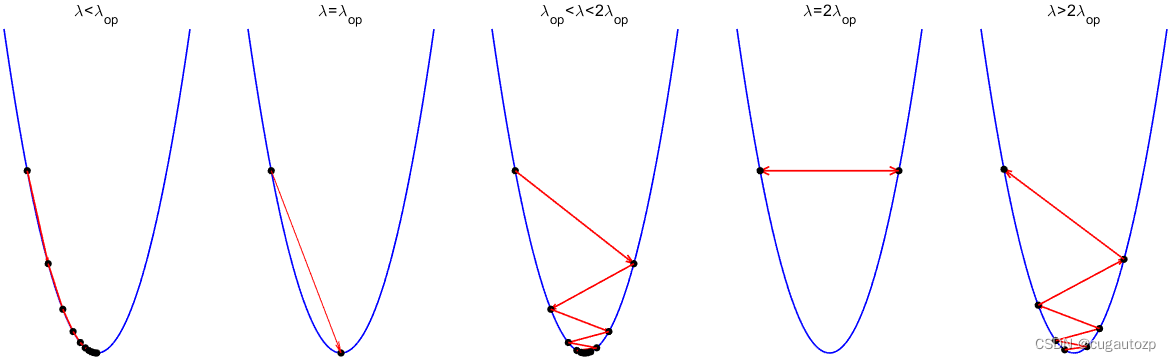
图 1 \text{图 1} 图 1
可以从这个图中看到最优步长为 λ o p \lambda_{op} λop,当步长 λ ∈ ( 0 , λ o p ) ∪ ( λ o p , 2 λ o p ) \lambda \in(0,\lambda_{op}) \cup (\lambda_{op},2\lambda_{op}) λ∈(0,λop)∪(λop,2λop) 迭代次数很多收敛速度很慢。很有意思的是当 λ = 2 λ o p \lambda =2\lambda _{op} λ=2λop 时不迭代了直接在等高线上来回迭代。当 λ ∈ ( 2 λ o p , ∞ ) \lambda \in(2\lambda_{op},\infty) λ∈(2λop,∞) 时反向迭代了,远离了极小值点。
2.4 缺点7
某点的负梯度方向,通常只是在该点附近才具有这种最速下降的性质。
最速下降法利用目标函数一阶梯度进行下降求解,易产生锯齿现象(如下图 ),在开始几步,目标函数下降较快;但在接近极小点时,收敛速度长久不理想了。特别适当目标函数的等值线为比较扁平的椭圆时,收敛就更慢了。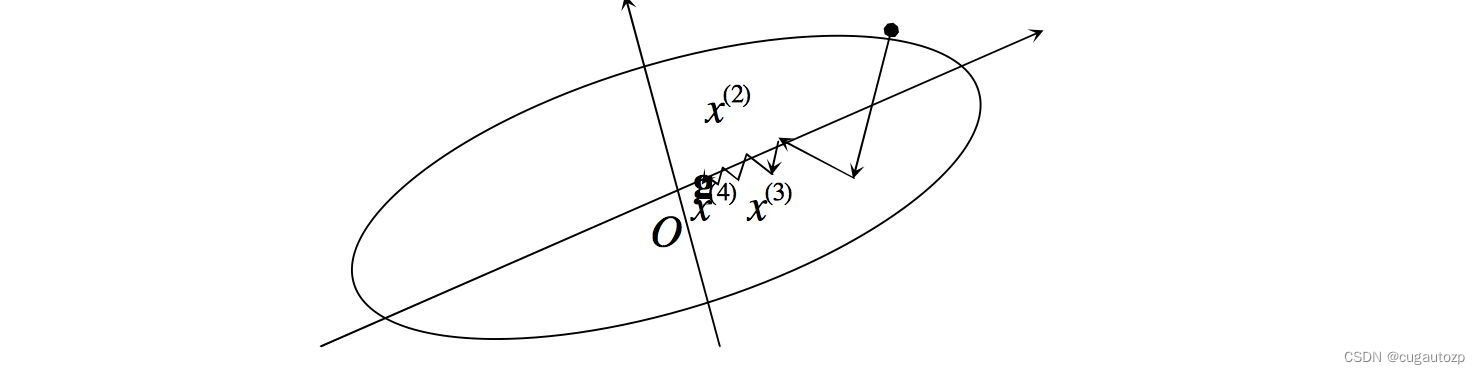
因此,在实用中常用最速下降法和其他方法联合应用,在前期使用最速下降法,而在接近极小值点时,可改用收敛较快的其他方法。
3 示例说明
这个例子就用这篇文章的示例9 虽然用了他的例子本人代码和他代码完全不一样。如果大家感兴趣也可以去看这个人的代码。好了废话不多说上题目: m i n f ( x ) = x 1 2 + 2 x 2 2 − 2 x 1 x 2 − 2 x 2 min f(x) = x_1^{2}+2x_2^2-2x_1x_2-2x_2 minf(x)=x12+2x22−2x1x2−2x2其中 x = ( x 1 , x 2 ) T x=(x_1,x_2)^T x=(x1,x2)T, x 0 = ( 0 , 0 ) T x^{0}=(0,0)^T x0=(0,0)T 。
(1) 求梯度函数 ∇ f ( x ) = ( 2 x 1 − 2 x 2 4 x 2 − 2 x 1 − 2 ) \nabla f(x)=\begin{pmatrix} 2x_1-2x_2\\ 4x_2-2x_1-2\end{pmatrix} ∇f(x)=(2x1−2x24x2−2x1−2) Hessian 矩阵 H ( x ) = ∇ ( ∇ f ( x ) ) = ( 2 − 2 − 2 4 ) H(x)=\nabla(\nabla f(x))=\begin{pmatrix} 2&-2\\ -2&4\end{pmatrix} H(x)=∇(∇f(x))=(2−2−24)
(2) 将 x ( 0 ) = ( 0 , 0 ) T x^{(0)}=(0,0)^T x(0)=(0,0)T 代入上式 (1) 中,得到 ∇ f ( x ( 0 ) ) = ( 0 − 2 ) \nabla f(x^{(0)})=\begin{pmatrix} 0\\ -2\end{pmatrix} ∇f(x(0))=(0−2) ,即 p ( 0 ) = − ∇ f ( x ( 0 ) ) = ( 0 2 ) p^{(0)}=-\nabla f(x^{(0)})=\begin{pmatrix} 0\\ 2\end{pmatrix} p(0)=−∇f(x(0))=(02)
(3) H ( x ( 0 ) ) = ( 2 − 2 − 2 4 ) H(x^{(0)})=\begin{pmatrix} 2&-2\\ -2&4\end{pmatrix} H(x(0))=(2−2−24) 和 ∇ f ( x ( 0 ) ) \nabla f(x^{(0)}) ∇f(x(0)) 代入 λ k = ∇ f ( x ( k ) ) T ∇ f ( x ( k ) ) ∇ f ( x ( k ) ) T H ( x ( k ) ) ∇ f ( x ( k ) ) \lambda_{k}=\frac{\nabla f\left(x^{(k)}\right)^{T} \nabla f\left(x^{(k)}\right)}{\nabla f\left(x^{(k)}\right)^{T} H\left(x^{(k)}\right) \nabla f\left(x^{(k)}\right)} λk=∇f(x(k))TH(x(k))∇f(x(k))∇f(x(k))T∇f(x(k))
得到 λ = ( 0 − 2 ) ( 0 − 2 ) ( 0 − 2 ) ( 2 − 2 − 2 4 ) ( 0 − 2 ) = 1 4 \lambda=\frac{\begin{pmatrix} 0& -2\end{pmatrix} \begin{pmatrix} 0\\ -2\end{pmatrix}}{\begin{pmatrix} 0& -2\end{pmatrix}\begin{pmatrix} 2&-2\\ -2&4\end{pmatrix} \begin{pmatrix} 0\\ -2\end{pmatrix}}=\frac{1}{4} λ=(0−2)(2−2−24)(0−2)(0−2)(0−2)=41
(4) x ( 1 ) = x ( 0 ) + λ p ( 0 ) = ( 0 1 ) x^{(1)}=x^{(0)}+\lambda p^{(0)}=\begin{pmatrix} 0\\ 1\end{pmatrix} x(1)=x(0)+λp(0)=(01)
同理转回(2)可以一直迭代回去一直到满足条件为止,得到最优解为 x ∗ = ( 1 , 1 ) T , y ∗ = − 1 x^*=(1,1)^T,y^*=-1 x∗=(1,1)T,y∗=−1
4 代码实现
根据上面的方法步骤来看,其实编写代码的时候只需要几个模块就行,(1)求 ∇ f ( x ) \nabla f(x) ∇f(x) 的函数,(2)求 Hessian 矩阵 H ( x ) H(x) H(x) 的模块 ;(3)将前面两个函数放在一起构造一个求最速下法的函数即可;(4)为了可视化,本人又增加了一个生成GIF的动态最速下降法的画图函数。
声明:
(2022.5.30)现已经解决了限制,可以实现n元n次函数,GDplot()画图函数只能绘制三维图) 注意:接下来的几个模快代码里有会用到在开头就提醒大家得必备一些函数的应用。
先放结果:
生成的GIF图: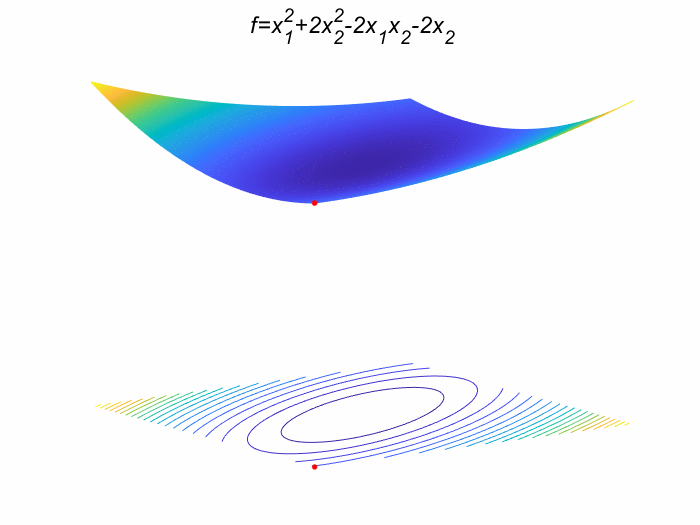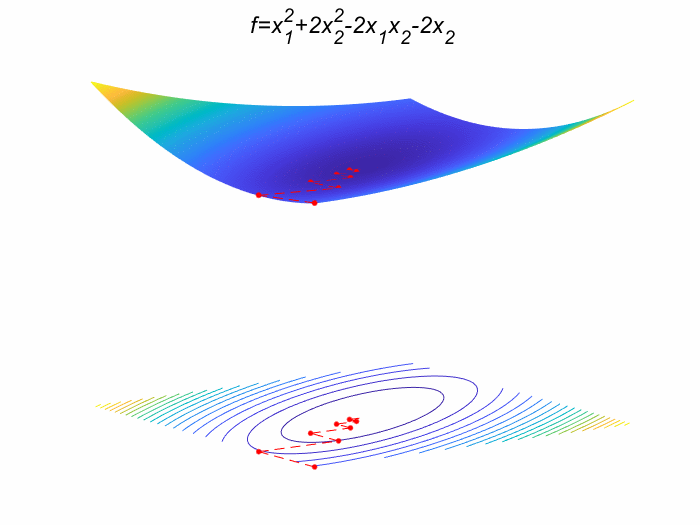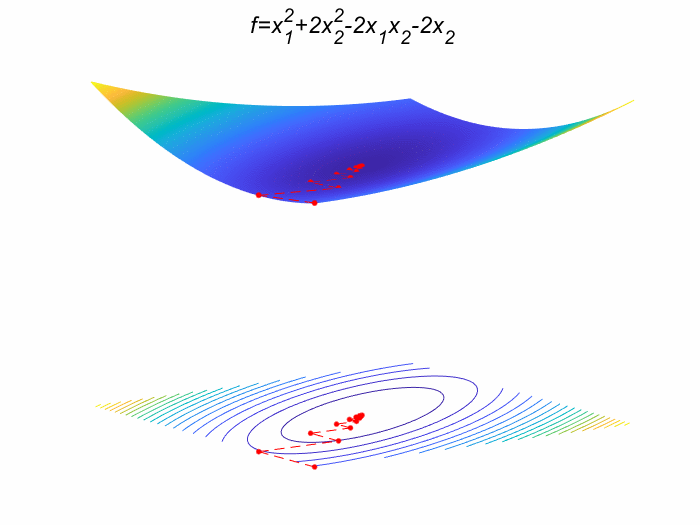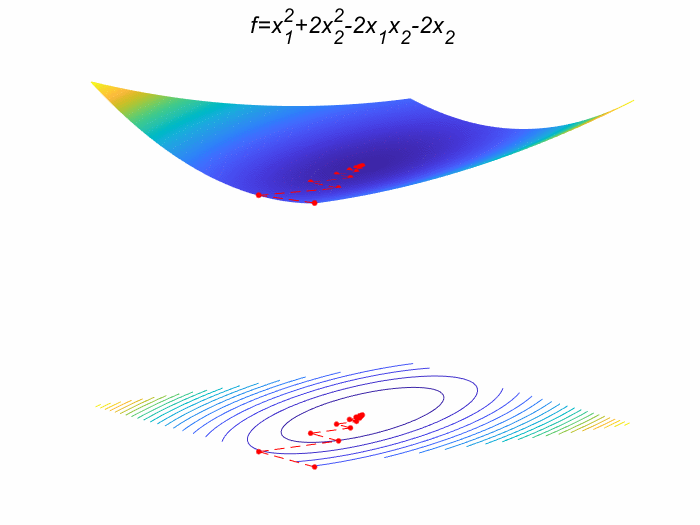
4.1 ∇ f ( x ) \nabla f(x) ∇f(x) 的函数模块代码实现
这个函数的 输入 有两个:(1)fun:表示函数表达式,matlab中一般用句柄函数形式表达。句柄函数写法在文章的开头就写过,或者不了解的同学可以去看参考文献的第一个。(2)x:表示变量字符串,这里一般是 x 1 , x 2 x_1,x_2 x1,x2,下面也给出了例子。
输出:df:是一个句柄函数
代码如下:
function df=nabla_f(fun,x)% ∇f 求梯度 df=[]; x=str2sym(x); for i=1:length(x) df1 = diff(fun,x(i)); df=[df;df1]; end df= matlabFunction(df);end例如输入以下代码运行后可以得到一个df的句柄函数:
f=@(x1,x2) x1.^2+2*x2.^2-2*x1.*x2-2*x2;x ='[x1,x2]';df=nabla_f(f,x)output:
4.2 Hessian 矩阵 H ( x ) H(x) H(x) 的模块代码实现
这个函数的 输入 有4个:(1)df:表示为 ∇ f ∇f ∇f ,即为函数nabla_f 的结果。(2)x:表示变量字符串,这里一般是 x 1 , x 2 x_1,x_2 x1,x2。(3)x0:表示初始的 x ( 0 ) x^{(0)} x(0)。(4)n:表示当前迭代次数。
输出:df:是一个句柄函数
代码如下:
function H = Hesse(df,x,x0,n)% Hesse矩阵 H(x)=∇(∇f) % df 为 ∇f,即为函数nabla_f的结果 ∇f H=[]; x=str2sym(x); for i=1:length(x) df1 = diff(df,x(i)); H=[H,df1]; end% H = matlabFunction(H); s=char(H); if find(s=='x') H = matlabFunction(H); H = H(x0{n}(1),x0{n}(2)); else H = double(H); endend4.3 最速下降法函数模块代码实现
输入:(1)f:为上面定义的句柄函数 例如:f= @(x1,x2) 2*x1.^2+2*x2.^2+2*x1.*x2+x1-x2。(2) x:为表示变量字符串,这里一般是 x 1 , x 2 x_1,x_2 x1,x2.(3)x0:表示起始点 x ( 0 ) x^{(0)} x(0) 。(4)epsilon 为 ε ε ε 精度
代码如下:
function [x0,i] = GD(f,x,x0,epsilon)% 梯度下降法 也可以称:最速下降法% input:f 为上面定义的句柄函数 例如:f= @(x1,x2) 2*x1.^2+2*x2.^2+2*x1.*x2+x1-x2;% x 为表示变量字符串,这里一般是 x1,x2% x0 表示起始点% epsilon 为ε精度% output:x0 为GD函数出来的从起始点x0寻优到极小值点的所有点集合% i 为GD函数寻优过程得到点的个数即:i==length(x0)% 可以打印出最小值 min{f},以及极小值值点 x% i=1; df = nabla_f(f,x); H = Hesse(df,x,x0,i); dfx=df(x0{1}(1),x0{1}(2)); er=norm(dfx); while er > epsilon p = -dfx; lambda = dfx'*dfx/(dfx'*H*dfx); i=i+1; x0{i} = x0{i-1}+lambda*p; dfx = df(x0{i}(1),x0{i}(2)); H = Hesse(df,x,x0,i); er = norm(dfx); end fmin = f(x0{i}(1),x0{i}(2)); disp('极小值点:'); disp(['x1 = ',num2str(x0{i}(1))]); disp(['x2 = ',num2str(x0{i}(2))]); fprintf('\nf最小值:\n min{f}=%f\n',fmin);end*4.4 最速下降法画图函数模块代码实现
这个函数代码感兴趣的同学可以看看,个人只把代码放在这里就不加解释。主要是写了这么长太累偷个懒不过分吧!
创新点:1. 可以根据 f的表达式自动生成图的标题,意思就是不需要自己手动打图标题,输入任意的 f f f 可以实现任意 f f f 的图标题显示,这都得益于写了一个 f2t() 函数,该函数实现了将句柄函数格式 (function_handle) 转化为 T e x Tex Tex 格式的字符串。
更新2022-11-6已经将suptitle改为了sgtitle,并上传了f2s函数
代码如下:
function GDplot(f,x0,i,x1,x2,GIFname)% input:f 为上面定义的句柄函数 例如:f= @(x1,x2) 2*x1.^2+2*x2.^2+2*x1.*x2+x1-x2;% x0 为GD函数出来的从起始点x0寻优到极小值点的所有点集合% i 为GD函数寻优过程得到点的个数即:i==length(x0)% x1 为f函数中第一个变量的取值范围% x2 为f函数中第二个变量的取值范围% % output:生成一个gif [x1,x2]=meshgrid(x1,x2); z=f(x1,x2); figure('color','w') sgtitle(['\it f=',f2s(f)]) subplot(211) mesh(x1,x2,z) axis off view([-35,45]) hold on subplot(212) contour(x1,x2,z,20) zlim([0,0.5]) set(gca,'ZTick',[],'zcolor','w') axis off view([-35,45]) hold on pic_num = 1; for j =1:i-1 a=[x0{j}(1),x0{j}(2),f(x0{j}(1),x0{j}(2))]; b=[x0{j+1}(1),x0{j+1}(2),f(x0{j+1}(1),x0{j+1}(2))]; c=[a',b']; a1=[x0{j}(1),x0{j}(2)]; b1=[x0{j+1}(1),x0{j+1}(2)]; c1=[a1',b1']; subplot(211) plot3(x0{j}(1),x0{j}(2),f(x0{j}(1),x0{j}(2)),'r.','MarkerSize',10) subplot(212) plot(x0{j}(1),x0{j}(2),'r.','MarkerSize',10) drawnow F(j)=getframe(gcf); pause(0.5) subplot(211) plot3(c(1,:),c(2,:),c(3,:),'r--') subplot(212) plot(c1(1,:),c1(2,:),'r--') drawnow F(2*j)=getframe(gcf); pause(0.5) % 绘制并保存gif I=frame2im(F(j)); [I,map]=rgb2ind(I,256); I1=frame2im(F(2*j)); [I1,map1]=rgb2ind(I1,256); if pic_num == 1 imwrite(I,map, GIFname ,'gif', 'Loopcount',inf,'DelayTime',0.5); else imwrite(I,map, GIFname ,'gif','WriteMode','append','DelayTime',0.5); imwrite(I1,map1, GIFname ,'gif','WriteMode','append','DelayTime',0.5); end pic_num = pic_num + 1; end subplot(211) plot3(x0{i}(1),x0{i}(2),f(x0{i}(1),x0{i}(2)),'r.','MarkerSize',9) subplot(212) plot(x0{i}(1),x0{i}(2),'r.','MarkerSize',9) F(2*i-1)=getframe(gcf); I=frame2im(F(2*i-1)); [I,map]=rgb2ind(I,256); imwrite(I,map, GIFname ,'gif','WriteMode','append','DelayTime',0.5);endfunction s = f2s(fun)% 句柄函数的转换为字符串 % 主要是用来画图title用的,可自动将句柄函数转为字符串函数% 在绘制画图时可以自动生成函数表达式 title(并且以Latex形式显示出来),避免手动敲击函数公式 s = func2str(fun); s = char(s); c = strfind(s,')'); s(1:c(1))=[]; c1 = strfind(s,'.'); s(c1)=[]; c2 = strfind(s,'*'); s(c2)=[]; c3 = strfind(s,'x'); for i = 1:length(c3) s = insertAfter(s,c3(i)+i-1,'_'); end end4.5 主函数
代码如下:
clcclear allclose all% f= @(x1,x2) 2*x1.^2+2*x2.^2+2*x1.*x2+x1-x2;f= @(x1,x2) x1.^2+2*x2.^2-2*x1.*x2-2*x2; % 句柄函数表达式% f= @(x1,x2) (x1-1).^2+(x2-1).^2;% f=@(x1,x2) x1.^4+3*x1.^2*x2-x2.^4;x0{1}=[0;0];x ='[x1,x2]'; % 函数变量字符串epsilon=0.001; % ε为误差精度[x0,i] = GD(f,x,x0,epsilon);x1=0:0.01:2;x2=x1;GIFname = 'f1.gif';GDplot(f,x0,i,x1,x2,GIFname)4.6 上面图1的代码
图1代码直接下载文件链接:点击此处下载代码文件
4.7 完整代码文件
如果是小白的同学可以下载这个完整代码(包含本文章的代码+图1的代码):
代码已经放入个人GitHub中:https://github.com/cug-auto-zp/CSDN/tree/main/gradient
如果进不了GitHub的读者,这里还提供了资源下载链接:资源链接
5 总结
写这篇文章还是要感谢这些博主写的文章个人感觉看了他们的文章收获非常多。给大家代码一方面是方便大家学习,另一方面是我也是通过大佬们的文章和公开的代码发现matlab有很个人不知道的函数,边看边学代码,有很多人问我是这么学的matlab,其实也不用刻意去学习这个东西,我都是在边看边积累的过程不断地扩充了自己的matlab的知识。所以个人坚持将这种开源的代码的思想一直进行下去。
6 引用参考
句柄函数 ↩︎
matlab官方文档——matlabFunction:https://ww2.mathworks.cn/help/symbolic/matlabfunction.html ↩︎
方向导数与梯度:https://blog.csdn.net/myarrow/article/details/51332421 ↩︎
梯度(gradient)到底是个什么东西?物理意义和数学意义分别是什么?:https://www.zhihu.com/question/29151564 ↩︎
梯度、散度、旋度:https://zhuanlan.zhihu.com/p/97545154 ↩︎
第八讲梯度下降法:https://zhuanlan.zhihu.com/p/335191534 ↩︎
无约束优化问题 — 最速下降法:https://zhuanlan.zhihu.com/p/445223282 ↩︎ ↩︎ ↩︎
最速下降法(上):https://www.bilibili.com/video/BV1RK4y1a75C/
最速下降法(下):
https://www.bilibili.com/video/BV1ey4y1k7jY/?spm_id_from=333.788.recommend_more_video.-1 ↩︎
优化算法之——最速下降法:https://blog.csdn.net/m0_37570854/article/details/88559619 ↩︎