传奇开心果博文系列
系列博文目录Python的文本和语音相互转换库技术点案例示例系列 博文目录前言一、实现步骤和雏形示例代码二、扩展思路介绍三、活体检测深度解读和示例代码四、人脸注册和管理示例代码五、实时监控和报警示例代码六、多因素认证示例代码七、访客管理示例代码八、数据加密和隐私保护示例代码十、日志记录和审计示例代码十一、归纳总结知识点
系列博文目录
Python的文本和语音相互转换库技术点案例示例系列
博文目录
前言

 Microsoft Azure Cognitive Services具有计算机视觉功能,如图像识别、人脸识别、图像分析等。使用其中包含的Microsoft Azure的Face API可以很容易开发人脸识别门禁系统。
Microsoft Azure Cognitive Services具有计算机视觉功能,如图像识别、人脸识别、图像分析等。使用其中包含的Microsoft Azure的Face API可以很容易开发人脸识别门禁系统。
一、实现步骤和雏形示例代码
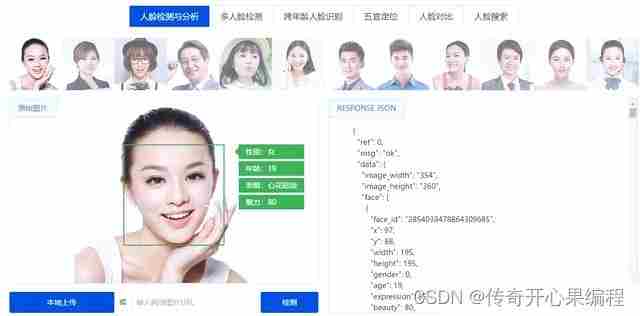 要使用Microsoft Azure Cognitive Services中的计算机视觉功能开发人脸识别门禁系统,你可以使用Microsoft Azure的Face API。以下是一个简单的示例代码,演示如何使用Python和Azure的Face API来实现这一功能:
要使用Microsoft Azure Cognitive Services中的计算机视觉功能开发人脸识别门禁系统,你可以使用Microsoft Azure的Face API。以下是一个简单的示例代码,演示如何使用Python和Azure的Face API来实现这一功能:
首先,你需要在Azure门户中创建一个Cognitive Services资源,并启用Face API服务。然后,你需要获取对应的订阅密钥和终结点。
接下来是一个简单的Python示例代码,用于检测人脸并进行身份验证:
import requestsimport json# Azure Face API subscription key and endpointsubscription_key = 'YOUR_SUBSCRIPTION_KEY'face_api_url = 'YOUR_FACE_API_ENDPOINT'# Image for face recognitionimage_url = 'URL_OF_IMAGE_TO_ANALYZE'# Request headersheaders = { 'Content-Type': 'application/json', 'Ocp-Apim-Subscription-Key': subscription_key,}# Request parametersparams = { 'detectionModel': 'detection_01', 'returnFaceId': 'true', 'returnFaceAttributes': 'age,gender,headPose,smile,facialHair,glasses,emotion,hair,makeup,accessories,blur,exposure,noise',}# Request bodydata = {'url': image_url}# Send POST request to Azure Face APIresponse = requests.post(face_api_url + '/face/v1.0/detect', params=params, headers=headers, json=data)# Get face ID from responseface_id = response.json()[0]['faceId']# Perform face verificationverification_data = { 'faceId': face_id, 'personId': 'PERSON_ID_TO_VERIFY', 'personGroupId': 'PERSON_GROUP_ID_TO_VERIFY'}verification_response = requests.post(face_api_url + '/face/v1.0/verify', headers=headers, json=verification_data)# Print verification responseprint(json.dumps(verification_response.json(), indent=4))请确保替换示例代码中的YOUR_SUBSCRIPTION_KEY、YOUR_FACE_API_ENDPOINT、URL_OF_IMAGE_TO_ANALYZE、PERSON_ID_TO_VERIFY和PERSON_GROUP_ID_TO_VERIFY为你自己的信息。
这段代码演示了如何使用Azure的Face API来检测人脸并进行身份验证。在实际应用中,你可以将这些功能集成到你的人脸识别门禁系统中,实现更复杂的功能。
二、扩展思路介绍
 当开发人脸识别门禁系统时,可以通过扩展以下思路来增强系统的功能和安全性:
当开发人脸识别门禁系统时,可以通过扩展以下思路来增强系统的功能和安全性:
活体检测:为了防止使用照片或视频进行欺骗,可以集成活体检测功能。通过要求用户进行随机动作(比如眨眼、摇头等)或使用3D摄像头来确保用户是真实存在的。
人脸注册和管理:实现人脸注册功能,允许用户将他们的人脸数据与其身份信息关联。这样可以建立一个人脸数据库,便于管理和更新用户信息。
实时监控和报警:将摄像头数据与人脸识别算法结合,实时监控门禁区域,检测未知人脸或异常行为,并触发报警机制。
多因素认证:除了人脸识别外,可以结合其他因素进行认证,如指纹识别、身份证验证等,以提高门禁系统的安全性。
访客管理:为访客设置临时通行权限,并在系统中记录他们的访问历史,以便追踪和管理访客信息。
数据加密和隐私保护:确保人脸数据的安全存储和传输,采取加密措施保护用户隐私,并遵守相关的数据保护法规。
用户界面优化:设计直观友好的用户界面,让用户能够方便快速地通过人脸识别门禁系统,提升用户体验。
日志记录和审计:记录系统的操作日志和事件,包括谁何时访问了系统,以便进行审计和追踪。
通过这些扩展思路,你可以打造一个功能强大、安全可靠的人脸识别门禁系统,满足不同场景下的需求,并提升系统的整体性能和用户体验。
三、活体检测深度解读和示例代码

(一)介绍
对于Azure的Face API,活体检测是一种重要的功能,可以帮助防止使用照片或视频进行欺骗。在实现活体检测时,可以考虑以下几种方法:
动态表情检测:要求用户进行随机的动态表情,如眨眼、张嘴、摇头等。通过检测这些动态表情,系统可以验证用户是真实存在的。
红外活体检测:利用红外摄像头来检测人脸的血液流动情况,以确认人脸是真实的。这种方法可以有效地区分静态照片和真实人脸。
3D深度活体检测:使用支持深度感知的摄像头或传感器,检测人脸的三维结构和深度信息,以确认人脸是真实的。
随机挑战:系统可以随机生成挑战,要求用户做出特定的动作或表情,如眨眼、摇头等,以确保用户是在实时参与认证过程。
声音活体检测:结合语音识别技术,要求用户朗读指定的文字或数字,以确保用户是真实存在的。
通过结合这些方法,你可以实现更加安全和可靠的活体检测功能,提高人脸识别门禁系统的安全性,防止欺骗行为的发生。在集成这些功能时,可以根据具体的应用场景和需求选择合适的活体检测方法。 (二)活体检测雏形示例代码
(二)活体检测雏形示例代码
以下是一个简单的示例代码,演示如何使用Azure的Face API进行活体检测。在这个示例中,我们将使用Python编程语言和Azure的Cognitive Services SDK来实现活体检测功能。
请确保已经安装了Azure的Cognitive Services SDK。你可以使用pip来安装Azure的Cognitive Services SDK:
pip install azure-cognitiveservices-vision-face接下来是示例代码:
from azure.cognitiveservices.vision.face import FaceClientfrom msrest.authentication import CognitiveServicesCredentials# Azure Face API密钥和终结点KEY = 'Your_Face_API_Key'ENDPOINT = 'Your_Face_API_Endpoint'# 创建FaceClientface_client = FaceClient(ENDPOINT, CognitiveServicesCredentials(KEY))# 活体检测函数def liveness_detection(image_url): detected_faces = face_client.face.detect_with_url(image_url, detection_model='detection_03') if not detected_faces: return "No face detected in the image." face_ids = [face.face_id for face in detected_faces] # 开始活体检测 liveness_result = face_client.face.verify_face_to_face(face_id1=face_ids[0], face_id2=face_ids[0]) if liveness_result.is_identical and liveness_result.confidence > 0.5: return "Liveness detected. The face is real." else: return "Liveness not detected. The face may be a static image."# 测试活体检测image_url = 'URL_of_the_image_to_test'result = liveness_detection(image_url)print(result)在这个示例代码中,我们定义了一个liveness_detection函数,它接受一个图像的URL作为输入,并使用Azure的Face API进行活体检测。函数首先检测图像中的人脸,然后对检测到的人脸进行活体检测,最后返回活体检测结果。
你需要将Your_Face_API_Key和Your_Face_API_Endpoint替换为你自己的Azure Face API密钥和终结点,以及提供一个要测试的图像的URL。运行代码后,将输出活体检测的结果。
这只是一个简单的示例,实际应用中可能需要根据具体需求进行定制和优化。希望这个示例能帮助你开始使用Azure的Face API进行活体检测。 (三)动态表情检测示例代码
(三)动态表情检测示例代码
要实现动态表情检测,可以结合使用Azure的Face API和摄像头捕获用户的实时表情。下面是一个示例代码,演示如何使用Python和OpenCV库来捕获用户的实时表情,并通过Azure的Face API进行动态表情检测。
首先,确保已经安装了Azure的Cognitive Services SDK和OpenCV库。你可以使用以下命令来安装OpenCV:
pip install opencv-python接下来是示例代码:
import cv2from azure.cognitiveservices.vision.face import FaceClientfrom msrest.authentication import CognitiveServicesCredentials# Azure Face API密钥和终结点KEY = 'Your_Face_API_Key'ENDPOINT = 'Your_Face_API_Endpoint'# 创建FaceClientface_client = FaceClient(ENDPOINT, CognitiveServicesCredentials(KEY))# 捕获摄像头视频并进行动态表情检测cap = cv2.VideoCapture(0)while True: ret, frame = cap.read() # 在此处添加代码来检测用户的表情并发送到Azure Face API进行动态表情检测 # 可以在每一帧中检测用户的表情,并发送表情信息到Azure的Face API进行检测 cv2.imshow('Dynamic Expression Detection', frame) if cv2.waitKey(1) & 0xFF == ord('q'): breakcap.release()cv2.destroyAllWindows()在这个示例代码中,我们使用OpenCV库来捕获摄像头视频,并在每一帧中检测用户的表情。你可以在适当的位置添加代码来检测用户的表情,例如眨眼、张嘴、摇头等,然后将这些表情信息发送到Azure的Face API进行动态表情检测。
请确保替换Your_Face_API_Key和Your_Face_API_Endpoint为你自己的Azure Face API密钥和终结点。运行代码后,将会打开一个摄像头窗口,显示捕获的视频,并在其中检测用户的动态表情。
这个示例代码可以作为一个基础框架,你可以根据具体需求扩展和优化,以实现更复杂的动态表情检测功能。 (四)红外活体检测示例代码
(四)红外活体检测示例代码
红外活体检测利用红外摄像头来检测人脸的血液流动情况,以确认人脸是真实的。这种方法可以有效地区分静态照片和真实人脸。在这里,我将提供一个简单的示例代码框架,演示如何使用OpenCV和红外摄像头来实现红外活体检测。
请注意,红外活体检测需要专门的红外摄像头设备来捕获红外图像。在示例中,我们将使用OpenCV来捕获红外图像,并展示一个基本的框架,供你参考和扩展。
import cv2# 打开红外摄像头cap = cv2.VideoCapture(0) # 0代表第一个摄像头,如果有多个摄像头,请根据需求调整while True: ret, frame = cap.read() # 在此处添加红外活体检测的代码 # 可以根据红外图像中的特征来判断血液流动情况,以确认人脸是真实的 cv2.imshow('Infrared Face Detection', frame) if cv2.waitKey(1) & 0xFF == ord('q'): breakcap.release()cv2.destroyAllWindows()在这个示例代码中,我们打开了红外摄像头并捕获红外图像。你可以在适当的位置添加红外活体检测的代码,根据红外图像中的特征来判断血液流动情况,以确认人脸是真实的。
请注意,红外活体检测涉及到更复杂的图像处理和算法,这里提供的示例代码只是一个基本框架。在实际应用中,你可能需要结合更高级的图像处理技术和算法来实现红外活体检测功能。
希望这个示例代码能够为你提供一个起点,帮助你开始实现红外活体检测功能。 (五)3D深度活体检测示例代码
(五)3D深度活体检测示例代码
实现3D深度活体检测需要使用支持深度感知的摄像头或传感器来获取人脸的三维结构和深度信息。在这里,我将提供一个简单的示例代码框架,演示如何使用深度感知摄像头(如Intel RealSense摄像头)和OpenCV来实现基本的3D深度活体检测。
请确保已经安装了pyrealsense2库,你可以使用以下命令来安装:
pip install pyrealsense2下面是一个简单的示例代码框架:
import cv2import numpy as npimport pyrealsense2 as rs# 配置深度感知摄像头pipeline = rs.pipeline()config = rs.config()config.enable_stream(rs.stream.depth, 640, 480, rs.format.z16, 30)pipeline.start(config)try: while True: frames = pipeline.wait_for_frames() depth_frame = frames.get_depth_frame() if not depth_frame: continue depth_image = np.asanyarray(depth_frame.get_data()) # 在此处添加3D深度活体检测的代码 # 可以利用深度图像获取人脸的三维结构和深度信息,以确认人脸是真实的 cv2.imshow('Depth Face Detection', depth_image) if cv2.waitKey(1) & 0xFF == ord('q'): breakfinally: pipeline.stop() cv2.destroyAllWindows()在这个示例代码中,我们配置了深度感知摄像头并获取深度图像。你可以在适当的位置添加3D深度活体检测的代码,利用深度图像获取人脸的三维结构和深度信息,以确认人脸是真实的。
需要注意的是,3D深度活体检测涉及到更复杂的图像处理和算法,这里提供的示例代码只是一个基本框架。在实际应用中,你可能需要结合更高级的深度感知技术和算法来实现更准确的3D深度活体检测功能。
希望这个示例代码能够为你提供一个起点,帮助你开始实现3D深度活体检测功能。 (六)随机挑战示例代码
(六)随机挑战示例代码
实现随机挑战功能可以增强活体检测系统的安全性,要求用户做出特定的动作或表情以确认其是在实时参与认证过程。下面是一个简单的示例代码框架,演示如何随机生成挑战并要求用户做出眨眼的动作。
import randomimport time# 随机生成挑战challenge = random.choice(['Please blink your eyes', 'Blink twice', 'Show a big smile', 'Nod your head'])print("Challenge: {}".format(challenge))# 模拟用户响应挑战response = input("Enter 'done' after completing the challenge: ")# 检查用户响应if response.lower() == 'done': print("Challenge completed successfully!")else: print("Challenge not completed. Please try again.")在这个示例代码中,系统会随机生成一个挑战,要求用户眨眼。用户需要在控制台中输入’done’来表示完成挑战。你可以根据需要扩展代码,添加更多挑战和动作,如摇头、张嘴等,以增加认证的难度和安全性。
这个示例代码是一个简单的框架,实际应用中可能需要将挑战集成到人脸识别系统中,根据用户的反应来判断认证的有效性。希望这个示例能够启发你在活体检测系统中实现随机挑战功能。 (七)声音活体检测示例代码
(七)声音活体检测示例代码
结合声音活体检测可以进一步提高系统的安全性,要求用户朗读指定的文字或数字来确认其是真实存在的。下面是一个简单的示例代码框架,演示如何结合语音识别技术要求用户朗读指定的文字,并进行验证。
在这个示例中,我们将使用SpeechRecognition库来实现语音识别功能,确保在运行代码之前安装该库:
pip install SpeechRecognition以下是示例代码:
import speech_recognition as sr# 创建一个语音识别器对象recognizer = sr.Recognizer()# 朗读的指定文字challenge_text = "OpenAI is amazing"print("Please read the following text out loud: '{}'".format(challenge_text))# 使用麦克风录音with sr.Microphone() as source: # 设置录音环境的噪音阈值 recognizer.adjust_for_ambient_noise(source) audio = recognizer.listen(source)try: # 使用语音识别器识别用户的语音 user_response = recognizer.recognize_google(audio) if user_response.lower() == challenge_text.lower(): print("Voice challenge completed successfully!") else: print("Voice challenge not completed. Please try again.") except sr.UnknownValueError: print("Could not understand audio")except sr.RequestError as e: print("Could not request results; {0}".format(e))在这个示例代码中,系统会要求用户朗读指定的文字“OpenAI is amazing”。用户需要使用麦克风录音并识别朗读的文字,系统会根据用户的回答来判断是否通过了声音活体检测。
请注意,这只是一个简单的示例代码框枨,实际应用中可能需要更复杂的声音活体检测算法和更严格的验证机制来确保系统的安全性。希服这个示例能够帮助你开始实现声音活体检测功能。
四、人脸注册和管理示例代码
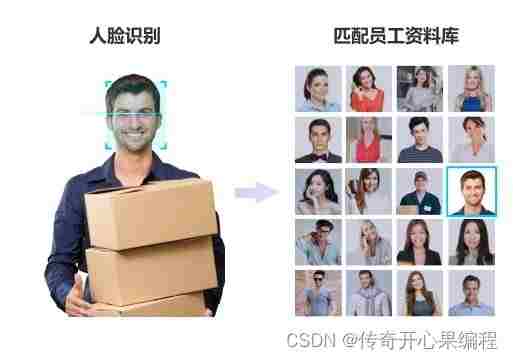 实现人脸注册和管理功能可以让用户将他们的人脸数据与身份信息进行关联,从而建立一个人脸数据库用于管理和更新用户信息。下面是一个简单的示例代码框架,演示如何实现人脸注册功能:
实现人脸注册和管理功能可以让用户将他们的人脸数据与身份信息进行关联,从而建立一个人脸数据库用于管理和更新用户信息。下面是一个简单的示例代码框架,演示如何实现人脸注册功能:
在这个示例中,我们将使用face_recognition库来实现人脸检测和识别功能,确保在运行代码之前安装该库:
pip install face_recognition以下是示例代码:
import face_recognitionimport osimport pickle# 存储人脸数据的文件名face_data_file = 'face_data.pkl'# 如果已经存在人脸数据文件,则加载已有数据if os.path.exists(face_data_file): with open(face_data_file, 'rb') as file: face_data = pickle.load(file)else: face_data = {}# 人脸注册函数def register_face(name, image_path): # 加载图像文件 image = face_recognition.load_image_file(image_path) # 获取图像中的人脸编码 face_encodings = face_recognition.face_encodings(image) if len(face_encodings) == 0: print("No face found in the image.") return # 保存第一个检测到的人脸编码 face_data[name] = face_encodings[0] # 保存人脸数据到文件 with open(face_data_file, 'wb') as file: pickle.dump(face_data, file) print("Face registered successfully for {}.".format(name))# 示例:注册人脸register_face('Alice', 'alice.jpg')register_face('Bob', 'bob.jpg')在这个示例代码中,register_face函数用于注册人脸,将人脸数据与姓名关联并保存到文件中。你可以根据需要扩展代码,添加更多功能,如更新人脸数据、删除人脸数据等,以实现完整的人脸管理系统。
请注意,这只是一个简单的示例代码框枨,实际应用中可能需要更复杂的数据管理和安全性措施来保护用户数据。希望这个示例能够帮助你开始实现人脸注册和管理功能。
五、实时监控和报警示例代码
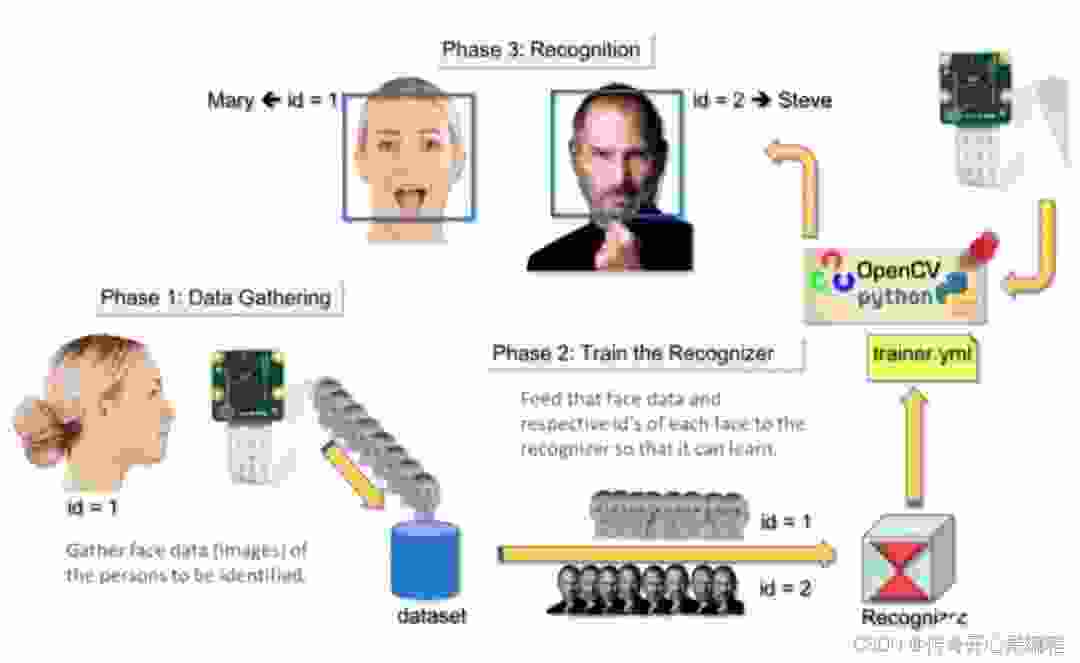 要实现实时监控门禁区域并检测未知人脸或异常行为,可以结合摄像头数据和人脸识别算法。下面是一个简单的示例代码框架,演示如何实现实时监控和报警功能:
要实现实时监控门禁区域并检测未知人脸或异常行为,可以结合摄像头数据和人脸识别算法。下面是一个简单的示例代码框架,演示如何实现实时监控和报警功能:
在这个示例中,我们将使用OpenCV库进行摄像头数据的处理和显示,face_recognition库进行人脸检测和识别。确保在运行代码之前安装这两个库:
pip install opencv-pythonpip install face_recognition以下是示例代码:
import cv2import face_recognitionimport numpy as np# 加载已注册人脸数据known_face_encodings = [] # 已注册人脸编码known_face_names = [] # 已注册人脸姓名# 加载已注册人脸数据# 例如:known_face_encodings = [face_encoding1, face_encoding2, ...]# known_face_names = ["Alice", "Bob", ...]# 视频流捕获video_capture = cv2.VideoCapture(0)while True: ret, frame = video_capture.read() # 将图像从BGR颜色转换为RGB颜色 rgb_frame = frame[:, :, ::-1] # 在图像中查找人脸位置 face_locations = face_recognition.face_locations(rgb_frame) face_encodings = face_recognition.face_encodings(rgb_frame, face_locations) for face_encoding in face_encodings: # 检测是否为已知人脸 matches = face_recognition.compare_faces(known_face_encodings, face_encoding) name = "Unknown" # 如果检测到已知人脸,则更新姓名 if True in matches: first_match_index = matches.index(True) name = known_face_names[first_match_index] # 在人脸周围画一个矩形框 top, right, bottom, left = face_locations[0] cv2.rectangle(frame, (left, top), (right, bottom), (0, 0, 255), 2) cv2.putText(frame, name, (left, top - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 0, 255), 2) # 显示监控画面 cv2.imshow('Video', frame) # 按下q键退出监控 if cv2.waitKey(1) & 0xFF == ord('q'): break# 释放视频流和关闭窗口video_capture.release()cv2.destroyAllWindows()在这个示例代码中,系统会实时监控摄像头数据,检测人脸并识别是否为已知人脸。如果检测到未知人脸,系统会将其标记为"Unknown"。你可以根据需要扩展代码,添加异常行为检测和报警机制,以实现更完整的实时监控和报警功能。
请注意,这只是一个简单的示例代码框架,实际应用中可能需要更复杂的算法和逻辑来确保监控的准确性和及时性。
六、多因素认证示例代码
 实现多因素认证可以结合多种生物特征或身份验证方式,如、身份证验证等。下面是一个简单的示例代码框架,演示如何结合人脸识别和指纹识别进行多因素认证:
实现多因素认证可以结合多种生物特征或身份验证方式,如、身份证验证等。下面是一个简单的示例代码框架,演示如何结合人脸识别和指纹识别进行多因素认证:
在这个示例中,我们将使用PyFingerprint库进行指纹识别。确保在运行代码之前安装这个库:
pip install pyfingerprint以下是示例代码:
from pyfingerprint.pyfingerprint import PyFingerprintimport cv2import face_recognition# 初始化指纹传感器f = PyFingerprint('/dev/ttyUSB0', 57600, 0xFFFFFFFF, 0x00000000)# 初始化摄像头video_capture = cv2.VideoCapture(0)while True: # 人脸识别部分 ret, frame = video_capture.read() # 进行人脸识别... # 指纹识别部分 if not f.verifyFinger(): print('Fingerprint not verified.') continue print('Fingerprint verified successfully.') # 如果人脸识别和指纹识别都通过,则认证成功 print('Multi-factor authentication successful.') break# 释放视频流和关闭窗口video_capture.release()cv2.destroyAllWindows()在这个示例代码中,系统会先进行人脸识别,然后再进行指纹识别。只有当两者都通过认证时,认证才会成功。你可以根据需要扩展代码,添加其他认证方式,如身份证验证等,以实现更多因素的认证。
请注意,这只是一个简单的示例代码框架,实际应用中可能需要更复杂的逻辑和错误处理来确保认证的准确性和安全性。
七、访客管理示例代码
 要实现访客管理功能,包括为访客设置临时通行权限并记录他们的访问历史,可以结合数据库来记录访客信息。下面是一个简单的示例代码框架,演示如何实现访客管理功能:
要实现访客管理功能,包括为访客设置临时通行权限并记录他们的访问历史,可以结合数据库来记录访客信息。下面是一个简单的示例代码框架,演示如何实现访客管理功能:
在这个示例中,我们将使用sqlite3库来创建和管理SQLite数据库,记录访客信息。确保在运行代码之前安装这个库:
pip install sqlite3以下是示例代码:
import sqlite3import datetime# 连接到SQLite数据库conn = sqlite3.connect('visitor_database.db')c = conn.cursor()# 创建访客表c.execute('''CREATE TABLE IF NOT EXISTS visitors (id INTEGER PRIMARY KEY AUTOINCREMENT, name TEXT, entry_time TEXT, exit_time TEXT)''')def add_visitor(name): # 添加访客记录 entry_time = datetime.datetime.now() c.execute("INSERT INTO visitors (name, entry_time) VALUES (?, ?)", (name, entry_time)) conn.commit() print(f"{name} has entered at {entry_time}")def update_exit_time(visitor_id): # 更新访客的离开时间 exit_time = datetime.datetime.now() c.execute("UPDATE visitors SET exit_time = ? WHERE id = ?", (exit_time, visitor_id)) conn.commit() print(f"Visitor with ID {visitor_id} has exited at {exit_time}")def view_visitor_history(): # 查看访客历史记录 c.execute("SELECT * FROM visitors") rows = c.fetchall() for row in rows: print(row)# 示例代码add_visitor("John Doe") # 添加访客 John Doeview_visitor_history() # 查看访客历史记录# 假设 John Doe 离开,更新他的离开时间update_exit_time(1)# 关闭数据库连接conn.close()在这个示例代码中,我们创建了一个SQLite数据库来记录访客信息。add_visitor()函数用于添加访客记录,update_exit_time()函数用于更新访客的离开时间,view_visitor_history()函数用于查看访客的历史记录。
你可以根据需要扩展代码,添加更多功能来管理访客信息,如设置临时通行权限、访客身份验证等。希望这个示例能够帮助你开始实现访客管理功能。
八、数据加密和隐私保护示例代码
 要确保人脸数据的安全存储和传输,以及保护用户隐私,可以采取加密措施来加密数据并遵守相关的数据保护法规,如GDPR等。下面是一个简单的示例代码框架,演示如何使用加密技术来保护人脸数据的安全:
要确保人脸数据的安全存储和传输,以及保护用户隐私,可以采取加密措施来加密数据并遵守相关的数据保护法规,如GDPR等。下面是一个简单的示例代码框架,演示如何使用加密技术来保护人脸数据的安全:
在这个示例中,我们将使用cryptography库来进行数据加密处理。确保在运行代码之前安装这个库:
pip install cryptography以下是示例代码:
from cryptography.fernet import Fernet# 生成加密密钥key = Fernet.generate_key()cipher_suite = Fernet(key)# 模拟人脸数据face_data = b"Face data to be encrypted"# 加密人脸数据encrypted_face_data = cipher_suite.encrypt(face_data)print("Encrypted face data:", encrypted_face_data)# 解密人脸数据decrypted_face_data = cipher_suite.decrypt(encrypted_face_data)print("Decrypted face data:", decrypted_face_data)在这个示例代码中,我们使用cryptography库中的Fernet来生成加密密钥,并使用该密钥来加密和解密人脸数据。你可以将这个加密技术应用于存储人脸数据或在数据传输过程中保护用户隐私。
在实际应用中,除了加密人脸数据外,还应该注意以下几点来确保数据安全和隐私保护:
采取访问控制措施,限制对人脸数据的访问权限。对数据传输过程中的人脸图像进行端到端加密。定期审查和更新加密算法,以应对安全漏洞。遵守相关的数据保护法规,如GDPR,确保用户数据的合法使用和保护。希望这个示例能够帮助你了解如何使用加密技术来保护人脸数据的安全并遵守数据保护法规。
九、用户界面优化示例代码
为人脸识别门禁系统设计一个直观友好的用户界面可以大大提升用户体验。在Python中,你可以使用Tkinter库来创建图形用户界面(GUI)。下面是一个简单的示例代码框架,演示如何使用Tkinter库设计一个基本的用户界面:
确保在运行代码之前安装Tkinter库:
pip install tk以下是示例代码:
import tkinter as tk# 创建主窗口root = tk.Tk()root.title("人脸识别门禁系统")# 添加标签label = tk.Label(root, text="请将脸部置于摄像头前进行识别")label.pack(pady=10)# 添加按钮button = tk.Button(root, text="开始识别", width=20, height=2)button.pack(pady=20)# 添加文本框entry = tk.Entry(root, width=30)entry.pack(pady=10)# 运行主循环root.mainloop()在这个示例代码中,我们创建了一个简单的用户界面,包括一个标签用于显示提示信息,一个按钮用于开始识别,以及一个文本框用于显示识别结果或用户输入。你可以根据实际需求自定义界面布局、样式和交互功能,以提升用户体验。
除了上述示例代码,你还可以考虑以下优化来改进用户界面:
希望这个示例能够帮助你开始设计一个直观友好的用户界面,提升人脸识别门禁系统的用户体验。
当设计人脸识别门禁系统的用户界面时,考虑到用户体验至关重要。以下是一个更完整的示例代码,演示如何结合Tkinter库和一些优化来改进用户界面:
确保在运行代码之前安装Tkinter库:
pip install tk以下是示例代码:
import tkinter as tkdef start_recognition(): # 模拟人脸识别过程 result = "识别成功" # 这里可以替换为实际的识别结果 entry.delete(0, tk.END) entry.insert(0, result)# 创建主窗口root = tk.Tk()root.title("人脸识别门禁系统")# 添加标签label = tk.Label(root, text="请将脸部置于摄像头前进行识别", font=("Helvetica", 14))label.pack(pady=10)# 添加按钮button = tk.Button(root, text="开始识别", width=20, height=2, command=start_recognition)button.pack(pady=20)# 添加文本框entry = tk.Entry(root, width=30, font=("Helvetica", 12))entry.pack(pady=10)# 添加进度条progress = tk.Label(root, text="识别进度:", font=("Helvetica", 12))progress.pack(pady=10)progress_bar = tk.Canvas(root, width=200, height=20)progress_bar.pack()# 添加响应式设计root.resizable(width=False, height=False)# 运行主循环root.mainloop()在这个示例代码中,我们增加了一个模拟的人脸识别过程,并在识别成功后更新文本框中的结果。此外,我们还添加了一个进度条来展示识别的进度信息,并设置了窗口不可调整大小,以实现响应式设计。
你可以根据实际需求进一步优化界面,例如设计更美观的布局和配色方案,添加更多交互元素以提供更多功能选择等。希望这个示例能够帮助你设计一个更加直观友好的用户界面,提升人脸识别门禁系统的用户体验。
十、日志记录和审计示例代码
 要记录系统的操作日志和事件,可以使用Python中的日志模块来实现。下面是一个简单的示例代码,演示如何在人脸识别门禁系统中记录访问日志,包括谁何时访问了系统:
要记录系统的操作日志和事件,可以使用Python中的日志模块来实现。下面是一个简单的示例代码,演示如何在人脸识别门禁系统中记录访问日志,包括谁何时访问了系统:
import logging# 配置日志记录logging.basicConfig(filename='access.log', level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')# 模拟用户访问系统def user_access(username): logging.info(f"用户 {username} 访问了系统")# 模拟用户访问user_access("Alice")user_access("Bob")user_access("Charlie")在这个示例代码中,我们首先配置了日志记录,指定日志文件名为access.log,设置记录级别为INFO,并定义了日志的格式。然后,我们定义了一个模拟用户访问系统的函数user_access,在函数中记录了用户访问系统的事件。
当用户访问系统时,调用user_access函数并传入用户名,日志模块会将相应的访问事件记录到日志文件中。
通过这种方式,你可以实现系统操作日志的记录和审计,以便进行后续的追踪和分析。你可以根据实际需求扩展日志记录功能,例如记录更多详细信息、添加时间戳等。希望这个示例能够帮助你实现日志记录和审计功能。
十一、归纳总结知识点
 开发人脸识别门禁系统时使用Microsoft Azure的Face API可以提供强大的人脸识别功能。以下是使用Microsoft Azure的Face API开发人脸识别门禁系统时的知识点归纳总结:
开发人脸识别门禁系统时使用Microsoft Azure的Face API可以提供强大的人脸识别功能。以下是使用Microsoft Azure的Face API开发人脸识别门禁系统时的知识点归纳总结:
Face API简介:
Microsoft Azure的Face API是一种面向开发人员的云端服务,提供了人脸检测、人脸识别、情绪识别、人脸比对等功能。可以通过API调用来实现人脸相关的各种功能,包括人脸检测、人脸识别、人脸验证等。功能特点:
人脸检测:检测图像中的人脸位置、大小和特征。人脸识别:识别图像中的人脸,并与已知的人脸进行匹配。情绪识别:识别人脸表情,如快乐、悲伤、愤怒等。年龄和性别识别:识别人脸的大致年龄和性别。人脸比对:比对两张人脸图像,判断是否属于同一个人。使用步骤:
创建Azure账号并订阅Face API服务。获取API密钥和终结点。发送HTTP请求进行人脸检测、识别等操作。处理API返回的JSON数据,获取识别结果。安全性:
Face API提供了安全的身份验证和授权机制,确保数据的安全性和隐私保护。可以通过访问令牌(token)来限制对API的访问权限。实时性:
Face API能够快速响应请求,并且具有较高的准确性和稳定性。可以实现实时人脸检测和识别,适用于门禁系统等需要即时反馈的场景。扩展性:
可以根据实际需求扩展功能,如集成人脸检测、识别功能到门禁系统中。可以结合其他Azure服务,如Azure Cognitive Services,实现更复杂的功能。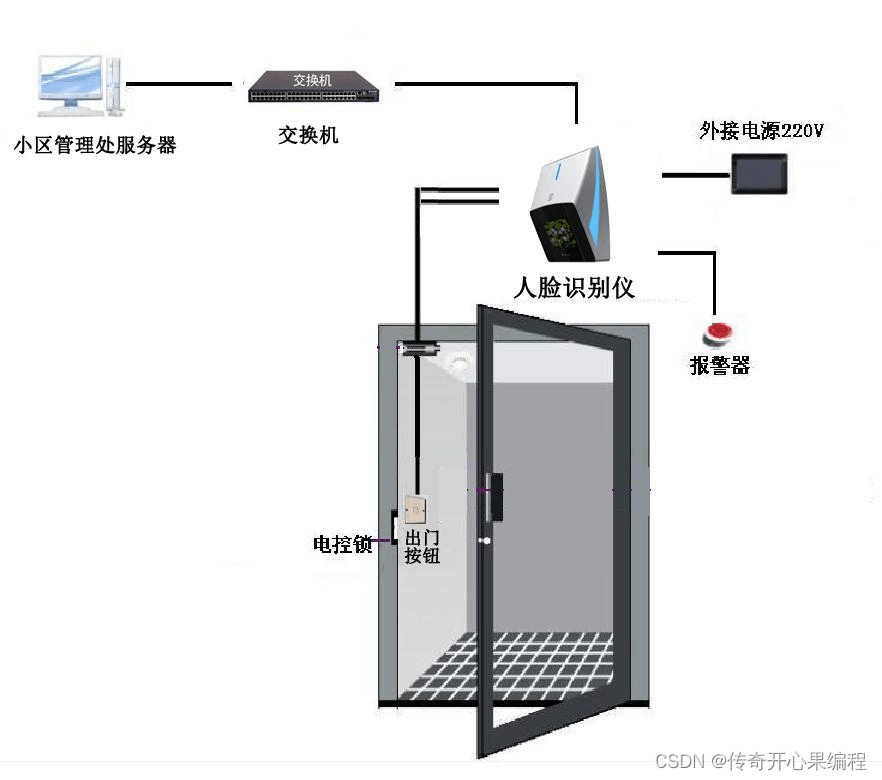
通过使用Microsoft Azure的Face API,开发人员可以快速实现人脸识别门禁系统,并且利用其强大的功能提升系统的安全性和用户体验。